- The paper’s main contribution is the derivation of closed-form optimism measures that quantify the training-testing error gap in tensor regression models.
- By leveraging CP and Tucker decompositions, it shows that model optimism is minimized at the true rank, outperforming traditional AIC/BIC criteria.
- Extensive numerical experiments and real-world applications, such as image regression and neural network compression, validate the proposed rank selection strategy.
Asymptotic Optimism in Tensor Regression: Theory, Model Selection, and Neural Network Compression
Introduction and Motivation
The paper "Asymptotic Optimism for Tensor Regression Models with Applications to Neural Network Compression" (2603.26048) rigorously addresses the challenge of model selection in high-dimensional tensor regression, focusing on the scalar-on-tensor setting with random-design covariates. Conventional model selection criteria—AIC, BIC, and Mallows's Cp—depend on in-sample error and parameter count, which fail to reliably capture predictive power and complexity for tensor-based models, particularly under random design and low-rank decompositions. The authors advance the theoretical understanding by deriving closed-form expressions for the expected optimism (i.e., the training-testing error discrepancy) for tensor regression models using CP and Tucker decompositions. Notably, they demonstrate that the expected optimism is minimized at the true tensor rank, establishing a principled, prediction-oriented rank-selection rule aligned with cross-validation and naturally extendable to ensemble approaches and neural network compression. The paper further delineates the boundaries and failure modes of conventional criteria, validates theory via extensive numerical experiments, and applies the findings to practical image regression and tensorized neural network compression.
Theoretical Framework: Optimism under Random Design
Revisiting Optimism
