CoE: Collaborative Entropy for Uncertainty Quantification in Agentic Multi-LLM Systems
Published 30 Mar 2026 in cs.AI | (2603.28360v1)
Abstract: Uncertainty estimation in multi-LLM systems remains largely single-model-centric: existing methods quantify uncertainty within each model but do not adequately capture semantic disagreement across models. To address this gap, we propose Collaborative Entropy (CoE), a unified information-theoretic metric for semantic uncertainty in multi-LLM collaboration. CoE is defined on a shared semantic cluster space and combines two components: intra-model semantic entropy and inter-model divergence to the ensemble mean. CoE is not a weighted ensemble predictor; it is a system-level uncertainty measure that characterizes collaborative confidence and disagreement. We analyze several core properties of CoE, including non-negativity, zero-value certainty under perfect semantic consensus, and the behavior of CoE when individual models collapse to delta distributions. These results clarify when reducing per-model uncertainty is sufficient and when residual inter-model disagreement remains. We also present a simple CoE-guided, training-free post-hoc coordination heuristic as a practical application of the metric. Experiments on \textit{TriviaQA} and \textit{SQuAD} with LLaMA-3.1-8B-Instruct, Qwen-2.5-7B-Instruct, and Mistral-7B-Instruct show that CoE provides stronger uncertainty estimation than standard entropy- and divergence-based baselines, with gains becoming larger as additional heterogeneous models are introduced. Overall, CoE offers a useful uncertainty-aware perspective on multi-LLM collaboration.
The paper introduces CoE, a novel framework decomposing uncertainty in multi-LLM ensembles into intra-model (aleatoric) and inter-model (epistemic) components.
It employs semantic clustering and asymmetric KL divergence metrics to diagnose ensemble uncertainty and drive effective model coordination.
Empirical evaluations on TriviaQA and SQuAD demonstrate significant AUROC improvements with increased ensemble size, highlighting robust calibration.
Collaborative Entropy for Uncertainty Quantification in Agentic Multi-LLM Systems
Introduction
Large-scale deployment of LLM ensembles in decision-critical domains exposes a fundamental challenge: standard uncertainty quantification (UQ) is typically single-model-centric and fails to capture semantic disagreement among heterogeneous models. The paper "CoE: Collaborative Entropy for Uncertainty Quantification in Agentic Multi-LLM Systems" (2603.28360) systematically addresses this gap by proposing Collaborative Entropy (CoE), an information-theoretic metric for system-level quantification of semantic uncertainty in multi-LLM systems. The central claim is that CoE accurately decomposes uncertainty into intra-model (aleatoric) and inter-model (epistemic) components, yielding actionable diagnostics and improved ensemble calibration.
Problem Formulation and Motivation
Single-model UQ approaches—such as token-level entropy, semantic entropy (SE), and self-consistency—quantify internal uncertainty but ignore cross-model epistemic divergence. In agentic multi-LLM contexts, predictions may diverge semantically despite strong internal confidence, an effect that cannot be captured by averaging individual model entropies. Existing alternatives (e.g., simple ensemble averaging or self-consistency voting) conflate fundamentally distinct uncertainty sources, obfuscating the underlying reasons for ensemble uncertainty.
CoE is not a scoring rule or an aggregation method, but a diagnostic framework for uncertainty measurement at the system level. It quantifies and separates:
Aleatoric uncertainty: residual ambiguity in each LLM’s semantic output distribution,
Epistemic uncertainty: irreducible disagreement among models caused by heterogeneous training, inductive biases, or underlying knowledge disparities.
The system processes candidate generations from each LLM using semantic clustering, then quantifies uncertainty through explicit decomposition.
Figure 1: Overview of the CoE framework for agentic multi-LLM uncertainty quantification; local clustering and central aggregation yield system-level collaborative entropy.
Collaborative Entropy: Formalism and Theoretical Properties
CoE is defined for a set of LLMs K as follows: For each query, all LLMs generate candidate responses. These responses are clustered into semantic clusters via bidirectional entailment, forming per-model cluster distributions pi(⋅∣x). CoE decomposes into two components:
Intra-model uncertainty (UA): Average semantic entropy across all models.
Inter-model uncertainty (UE): Weighted average of the KL divergences from each model’s cluster distribution to the ensemble mean.
Non-negativity: UCoE≥0 for all input/model ensembles.
Zero Value Certainty: UCoE=0 iff all models are internally certain and yield identical semantic clusters.
Residual Epistemic Divergence: Minimizing each SE(xi) individually does not guarantee UCoE→0 unless the models also align semantically—incompatible delta distributions preserve epistemic uncertainty.
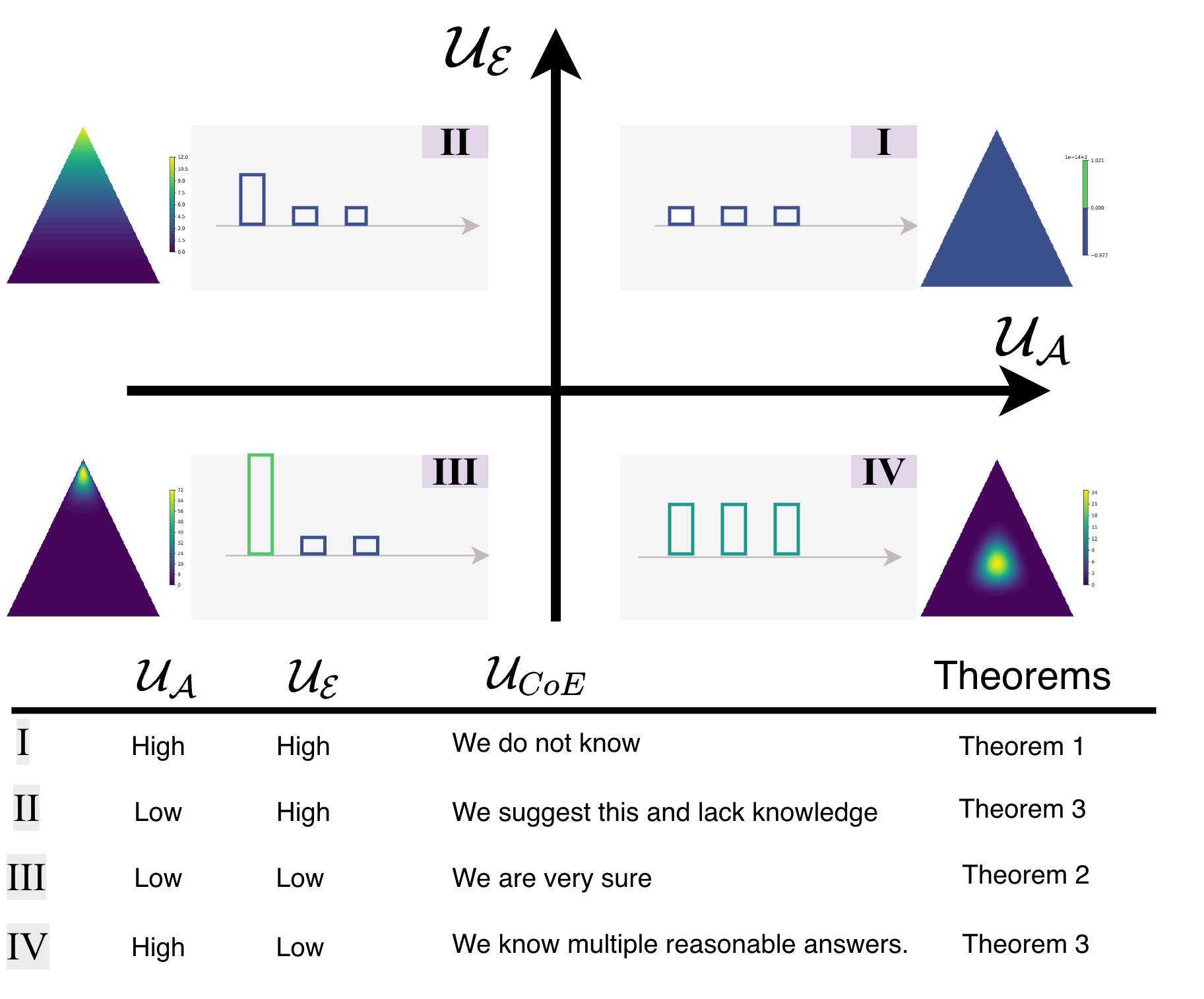
The Four Uncertainty Regimes
Mapping the uncertainty landscape, the paper introduces a quadrant-based interpretation in the (UA,UE) plane:
I: High pi(⋅∣x)0, High pi(⋅∣x)1: Maximum uncertainty—models are ambiguous and disagree.
II: Low pi(⋅∣x)2, High pi(⋅∣x)3: Models are confident, but in semantic disagreement (irreducible epistemic divergence).
III: Low pi(⋅∣x)4, Low pi(⋅∣x)5: Ideal, all models are certain and agree.
IV: High pi(⋅∣x)6, Low pi(⋅∣x)7: Consensus on distribution, but shared ambiguity.
Figure 2: Visualization of CoE quadrants; Dirichlet distributions and bar charts illustrate characteristic combinations of pi(⋅∣x)8 (x-axis) and pi(⋅∣x)9 (y-axis).
