- The paper introduces a novel multimodal LLM framework with a text-guided memory pyramid to capture both spatial details and long-range temporal context in surgical video QA.
- It uses curriculum-style Surgical Competency Progression training and achieves superior performance across perception, assessment, and reasoning tasks in cholecystectomy.
- Quantitative and ablation analyses demonstrate that leveraging temporal memory and cross-modal attention significantly enhances clinical assessment and safety verification.
SurgTEMP: Temporal-Aware Surgical Video Question Answering with Text-Guided Visual Memory
Motivation and Challenges in Surgical Video QA
The complexity and risk in laparoscopic cholecystectomy demand expert-level intraoperative interpretation and assessment. Surgical video QA systems have the potential to satisfy both educational and real-time support needs, yet most prior approaches are constrained to static image-based VQA, with limited temporal modeling. This neglects critical temporal semantics essential for procedure-specific assessments, such as Critical View of Safety (CVS) achievement, adverse event detection, and skill evaluation. Additionally, the domain exhibits low visual contrast, hierarchical task dependencies, and requires variable spatiotemporal granularity. These challenges necessitate novel multimodal LLM-based approaches capable of dynamic temporal understanding and domain-specific reasoning.
Architecture of SurgTEMP and Text-Guided Memory Pyramid
SurgTEMP introduces a multimodal LLM framework integrating a domain-adaptive Text-Guided Memory Pyramid (TEMP) module. The core pipeline uses SigLIP-based visual encoding, a multi-modal projector, spatial pooling, and Qwen2-7B as the language backend. The TEMP module leverages cross-modal attention to guide hierarchical memory formation—selecting spatially relevant patches and temporally salient frames based on the textual query, efficiently constructing both spatial and temporal memory banks.
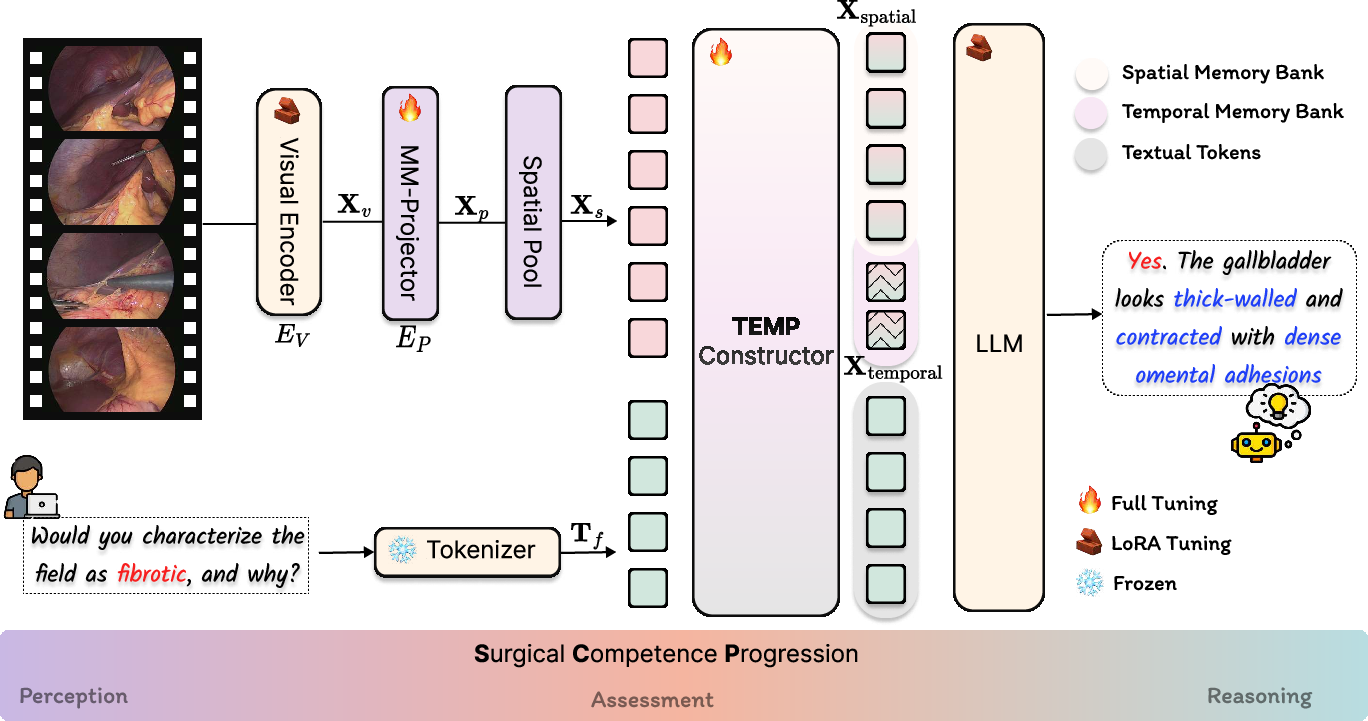
Figure 1: SurgTEMP architecture highlighting multimodal feature extraction and hierarchical memory bank integration for video QA.
