- The paper introduces Sven, which employs truncated SVD of the loss Jacobian to approximate natural gradient updates efficiently.
- Sven demonstrates accelerated convergence and lower regression loss compared to conventional optimizers like SGD, Adam, and LBFGS.
- The study highlights memory bottlenecks and proposes micro-batching and parameter-batching as strategies to scale optimization in over-parametrized models.
Sven: Singular Value Descent as a Computationally Efficient Natural Gradient Method
Introduction
The paper "Sven: Singular Value dEsceNt as a Computationally Efficient Natural Gradient Method" (2604.01279) introduces Sven, an optimizer for neural networks that leverages the decomposition of loss functions across individual data points. Sven utilizes a global view by simultaneously considering each sample's residual and calculating a minimum-norm update using the Moore-Penrose pseudoinverse of the loss Jacobian. To circumvent the computational intractability in the over-parametrized regime, the pseudoinverse is approximated via truncated singular value decomposition (SVD), retaining only the k dominant directions, resulting in approximately k-fold computational overhead relative to stochastic gradient descent (SGD).
Methodological Framework
The underlying principle of Sven is the explicit treatment of each data point's residual in batched loss optimization. Instead of aggregating losses into a scalar for gradient computation, as in SGD and its variants, Sven formulates the optimization as a simultaneous minimization of all point-wise residuals. Concretely, given a loss function decomposed as L(θ)=∑αℓα(θ), Sven constructs the Jacobian M of residuals with respect to parameters and determines the parameter update by application of the Moore-Penrose pseudoinverse, i.e., the solution to
δθ=−ηM+R,
where R is the vector of residuals, η the learning rate, and M+ the pseudoinverse. In large-scale neural settings, computing M+ directly is prohibitive due to memory and compute costs, so the update uses a truncated SVD with rank-k selected via a relative tolerance parameter.
This approach generalizes the natural gradient method to the over-parametrized regime: in the under-parametrized limit, Sven's update recovers the natural gradient prescription, whereas in modern settings—characterized by number of parameters vastly exceeding batch size—it yields a computationally feasible and empirically effective alternative.
Relation to Other Optimization Paradigms
Sven is positioned at the intersection of natural gradient descent, second-order/quasi-Newton optimizers, and recent pseudoinverse-based descent methods. Classic natural gradient descent [Amari 1998] is theoretically optimal for information-geometric progression but remains computationally infeasible for high-dimensional neural networks. Block-diagonal approximations such as K-FAC or Kronecker-factored variants attempt to alleviate this but fall short of handling the geometry of the entire loss Jacobian simultaneously.
Distinct among recent approaches, Sven applies SVD over the data index (i.e., sample-wise residuals) and computes the minimum-norm update across all constraints. In contrast, recent works such as Exact Gauss-Newton (EGN) [korbit2024egn] and Jacobian Descent (JD) [quinton2024jacobian] either operate on the model output Jacobian or introduce projection-based conflict resolution, but do not utilize the direct connection to natural gradients nor apply the SVD structure in the way Sven proposes. The mechanistic predecessor Half-Inverse Gradients (HIG) performs a similar SVD but applies continuous exponentiation rather than rank truncation and is focused on other application domains.
Empirical Results
Sven was evaluated on canonical regression tasks (1D function regression, random polynomial regression) and MNIST classification, compared to SGD, RMSProp, Adam, and limited-memory BFGS (LBFGS). Experiments consistently demonstrate Sven's accelerated convergence (both per-epoch and wall-time scaled) and lower final loss on regression benchmarks, with a wall-time efficiency advantage over LBFGS.
