- The paper introduces TerraSky3D, a meticulously curated 4K dataset combining ground, aerial, and mixed views of European landmarks to advance 3D reconstruction and localization.
- It employs rigorous pre-calibration, COLMAP-based sparse reconstruction, and APD-MVS dense depth estimation to achieve sub-pixel accuracy and superior geometric consistency.
- Results demonstrate that models retrained on TerraSky3D significantly outperform prior benchmarks, improving cross-view reasoning and performance in challenging mixed-view scenarios.
TerraSky3D: Multi-View Reconstructions of European Landmarks in 4K
Introduction and Motivation
The growth of high-fidelity vision models for 3D scene understanding, SfM, and MVS depends critically on the availability of accurate, richly annotated, and comprehensive datasets. Prior large-scale datasets, typically derived from uncontrolled internet photo sources, face persistent limitations—such as unresolved camera intrinsics, unrectified geometric artifacts, and lack of modality diversity—that inhibit robust generalization, particularly for mixed ground–aerial scenarios. TerraSky3D (2603.28287) directly addresses these gaps by providing a large-scale, meticulously curated collection of 4K ground, aerial, and mixed-perspective scenes, emphasizing European landmarks with rigorous calibration and geometric consistency. This enables benchmarking and training of models for cross-view reasoning, large-baseline reconstruction, and data-driven localization under practical deployment conditions.
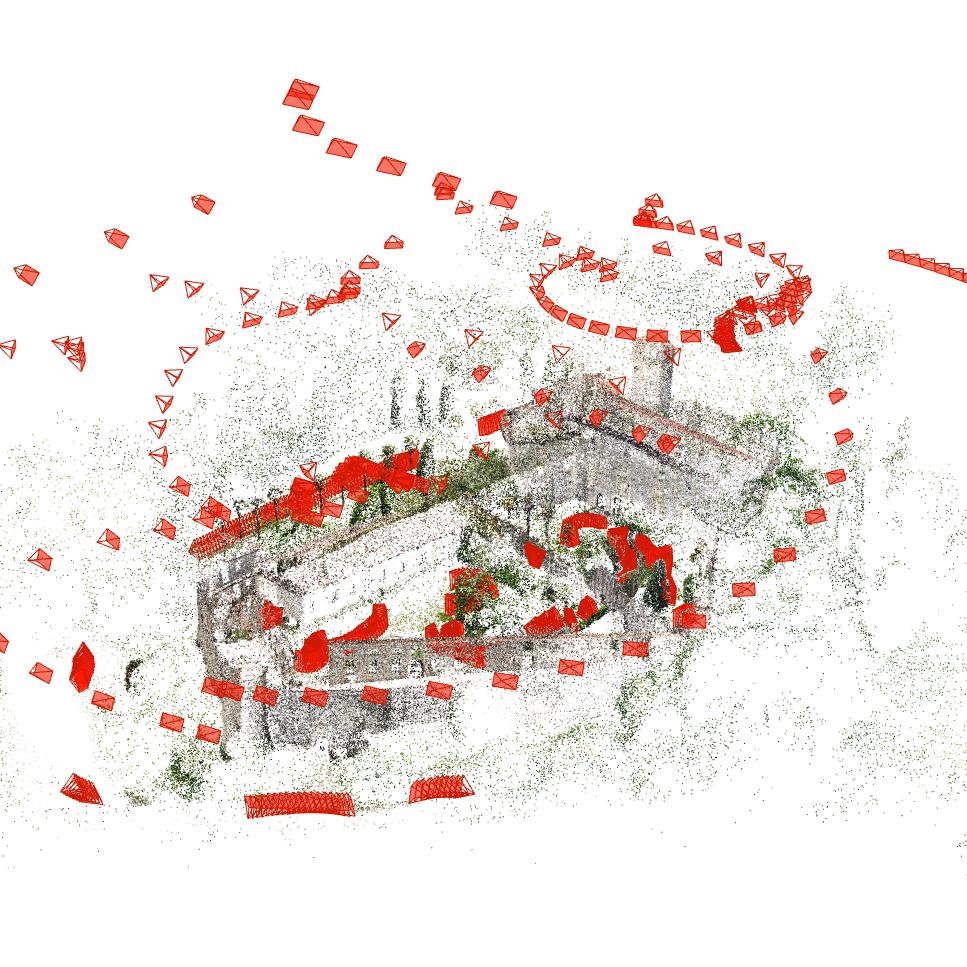








Figure 1: Example scene from TerraSky3D—sparse reconstruction of Villalta Castle, Italy, and representative images from aerial and ground perspectives, paired with semantically filtered depth maps.
