- The paper introduces CCDNet, a novel framework using a weighted multi-branch perceptron, aggregation fusion neck, and contrastive-aided discriminator to tackle IR small target detection challenges.
- It achieves significant precision and F1 score improvements over existing methods, particularly under conditions of severe camouflage and distractor interference.
- The modular design combining local/global contrastive learning and bidirectional context fusion enables robust, real-time detection in critical operational applications.
Camouflage-aware Counter-Distraction Network (CCDNet) for Infrared Small Target Detection
Introduction and Problem Context
Infrared small target detection (IRSTD) is critical for applications such as wilderness search and maritime rescue, yet challenges persist due to two dominant factors: target camouflage (as targets often present with low contrast, blurred contours, and insufficient texture against complex backgrounds) and distractor interference (background objects with target-like appearances leading to false alarms). Previous works, particularly deep learning (DL)-based methods, have advanced semantic representation learning but still underperform when confronted with these two adverse factors, largely due to limitations in feature extraction, insufficient exploitation of context, and a lack of targeted distractor discrimination.
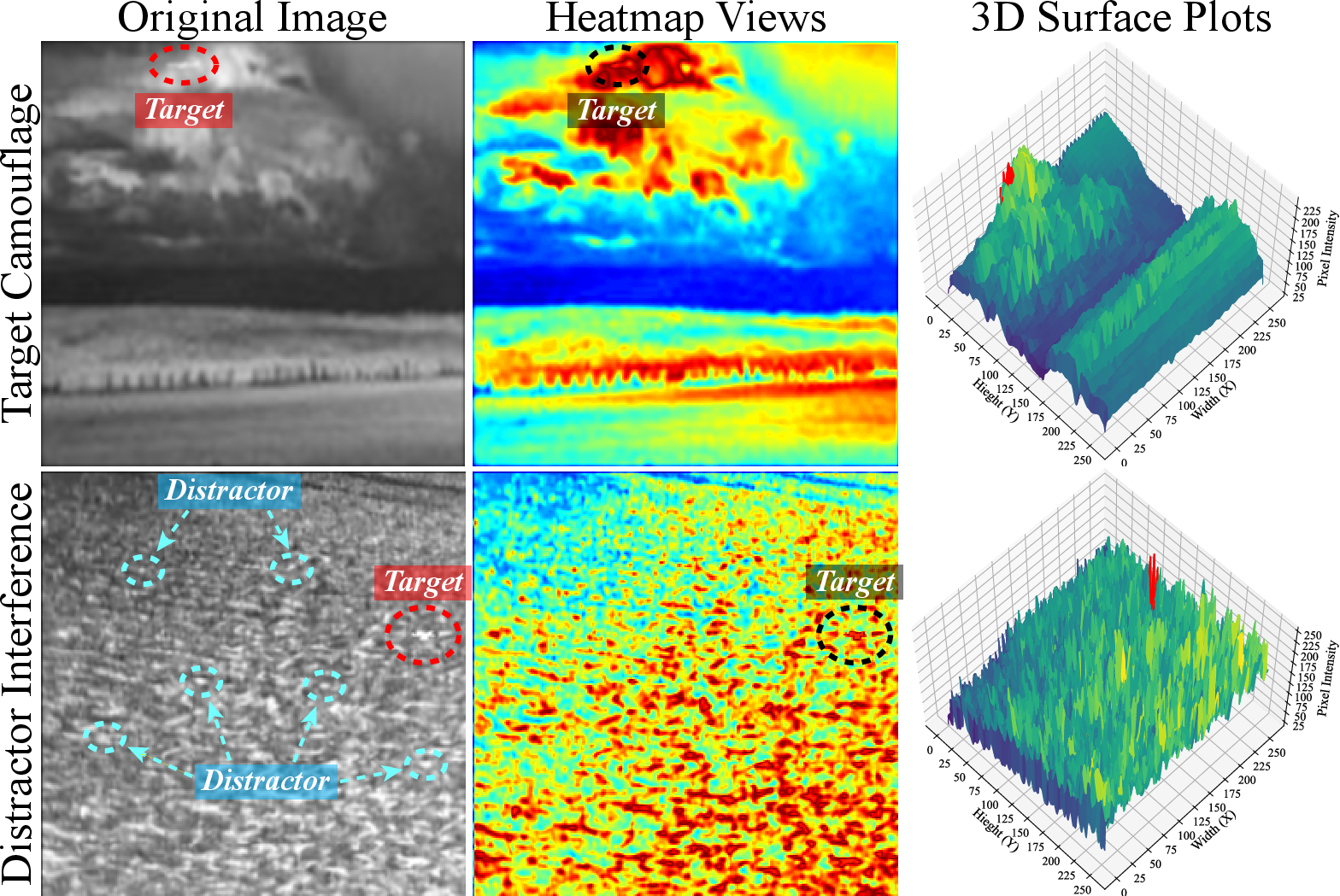
Figure 1: Illustrations of two key challenges in IRSTD tasks: target camouflage and distractor interference.
