Towards Automatic Soccer Commentary Generation with Knowledge-Enhanced Visual Reasoning
Abstract: Soccer commentary plays a crucial role in enhancing the soccer game viewing experience for audiences. Previous studies in automatic soccer commentary generation typically adopt an end-to-end method to generate anonymous live text commentary. Such generated commentary is insufficient in the context of real-world live televised commentary, as it contains anonymous entities, context-dependent errors and lacks statistical insights of the game events. To bridge the gap, we propose GameSight, a two-stage model to address soccer commentary generation as a knowledge-enhanced visual reasoning task, enabling live-televised-like knowledgeable commentary with accurate reference to entities (players and teams). GameSight starts by performing visual reasoning to align anonymous entities with fine-grained visual and contextual analysis. Subsequently, the entity-aligned commentary is refined with knowledge by incorporating external historical statistics and iteratively updated internal game state information. Consequently, GameSight improves the player alignment accuracy by 18.5% on SN-Caption-test-align dataset compared to Gemini 2.5-pro. Combined with further knowledge enhancement, GameSight outperforms in segment-level accuracy and commentary quality, as well as game-level contextual relevance and structural composition. We believe that our work paves the way for a more informative and engaging human-centric experience with the AI sports application. Demo Page: https://gamesight2025.github.io/gamesight2025



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
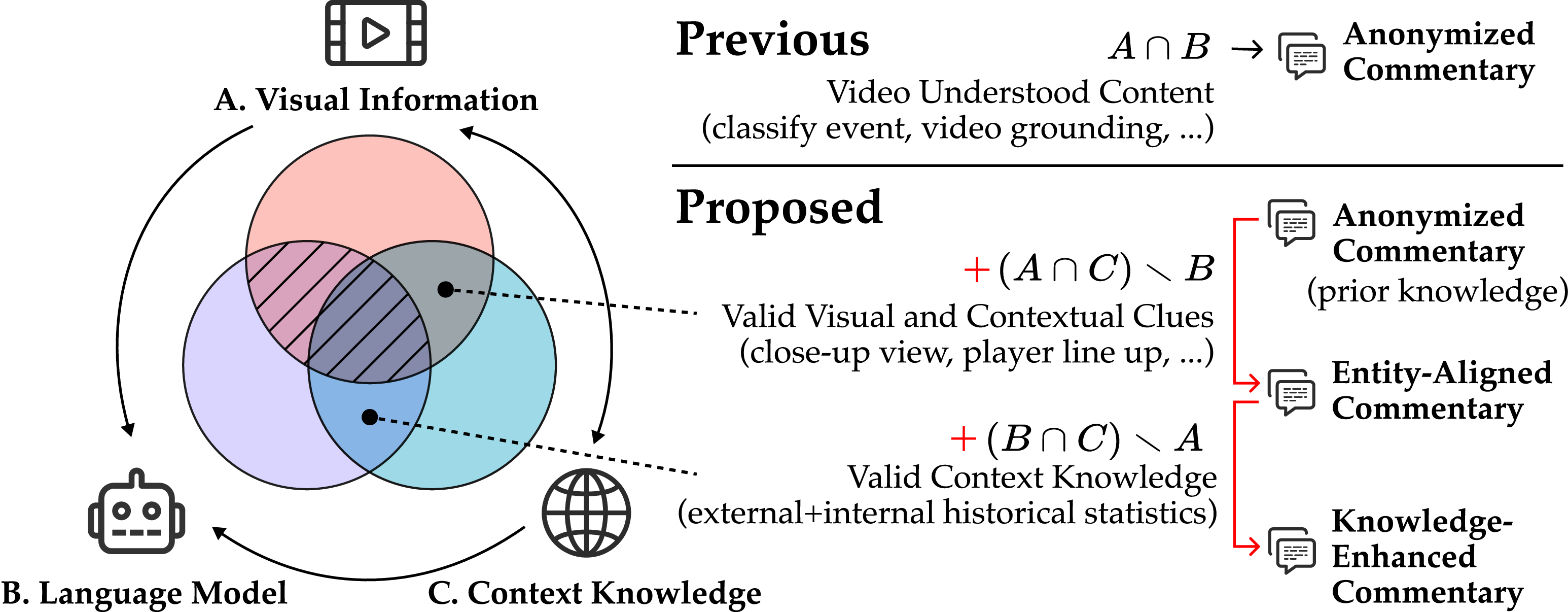
This paper introduces GameSight, an AI system that watches soccer videos and creates live, TV‑style commentary—like what you hear from professional commentators. Unlike earlier systems that wrote generic lines with “Player [#10]” or “Team [A],” GameSight figures out who the players and teams actually are and adds smart facts and context, making the commentary feel more human and engaging.
What questions the researchers wanted to answer
The authors focused on three simple but important goals:
- Can an AI correctly name the right player and team involved in a moment, instead of using anonymous labels?
- Can it keep track of what’s happening in the match (like the score or who just took a corner) so it doesn’t say things that conflict with earlier events?