TEMP computation includes multi-level text-visual attention maps, Gumbel-Softmax-based differentiable frame selection, patch-level reweighting, and insertion of learnable separator tokens to encode structural boundaries. This design enables explicit modeling of both fine-grained operative details and long-range procedural context, crucial for clinical assessments across variable-length videos.
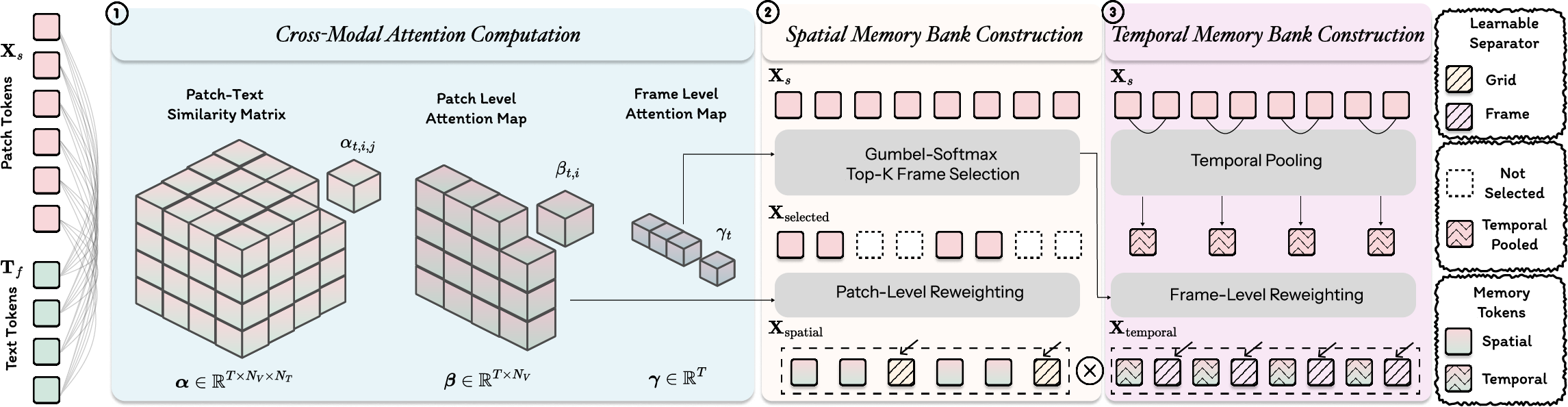
Figure 2: TEMP module processing steps: cross-modal attention, spatial memory bank construction, temporal memory bank formation.
CholeVidQA-32K Dataset and Curation
SurgTEMP is trained and evaluated on the CholeVidQA-32K dataset, which comprises 32K open-ended QA pairs and 3,855 video segments (~128 hours), segmented from CholecT50, Endoscapes, and CholeScore sources. The dataset is designed to capture the hierarchical progression of surgical competencies with three levels—Perception (tool, action, anatomy), Assessment (CVS, difficulty, adverse events, skills), and Reasoning (scene description, rationale, planning).
