- The paper introduces SLVMEval, a benchmark for meta-evaluating text-to-long video generation metrics through controlled synthetic degradations.
- The paper employs human annotations and temporal subsampling to ensure rigorous, aspect-specific quality comparisons between high- and low-quality video pairs.
- The paper reveals that current automatic evaluation systems significantly underperform compared to human benchmarks, particularly in semantic and temporal reasoning.
SLVMEval: A Benchmark for Meta-Evaluation of Text-to-Long Video Generation Metrics
Motivation and Context
The rapid increase in research on text-to-video (T2V) generation has been accompanied by a surge in video lengths targeted by new models, from a few seconds to several minutes and beyond. Consequently, the evaluation of these models—traditionally focused on short, synthetic or natural video clips—has become critically misaligned with the increasing scale of generated content. Most existing benchmarks and evaluation systems, such as VBench and UVE, implicitly assume short-form videos and do not address the unique challenges present in text-to-long video (T2LV) generation. SLVMEval is proposed to fill this evaluation gap, providing a meta-evaluation benchmark for assessing the reliability of automatic T2V evaluation systems on long videos (up to nearly 3 hours). The benchmark also investigates the minimum requirements necessary for such evaluation systems to be trustworthy proxies for human assessment in the T2LV regime.
SLVMEval Construction
SLVMEval is constructed using a dense video-captioning dataset (Vript), which contains authentic, long-form videos segmented into semantically coherent clips with corresponding captions. From each source video, synthetic degradations targeting specific quality aspects are applied to generate aspect-controlled low-quality videos. Each prompt thus yields a pair: a high-quality original and a synthetically degraded counterpart differing in a controlled manner along one aspect.
To ensure rigorous testbed integrity, every degraded pair is assessed by a pool of human annotators, and only pairs where the degradation is clearly and reliably perceptible are retained. This process enforces that the resulting task—distinguishing high- from low-quality based on a specified aspect—is easy for humans. The composition of the dataset is both content- and temporal-balanced, spanning 15 categories and a broad range of durations, with the average clip length at 19 minutes and the maximum exceeding 2 hours and 50 minutes.
The distributional statistics of SLVMEval are shown in Figures 8 and 9.
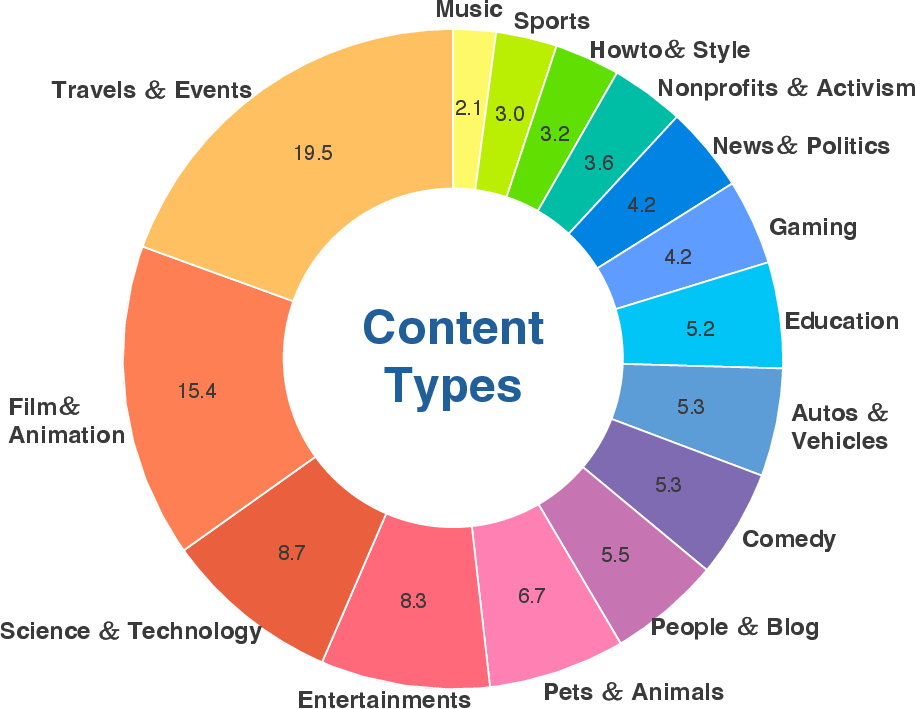
Figure 1: Distribution of video content categories in SLVMEval, ensuring balanced evaluation across diverse real-world scenarios.
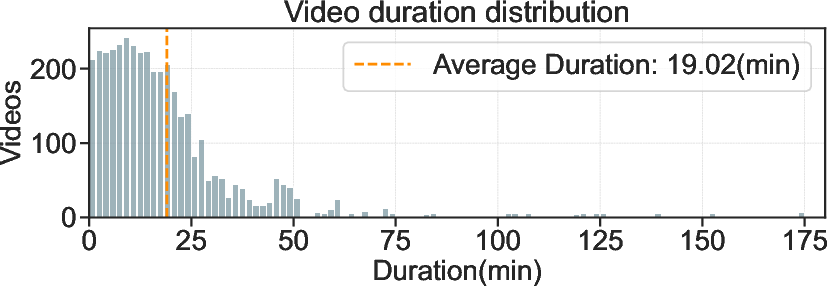
Figure 2: Distribution of video durations in SLVMEval, demonstrating coverage from short to ultra-long videos.