Methodology: Camouflage-aware Counter-Distraction Network (CCDNet)
CCDNet is designed to overcome both camouflage and distractor challenges via three innovations: 1) a Weighted Multi-branch Perceptron (WMP) backbone, 2) an Aggregation-and-Refinement Fusion Neck (ARFN), and 3) a Contrastive-aided Distractor Discriminator (CaDD). The overall architecture is shown below.
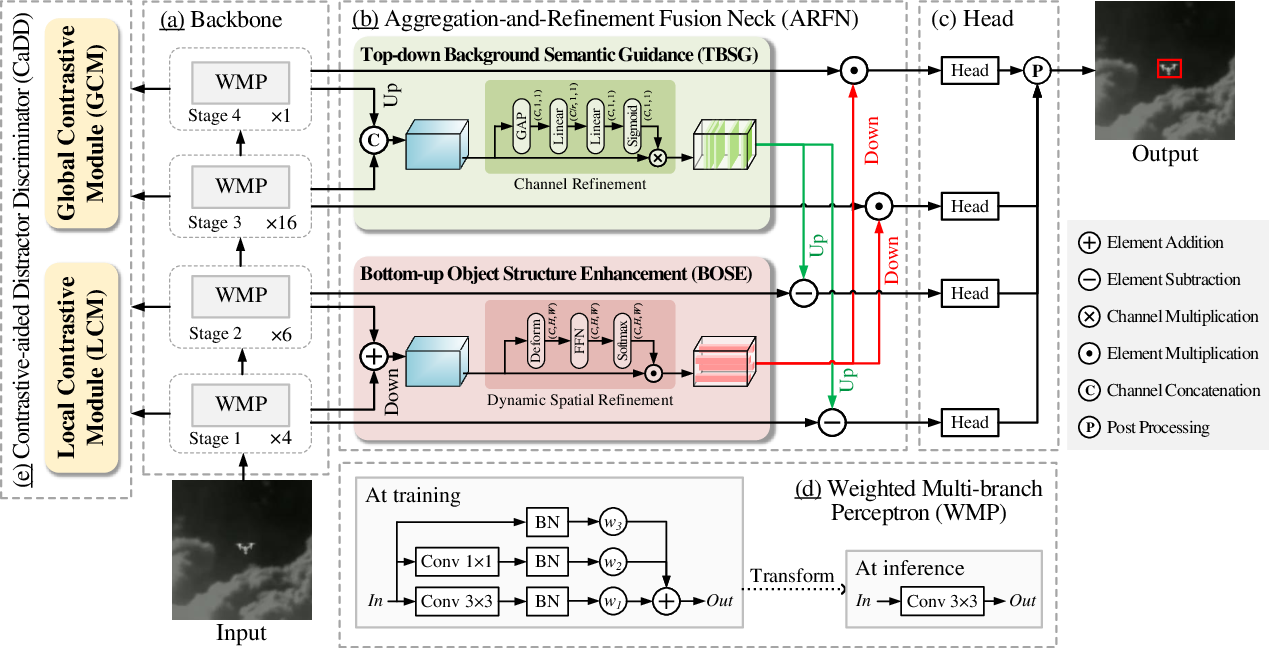
Figure 2: Overview of CCDNet, including WMP backbone, ARFN, and CaDD with LCM and GCM modules.
Weighted Multi-branch Perceptron Backbone
Instead of deepening backbone architectures—which is problematic for the spatial integrity of small targets—CCDNet extends the network’s width. The WMP backbone merges multi-scale context via three parallel branches with distinct receptive fields, and branch contributions are modulated by learned self-conditioning parameters. This strategy preserves spatial detail and represents targets and backgrounds adaptively.