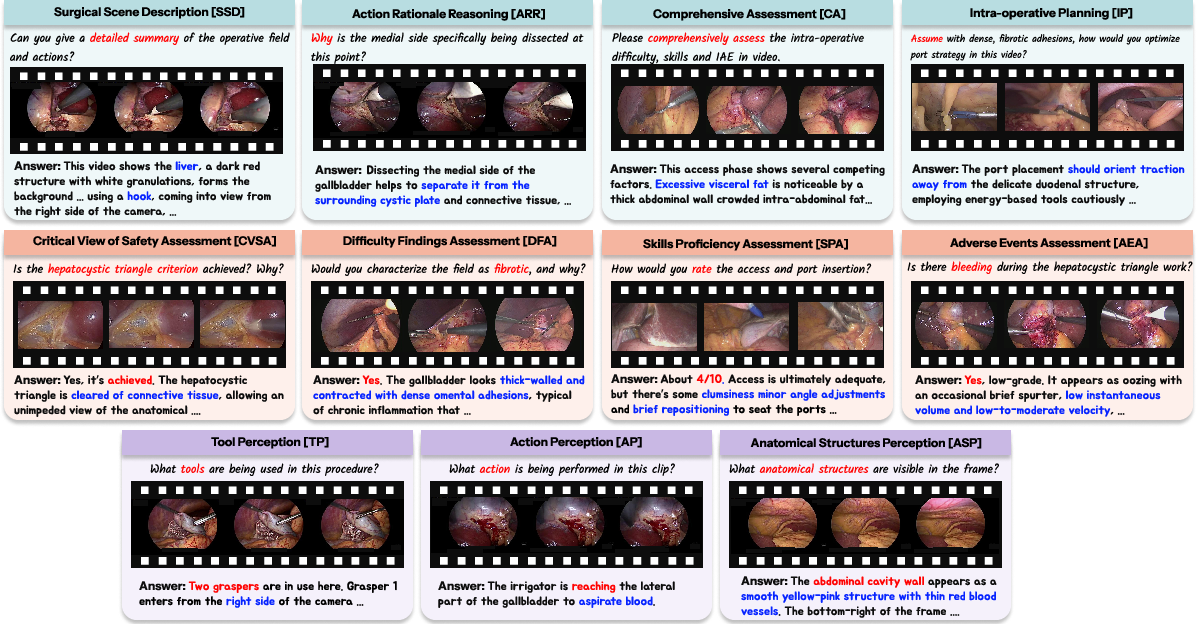
Figure 3: CholeVidQA-32K hierarchy showing 11 tasks mapped to Perception, Assessment, and Reasoning cognitive levels.
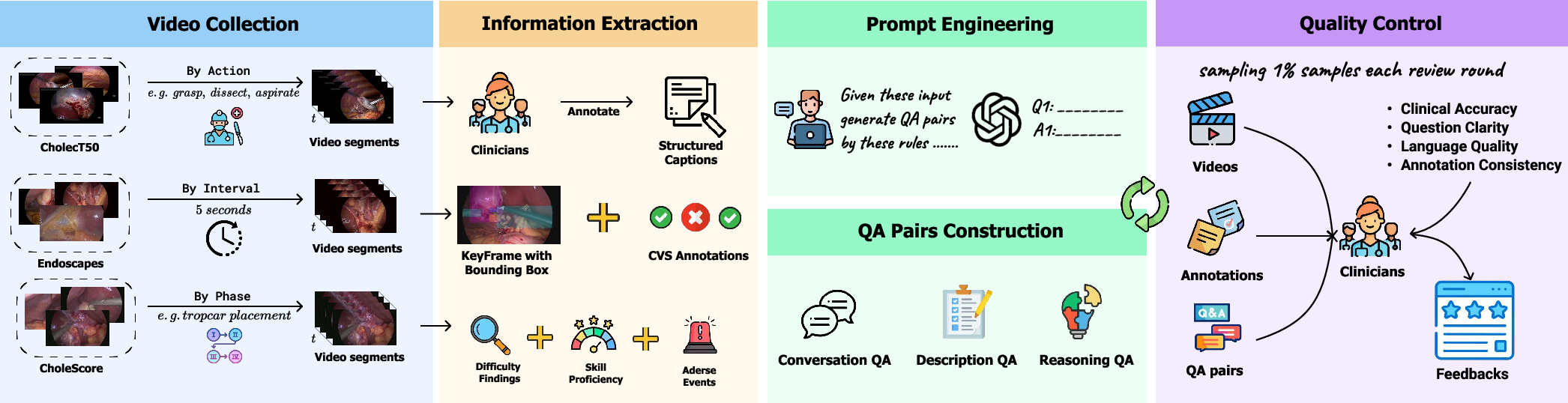
Figure 4: Dataset curation pipeline integrating expert annotation, prompt engineering, and stratified review for quality assurance.