This provides an actionable diagnosis: e.g., high epistemic uncertainty with low aleatoric calls for cross-model alignment rather than more sampling.
Empirical Evaluation
Experimental Setup
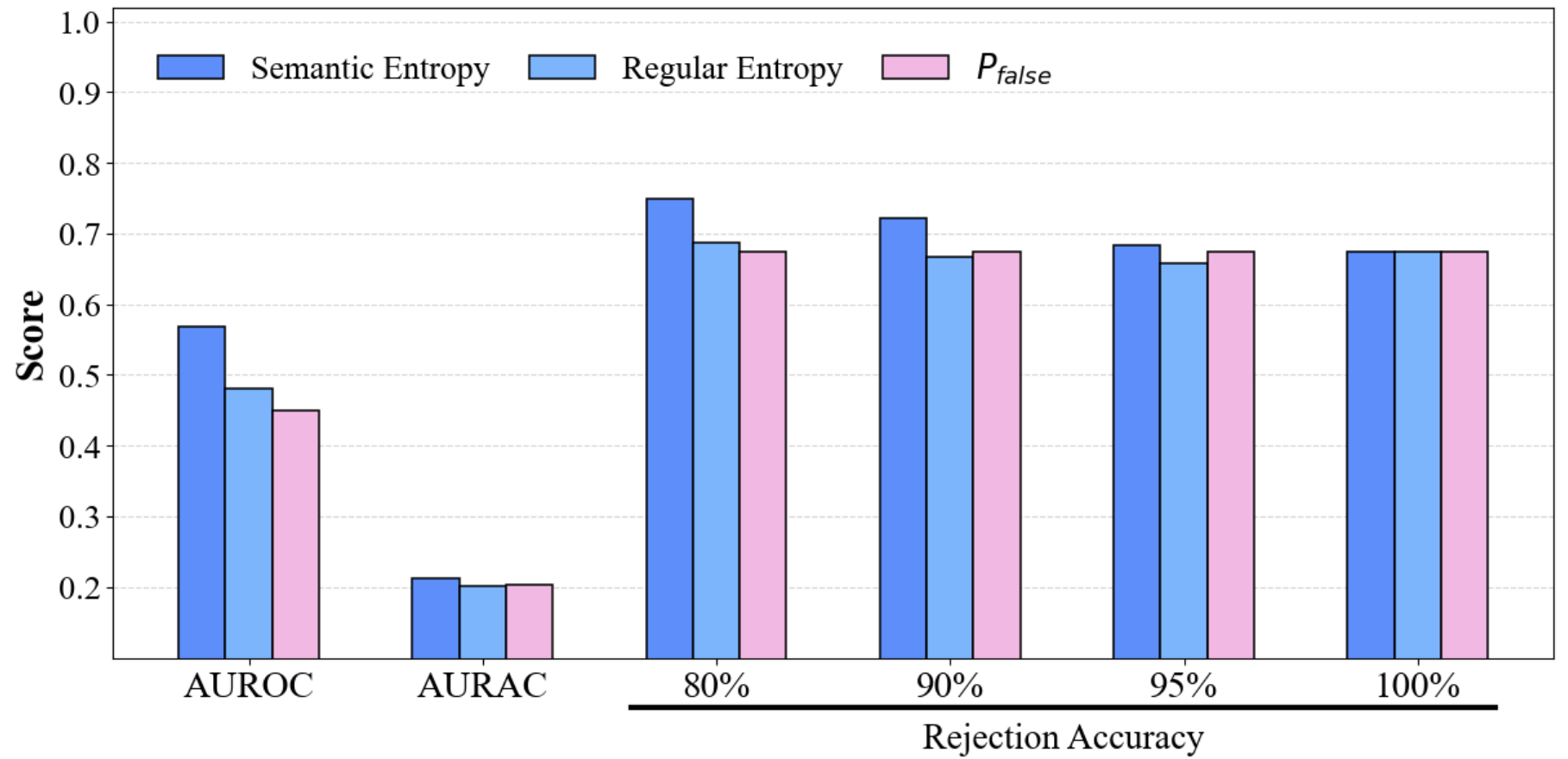
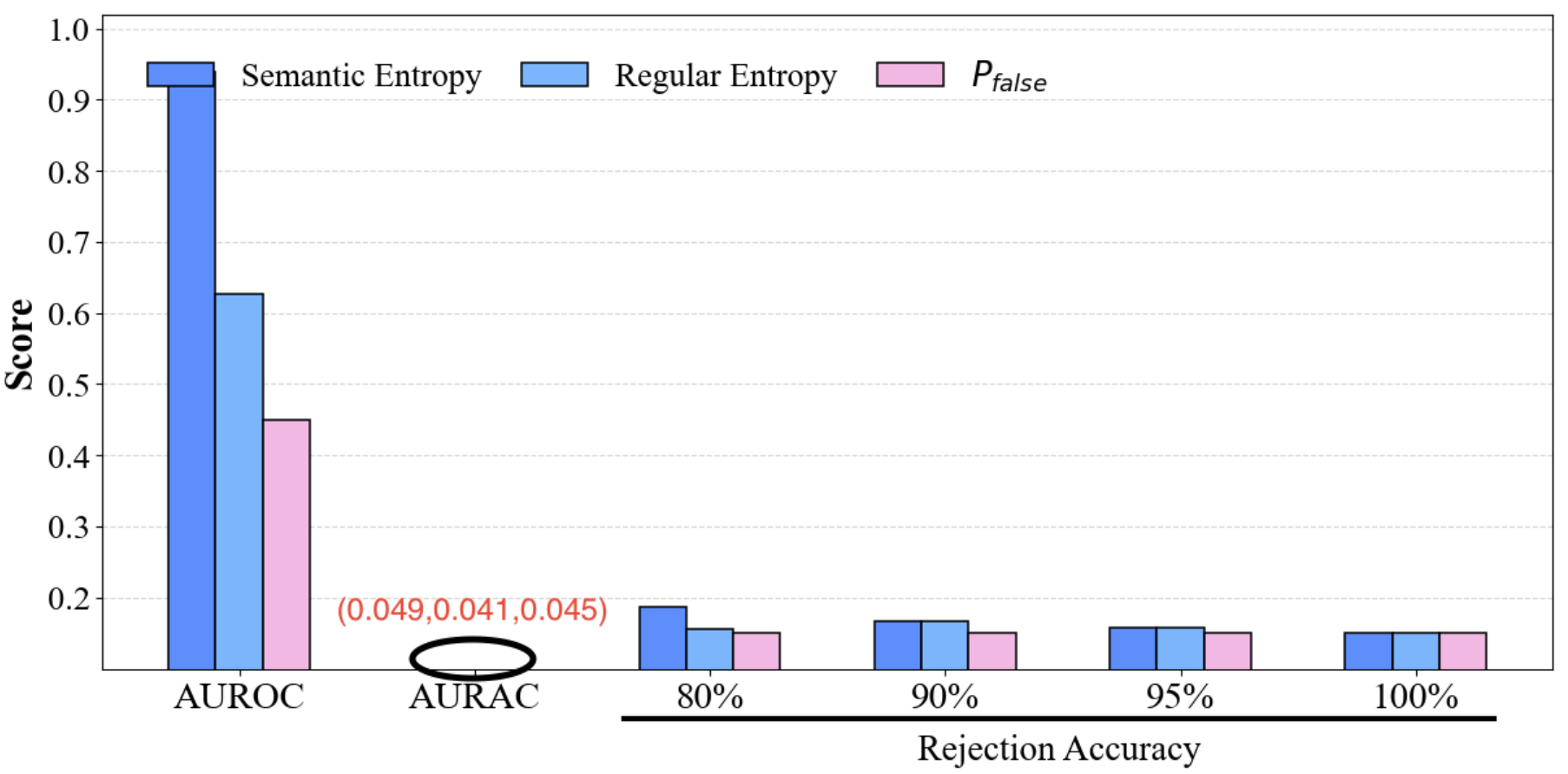
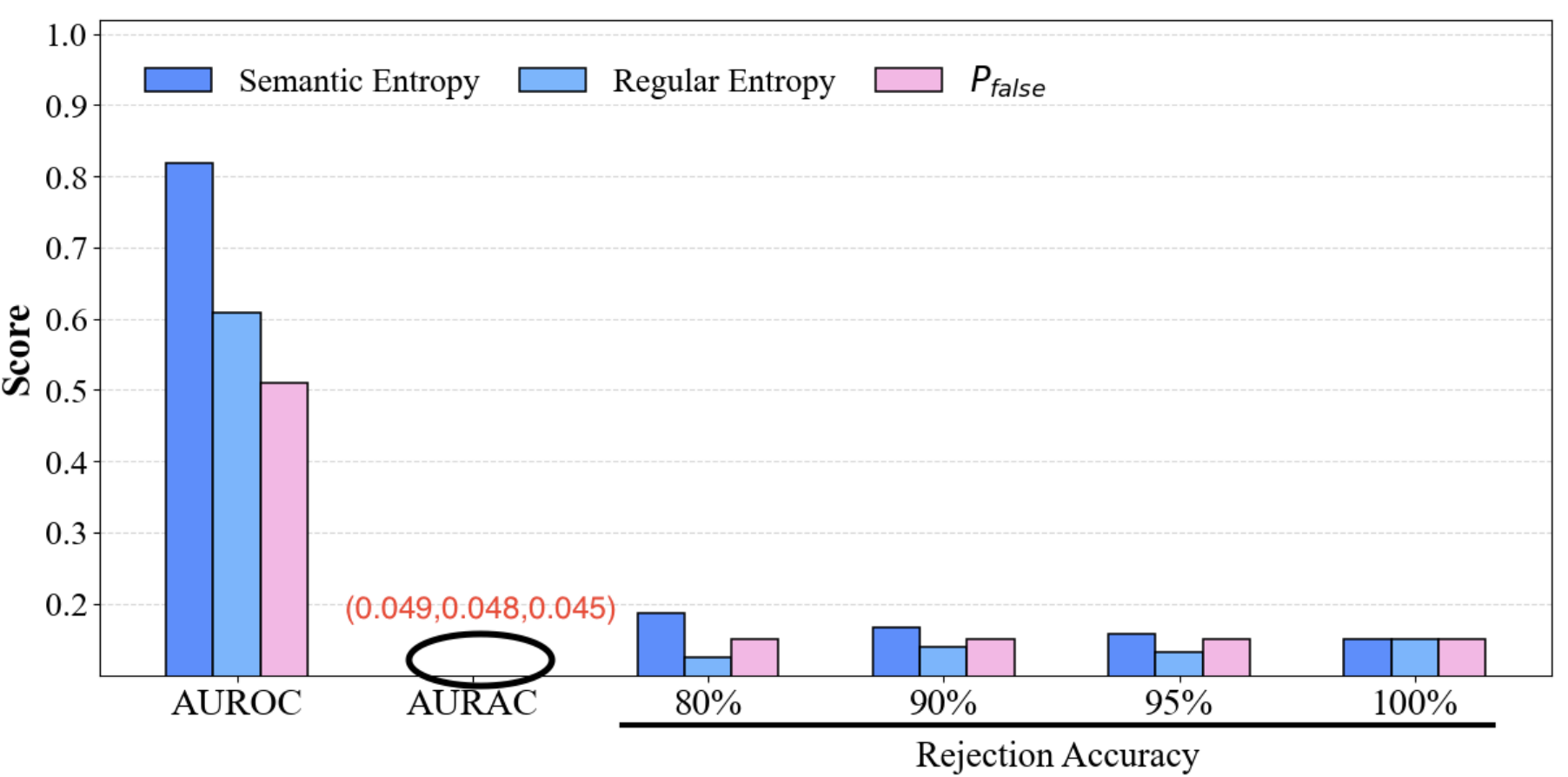
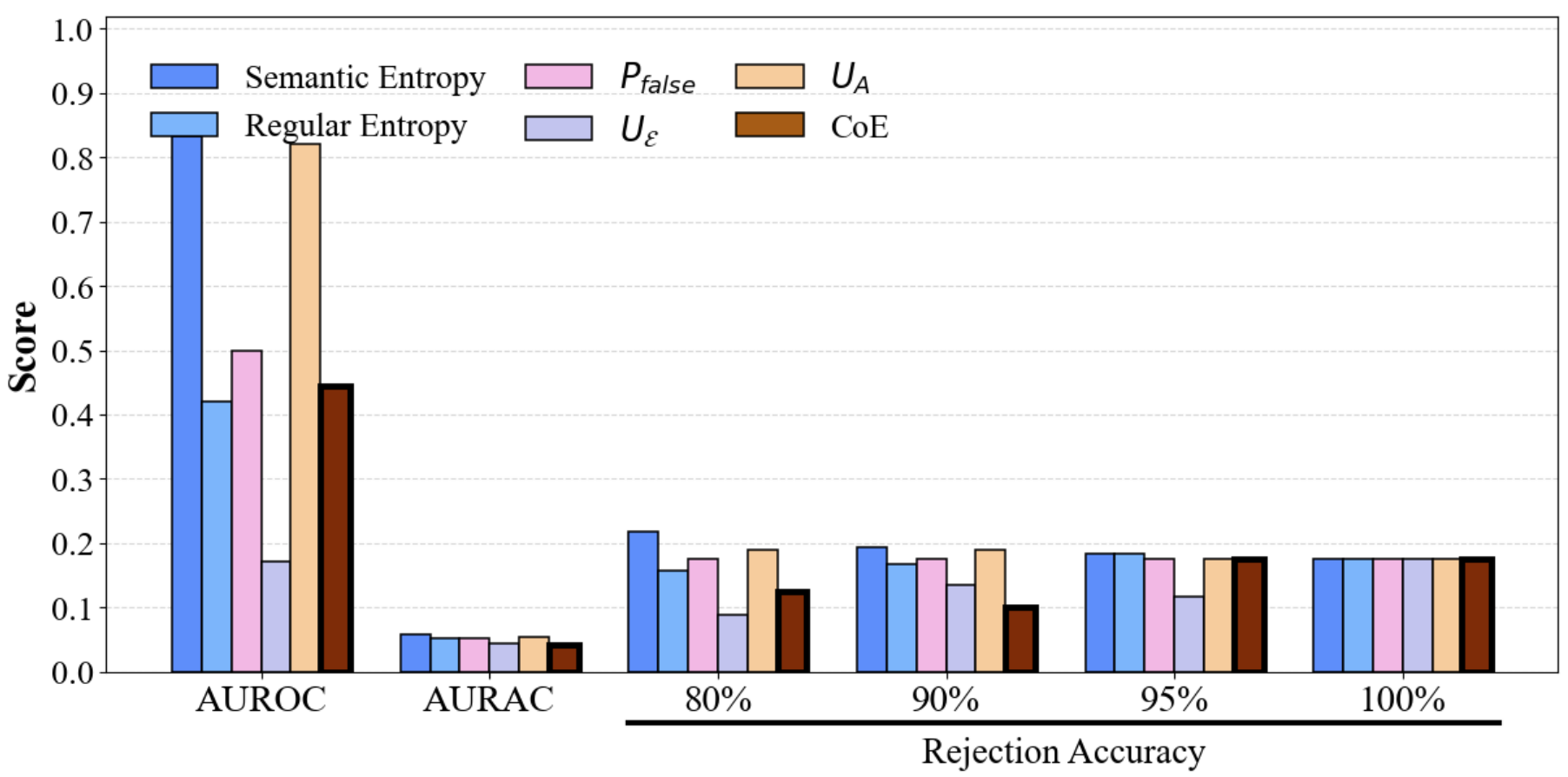
Empirical validation uses LLaMA-3.1-8B-Instruct, Qwen-2.5-7B-Instruct, and Mistral-7B-Instruct on TriviaQA and SQuAD QA datasets. The evaluation benchmarks selective prediction using AUROC (discriminative), AURAC (selective), and rejection accuracy. Baselines include token-level entropy, semantic entropy, and UA0 (self-consistency scoring).
