- The paper introduces novel structured shuffling methods, block reshuffling and paired reversal, to reduce gradient variance and cancel order-dependent drift in SGD.
- It leverages an LLM-guided evolution pipeline to derive the Adaptive Block Reshuffling algorithm, yielding improved optimization constants and enhanced convergence stability.
- Empirical results across diverse tasks show that structured shuffling consistently lowers training loss and improves performance compared to traditional permutation methods.
Structured Shuffling Schemes for Without-Replacement SGD: Block Reshuffling and Paired Reversal
Introduction and Motivation
The paper "Learning to Shuffle: Block Reshuffling and Reversal Schemes for Stochastic Optimization" (2604.00260) investigates the theoretical and empirical advantages of structured data-ordering strategies in stochastic optimization. Typical implementations of SGD in modern ML workflows employ without-replacement sampling—processing dataset elements through permutations of the data at the start of each epoch. While classical shuffling schemes (incremental gradient, shuffle-once, and random reshuffling) are well-characterized, they treat permutations as unstructured, and research has lacked constructive guidance for designing superior data-ordering approaches.
This work leverages an LLM-guided program evolution pipeline (OpenEvolve) to discover new shuffling rules. From that discovery, two structural components—block reshuffling and paired reversal—are abstracted, formally analyzed, and shown to deliver provable improvements in optimization constants and stability, as validated by empirical results.
Block Reshuffling: Variance Reduction Through Structured Aggregation
Block reshuffling partitions dataset indices into contiguous blocks and randomly permutes the blocks, maintaining within-block order. This process interpolates between random