- The paper proposes SHARPEN, which integrates interpretable SHAP-based fault localization with CMA-ES for targeted neural repair.
- It demonstrates significant reductions in backdoor and adversarial vulnerabilities while minimally impacting model accuracy.
- The approach offers a modular, fast, and architecture-agnostic repair solution for enhancing deep network reliability.
Shapley-Guided Neural Repair via Derivative-Free Optimization: Framework and Insights
Problem Motivation and Scope
Ensuring the reliability of Deep Neural Networks (DNNs) in safety-critical applications demands robust mitigation of defects such as backdoors, adversarial vulnerabilities, and unfairness. Conventional neural repair approaches bifurcate into search-based heuristics and constraint-solving methods. Search-based methods—typically reliant on gradients—struggle with model heterogeneity and interpretability, while constraint-based techniques, despite theoretical guarantees, exhibit poor scalability and are often tied to specific activation functions or model structures. SHARPEN addresses these core challenges by integrating a principled, interpretable fault localization strategy with a derivative-free repair mechanism, targeting a modular and generalizable repair solution applicable across architectures and defect types.
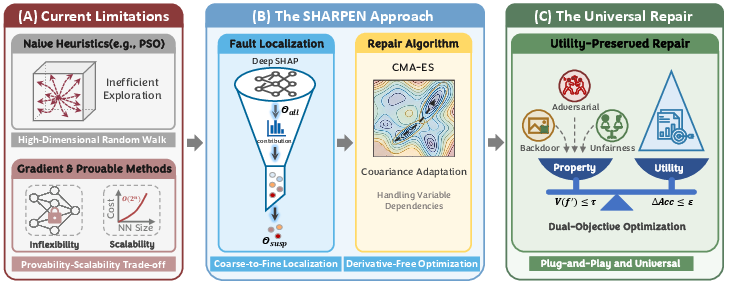
Figure 1: SHARPEN shifts from unscalable or unprincipled search to interpretability-guided, locally-constrained optimization for utility-preserved neural repair.
SHARPEN Framework Overview
SHARPEN’s workflow consists of a two-stage pipeline: interpretable fault localization and targeted, derivative-free optimization.
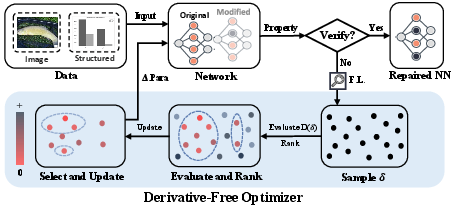
Figure 2: End-to-end SHARPEN workflow, moving from property checking through fault localization to repair.
If a model violates a target property—such as excessive backdoor success rate (BSR), adversarial success rate (ASR), or unfairness (UF)—SHARPEN first localizes critical faulty neurons or filters linked to misbehavior via a hierarchical SHAP (Shapley-value) analysis. Leveraging Deep SHAP, SHARPEN efficiently quantifies marginal attribution from activations, starting at the layer-level and refining down to individual neurons, contrasting 'violating' and 'benign' inputs to pinpoint parameters with maximal attribution discrepancies.
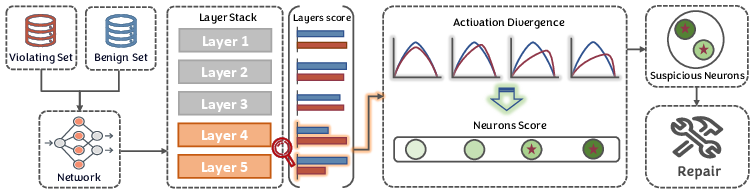
Figure 3: Deep SHAP-based coarse-to-fine neuron and layer fault localization strategy.
Once targets are isolated, SHARPEN applies Covariance Matrix Adaptation Evolution Strategy (CMA-ES), a black-box evolutionary algorithm, for parameter perturbation. The optimization operates over a highly pruned parameter subspace, maximizing repair efficacy while minimally impacting clean performance.
SHAP-Guided Coarse-to-Fine Fault Localization
The localization step adopts a two-stage process:
- Layer-level attribution: For each candidate layer, SHAP attributions are computed for both clean and defective models using the same inputs, yielding a contribution score measuring mean absolute attribution discrepancy. Layers with the highest such scores are considered responsible for property violations.