Main Results
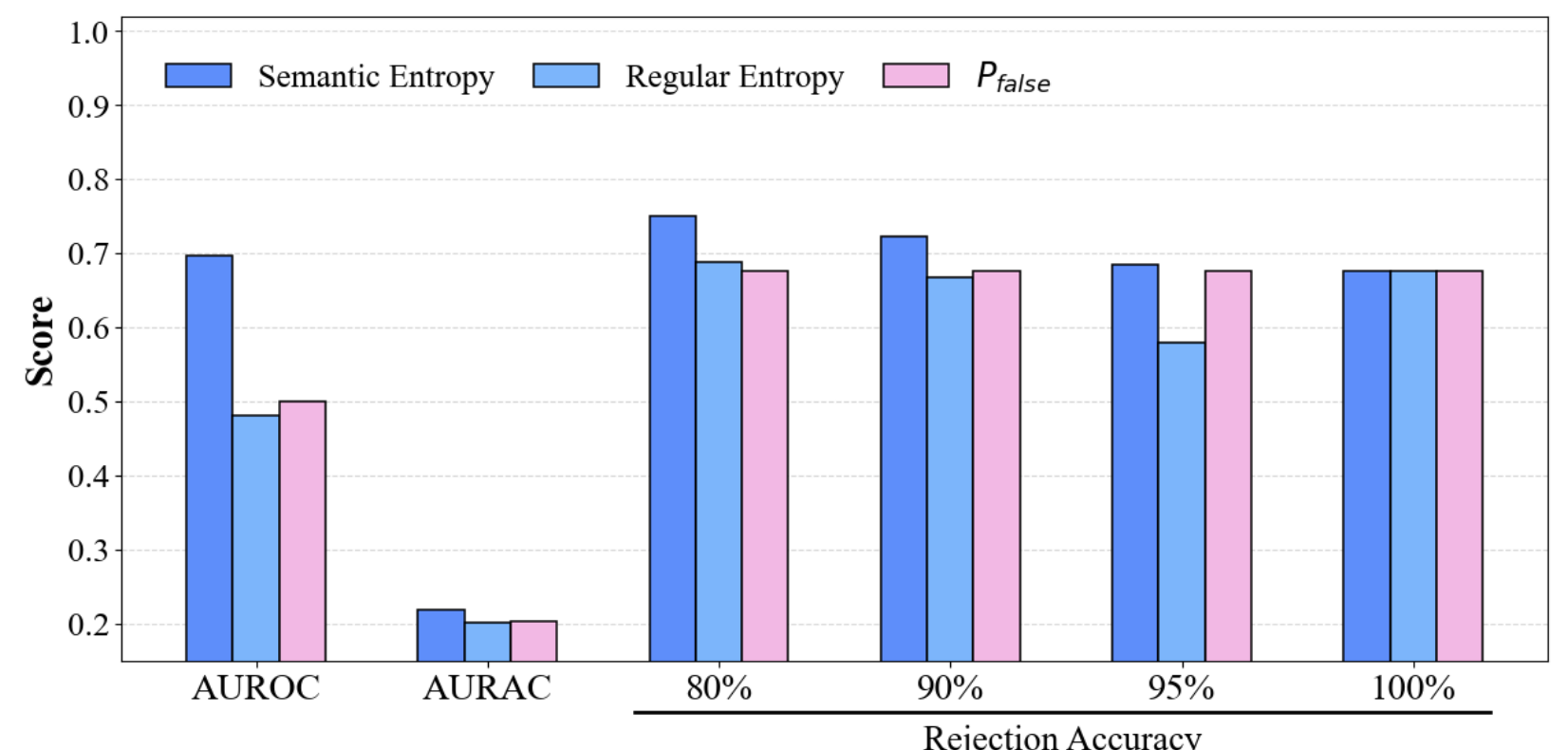
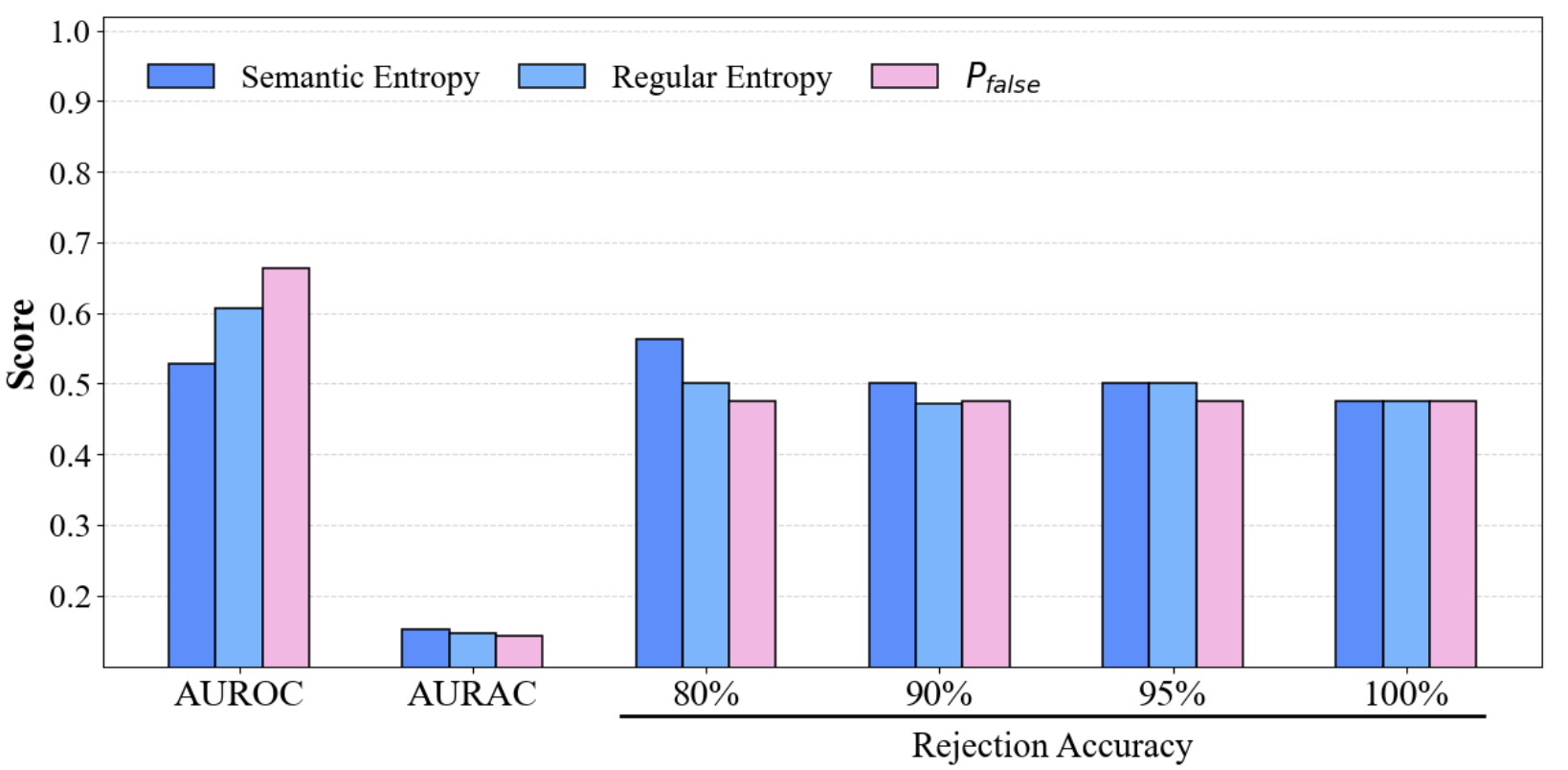
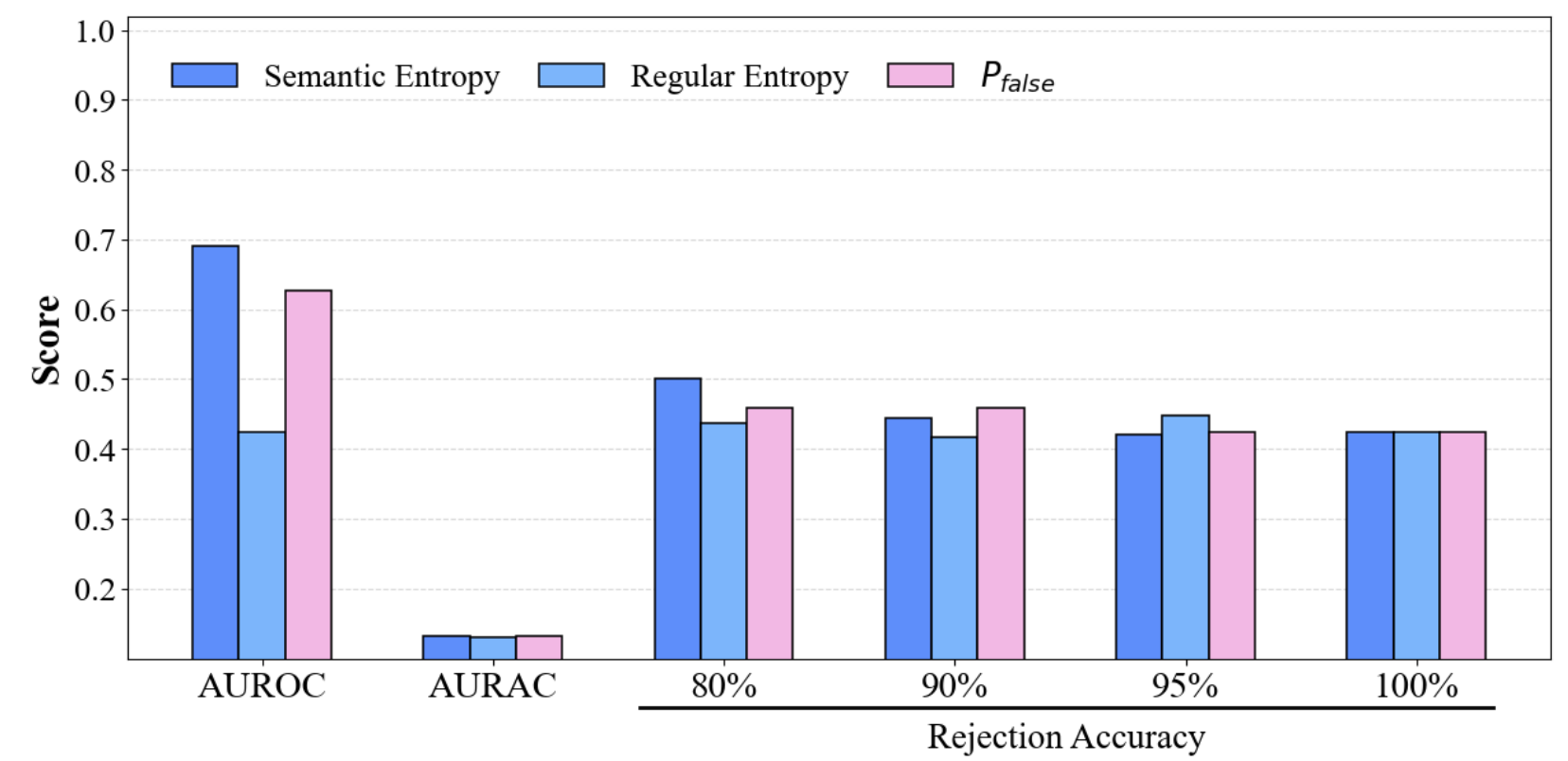
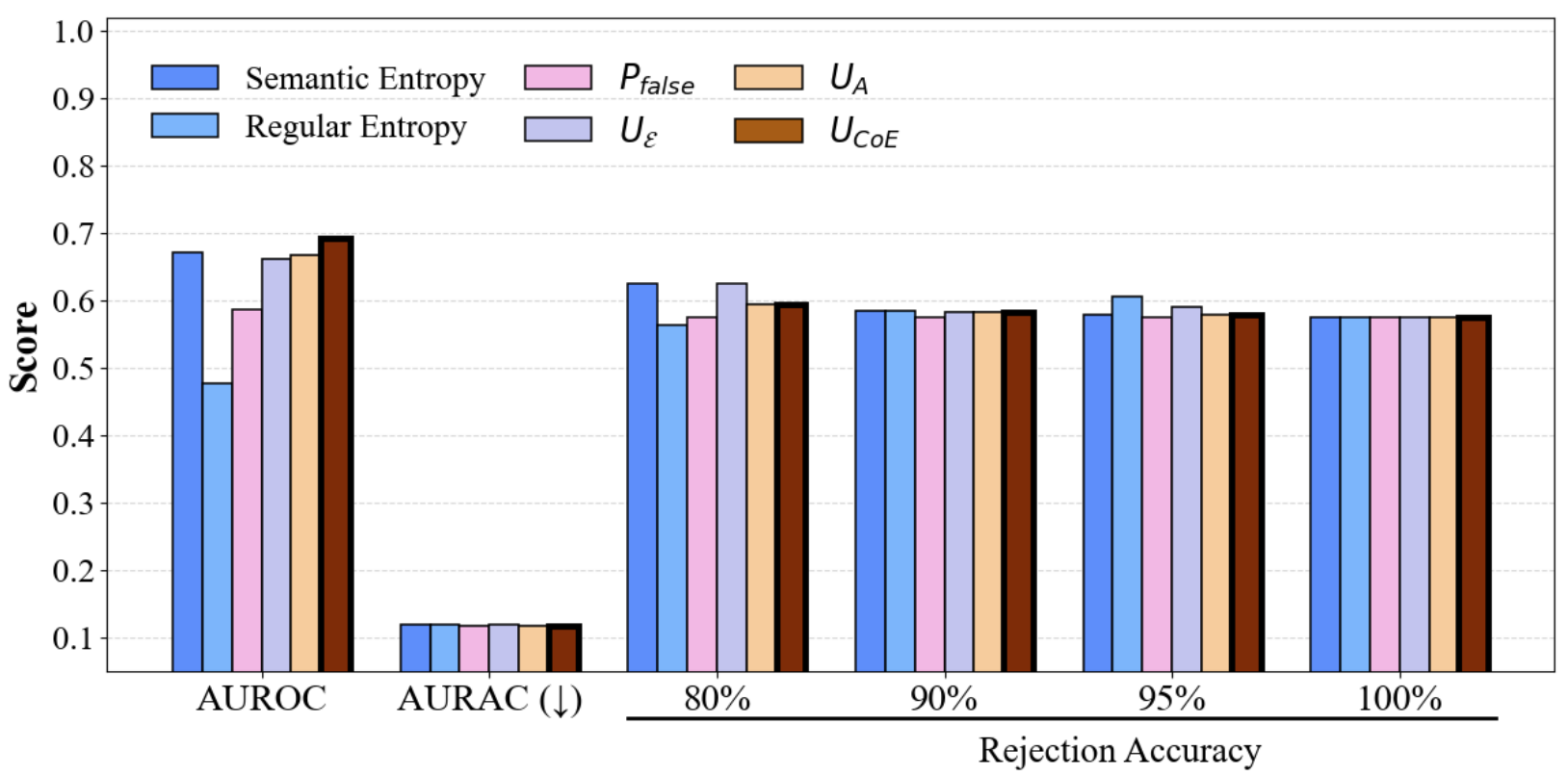
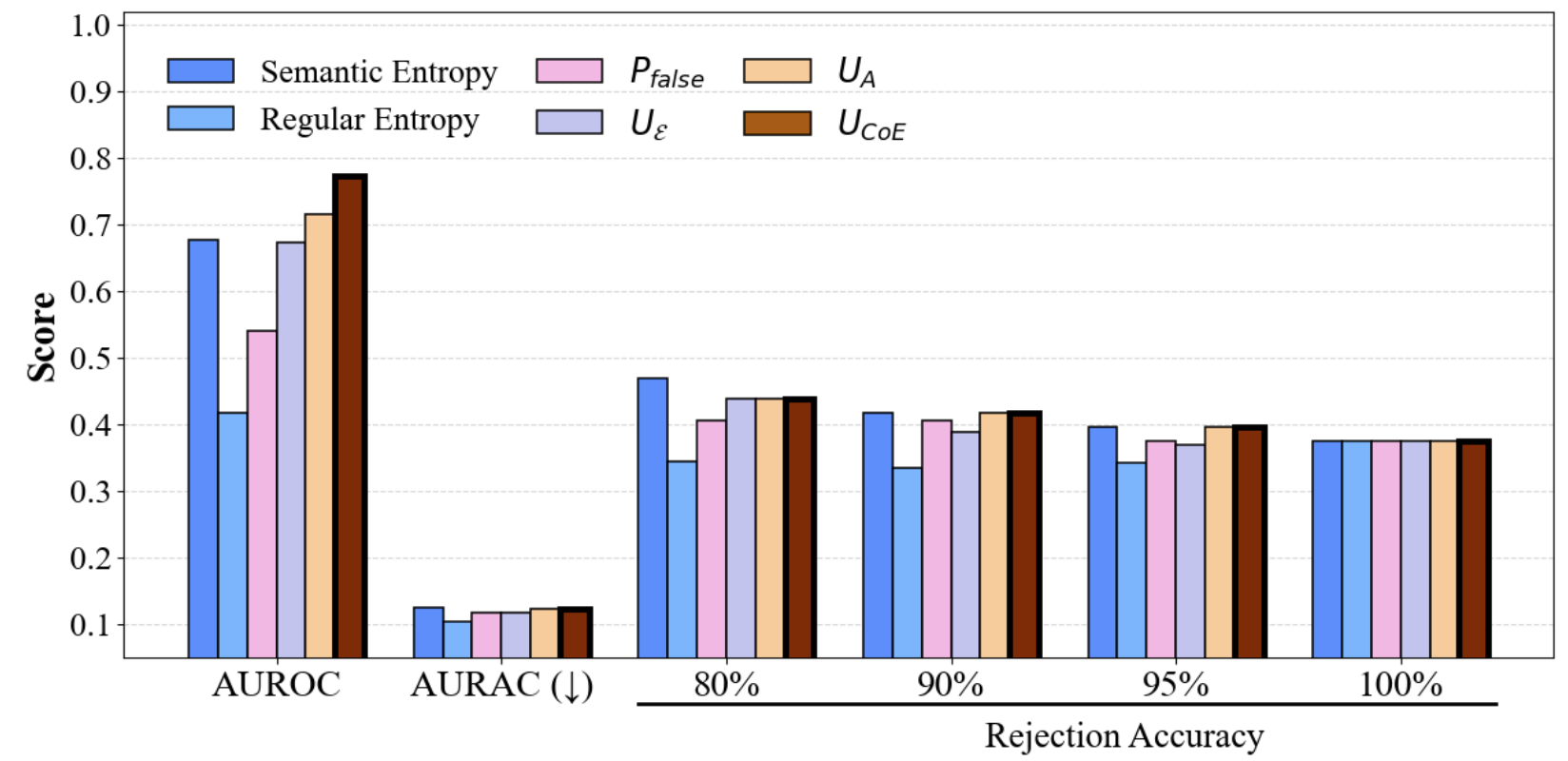
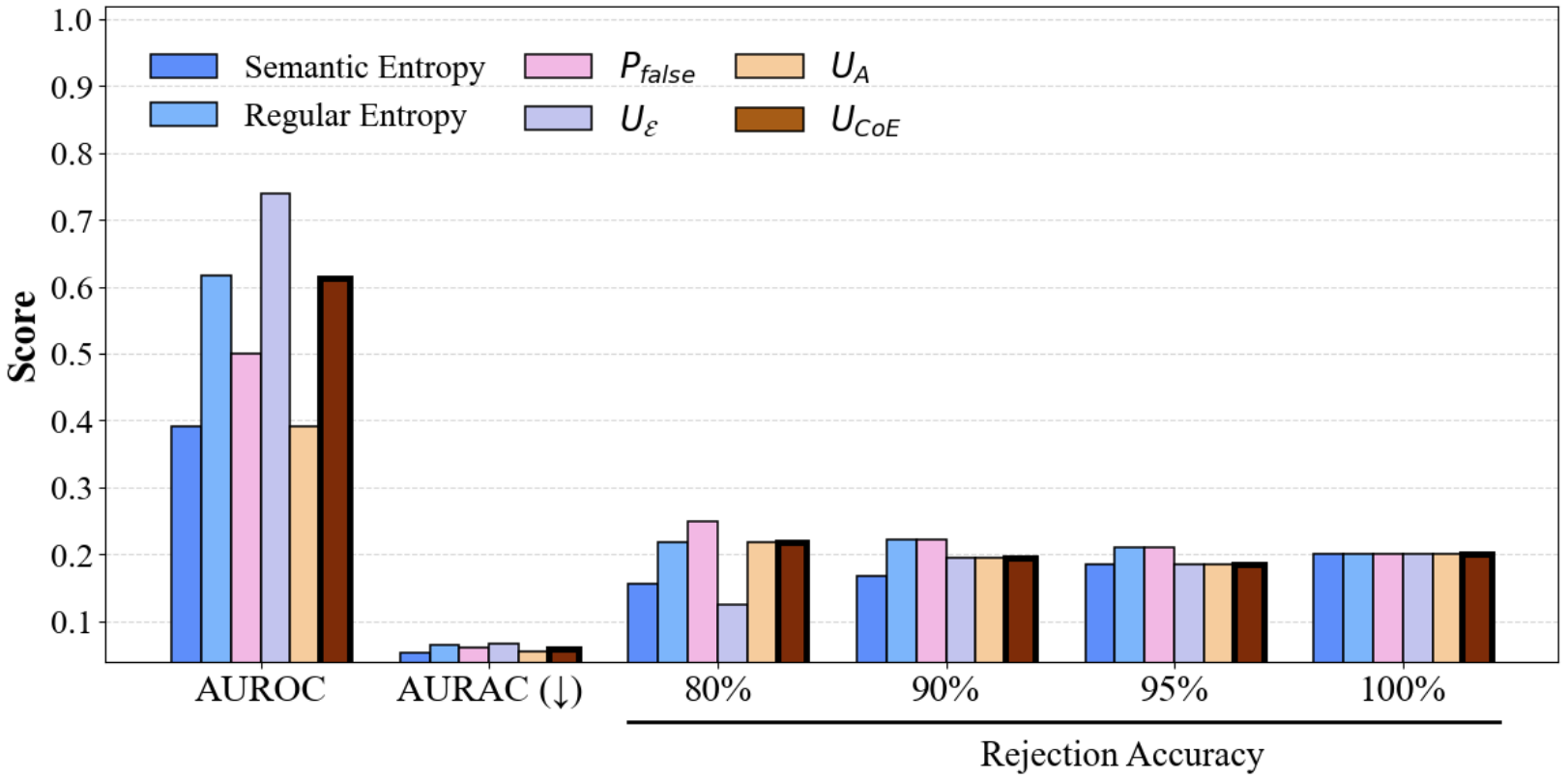
CoE substantially outperforms single-model and undifferentiated ensemble baselines, with improvements scaling as more heterogeneous models are included. For instance, on TriviaQA, CoE achieves an AUROC of 0.683 (2 models) and 0.772 (3 models), surpassing all baselines. Gains become more significant on SQuAD as well.