Optimism quantifies the gap between training and test performance, serving as an unbiased estimator of generalization error when covariates are random and statistically independent between training and testing (Random-X regime). Standard "Fixed-X" approaches (where test covariates exactly match those of training) are misaligned with real predictive tasks. The authors leverage recent advances in optimism theory—specifically, the work of Luan et al. and Luo & Zhu—which provide rigorous population-level formulas for excess risk in random-design linear and kernel ridge regression.
Tensor Regression via Kernel Ridge Equivalence
Both CP and Tucker decomposed tensor regressors admit equivalence to kernel ridge regression (KRR) with specific multilinear kernels [yu2018tensor]. The mapping facilitates direct derivation of optimism expressions by analytic kernel feature spectra, rather than naive parameter counting. The key innovation is that the low-rank structure is encoded into the kernel spectrum, enabling more precise complexity quantification and generalization error assessment.
Main Results: Population Optimism for CP and Tucker Regression
Rank Optimality
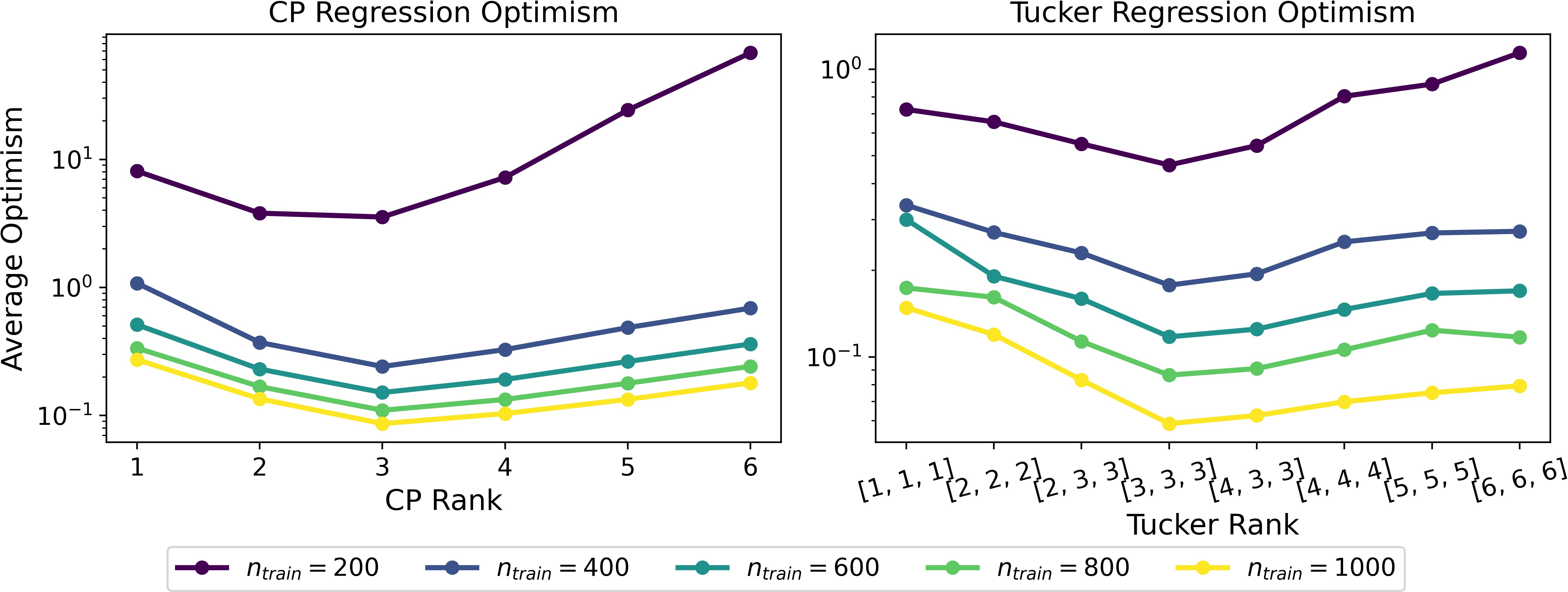
For both CP and Tucker decompositions, the expected optimism is expressed as a sum over the kernel spectrum (eigenvalues), parameterized by the target rank. Under mild regularization and moderate noise, the expected optimism is minimized when the target rank matches the true rank—i.e., neither under- nor over-estimating rank leads to reduced generalization error.
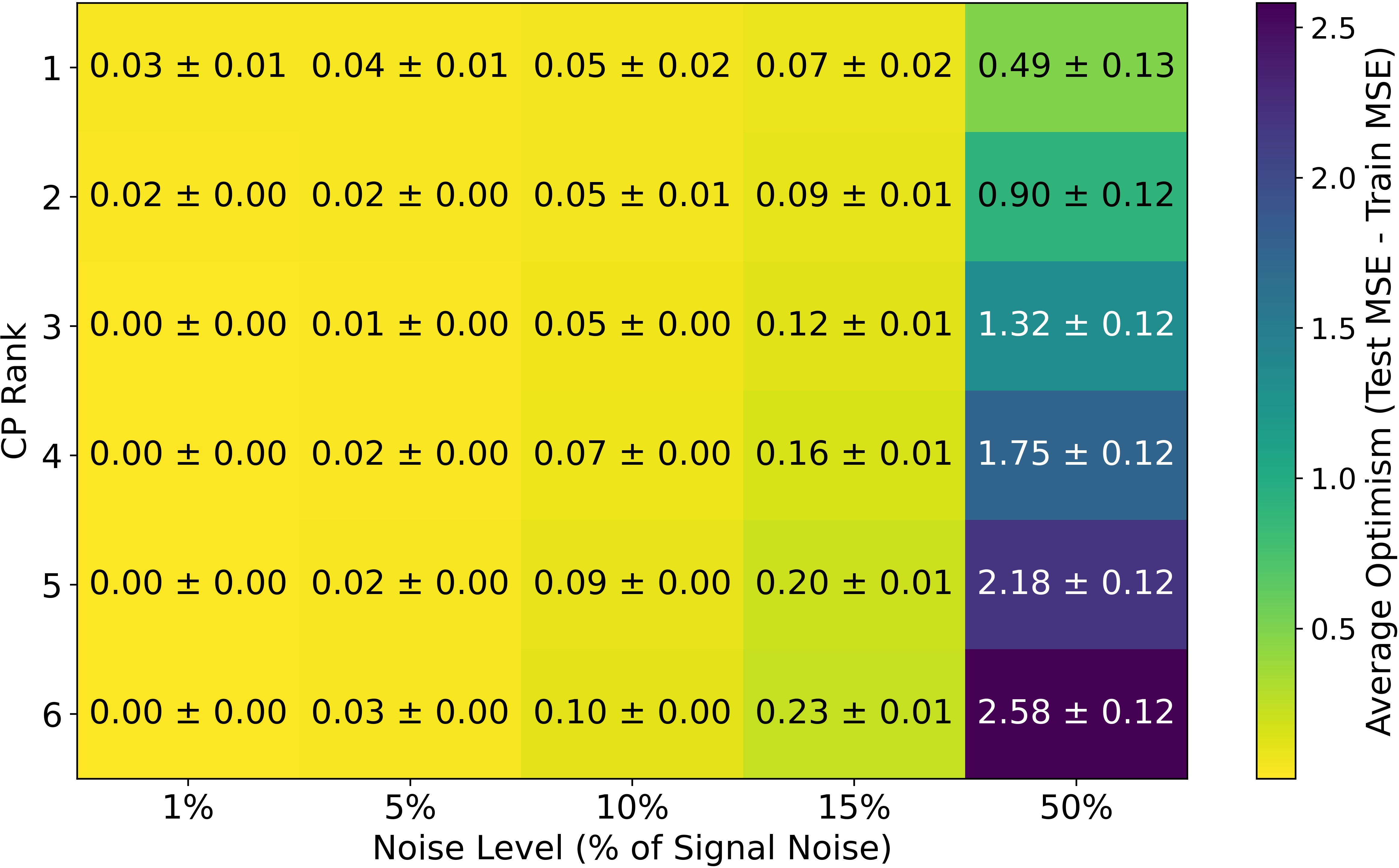
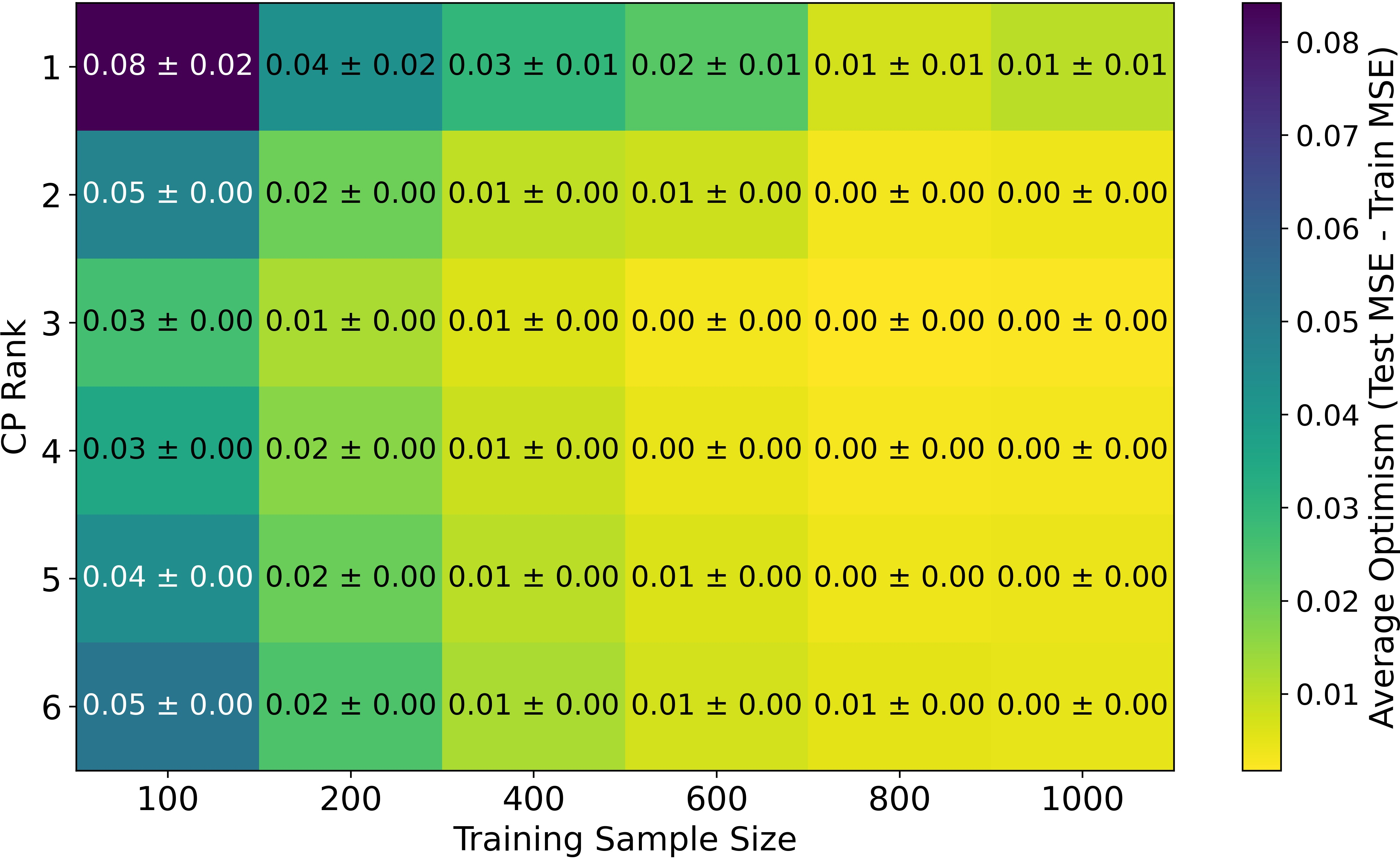
Figure 1: Average optimism of tensor KRR model for varying CP ranks and noise levels, confirming the minimum at the true rank.
The theoretical results are:
The closed-form expressions for expected optimism (see equations (3.15), (3.17), (3.21) in the paper) directly link optimism to spectral properties of CP/Tucker kernel matrices and regularization magnitude. The approximation terms are shown to be negligible except in extreme noise or shrinkage regimes.