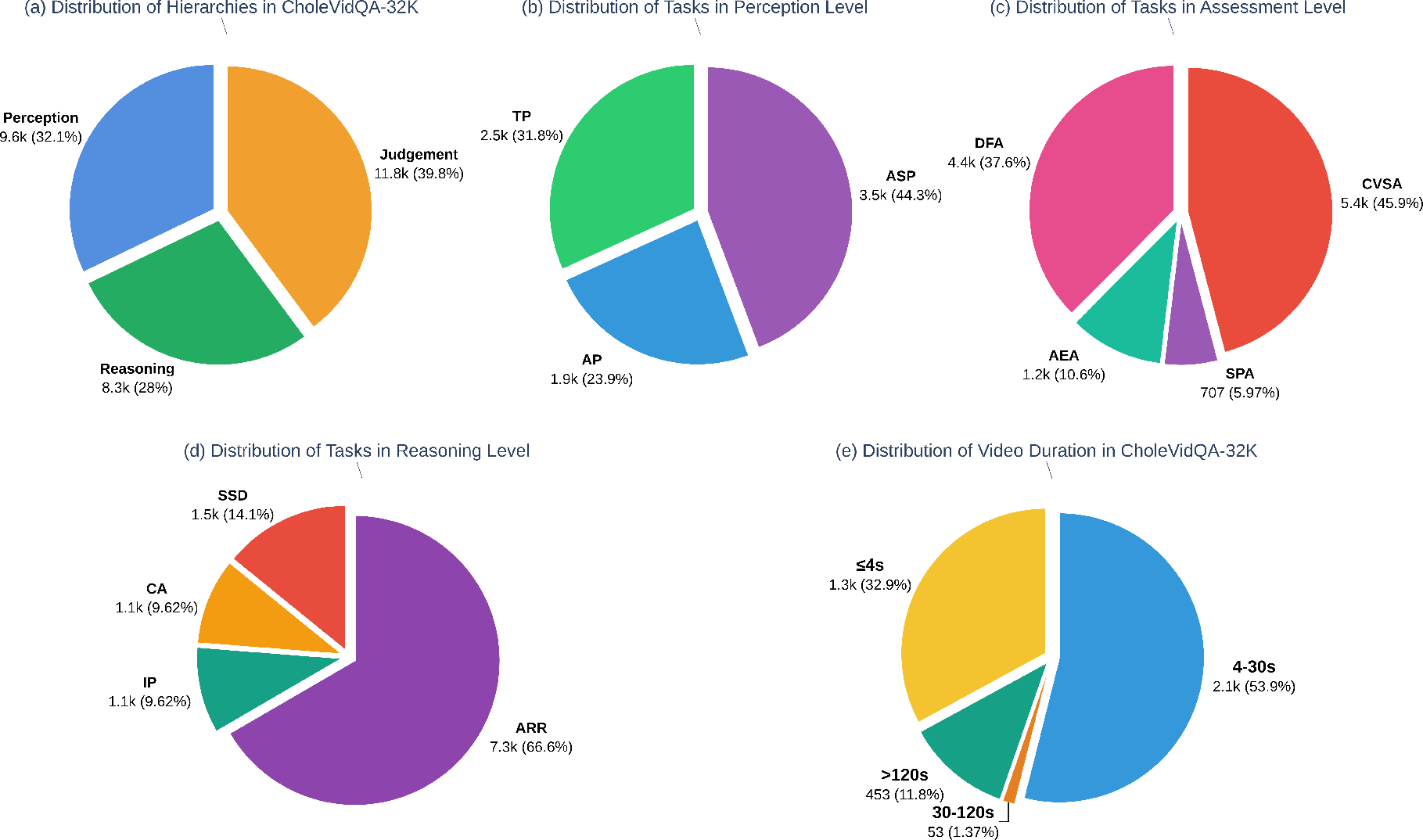
Figure 5: CholeVidQA-32K composition and task distribution across hierarchy and temporal duration.