- Can it add useful insights and stats (like “this is his 5th goal this season”) rather than just describing what’s on the screen?
How GameSight works (in everyday language)
The system works in two main steps, similar to how a real commentator thinks:
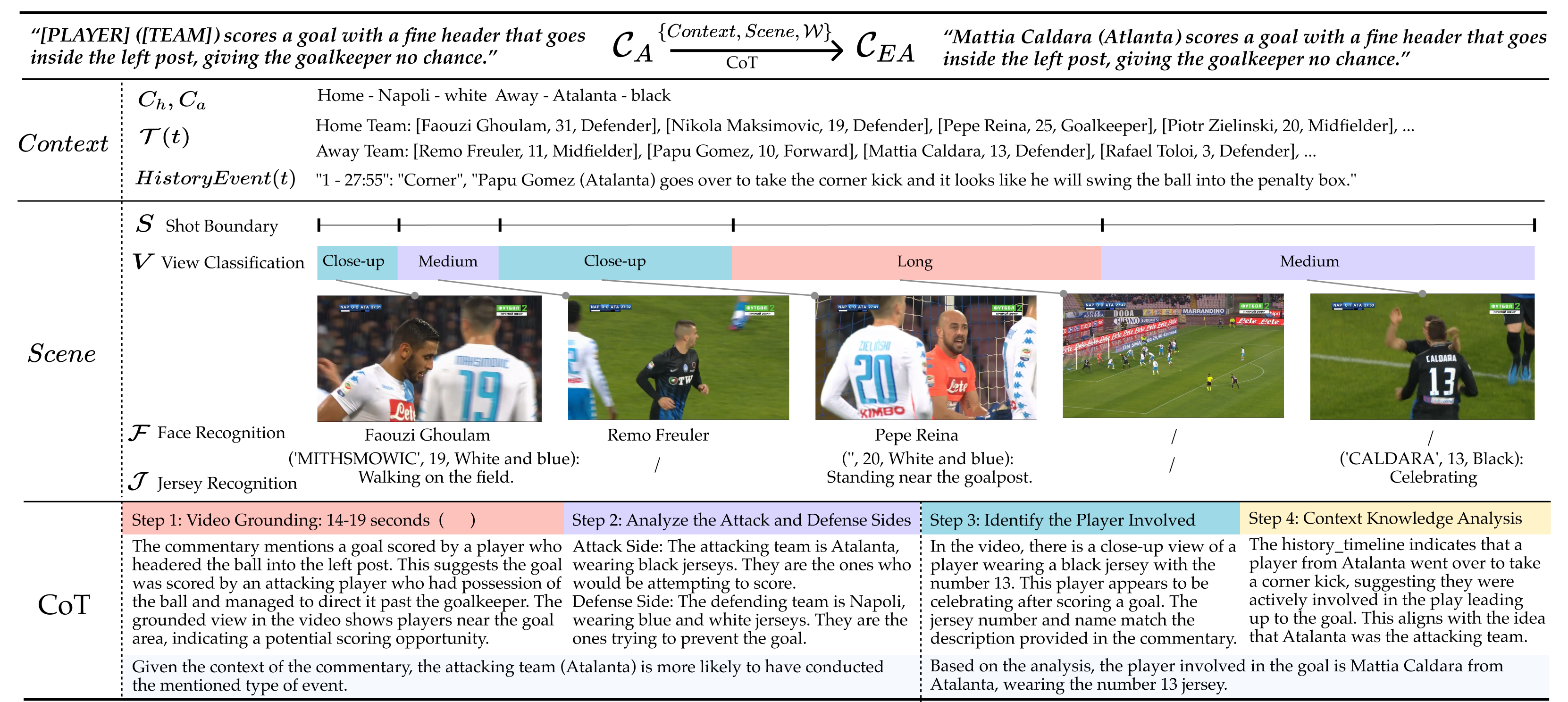
Step 1: Figure out “who’s who” using visual reasoning
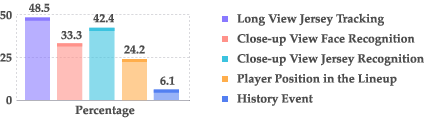
Think of this as a detective phase. The AI scans the video and uses many clues to identify the right player and team:
- Camera views: It notices when the broadcast cuts to a close-up or a medium shot. These shots often show the key player’s face or jersey right after an important moment.
- Faces, jersey numbers, and team colors: It looks for faces, shirt numbers, and colors to narrow down who’s involved.
- Timing clues: It learns which frames (moments) in the clip are most linked to the event being described, so it doesn’t get distracted by other actions happening nearby.
To make this step accurate, the researchers trained a video‑LLM with two techniques:
- Supervised fine‑tuning (SFT): Like giving the AI lots of examples and corrections so it learns the task well.
- GRPO (a reward-based strategy): Like giving it small “thumbs up” signals when its reasoning leads to the right choice, so it learns to think more carefully.
