- The paper presents SFI, a method where LLMs generate structured, machine-verifiable reasoning steps to ensure logical soundness.
- It demonstrates that SFI achieves high answer accuracy while markedly improving reasoning reliability compared to outcome-only approaches.
- Empirical evaluations on benchmarks like ProverQA show that SFI enhances generalization and robustness in step-by-step logical reasoning.
LLMs exhibit strong performance on multi-step logical reasoning tasks, particularly when outcome-based rewards are leveraged during reinforcement learning. Conventional RL fine-tuning strategies provide supervision at the level of final answer correctness but systematically fail to enforce the reliability and logical soundness of intermediate reasoning steps. This discrepancy leads to models that can produce correct answers with flawed or invalid reasoning chains, which is problematic in mathematical and safety-critical reasoning domains.
The paper introduces a methodology—Structured Formal Intermediaries (SFI)—where LLMs generate stepwise structured reasoning aligned with natural language explanations. Each reasoning step is represented in a machine-verifiable intermediate format (e.g., JSON/YAML), and subsequently, a formal prover verifies each step. Only complete chains that pass all verifications receive maximal reward, enforcing reliability at a granular level.
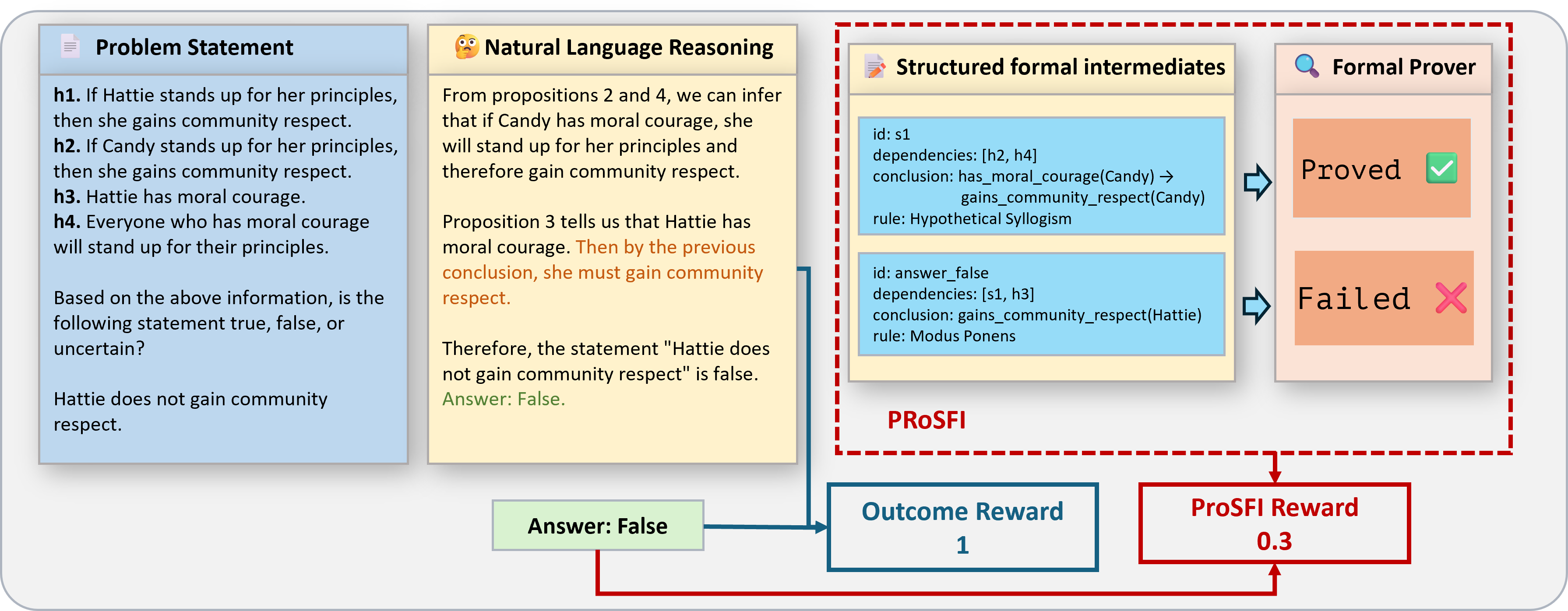
Figure 1: Pipeline of SFI, contrasting stepwise formal verification with traditional outcome reward; even correct answers can be penalized for flawed intermediate logic.
Methodological Framework
Rather than prompting LLMs to emit full formal proofs (e.g., Lean 4 scripts), which remains impractical for models below 7B in scale, SFI proposes a lightweight structured format for intermediate steps:
- Each step is atomic, encodes dependencies, formal conclusion, and the logical rule applied (e.g., Modus Ponens, Hypothetical Syllogism).
- Steps are machine-parsable and serve as sub-problems for formal verification.
- This decouples LLM generation from full proof construction, minimizing the structural misalignment observed in direct formal output.
Reward Construction
The reward function for RL post-training is accordingly nuanced:
- R=1.0: Answer correct, all steps verified.
- R=0.3: Answer correct, but some steps failed verification.
- R=0.1: Format correct, but answer incorrect.
- R=0.0: Format incorrect or other failures.
This fine-grained reward mechanism exploits the capability of formal provers to supply stepwise supervision and aligns model behavior toward credibly structured reasoning chains.