Surgical Competency Progression Training and Baseline Comparison
The Surgical Competency Progression (SCP) scheme implements curriculum-style, stage-wise training by sequentially exposing the model to perception, assessment, and reasoning tasks. Progressive sampling ensures foundational skills are maintained in later stages. Baseline comparisons include both zero-shot (mPLUG-Owl3, InternVideo2.5, LongVA, LLaVA-Video, VideoGPT+) and fine-tuned models (LLaVA-Video-ft, VideoGPT+-ft).
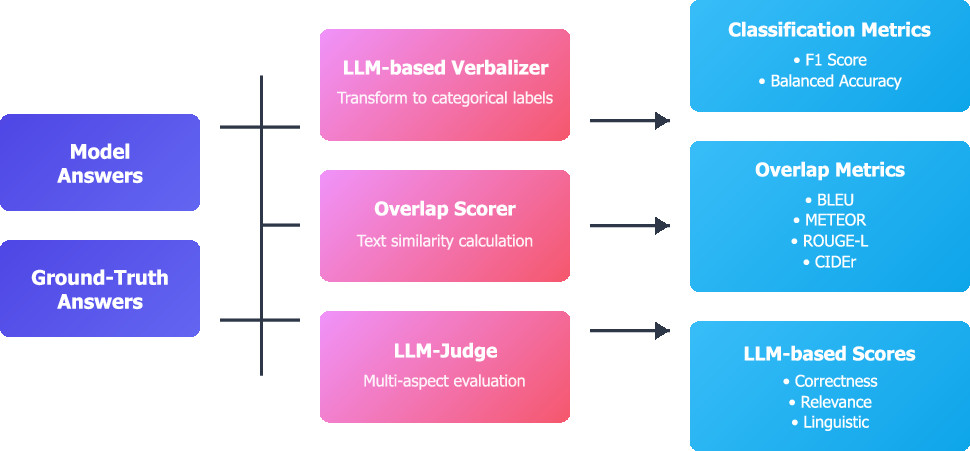
Figure 6: Evaluation pipeline incorporates categorical metrics, overlap metrics, and LLM-based multidimensional scores.
Quantitative Results and Ablation Analysis
SurgTEMP exhibits dominant performance across metrics: balanced accuracy, F1, BLEU, METEOR, ROUGE-L, CIDEr, and GPT-judge correctness, relevance, and linguistic quality—consistently outperforming zero-shot and fine-tuned baselines, particularly on assessment and reasoning tasks requiring long-range context and domain-specific understanding.