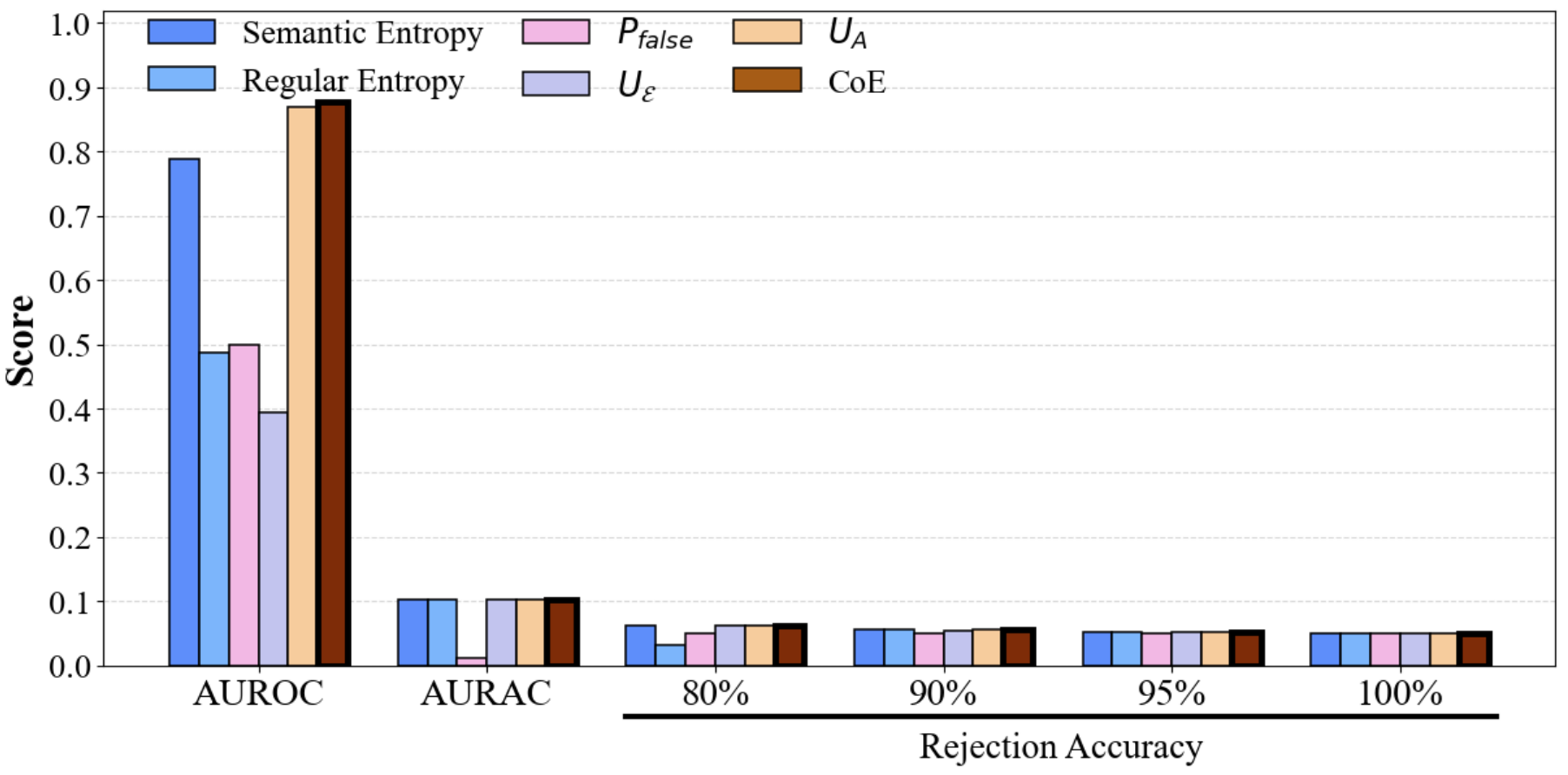
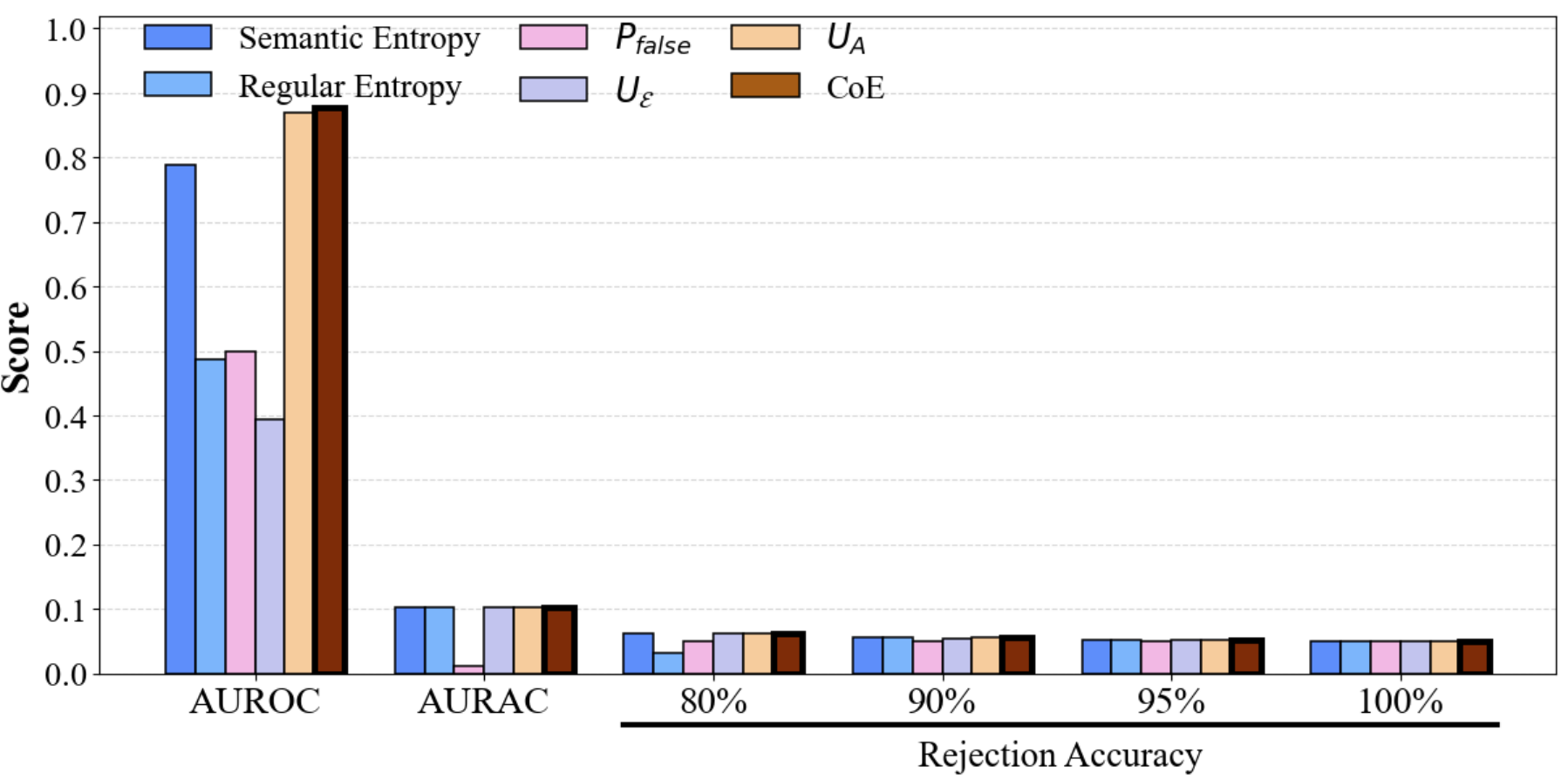
Figure 3: Performance comparison of CoE with different divergence metrics on TriviaQA (upper row: single models; lower row: multi-model ensembles, KL divergence).