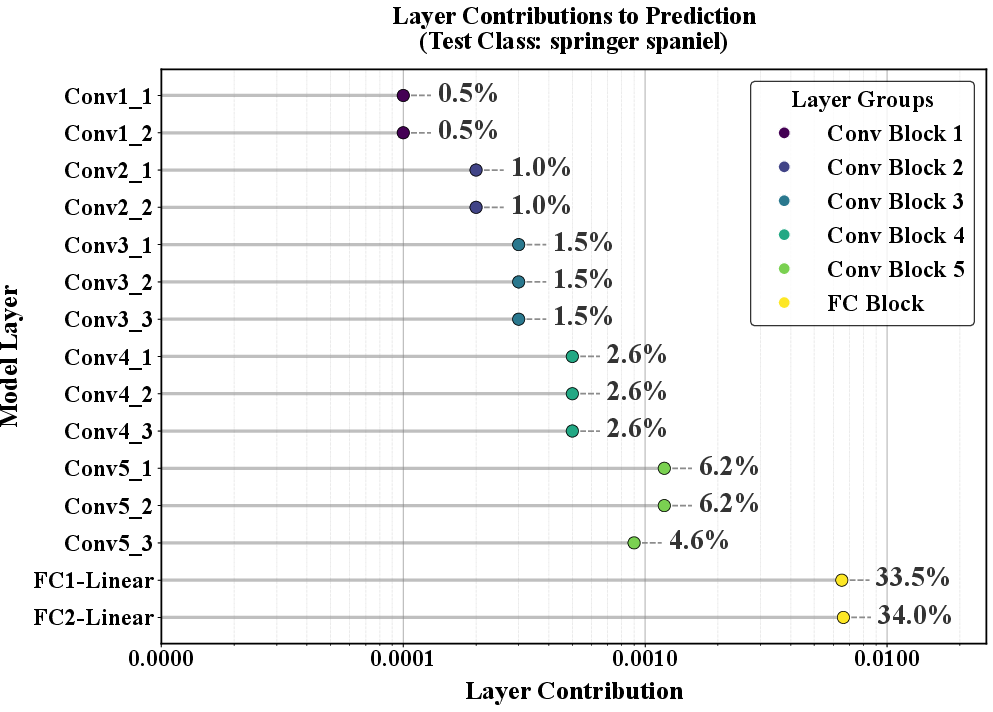
Figure 4: Layer-level SHAP attribution differentials identify candidate layers (e.g., FC and final Conv) as responsible for backdoor effects.
- Neuron-level refinement: Within suspicious layers, neuron-specific SHAP-value differences are calculated. Neurons with top absolute divergences are mapped back to their corresponding weights (for FC/linear layers) or convolutional kernels (for Conv layers).
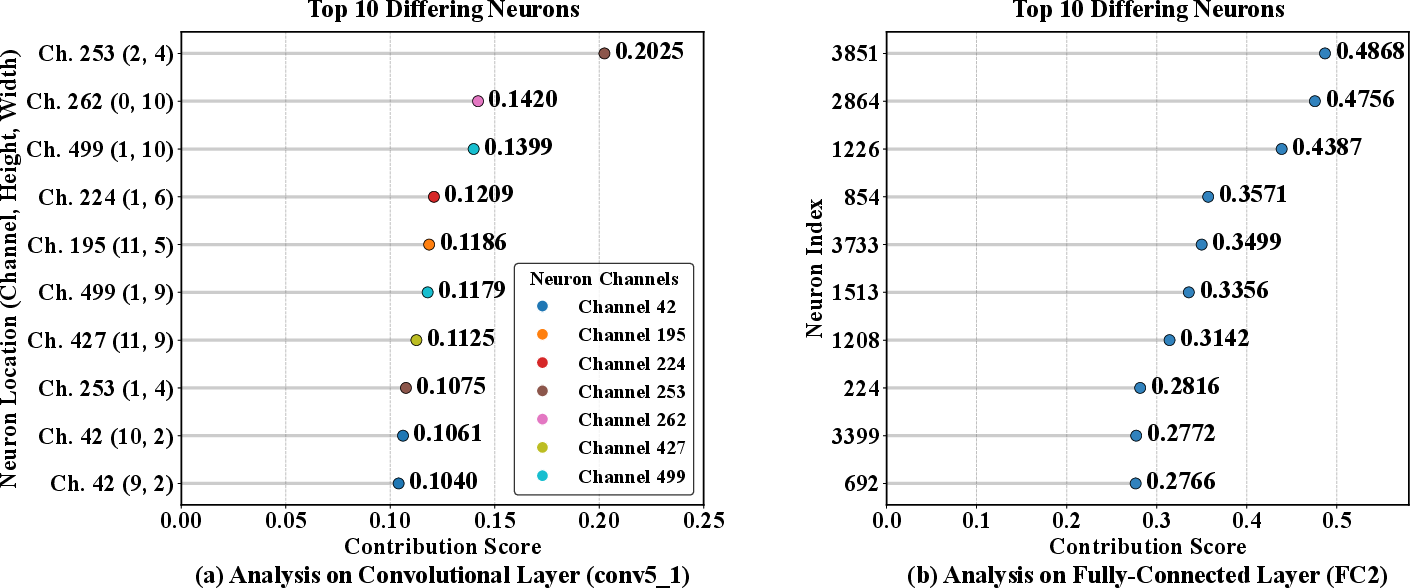
Figure 5: Neuron-level attribution discrepancy highlights critical activations in conv5_1 and FC2 for BadNets removal.
This workflow drastically shrinks the search space, focusing subsequent optimization only on parameters demonstrating clear, SHAP-guided causal evidence of faulty behavior. Visualizations at the channel level further elucidate spatial attribution shifts underlying the defects.