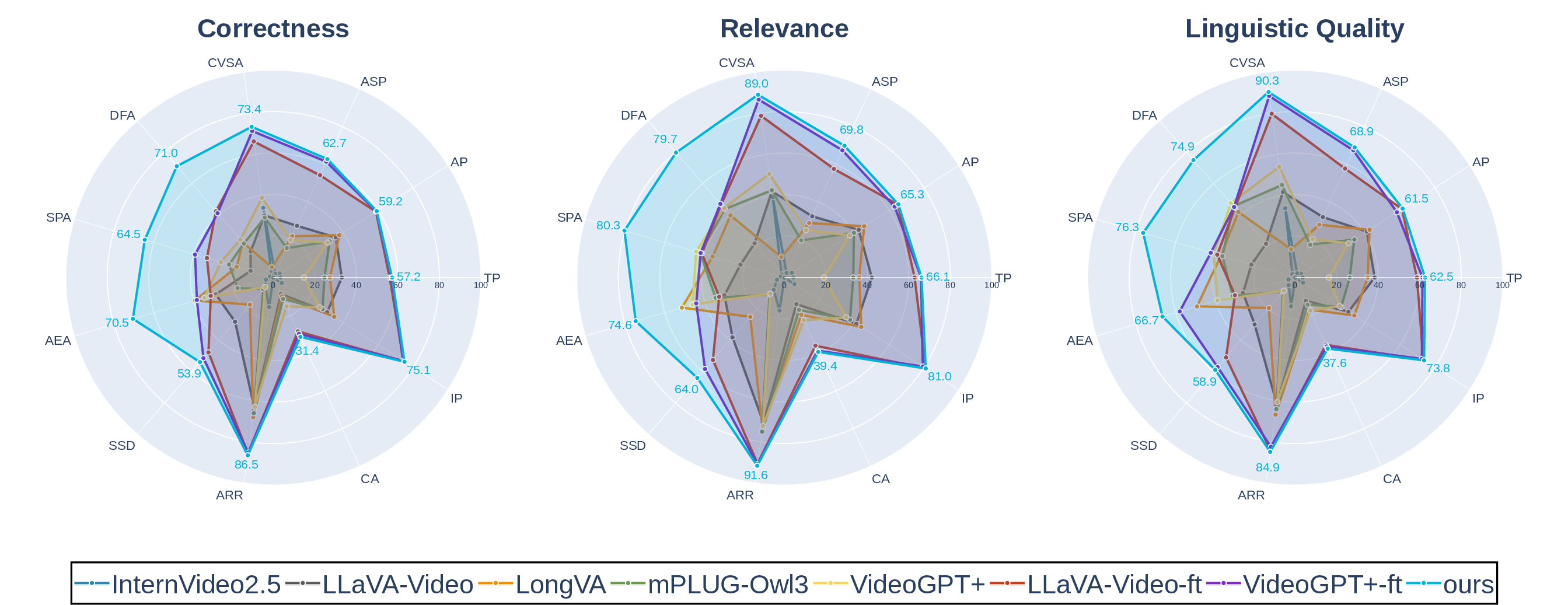
Figure 7: Radar chart of model performance on task hierarchies, demonstrating balanced excellence and high scores across Perception, Assessment, and Reasoning.
Ablation studies indicate substantial drops in correctness, relevance, and linguistic quality when disabling temporal memory bank, text-guided attention selection, learnable separators, and SCP, underscoring the necessity of hierarchical, text-driven visual memory and progressive training.
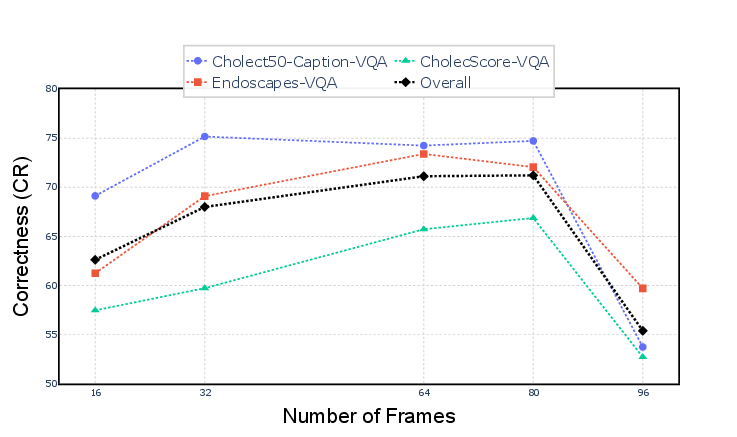
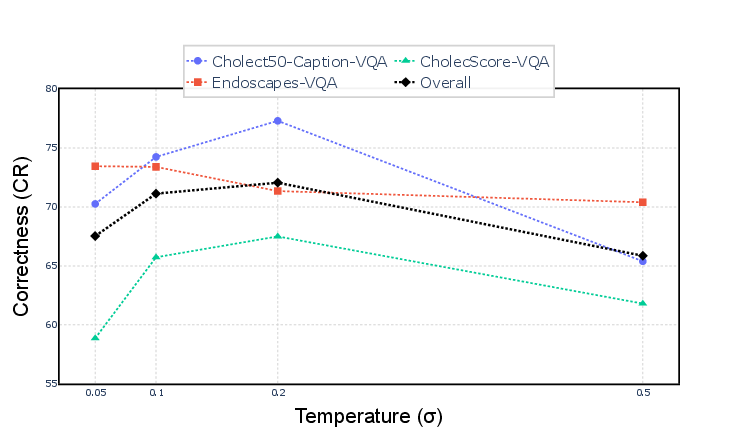
Figure 8: Frame sampling sensitivity: performance saturates around 64 frames, with further increases causing degradation due to token selection saturation.
