- The paper introduces a robust computational framework using fastText, Word2vec, and the Discriminative Lexicon Model to achieve over 97% comprehension accuracy for mapping Polish forms to meanings.
- It employs techniques such as LDA and t-SNE to visualize and quantify the clear clustering of phonotactic and morphosyntactic features within semantic spaces.
- The study challenges traditional views by demonstrating that detailed phonological and morphological cues systematically influence semantic representations in Polish.
Introduction
This study presents a rigorous computational investigation into the interaction between phonological, morphonological, and morphosyntactic structure and semantics in Polish, a language characterized by highly complex consonant clusters, rich inflectional morphology, and nontrivial morphonotactic processes. The work leverages distributional semantics—specifically, fastText and Word2vec embeddings—and the Discriminative Lexicon Model (DLM) to systematically explore the extent to which semantic space encodes or mirrors sub-lexical, morphological, and morphotactic regularities. Linear Discriminant Analysis (LDA) and t-SNE projections are employed to quantify and visualize the semantic separability of features at different linguistic strata. The study postulates and empirically supports a strong isomorphy between form space and semantic space in Polish, challenging strict views on the arbitrariness of the sign.
Theoretical and Linguistic Background
Contrary to the traditional stance of dual articulation and arbitrariness (de Saussure, Martinet), a growing empirical literature contends that phonetic, phonological, and morphological structure is systematically reflected in word meanings and vice versa. The evidence spans iconicity, duration differences among English homophones, and morphologically-driven phonetic effects in diverse typologies. Polish provides an ideal testbed due to its extreme phonotactic permissiveness, exemplified by morphonotactically intricate initial clusters arising from productive and unproductive prefixation, vowel-zero alternations, and rich case, gender, and number distinctions. Of particular interest are productive aspectual prefixes (e.g., s-, z-, w-, wz-), the gradient parsability of morpheme boundaries, and alignment between morphological decomposition and perception/production mechanisms.
Dataset Construction and Representation
The study compiles a corpus-derived dataset of 8,015 unique words (strings) from the 8,000-lemma "Słownik Podstawowy Języka Polskiego dla Cudzoziemców" and extracts all forms containing initial morphonotactic clusters, subsequently deduplicated for syncretic forms. Each form is annotated for part of speech, detailed morphosyntactic categories (case, number, gender, person, tense, aspect), and cluster-level phonological/morphonological attributes (size, markedness, prefix identity, morpheme parsability). Embeddings are provided both by fastText (subword-sensitive) and standard Word2vec (whole-word-based), allowing assessment of the impact of sublexical distributional information.
The DLM is instantiated with form representations as n-gram presence vectors and meanings as embeddings. As a strictly compositional, analogy-based approach, the DLM eschews explicit morpheme segmentation, learning only linear mappings between form space and embedding space via analytic solutions (end-state learning). Comprehension (form-to-meaning) accuracy reaches >97% across train, test, and held-out sets; production accuracy is comparable for seen items and 77.8% for held-out forms, with most errors involving grammatical feature substitutions rather than stem misprediction. Crucially, out-of-vocabulary productions are overwhelmingly well-formed and legal, further confirming the generalizability of the learned mappings.
Visualization of High-Dimensional Structure
Scatterplots of 2D t-SNE projections (e.g., for parts of speech, case, number, person, gender, cluster size/markedness) show nontrivial but robust clusterings for morphosyntactic categories (Figure 1, Figure 2). Most strikingly, even purely phonotactic properties (e.g., initial cluster markedness) induce weak—yet measurable—clustering in semantically induced structures, as evidenced in Figure 3.
