- The paper introduces a semi-automated system that streamlines competency question elicitation using LLMs and iterative expert feedback.
- It details a four-phase workflow that integrates multi-source extraction, collaborative validation via a Notion dashboard, and automated reformulation.
- Empirical results show marked improvements in acceptance rates across scientific and cultural heritage scenarios, ensuring robust ontology requirements.
IDEA2: Expert-in-the-loop Competency Question Elicitation for Collaborative Ontology Engineering
Introduction
The bottleneck of competency question (CQ) elicitation continues to pose significant challenges in ontology engineering (OE), particularly in bridging communication between domain experts (DEs) and knowledge engineers. Traditional workflows depend on labor-intensive collaboration, resulting in inefficiencies and ambiguities that impede the construction of robust, relevant ontology requirements. IDEA2 proposes a semi-automated, expert-in-the-loop system that leverages LLMs within a collaborative feedback architecture to streamline requirement elicitation, validation, and iterative refinement.
Architecture and Workflow of IDEA2
IDEA2 decomposes the competency question lifecycle into four discrete, orchestrated phases: multi-source CQ extraction, collaborative expert validation, iterative reformulation guided by expert critique, and comprehensive provenance tracking. The architecture assigns the LLM the task of generating candidate CQs from heterogeneous sources, while validation and refinement are mediated by collaborative dashboards, allowing DEs to iteratively steer the specification process.
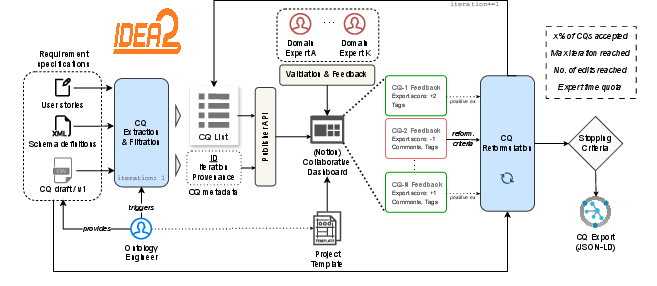
Figure 1: Overview of the IDEA2 architecture, showing LLM-based CQ extraction, collaborative validation, feedback-driven iterative reformulation, and export upon meeting stopping criteria.
Candidate CQs are ingested from narrative and semi-structured sources (e.g., personas, user stories, legacy schemas), processed via a prompt-engineered few-shot chain that enforces atomicity and abstraction, and de-duplicated through embedding-based similarity checks. The resulting CQ pool dynamically incorporates both machine- and human-authored requirements, maintaining flexibility across diverse OE scenarios.
Collaborative Validation and Feedback Integration
The validated pipeline is tightly integrated with an accessible, cloud-native dashboard—implemented via the Notion API—to capture structured votes, feedback, and comments for each CQ.
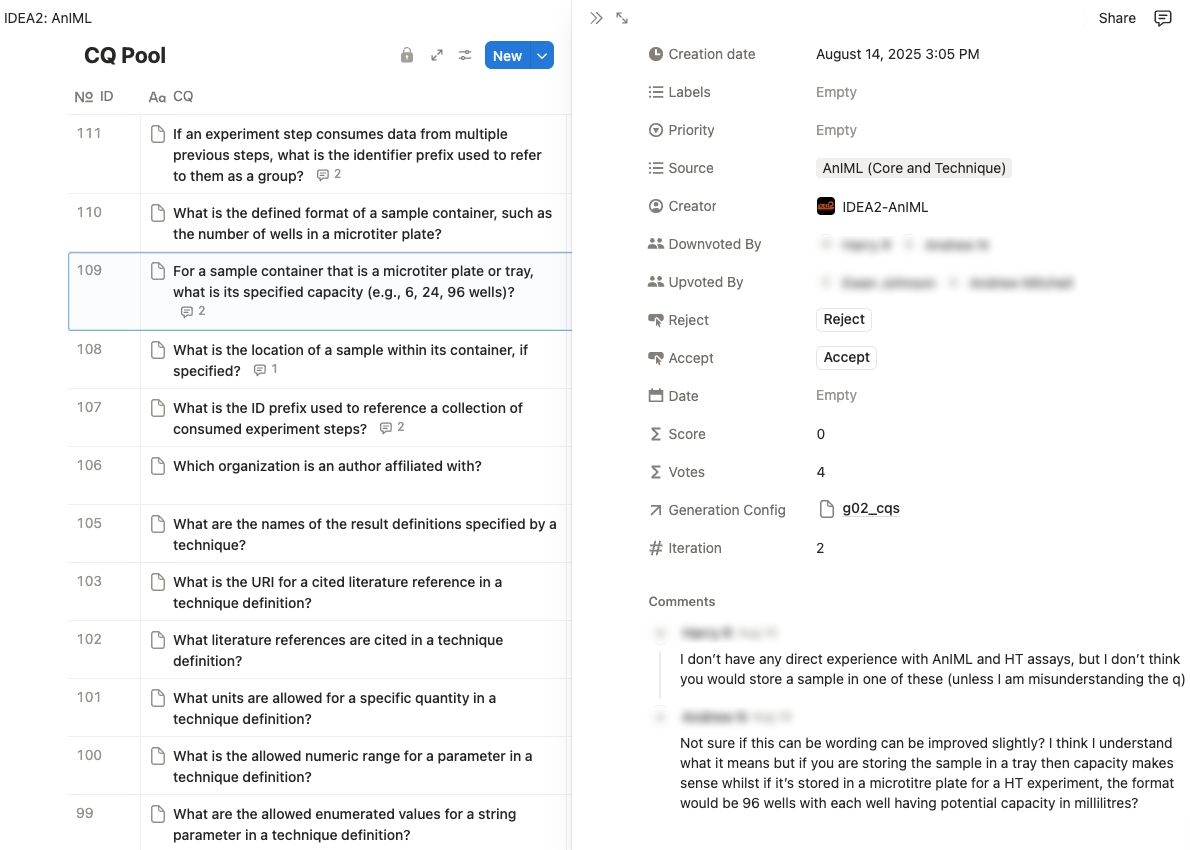
Figure 2: IDEA2’s collaborative dashboard on Notion, displaying the CQ Pool and detailed validation interface, highlighting expert comments that guide LLM reformulation.
