- The paper shows that incorporating a Hybrid Ensemble Decoder improves prediction diversity and achieves a 6.2 absolute mAP gain at 10-shot on challenging benchmarks.
- The paper demonstrates a unified progressive fine-tuning strategy that prevents overfitting and stabilizes convergence under cross-domain shifts.
- The approach leverages minimal architectural adjustments to optimize pre-trained transformer detectors without increasing model complexity or parameter count.
A Closer Look at Cross-Domain Few-Shot Object Detection: Fine-Tuning Matters and Parallel Decoder Helps
Introduction
The paper "A Closer Look at Cross-Domain Few-Shot Object Detection: Fine-Tuning Matters and Parallel Decoder Helps" (2603.28182) systematically addresses the limitations posed by few-shot object detection (FSOD) under cross-domain scenarios. Few-shot adaptation for object detectors typically suffers from overfitting, unstable optimization, and poor generalization, especially when faced with significant distribution shifts. Current SOTA methods often rely on computationally expensive data augmentation or foundation model scaling. This work advances the field by introducing a hybrid ensemble decoder (HED) and a unified progressive fine-tuning strategy that make model adaptation both more effective and robust, without increasing parameter count or reliance on data generation modules.
The cross-domain FSOD setting is formally defined as the task of detecting novel object categories given a handful of annotated examples (1/5/10 shots), with the additional requirement that novel classes and downstream datasets may be from visual domains substantially different from upstream natural image data. The challenge is thus tri-fold: scarcity of training data, domain shift, and intrinsic model brittleness during transfer.
The foundation of the proposed approach is modern DETR-style transformer detectors, such as MMGroundingDINO (MMGDINO), which already exhibit reasonable zero-shot transfer. Baseline analysis in the paper demonstrates that while simple data augmentation combined with adaptive learning rate scheduling forms a strong baseline, further improvement necessitates structural and procedural innovations.
Hybrid Ensemble Decoder (HED)
The Hybrid Ensemble Decoder reformulates the standard fully sequential DETR decoder as a partially parallelized architecture. After several shared hierarchical refinement layers, multiple parallel decoder branches are instantiated. Each branch receives either inherited denoising queries from previous layers or randomly initialized denoising queries, enhancing stochasticity and predictive diversity.
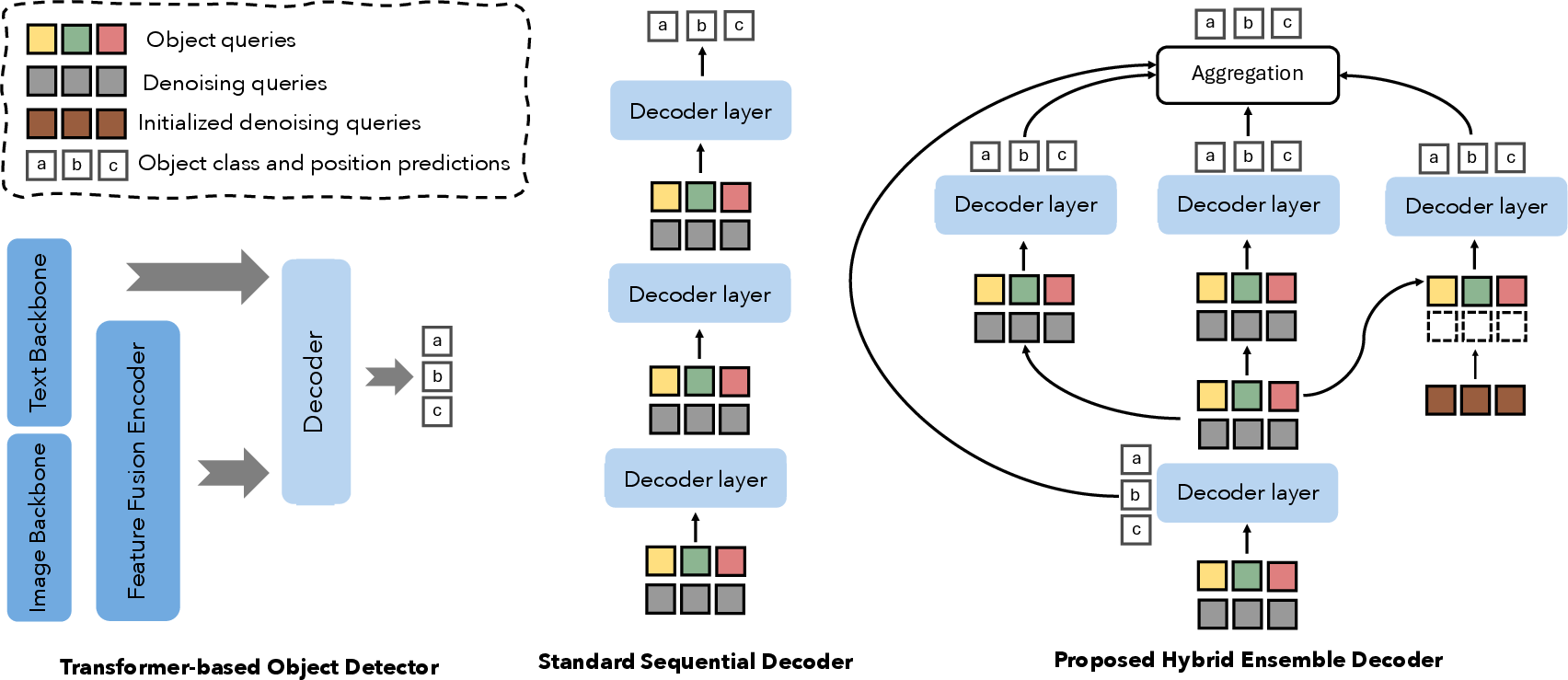
Figure 1: Overview of the hybrid ensemble decoder; parallelized decoder layers aggregate predictions derived from both inherited and randomly re-initialized denoising queries, promoting diversity without adding parameters.