Before building this, they ran a “Player Guessing” game with expert commentators. Humans reached 96.3% accuracy and relied on more than just player tracking—they used close-ups, context, and smart guesses. That inspired the AI’s design to use many kinds of clues, not just one.
Step 2: Enrich the commentary with knowledge
Once the AI knows who’s involved, it writes the commentary and adds insights, like a pro commentator who mixes description with context:
- External knowledge: It connects to a soccer statistics database (think: a huge, organized book of past games and player records). The team improved an existing system so queries are more precise, time-aware (no “future” info leaks), and detailed (e.g., own goals, penalties).
- Internal game memory: It keeps an evolving log of the current match—scoreline, who scored, who assisted, cards, and useful player background—so the commentary stays consistent throughout the game.
Finally, a LLM (the text-writing brain) blends the “who” with the knowledge to produce TV‑style commentary that isn’t just descriptive, but also explains and comments on the action.
What the researchers found and why it matters
The team ran many tests comparing GameSight to strong baselines and commercial models:
- Better at naming players: GameSight improved player identification accuracy by 18.5% over a top commercial video model (Gemini 2.5‑pro). Training with both SFT and GRPO gave the best results, showing that “teaching + rewarding good reasoning” helps the AI think better.
- Smarter use of stats: Their upgraded knowledge system raised external statistics accuracy from about 65% to about 82%. For in‑game facts (like who scored), accuracy was very high (around 99% for goal-related details).
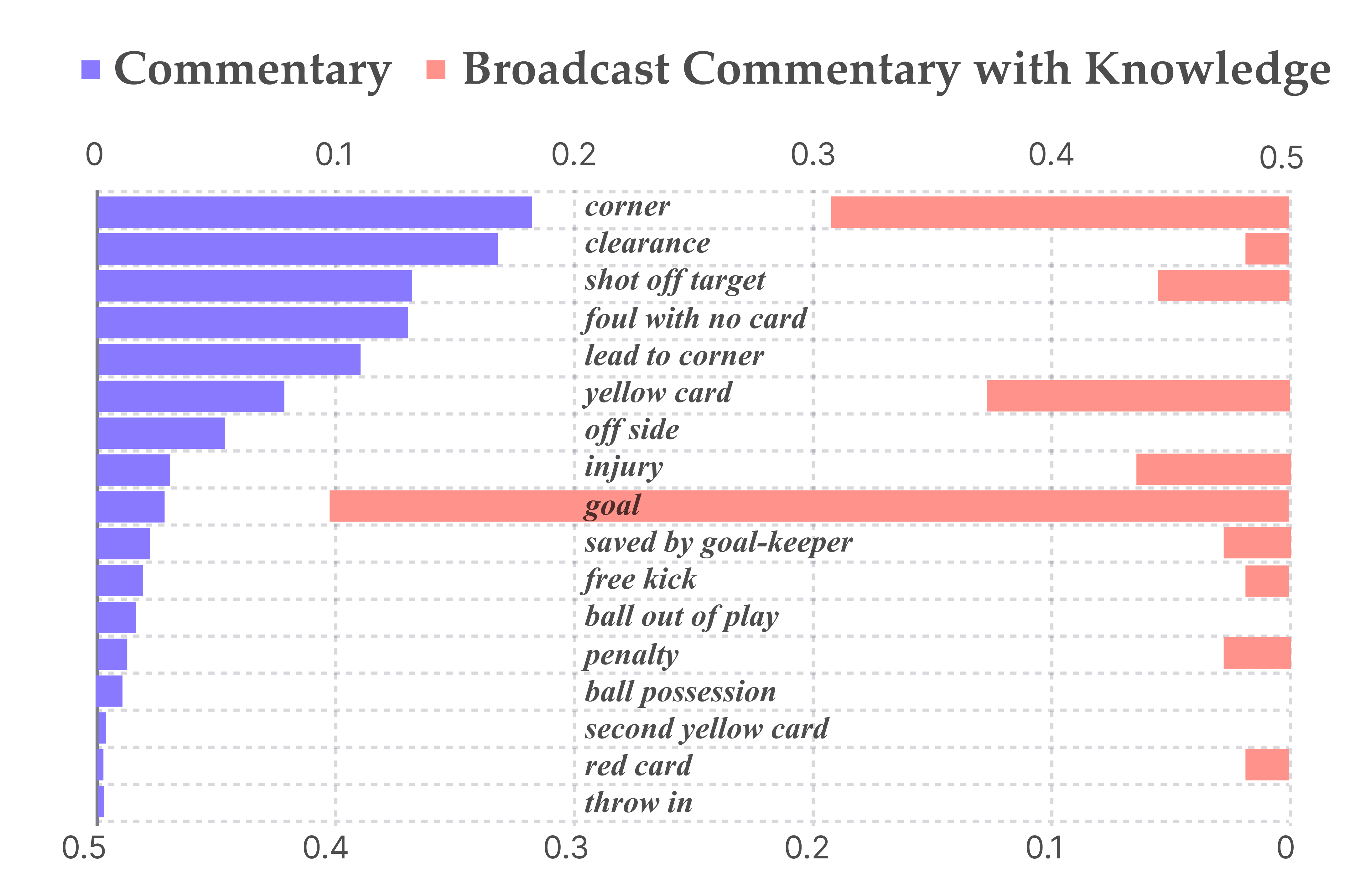
- More like TV commentary: When judged against real TV commentary, GameSight’s output matched the tone and structure better than earlier systems. It didn’t just describe; it also explained and commented—keeping description under 50%, which sports communication experts say is a good balance.