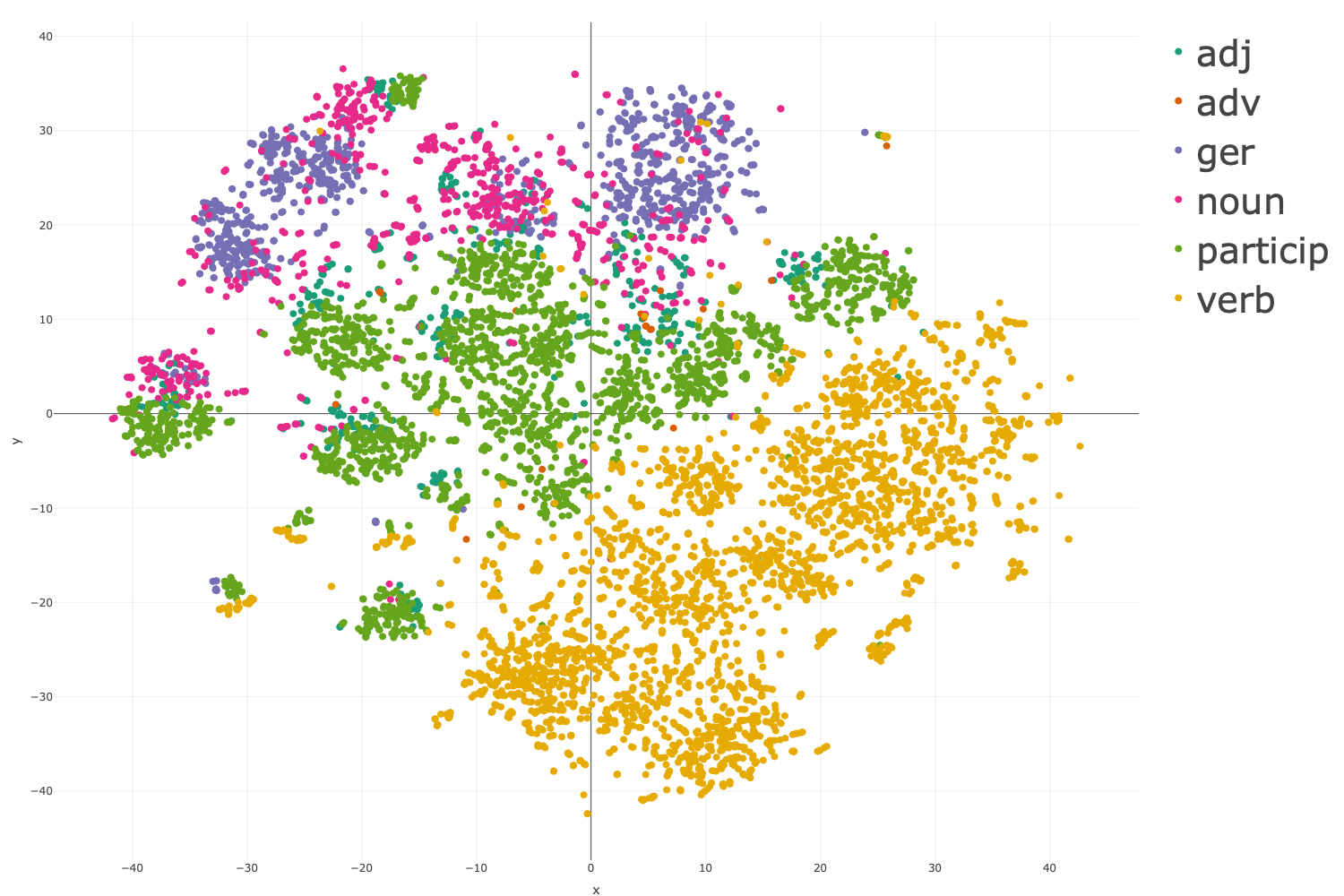
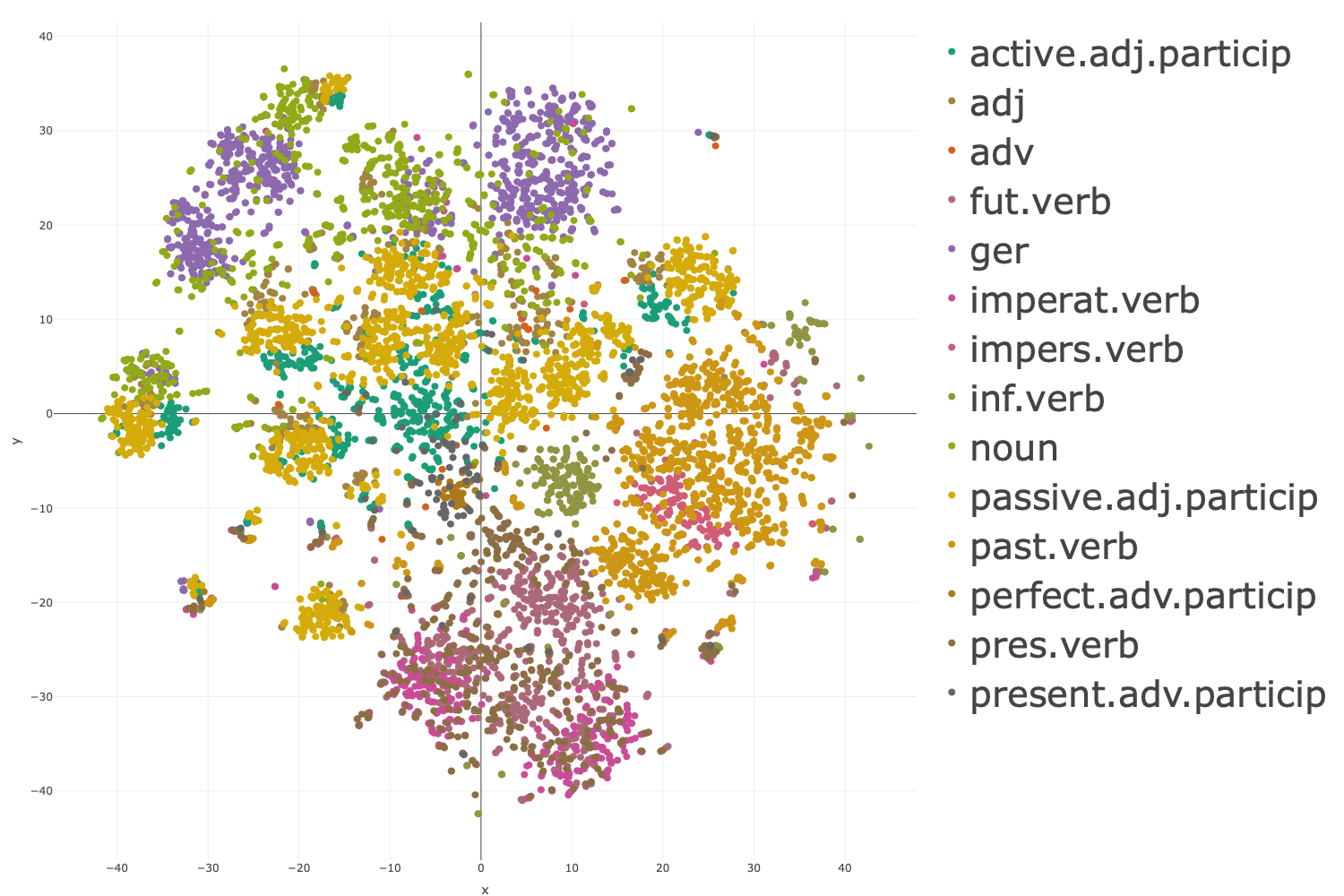
Figure 1: Scatterplots in t-SNE space color-coded for POS and detailed morphosyntactic classes, demonstrating strong separation by major morphosyntactic categories.
