- The paper introduces a technology-agnostic, hierarchical netlist optimization framework that integrates architectural exploration with standard-cell-aware logic synthesis to achieve global optimization under user-defined constraints.
- The paper demonstrates that strategic hybrid insertion of Ling nodes reduces delay by 16–20% with a marginal area cost, leading to a 10–14% improvement in the area–delay product.
- The paper validates AXON through extensive benchmarking against commercial synthesis and classical adder designs, revealing superior delay, area, and power performance across various benchmarks.
AXON: Automated Netlist Optimization for High-Speed Adders
Introduction
The paper "AXON: An Automated Netlist Optimization Framework for High-Speed Adders" (2603.28184) addresses the inefficiencies and suboptimality endemic to current adder design flows. Adders are critical in datapaths and define the spectral performance envelope for CPUs, DSPs, and accelerators. While parallel-prefix architectures (Kogge–Stone, Brent–Kung, Sklansky, Han–Carlson, Ling) define the design space for high-performance adders, practical architecture selection is constrained by heuristic, experience-driven, and tool-flow limitations. Existing academic efforts focus predominantly on topology search absent netlist-level and technology mapping optimization, while commercial EDA tools lack adder-specific logic synthesis strategies.
This work introduces AXON, a technology-agnostic, hierarchical netlist optimization framework that unifies architectural exploration with standard-cell-aware logic synthesis, producing globally optimized netlists for high-speed adders under user-defined delay, area, and power constraints.
Background: Parallel-Prefix Adder Trade-Offs
Classical parallel-prefix adder structures deliver logarithmic-depth carry computation through prefix trees, balancing area, wirelength, and delay. Kogge–Stone architectures (minimal depth, high area), Brent–Kung (folded topology, moderate depth/area), Sklansky (minimal depth, maximal wire congestion), and Han–Carlson/Ling variants position themselves at different PPA envelopes.
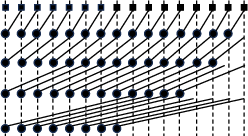
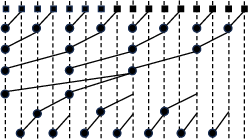
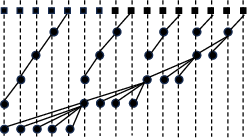
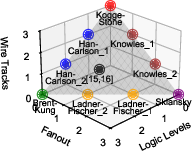
Figure 1: Kogge–Stone structure exemplifying minimal logic depth via regular prefix tree topology.
Classical adder architectures are heuristically constructed and sample only a sparse subset of the exponential topology design space. Design space optimality cannot be guaranteed for practical area, power, or timing constraints, particularly at advanced nodes with aggressive PPA requirements.
AXON Framework: Hierarchical Netlist Optimization
AXON performs joint architectural-netlist exploration as illustrated below.
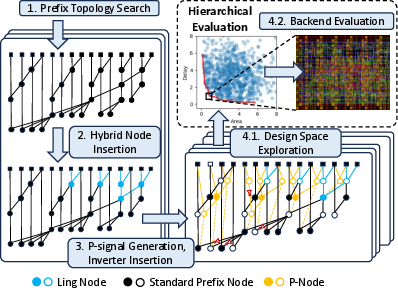
Figure 2: AXON overview showing hierarchical search from prefix topology to standard-cell-level netlist, including hybrid node insertion and inverter placement optimization.
The AXON pipeline operates in four stages:
- Prefix Topology Search: Topology enumeration is seeded by a depth-first algorithm [Roy et al. 2016] targeting minimal-node trees under fanout and logic depth constraints.
- Hybrid Node Insertion: Ling nodes are selectively deployed along the critical path, enabling lower logic depth through alternative propagate logic. Prefix/Ling interconversion is formalized, permitting fine-grained control over depth/area trade-off.
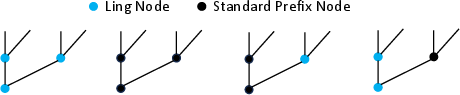
Figure 3: Standard prefix vs. Ling node conversion details, enabling selective deployment within a topology.
- Propagate Network and Inverter Insertion: The propagate (P) signal network is synthesized on demand, avoiding redundant computation. Signal polarity mismatches caused by cell-level mappings (e.g., AND/OR vs. NAND/NOR implementations) are detected, and inverter insertion is strategically optimized to minimize delay and area. Multi-mismatch clusters are decomposed to allow tractable exhaustive search over inverter placements.