Degradation Aspects and Methods
SLVMEval defines 10 core aspects, partitioned into:
- Video Quality: aesthetics, technical quality, appearance style, background consistency
- Video-Text Consistency: temporal flow, comprehensiveness, object integrity, spatial relationship, dynamics degree, color
Each category targets a different axis of T2LV metric assessment. For instance, temporal flow and comprehensiveness probe semantic and chronological coherence, while object integrity and color test whether content or color information in the prompt transfers to the video. Degradation operations are implemented via controlled algorithmic modifications, e.g., temporal shuffling, style transfer, background replacement, object removal, inpainting, or color perturbation, appropriately informed by automated caption parsing.
This systematic design enables precise, aspect-specific evaluation of metric robustness and sensitivity.
Evaluation Systems and Protocol
The benchmark evaluates a set of existing automatic evaluation systems:
- Pairwise VLM-as-a-Judge: Video-based (direct video comparison with GPT-5, GPT-5-mini, Qwen3-VL), and text-based (captioning followed by language-model comparison)
- CLIPScore: Frame-based text-video relevance scoring using CLIP/v2
- VideoScore: Regression-based video quality scoring pretrained on human feedback
All systems are evaluated through forced-choice tasks (identify the higher-quality video in a pair) with accuracy as the primary metric. For computational tractability on long videos, temporal subsampling strategies are applied: videos are divided into clips, with representative frames (e.g., centroid of each segment) supplied to models with limited context capacity.
The reliability and difficulty of the evaluation task is established by including human annotator performance as an upper bound.
Experimental Analysis
Extensive experiments analyze various axes of evaluation system performance.
Key findings:
- Gap to Human Performance: Human annotators achieve 84.7%–96.8% accuracy across aspects; all automatic systems lag behind, especially on video-text consistency and semantic/temporal aspects, often falling below 60%. GPT-5 (video-based evaluation) obtains the highest automatic score but remains inferior to humans on 9 out of 10 aspects.
- Aspect-wise Sensitivity: Automatic systems are strongest on surface-level degradations (e.g., technical quality, style) but weak on those requiring event, temporal, or semantic comprehension (e.g., dynamics, temporal flow, comprehensiveness).
- Systemic Weaknesses: CLIPScore performs relatively well on object integrity and comprehensiveness due to its alignment induction, but is effectively random on aspects requiring temporal reasoning—consistent with its fundamental design as a frame-level metric.
- Video Length Effects: There is a statistically supported negative correlation between video duration and evaluation accuracy for most metrics and aspects. This is pronounced for background consistency and color, as shown in Figure 3.
- Scalability of Data Construction: Results before and after manual filtering of degraded pairs are highly correlated, indicating that the synthetic data generation pipeline can scale the benchmark effectively without laborious annotation for these degradation types (Figure 4).
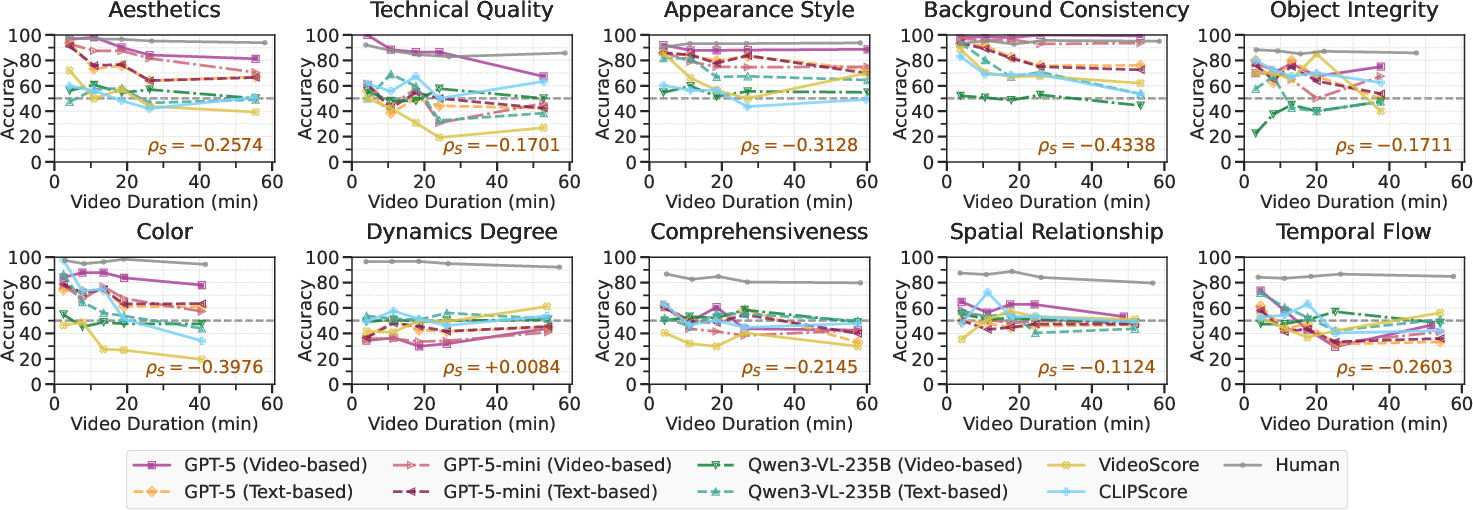
Figure 3: Accuracy of evaluation systems decreases with increasing video duration, especially on aspects involving background and color consistency.