Dataset Composition and Acquisition Pipeline
TerraSky3D comprises 150 scenes with over 50,000 post-processed images sampled from 4K/30fps video streams. Data is collected using consumer-grade smartphones (ground) and DJI Mavic 3 drones (aerial), ensuring angular and spatial coverage in all scenarios. Rigid pre-calibration with ChArUco boards and OpenCV produces sub-pixel intrinsic accuracy in the SIMPLE_RADIAL model. Of particular importance is the inclusion of 30 scenes with coregistered ground and aerial images—a modality combination largely absent in previous public datasets and essential for developing algorithms robust to extreme cross-view disparities.
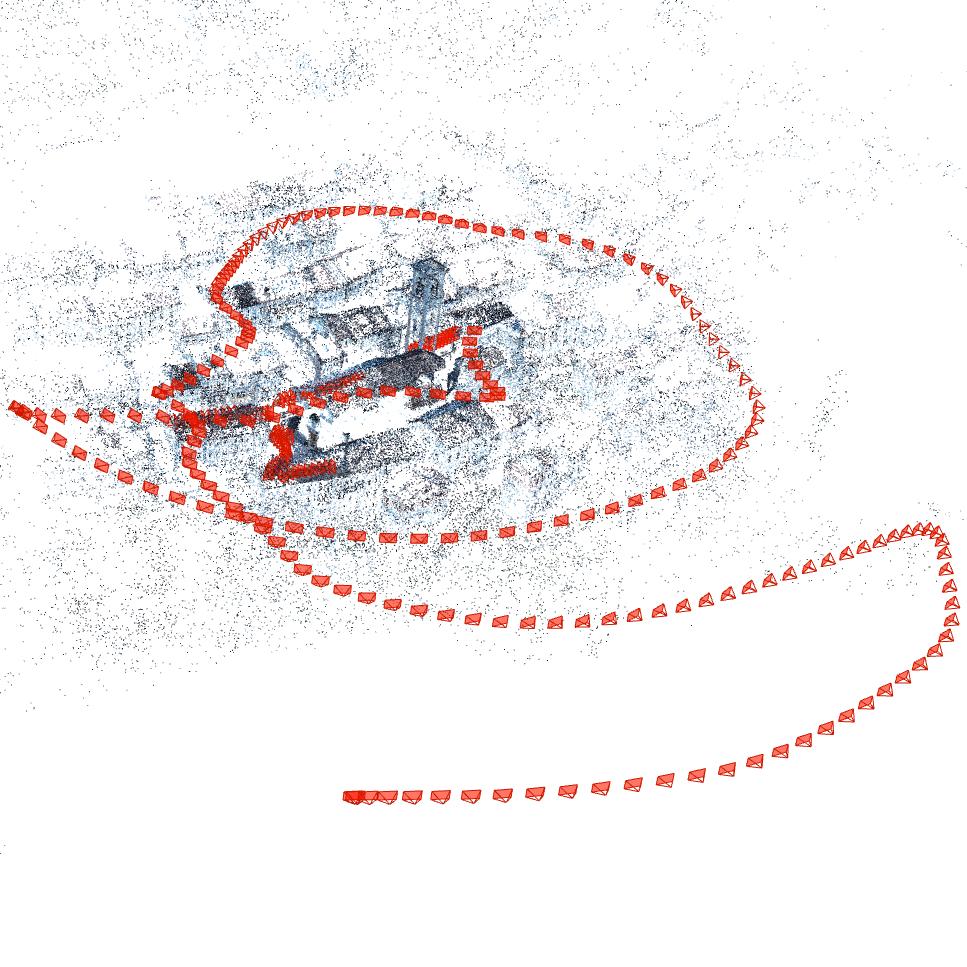
Figure 2: Geographical distribution of TerraSky3D’s data collection sites, spanning diverse architectural and environmental domains across 11 European countries.
