- The paper introduces a Hypergraph Bradley-Terry model that generalizes pairwise comparisons to multiplayer games using directed hyperedges.
- It derives fixed-point iterative updates that efficiently estimate latent player strengths even with varying team configurations.
- Empirical results on synthetic and Whist datasets demonstrate high correlations with true skills and scalable performance with increased game counts.
Extension of the Bradley-Terry Model to Directed Hyperedges: Inference and Empirical Analysis
Introduction and Motivation
The paper "On rankings in multiplayer games with an application to the game of Whist" (2604.00641) addresses statistical ranking in multiplayer game contexts where two possibly non-fixed teams compete and team compositions vary across matches. Traditional paired-comparison models, notably the Bradley-Terry (BT) model, are limited to fixed teams or individual pairings, with log-likelihood maximization approaches dating back to Zermelo. Prior computationally efficient algorithms (e.g., Newman's accelerated update) still assume two-player or fixed-team scenarios. Realistic settings—including partnership card games, team-based video games, and variable-cohort sports—necessitate joint inference over a latent space capturing individual strengths when matches map onto generalized, structured interactions.
The authors introduce a generalization of the BT model to games represented as directed hyperedges, where each observed outcome indicates a win of team I over team J, with I and J arbitrary (typically disjoint) subsets of the player pool. This formulation naturally encodes games like Whist, bridge variants, or ad-hoc digital games where team configurations change. The paper posits a probabilistic structure for these outcomes, derives efficient fixed-point parameter estimation rules generalizing Newman's method to directed hypergraphs, and benchmarks these against existing alternatives.
Hypergraph Bradley-Terry (HBT) Model
The probability of a team I defeating team J is modeled as
P[I←J]=∏i∈Iπi+∏j∈Jπj∏i∈Iπi
where πi>0 signifies the strength/skill of player i. This framework admits games with unequal team sizes and accommodates a latent skill parameter per individual. Unlike standard Bradley-Terry, rescaling invariance no longer holds when ∣I∣=∣J∣, and the outcome distribution does not correspond to a sum-based aggregation, in contradistinction to the Generalized Bradley-Terry (GBT) model of Huang et al., where
J0
Given a collection of observed hyperedges J1 with associated outcome counts J2, the log-likelihood is
J3
from which an efficient fixed-point iteration akin to Newman's update for the classical BT model is derived:
J4
This iteration enjoys improved empirical convergence rates compared to previous Zermelo-style updates even in high-cardinality hypergraph regimes, and reduces to Newman's update in the two-player limit.
Fast Estimation for GBT
The paper also presents an alternative update rule for the GBT model:
J5
which mirrors the HBT update structure but leverages sum-based scoring for team strength.
Computational and Theoretical Remarks
The derivation systematically applies gradient ascent to the log-likelihood, grouping terms to construct monotonic updates. Robustness to team overlap and an explicit extension to non-disjoint sets is provided, which is relevant for citation or influence networks. Notably, convergence guarantees and identifiability under mild connectivity assumptions are left as future work.
Comparison with Existing Models
Two principal alternatives frame the comparison:
- Generalized Bradley-Terry (GBT) Model: Employs additive aggregation, appropriate for modeling "best-of" or "group-leader" competitions, where total team strength sums linearly. However, its likelihood landscape and convergence characteristics differ substantially from the HBT.
- Plackett-Luce (PL) Model: Handles cases where the output is a full ordering/permutation of all players; inapplicable to two-team settings with only win/loss outcomes and no ordinal ranking.
Empirically, the HBT model offers more nuanced sensitivity to team configuration than both BT (which breaks hyperedges into all possible pairwise wins) or GBT, and aligns with logistic assumptions on the difference in aggregate team “log-strength.”
Empirical Results
Synthetic Data
The authors evaluate their inference algorithms on synthetic datasets generated according to the HBT generative mechanics with varied player pools and match counts.
Strong monotonicity is observed in Pearson correlation between inferred (J6) and true (J7) latent skills as the volume of data increases, and the algorithms yield highly concordant rankings—up to the permutation ambiguity induced by invariance in the model.