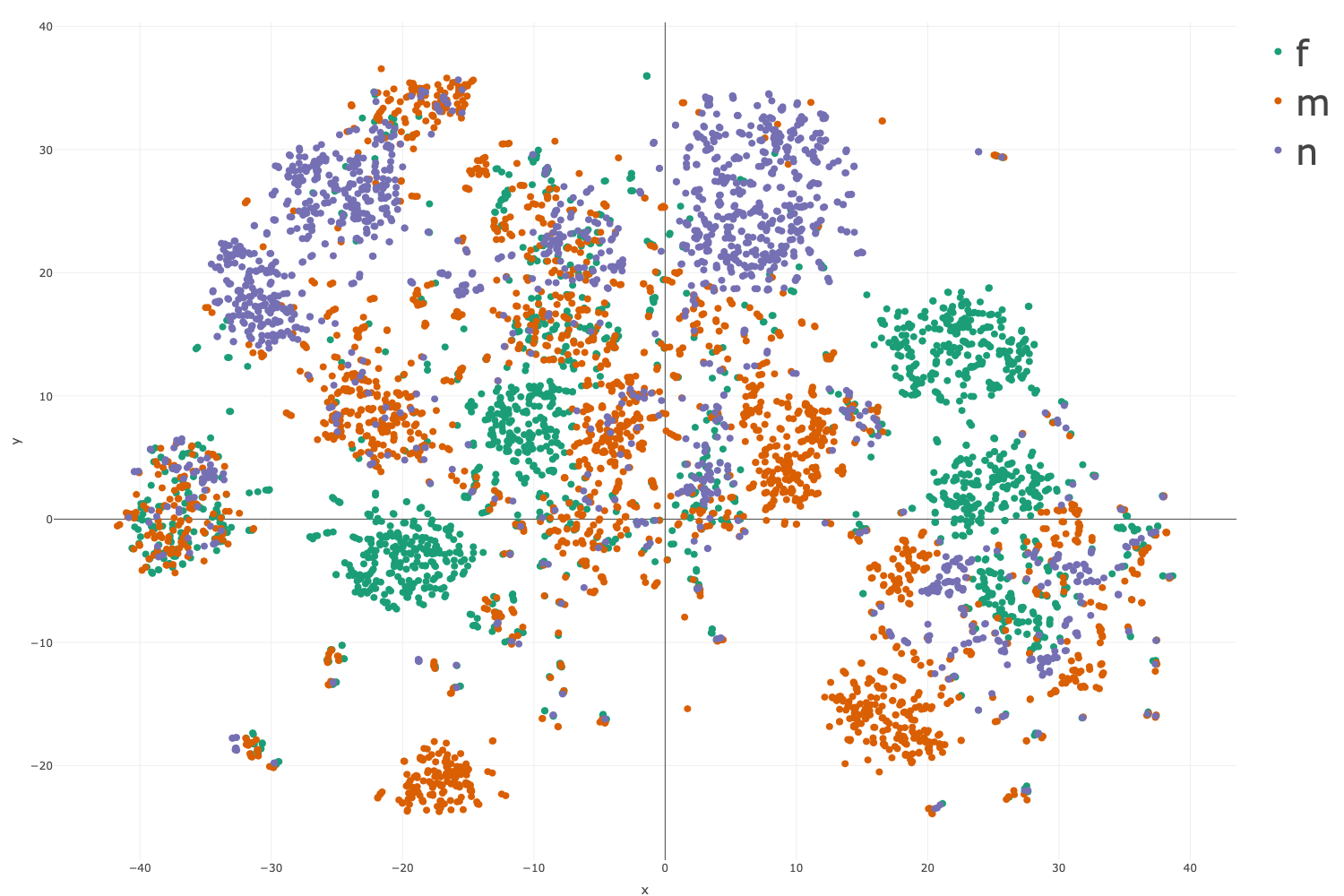
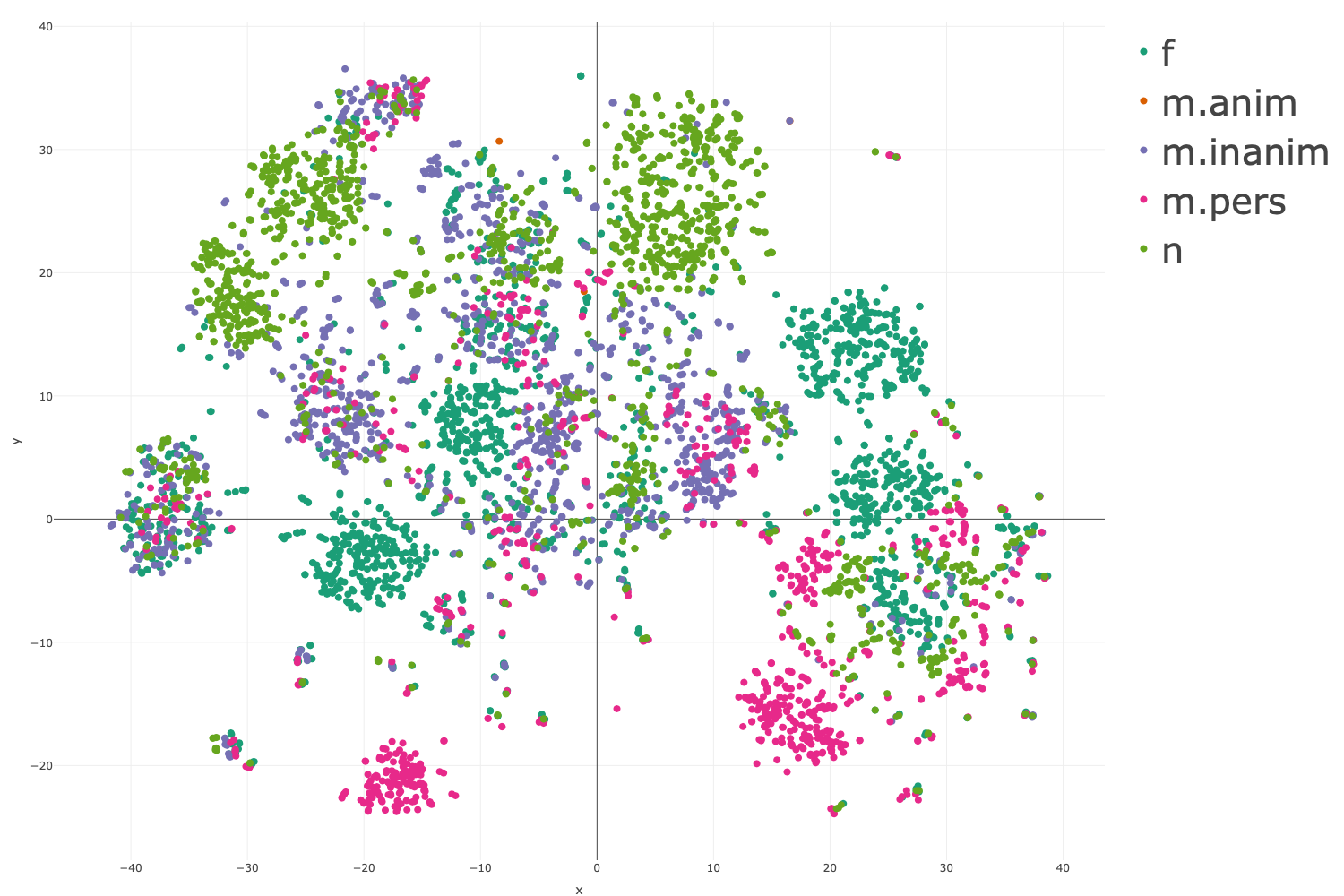
Figure 2: Gender-based t-SNE clusterings, showing non-random distribution and partial overlaps directly corresponding to morphological syncretism.
Discriminability Analysis (LDA)
Supervised LDA with cross-validation quantifies the degree of semantic isomorphy for a wide spectrum of linguistic features:
- Morphosyntactic categories (e.g., person, tense, aspect, case, number) are predicted from embeddings at accuracies between 89–99%, greatly exceeding majority baselines.
- Fine-grained morphonotactic and phonotactic properties (prefix identity, cluster markedness, cluster length, morpheme boundary parsability) are also recoverable with 81–97% accuracy.
This holds for both fastText and Word2vec representations, though fastText consistently reports higher discriminability, particularly as cluster complexity and sublexical irregularity increase.
Principal Components Analysis
Variance partitioning (Figure 4, Figure 5) reveals that morphosyntactic features account for significant portions of the first 50–100 principal components, signifying direct entanglement with macro-axes of semantic variation. In contrast, phonotactic and morphonotactic variables are encoded diffusely, requiring 200+ PCs for full classification accuracy, indicating weaker, distributed representation.