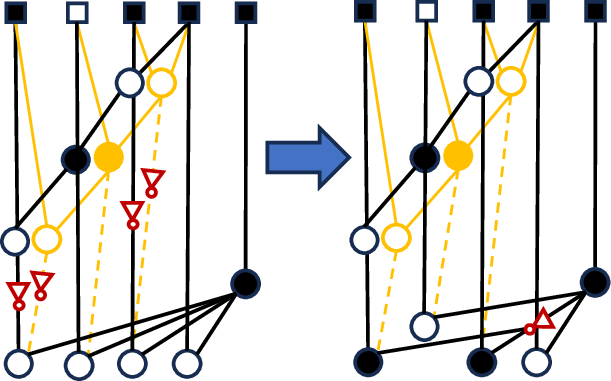
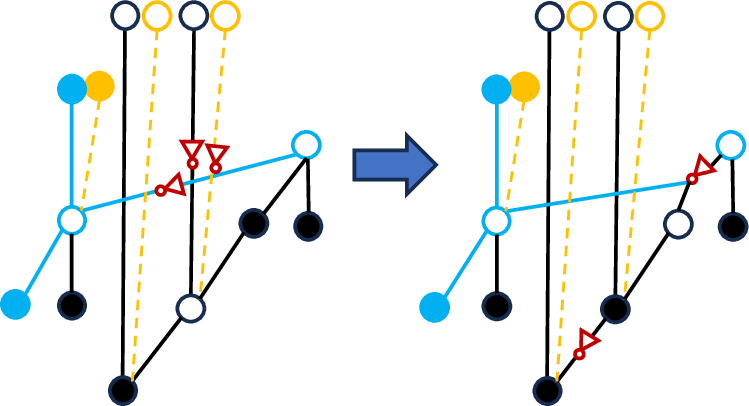
Figure 4: Examples of inverter insertion strategies and their impact on polarity and delay for a prefix network.
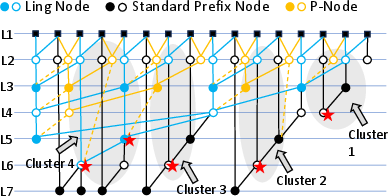
Figure 5: Cluster decomposition for inverter insertion, constraining search complexity and isolating polarity domains.
- Hierarchical Evaluation and Selection: Rapid logic-level coarse estimation (delay, area, via simplified FO1 and transistor counting) prunes the candidate set, followed by full physical APR for elite candidates. This two-stage strategy balances search tractability with implementation fidelity.
Results: Analytical and Empirical Evaluation
Hybrid Parallel-Prefix and Ling Nodes
Injecting Ling nodes along critical paths yields 16–20% delay reduction at a marginal area cost (≤9.2%), leading to 10–14% ADP improvement. AXON optimally targets critical regions for Ling insertion, while peripheral nodes retain standard prefix logic for area efficiency.
Design Space Exploration
A combinatorial design space (prefix structure, propagate network, inverter placement) is thoroughly explored, generating tens of thousands of candidate netlists per benchmark (16/23/31/32-bit widths).