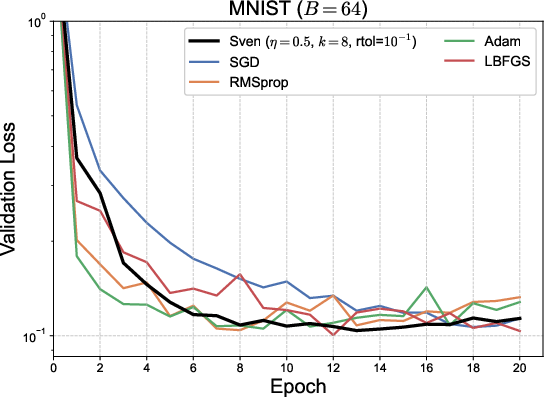
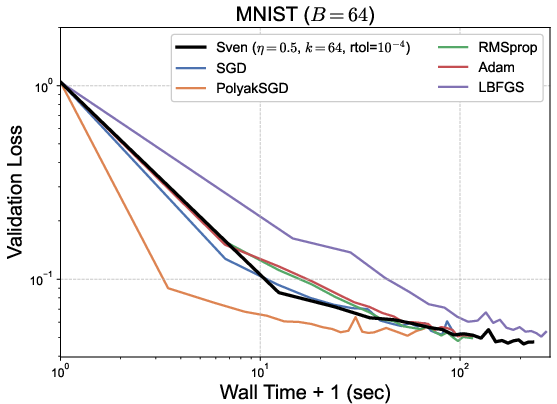
Figure 1: Validation loss as a function of epoch (top) and wall time (bottom) for several tasks. Sven converges faster per epoch and achieves lower loss than standard first-order optimizers, showing efficiency competitive with LBFGS at a fraction of the wall-time cost.
Key findings:
- Sven converges in fewer epochs and consistently to a lower loss than Adam, RMSProp, and SGD in regression settings.
- Despite increased per-step computation, wall time remains advantageous compared to quasi-Newton (LBFGS) methods.
- On MNIST, Sven matches Adam in classification error but does not surpass it, pointing to qualitative differences in the singular value structure between regression and classification objectives.
Ablation studies varying k0 and the SVD truncation parameter ("rtol") reveal performance saturation at k1 and sensitivity to the singular value spectrum hierarchy: in 1D regression, the hierarchy is pronounced, and additional singular directions matter; in high-dimensional polynomial regression and MNIST, the singular spectrum is flatter, diminishing the impact of high k2 values.
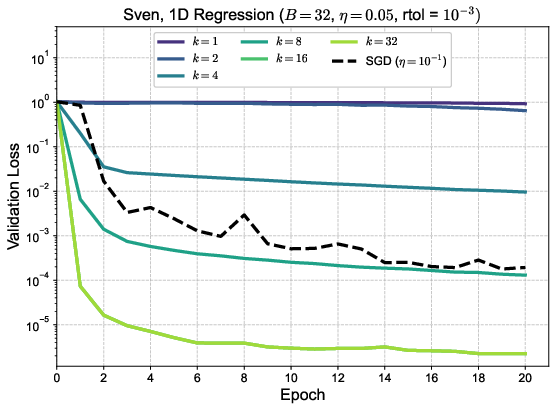
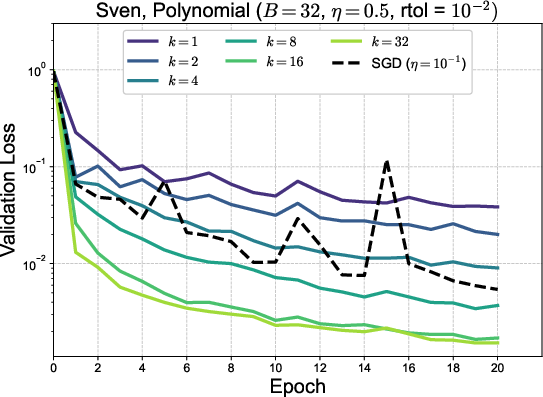
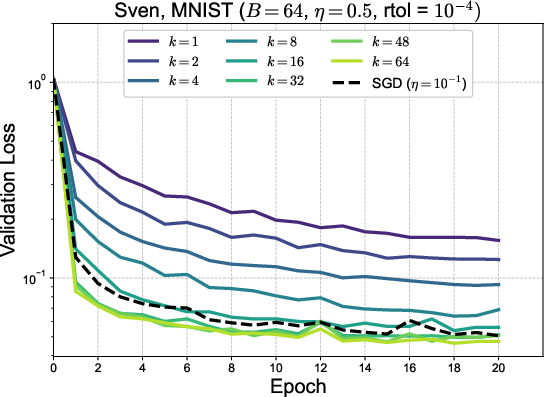
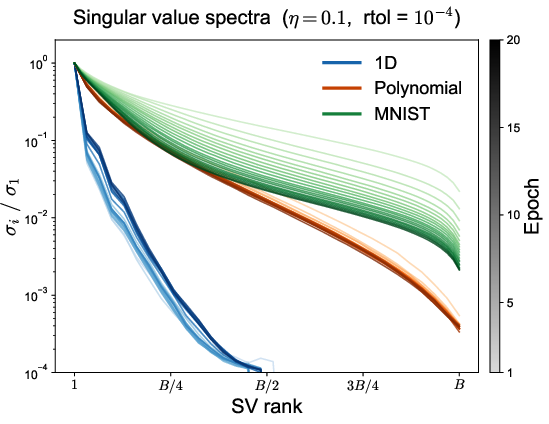
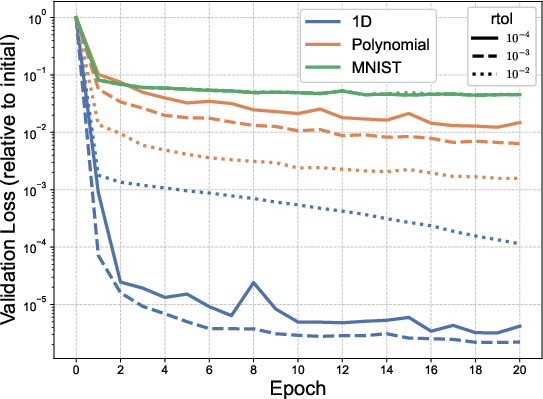
Figure 2: Training loss versus epoch for MNIST across varying k3 (top) and rtol (bottom right); bottom left displays singular value spectra evolution, showcasing divergences in singular structure across tasks.