reshuffling (b=1) and incremental gradient (b=n), yielding a spectrum of structures. Statistically, block-averaged gradients possess reduced variance compared to individual gradients, formalized as:
σind2(w)=σwithin2(w)+σblk2(w)
Lemma 1 establishes that whenever within-block gradients are not identical, block-level variance σblk2(w) is strictly smaller, reducing the prefix-gradient variance constants underlying convergence analyses.
This variance reduction strictly improves optimization constants in unified shuffling theory, especially when local gradient coherence is present.
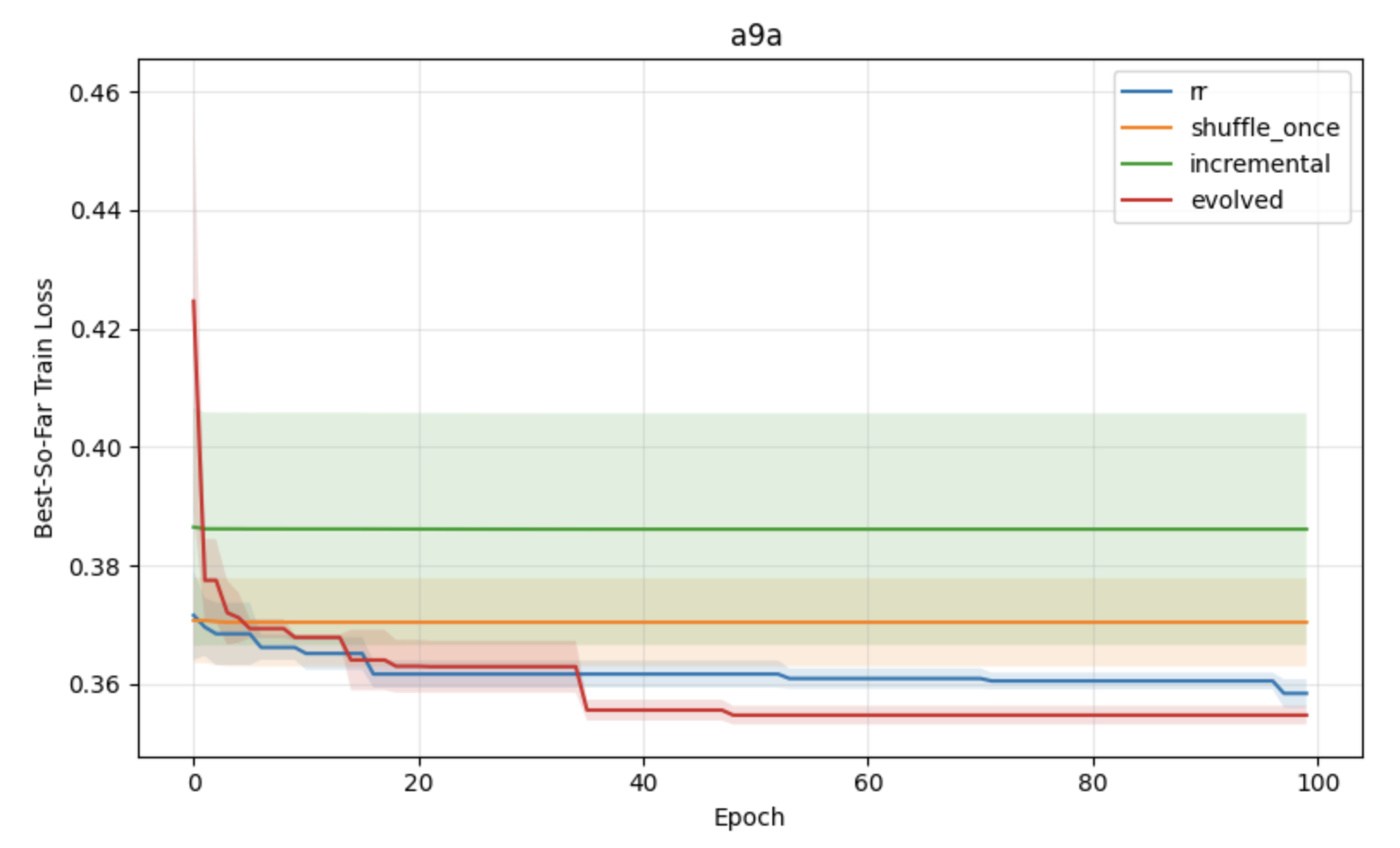
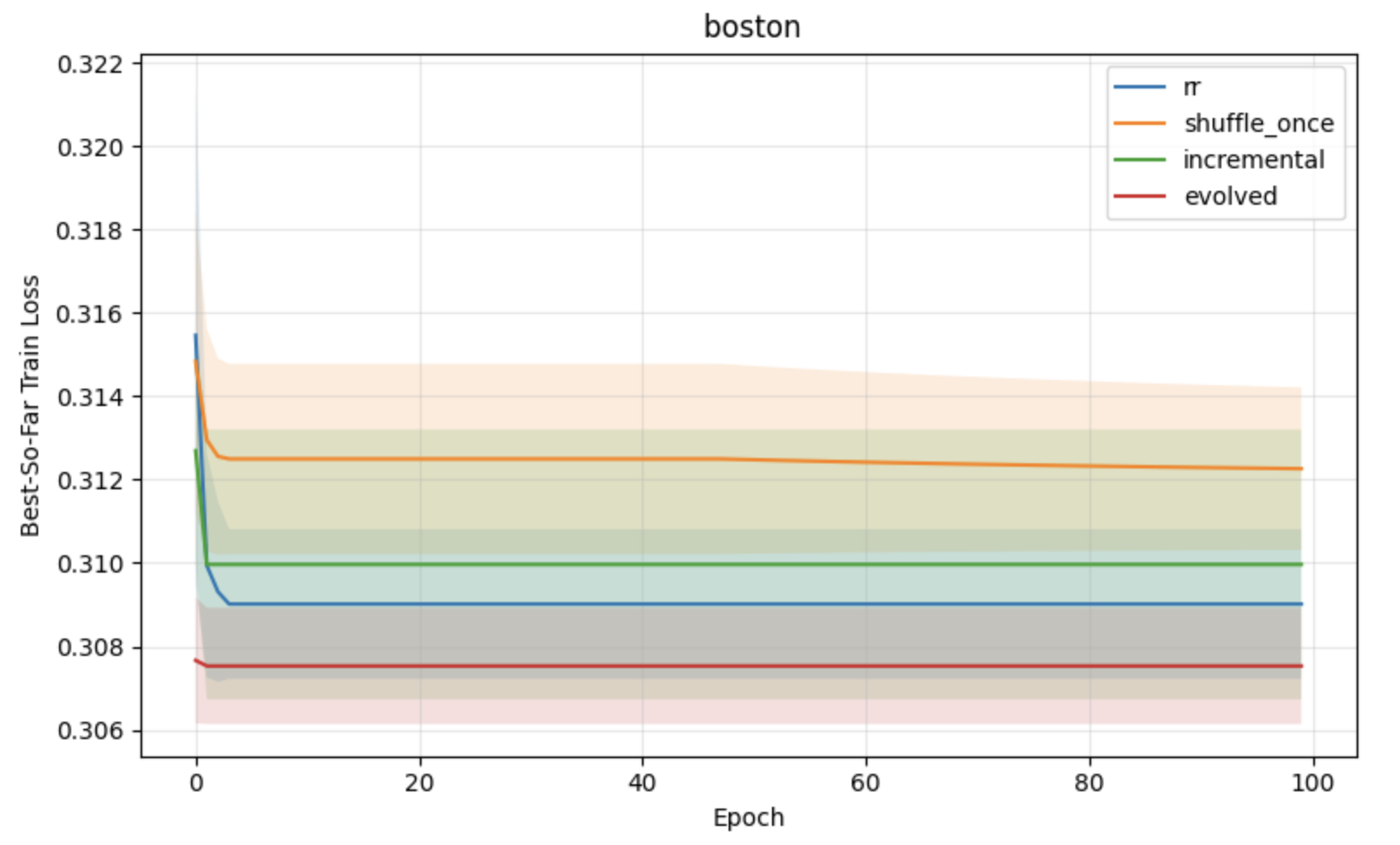
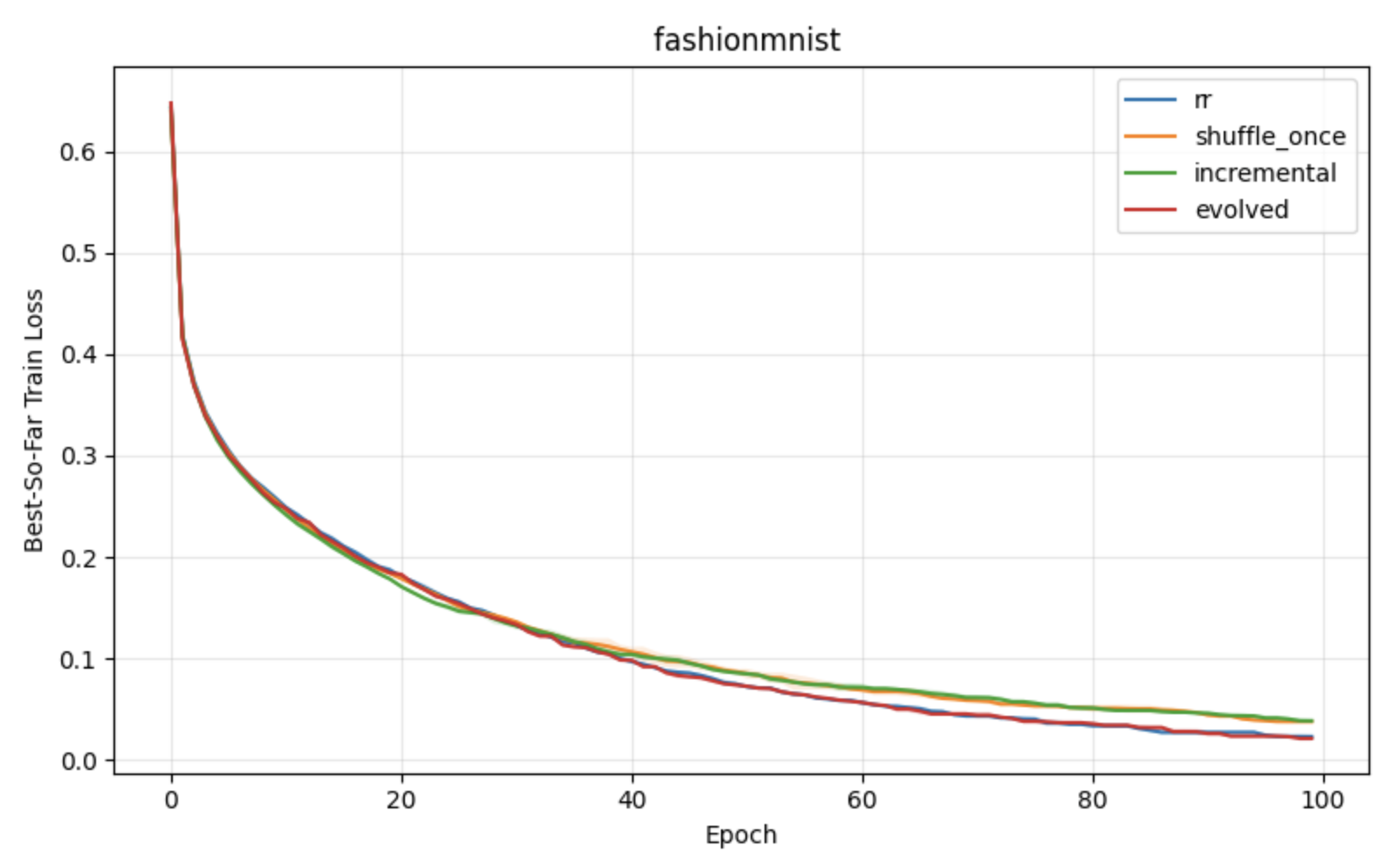
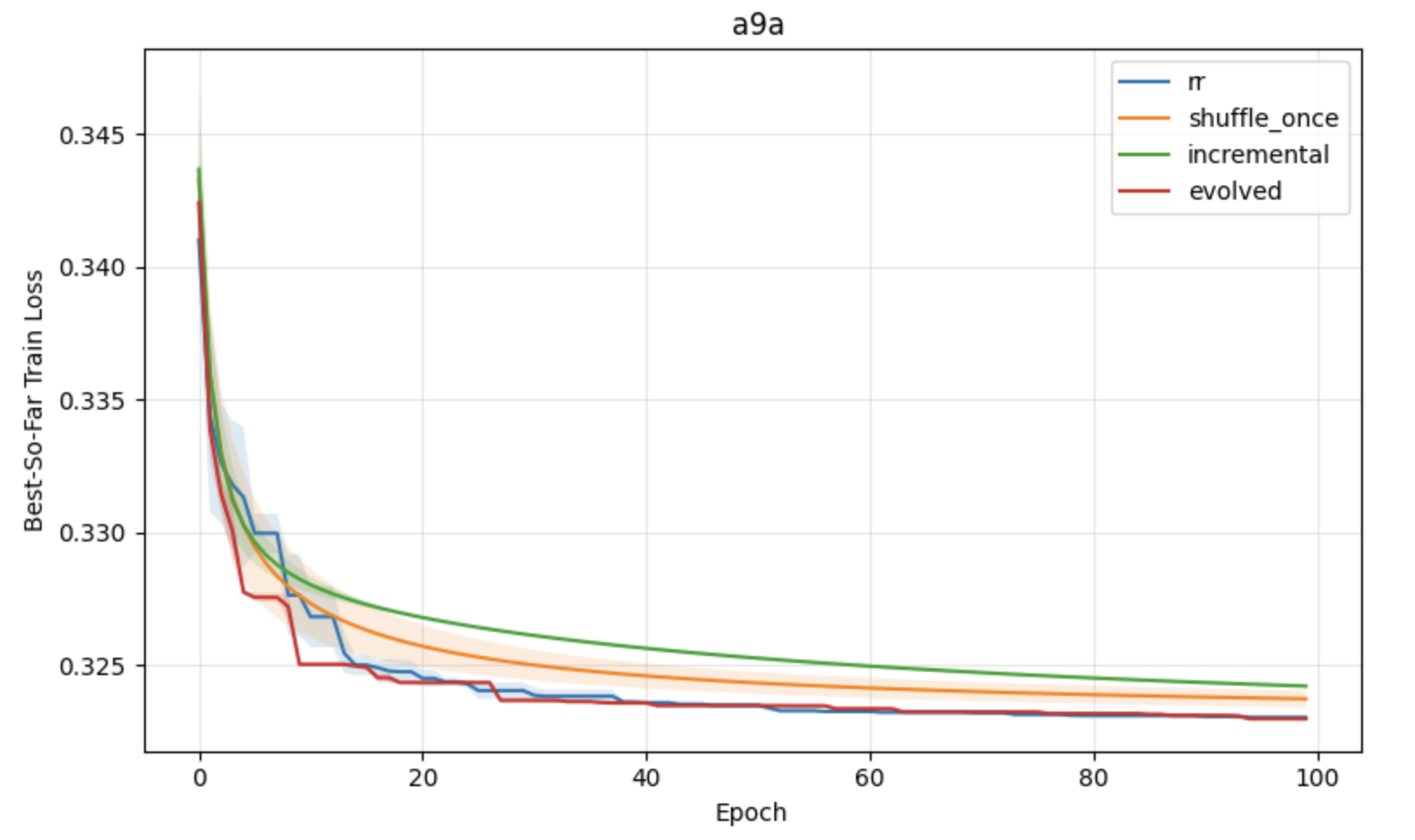
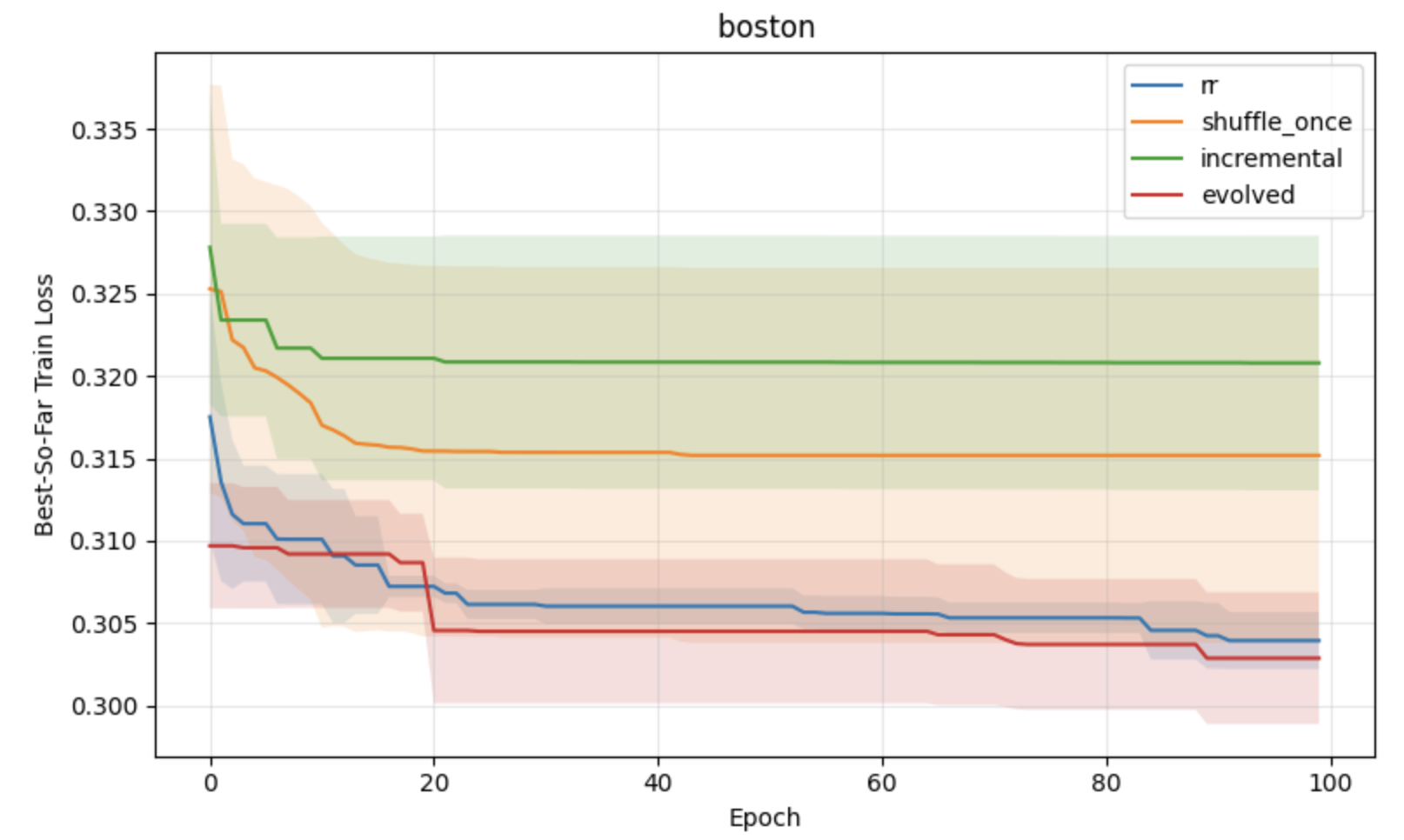
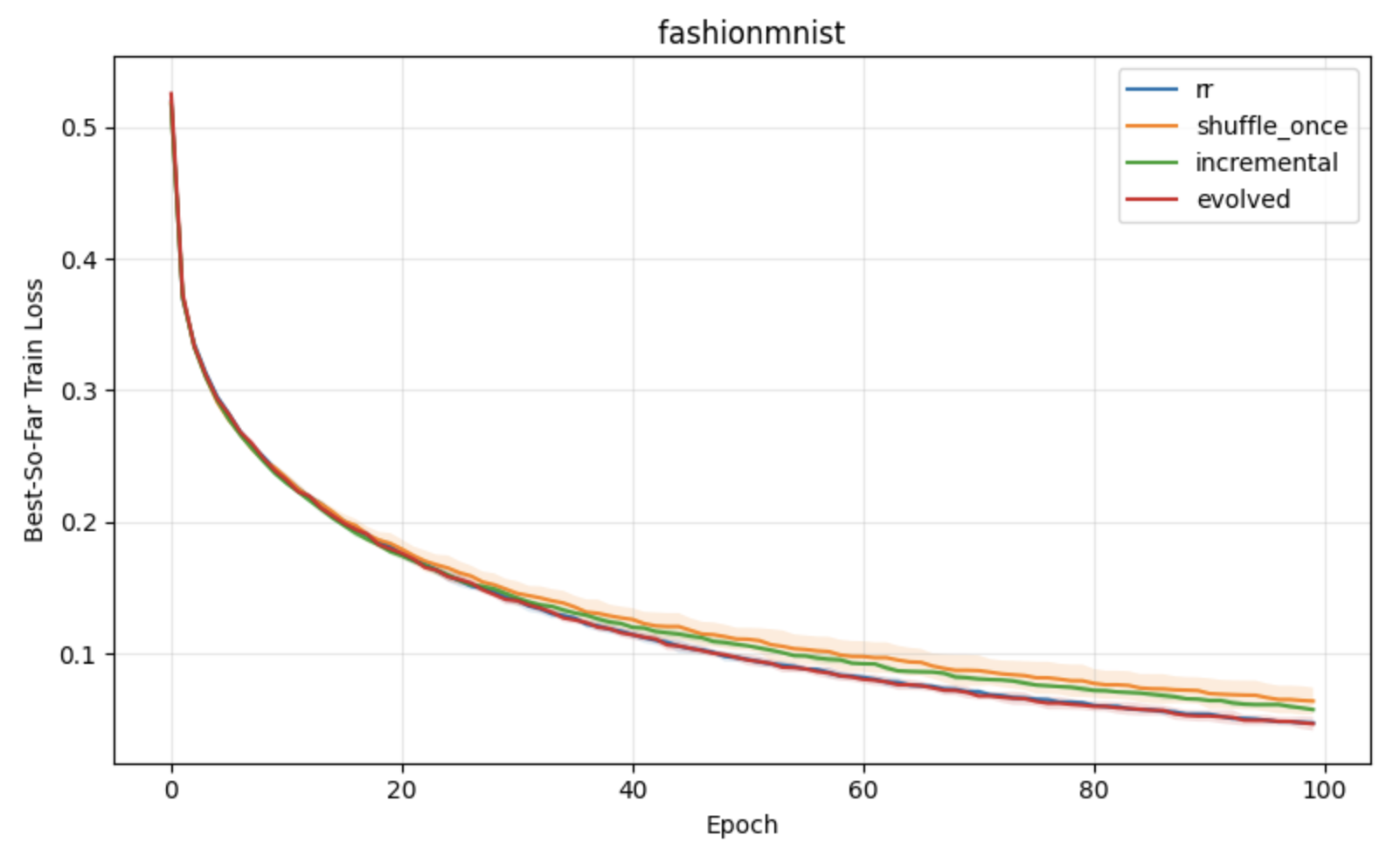
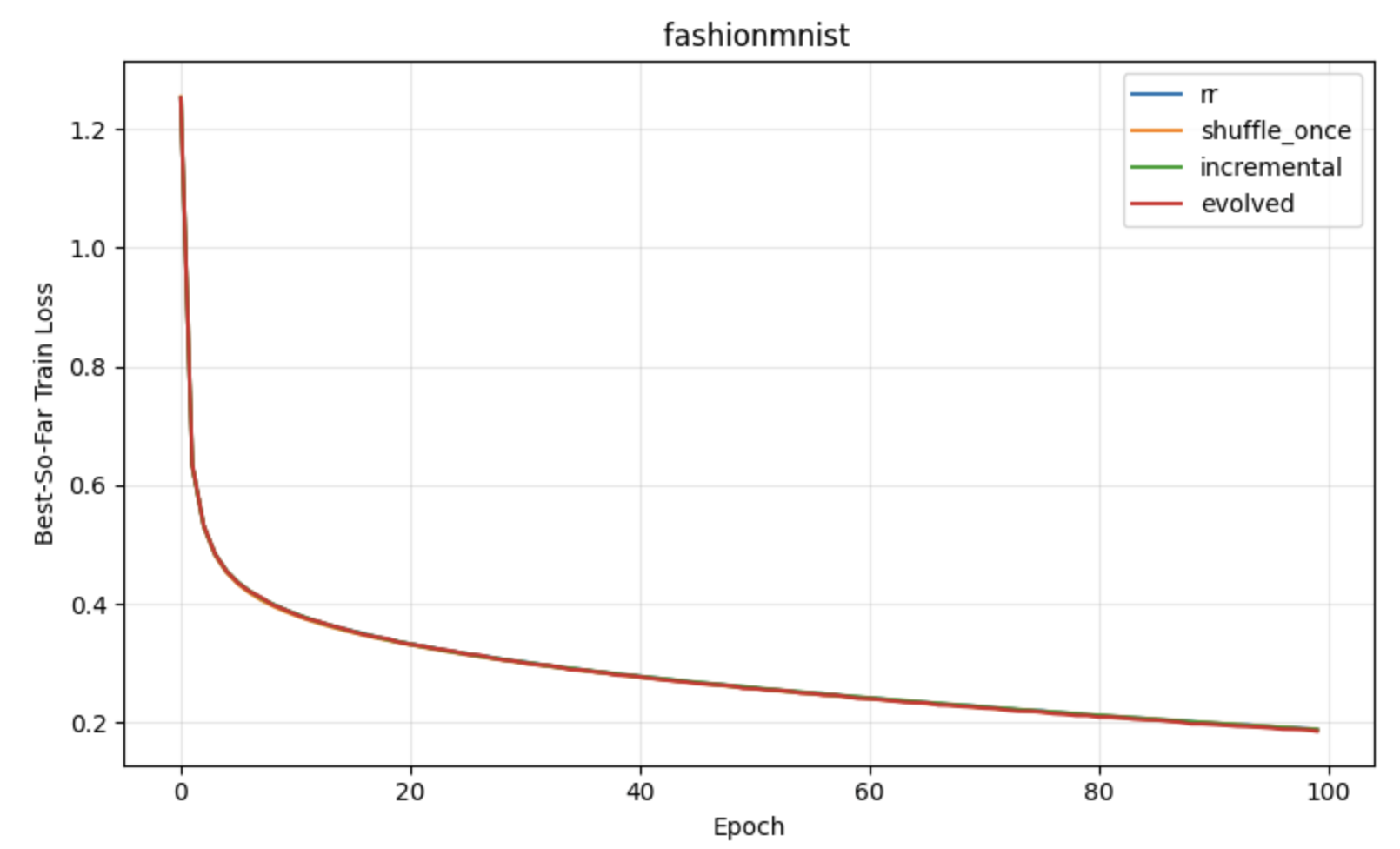
