Towards Reliable Truth-Aligned Uncertainty Estimation in Large Language Models
Published 1 Apr 2026 in cs.AI and cs.CL | (2604.00445v1)
Abstract: Uncertainty estimation (UE) aims to detect hallucinated outputs of LLMs to improve their reliability. However, UE metrics often exhibit unstable performance across configurations, which significantly limits their applicability. In this work, we formalise this phenomenon as proxy failure, since most UE metrics originate from model behaviour, rather than being explicitly grounded in the factual correctness of LLM outputs. With this, we show that UE metrics become non-discriminative precisely in low-information regimes. To alleviate this, we propose Truth AnChoring (TAC), a post-hoc calibration method to remedy UE metrics, by mapping the raw scores to truth-aligned scores. Even with noisy and few-shot supervision, our TAC can support the learning of well-calibrated uncertainty estimates, and presents a practical calibration protocol. Our findings highlight the limitations of treating heuristic UE metrics as direct indicators of truth uncertainty, and position our TAC as a necessary step toward more reliable uncertainty estimation for LLMs. The code repository is available at https://github.com/ponhvoan/TruthAnchor/.
The paper establishes that common uncertainty metrics can fail due to proxy failure, where internal signals do not correlate with factual correctness.
It presents Truth Anchoring (TAC), a lightweight post-hoc calibration method using minimal supervision to convert raw scores into truth-aligned probabilities.
Experimental results demonstrate significant reductions in Expected Calibration Error and improved generalizability across various LLM architectures and datasets.
Truth-Anchored Uncertainty Estimation in LLMs
Motivation and Problem Statement
LLMs are widely deployed, but their tendency to generate factually incorrect or hallucinated outputs poses persistent reliability challenges in domains such as medicine and finance. Uncertainty estimation (UE) is used to score each generation according to its predicted correctness, with the hope of surfacing potential hallucinations for downstream intervention or abstention. However, empirical observation reveals that widely used UE metrics (predictive entropy, perplexity, response consistency, various information-theoretic and embedding-based scores) often fail to generalize: their discriminative and calibration performance degrades sharply across datasets, architectures, and evaluation settings. The paper formalizes this instability as "proxy failure," highlighting that most uncertainty metrics are informed primarily by model-internal signals rather than being explicitly grounded in the factual correctness of outputs.
Formal Characterization of Proxy Failure