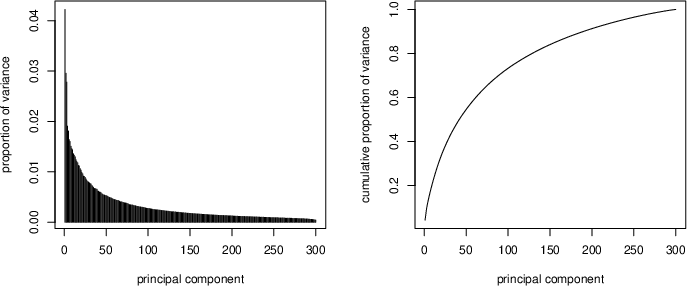
Figure 4: Cumulative explained variance by principal components in semantic space.
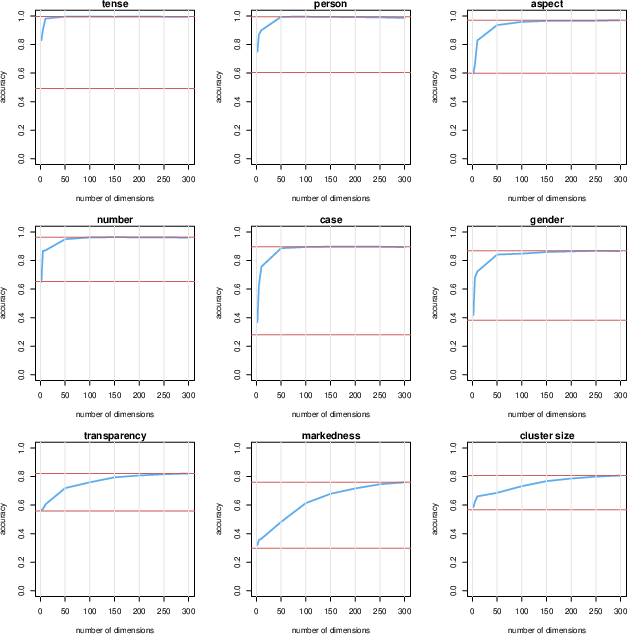
Figure 5: Classification accuracy of morphosyntactic and phonotactic categories as a function of number of principal components used in LDA.
Implications and Contributions
This work decisively demonstrates that in Polish, morphological (inflectional, derivational), morphonological, and a broad spectrum of phonotactic properties are systematically encoded in semantic embeddings derived purely from distributional statistics. The correspondence transcends morphological boundaries and is recoverable even in embeddings not privy to subword information, highlighting the prevalence of non-arbitrary form-to-meaning mappings. Morphosyntactic variables—person, case, tense, gender—not only structure semantic space but also dominate principal axes of variation, underscoring their centrality in meaning organization. The recoverability of phonotactic features through embeddings provides compelling evidence for a gradient—and partially iconic—mapping between linguistic form and usage-induced semantics.
These findings challenge strict decompositional and symbolic models of morphology by empirically validating the DLM’s distributional, non-segmental mapping. The demonstration that production and comprehension can be highly accurate in a system with opaque morphology, heavy syncretism, and non-concatenative morphonotactics indicates that Polish learners may efficiently exploit analogical and distributional cues without morpheme segmentation.
For computational linguistics, the direct association between phonotactics/morphonotactics and semantic structure foreshadows efficient, language-generic approaches to processing languages with complex morphophonology. The results inform architecture choices for unsupervised LLMs and ground claims about the emergent nature of meaning in natural language.
Conclusion
This comprehensive study offers robust empirical support for the theoretical position that semantic space in natural language—even in a typologically complex system such as Polish—significantly reflects and encodes detailed properties of word form, morphological structure, and phonotactic legality. The isomorphism between meaning and form, quantified here, challenges the tenet of radical arbitrariness and sets the stage for more integrated, analogical models of the mental lexicon. Future research can generalize these findings to other morphologically rich, phonotactically intricate lexicons, examining typological parameters that mediate the strength of semantic-form alignment and further refining the representation of morphonotactic cues in neural and probabilistic models of language.