Figure 1: Comparative performance of shuffling schemes under constant learning rates, showing superior convergence and stability for block reshuffling-based strategies.
Paired Reversal: Symmetrization and Order-Sensitivity Cancellation
A common source of inefficiency is permutation-induced, order-dependent drift in epoch-based SGD. Under standard smoothness assumptions, this manifests as a second-order (γ2) term dependent on the within-epoch order. Paired reversal addresses this by averaging the updates from a permutation and its reverse, forming a symmetrized epoch map:
Tˉπ(w)=21(Tπ(w)+Trev(π)(w))
Theoretical analysis shows that this cancels the entire order-dependent γ2 term, reducing sensitivity from O(γ2) to O(γ3) (Theorem 1). This symmetrization induces rigorously provable stability, unaffected by the randomness of the permutation and introducing no computational overhead.
Algorithmic Discovery via LLM-Guided Evolution
The LLM-guided evolution process (OpenEvolve) explored deterministic Python functions that map epoch-level statistics to dataset permutations. Effective rules discovered by this pipeline manifested recurring structural elements: block-level partitioning and periodic reversal transforms, guided solely by training loss dynamics. This led to the formalization of the Adaptive Block Reshuffling with Periodic Transforms (APR) algorithm, capable of adaptively switching regimes based on loss improvement thresholds.
APR is always compatible with unified shuffling convergence analyses, since it outputs a single valid permutation per epoch.
Comprehensive Empirical Validation
The paper presents robust numerical experiments across classification and regression tasks, convex and nonconvex settings, and both constant and diminishing learning rates. Experiments were conducted on standard datasets—tabular, image, and neural network benchmarks—using both SGD and Adam.
Key findings:
- APR consistently yields lower training loss and greater stability in convex tasks relative to incremental gradient, shuffle-once, and random reshuffling, most notably under constant learning rates.
- APR exhibits reduced variance across runs, indicating smoother optimization dynamics.
- While performance differences diminish in the small learning rate regime, structured shuffling is advantageous when order effects are non-negligible.
- Gains persist under adaptive optimizers such as Adam, suggesting applicability beyond vanilla SGD.
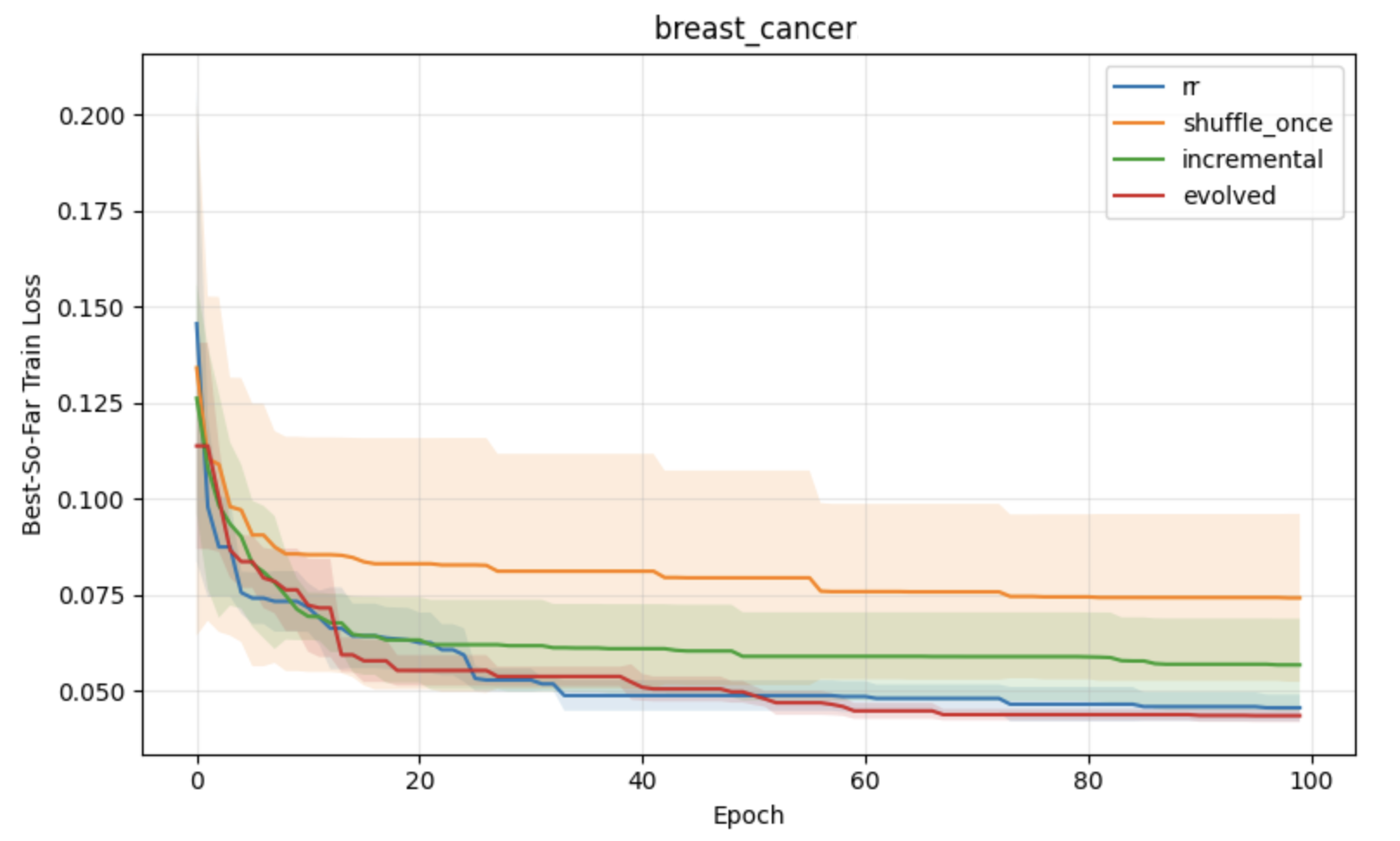
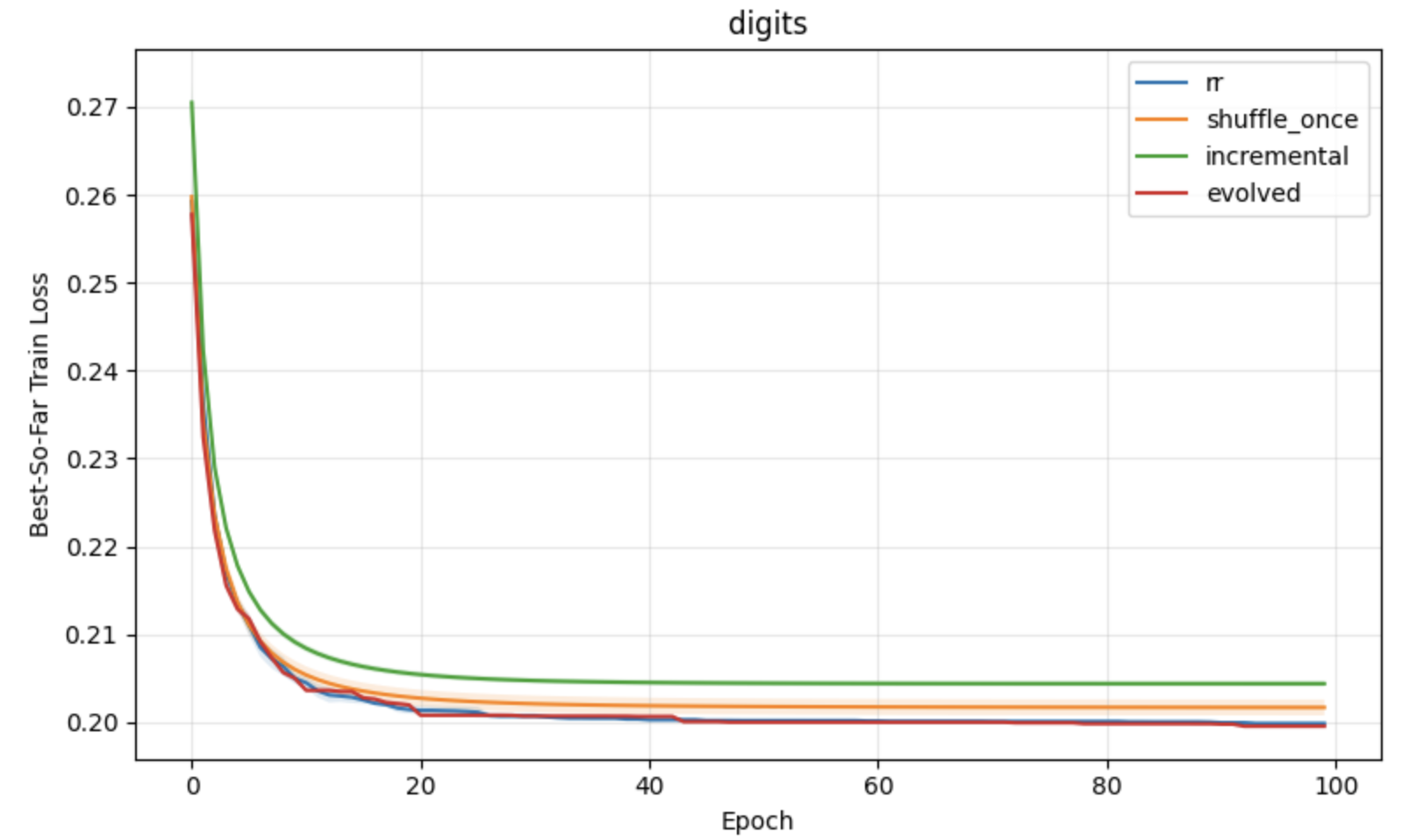
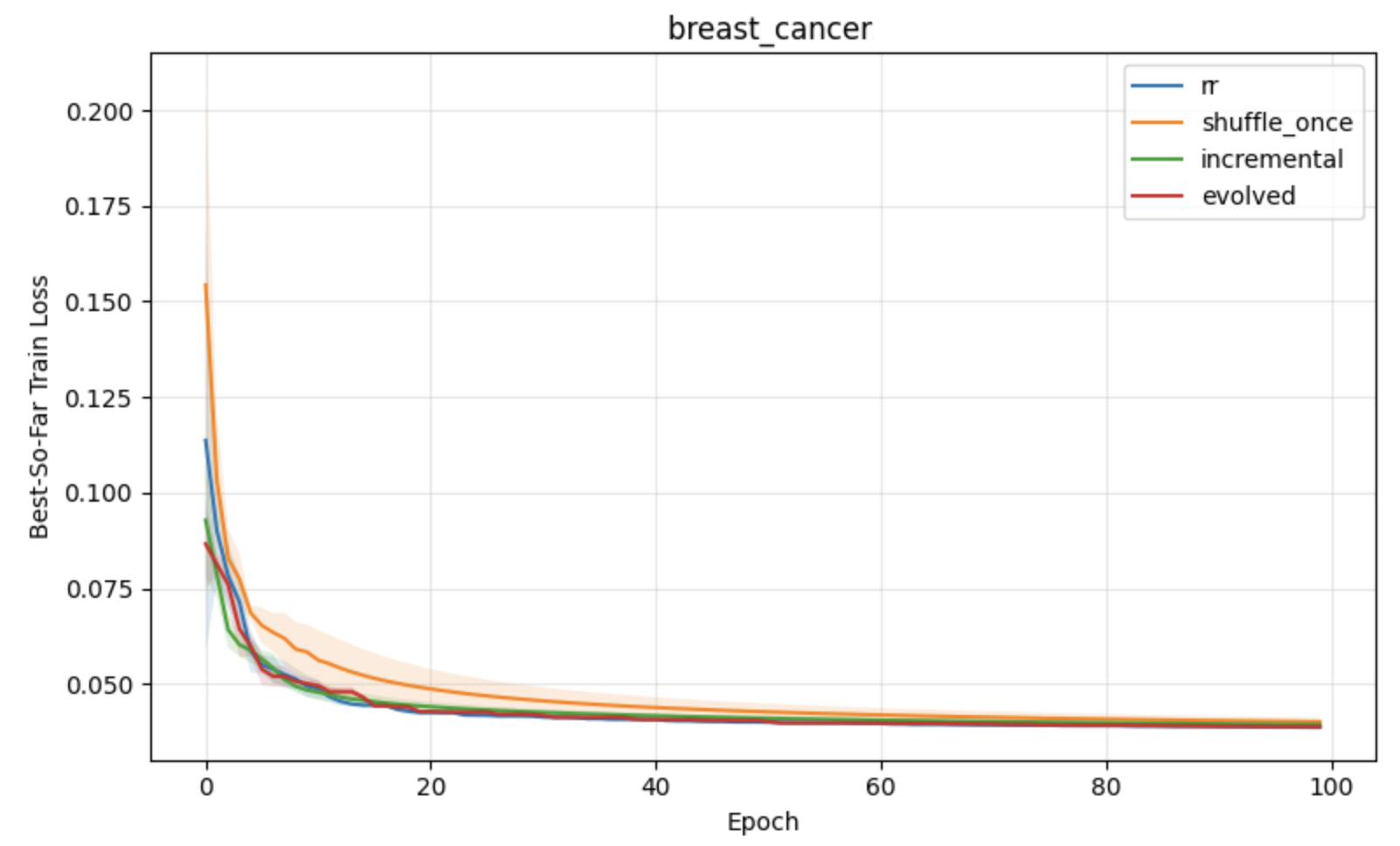
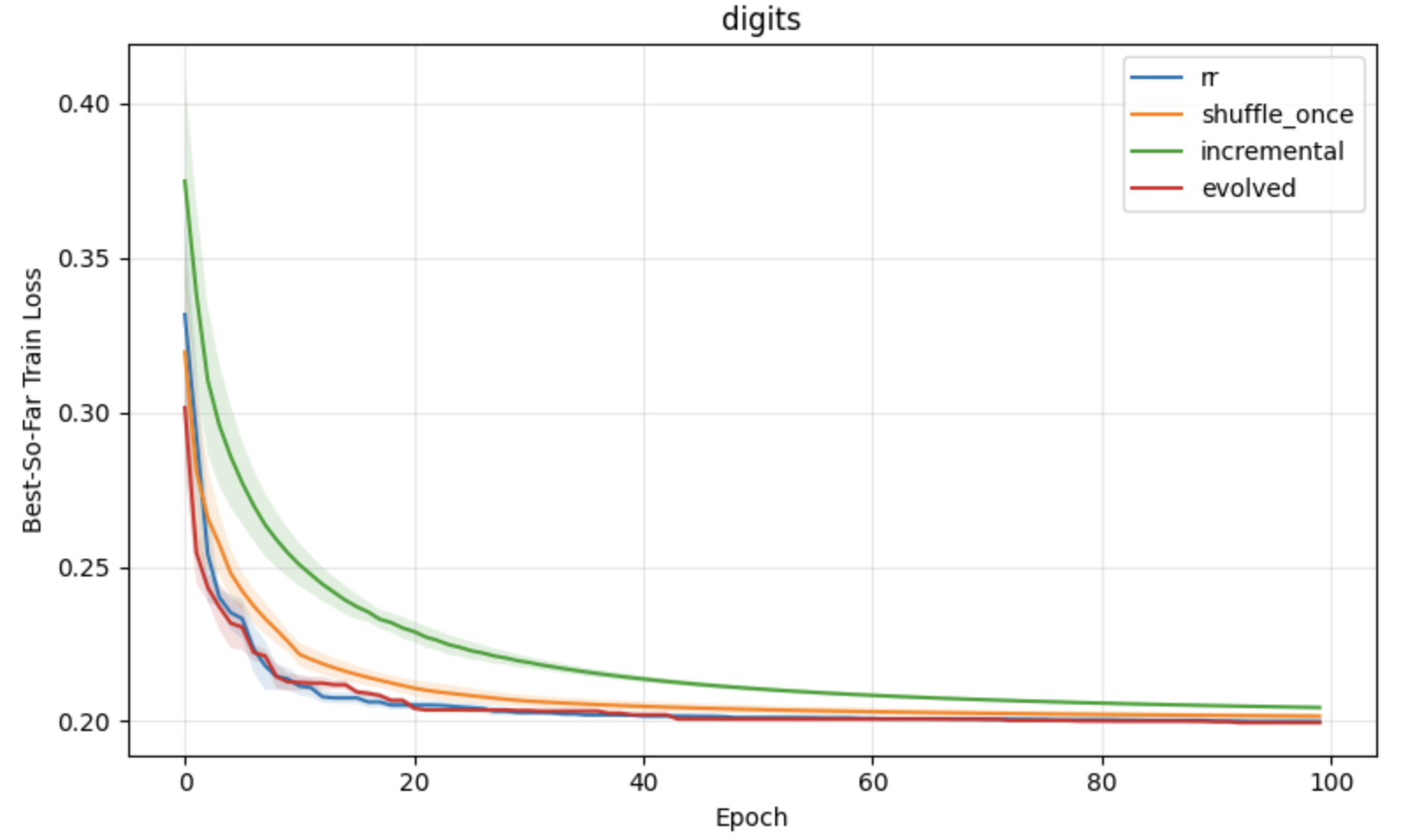
Figure 2: Classification task results under constant learning rates, demonstrating optimization advantages of block reshuffling in APR.
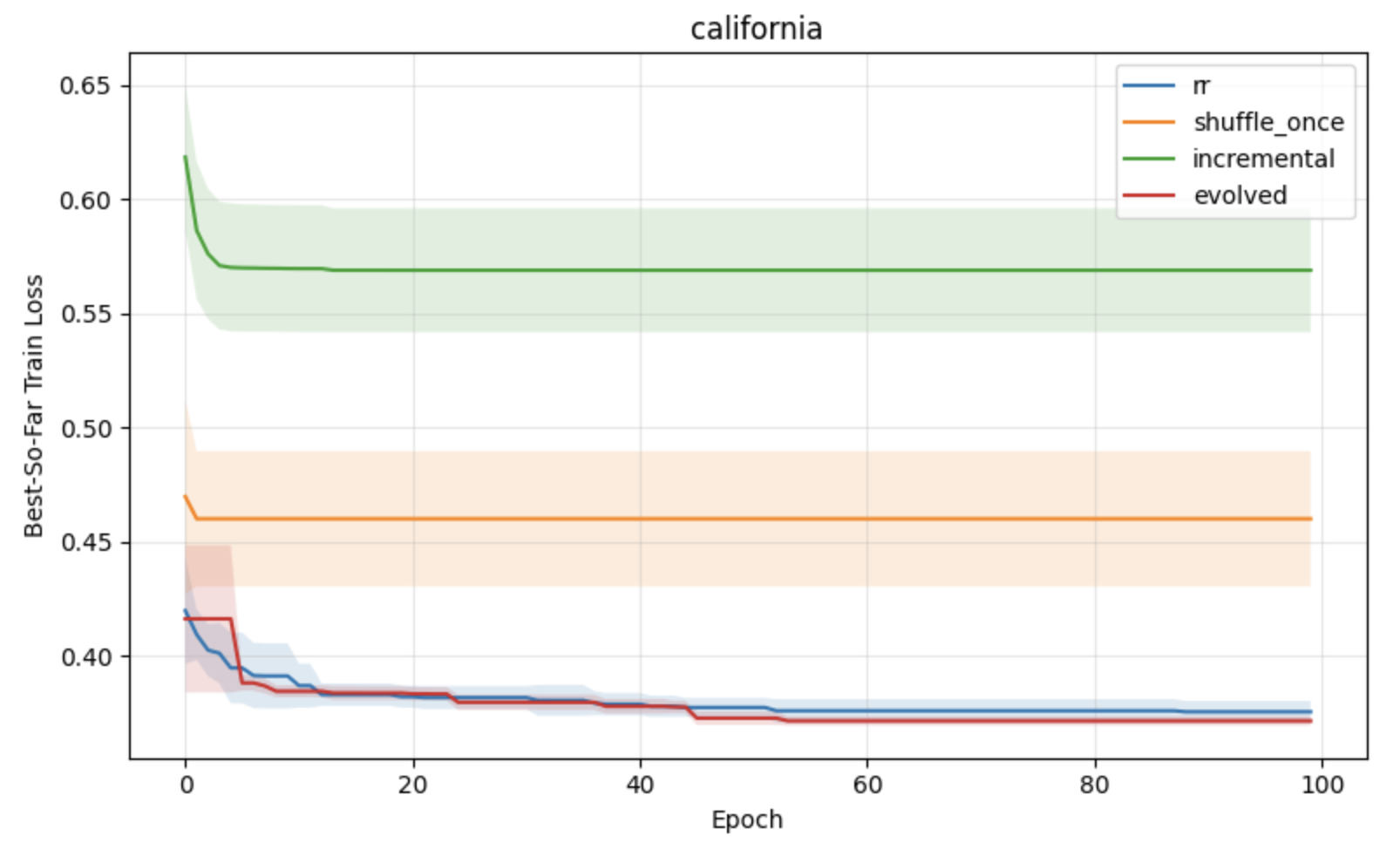
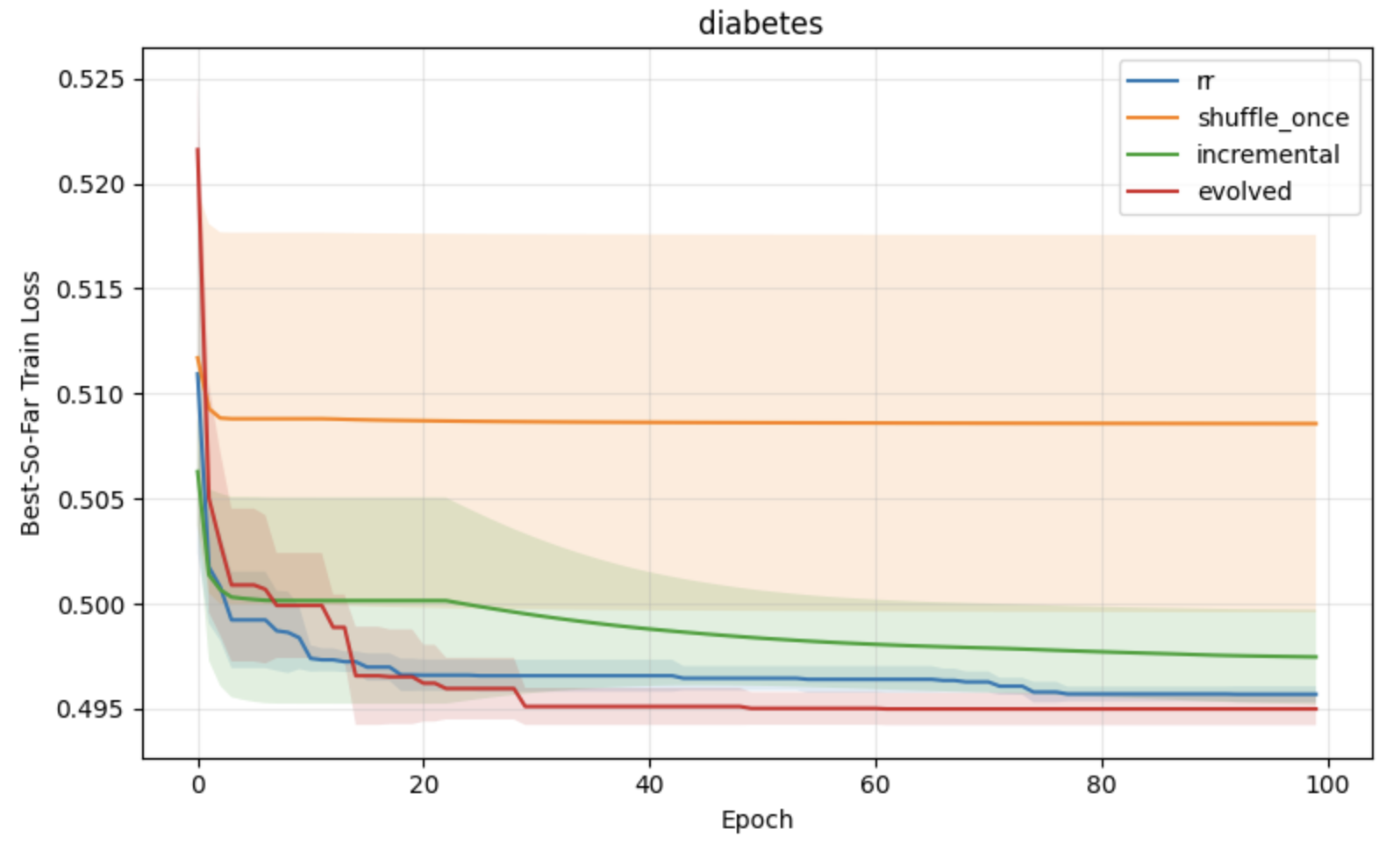
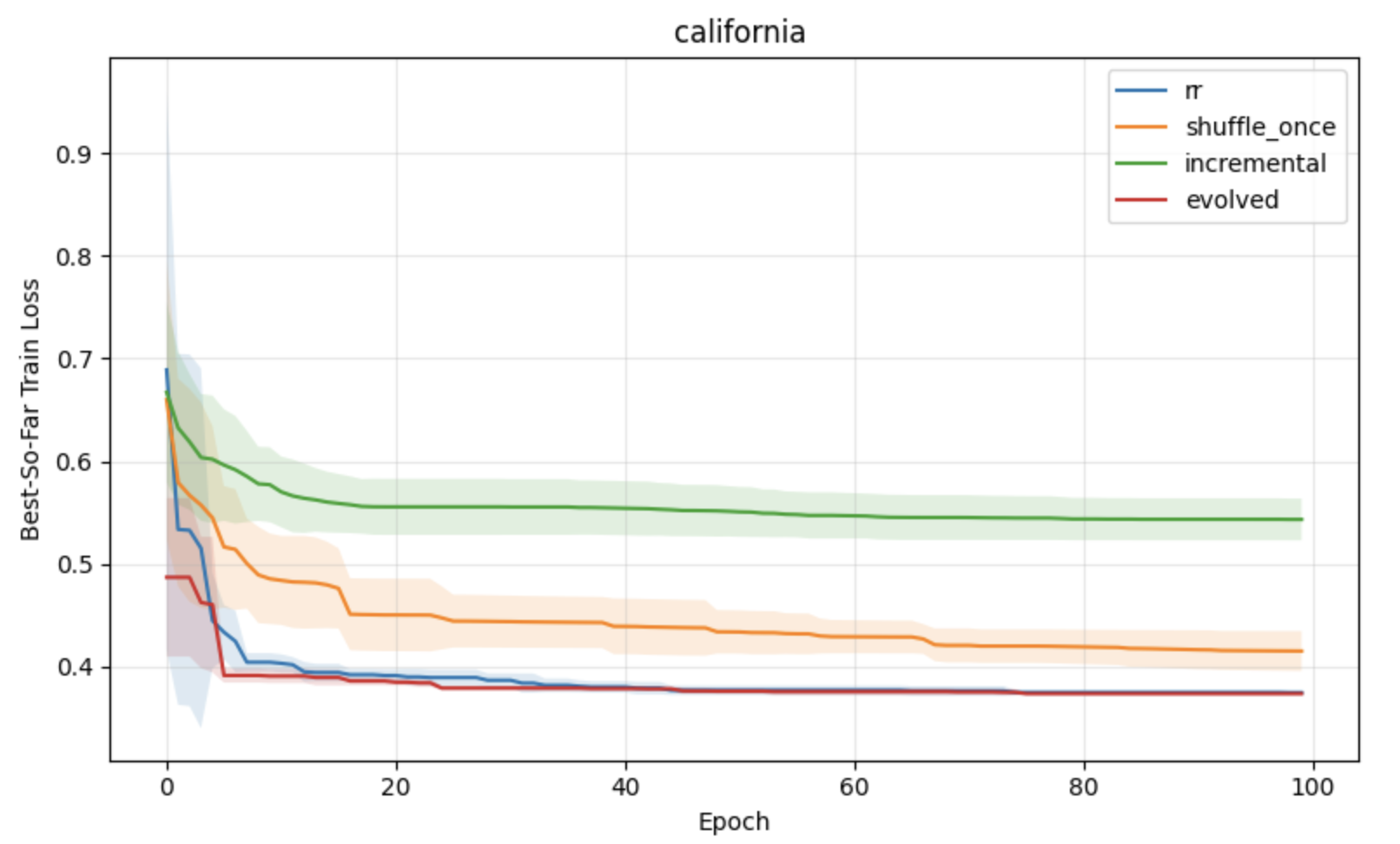
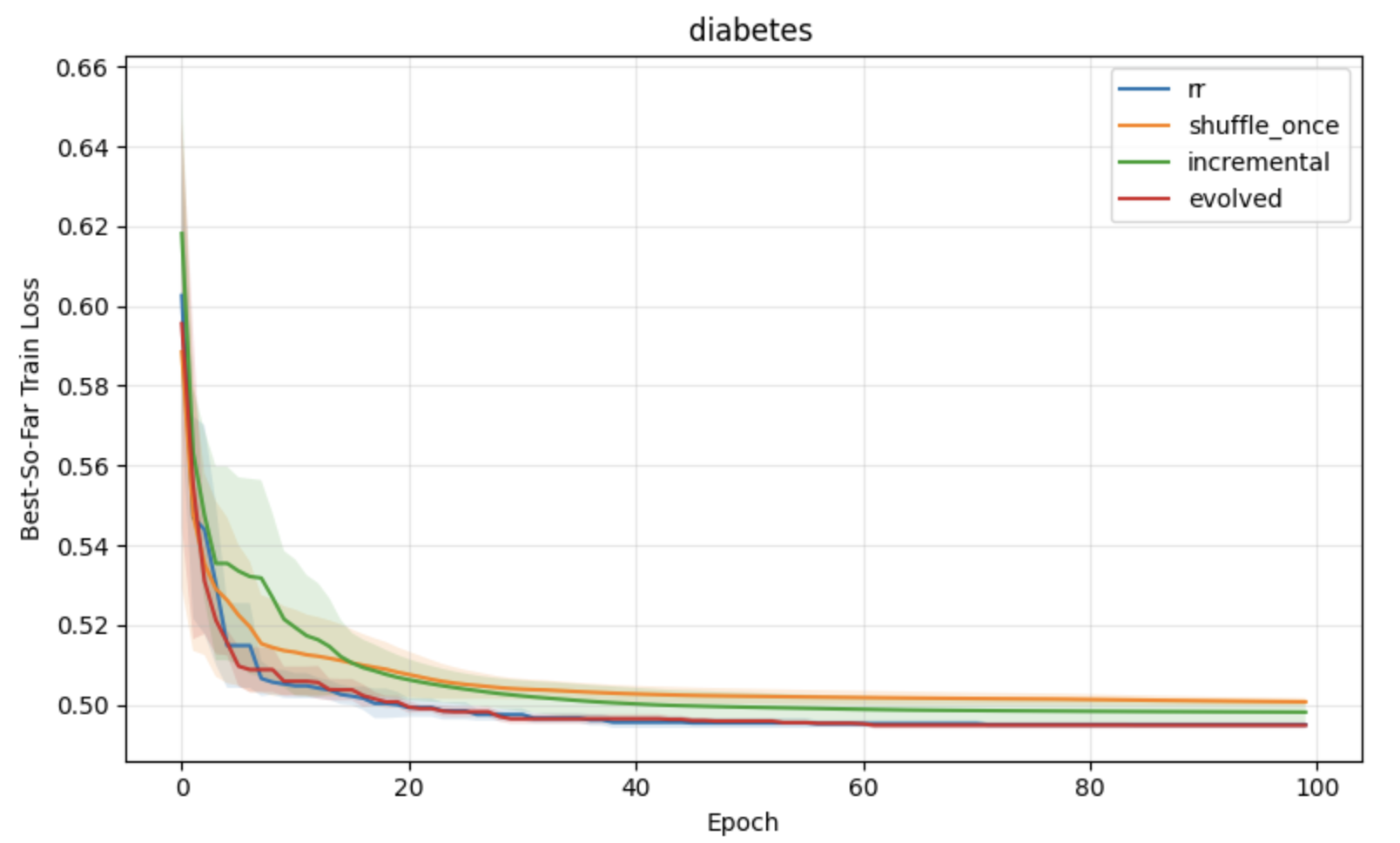