The paper offers a theoretical analysis connecting the discriminability of an uncertainty score (as quantified by AUC for distinguishing correct from incorrect generations) to the mutual information between the score and the actual correctness label. The central result establishes that if a given UE score S carries only minimal information about correctness C, then its AUC is provably close to chance:
∣AUC(S)−0.5∣≤I(C,S)/2pc(1−pc)
where I(C,S) is the mutual information and pc is the base rate of correctness (see Section 3 for details).
A concrete instantiation of proxy failure is provided via predictive entropy. The authors show via constructive argument that it is possible for two responses—one correct, one incorrect—to generate identical entropy profiles under certain generative scenarios. Thus, predictive entropy (and by extension, many local uncertainty measures) can become entirely non-discriminative with respect to truth.
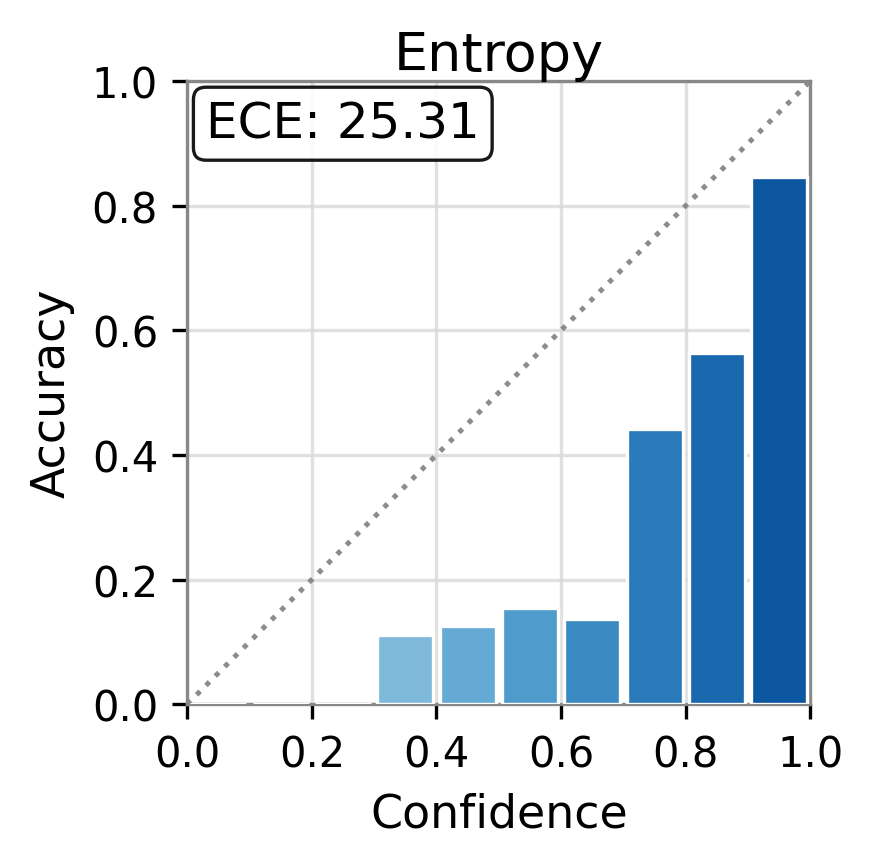
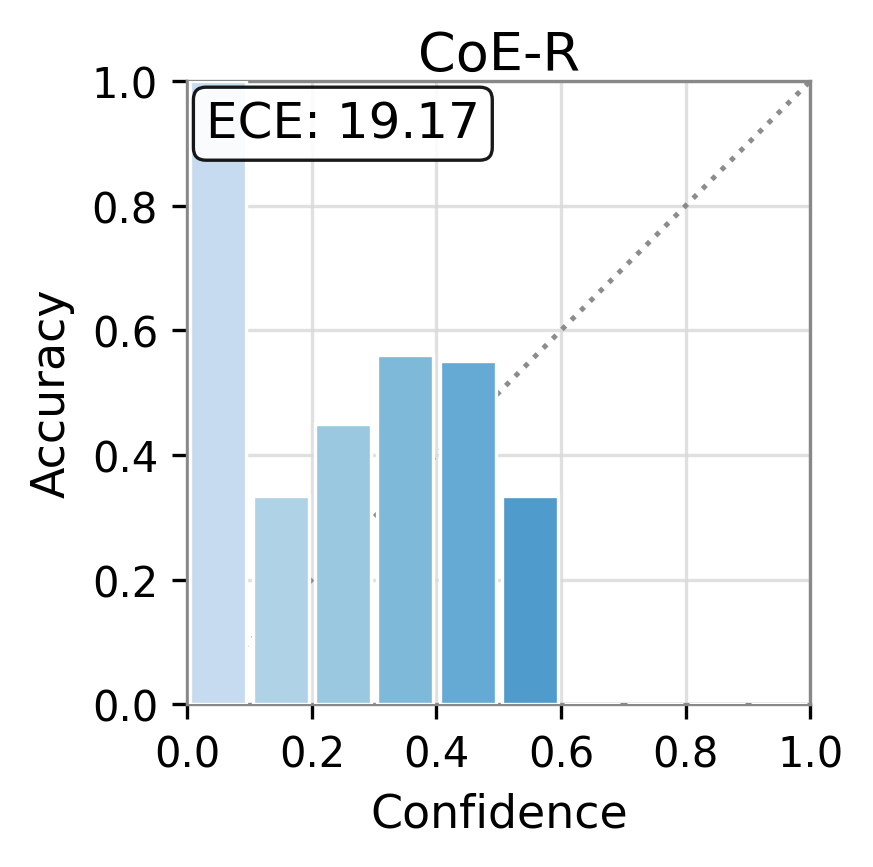
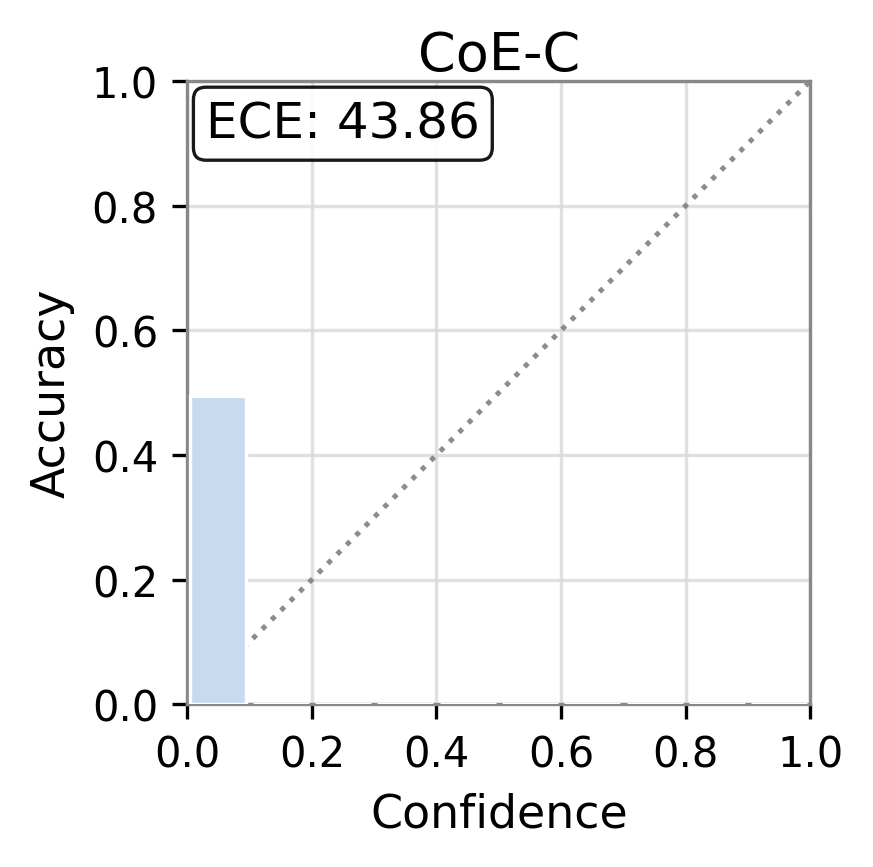
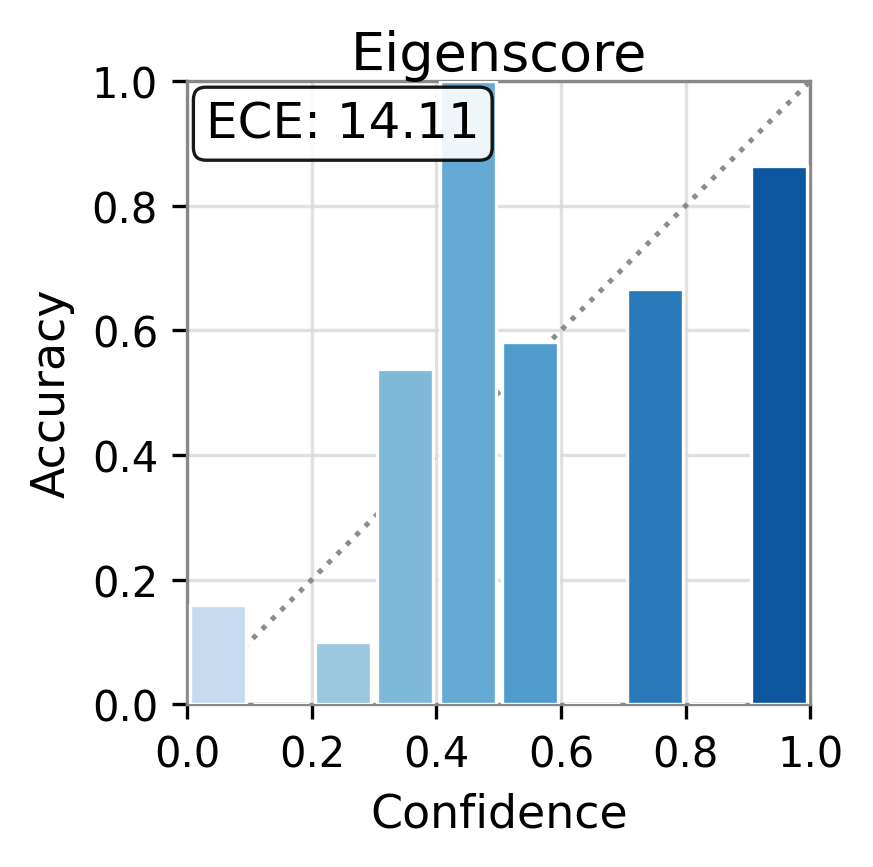
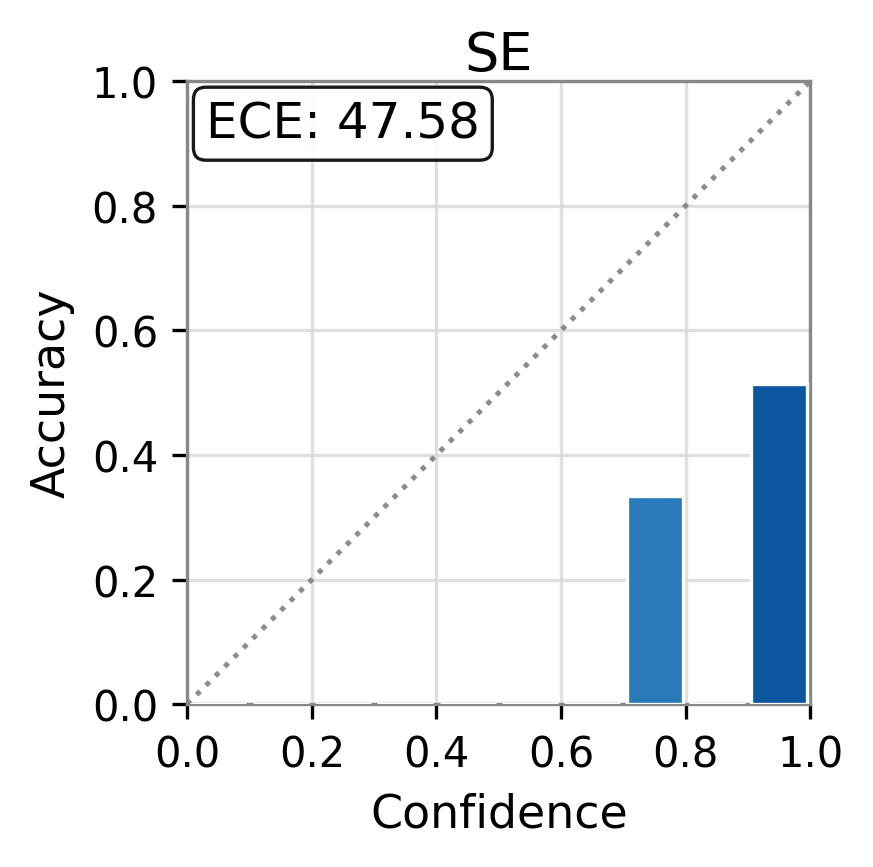
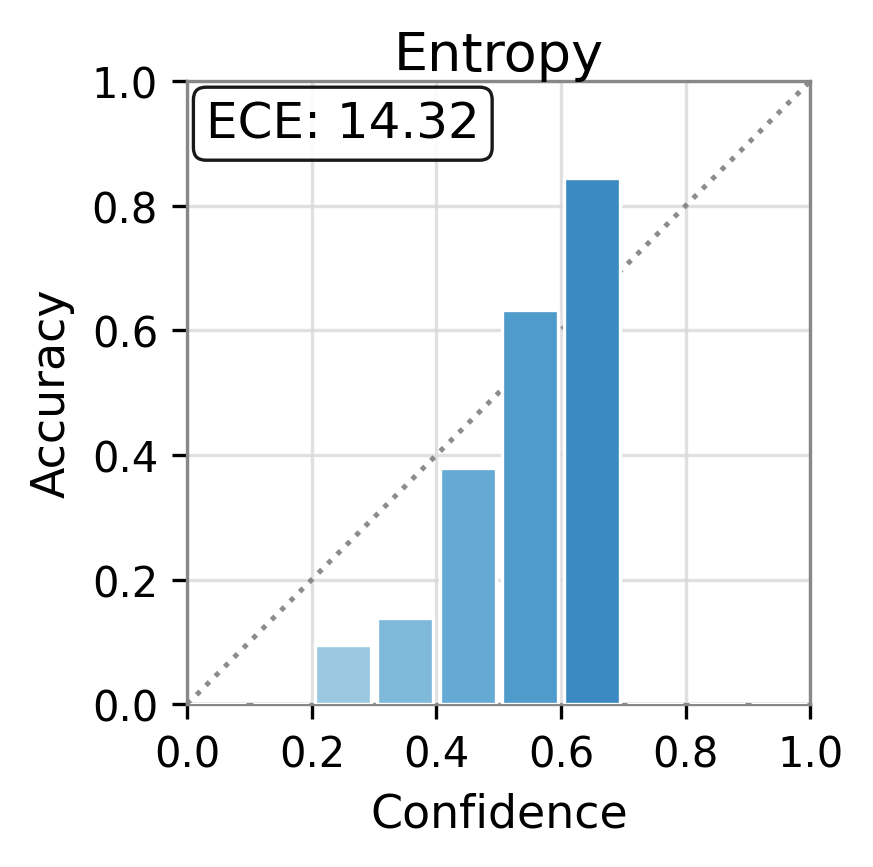
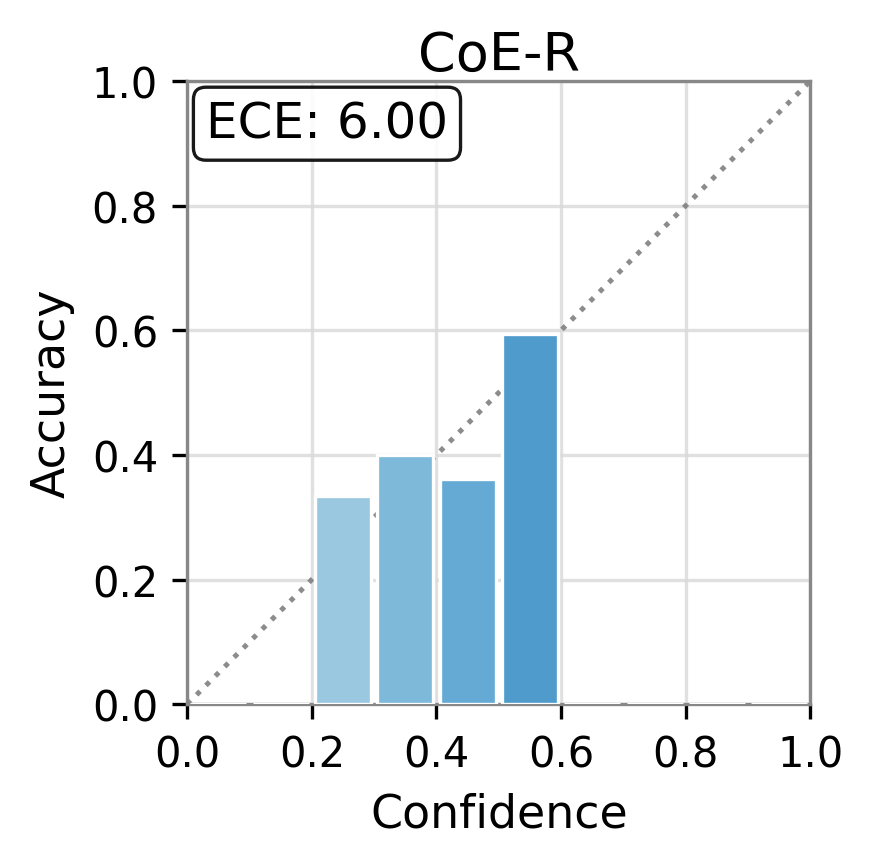
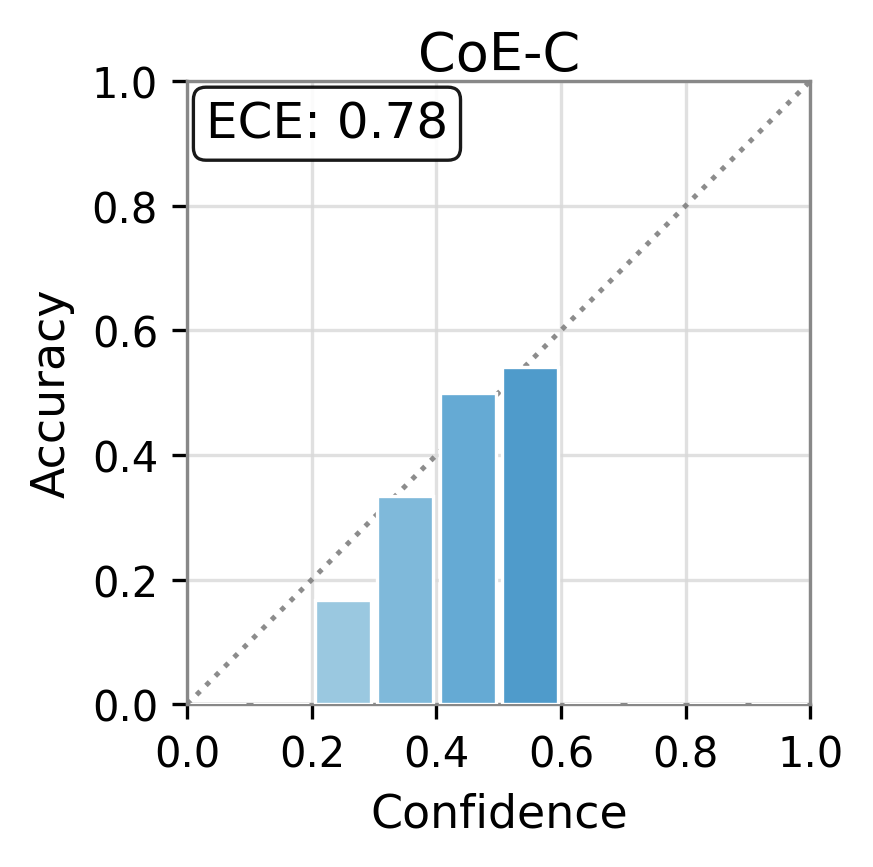
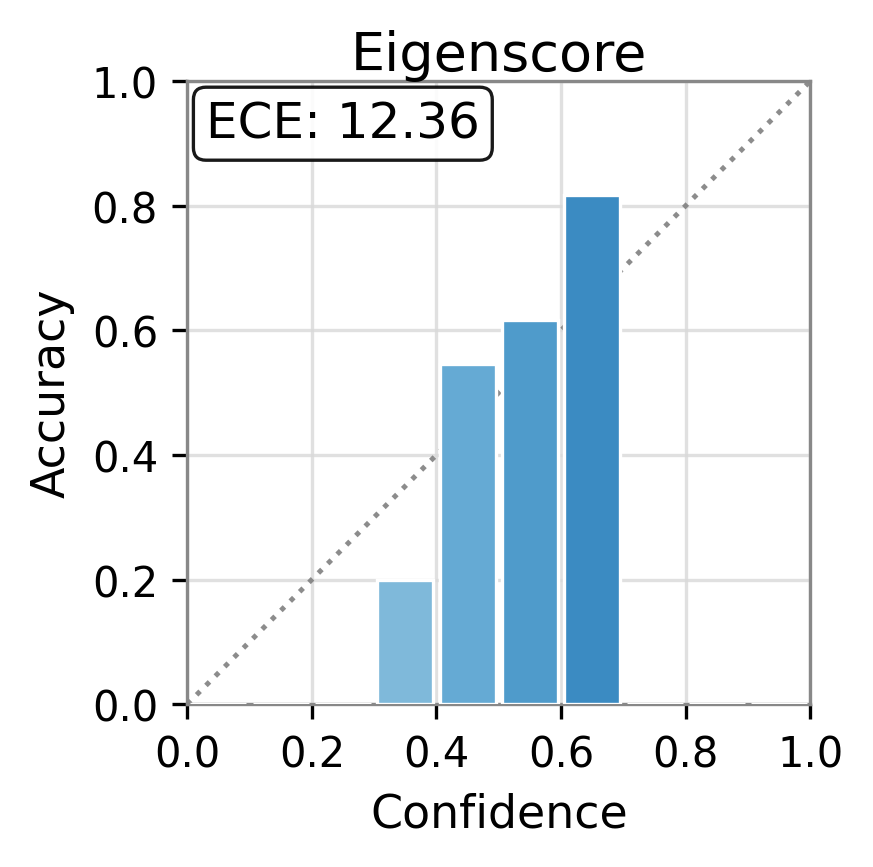
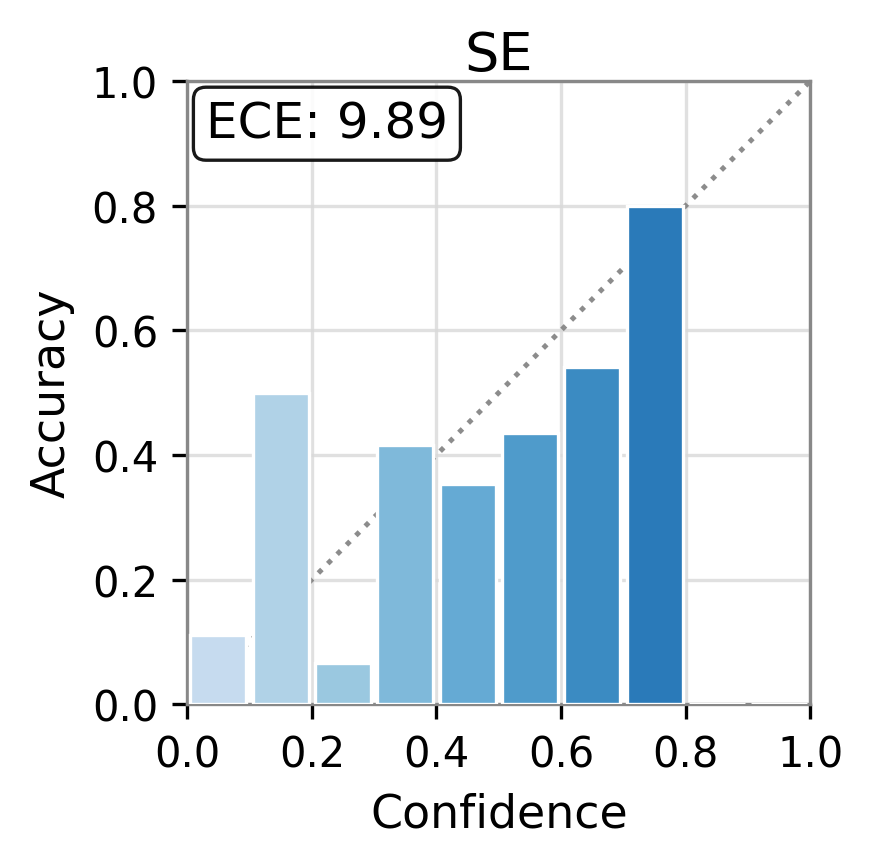
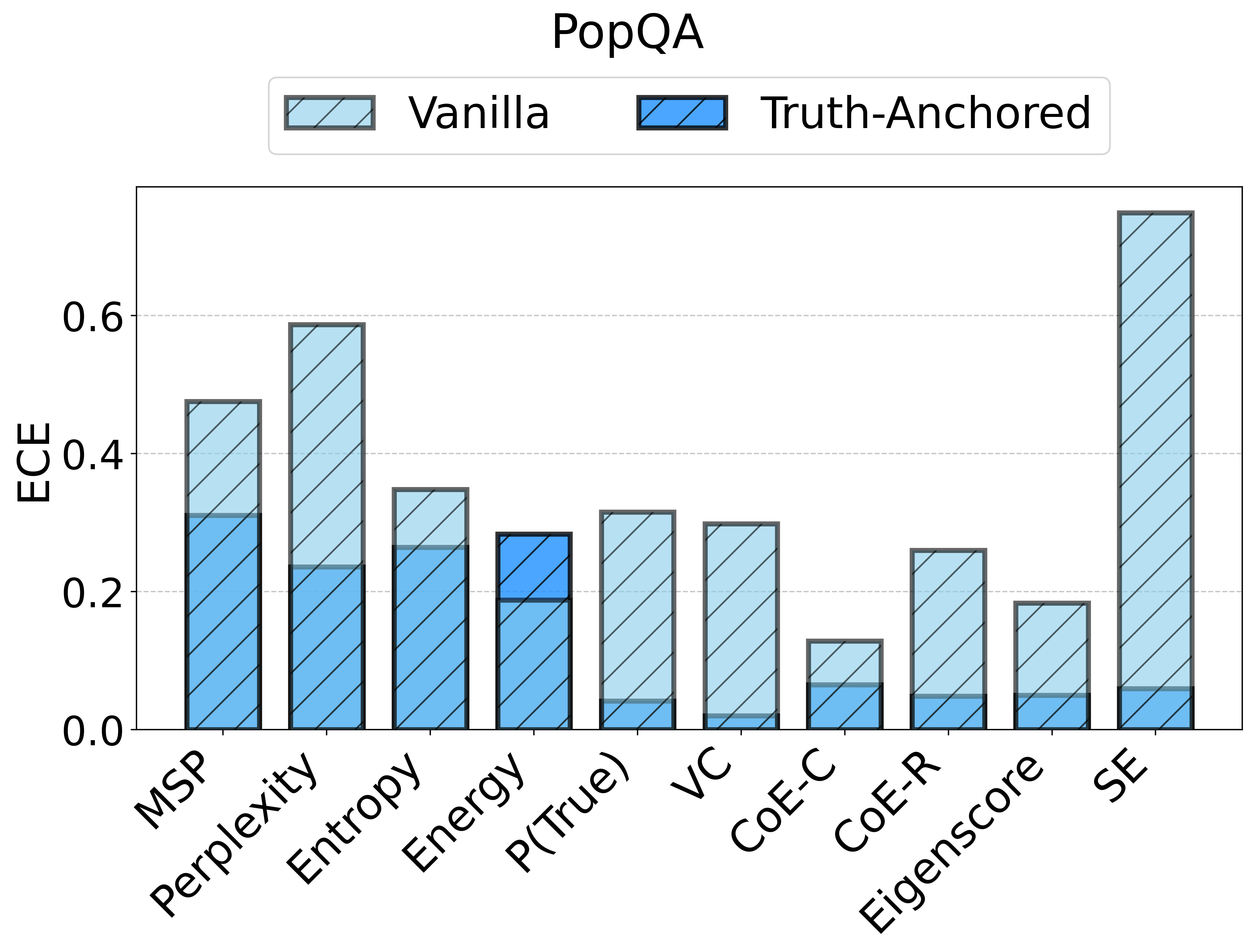