- Easier to follow: Text analysis showed GameSight had stronger coherence—its sentences linked together better, with clearer cause-and-effect and references (like “he,” “that pass,” “the goal”) that actually point back to the right things. Listeners also preferred it more than plain live-text style captions.
Why this matters: For fans, that means more enjoyable and informative commentary. For products and broadcasts, it shows that AI can move beyond captions and start offering genuinely helpful, broadcast-quality narration.
What this could mean in the future
GameSight shows that splitting a hard problem into two clear steps—first “who is involved,” then “what’s the insightful story”—works really well. This approach:
- Could make AI sports apps, highlight reels, and live streams more engaging and easier to understand.
- Might be adapted to other sports where identifying people and adding context is key (basketball, American football, etc.).
- Highlights the power of combining video understanding with trustworthy, up‑to‑date knowledge.
In short, this research brings AI commentary closer to the way real commentators work: identify the right players quickly, keep the match story straight, and add smart facts that make the game more exciting to watch.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concrete, actionable list of what remains missing, uncertain, or unexplored based on the paper.
- Real-time feasibility is untested: end-to-end latency, throughput, and memory footprint of the two-stage pipeline (shot detection, face/jersey recognition, retrieval, LLM reasoning) under live broadcast constraints are not measured or optimized.
- Robustness to broadcast variability is unquantified: performance under different leagues, stadium lighting, camera rigs, zoom/replays, on-screen graphics, compression artifacts, and alternate/third kits is not assessed.
- Sensitivity to video resolution and frame rate is unstudied: model is fine-tuned at 180p and 1 fps due to resource limits, yet human cues are often high-frequency and high-resolution; the trade-off between resource use and entity accuracy remains unclear.
- No ablation of Stage I inputs: the independent and combined contributions of C_GS (internal game state), Scene (fine-grained visual cues), and W (MatchVision-derived frame-level guidance) to alignment accuracy are not analyzed.
- Reliance on external event guidance is brittle: Stage I depends on a Q-former-derived frame-level relevance vector from another model (MatchVision), but the propagation of its errors and the robustness without W are not quantified.
- Event localization accuracy is not reported: how reliably the correct event is selected within the fixed-length segment (e.g., when multiple events occur) is not evaluated.
- Error propagation from anonymized commentary is unaddressed: Stage I assumes an initial CA from an end-to-end model; the system’s behavior when CA is wrong, incomplete, or temporally misaligned is not studied.
- Limited failure-mode analysis: there is no detailed breakdown of entity-alignment errors (e.g., long-view scenes vs. close-ups, occlusions, similar jersey fonts/colors, substitutes, keeper-specific gear).
- Player identification remains partial: accuracy tops at ~71% even after SFT+GRPO; whether integrating player tracking, re-identification, and number- or face-specific models could push toward human-level (>95%) is not investigated.
- Training–inference mismatch is unclear: fine-tuning reportedly uses only video, query, and ground-truth answer, while inference leverages richer prompts (C_GS, Scene, W); the impact of this mismatch on generalization is not analyzed.
- Generalization across seasons/teams/kits is not validated: the model’s stability when rosters, kit designs, and jersey fonts change season-to-season is not assessed.
- Coverage of event types is incomplete: focus is on goals, corners, and cards; handling of VAR overturns, disallowed goals, injuries, substitutions, tactical formations, and off-camera incidents is not evaluated.
- Missing audio/graphic cues: the system does not exploit ASR from live commentators, crowd audio, or scoreboard/time/score OCR—signals that could significantly improve grounding and context accuracy.
- Temporal coherence at game scale is not modeled: “game-level” evaluation concatenates segment outputs, but no explicit long-horizon memory or planning is trained; consistency across 90-minute narratives (e.g., evolving tactics, storyline callbacks) is untested.
- Knowledge correctness and attribution remain partial: external KAG reaches 81.8% accuracy, but there is no robust verification beyond an LLM “double check,” no calibrated confidence, nor citation/attribution mechanisms to reduce hallucinations.
- External knowledge scope is limited: the KAG schema does not explicitly cover advanced analytics (e.g., xG, shot maps, pressing metrics), and the freshness/update cadence of statistics is not specified.
- Temporal leakage controls are only partially described: while future matches are excluded, a formal audit ensuring no leakage from future statistics or post-processed season summaries is absent.
- Internal context tracker reliability is not stress-tested: correctness during rapid sequences (goals overturned by VAR, back-to-back cards/substitutions, added time) and conflict resolution in state updates are not evaluated.