Figure 3: Regression task results under constant learning rates, with lower loss and variance for APR compared to standard shuffling baselines.
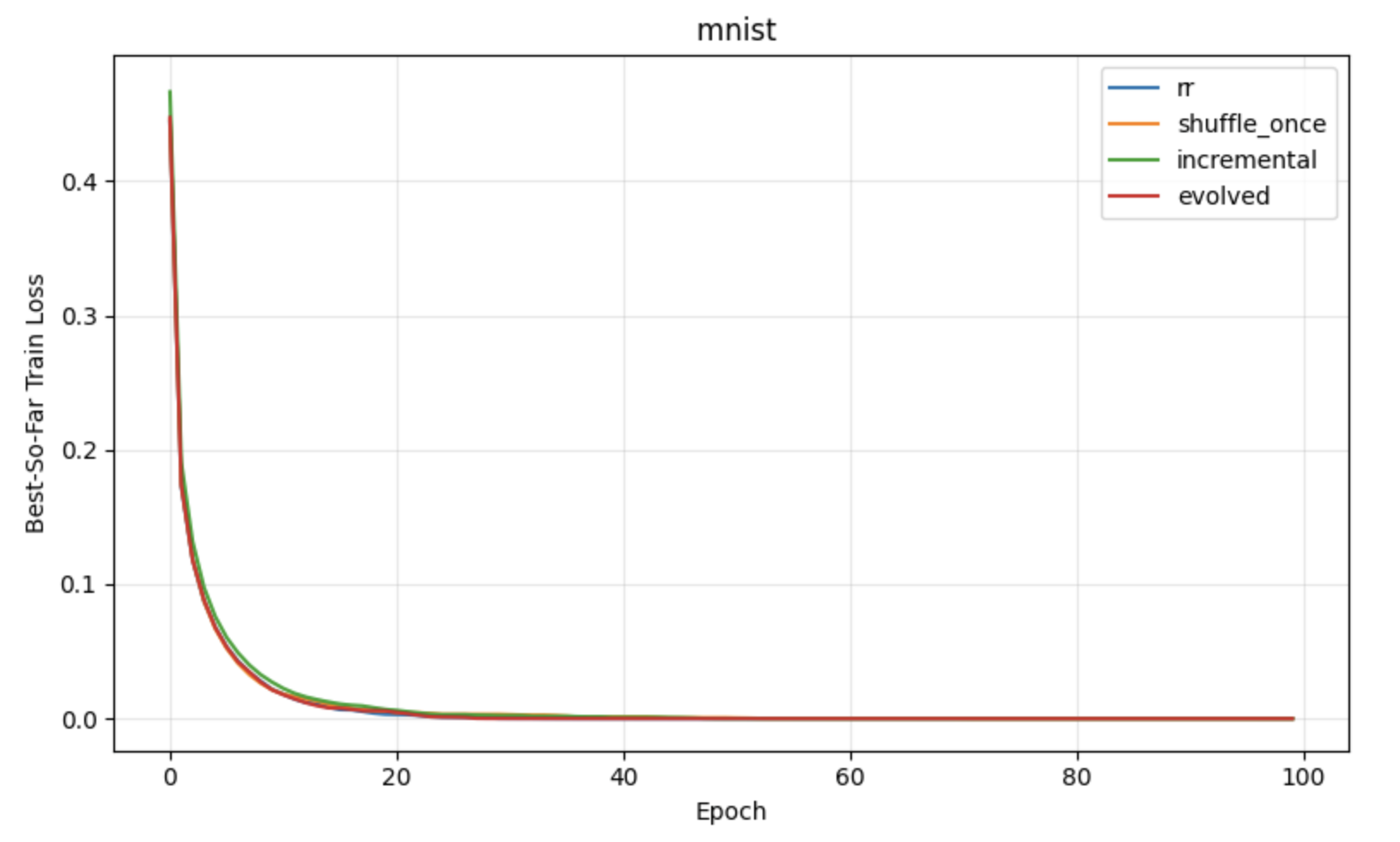
Figure 4: Classification with neural networks, emphasizing consistent improvements of APR on more complex, nonconvex problems.
Theoretical and Practical Implications
This research establishes that structured permutations offer mechanistic improvements: block reshuffling reduces prefix-gradient variance, and paired reversal rigorously cancels order dependence. These mechanisms yield optimization constants improvements and enhanced trajectory stability, suggesting broad applicability in large-scale training.
Practically, the APR algorithm is computationally efficient, requires no additional storage, and is compatible with standard SGD frameworks. Theoretical analyses confirm benefits for both constant and diminishing learning rates, though most pronounced in moderate learning rate regimes.
Theoretically, the principles of variance and symmetry embodied by block reshuffling and paired reversal suggest a rich, unexplored design space for permutation structures in without-replacement stochastic optimization. These insights motivate further investigation into algorithm synthesis, structured permutation theory, and sharper convergence bounds.
Conclusion
This paper formalizes and validates the utility of structured shuffling schemes—specifically, block reshuffling and paired reversal—providing both theoretical proofs and strong empirical results. By leveraging LLM-guided discovery and unified shuffling analyses, it demonstrates that nontrivial permutation structures can improve optimization constants and stability in without-replacement SGD. The practical efficacy and theoretical clarity of these mechanisms suggest promising directions for future algorithmic innovation in stochastic optimization.