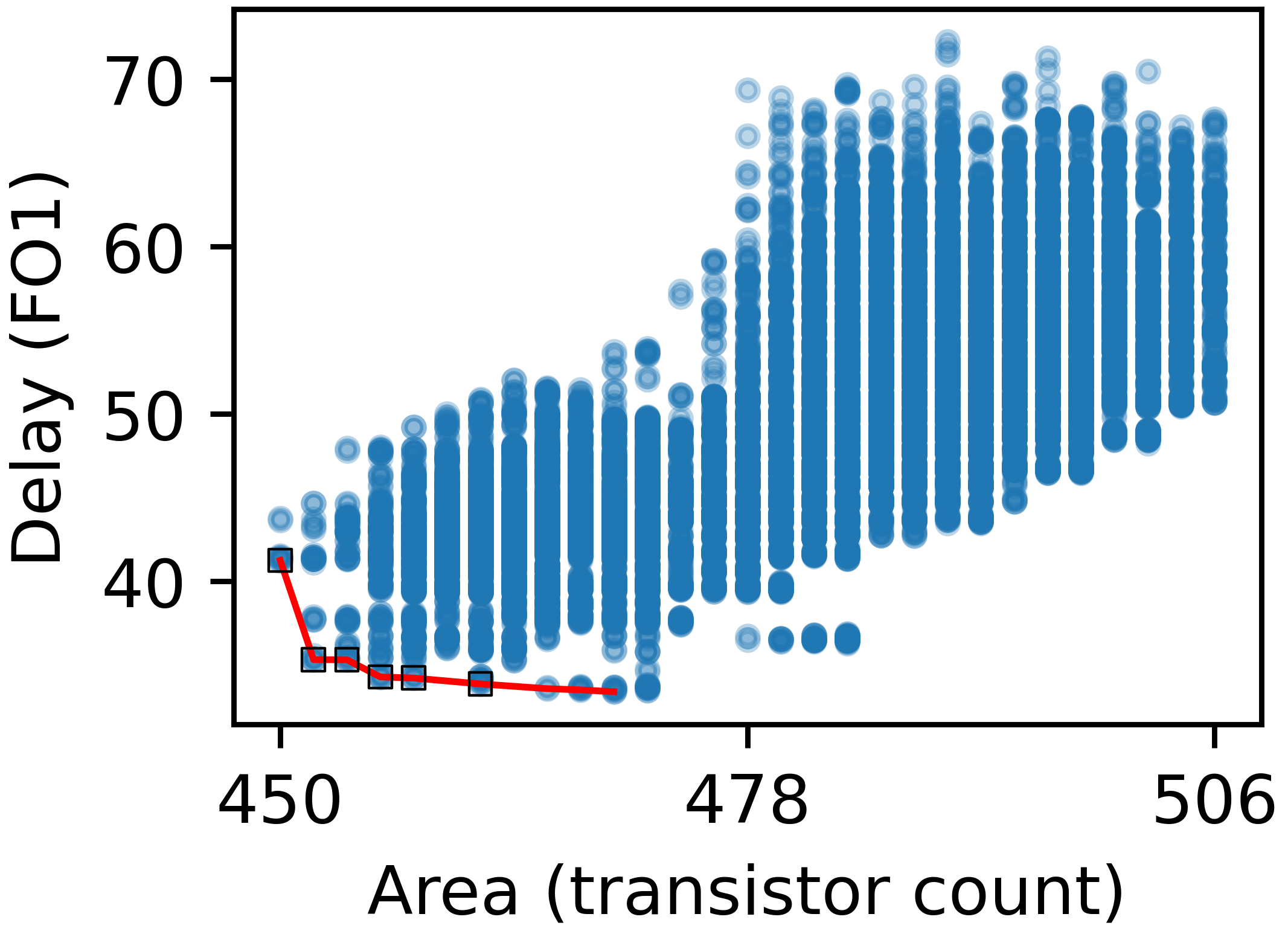
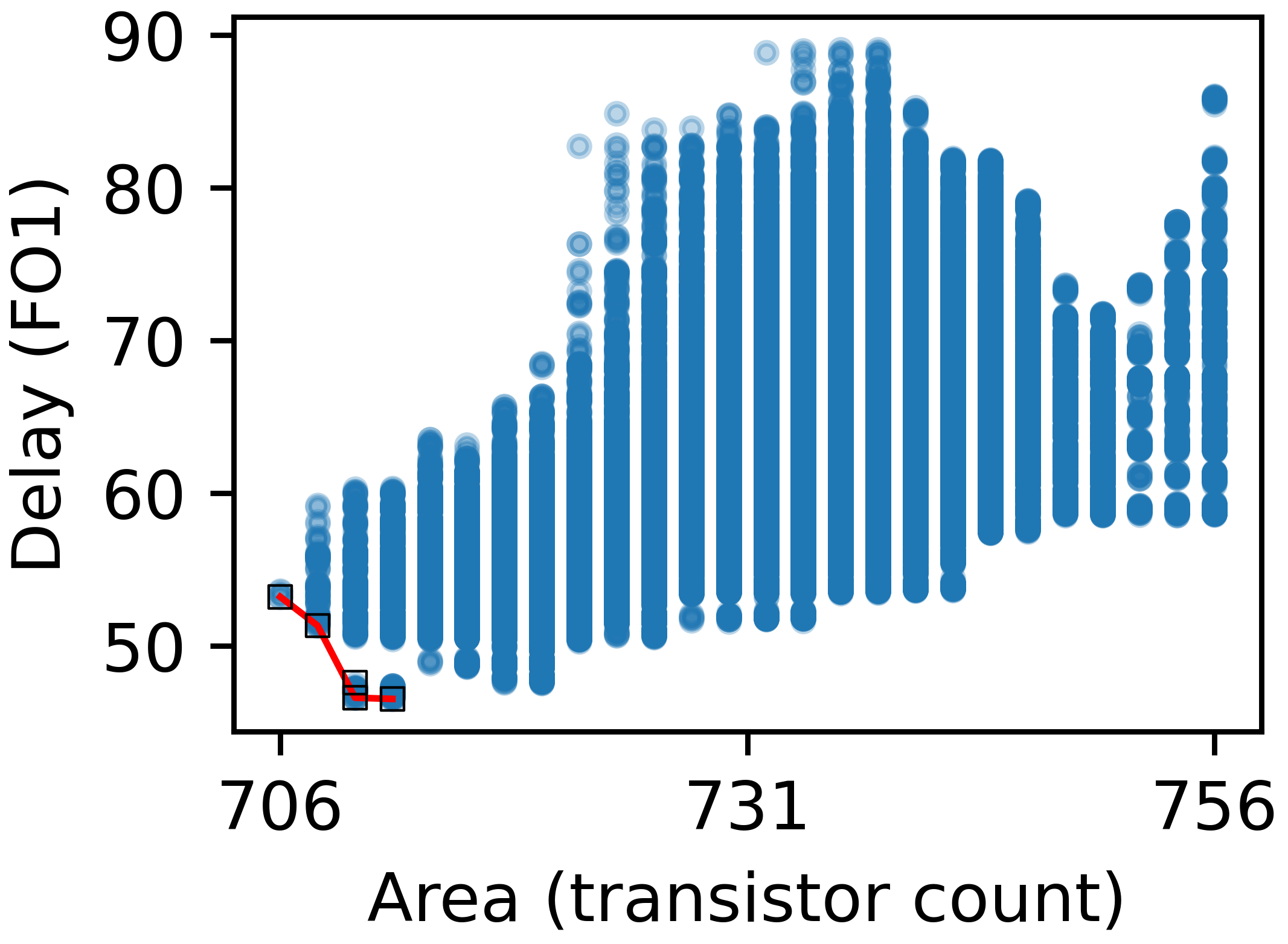
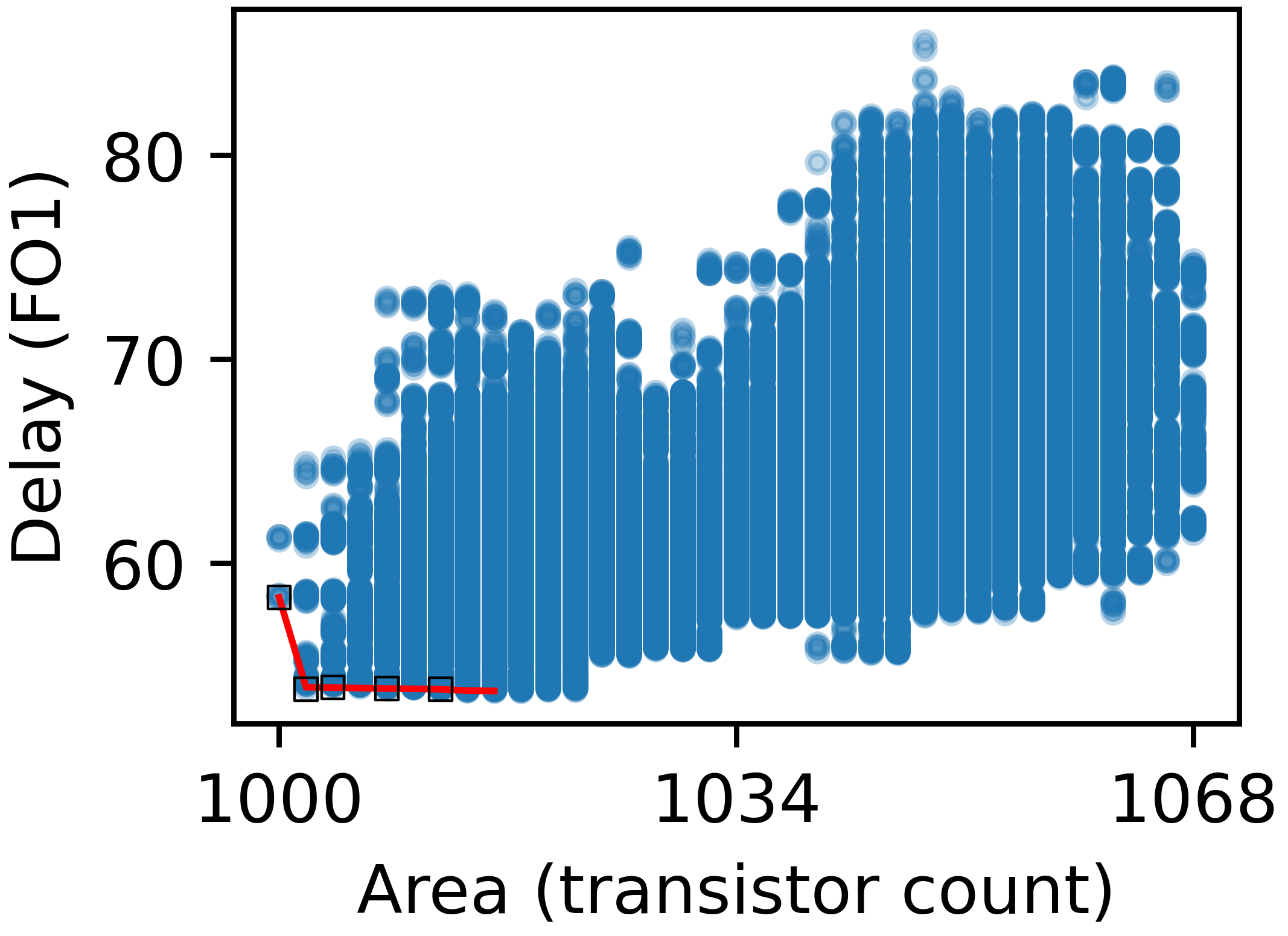
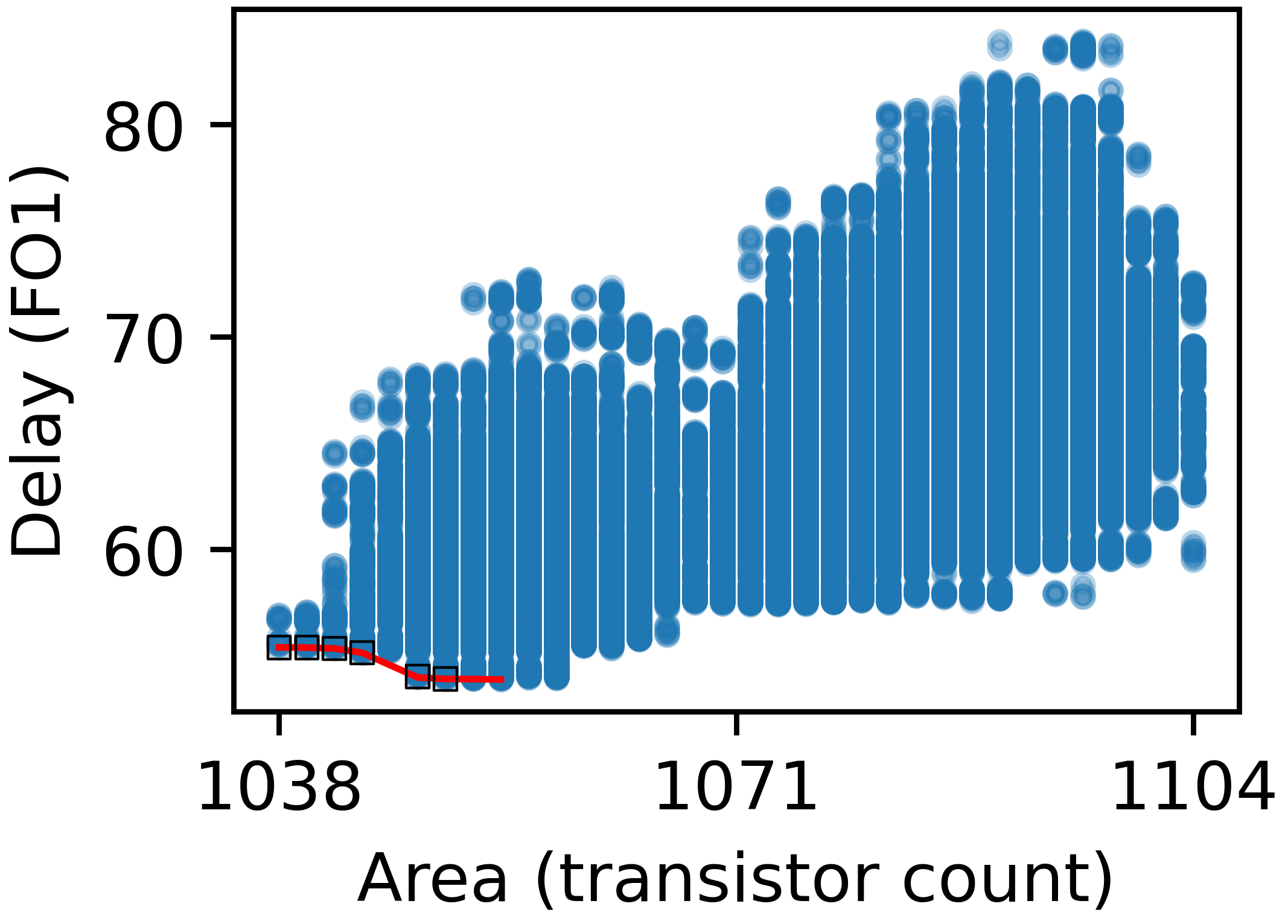
Figure 6: Scatter plot visualization for 16-bit design space, revealing substantial intra-space delay/area variation governed by P-network and inverter strategy.
The delay spread, even with identical logic node counts, can exceed 50%, verifying the necessity of full-netlist optimization as performed by AXON.
Post-Synthesis and APR Benchmarking
AXON-optimized netlists are compared to:
- Commercial synthesis of plain "A+B" RTL.
- Commercial synthesis of minimal-node prefix adders (per [Roy et al. 2014, 2016]).
- Classical manually generated Kogge–Stone, Sklansky, Brent–Kung, Han–Carlson variants.
Quantitative outcomes:
- AXON reduces delay by 9.9–24.2% versus "A+B" RTL, and up to 10.3% versus minimal-node topologies, at equivalent or lower area for large designs.
- Area–delay product (ADP) improves up to 12.6%; energy–delay product (EDP) by up to 32.1%.
- AXON surpasses Pareto envelopes defined by commercial synthesis and all classical prefix adders for each evaluated PPA metric.
Practical and Theoretical Implications
AXON demonstrates that co-optimization across topology, propagate network, and gate-level implementation is essential for extracting maximum performance from modern standard-cell libraries. The hybrid Prefix–Ling model enables adaptive PPA tuning, previously infeasible with monolithic prefix logic. By factoring in downstream mapping and netlist arrangement, AXON exposes optimal designs overlooked by both manual and tool-driven flows.
From a practical standpoint, AXON provides a path for automated generation of adder IP blocks optimized for both high-throughput (datacenter ASIC/CPU/GPU) and low-power (edge/MCU/accelerator) deployments. The methodology naturally generalizes to other arithmetic circuits constructed with prefix logic (e.g., multipliers, counters).
The theoretical implications include a reaffirmation of the exponential richness in the adder design space and the necessity for exhaustive, multi-level search—with logic synthesis and physical realization tightly integrated into early architectural decision processes.
Speculation on Future Developments
Advancement paths include:
- Extension of AXON's hybridization logic to other high-performance arithmetic blocks.
- ML-guided heuristics to accelerate candidate pruning and Pareto frontier identification in even larger design spaces.
- Integration with technology-specific cell library profiling for node-type and polarity-aware adder construction.
- Plug-and-play extensions within EDA flows, providing rapid evaluation for arbitrary PPA objectives.
Conclusion
AXON establishes a rigorous, automated pipeline for high-performance adder design, fusing architectural and netlist-level innovation with practical technology mapping. By systematically exposing the architectural and cell-level design space, AXON achieves significant improvements across delay, area, and power envelopes compared to both commercial and canonical adder design approaches. These results exemplify the critical role of structured, multi-level optimization in modern logic synthesis and point toward future automated circuit generation paradigms for arithmetic-intensive domains.