- The paper introduces a two-stage framework that combines video diffusion for multi-view synthesis with a density-driven X-ray sampling strategy and RDA network for CBCT reconstruction.
- It achieves state-of-the-art performance with PSNR of 39.21 dB and SSIM of 0.9735, significantly outperforming previous neural attenuation field methods.
- The method enables precise 3D dental imaging from a single X-ray, reducing radiation exposure and equipment costs while preserving fine anatomical details.
HiCT: High-Precision 3D CBCT Reconstruction from a Single X-ray
Introduction
Dental cone-beam computed tomography (CBCT) is the modality of choice for high-fidelity 3D visualization of maxillofacial anatomy, but its widespread adoption is hampered by high radiation exposure and equipment costs relative to 2D panoramic X-rays (PX). Single-image 3D reconstruction from PX thus offers clear practical value in clinical contexts, but is severely ill-posed due to projective scatter, view inconsistency, and the unique physics of X-ray imaging. The HiCT framework addresses these challenges through a two-stage architecture: (1) 3D-consistent multi-view generation using video diffusion models, and (2) volumetric CBCT synthesis leveraging a novel density-driven X-ray sampling strategy and a Ray-based Dynamic Attention (RDA) network.
Figure 1: The pipeline of HiCT.
Methodology
Stage 1: Multi-view Synthesis via Video Diffusion
The first stage addresses multi-view geometric consistency—a critical limitation in existing diffusion and GAN-based 2D-to-3D approaches. HiCT utilizes a video diffusion model to synthesize a sequence of projections from a single PX input, with explicit pose-conditioning and cross-attention to propagated CLIP feature embeddings. The input PX is first encoded to a latent space, concatenated with latent noise, and passed through a 3D U-Net denoiser conditioned on viewing elevation and semantics. Unlike prior methods producing independent views (e.g., Zero123 [zero123], SyncDreamer [Syncdreamer]), temporally coherent modeling ensures structural consistency across synthesized projections.
The loss is a pose-weighted MSE between the denoiser’s noise prediction and the ground truth diffusion trajectory, optimizing the alignment between predicted and true latent sequences across all camera poses.
Stage 2: 3D CBCT Reconstruction with Hybrid X-ray Sampling and RDA
CBCT synthesis is formulated as a NeRF-style volume rendering problem, but, critically, adapted to X-ray physics. HiCT’s X-ray sampling stratifies rays by material density, skipping near-vacuum intervals and focusing computational density in high-absorption anatomical regions. This is accomplished via construction of a 3D occupancy grid and systematic resampling within dense segments, enhancing both computational efficiency and anatomical fidelity.
The RDA network further advances neural field modeling by capturing intra-ray dependencies with multi-head self-attention. Features at sampled points along each ray are encoded, then processed in sequence-aware transformer blocks, culminating in radiodensity predictions sensitive to continuous attenuation and anatomical boundaries.
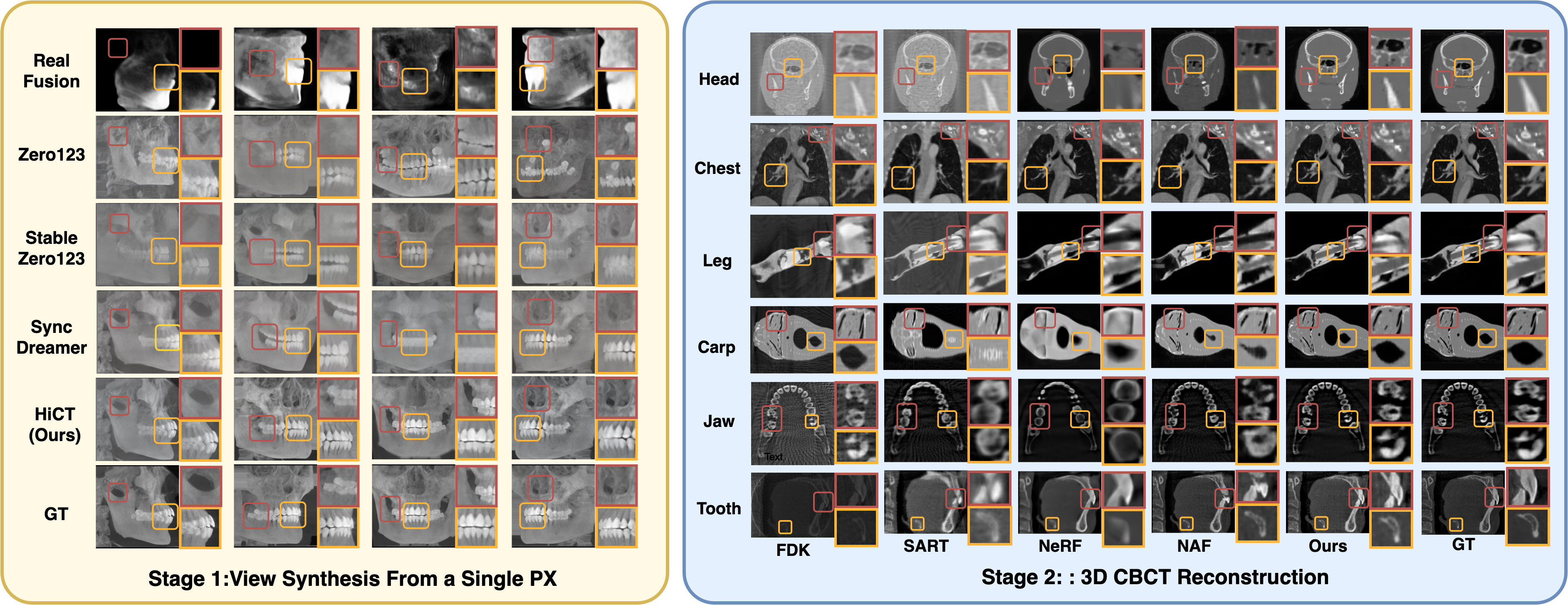