Model-Averaged and Ensemble Settings
Extending to ensembles and model averaging, the paper proves the optimism of an ensemble-averaged estimator is strictly upper-bounded by the weighted average of component optimisms. Thus, ensemble approaches (including TRMA [bu2025improving]) further stabilize generalization error and yield robust rank selection across heterogeneous data settings.
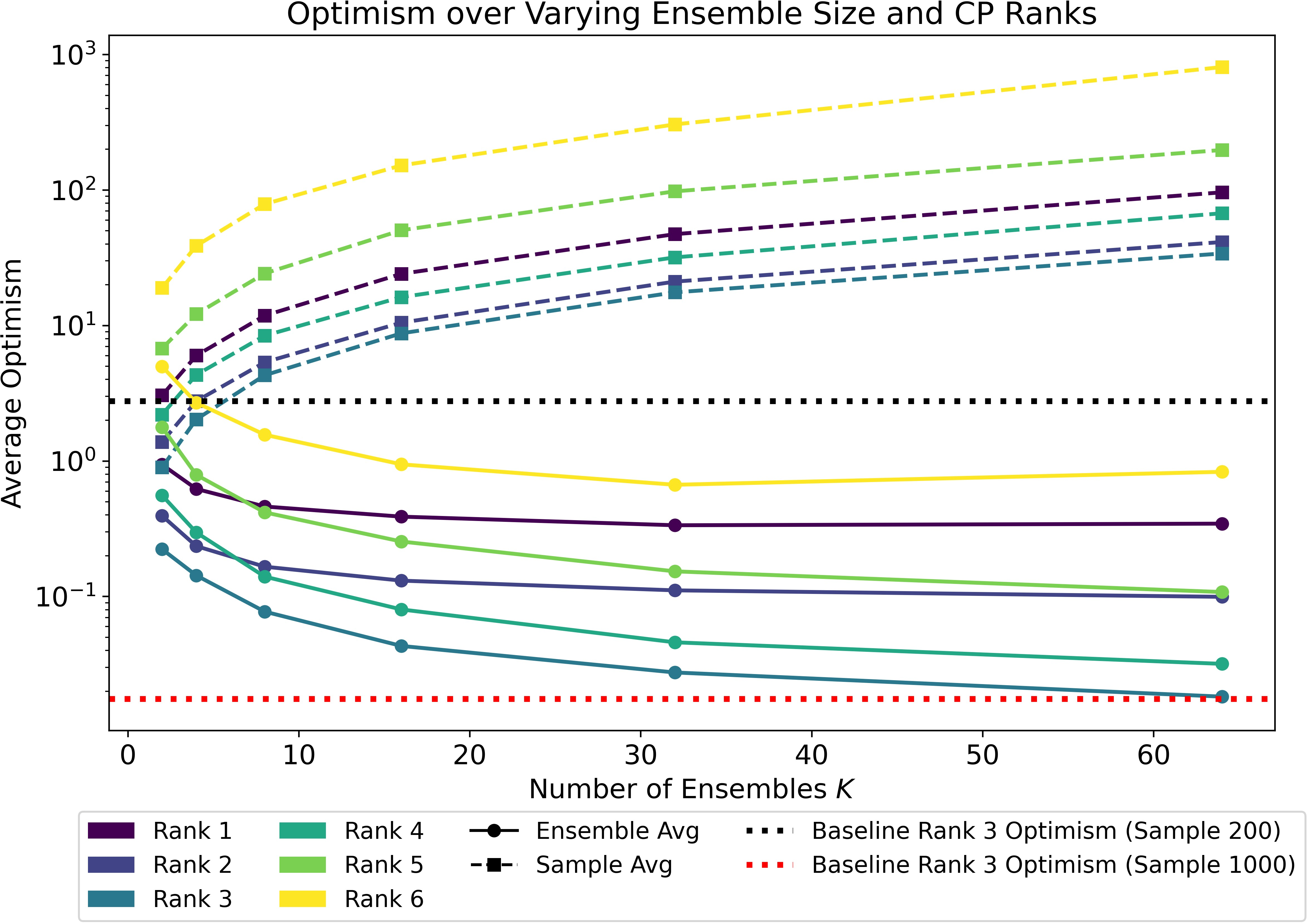
Figure 3: Ensemble CP regression optimism versus arithmetic mean of individual components, confirming strict upper-boundedness.
Numerical and Real-World Evidence
Simulation Studies
Oracle and realistic experiments validate theory: optimism is minimized at true rank and scales O(n−1) and O(σ2). Empirical results confirm analytic formulas up to high-dimensional, finite-sample effects.
Image Regression and Model Selection