Individual scenes encompass complex urban geometries, heritage structures, and bridges, facilitating evaluation of models in challenging real-world settings. TerraSky3D also releases all COLMAP project files, sparse reconstructions, dense APD-MVS depth maps, and semantic masks.
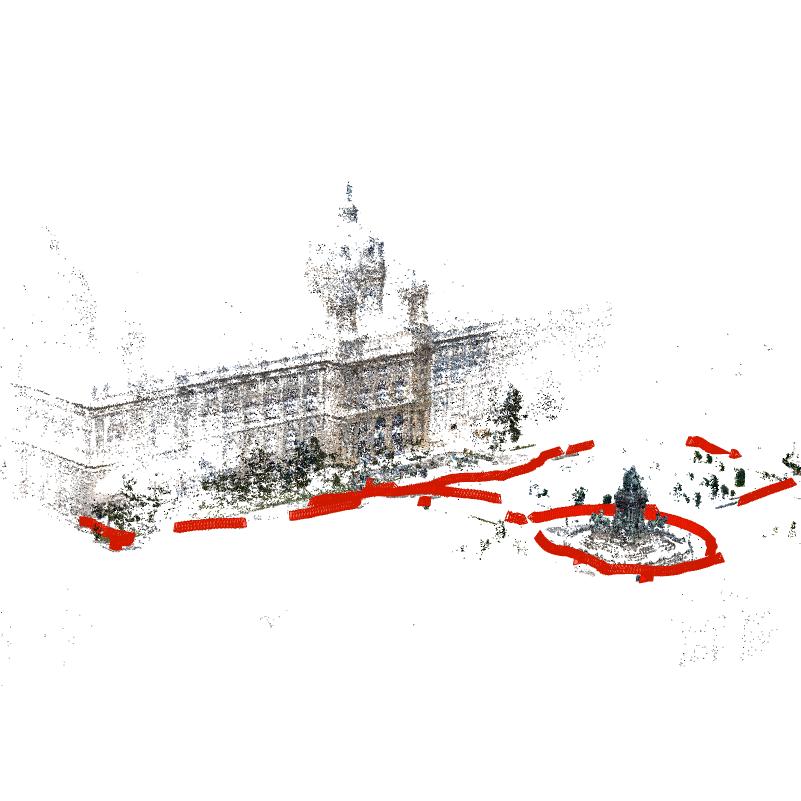








Figure 3: Sparse reconstruction and paired high-resolution RGB and semantically filtered depth maps from the Natural History Museum, Vienna—demonstrating geometric detail and cross-modality.
Generation of Geometric Ground Truth
For 3D structure estimation, the pipeline maintains strict quality standards through:
- Pre-calibrated image intrinsics
- COLMAP-based sparse reconstruction with manual QA
- Dense depth estimation using APD-MVS, which dynamically adapts its matching field to maximize geometric quality, particularly in low-texture zones.
Post-processed depth maps undergo semantic filtering: Mask2Former segments out sky, vegetation, and non-static elements, and APD-MVS confidence masking further prunes unreliable regions. The evaluation indicates a mean reprojection error of only 0.8 pixels over the full dataset.

Figure 4: Depth filtering workflow—raw RGB, APD-MVS depth, semantic mask, confidence mask, and final filtered depth for a challenging mixed-view outdoor scene.
Comparative Analysis with Existing Benchmarks
Distinct advantages over prior datasets include:
- Verified camera calibrations (as opposed to unreliable per-image intrinsics estimated from unconstrained datasets)
- Consistent 4K spatial resolution and aspect ratio
- Large proportion of scenes with both ground and aerial views, directly supporting cross-view/generalization research
- Real (not rendered) aerial imagery
For example, in contrast to MegaDepth and MegaScenes, TerraSky3D’s image set does not rely on internet scraping. Compared to mixed-view benchmarks like AerialMegaDepth and University-1652, it eliminates domain gaps arising from synthetic renderings or unverified Google Streets imagery.