To address the dominating memory bottleneck—the principal constraint in scaling Sven—two strategies were proposed: micro-batching (subdividing batches for localized residual aggregation) and parameter-batching (updating only parameter subsets per step). Micro-batching interpolates between per-sample and batch-mean loss, trading off memory for computational fidelity; parameter-batching, if supported by autograd frameworks, would further alleviate overhead by decreasing stored active subsets at each update.
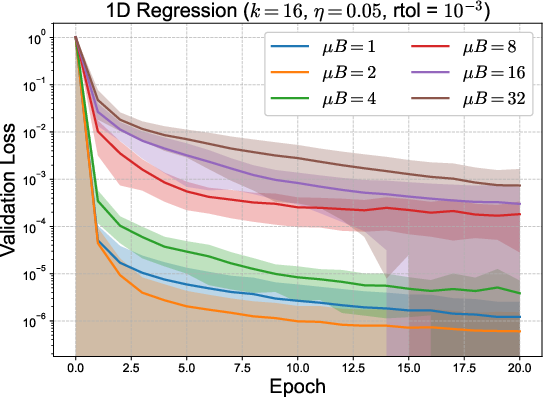
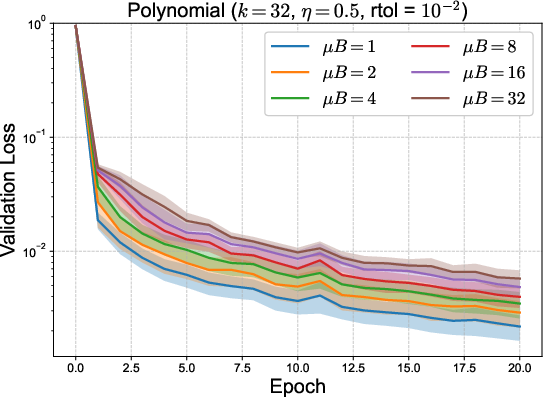
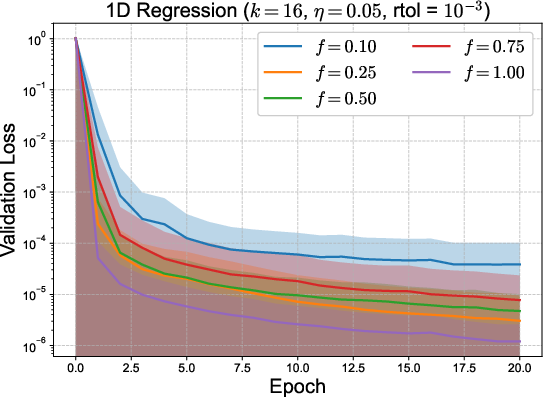
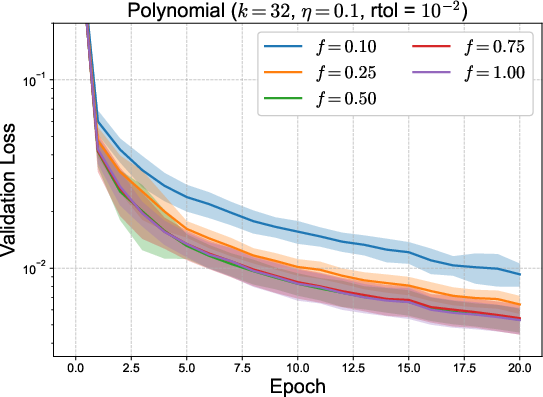
Figure 3: Validation loss for toy 1D and polynomial regression using micro-batching (top) and parameter batching (bottom) to balance memory and compute. Mean and error bands depict effect of reduced memory strategies.
Theoretical Implications
By explicitly connecting sample-wise loss structure, SVD of the residual Jacobian, and the natural gradient metric on the loss landscape, Sven prompts revisiting the geometric interpretation of optimization trajectories. In the under-parametrized regime, Sven corresponds exactly to natural gradient flow with exponential convergence of the expansion coefficients, supporting information-geometric interpretations. In the realistic over-parametrized setting, the pseudoinverse global update can be viewed as an informed compromise constrained by memory, using the leading singular modes to correct the optimization trajectory while regularizing against pathological updates from ill-conditioned directions.
Practical Applications and Speculative Outlook
Practically, Sven yields strong empirical results on regression tasks and exhibits competitive behavior for cross-entropy classification, though benefits are less pronounced. The algorithm is especially advantageous in scientific computing contexts where loss decomposition reflects physically