Empirical Evaluations
Experiments are conducted on ProverQA, a synthetic first-order logic benchmark with ground-truth stepwise reasoning annotations. The Qwen2.5-7B-Instruct serves as the base architecture, trained with the GRPO RL framework under various supervision protocols.
Attempts to prompt direct Lean 4 code from 7B LLMs fail, with extremely low rewards and brittle, unstructured proofs. Compilation success does not translate to reliable reasoning trace alignment, indicating the necessity of intermediate scaffolding provided by SFI.
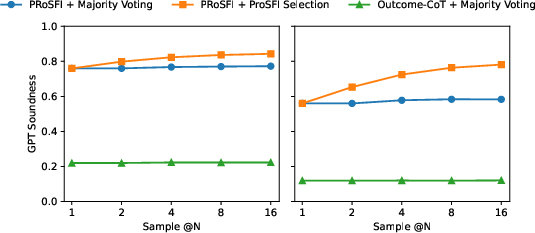
Test-Time Scaling and Robustness
SFI is compatible with test-time scaling protocols like Don't Trust; Verify (DTV), allowing for batch sampling of multiple paths and selection via formal verification. This mechanism is absent in outcome-only protocols where answer voting cannot filter unsound reasoning.
Metric Correlation and Reliability
Correlation analysis demonstrates that SFI reward hits align more closely with reasoning soundness than answer correctness alone, validating the efficacy of the stepwise verification reward model.
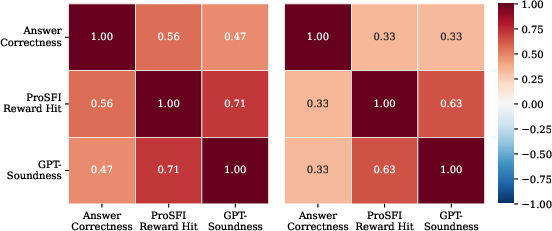
Figure 3: Strong correlation between SFI Reward Hit and GPT Soundness, illustrating the utility of formal step validation versus mere answer accuracy.
Logical Reasoning Generalization
Extensive tests on the Knights and Knaves dataset further show that SFI-based RL consistently improves logical consistency across varying difficulty levels, with OOD robustness for large problem sizes (up to 8 characters).
Analysis of Reasoning Path Soundness
Outcome-CoT confusion analyses highlight the problem: a considerable proportion of correct answers are underpinned by unsound intermediate reasoning steps, reinforcing the inadequacy of answer-level supervision.
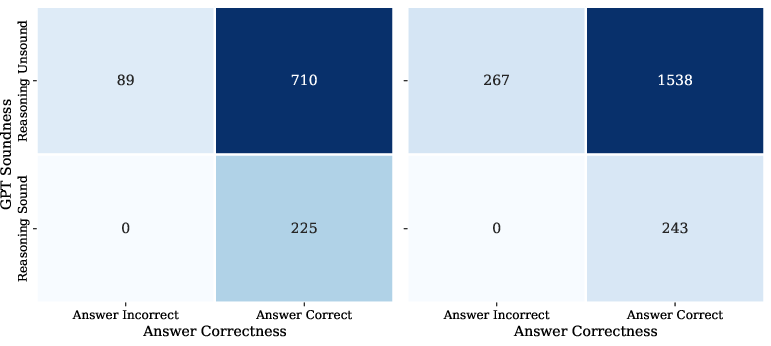
Figure 4: Confusion matrix for Outcome-CoT reveals frequent misalignment between answer correctness and reasoning soundness; sound reasoning is not guaranteed by correct final answers.
SFI addresses these pitfalls, ensuring that verified, atomic logic is enforced throughout the reasoning chain. Typical failure modes in outcome-only setups include semantic confusion and commonsense shortcuts, both systematically mitigated by structured formal intermediaries.
Practical and Theoretical Implications
The proposed paradigm represents a practical shift from outcome-centric evaluations toward reasoning chain reliability. SFI's modular framework bridges natural language reasoning with formal logic, enabling:
- Efficient RL for modest-sized LLMs utilizing stepwise formal feedback.
- Facilitation of robust test-time scaling and improved faithfulness.
- Generalization across domains (e.g., mathematical, algorithmic puzzles).
- Integration with more advanced verification tools and domain-specific formal models.
Theoretically, enforcing machine-verifiable intermediates offers a path to scalable reliable AI reasoning, reducing the reliance on expensive human annotation and circumventing the computational bottlenecks of full formal proof generation in resource-constrained settings.
Future Directions
- Extension of SFI to broader forms of reasoning, including general NLP and complex theorem proving, necessitating richer formal datasets and stronger base models.
- Adoption of more granular reward structures for RL to further enhance credit assignment and learning stability.
- Deep integration with evolving formal automated reasoning tools (e.g., DeepSeek-Prover, Z3, Isabelle) to increase coverage and rigor.
Conclusion
SFI introduces a reinforcement learning framework that leverages structured intermediate representations for step-level formal verification, enforcing logical soundness in LLM-generated reasoning chains without sacrificing final answer accuracy. Empirical results across multiple datasets underscore its ability to deliver credible, machine-verifiable reasoning that generalizes robustly, representing a significant advance in trustworthy logical reasoning with LLMs.