Figure 1: Reliability diagrams show calibration (ECE) of vanilla uncertainty setups and post-hoc calibrated TAC, demonstrating substantial ECE reductions.
Truth Anchoring (TAC): Post-hoc Calibration of Uncertainty
To remedy the decoupling between model-internal uncertainty and the external notion of correctness, the authors introduce Truth Anchoring (TAC). The approach is both minimal and general: a parametric mapping (typically, a lightweight MLP) is trained to convert raw uncertainty scores into calibrated, truth-aligned probabilities. The only supervision required is a small set of noisy or few-shot correctness annotations for model outputs. The training objective combines binary cross-entropy for probabilistic calibration and, optionally, a pairwise ranking loss for improved ordering. Importantly, TAC can be applied post-hoc to already computed uncertainty scores, requiring no modifications to the LLM or the original uncertainty computation protocol.
Experimental Evaluation
Datasets and Experimental Setup
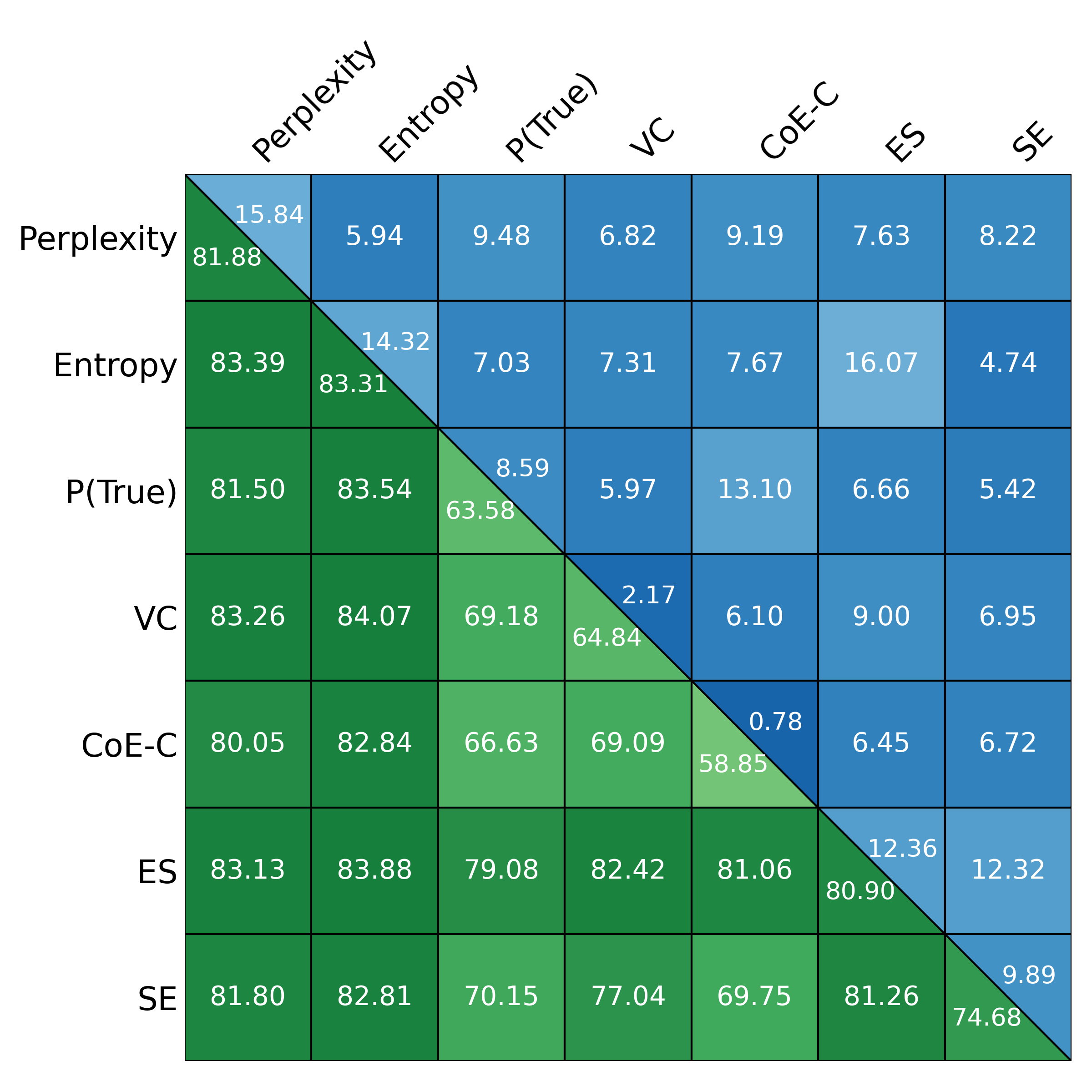
Experiments are conducted on three canonical open-domain QA benchmarks—TriviaQA, SciQ, and PopQA—using five different LLM architectures (Qwen-3-4B, Llama-3.2-3B, Ministral-3-8B, Gemma-2-9B, etc.). Multiple families of uncertainty scores are evaluated: logit-based (entropy, perplexity), elicitation-based, internal-state-based (CoE-C, CoE-R), and consistency-based scores.