Figure 4: Performance comparison of CoE with different divergence metrics on SQuAD, demonstrating consistent gains in AUROC/AURAC with increasing ensemble size.
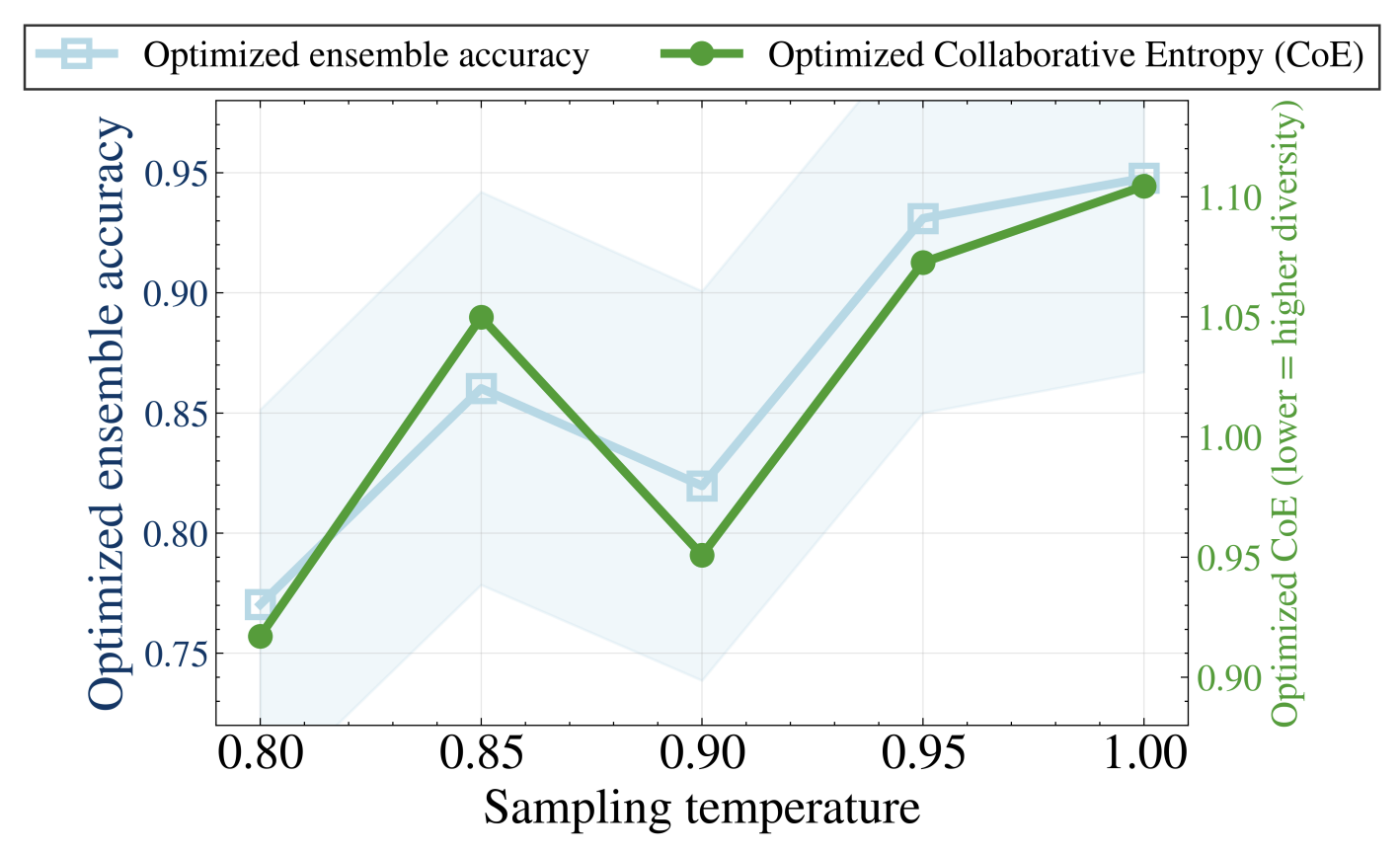
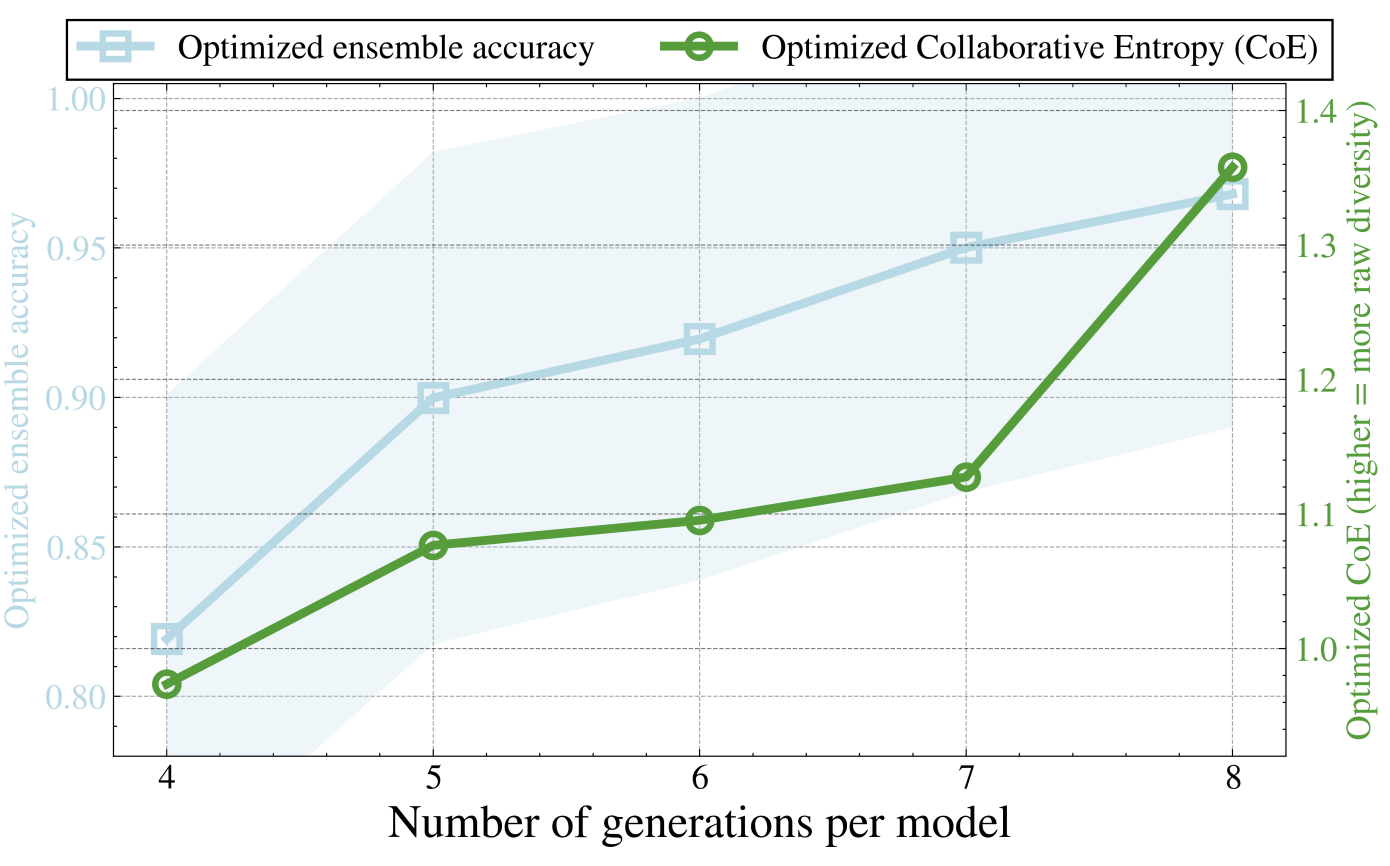
The superiority of CoE holds regardless of sampling temperature and generation count, and persists even for ensembles of more models.
