- The paper introduces a novel hypergraph partitioning framework that integrates logic replication to minimize inter-FPGA communication cost.
- It employs dynamic FPGA-aware coarsening and heat-driven assignment to optimize resource utilization while reducing latency.
- Empirical results demonstrate a 52.3% reduction in hop distance and an 11.1× speedup over state-of-the-art methods, ensuring scalability.
RePart: Logic Replication-Optimized Hypergraph Partitioning for Multi-FPGA Systems
Problem Motivation and Prior Art
Partitioning logic netlists for deployment onto multi-FPGA systems (MFS) is an enduring challenge in large-scale VLSI verification, hardware emulation, and recently, LLM hardware platforms. The crux lies in distributing highly-connected, resource-diverse netlists onto multiple FPGAs under severe resource, I/O bandwidth, and topology constraints, while minimizing total inter-FPGA communication cost. Existing approaches—predicated on classical multilevel hypergraph partitioning paradigms—typically emphasize edge cut optimization or cut size minimization, neglecting MFS-specific topological communication patterns and hardware underutilization stemming from static balance constraints.
Several state-of-the-art frameworks (e.g., hMETIS, KaHyPar), along with recent MFS-oriented solutions (e.g., TopoPart, MaPart), seek to minimize the logical cut or edge cuts, but suffer fundamental limitations: they abstract away network topology (e.g., non-mesh interconnect, bottleneck links) and tend to leave a significant portion of on-chip resources idle due to conservative load balancing. This exacerbates I/O congestion, inflates TDM overhead, and impedes scalability in large, heterogeneous MFS deployments.
Framework Overview and Technical Innovations
RePart introduces a topology- and resource-aware multilevel hypergraph partitioning pipeline with rigorously integrated logic replication, explicitly targeting the minimization of total hop distance and maximization of resource utilization. The authors firmly position RePart as not merely an incremental improvement but a comprehensive rethinking of the partitioning flow to accommodate the actual physical and architectural realities of contemporary MFS.
The pipeline comprises:
- Dynamic Coarsening with FPGA-Aware Scoring:
Coarsening proceeds by merging node pairs based on a combined connectivity and balance score. Notably, a dynamically adapted penalty exponent governs the influence of resource imbalance over the coarsening levels, transitioning from connectivity-driven clusters to resource-balanced aggregates, thus preserving both interconnect locality and mapping feasibility. The penalty adapts logarithmically with the coarsening depth to maintain an optimal balance between solution quality and feasibility.
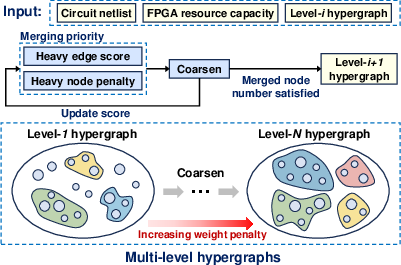
Figure 1: Adaptive vertex merging in coarsening, smoothly shifting from connectivity-oriented to resource-balanced clusters as hierarchy deepens.
- Heat-Value Guided Assignment:
Assignment to FPGAs employs a "heat value": a metric quantifying both the centrality of FPGAs in the physical network and the criticality/connectivity of nodes, informing an efficient, topology-minimizing initial mapping. High heat nodes are preferentially mapped to low-hop central FPGAs, with explicit consideration for heterogeneous FPGA capacities. Deep backtracking and heuristic-driven exploration allow for cross-valley moves and improved escape from local minima.
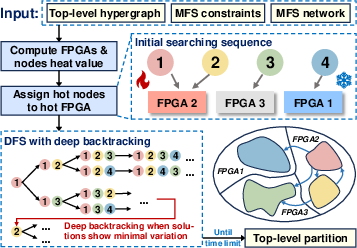
Figure 2: High-heat nodes are prioritized for assignment to well-connected, resource-rich FPGAs, promoting minimal hop communication.
- Refinement with Logic Replication and Deletion:
RePart’s refinement innovates beyond standard FM/KL local moves and exchanges: it supports logic replication—copying logic to multiple FPGAs to locally satisfy downstream sinks, thereby truncating inter-FPGA connections—as well as a deletion operation for pruning excessive/obsolete replicas. These four operators (move, exchange, replicate, delete) are scheduled through a tailored $1+3K$-Heap structure enabling rapid, local gain recalculation, crucial for large benchmarks. Incremental gain updates ensure fast adaption to refined hypergraph states, and the delete operation is strategically deployed to recover resource headroom for subsequent beneficial moves.
