- The paper presents DVGT-2, a novel model that leverages dense metric 3D geometry as a core representation for precise trajectory planning in autonomous driving.
- It employs a sliding-window streaming approach to achieve constant O(1) latency (~260ms/frame) and memory usage, enabling real-time inference.
- Empirical evaluations demonstrate state-of-the-art performance in local ray depth estimation and closed-loop planning across diverse benchmarks.
DVGT-2: A Vision-Geometry-Action Model for Scalable Autonomous Driving
Paradigm Shift: From VLA to VGA in Autonomous Driving
Recent end-to-end autonomous driving models have shifted from sparse perception-driven pipelines to vision-language-action (VLA) architectures that leverage VLMs for semantic context and decision making. However, language-centric models suffer from ambiguity and lack the spatial precision required for robust planning. "DVGT-2: Vision-Geometry-Action Model for Autonomous Driving at Scale" (2604.00813) advocates a paradigmatic transition to Vision-Geometry-Action (VGA), positing dense metric 3D geometry as the critical intermediate representation. VGA integrates fine-grained, pixel-aligned spatial information as the primary driver for trajectory planning, providing a more exhaustive and precise counterpart to VLA's high-level—but inherently lossy—scene abstraction.
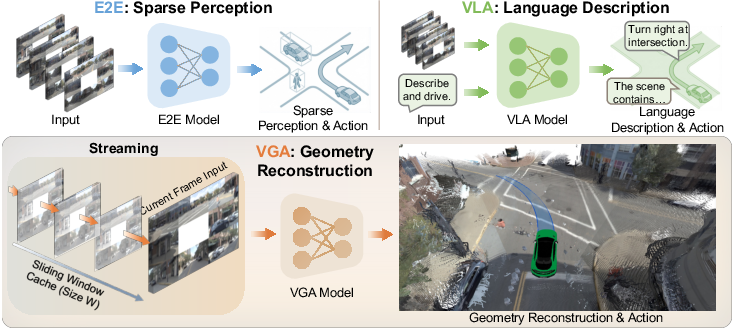
Figure 2: Comparative overview of paradigms in autonomous driving; VGA reconstructs dense 3D geometry, surpassing sparse and language-based intermediates.
DVGT-2 Architecture: Efficient Streaming Geometry and Planning
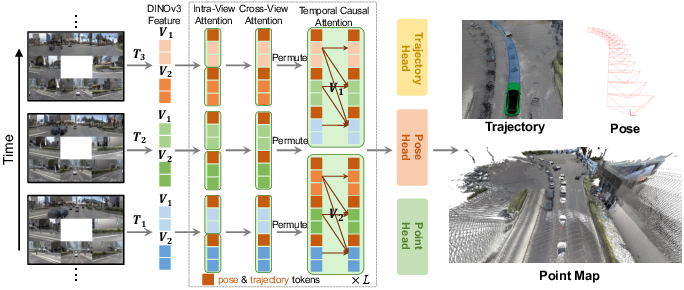
The core innovation in DVGT-2 is a streaming visual geometry transformer that processes online, multi-frame, multi-view inputs in real time, jointly predicting dense 3D pointmaps, current ego-poses (relative), and future trajectories per frame.
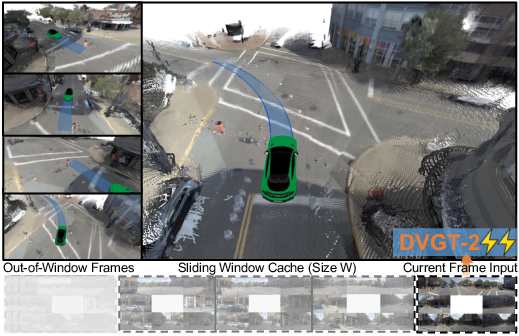
Figure 1: Overview of DVGT-2: A streaming architecture that jointly predicts dense geometry, ego state, and planned trajectory for each timestep from multi-camera inputs.