Frame Selection Visualization and Qualitative Analysis
SurgTEMP's frame selection mechanism consistently identifies clinically informative segments, optimizing attention to safety-relevant events, while avoiding irrelevant out-of-body frames. Visualization corroborates alignment with expert-identified frames, supporting precise clinical assessments.
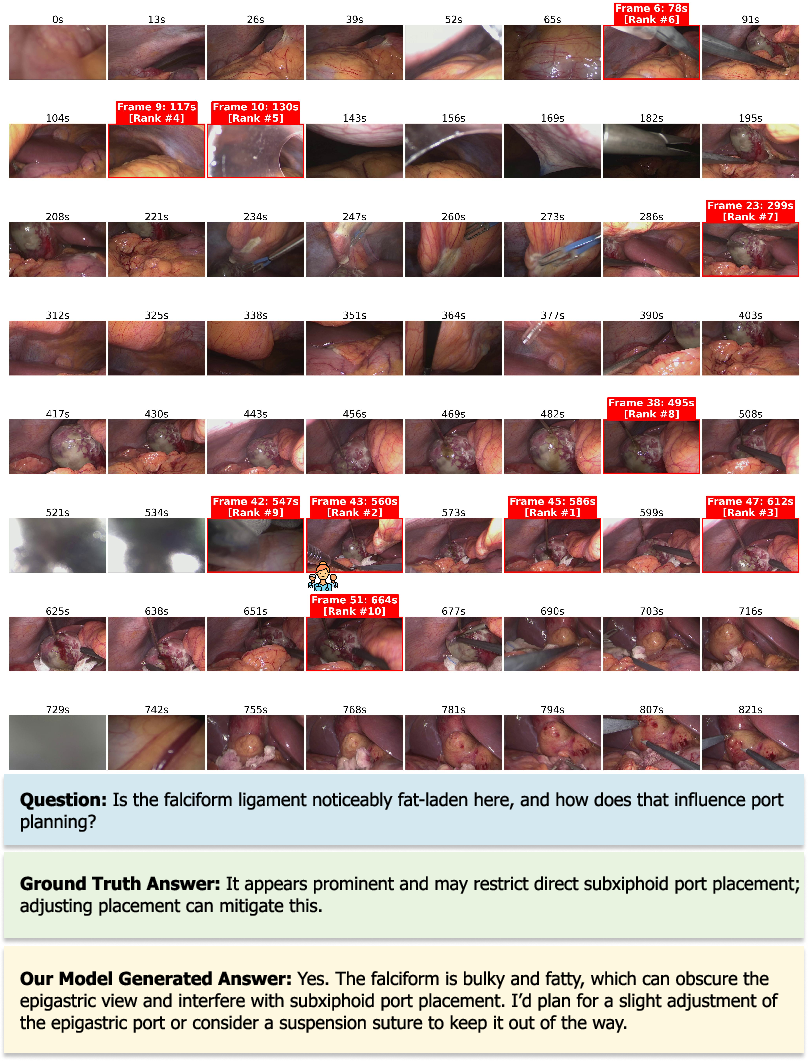
Figure 9: TEMP module frame selection—informative frames highlighted, aligning with clinical expert choices and facilitating precise reasoning.
Qualitative comparison of model outputs demonstrates that SurgTEMP generates contextually and clinically appropriate responses, excelling in perception, assessment (CVS, difficulty, adverse events, skills), and reasoning (scene description, rationale, planning) over baseline architectures.