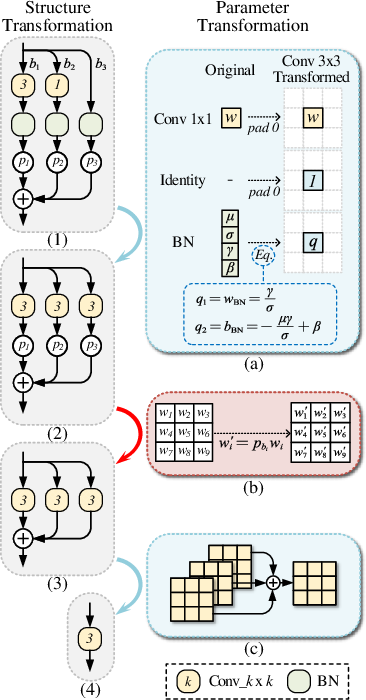
Figure 3: Structure transformation of the WMP, showing the parameter integration and branch self-conditioning system.
Ablation studies demonstrate WMP’s superiority over ResNet, RepVGG, and Inception blocks for IRSTD under precision, recall, and F1.
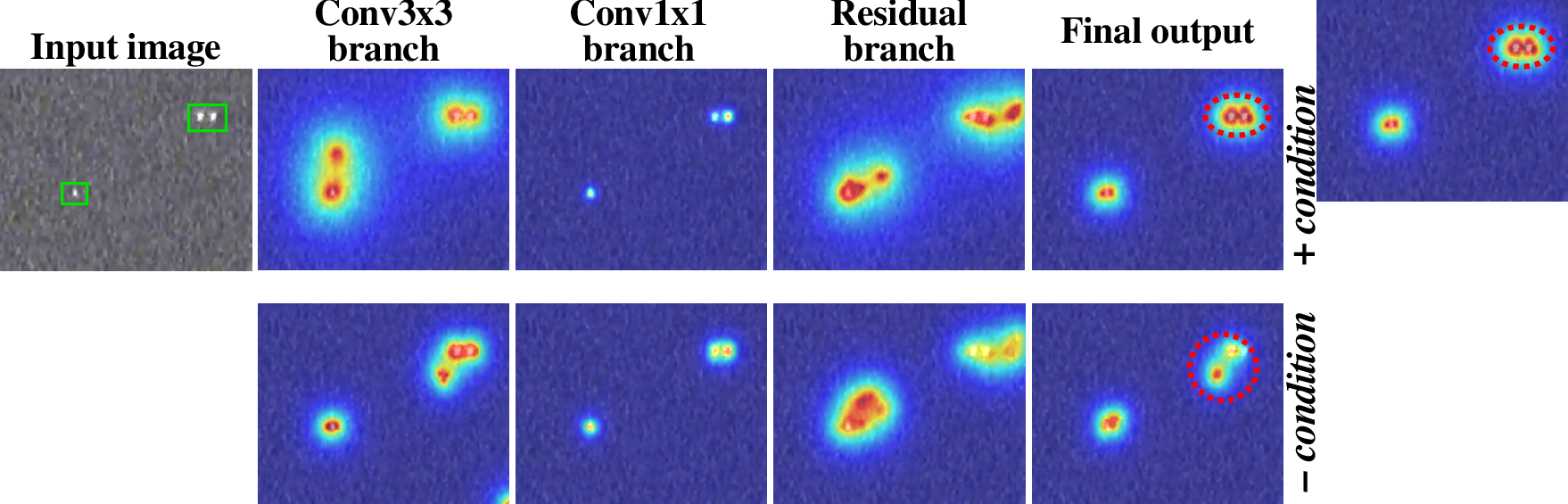
Figure 4: Heatmaps from the WMP backbone verifying accurate target perception by WMP modules.
Aggregation-and-Refinement Fusion Neck (ARFN)
The ARFN executes bidirectional context fusion. It includes:
- Top-down Background Semantic Guidance (TBSG): Upsampled deep background semantics guide and suppress background dominance in shallow stages.
- Bottom-up Object Structure Enhancement (BOSE): Fine-grained structure from shallow features refines deep-layer semantics to reinforce target regions.
