- The paper systematically benchmarks and develops open-source MT systems for Esperanto, comparing rule-based, encoder-decoder, and LLM methodologies.
- It demonstrates that multilingual encoder-decoder models, such as NLLB-200-3.3B, achieve state-of-the-art performance while compact models offer efficient trade-offs.
- The study reveals translation asymmetry favoring high-resource languages and validates neural metrics that align well with human evaluations.
Open Machine Translation for Esperanto: A Systematic Evaluation of Open Models
Overview and Motivation
The paper "Open Machine Translation for Esperanto" (2603.29345) systematically benchmarks and develops open-source Machine Translation (MT) systems for Esperanto—a highly regular constructed language with significant web presence but limited specialized NLP tooling. The work rigorously evaluates rule-based, encoder–decoder, and LLM-based paradigms for bidirectional translation among English, Spanish, Catalan, and Esperanto. The study also presents new compact models, offers in-depth analyses via automatic and human metrics, and releases all code and best-performing checkpoints to foster reproducibility and grassroots technical sovereignty. The findings have broader implications for MT in low-resource and constructed languages, as well as for the evaluation protocols guiding the rapid evolution of LLMs and neural evaluation metrics.
Context: Esperanto in MT and NLP
Esperanto, established in 1887, stands apart as the most successful a posteriori conlang, characterized by strict morphological regularity and a globally distributed speaker community. Despite substantial digital resources—including Wikipedia and inclusion in large-scale pretraining corpora such as MADLAD-400 and HPLT—it remains under-served by dedicated MT tools and evaluation frameworks. The paper identifies the lack of systematic evaluation benchmarks and advanced open-source MT systems for Esperanto, contrasting with the commercial platforms that are expressly excluded from consideration.
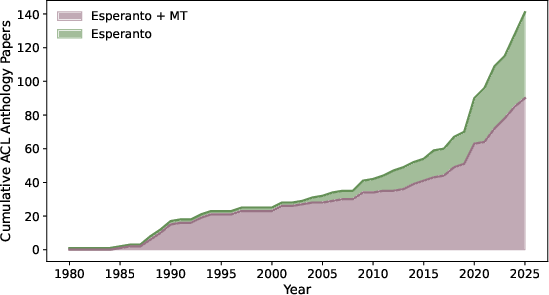
Figure 1: The cumulative number of ACL Anthology papers mentioning "Esperanto" and "Esperanto and Machine Translation," highlighting the historical evolution from MT-centric attention toward a more diverse computational linguistics engagement.
A historical survey of ACL Anthology reveals that early computational works overwhelmingly focused on MT for Esperanto, while more recent decades have shifted toward broader NLP tasks as MT paradigms matured and NLU increased in prominence.
Experimental Protocol
The evaluation spans six translation directions among English, Spanish, Catalan, and Esperanto. Models assessed include:
- Rule-Based MT: Apertium, with limited coverage.
- Multilingual encoder–decoder Transformers: Several NLLB family models up to 3.3B parameters, including both distilled variants.
- General-Purpose and MT-Tuned LLMs: Llama-3.1-8B-Instruct, Unbabel’s TowerInstruct and Tower-Plus.
- Custom Compact Transformers: Bilingual Marian Transformer-base (60M) and Transformer-tiny (17M).
All models are benchmarked out-of-the-box and/or after fine-tuning. The FLORES+ benchmark provides a standardized, multilingual test set for evaluation. Training data is sourced from a rigorously filtered aggregate of OPUS parallel corpora, and model-specific tokenization strategies (SentencePiece, Llama vocab) are employed to avoid resource imbalance.
Main Results
Model Comparison and Metrics
Across translation directions, the NLLB-200-3.3B sets the strongest baseline, achieving state-of-the-art ChrF++ scores and outperforming all general-purpose and MT-specialized LLMs. The distilled 1.3B model matches or slightly surpasses larger non-distilled NLLBs in some configurations, demonstrating the effectiveness of parameter- and memory-efficient distillation. Notably, MT-tuned LLMs such as TowerInstruct-7B-v0.2 demonstrate major performance degradation, frequently failing to maintain language control and producing malformed or code-switched outputs. In contrast, Llama-3.1-8B-Instruct—despite zero-shot application—remains robust and competitive with fine-tuned variants.
Experimental results further demonstrate that compact, task-specific architectures (Marian Transformer-base) meet or exceed the translation quality of fine-tuned Llama-3.1-8B-Instruct-FT in several directions while requiring two orders of magnitude fewer parameters and resources.
Translation Directionality Effects
Performance is asymmetrical: translation from Esperanto into high-resource languages consistently outperforms translation into Esperanto. This is attributed to greater training data density and richer representations for English, Spanish, and Catalan.
Human Evaluation and Metric Correlation
A targeted human evaluation focused on the Spanish–Esperanto pair confirms automatic metrics, with NLLB consistently preferred by annotators. A qualitative error analysis reveals that the principal failure modes differ: compact Transformers tend toward literal, sometimes brittle, translations; Llama-based outputs are fluent but susceptible to omissions, hallucinations, or subject misassignment. NLLB produces fluent translations, but its regular handling of Esperanto morphology sometimes yields excessively compositional or literal forms.
