- The paper introduces front-layer fine-tuning of CLIP using specialized contrastive losses for both presence-based and absence-based negation, yielding significant performance improvements.
- The paper achieves up to 52.65% accuracy improvement on presence-based negation tasks while maintaining strong retrieval performance in general vision-language benchmarks.
- The paper demonstrates that optimizing only the initial transformer layers enhances fine-grained syntactic modeling and negation understanding without compromising overall semantic alignment.
Omni-NegCLIP: Front-Layer Contrastive Fine-Tuning for Comprehensive Negation in Vision-LLMs
Motivation and Background
Vision-LLMs (VLMs), particularly CLIP, have become foundational in multimodal AI due to their robust image-text alignment via contrastive learning. Despite these strengths, recent evidence demonstrates that CLIP exhibits substantial failure modes regarding the understanding of linguistic negation, particularly for sentences containing "no," "not," or "without" [singh2024learn]. Negation is structurally critical for natural language semantics, and CLIP's insensitivity undermines commonsense reasoning, robustness, and downstream utility in tasks such as retrieval and T2I generation. Previous approaches, including CoN-CLIP and NegationCLIP, target only single types of negation tasks and show poor performance when generalized to complementary negation forms.
Omni-NegCLIP addresses the lack of comprehensive negation understanding by formally defining and tackling two critical forms:
- Presence-Based Negation: Negation of entities actually present in the image (e.g., an image of a cat, caption: "a cat", negated: "not a cat").
- Absence-Based Negation: Negation involving plausible but absent entities (e.g., an image without a dog, caption: "a cat", negated: "no dog").
Illustrative examples from CC-Neg and NegRefCOCOg clarify the semantic distinction.

Figure 1: Example instances of presence-based and absence-based negation from CC-Neg and NegRefCOCOg benchmarks.
Contrastive Objective Design
Omni-NegCLIP extends the canonical InfoNCE objective used in CLIP by constructing custom contrastive losses for each negation form:
- Presence-Based Contrastive Objective: Aligns image embeddings with true caption embeddings and penalizes similarity to their negated caption embeddings. This is achieved via a combination of image-to-caption, caption-to-image, and explicit negation discrimination losses, resulting in substantial semantic separation between image and negated caption.
- Absence-Based Contrastive Objective: Aligns image embeddings equally with original and absence-based negated captions but introduces a margin-based penalty to enforce explicit semantic distinction in the text embedding space between original and negated captions.
Both objectives are computed via mini-batch triplets with dedicated loss components, optimizing the fine-grained negation discrimination and robustness.
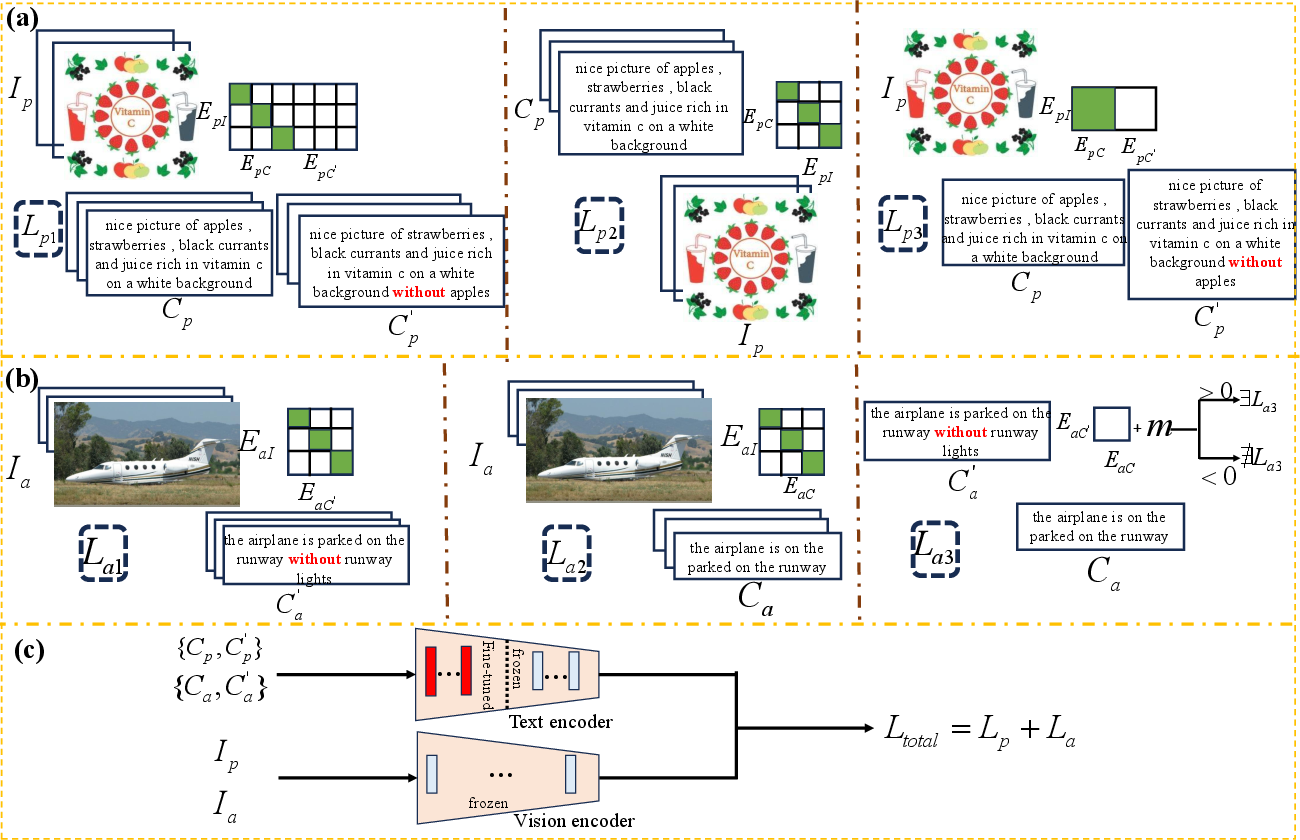
Figure 2: Schematic of presence-based and absence-based contrastive objectives and the Omni-NegCLIP fine-tuning pipeline.