- Multilingual and cultural style adaptation is not explored: the approach is tested in English; portability to other languages and culturally distinct sportscasting styles is unknown.
- Evaluation metrics underrepresent televised quality: reliance on BLEU/CIDEr and limited anecdotal human MOS lacks rigorous expert panel evaluations, inter-rater reliability, and task-specific rubrics for televised commentary quality.
- Limited human-in-the-loop testing: while a small “Player Guessing” study is performed, there is no large-scale user study with professional commentators assessing utility, edit burden, or trust.
- Interpretability at inference time is unclear: CoT-style “answer-guided reasoning” is used for training, but whether the system produces faithful, inspectable rationales online is not discussed.
- Scalability and cost of deployment are unclear: SFT+GRPO on Video-LMMs and GPT-4o-based Stage II introduce significant compute and API costs; strategies for edge deployment or cost-aware inference are not offered.
- Dataset coverage and biases are not documented: the distribution of events, camera styles, and leagues in MatchTime/SN-Caption-test-align and their impact on generalization are not provided.
- Reproducibility risks due to closed tools: Stage II depends on GPT-4o, and parts of Stage I rely on proprietary baselines; open-source substitutes, full prompts, and code checkpoints are not fully specified for exact replication.
- Ethical and privacy considerations are not addressed: player face recognition in live broadcasts raises consent and compliance questions across jurisdictions; guidelines and mitigations are missing.
- Path to audio sportscasting is unaddressed: the system outputs text; mapping to natural, synchronized speech with prosody, name pronunciation, and co-commentator dynamics is left for future work.
- Cross-sport portability is open: it is unclear which components (entity grounding, KAG, state tracking) transfer to basketball, American football, or tennis and what sport-specific adaptations are needed.
Practical Applications
Below is a concise synthesis of practical applications that flow from the paper’s findings and methods (GameSight: a two-stage, knowledge-enhanced visual reasoning system for entity-aligned, televised-style soccer commentary). Each item indicates the target sector(s), potential tools/workflows, and key dependencies that might affect feasibility.
Immediate Applications
- AI commentator copilot for live production assistance
- Sectors: Media/broadcasting, OTT, software
- What: In-studio “copilot” that surfaces entity-aligned captions, probable player/team mentions, and vetted on-the-fly stats to human commentators/producer UIs.
- Tools/workflows:
- Stage I entity alignment service (API) integrated into broadcast control software (e.g., Vizrt/EVS/OBS plugin)
- Stage II “SoccerKAG” queries with time-aware SQL templates + LLM-based double-check
- Low-latency UI panel for suggested talking points and trend snippets
- Assumptions/dependencies: Access to roster/line-up feeds (substitutions, jersey numbers), adequate video quality for face/jersey cues, rights to use stats DB; human-in-the-loop for final on-air use.
- Automated commentary for lower-tier/long-tail streams
- Sectors: OTT, amateur sports tech, clubs
- What: Fully automated play-by-play+insight tracks for semi-pro/academy matches where human commentary is scarce.
- Tools/workflows:
- End-to-end pipeline: anonymized captions → Stage I alignment → Stage II knowledge insertion → TTS multilingual output
- Assumptions/dependencies: Modest latency tolerance (5–15s), stable team-color detection, minimal camera switching; licensing for TTS and data.
- Second-screen fan companion (mobile/tablet)
- Sectors: Consumer apps, fan engagement, advertising
- What: Real-time, personalized commentary feed with player names, context-aware stats, and explanations synchronized with the live match; supports multiple languages.
- Tools/workflows:
- Client app consumes live entity-aligned text + curated stat nuggets; push notifications for key events
- Assumptions/dependencies: Synchronization with broadcast timing, commercial rights for event data, guardrails to avoid spoilers for DVR users.
- Fast-turnaround highlights with credible captions
- Sectors: Media, social, clubs, creator tools
- What: Auto-generate short clips with player-grounded, knowledge-enhanced captions for social and post-match summaries.
- Tools/workflows:
- Batch Stage I alignment over event timelines → Stage II enrichment templates per event type (goal, card, corner, etc.) → Auto-subtitling/graphic overlays
- Assumptions/dependencies: Accurate event windows; license to publish player likeness/statistics.
- Semi-automatic tagging and labeling for analytics and archives
- Sectors: Sports analytics, MAM/DAM systems
- What: Use entity alignment to pre-label who-did-what-when for analysts and archivists, reducing manual effort.
- Tools/workflows:
- API for player/team assignment on segments; export to existing tagging platforms (Hudl, Wyscout-like tools)
- Assumptions/dependencies: Quality of close/medium shots, camera angle diversity; reviewer acceptance pipeline.
- Accessibility audio tracks (descriptive commentary)
- Sectors: Accessibility/assistive tech, OTT
- What: Generate descriptive, structured, under-50%-description commentary for visually impaired audiences, enriched with clear entity references and relevant stats.