Exploiting this bidirectional strategy enables formation of discriminative, target-centric features, significantly improving performance on camouflaged targets.

Figure 5: Heatmap comparison illustrating ARFN’s efficacy in highlighting target regions while suppressing background distraction.

Figure 6: Visual results of ARFN demonstrating improved separation of target from background during multi-stage feature fusion.
Contrastive-aided Distractor Discriminator (CaDD)
CaDD, active only during training, incorporates two modules:
- Local Contrastive Module (LCM): Computes regional contrasts around the target to maximize intra-class (target) saliency and suppress adjacent regions via triple-difference pooling and softmax-weighted combination; contrastive loss is formulated for each region, penalizing mismatches.
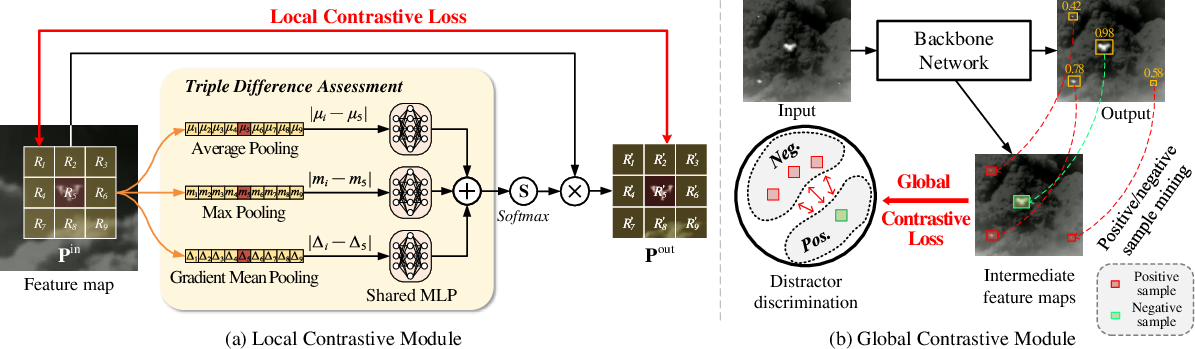
Figure 7: Illustration of LCM (local) and GCM (global) modules in CaDD for adaptive distractor discrimination.
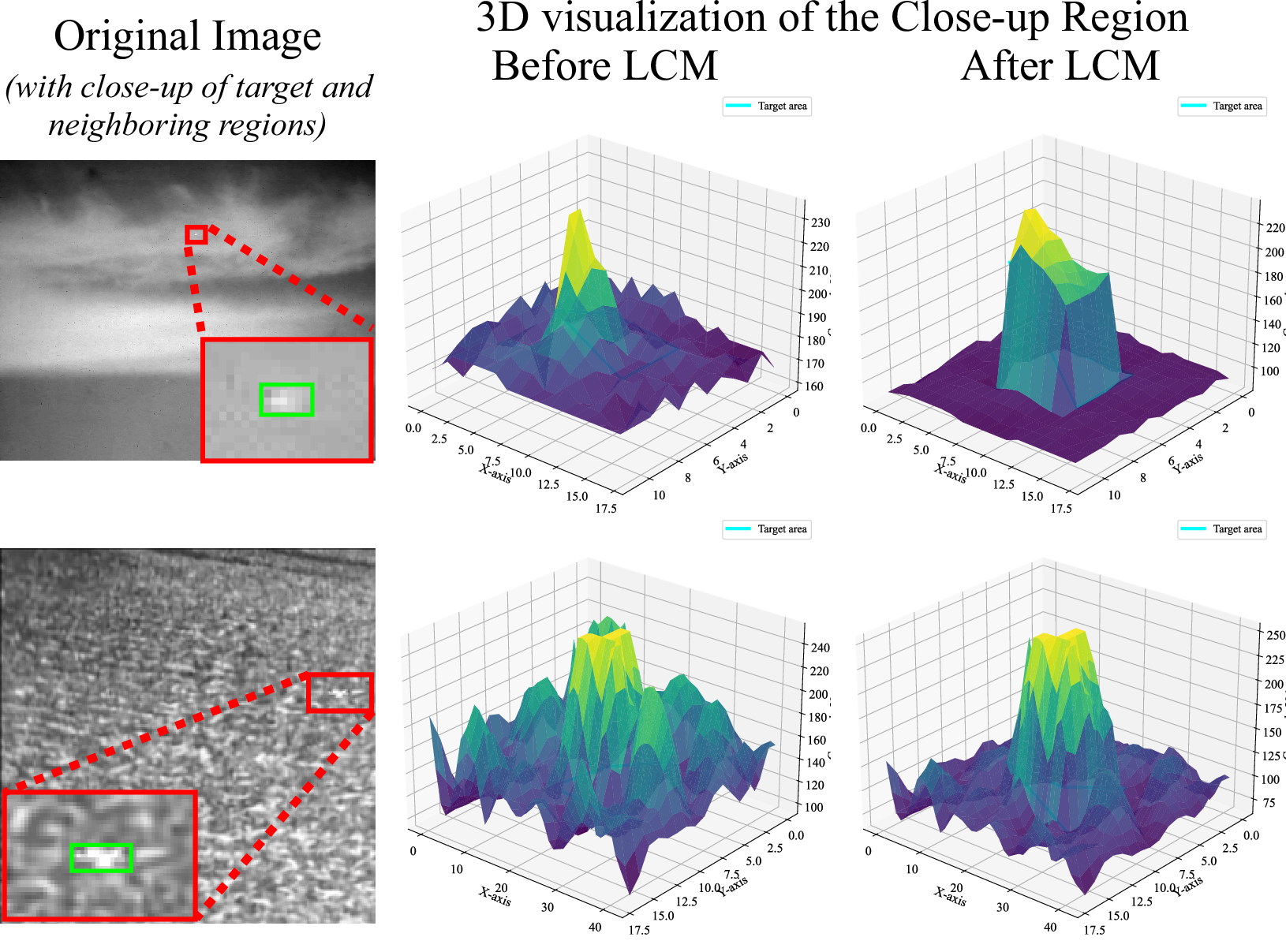
Figure 8: 3D visualization of LCM’s effect, where target regions are highlighted and backgrounds suppressed.
- Global Contrastive Module (GCM): Conducts similarity-based contrastive loss over an adaptively mined set of hard negative (distractor) and positive (real target) samples, identified by confidence thresholds on predicted results. GCM minimizes the chance of high-scoring distractors by maximizing inter-class discrimination on global feature spaces.
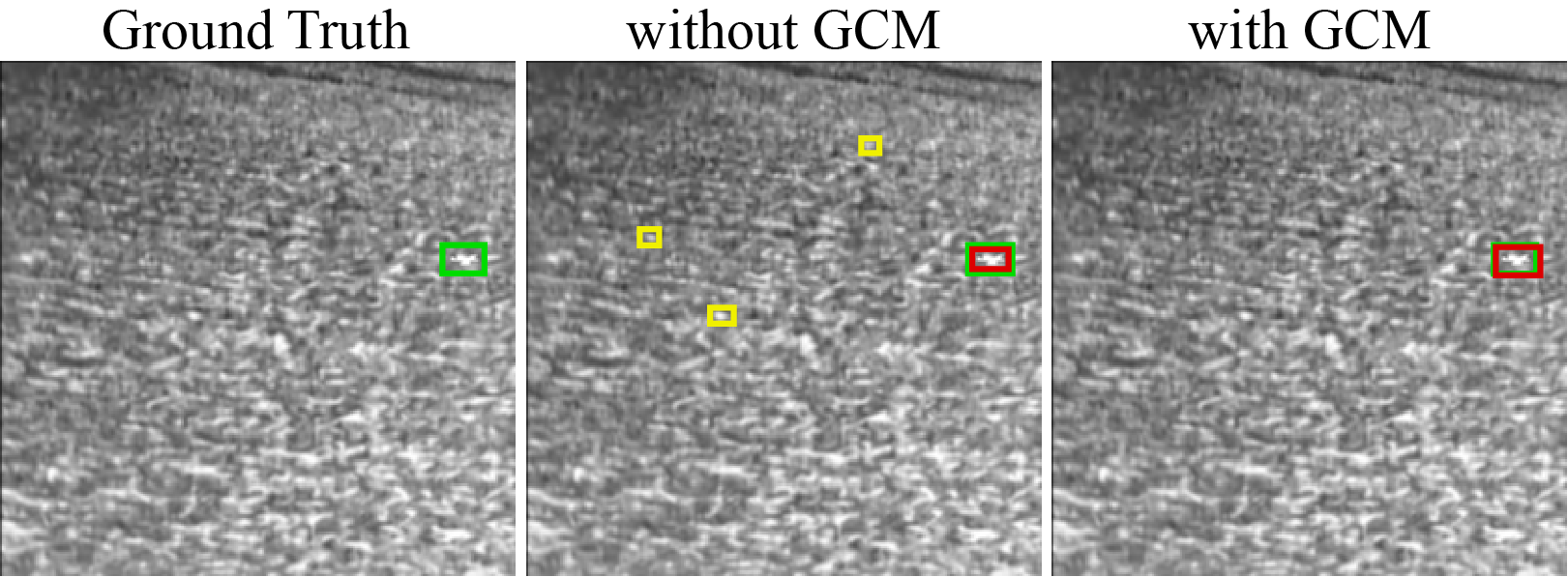
Figure 9: Visualization demonstrating that GCM successfully suppresses false detection due to distractors, improving overall accuracy.
