- The paper introduces Diff-VS, a diffusion U-Net model that efficiently separates vocals from musical mixtures by adapting the EDM framework and music-aware normalization.
- It employs dual-path RoFormer blocks, band-splitting, and sinusoidal noise conditioning to capture time and frequency dependencies for improved cSDR performance.
- With only 57M parameters and up to 10 inference steps, Diff-VS outperforms state-of-the-art discriminative and generative models on both objective and perceptual metrics.
Diff-VS: An Efficient Audio-Aware Diffusion U-Net for Vocals Separation
Introduction
The paper "Diff-VS: Efficient Audio-Aware Diffusion U-Net for Vocals Separation" (2604.01120) introduces an advanced generative framework for singing voice separation based on the Elucidated Diffusion Model (EDM). While generative models have demonstrated significant impact in audio generation and speech enhancement, their translation to music source separation—particularly in matching the performance of discriminative baselines on standard objective metrics—has been limited by computational inefficiency and architecture-domain mismatch. This work proposes methodologically principled adaptations of EDM for separating vocals from musical mixtures, including a music-informed U-Net backbone, input normalization, and efficient architectural modifications targeting music-specific statistical properties.
Recent discriminative models employing band-splitting and transformer variants (e.g., BS-RoFormer, Mel-RoFormer, SCNet) have reached strong performance on multi-stem separation, leveraging audio-domain priors and efficient model scaling. In contrast, generative models for source separation, including DDPM-based pipelines, have lagged behind primarily due to excessive inference steps, inflated parameter counts, and inadequate training data utilization. Early generative approaches such as MSDM and Diff-DMX-musdb have required up to 150 forward passes during inference and used over 400M parameters, all while showing poor generalization to real music sources. Hybrid strategies that post-process discriminative separations via GANs or diffusion (e.g., SDNet, SGMSE) achieve perceptual gains but still fall short in objective metrics like chunk-level SDR (cSDR).
Notably, the EDM framework by Karras et al. provides several innovations relevant to music separation, namely (i) model-agnostic architectural flexibility, (ii) efficient step scheduling via the ρ-parameterized noise schedule, and (iii) σ-dependent preconditioning via skip connections. These features theoretically equip generative models with the necessary expressivity and efficiency for real-world audio separation tasks.
Proposed Methodology
Diff-VS computes the complex Short-Time Fourier Transform (STFT) of stereo mixtures, separating real and imaginary components into channels to construct a C×F×T tensor, later expanded via concatenation with the noisy target for C=8. Peak normalization and amplitude warping are applied to mitigate nonuniform spectral distributions. Subsequently, band-splitting divides frequencies for specialized processing, a feature shown to enhance results in compact U-Nets. After band-splitting with Ns=4, the input spectral image tensor consequently has C=32 channels.
Model Architecture
The core architectural advancement lies in adapting DDPM++ to music, substituting pixel-wise attention with dual-path RoFormer blocks to independently capture time- and frequency-axis dependencies—aligning architectural inductive bias with domain structure. Additional modifications include removing time-downsampling (to suppress aliasing) and using GELU activation with tanh-approximation for stability. Noise conditioning is implemented through sinusoidal embeddings injected into all encoder and decoder blocks.
Training and Inference Regimen
Models are trained on excerpts from MUSDB18‑HQ and MoisesDB, with heavy data augmentation and STFT settings of 2048/1024 for window/hop. Training uses Adam with a cosine-annealed schedule, exponential moving average, and careful batch construction. For inference, EDM's parameterized noise schedule is explored: σmin=0.002, σmax=80, with ρ=2–$7$ deciding the spread of inference steps. The method is architected to minimize steps (≤10) without Heun’s sampler, leading to significant acceleration.
Experimental Analysis
Ablation studies demonstrate that both spectrogram normalization and, critically, architectural modifications (dual-path RoFormer and frequency split) are required for high SDR. Adjusting the EDM σ0 parameter and reducing inference steps produce up to σ1 dB improvements—an uncommonly large effect given model size sensitivity. The selection of σ2–σ3 instead of canonical σ4 achieves uniformly distributed denoising steps, maximizing separation fidelity.
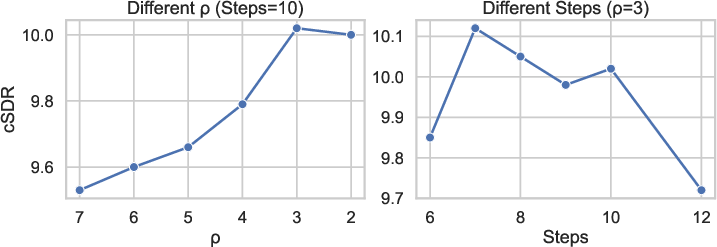
Figure 1: Ablation study illustrating the sensitivity of cSDR to inference parameter choices, especially the σ5 schedule and sampling steps.
When compared against state-of-the-art systems, the Diff-VS model (with only 57M parameters and 7 sampling steps) achieves 10.12 dB cSDR, outperforming HDemucs, TFC-TDFv3, and BSRNN discriminative models, and closing the gap with SCNet and BSRoFormer. Among generative approaches, Diff-VS surpasses previous best models (e.g., SGMSE, Diff-DMX) by at least 1.5 dB cSDR with fewer parameters and markedly fewer inference steps. With additional MoisesDB training data, the model further advances to 10.88 dB cSDR, only 2 dB behind the largest discriminative models despite not leveraging their scale.
Subjective quality, assessed via MERT-L12 embedding MSE (a reliable proxy for DMOS), reveals Diff-VS to outperform open-source SOTA models such as SCNet-L and SGMSEVS, indicating that architectural improvements in the generative regime also optimize perceptual quality, not merely objective SNR-based metrics.
Practical and Theoretical Implications
These results substantiate the applicability of diffusion models to source separation, counter to previous findings of their inferiority in music tasks. The demonstrated efficiency gain—operating at SOTA cSDR with a tenth the samples of antecedent generative works—enables practical, real-time or resource-constrained deployment. The strong subjective performance suggests a converging pathway between generative and discriminative paradigms, facilitated by input-aware normalization and domain-specific U-Net modifications.
Theoretically, this work shows that the EDM framework’s agnosticism enables effective adaptation to non-image domains via architectural priors (band-splitting, dual-path transformers). Additionally, the finding that nonstandard σ6 schedules yield marked improvements indicates that step-size scheduling for diffusion is highly domain-dependent and should not default to image-centric heuristics.
Future Directions
The presented framework can naturally be extended to multi-instrument separation given its modular channel structure, and the impact of more granular band-splitting, adaptive noise scheduling, or alternative spectral frontends (e.g., learnable filterbanks) warrants exploration. Further, diffusion-based post-processing of discriminative outputs, or integration into hybrid architectures, may unlock further perceptual gains. From an AI perspective, these results suggest that efficient generative models with appropriate audio priors can close the gap to discriminative methods, opening avenues for more interpretable, sample-efficient, and robust source separation systems.
Conclusion
This work establishes Diff-VS as an efficient, principled, and high-performing generative framework for vocal separation. Through domain-aligned input design, model architecture, and inference scheduling, the method sets new benchmarks for generative source separation, with both objective and subjective metrics approaching—and occasionally surpassing—leading discriminative systems. The study thus repositions diffusion models as viable, efficient candidates for music source separation, with compelling implications for future advancements in controllable and perceptually-optimized audio modeling.