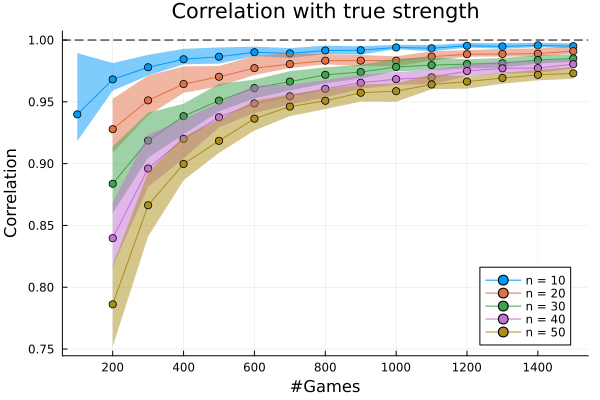
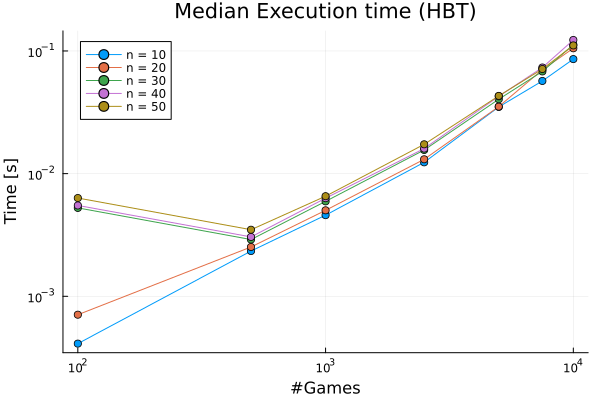
Figure 1: Left: Pearson correlation of estimated and true strengths for varying numbers of players and hyper-edges using the HBT inference method and comparators (GBT, BT); Right: Execution time scaling of HBT inference as a function of player count and hyper-edge count.
Computational cost is primarily a function of the number of observed games rather than player pool size, with HBT exhibiting essentially linear scaling in problem size, whereas classical BT (using pairwise collapses) quickly saturates as hyperedges increase.
Application to Whist Dataset
A real-world dataset is constructed from 300 games of Whist with 17 active participants. Each game structurally maps to a hyperedge (with frequent 2v2 play but also 1v3), and player performance is assessed by inferred latent strength in HBT, GBT, and classical BT—alongside empirical win rate benchmarks.
All methods yield approximately consistent rankings (Pearson correlation J8 between strength estimates), with slight variabilities. Methods diverge most for players with low participation; those with few games cluster at ranking extremes, reflecting greater uncertainty in latent strength inference due to data sparsity.
Implications and Prospects
Practical Use-Cases
The HBT model is directly applicable for ranking in:
- Multiplayer/combinatorial card games and their digital analogues
- Team sports with shifting compositions (e.g., pickup basketball)
- Systems where group-based outcomes are observed but aggregated over dynamically changing team assignments
The fixed-point inference method is scalable and well-suited to online or streaming analysis, provided outcome data is complete and the underlying hypergraph is sufficiently connected.
Theoretical Outlook
While empirical identifiability is promising, further work is required to analyze:
- The exact convergence properties in high-dimensional and sparse-observation limits
- Robustness to dependence between outcomes or non-competitive “noise”
- Extension to models with draws, ties, or explicit outcome randomness (as in (Fang et al., 21 Jan 2026))
- Inference under partial observability (incomplete hyperedges, missing data)
Further, the framework could be adapted to continuous or multi-class outcome scenarios and for broader combinatorial team structures. Bayesian and regularized variations could be explored to more systematically address player inactivity or low-frequency participation.
Conclusion
This work formulates an extension of the Bradley-Terry model for analyzing teamwise outcomes in multiplayer games, introducing an efficient inference method for player strengths and validating it both synthetically and on real-world competitive data. The approach generalizes classical paired-comparison inference, better suits modern heterogeneous multiplayer settings, and complements additive-aggregation alternatives like GBT. It lays a foundation for robust, scalable ranking systems in dynamic team competition environments and motivates future research into statistical and algorithmic properties of inference on outcome-labeled directed hypergraphs.