Layer-wise Negation Learning: Front-Layer Dominance
A layer-wise fine-tuning analysis reveals that the front transformer layers of CLIP's text encoder yield markedly higher accuracy for both negation types. Fine-tuning only the first K layers, as opposed to the later or all layers, is empirically more effective. This is hypothesized to stem from the necessity of modeling fine-grained syntactic structures and negation scope—structures predominantly encoded in the early transformer layers [dumpala2024seeing].
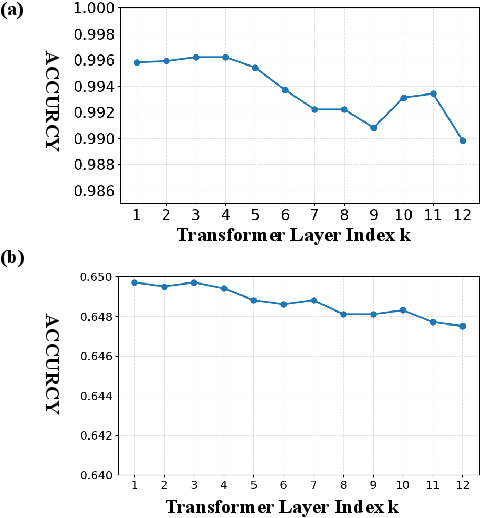
Figure 3: Cross-layer accuracy profiles for presence-based and absence-based negation tasks, showing superior negation modeling in front transformer layers.
Fine-Tuning Pipeline
In practice, Omni-NegCLIP fine-tunes only the front K transformer layers and the projection layer of the CLIP text encoder per training step, using a combined loss from the presence- and absence-based objectives. This strategy maximizes negation learning while maintaining general semantic alignment. Optimization uses AdamW and a margin parameter for loss separation, with batch triplets sampled from CC-Neg and OAN datasets.
Experimental Results
Omni-NegCLIP is evaluated on three architectures: ViT-B/32, ViT-B/16, and ViT-L/14. The method is compared against pretrained CLIP, CoN-CLIP, and NegationCLIP on CC-Neg (presence-based), NegRefCOCOg (absence-based), and COCO retrieval (general capability).
- Presence-Based Negation: Omni-NegCLIP achieves up to 51.60% to 52.65% accuracy improvement over CLIP and up to 45.26% over NegationCLIP.
- Absence-Based Negation: Improvements reach 11.81% to 12.50% over CLIP, and up to 17.07% over CoN-CLIP.
- General Retrieval: In COCO retrieval, Omni-NegCLIP outperforms CLIP by up to 19.62% and maintains high accuracy compared to NegationCLIP.
Notably, Omni-NegCLIP demonstrates balanced performance: Unlike previous methods, it does not overfit to one negation form, providing excellent results on both negation benchmarks as well as general retrieval.
Ablation and Analysis
Systematic ablation studies confirm the necessity of explicit negation discrimination losses and margin penalties. Fine-tuning more than six front layers or inappropriate loss configurations reduces accuracy, emphasizing that front-layer adaptation and nuanced objectives are critical. Proper margin settings (e.g., m=0.9) are essential to enforce text embedding separation without semantic ambiguity.
Theoretical and Practical Implications
Omni-NegCLIP's architecture and objectives represent a new paradigm for enhancing multimodal models' interpretability and linguistic robustness. By successfully disentangling semantic negation across both presence and absence scenarios, it closes critical gaps in VLM reasoning. The methodology highlights the importance of front-layer transformer adaptation for modeling syntactic and semantic subtleties, suggesting future directions in hierarchical or syntactic-aware fine-tuning protocols for VLMs.
Practically, improved negation comprehension in CLIP unlocks advancement in search, question answering, and generative tasks, enabling models to better handle compositional linguistic phenomena. The results suggest robust transferability to other foundational vision-language architectures.
Conclusion
Omni-NegCLIP introduces front-layer contrastive fine-tuning combined with bespoke objectives for both presence-based and absence-based negation, demonstrably improving CLIP's negation understanding without sacrificing general capability. The findings establish front-layer transformer adaptability as crucial for fine-grained semantic modeling, paving the way for future VLM improvements in linguistic robustness and compositional reasoning.