- Tools/workflows:
- Narration templates aligned to regulatory guidelines; TTS with prosody controls
- Assumptions/dependencies: Legal frameworks for AI descriptions; consistency/accuracy guardrails.
- Quality assurance for live text feeds
- Sectors: Data providers, sportsbooks (non-wagering narrative), OTT
- What: Cross-check and correct context-dependent errors (e.g., score, scorer/assister) in live text commentary via internal game context tracking.
- Tools/workflows:
- Stage II internal game context database with event timelines; anomaly detection alerts to editors
- Assumptions/dependencies: Ingest of reliable score/event signals; editorial workflows for overrides.
- Multilingual localization of commentary
- Sectors: Global media, OTT, clubs
- What: Convert aligned/enriched commentary into multiple languages with consistent named entities and stats.
- Tools/workflows:
- Entity-protected MT + TTS; glossary-enforced translation (player/team names)
- Assumptions/dependencies: Name transliteration standards; latency budgets for live operations.
- Sponsor/inventory-aware overlays and ad copy
- Sectors: Advertising technology, broadcast graphics
- What: Trigger brand-safe, contextually relevant graphics or copy (e.g., “Player X’s 10th goal this season”) when confidence is high.
- Tools/workflows:
- Confidence-thresholded events from Stage I + fact-checked stats from Stage II to drive graphics engines
- Assumptions/dependencies: Contracts for real-time brand creatives; strict fact-checking to avoid false claims.
- Research benchmarks and training curriculum for multi-modal reasoning
- Sectors: Academia, AI labs
- What: Use the two-stage design (SFT + GRPO on Video-LMMs with context and knowledge) as a template for studying compositional visual reasoning and temporal grounding in video.
- Tools/workflows:
- Public protocol for instruction tuning with answer-guided CoT; release of anonymized prompts and evaluation scripts
- Assumptions/dependencies: Dataset licenses; reproducible compute environment.
Long-Term Applications
- Fully autonomous top-tier broadcast commentary (primary feed)
- Sectors: Media/broadcasting
- What: Replace or co-anchor live televised commentary with AI providing entity-perfect, culturally nuanced, low-latency narration.
- Tools/workflows:
- Robust Stage I under broadcast conditions (occlusions, crowded frames) + domain-safe knowledge generation; low-latency inference (edge/on-prem GPUs)
- Assumptions/dependencies: Sub-2s end-to-end latency, >99% player alignment across all shots, union/regulatory acceptance, strong safety guardrails; extensive QA.
- Cross-sport generalization (basketball, rugby, hockey, American football)
- Sectors: Media, analytics, software
- What: Extend the two-stage pipeline to other sports with different camera grammars and event ontologies.
- Tools/workflows:
- Sport-specific fine-grained shot taxonomies; new KAG schemas; retraining SFT/GRPO with domain data
- Assumptions/dependencies: Availability of high-quality multi-view footage and reliable stats DBs per sport; new annotation pipelines.
- Edge/on-camera commentary for smart stadiums and consumer cameras
- Sectors: Hardware/IoT, venues, consumer devices
- What: On-device inference generates personalized commentary for in-venue screens or action cams (e.g., youth matches).
- Tools/workflows:
- Compressed Video-LMMs, jersey/face recognition on edge NPUs; intermittent cloud KAG sync
- Assumptions/dependencies: Efficient models, privacy-preserving on-device analytics, constrained lighting/angles.
- Real-time coaching dashboards with narrative explanations
- Sectors: Clubs, performance analytics
- What: Live, entity-grounded narratives explaining tactical patterns, player trends, and context (“X pressed high in last 10 minutes”).
- Tools/workflows:
- Fusion of tracking/minimap with Stage I/II outputs; explanation templates tied to tactical taxonomies
- Assumptions/dependencies: Access to tracking data; validated tactical ontologies; coach acceptance.
- Regulatory/compliance toolkits for AI-generated sports content
- Sectors: Policy, legal, broadcast ops
- What: Tooling that enforces time-aware retrieval (no data leakage), attribution, disclosure, bias checks, and red teaming for hallucinations.
- Tools/workflows:
- “Compliance layer” that rejects future-looking stats, logs sources, and audits outputs
- Assumptions/dependencies: Emerging standards for AI transparency in live media; integration with rights/licensing systems.
- Personalized fan narratives and learning experiences
- Sectors: Education (media literacy), fan engagement
- What: Explain tactics, rules, and player histories at variable depth for different fan profiles (novice vs. expert), potentially as an interactive tutor.
- Tools/workflows:
- Profile-driven prompting; progressive disclosure UX; explain-why chains grounded in KAG
- Assumptions/dependencies: Rich, accurate knowledge graphs; robust personalization safeguards.
- Data marketplace for AI-grade sports knowledge and context feeds
- Sectors: Data providers, platforms
- What: Standardized APIs for “AI-ready” line-ups, substitutions, event ontologies, temporal constraints, and schema-aligned historical stats.