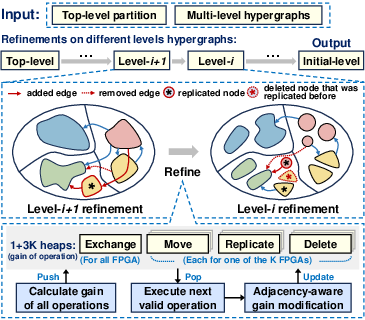
Figure 3: The four-tier refinement phase incorporates logic moves, exchanges, replication to new FPGAs, and strategic deletion for resource recovery.
Numerical Results and Empirical Claims
RePart is evaluated on both the strict EDA Elite Challenge Contest benchmark (complex, weighted, multi-resource, topology-rich) and the conventional Titan23 suite (unweighted, single resource). The principal metric is total hop distance, a direct proxy for communication latency and TDM overhead in real MFS.
- Average hop distance reduction: On the EDA Contest, RePart cuts total hop distance by 52.3% relative to KaHyPar and 14.0% relative to the contest’s best entries, with an average 11.1× speedup.
- Resource utilization: Replication alone (as tested in the RePart-mini ablation) provides substantial benefit, but full RePart (dynamic coarsening, heat-guided assignment, four-mode refinement) demonstrates a further major jump in quality.
- Cut size: Despite not being the optimization target, cut size (legacy metric) is concurrently improved, outperforming or matching all contemporary frameworks.
The framework demonstrates stable improvements across both complex and (relatively) simpler benchmarks, validating its generality.
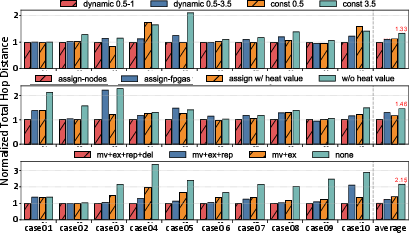
Figure 4: Ablation study showing that each major RePart innovation (dynamic coarsening, heat assignment, four-op refinement) yields compounding reductions in normalized total hop distance.
Theoretical and Practical Implications
RePart refines the design space for hypergraph partitioning with the following implications:
- Resource-Efficient Replication: Direct integration of logic replication within the multilevel flow ensures resources are thoroughly exercised, not simply partitioned. The inclusion of deletion maintains long-term flexibility and refines prior multilevel approaches, which did not support refined resource recovery.
- Topology-Conscious Partitioning: By optimizing hop distance rather than naive cut size, RePart directly targets physical deployment metrics (latency, bandwidth, TDM), which are critical in the context of dense, bandwidth-constrained hardware fabrics.
- Acceleration: The $1+3K$-Heap structure together with local, incremental gain recalculation admits significant runtime reduction, breaking an important barrier of hypergraph partitioning applicability to industrial-scale netlists.
- Generalizability: RePart’s improvements are transferable to unweighted/simpler partitioning contexts, ensuring backward compatibility and extensibility.
Practical deployments integrating RePart can expect notable reductions in interconnect delay and improvements in FPGA utilization, making it suitable for current corners of VLSI emulation, rapid ASIC prototyping, or distributed AI hardware backends.
Future Directions
Several avenues emerge for future development:
- Hierarchical Heterogeneous Hardware: Extending RePart to accommodate not solely multi-FPGA but hybrid accelerator fabrics (FPGA-ASIC, FPGA-CPU) with diverging network and resource profiles.
- Non-Tree/Irregular Topologies: Further customizing the methodology for non-standard, perhaps reconfigurable, inter-FPGA topologies seen in evolving hardware cloud fabrics.
- Online Partition Adaptation: Integrating online adaptation for dynamic netlists or dynamically reconfigurable logic platforms.
Conclusion
RePart delivers a rigorously engineered, open-source hypergraph partitioning framework fusing topology-awareness, adaptive coarsening, heat-driven assignment, and a resource-recovering, replication-optimized refinement mechanism into a unified pipeline. Empirical evidence substantiates strong reductions in communication cost and substantial runtime acceleration, advancing the boundary of scalable logic partitioning for contemporary multi-FPGA platforms. RePart’s methodologically sound and modular innovations position it as a robust foundation for further advances in hardware-aware partitioning and resource-optimized deployment.