Core Results
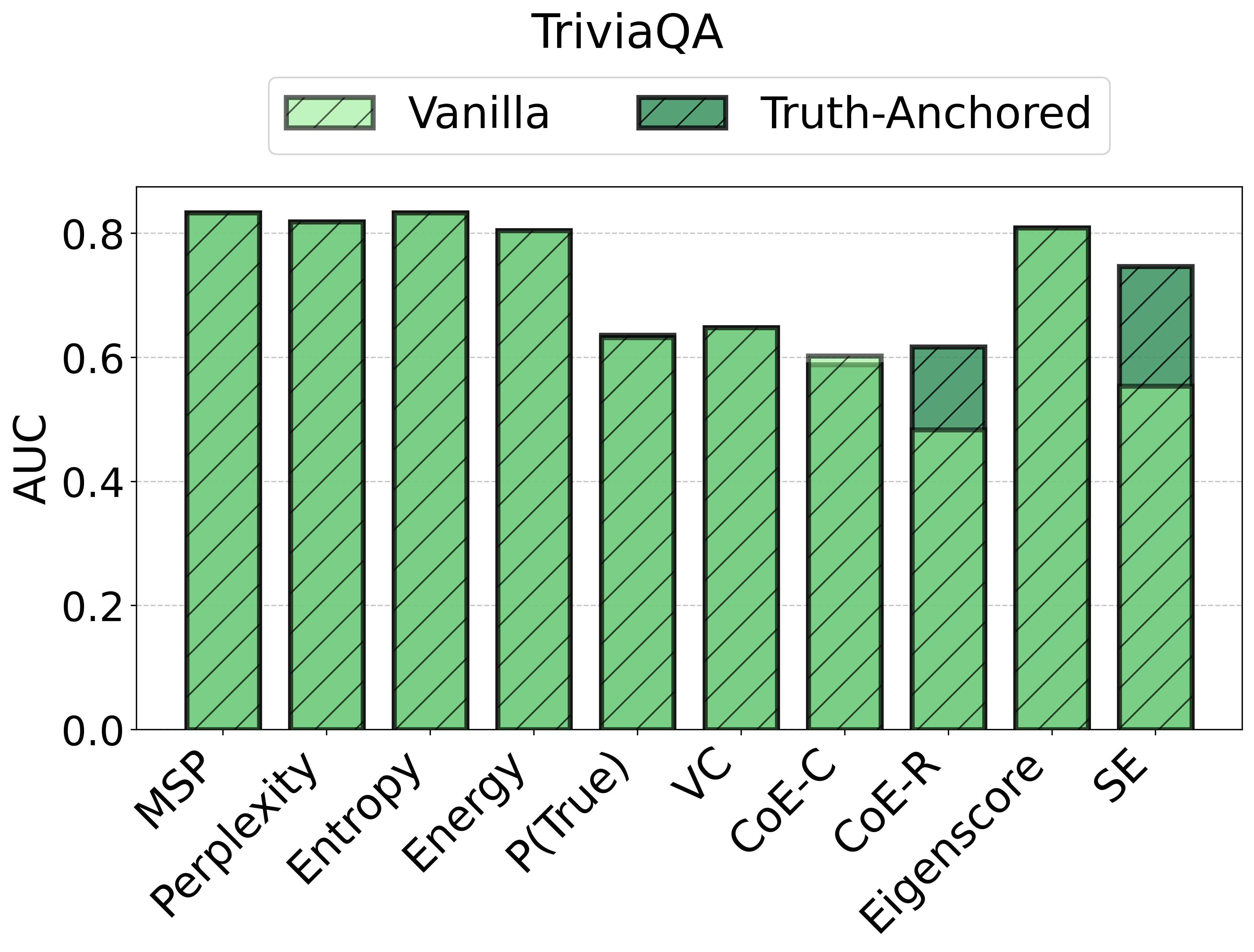
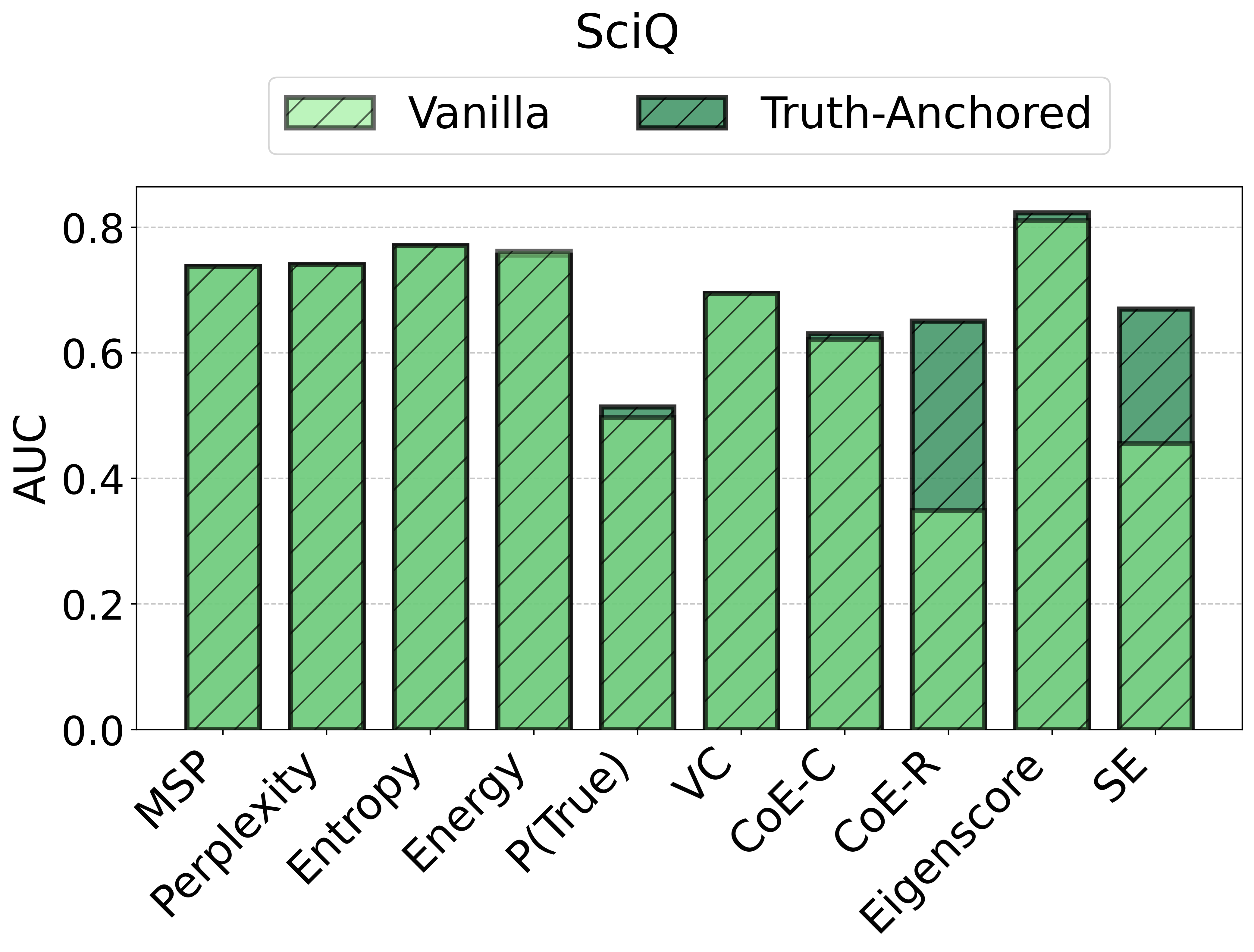
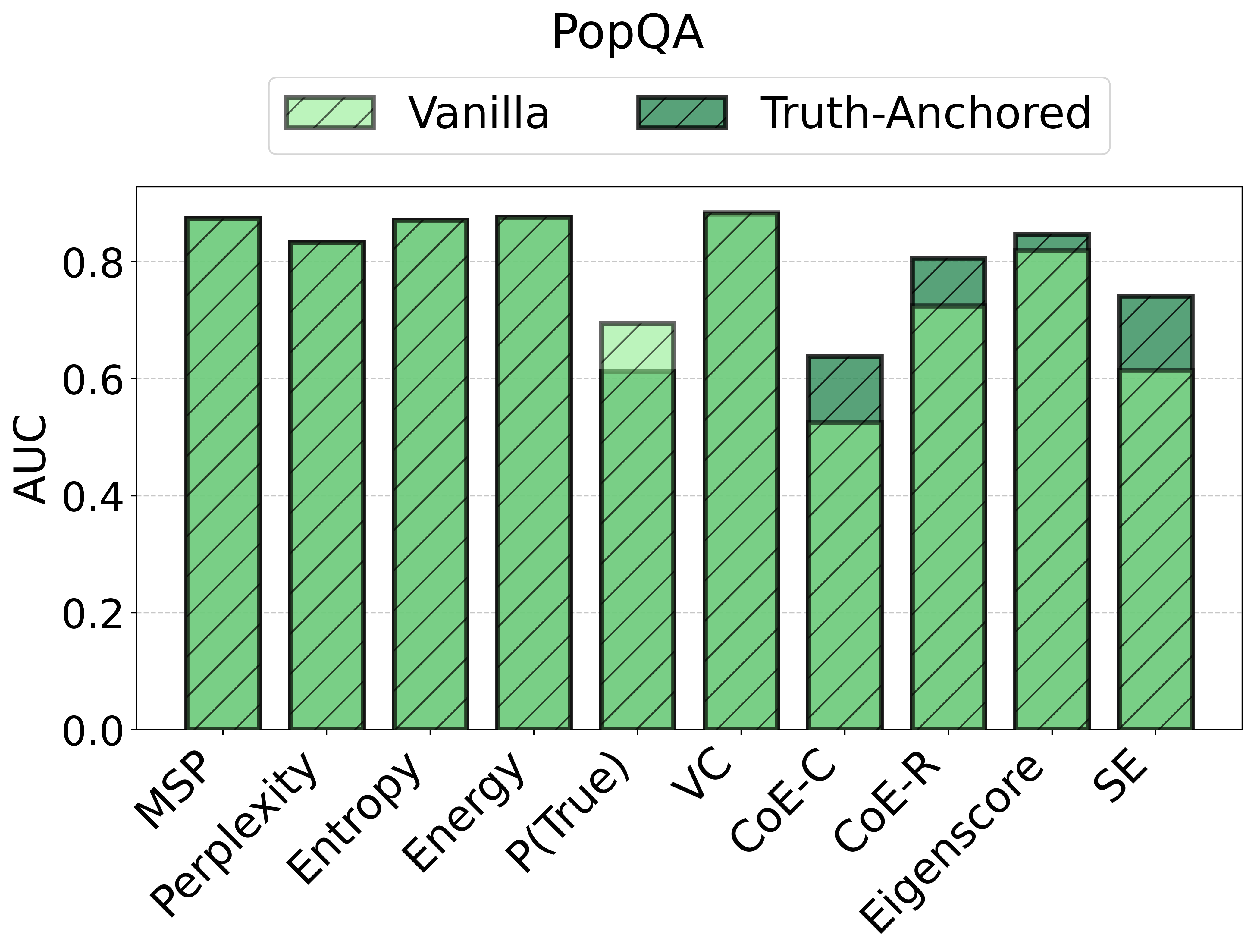
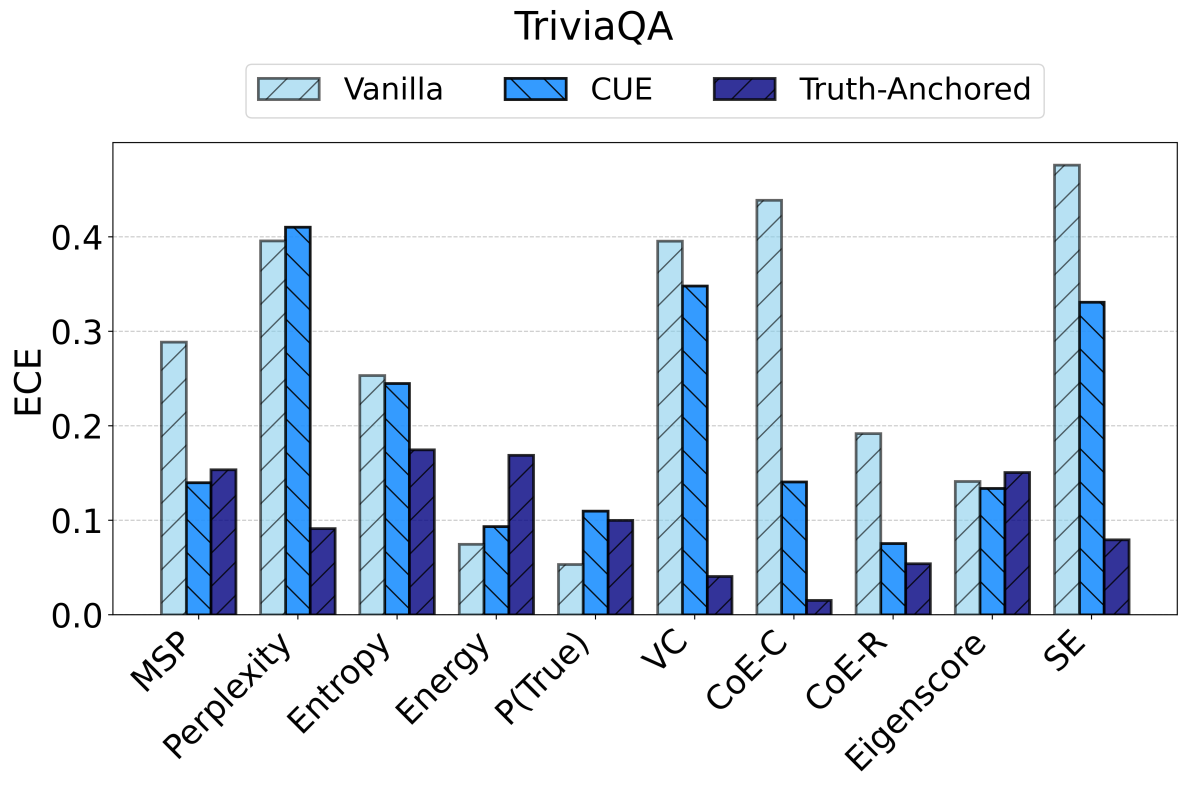
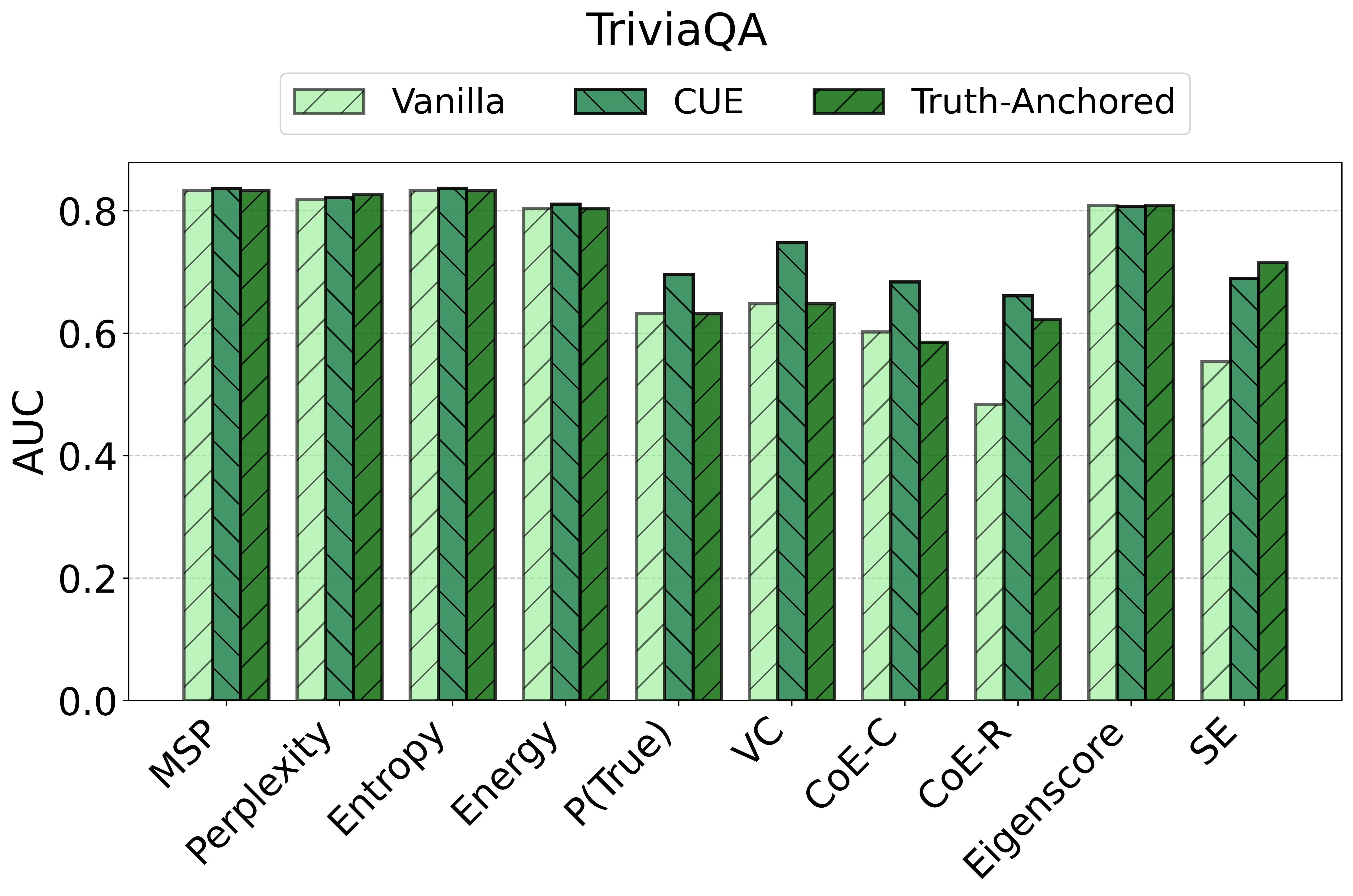
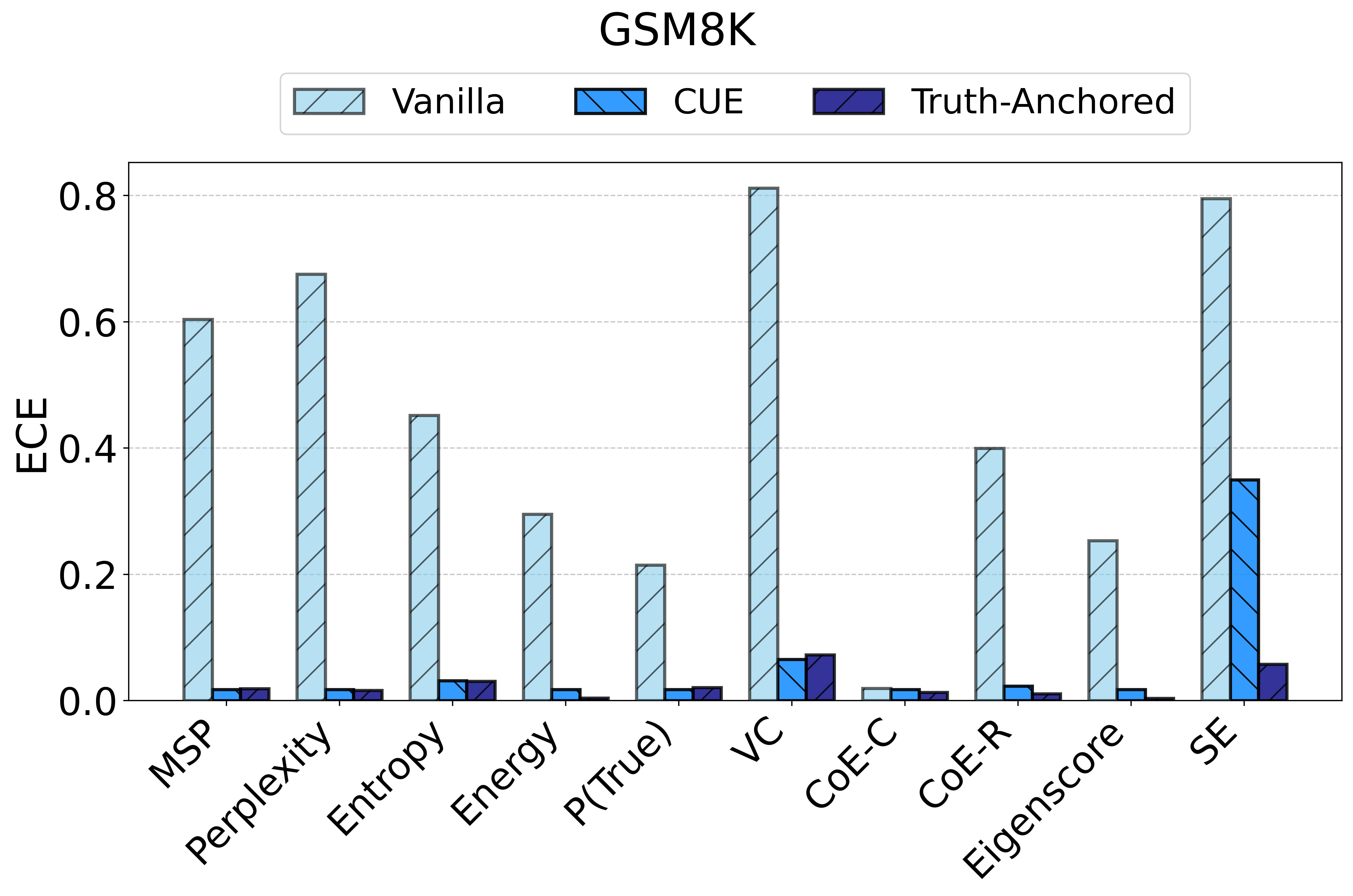
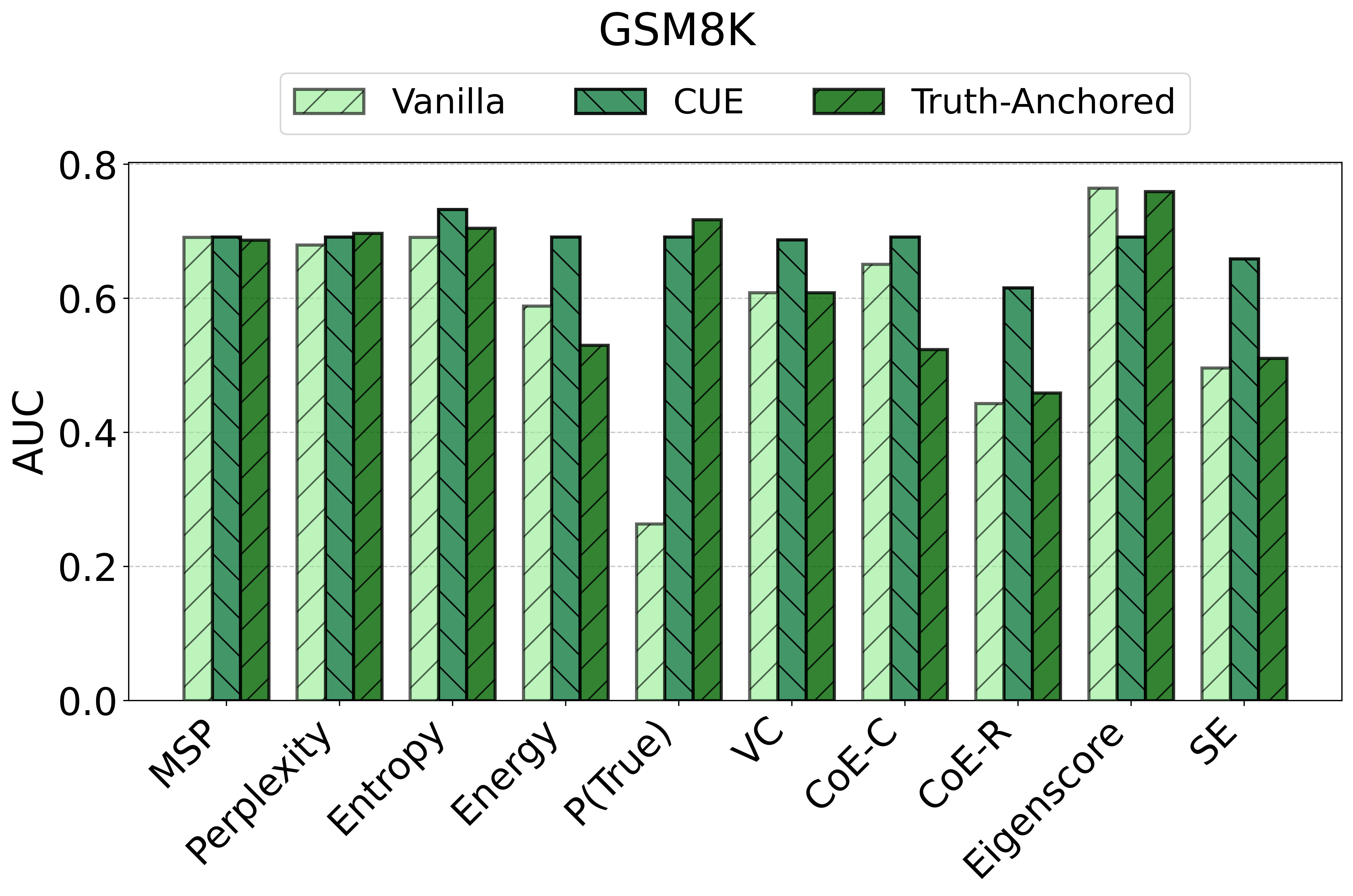
TAC demonstrates consistent and substantial improvements in the calibration of uncertainty estimates as quantified by Expected Calibration Error (ECE). Across all models and datasets, the calibration error is reduced by large margins (e.g., reductions in ECE of up to 75 points for some scores and datasets) and often, but not always, the AUC improves as well. Critically, the magnitude of improvement is sometimes greater than that of competitor frameworks such as CUE, which trains more complex correctors over richer embedding features.