The FGNET facial age dataset is analyzed via CP regression. AIC and BIC fail to identify optimal ranks; optimism aligns predictive risk to true generalization, selecting models with lowest test error.
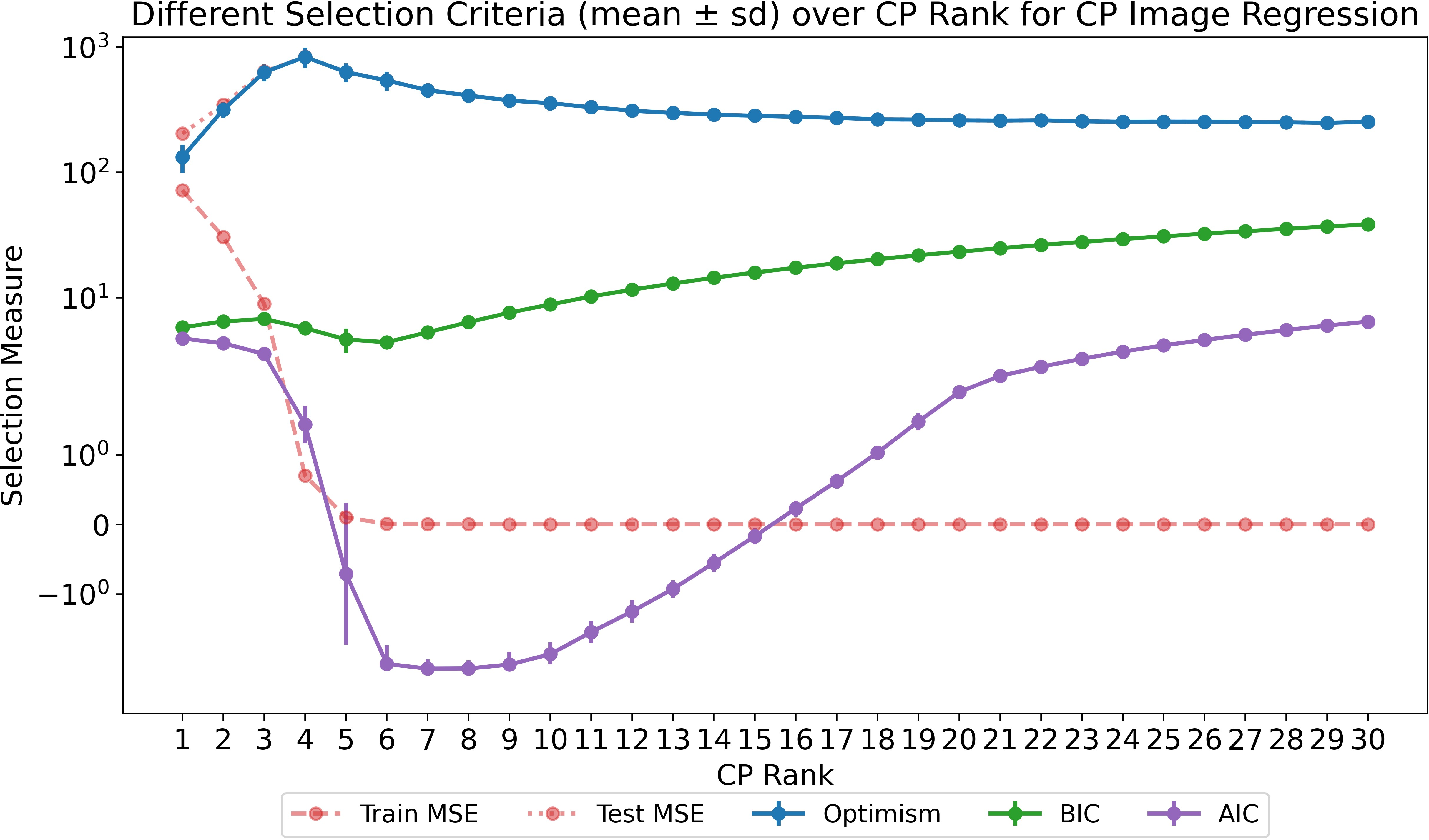
Figure 4: Optimism, AIC, and BIC tendencies versus CP rank for image regression; only optimism tracks minimum test MSE accurately.
Neural Network Compression
The optimism framework is extended to tensor-structured neural network layers (CNN and MLP), guiding rank selection for CP-compressed convolutional layers. Optimism, not AIC/BIC, selects architectures with minimal test error, even in over-parameterized regimes. Low-rank compression occasionally yields better generalization than uncompressed networks, consistent with findings in recent literature on benign overfitting in deep models.
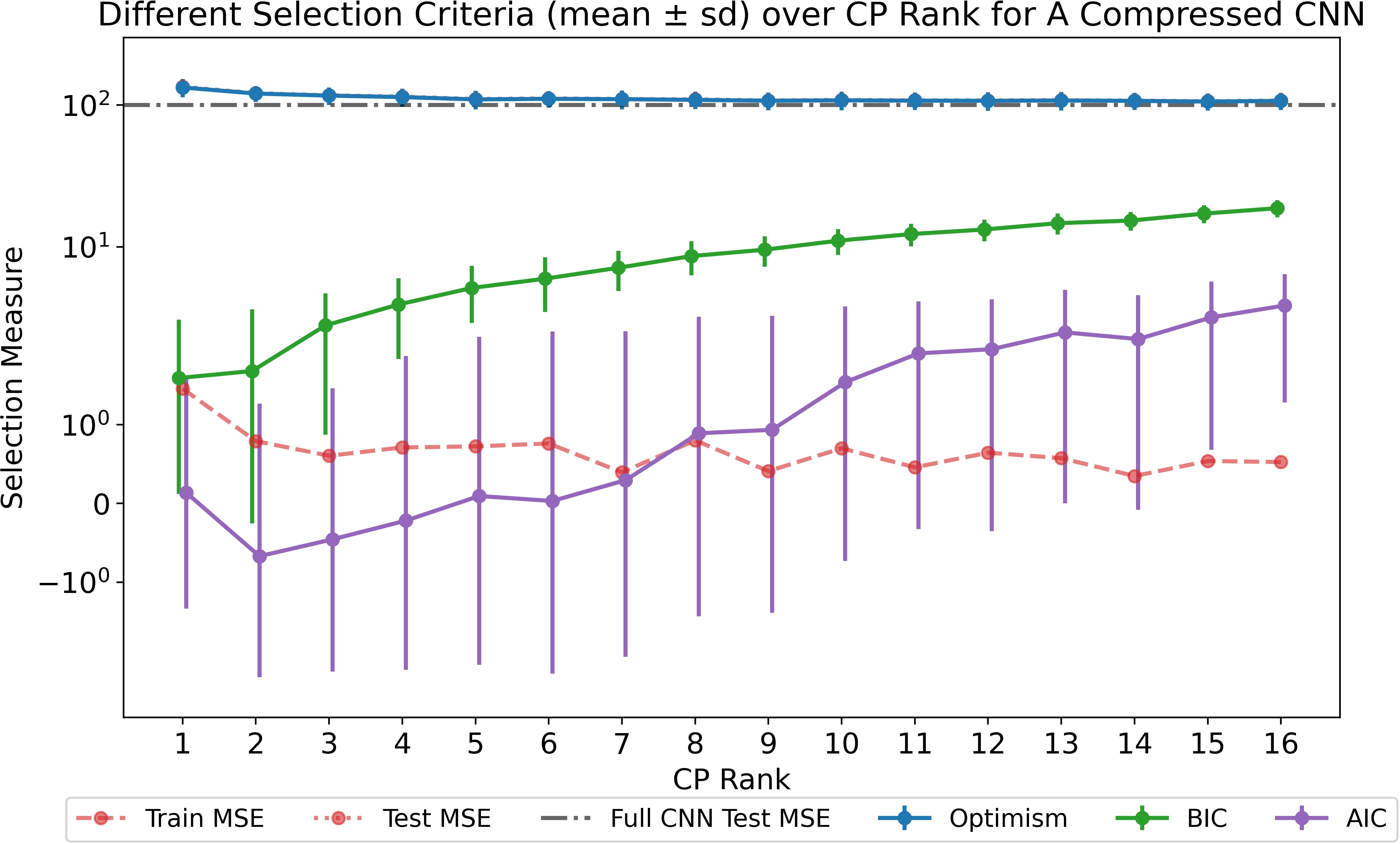
Figure 5: Optimism versus CP rank for compressed CNN layers under various criteria; optimism selects configurations yielding minimal test error.