The model comprises:
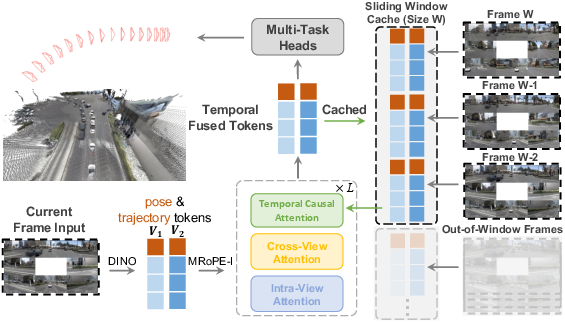
Sliding-Window Streaming: Constant-Cost Real-Time Inference
Contrasting with prior global and streaming geometry models (e.g., DVGT, StreamVGGT), DVGT-2 employs a fixed-size window to cache historical intermediate features, eradicating the computational and memory bloat associated with global or full-history paradigms. By reconstructing local geometry (per-frame, ego-centric) and accumulating only relative pose estimates, the model achieves:
Empirical measurements validate that DVGT-2 maintains stable latency (~260ms/frame) and flat memory usage across hundreds of frames, while alternatives suffer from quadratic or linear growth, ultimately leading to out-of-memory scenarios.
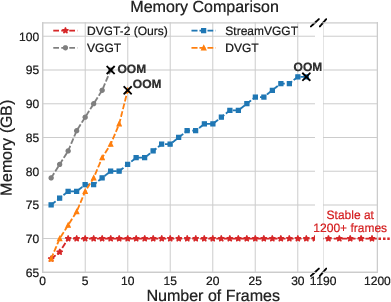
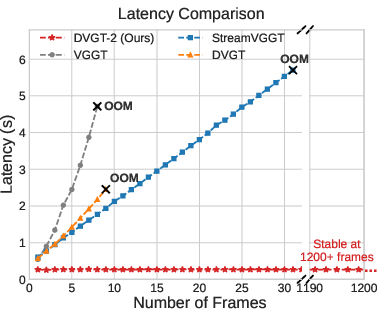
Figure 5: Memory usage comparison: DVGT-2 sustains constant cost versus catastrophic growth in prior models.
DVGT-2 achieves state-of-the-art performance in local ray depth estimation (Abs Rel, δ<1.25) across multiple datasets (OpenScene, nuScenes, Waymo, KITTI, DDAD), with competitive results in global point reconstruction despite lacking access to full trajectory context during inference.
- On OpenScene, DVGT-2 attains Abs Rel = 0.040, δ<1.25 = 0.977, far surpassing both full-sequence and previous streaming methods.
- On nuScenes, DVGT-2 outperforms all but the heaviest batch models in both accuracy and latency.
In closed-loop planning on NAVSIM v2, DVGT-2 achieves EPDMS = 88.9, outperforming all published SOTA, including VLA-based, occupancy-based, and multi-modal models. Open-loop planning on nuScenes yields an average L2 error of 0.78m and a collision rate of 0.19%, setting new benchmarks in safety and reliability.

Figure 7: Qualitative results: DVGT-2 reconstructs high-fidelity geometry and robust future trajectories from complex multi-view driving scenes.
Theoretical and Practical Implications
Adopting dense geometry as the central bridge between perception and action has significant implications:
- Theoretical: VGA dispenses with heuristic, application-specific sparse representations and language auxiliaries, leveraging continuous geometry for end-to-end optimization. The anchor-based diffusion for both pose and planning integrates uncertainty-aware, multi-modal distribution modeling into a metric-geometric pipeline.
- Practical: Sliding-window streaming supports unbounded real-world deployment without expensive fine-tuning or manual calibration across platforms. The annotation efficiency of geometry-based supervision reduces dependency on scarce labeled data.
DVGT-2's architecture can be adapted to alternative sensor configurations, extended camera setups, and rapidly varying environmental contexts with minimal modification—demonstrating robust out-of-domain generalization by direct transfer.
Limitations and Future Developments
The local-to-global aggregation for pose inference introduces cumulative drift, limiting long-term global consistency. Heavier predictors or global correction modules could help, but at the cost of real-time operation. Furthermore, the strong reliance on geometric consistency may underperform in situations where non-metric, high-level semantics are indispensable (e.g., reasoning about invisible agents or intent).
Future works may focus on:
- Integrating semantic priors with dense geometry for improved reasoning about occluded agents.
- Hybridizing world model architectures with VGA for more expressive, controllable simulation.
- Extending diffusion-based planners to longer horizons with self-correcting mechanisms for pose drift.
Conclusion
DVGT-2 operationalizes the Vision-Geometry-Action paradigm for scalable, annotation-efficient autonomous driving. Through online, streaming inference with fixed resource cost and joint prediction of geometry and plan, it achieves leading accuracy and safety across industry-standard benchmarks. The methodology marks a clear trajectory toward geometry-centric autonomous systems with robust, transferable, efficient planning modules, and opens new frontiers for integration with world models and semantic reasoning engines.