This joint scheme fosters both local and global target/distractor distinction. Ablation reveals combined LCM+GCM yields ≈3.5% increase in precision and near 3% F1 over baseline.
Experimental Evaluation
Datasets and Implementation
CCDNet is evaluated on three public IRSTD datasets (IRSTD-1k, NUDT-SIRST, NUAA-SIRST). All methods are consistently retrained using the provided splits and converted object detection labels. Evaluation uses precision (P), recall (R), and F1 at target level, alongside computational metrics (params, FLOPs, FPS).
Quantitative Results
CCDNet achieves the highest F1 on all datasets, outperforming state-of-the-art DL-based and classical methods. For example, compared to MSHNet, CCDNet leads by 1.55% (IRSTD-1k), 0.01% (NUDT-SIRST), and 1.48% (NUAA-SIRST) in F1 score. The improvement is especially pronounced under high distractor or strong camouflage conditions. Inference speed remains competitive, facilitating real-time application.
Qualitative and Ablation Analysis
Qualitative visualizations confirm CCDNet’s ability to localize camouflaged targets and suppress distractor-induced false alarms more robustly than other methods.

Figure 10: Qualitative results comparing CCDNet and other methods. CCDNet achieves more accurate overlap with ground truth and fewer false alarms/missed detections.
Ablation studies validate that each core module (WMP, ARFN, CaDD) contributes substantial gains, and combined deployment is essential for best performance. Additional analysis shows alternative fusion or contrastive strategies (FPN, BiFPN; adversarial or random negative sampling) perform worse than the proposed designs. Figure 11 further visualizes how ARFN boosts focus on actual targets over misleading background regions.

Figure 11: Network visual heatmaps with and without ARFN, highlighting its role in focusing attention on targets across varied scenarios.
Theoretical and Practical Implications
This work establishes that for IRSTD, discriminative representation construction must go beyond global feature aggregation, especially under adversarial camouflage and distractor conditions. The width-enhanced and self-conditioned WMPs prevent spatial information loss, while ARFN bridges the context–structure gap across scales and CaDD’s local/global contrastive learning enforces robust inter-instance discrimination—key both for low SNR detection and for deployment in operationally critical fields (e.g., search and rescue, surveillance).
Practically, the architecture is modular and extensible, with the CaDD functioning as an “active regularizer” that introduces no inference overhead, suggesting broader applicability to other small-object or background-rich detection tasks. The study indicates that future research should focus on adaptive context strategies, learnable negative mining in contrastive loss, and further reduction of real-time computational overhead, especially for edge deployments.
Conclusion
CCDNet advances the standard for infrared small target detection by integrating width-oriented backbone design, bidirectional semantic-structure fusion, and contrastive-based distractor discrimination. Through systematic experiments, its efficacy in addressing camouflage and distractor interference is established via measurable improvements in detection robustness and accuracy. This architecture’s principles (context-aware feature extraction, adaptive local/global contrastive regularization) are transferable and should motivate further research into robust detection systems for complex and adverse visual domains.
Reference:
"CCDNet: Learning to Detect Camouflage against Distractors in Infrared Small Target Detection" (2603.29228)