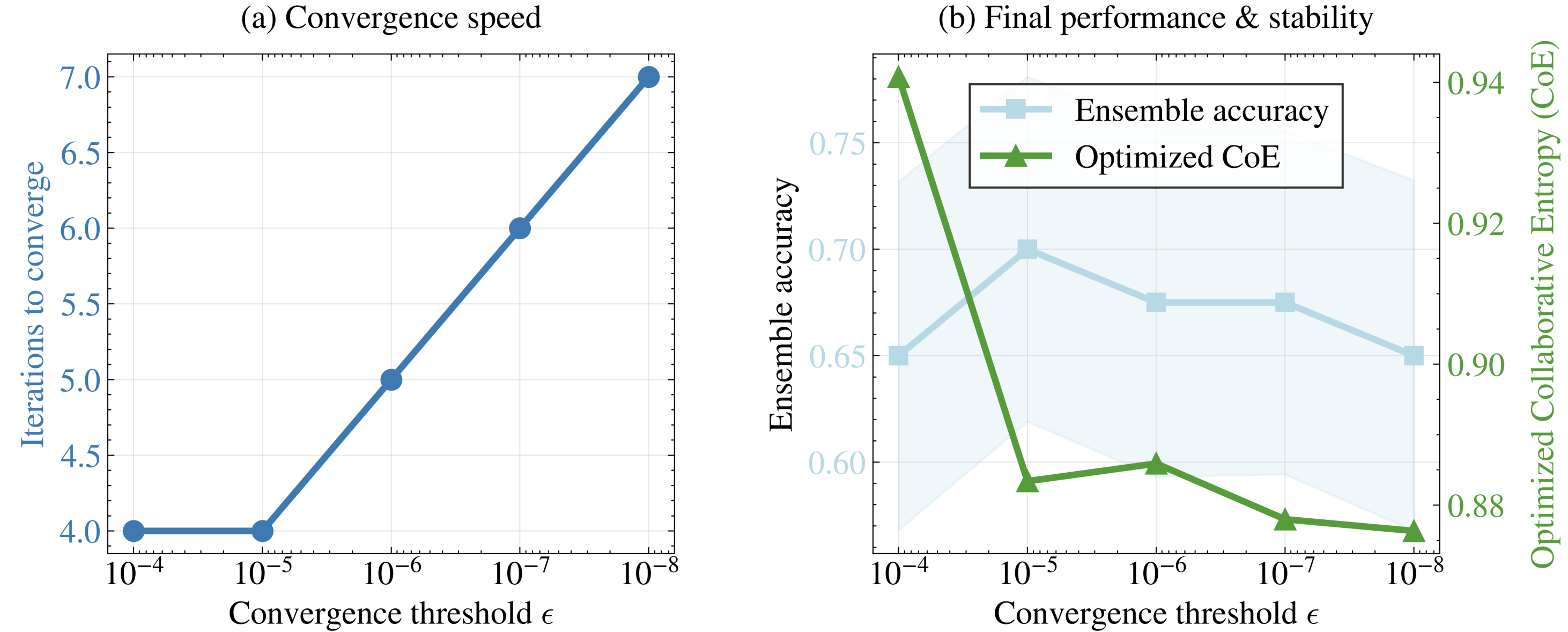
Figure 5: Robustness analysis of the CoE-guided algorithm under varying convergence thresholds UA1 (Llama + Qwen on TriviaQA).
Figure 6: Analysis of CoE-Reduction optimization algorithm under different temperatures and sample volumes, showing stable ensemble accuracy and decreasing final CoE.
Divergence Measures
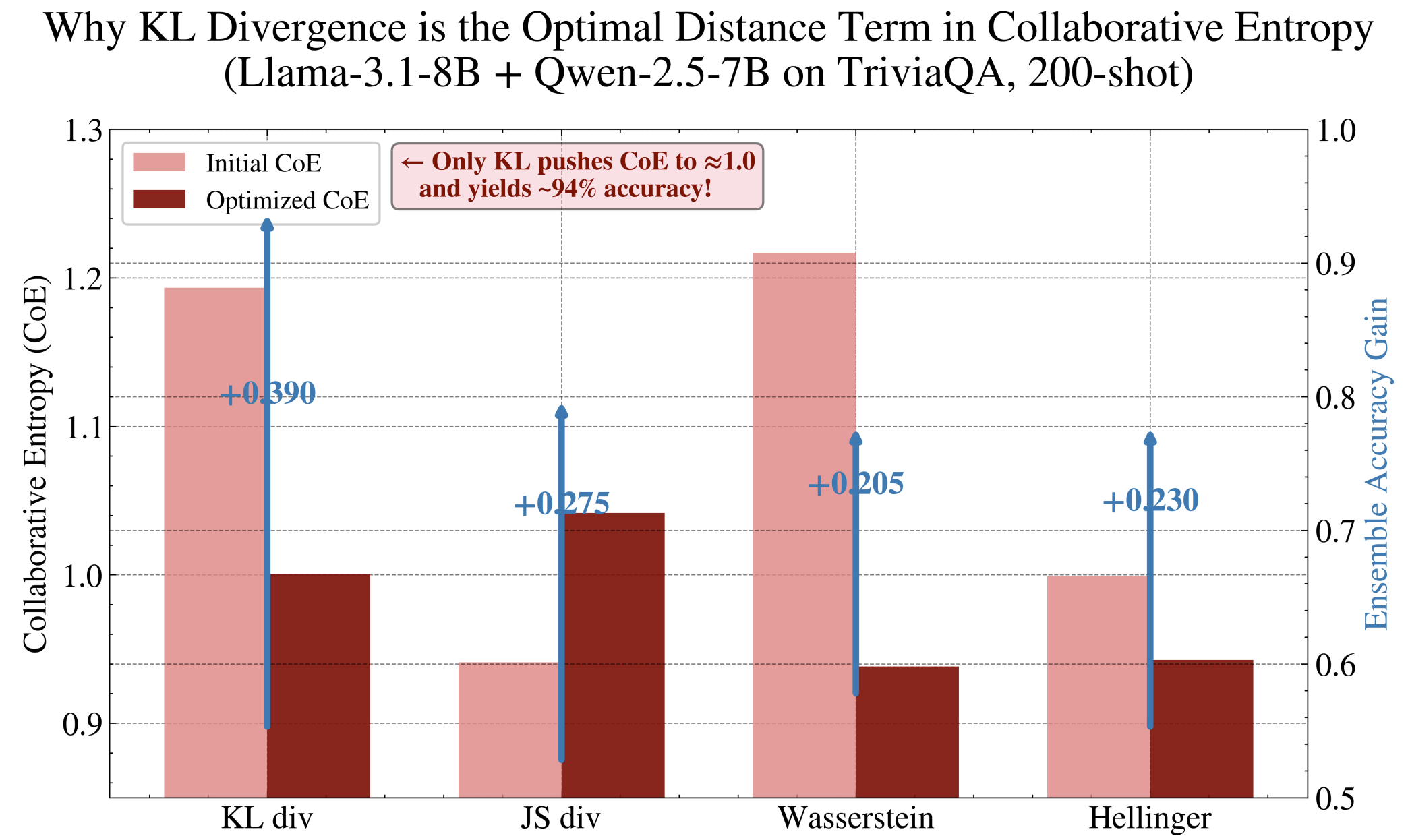
Ablation on divergence metrics (KL, JS, Hellinger, Wasserstein) shows that asymmetric KL divergence yields the best results, both in CoE reduction and accuracy gain, highlighting the importance of reference-directed epistemic quantification.
Figure 7: Accuracy gain and residual CoE after applying the CoE-guided heuristic under various divergence metrics. Asymmetric KL yields the largest accuracy gains and lowest residual uncertainty.
Heuristic Coordination
A practical, training-free CoE-guided inference-time heuristic is introduced. This iterative procedure reweights models based on entropy and confidence, focusing ensemble outputs by minimizing CoE. Its lightweight nature allows plug-and-play use in existing pipelines.
Implications and Limitations
Practical Impact
CoE furnishes a robust, diagnostic metric for uncertainty in agentic multi-LLM architectures. It identifies both optimizable (aleatoric) and irreducible (epistemic) sources, enabling targeted strategies for model coordination, abstention, and selective prediction. The minimal computational overhead and post-hoc applicability make CoE suitable for edge and production pipelines.
Theoretical Ramifications
The formal decomposition exposes when single-model entropy minimization is insufficient, establishing an analytic barrier to certainty due to irreducible epistemic divergence. This clarifies the failure modes of purely single-model-centric UQ metrics.
Limitations
The decomposition assumes that model-level aleatoric uncertainty is uncontaminated by epistemic factors—a simplification, as LLM hallucinations can inflate entropy. Additionally, KL-based inter-model divergence may be confounded by stylistic (not semantic) differences, motivating future work on semantic normalization.
Future Prospects
Scaling CoE to larger closed-source LLMs, leveraging generation frequency for probabilistic estimation, and integrating additional verbalized confidence signals will extend its utility. Application to multi-agent dialog systems and reasoning chains will further stress-test the interpretability and diagnostic power of the CoE framework.
Conclusion
CoE represents a principled advance in system-level uncertainty quantification for agentic multi-LLM orchestration. By explicitly decoupling intra-model and inter-model uncertainty, it provides precise diagnostics, robust selective prediction, and effective guidance for ensemble coordination. Its empirical superiority and theoretical clarity position it as a foundation for trustworthy, uncertainty-aware deployment of multi-LLM systems.
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.