Figure 2: HiCT demonstrates excellent visual consistency and boundary clarity in the results of multi-view projection generation stage and 3D CBCT generation stage when compared with GT.
Experimental Results
The method is evaluated on the new XCT dataset (500 PX-CBCT pairs plus extensive public CBCTs), outperforming all prior approaches by a substantial margin. HiCT achieves average PSNR/SSIM of 39.21 dB/0.9735, exceeding the best neural attenuation field baseline (NAF) by 5.8 dB PSNR and 0.062 SSIM, and demonstrating notable improvements in challenging anatomical regions—up to +7 dB on extremities ("Leg") and +7.7 dB on organs ("Pancreas").
In the view synthesis stage, HiCT attains PSNR 21.01 and SSIM 0.865, outperforming prior top methods (e.g., SyncDreamer) by +4.7 PSNR and +0.123 SSIM, and yielding superior scores across perceptual (LPIPS) and segmentation metrics (IoU, Dice). Qualitative comparisons confirm that HiCT eliminates common texture incoherence, ghosting, and geometric distortion present in contemporaneous diffusion and NeRF-based methods. The generated CBCT volumes preserve boundary sharpness and fine anatomical structure with remarkable fidelity.
Ablation studies reveal that both the X-ray sampling and RDA mechanisms contribute complementary gains: the hybrid sampler alone improves PSNR by +1.73 dB over baseline, while RDA adds +3.29 dB; combined, they deliver a +4.81 dB improvement.
Discussion and Implications
HiCT advances single-view 3D dental reconstruction by resolving multi-view inconsistency, suboptimal sampling, and physically inaccurate X-ray modeling—three long-standing obstacles in clinical neural rendering applications. The video diffusion paradigm enforces geometric coherence, critical for downstream inference tasks. The hybrid X-ray sampling paradigm ensures computational focus on meaningful anatomical detail, while RDA unlocks superior modeling of attenuation and material-specific radiodensity.
Theoretically, HiCT bridges a significant gap between 2D imaging and high-precision 3D reconstruction, without requiring multi-angle tomographic acquisition. Practically, it lowers the barrier for precise 3D dental imaging in resource-limited settings, supports data-efficient, low-radiation workflows, and provides a template for broader medical and industrial X-ray reconstruction tasks.
Future work could extend HiCT’s framework to generalized radiographic modalities, integrate explicit anatomical or patient-specific priors, and couple with self-supervised or reinforcement learning strategies for continuous adaptation to broader clinical variation.
Conclusion
HiCT demonstrates that high-fidelity, geometry- and detail-consistent 3D CBCT volumes can be reconstructed from a single PX through a hybrid video diffusion and neural rendering pipeline. The combination of pose-conditioned diffusion, density-aware X-ray sampling, and dynamic ray attention yields state-of-the-art performance both quantitatively and qualitatively across diverse anatomical regions. HiCT sets a new standard for single-view volumetric reconstruction in medical imaging, with wide-reaching implications for accessibility, safety, and clinical usability.