- Tools/workflows:
- Open schema specifications; SLAs for latency and consistency; versioned temporal scopes
- Assumptions/dependencies: Industry adoption; harmonization across leagues and vendors.
- Human-AI co-commentary authoring tools
- Sectors: Media, creator economy
- What: Authoring interfaces where humans sketch narrative arcs, and AI fills entity-accurate details and statistics while enforcing structure (description/explanation/comment balance).
- Tools/workflows:
- Template libraries; real-time conflict detection (e.g., wrong scorer) using internal context tracking
- Assumptions/dependencies: Ergonomic UI design; training for commentators; editorial policies.
- Fairness and inclusivity auditing of sports commentary
- Sectors: Policy, academia, social impact
- What: Tools that analyze AI and human commentary for bias (e.g., unequal attention by gender/ethnicity/role), phrasing disparities, and coverage balance.
- Tools/workflows:
- NLP bias detectors over commentary streams; alignment with ethical guidelines
- Assumptions/dependencies: Access to demographic labels (handled ethically); buy-in from leagues and broadcasters.
- Real-time micro-markets explanation (risk and regulation permitting)
- Sectors: Sports betting, fintech
- What: Provide factual, entity-grounded micro-commentary that explains odds shifts or key events without making predictions.
- Tools/workflows:
- Read-only integration with odds feeds; strict compliance filters; latency-tuned pipelines
- Assumptions/dependencies: Regulatory approval; strict prohibition of prescriptive advice; auditable provenance.
Notes on feasibility and cross-cutting dependencies
- Video quality and camera grammar: Stage I relies on clear close/medium shots, jersey colors/numbers, and occasional faces. Low-res, occlusions, or atypical broadcast styles reduce accuracy.
- Data rights and licensing: External statistics and player identities require licensed access; time-aware query constraints are essential to avoid “future leak.”
- Latency and compute: Live use cases need sub-5s total latency; edge optimization or on-prem GPUs may be necessary for premium feeds.
- Robustness and safety: Guardrails against hallucinations, confidence calibration, and human oversight for critical use.
- Generalization: Retraining and schema redesign are required for other sports or different leagues (jersey fonts, camera placements, women’s leagues, lower divisions).
- Multilingual deployment: Terminology consistency and name transliteration require managed glossaries and locale-specific QA.
Glossary
- Anaphor overlap: A discourse metric measuring how much pronouns and nouns repeat across adjacent sentences, indicating coherence. "Anaphor overlap measures the overlap between nouns and pronouns in adjacent sentences, indicating the semantic continuity within the passage by pointing back to the context."
- ASR transcription: A text transcript produced by Automatic Speech Recognition from audio. "and the whole 90 minutes sportscast's ASR transcription"
- Chain-of-Thought reasoning: A prompting strategy where models explicitly generate step-by-step intermediate reasoning. "to decompose the problem with Chain-of-Thought reasoning."
- Coh-Metrix: A computational toolset for analyzing textual cohesion and coherence. "we adopt human evaluation, sentiment polarity, and the Coh-Metrix~\cite{mcnamara2014automated} in discourse analysis to evaluate the coherence and contextual relevance."
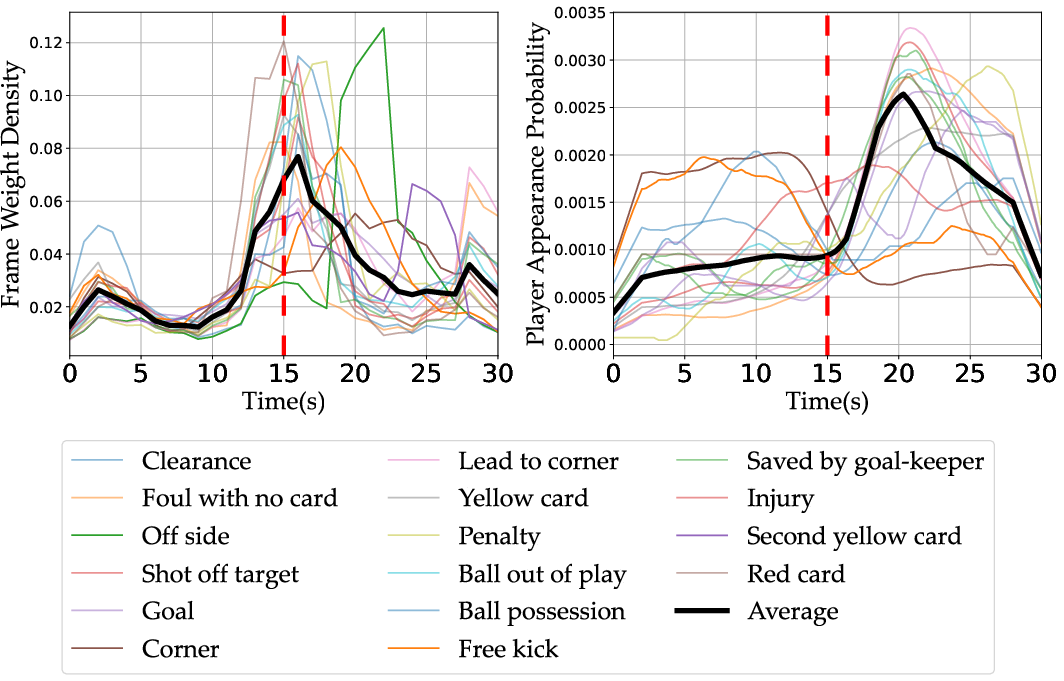
- Cross-attention: An attention mechanism that relates elements across two sequences/modalities (e.g., text and video frames). "from the Q-former's cross-attention layers of MatchVision to represent the relevance of each video frame to the generated narration"
- Domain adaptation (of VLMs): Adapting a general vision-LLM to perform well in a specific domain (e.g., soccer). "The domain adaptation of VLM \cite{jiang2025domainadaptationvlmsoccer} excels in understanding soccer concept in 2-second video clips, but it lacks the contextual reasoning capabilities for game-level entity-aligned commentary generation."