This design choice lowers technical barriers, eliminates the complexity of domain-specific OE tools, and supports rapid deployment for interdisciplinary teams. The dashboard enables binary voting (accept/reject), thematic tagging, and a "Buy a Feature" inspired prioritization mechanism, enhancing stakeholder agency during requirements curation. Qualitative feedback is directly injected into subsequent LLM context, ensuring that every rejected CQ is reformulated based on actionable, domain-grounded critique.
A core innovation in IDEA2 is the feedback-driven reformulation loop. Any CQ whose net score falls below a predefined threshold triggers automatic revision by the LLM. Each reformulation prompt is contextually enriched with the full validation log, prior CQ versions, and cumulative expert feedback, allowing the system to focus revisions on substantive issues—disambiguation, abstraction, semantic drift—identified by domain experts.
This process is repeated until explicit iteration caps, consensus thresholds, or other stopping criteria are fulfilled, striking a balance between quality assurance and resource constraints. The reformulation mechanism is model-agnostic but optimized for large-context models (e.g., Gemini 2.5 Pro), supporting ingestion of extensive requirement specifications and multi-turn feedback histories.
Provenance Management and Export
IDEA2 ensures transparency, reproducibility, and downstream reuse by tracking the complete lineage of every CQ. Each record contains model parameters, source links, version histories, and derivation metadata. The standardised JSON-LD export integrates with the OWLUnit, PROV-O, and Croissant vocabularies, maximizing interoperability and encouraging open publication of high-quality requirements datasets.
Empirical Validation
IDEA2 was evaluated across two distinct scenarios: scientific data (AnIML XML schema) and cultural heritage (personas and curator user stories).
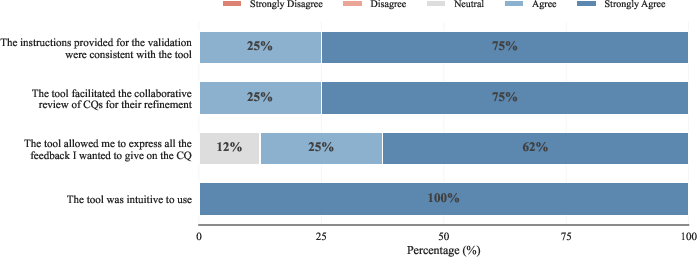
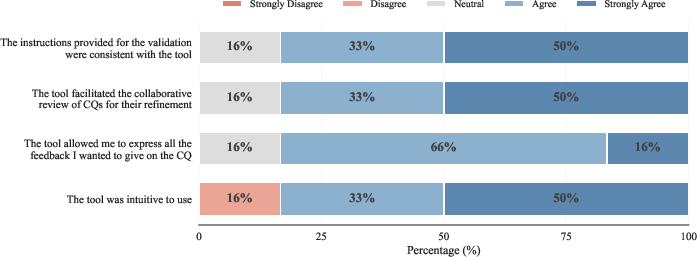
Figure 3: Scenario 1—AnIML workflow, illustrating application of IDEA2 in extracting and iteratively validating scientific data ontology requirements.
In the AnIML scenario, 103 CQs were generated from XML schema input, with a first-iteration acceptance rate of 95.1%. The iterative loop successfully elevated cumulative acceptance to 92.7% over 110 total validation tasks. The cultural heritage scenario stress-tested reformulation on previously rejected CQs, demonstrating a marked improvement—from an initial 69.6% acceptance to 85.7% post-reformulation—underscoring the efficacy of the HITL loop. Usability studies indicated high domain expert engagement and satisfaction in both settings.
Notably, the workflow yielded high observed inter-annotator agreement (≈90%), with Gwet’s AC1 and PABAK metrics confirming substantive reliability despite category imbalance. The system’s convergence rate and CQ throughput demonstrated practical acceleration over manual baselines.
Implications and Future Directions
IDEA2 recalibrates the role distribution within requirements engineering: knowledge engineers act as workflow facilitators and context curators, while DEs are empowered as direct validators and reformulators. This paradigm aligns with the demands of agile, iterative ontology development and supports broader, asynchronous expert participation—crucial for large-scale or distributed projects.
From a theoretical standpoint, the study confirms that LLMs can be reliably harnessed for requirement elicitation only when coupled to strong, contextually mediated human feedback. The HITL feedback loop not only corrects hallucinations and misalignments but enables the system to resolve subtle, domain-specific ambiguities that elude fully automated pipelines.
Further research is warranted to optimize expert engagement (e.g., via gamification), calibrate consensus mechanisms beyond majority voting (e.g., CrowdTruth models to manage constructive dissent), and improve the granularity and actionability of expert feedback. Integrating real-time feedback quality heuristics or active learning could further enhance reformulation accuracy and annotation efficiency.
Conclusion
IDEA2 operationalizes a robust integration of LLM automation with human expertise for the CQ authoring lifecycle in ontology engineering. The collaborative, reformulation-centered workflow demonstrated clear gains in efficiency, acceptance rate, and usability across both technical and narrative domains. By emphasizing transparent provenance, flexible integration, and actionable expert participation, IDEA2 positions itself as a modular, extensible architecture suitable for future high-stakes requirements engineering applications in AI- and knowledge-driven systems.