meaningful constraints (e.g., collocation for PDEs or bootstrap equations for CFTs), making simultaneous residual minimization desirable. Enhanced extensions may include adaptive selection of SVD rank and hybridization with existing techniques (e.g., adaptive moment preconditioning or structured gradient compression).
Further scaling to large neural architectures will critically depend on autograd system modifications to support batch-level Jacobian-vector products without incurring prohibitive memory costs. Such developments would potentially enable tractable natural-gradient-inspired optimizers for domains currently restricted to first-order methods.
Conclusion
Sven provides a computationally feasible and geometrically grounded alternative to both first-order (SGD family) and classical second-order methods in neural network optimization. Its foundation in the SVD structure of the sample-wise loss Jacobian and its extrapolation of natural gradients to over-parametrized models sets a robust precedent for the integration of global geometric information in scalable optimizers. Its practical superiority in regression tasks, transparent connection to information geometry, and identifiable memory bottlenecks outline clear next steps for methodological and engineering advances.
References
- "Sven: Singular Value dEsceNt as a Computationally Efficient Natural Gradient Method" (2604.01279)
- Korbit et al., "Exact Gauss-Newton Optimization for Training Deep Neural Networks" (Korbit et al., 2024)
- Quinton & Rey, "Jacobian Descent for Multi-Objective Optimization" (Quinton et al., 2024)
- Schnell et al., "Half-Inverse Gradients for Physical Deep Learning" (Schnell et al., 2022)
- Amari, "Natural Gradient Works Efficiently in Learning" (Neural Computation, 1998)