This ensembling scheme is central: it enables the aggregation of multiple complementary decoder predictions, capitalizing on the diversity induced by input-level stochasticity and the inherent differences in pretrained decoder layer weights. Empirical studies confirm that a hybrid configuration (one hierarchical + several parallel layers, denoising query τ>0) is optimal in balancing semantic stability and diversity.
Numerical Results
The HED yields significant gains in mAP across benchmarks. On CD-FSOD, it consistently outperforms prior methods, and on ODinW-13 and RF100-VL benchmarks, it matches or exceeds the performance of much larger or closed-source SOTA detectors such as SAM3 and GroundingDINO 1.5 Pro.
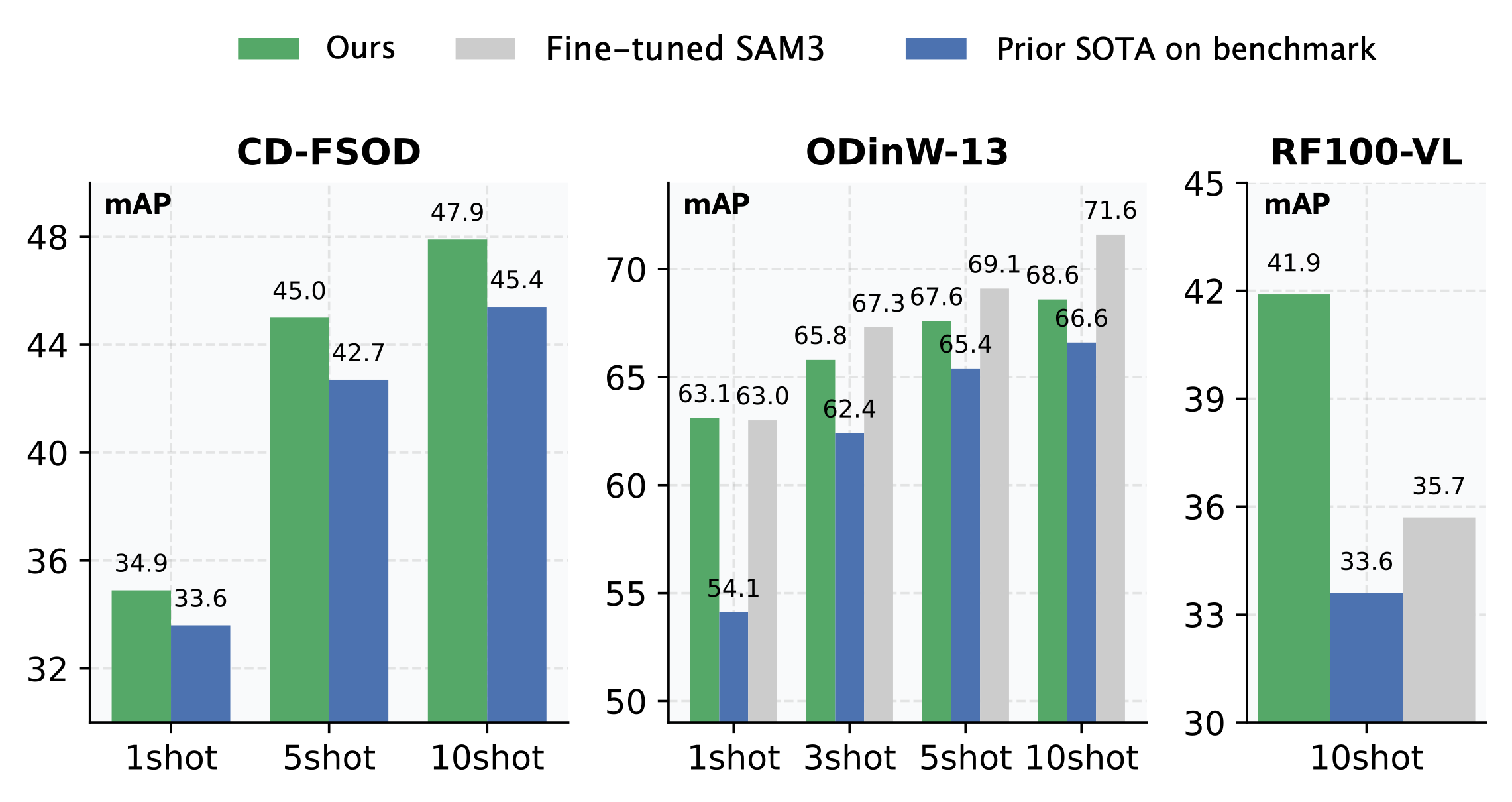
Figure 2: Large-scale cross-domain FSOD benchmarking: the proposed method with MMGDINO surpasses Domain-RAG and is competitive with or exceeds fine-tuned SAM3 models.