Quantitative Evaluation and Model Benchmarking
Pairwise and Absolute Pose Estimation
The dataset is used to extensively benchmark both sparse keypoint- and dense matcher-based models. Across 43,000 test image pairs (ground, aerial, and mixed), recent methods such as RoMa and LightGlue achieve maximum AUC@5∘ of 82.1 and 67.5 (mean of all scenarios), respectively, with clear evidence of performance degradation in the mixed aerial-ground case—a key finding underlying the value of the dataset for pushing method robustness.
Remarkably, models retrained on TerraSky3D (e.g., SANDesc) achieve a significant 1.8-point improvement over MegaDepth-based counterparts in the mixed scenario without loss of accuracy in ground or aerial. This demonstrates the utility of TerraSky3D for advancing cross-view learning.
End-to-End Structure-from-Motion
Learning-based pipelines (VGGT, π3, MapAnything) are evaluated on relative pose accuracy. VGGT achieves the highest average AUC@5∘ (49.7) and stable performance across challenging mixed and wide-baseline scenarios, whereas π3—despite peak scores on certain scenes—suffers catastrophic failures in geometric instability for others, revealing limits in current architecture robustness.
Novel View Synthesis
3DGS-based NVS is evaluated under LPIPS, PSNR, and SSIM metrics, with test-set PSNRs in the 19–24.5 dB range and LPIPS indicating strong visual fidelity. Mixed-view scenes, as expected, exhibit lower SSIM/PSNR due to aggressive viewpoint diversity, highlighting their utility for evaluating NVS methods beyond street-level or aerial-only datasets.
Geometric Consistency
A bidirectional reprojection consistency analysis against MegaDepth test scenes shows TerraSky3D yields higher inlier ratios (e.g., 51.4% vs. 43.0% at 1 px error), indicating superior geometric quality and lower noise in practical downstream supervision or evaluation tasks.
Illustrative Qualitative Diversity
Additional examples depict the range of urban and landmark architectures captured, combining ground and aerial geometry.








Figure 5: Scene showing multimodal geometry at the Italian Charnel House—capturing complex facades and topography.







Figure 6: Mixed-view 3D reconstruction and imagery for the Barcis Dam, illustrating the utility of cross-viewpoint ground truth for real-world multi-modal problems.
Technical Limitations
TerraSky3D, while advancing the field, does not remove all sources of real-scene acquisition error. Motion blur, imperfect semantic masks in fine or transparent structures, and limitations in depth quality where multi-view coverage is inherently constrained are acknowledged. The public release of APD-MVS confidence maps and complete data ensure downstream users can filter for the highest-fidelity regions as application demands dictate.
Implications and Future Outlook
TerraSky3D provides an immediately impactful benchmark for the evaluation and training of models targeting robust cross-view (ground–aerial) scene understanding, wide-baseline reconstruction, and geometry-grounded vision tasks. Its integrated 4K image and dense depth corpus enables quantitative advances in feature extraction, pose regression, NeRF/NVS, and downstream sequence alignment for robotics, AR, and digital twin applications.
By exposing the clear weakness of current models in mixed-view scenarios, the dataset motivates further architectural innovation in permutation-equivariant, cross-perspective, and large baseline-localization systems. The inclusion of spatially registered, high-resolution, real-world landmark imagery will facilitate rapid progress in geographically grounded computer vision and interpretable geometric deep learning.
Conclusion
TerraSky3D (2603.28287) constitutes a significant advance in 3D computer vision benchmarks by supplying a broad, high-fidelity, and modality-rich dataset with explicit, high-quality geometric supervision. It closes key gaps in existing resources, specifically with respect to real-world cross-view (aerial-ground) scenarios, and paves the way for both incremental and structural breakthroughs in wide-baseline generalization, robust deep feature extraction, and multi-modal 3D scene understanding. The immediate observation that leading models underperform in mixed-view settings underscores the pressing need for new methodological directions uniquely enabled by this resource.