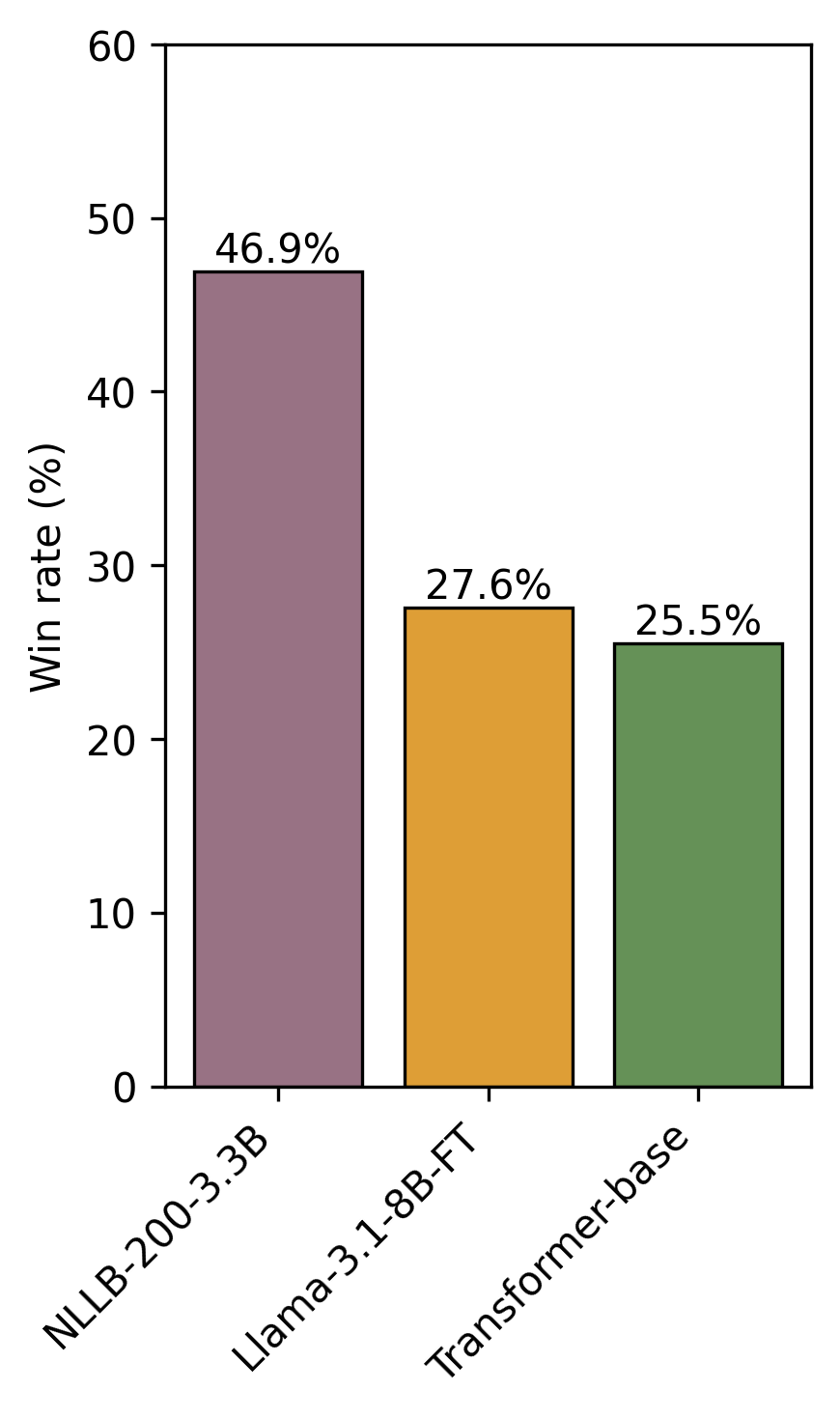
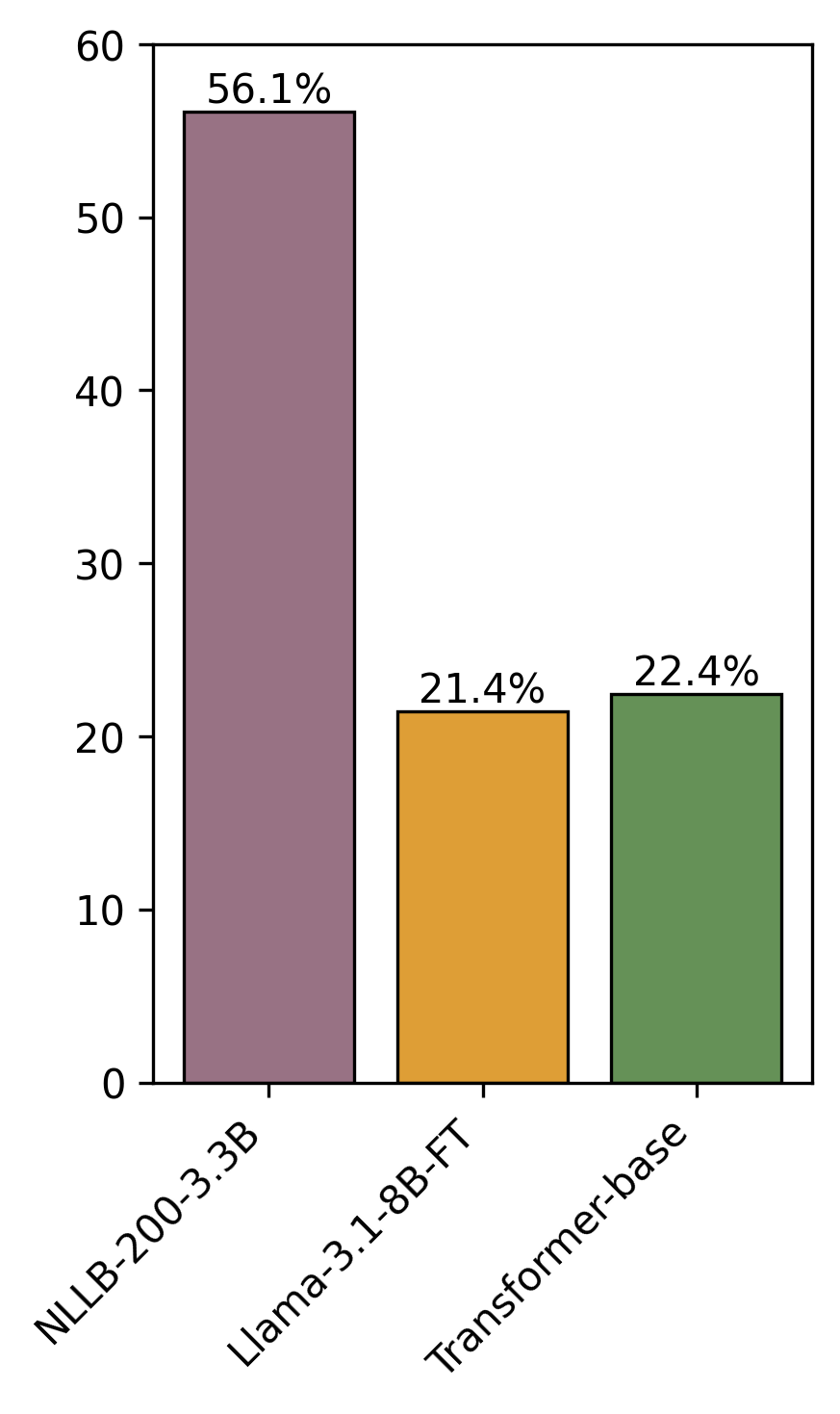
Figure 3: Human evaluation win rates for the Spanish → Esperanto translation direction illustrate the dominance of NLLB models, with both Llama and Transformer architectures trailing.
Correlation analyses show that learned neural metrics (COMET, MetricX) align substantially better with human judgments (Kendall’s τ up to 0.42) compared to n-gram overlap metrics (BLEU, ChrF++), even though these models have not been directly fine-tuned on Esperanto. This generalization reflects the effective cross-lingual transfer properties of the underlying pretraining frameworks (mT5, XLM-R).
Broader Implications
This systematic evaluation yields several significant implications:
- Multilingual encoder–decoders (NLLB) remain the de facto gold standard for low-resource MT, even as LLM-centric workflows become prevalent in NLP. The results confirm the findings from studies in other low-resource scenarios [de-gibert-etal-2025-scaling, tapo-etal-2025-bayelemabaga, scalvini-etal-2025-rethinking].
- General instruction-tuned LLMs offer greater robustness for translation involving non-focal languages than some translation-specialized LLMs whose fine-tuning regimes may induce catastrophic forgetting on non-target languages.
- Strong translation quality is achievable with sub-100M parameter models, emphasizing the ongoing utility of lightweight, efficiently deployable architectures for language communities lacking substantial compute infrastructure.
- Neural metrics offer reliable zero-shot human-correlated evaluation in language pairs with limited reference data, potentially guiding best practices for future evaluation of conlangs and typologically diverse languages.
Going forward, the study prompts investigation into whether conlang properties (morphological regularity, compositional transparency) intrinsically reduce translation difficulty, and it encourages exploration of Esperanto as an interlingua in pivot-based or hybrid (RBMT+NMT) systems. The public release of code and models directly addresses the need for reproducibility and technical sovereignty for smaller language communities.
Conclusion
"Open Machine Translation for Esperanto" (2603.29345) establishes rigorous baselines and methodological recommendations for open-source MT involving Esperanto, demonstrating that modern multilingual encoder–decoder systems decisively outperform both LLM-based and rule-based approaches. Compact, bespoke models offer a strong trade-off in efficiency and quality. The open release of code and models, combined with thorough evaluation protocols, provides essential infrastructure for future multilingual NLP research—particularly for low-resource and constructed languages. Further directions include evaluating the relative modelability of conlangs, leveraging Esperanto as a pivot in multilingual architectures, and integrating rule-based and neural paradigms for enhanced performance and debuggability.