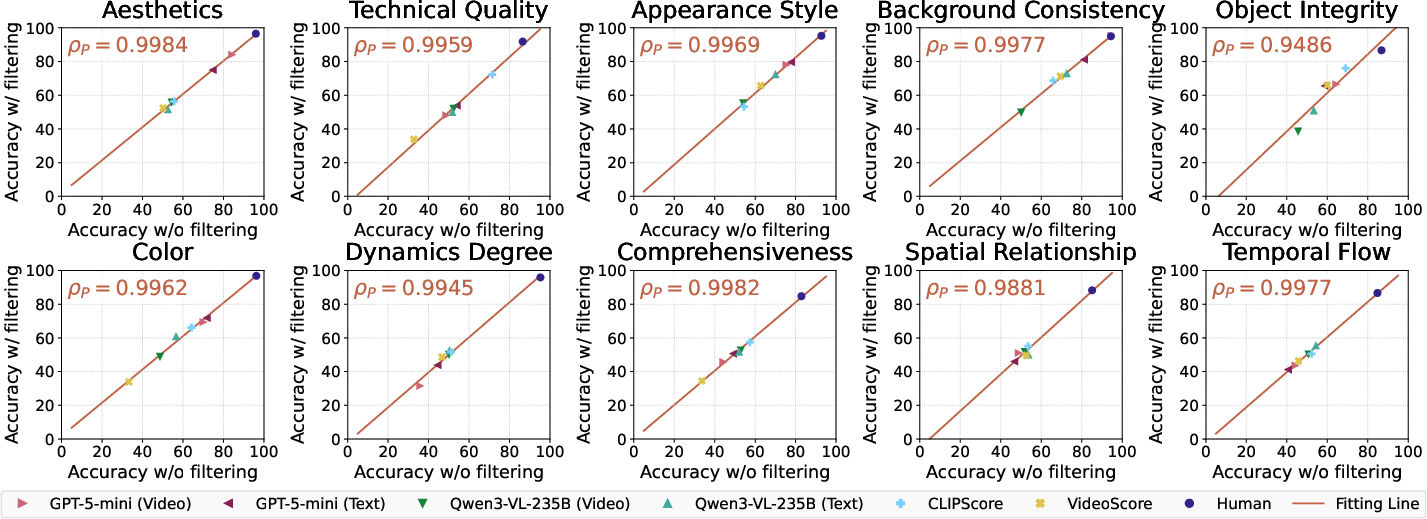
Figure 4: Accuracy before and after manual filtering is strongly correlated across systems and aspects, supporting the viability of automated testbed extension.
Implications and Forward Directions
SLVMEval exposes substantial limitations of current automatic metrics for T2LV evaluation:
- Metrics that suffice for short or static videos do not extrapolate to long-form, temporally complex content. This highlights the urgent need for developing scalable, temporally-aware, and semantically grounded evaluation methodologies.
- Reliance on CLIP-like and fine-tuned VLM metrics for long video will result in evaluation failures, especially for cross-frame reasoning, motivating future work in memory-augmented and event-centric video LLMs.
- The benchmark construction methodology, based on aspect-controlled synthetic degradation, is scalable and robust for developing new evaluation datasets, enabling rapid adaptation as T2LV model capabilities advance.
- Human-level performance on SLVMEval constitutes a necessary (though not sufficient) criterion for the deployment of automatic long video evaluation systems; future metrics and evaluators should target surpassing this minimal baseline before being applied in practical T2LV development.
Practically, SLVMEval enables reliable, comprehensive, and challenging meta-evaluation, paving the way for both improved metrics and models for next-generation video generation tasks.
Conclusion
SLVMEval inaugurates a robust, scalable testbed for meta-evaluation of T2LV metrics, revealing that existing automatic video evaluation systems are far from human-level reliability in the regime of long-form, semantically-rich video generation. The systematic aspect control, long video durations, and stringent human baselines set a new standard for evaluation system validation. The benchmark's extensibility and detailed diagnostic power make it a central reference for ongoing research in both evaluation metrics and T2LV modeling. Theoretical developments such as temporally dynamic, cross-clip, or hierarchical evaluators, and practical progress in more effective long video generation, are expected to be accelerated by the availability and adoption of SLVMEval.
Reference: "SLVMEval: Synthetic Meta Evaluation Benchmark for Text-to-Long Video Generation" (2603.29186)