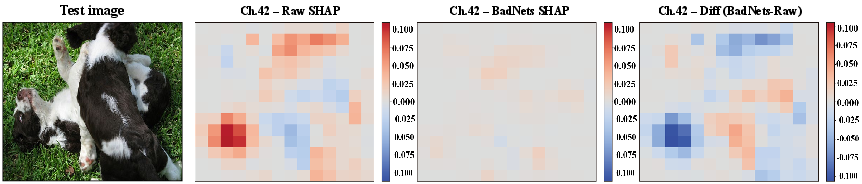
Figure 6: Channel-level SHAP heatmaps illustrate spatial attribution shifts between clean and defective models.
Neural Repair via Derivative-Free Optimization
Following fault localization, SHARPEN executes parameter adjustment exclusively on the detected problematic neurons. The optimization leverages CMA-ES to minimize a multi-component objective:
- Property loss: Quantifies violation (e.g., BSR, ASR, or UF).
- Clean accuracy loss: Penalizes accuracy degradation on benign data.
- Activation distance loss: Encourages post-repair activations to remain close to the benign reference.
- Regularization: Encourages minimal parameter movement.
The objective weights are configurable for task-specific trade-offs. Empirical sensitivity analyses confirm that moderate K (number of neurons) and accuracy-focused weightings yield optimal outcomes without affecting computational costs.
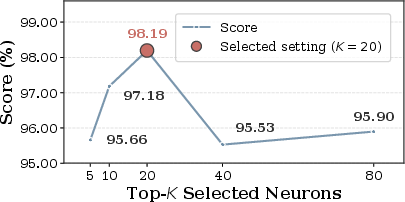
Figure 7: Increasing the number of repaired neurons (top-K) improves repair initially but exhibits diminishing returns beyond moderate K.
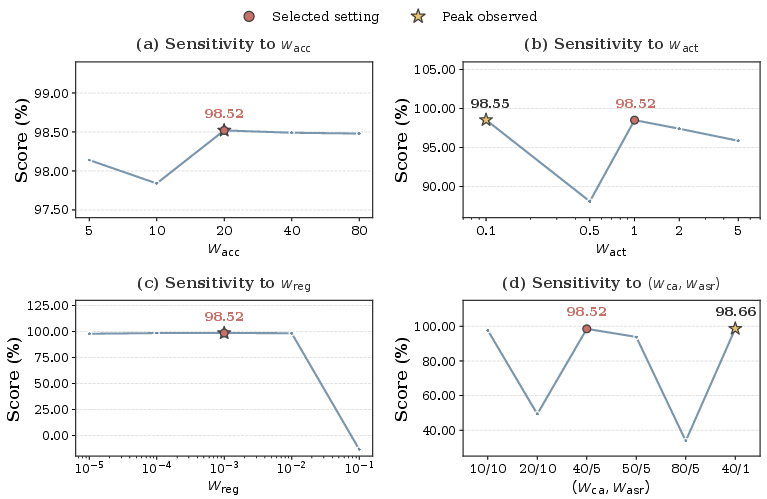
Figure 8: Robustness of SHARPEN to different objective function weightings demonstrated via OFAT sensitivity analysis.
Empirical Evaluation and Comparative Analysis
Evaluation across backdoor removal, adversarial robustness, and fairness repair on architectures including VGG13/16 and ResNet18 (for vision), and Multi-Layer Perceptrons (for tabular data), demonstrates SHARPEN’s substantial advantage:
- Backdoor removal: SHARPEN outperforms SOTA methods such as INNER and APRNN, achieving up to 10.56% higher repair-utility trade-off. For instance, on VGG13-BadNets, BSR drops by 99.12% with only a 0.6% accuracy decrement.
- Adversarial repair: Achieves up to 5.78% superior trade-off versus CARE, reducing ASR by up to 99.8% for negligible cost.
- Fairness repair: Excels over IDNN and ADF, with up to an 11.82% average Score improvement, achieving 78.05% unfairness reduction.
Critically, SHARPEN completes both localization and repair with lower computational cost—often an order of magnitude faster than search-based baselines—exploiting the reduced search space and gradient-independence.
Implications, Limitations, and Future Directions
Practically, SHARPEN's modular, plug-and-play design facilitates integration with various derivative-free optimizers (e.g., CMA-ES, RACOS), increasing its extensibility. Theoretically, SHAP-guided fault localization augments interpretability and sharpens the causal link between network internals and observed defects, bridging black-box heuristics and formal model auditability.
A limitation is the scalability of SHAP/Deep SHAP analysis for extremely large models, which may incur prohibitive overhead absent further algorithmic advances in attribution computation. Extending SHARPEN to transformer-based architectures, foundation models, and LLMs will require scalable, possibly sampling-based, explainability techniques. Furthermore, broadening property repair beyond BSR, ASR, and UF—toward complex behavioral and structural constraints—remains an open research avenue.
Conclusion
SHARPEN exemplifies effective synthesis of interpretability and black-box optimization for defect repair in neural networks. Its empirical superiority over established baselines, computational efficiency, and fault localization generality underline its utility for safe deployment of DNNs in sensitive domains. The approach sets a technical foundation for robust, interpretable, and architecture-agnostic neural repair, with immediate relevance as DNNs become more deeply integrated into socially consequential systems.