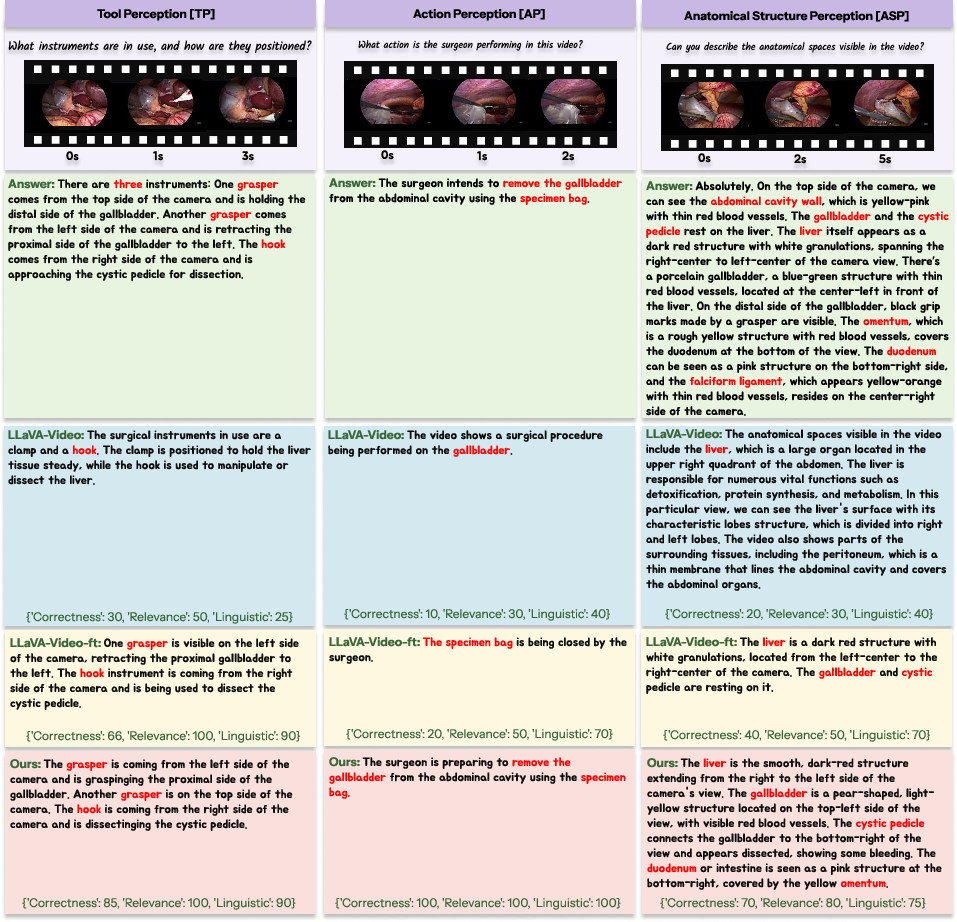
Figure 10: SurgTEMP achieves clinically grounded answer generation for perception-level tasks compared to baseline models.

Figure 11: SurgTEMP outperforms baselines in assessment-level tasks—accurate, context-aware clinical responses.

Figure 12: SurgTEMP demonstrates comprehensive, detailed reasoning on surgical scenarios with temporal coherence.
Practical and Theoretical Implications
SurgTEMP addresses domain-specific visual interpretation, temporal granularity, and hierarchical dependencies, providing a robust foundation for intraoperative QA and educational applications. The text-guided memory architecture enables adaptive reasoning about rare, subtle, or visually ambiguous events. The scalability of the TEMP module facilitates integration with longer and more complex surgical procedures, suggesting potential for broad cross-procedural generalization and AI-driven decision support.
Abstention and uncertainty estimation are not yet implemented; advancing these directions is essential for clinical deployment. Extension to more diverse surgical domains will further validate generalization capabilities.
Conclusion
SurgTEMP delivers a state-of-the-art solution for temporal-aware surgical video question answering, leveraging text-guided hierarchical memory and progressive training on a clinically rich dataset. Empirical results show superior performance on assessment and reasoning tasks, emphasizing the necessity for specialized architecture in safety-critical surgical QA. Future work should prioritize cross-procedural adaptation, uncertainty quantification, and real-time deployment in clinical practice.