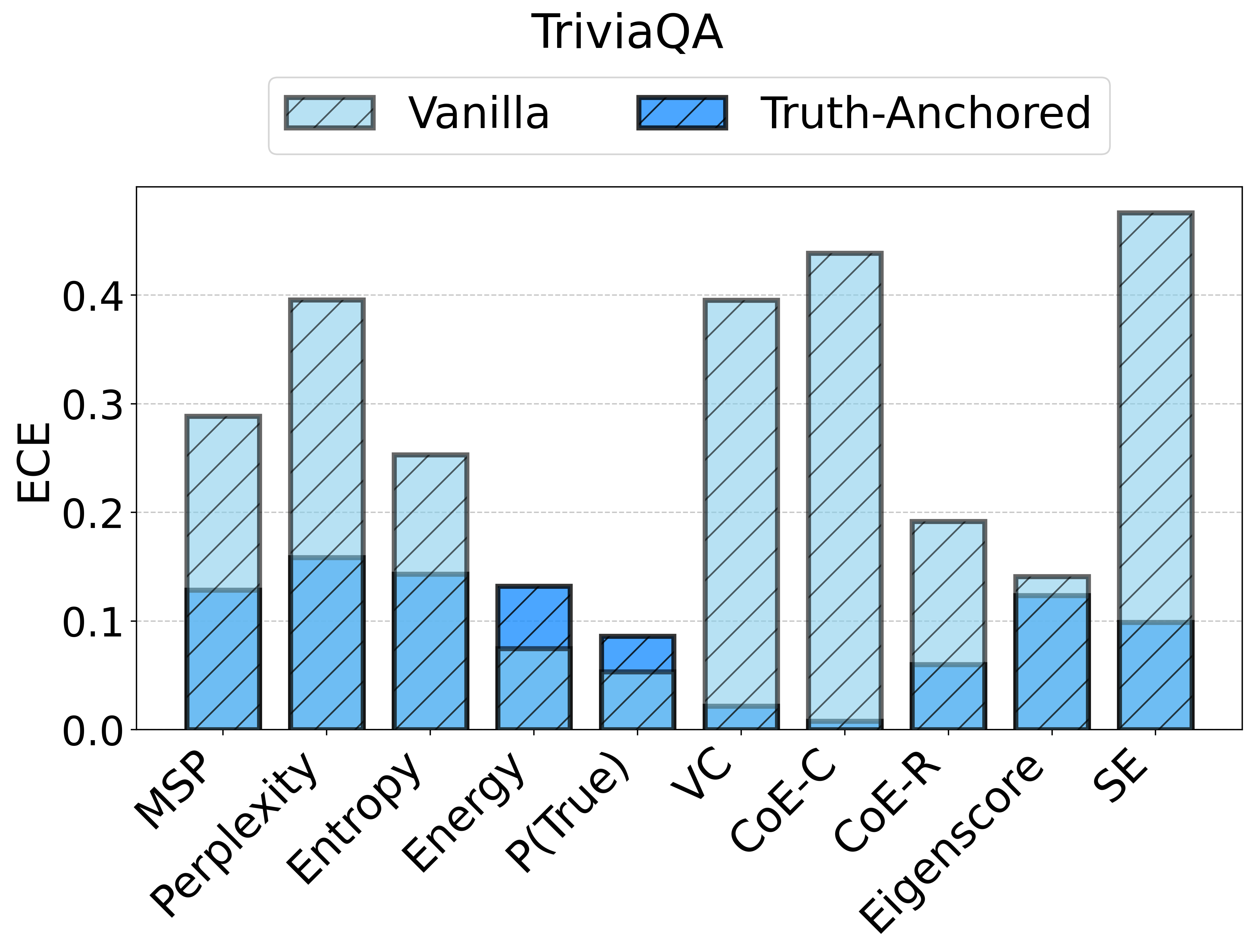
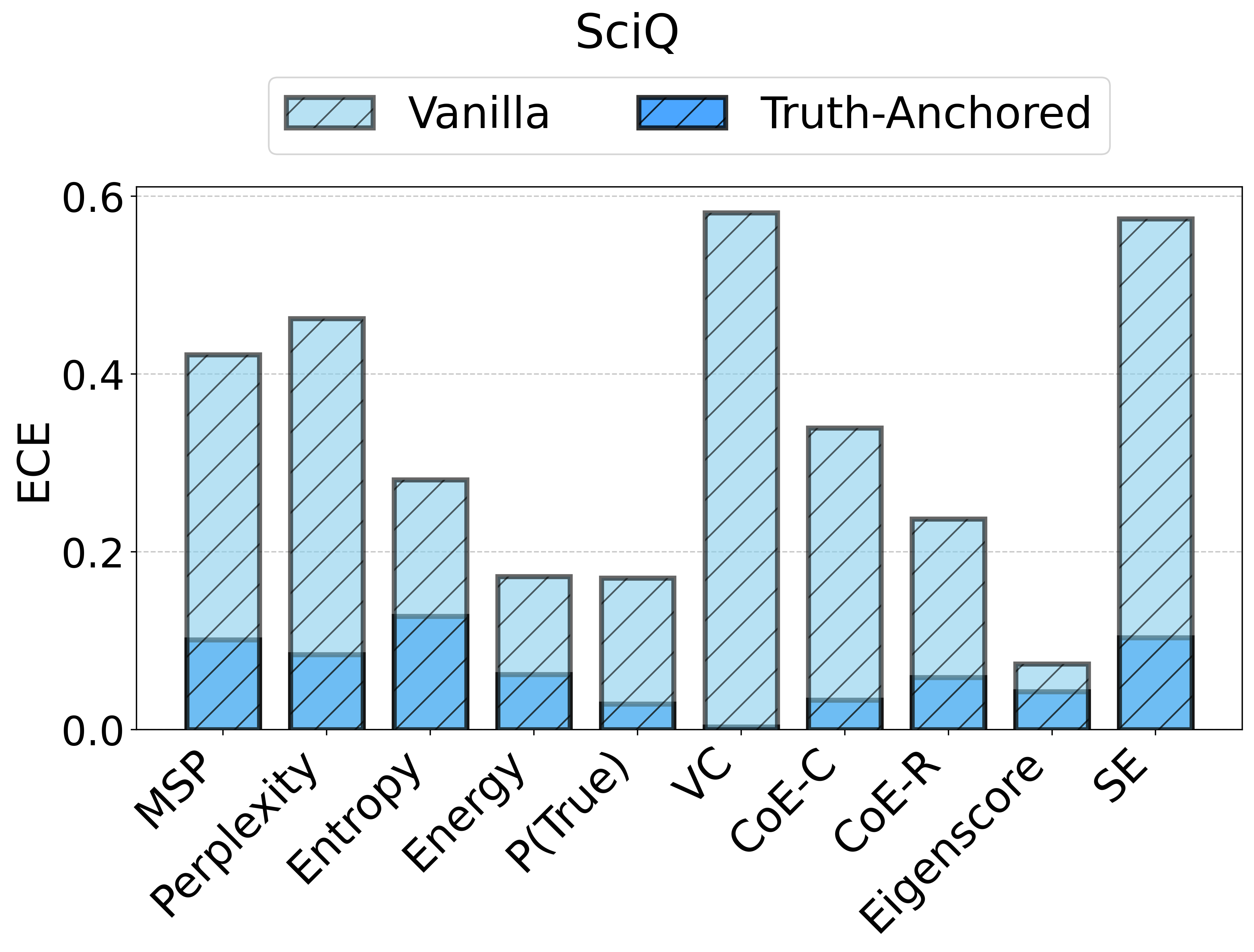
Figure 2: TAC delivers consistent ECE reductions and frequently boosts AUC for multiple uncertainty scores and datasets.
For example, the vanilla entropy score on Ministral-3-8B yields an ECE of 25.31 on TriviaQA; with TAC, this falls to 14.32—with AUC stability maintained or slightly improved. These trends are observed consistently over different UE scores and LLMs.
Notably, the instability of vanilla UE scores is strongly surfaced: the same score that is effective on one dataset/model pairing may degrade or act randomly in another.
Figure 3: Comparison of vanilla uncertainty, CUE, and TAC on TriviaQA, showing superior calibration and (often) ranking for TAC.
Robustness to Few-Shot/Noisy Supervision
TAC is highly robust with respect to the amount and quality of label supervision. Even with as few as 32 labeled examples, or with up to 30% label noise, calibrated scores remain close to the fully supervised version. This positions TAC as a practical post-hoc solution in real-world settings where gold labels are infrequent or imperfect.
The cross-dataset evaluation assesses the transferability of TAC: mappers trained on one dataset (e.g., SciQ) are applied to others (e.g., TriviaQA). While within-set calibration is optimal, cross-set TAC still yields significant ECE reductions over vanilla scores, underlining the generalizability of the truth-anchoring strategy even for partially OOD distributions.
Inter-score Combination
Since single-score TAC can only calibrate, not invent discriminability absent in the original score, the authors also consider joint calibration over concatenated pairs of scores (e.g., combining an internal-state and a consistency score). This often recovers improved AUC, especially with complementary scores—indicating opportunities for future work in score fusion.
Figure 5: Pairwise TAC—calibrating over joint scores—delivers further ECE/AUC improvements, especially when combining orthogonal uncertainty signals.
Theoretical and Practical Implications
The primary theoretical implication is that model-internal UE proxies cannot be presumed to reflect correctness beyond their accidental correlation; post-hoc calibration with explicit anchoring to correctness is essential for principled uncertainty estimation. Practically, TAC's minimality and label efficiency makes it deployable in realistic settings where only restricted supervision is available.
The TAC protocol also clarifies that improvements in calibration do not guarantee improved discriminability when the original uncertainty score is uninformative with respect to truth; future exploration is merited in constructing or fusing scores with independent information.
Limitations and Future Directions
The present study is confined to moderately-sized transformer LLMs and factoid QA datasets; large-scale extensions to LLMs an order of magnitude larger and to tasks involving long-form reasoning, open-world dialog, or subjective generation are necessary to validate the universal applicability of TAC. Moreover, the optimality of inter-score combinations for uncertainty fusion is an open question.
Conclusion
This research formalizes the limitations of prevailing uncertainty estimation metrics for LLMs, articulating and characterizing the "proxy failure" phenomenon. The proposed Truth Anchoring protocol supplies a practical, theoretically-motivated, and empirically validated remedy, enabling reliable uncertainty estimation via post-hoc calibration even in low-supervision or noisy-label settings. These results advocate for the injection of explicit correctness supervision as a necessary step toward robust and reliable deployment of LLMs in high-stakes domains.