- Entity alignment: Linking anonymized mentions in text to specific real-world entities (e.g., players/teams) in video. "to conduct entity alignment and knowledge enhancement for commentary."
- Entity grounding: Tying textual entity mentions to concrete visual evidence in the video. "Absence of entity grounding."
- Event grounding: Linking textual descriptions of events to the correct temporal/video segments. "which serves as a frame-level event grounding guidance."
- Game state reconstruction: Reconstructing the evolving state of a match (players, ball, context) from video. "and game state reconstruction have achieved significant progress."
- Group Relative Policy Optimization (GRPO): A reinforcement learning optimization method that uses group-relative rewards to improve reasoning/policy quality. "group relative policy optimization (GRPO)"
- Jersey number recognition: Detecting and recognizing player numbers on jerseys to identify players. "jersey number recognition~\cite{Cioppa2022Scaling,balaji_jersey_2023}"
- Knowledge-Augmented Generation (KAG): A generation approach that injects structured factual knowledge into the model’s outputs. "Knowledge-Augmented Generation (KAG) uses explicitly structured and factual knowledge to inform responses."
- Knowledge triples: Structured facts represented as subject–predicate–object used for knowledge-based generation or reasoning. "Goal~\cite{qi_goal_2023} generates commentary with knowledge triples."
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning method that injects low-rank adapters into pretrained models. "LoRA~\cite{hu2021loralowrankadaptationlarge} is adopted with a rank of 8."
- Mean Opinion Score (MOS): A human-rated subjective quality score averaged across raters. "The MOS test also shows that audience prefers our commentary than the original live text version."
- Optical character recognition: Automatically extracting machine-readable text from images or video frames. "zero-shot video understanding, video grounding, optical character recognition, and event captioning with timestamps."
- Play-break segmentation: Dividing sports videos into segments of active play versus breaks for downstream analysis. "play-break segmentation~\cite{tjondronegoro2003sports}."
- Q-former: A query-focused transformer module used to extract relevant visual features conditioned on queries. "from the Q-former's cross-attention layers of MatchVision to represent the relevance of each video frame to the generated narration"
- Retrieval-Augmented Generation (RAG): Enhancing generation by retrieving external text passages during inference. "Unlike the Retrieval-Augmented Generation (RAG) using retrieval-based models to retrieval information from large text corpus,"
- Reward alignment: Adjusting model behavior to optimize against a defined reward signal, often in RL-based fine-tuning. "and reward alignment in this single choice problem."
- Self-asking mechanism: A prompting tactic where the model generates and answers its own sub-questions to improve reasoning. "Additionally, we employ a self-asking mechanism~\cite{press2022measuring} to generate constrained questions grounded in the extracted knowledge."
- Shot boundary detection: Automatically detecting transitions between shots/camera cuts in video. "Shot boundary detection with view classification"
- Spatiotemporal visual encoder: A neural encoder that models both spatial (frame) and temporal (sequence) information in video. "a pretrained spatiotemporal visual encoder."
- Supervised fine-tuning (SFT): Training a pretrained model on labeled data to specialize it for a target task. "trained with supervised fine-tuning~(SFT) and group relative policy optimization~(GRPO)"
- Team affiliation detection: Determining which team a player belongs to in the analyzed footage. "Team affiliation detection."
- Temporal team line-up: A time-varying roster indicating which players are on the field at different moments. "It mainly includes the temporal team line-up , timeline, and timeline."
- Video grounding: Localizing where textual entities/events occur within a video. "zero-shot video understanding, video grounding, optical character recognition, and event captioning with timestamps."
- Video-LMMs: Video Large Multi-Modal Models that process both video and text for understanding and generation. "Video large multi-modal models (Video-LMMs)~\cite{li2023videochat, wang2025vcass} have shown remarkable performance in zero-shot video understanding, video grounding, optical character recognition, and event captioning with timestamps."
Collections
Sign up for free to add this paper to one or more collections.