Unified Progressive Fine-Tuning
Progressive fine-tuning is implemented as a two-stage protocol: an initial phase where the backbone is frozen followed by end-to-end fine-tuning, with transitions governed by a plateau-aware scheduler. This avoids catastrophic overfitting and enables more stable convergence—especially pertinent with extremely limited annotated data. Data augmentations are kept deliberately simple (mixup, flipping, color jitter) to avoid overfitting to dataset-specific artifacts.
The efficacy of this streamlined fine-tuning strategy is supported by extensive ablations showing non-trivial gains over baseline and single-phase fine-tuning approaches.
Robustness Under Domain Shift
The compositional nature of the HED, with stochastic denoising query injection, substantially improves both generalization and model calibration under out-of-distribution (OOD) shift. This is validated by evaluating on a synthetically constructed mixed-domain OOD test set derived from the CD-FSOD datasets.
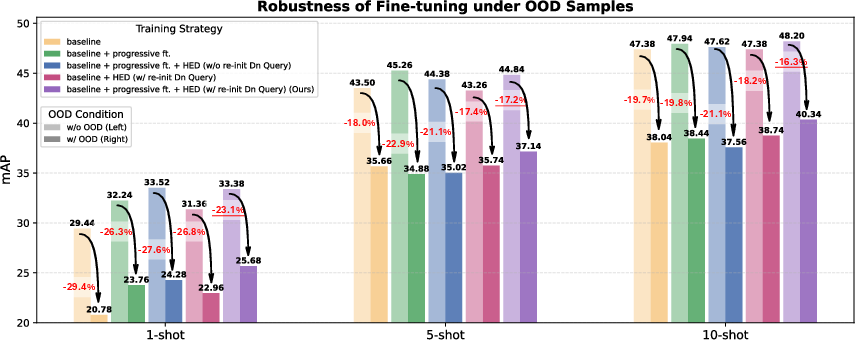
Figure 3: Performance reduction under OOD shift for various fine-tuning strategies. Input diversity via denoising query re-initialization and decoder layer parallelization exhibit the smallest degradation, i.e., best OOD robustness.
Results show that the hybrid ensemble decoder with random denoising initialization exhibits the lowest OOD performance drop and avoids overconfident false positives—a critical requirement for real-world semi-automated labeling and open-world detection systems.
While prior FSOD works often leverage meta-learning, large-scale data augmentation, or vision-language pretraining, these techniques either increase the parameter count, model complexity, or computational requirements. The contribution herein is orthogonal: exploiting and optimizing the pretrained foundation model's intrinsic capacity with no additional parameters or model heads, only minor architectural manipulations and training procedure optimization.
Notably, the HED achieves an average of 41.9 mAP@10shot on the challenging RF100-VL benchmark—a 6.2 mAP absolute improvement versus prior SOTA (SAM3 at 35.7).
Practical and Theoretical Implications
From a practical perspective, the approach enables robust few-shot adaptation for object detection across heterogeneous, real-world domains (e.g., medical, industrial, document images) with generic, reproducible training pipelines and without engineering overhead. Theoretically, the results reinforce the necessity of ensembling for predictive diversity and calibration in the FSOD regime, and suggest that optimal transfer requires balancing adaptation (via progressive fine-tuning) with robustness (via decoder input/structure diversity).
Future Directions
Future avenues include the integration of more principled uncertainty quantification for FSOD, exploration of hybrid ensemble strategies in the backbone and prediction heads, and automatic discovery of optimal decoder parallelization/topology via architecture search in the few-shot regime.
Conclusion
The paper presents compelling evidence that hybrid ensemble decoding and progressive fine-tuning are critical components for effective and robust cross-domain few-shot object detection. These contributions offer performance improvements, robustness to OOD shift, and practicality in deployment, all while maintaining parameter efficiency. This work hence establishes strong baselines and clear design principles for future FSOD research in cross-domain and data-scarce regimes.