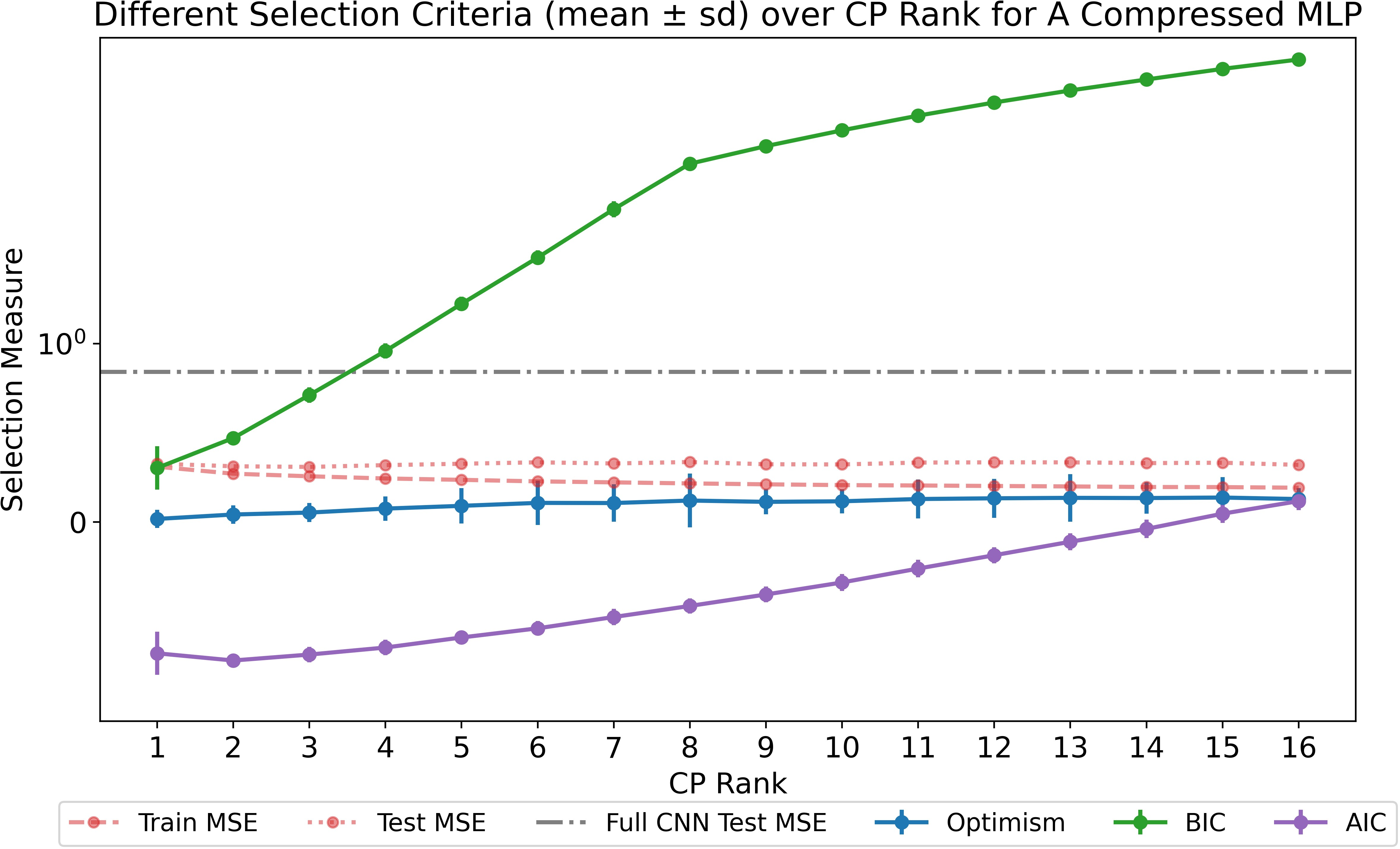
Figure 6: Optimism-driven rank selection in MLP compression yields simple models with optimal generalization; test error remains low across all ranks.
Implications and Future Directions
Theoretical Contributions
The paper establishes a rigorous complexity measure for tensor models via kernel ridge equivalence, overcoming deficiencies of parameter counting. The prediction-oriented optimism provides a unified criterion for model selection that is theoretically and empirically robust across random-design settings, tensor decompositions, and neural network architectures. Rank selection by minimizing optimism is shown to be consistent and resistant to misspecification errors and regularization pathologies, given noise boundedness and moderate sample sizes.
Practical and Algorithmic Impact
Optimism-minimizing rank selection is preferable in tensor regression and tensorized deep learning. It delivers reliable balancing of complexity and generalization, outperforming classical criteria (AIC/BIC) especially when standard notions of "effective parameters" are ill-defined or misleading, as in neural networks and high-dimensional tensors. The direct connection to cross-validation and ensemble averaging extends applicability to adaptive and heterogeneous modeling.
Future Directions
Extensions to higher-order tensor decompositions (e.g., Tensor-Train), tree-based ensemble models, and nonlinear architectures are a natural progression. Investigating optimism-driven regularization in deep over-parameterized models and exploring connections to overfitting theory (benign overfitting, neural tangent kernels) remain open research avenues. The findings further suggest optimism-based selection as a robust mechanism for automated rank adaptation in contemporary machine learning pipelines.
Conclusion
This work advances the theory and practice of model selection in tensor regression and tensorized neural networks, providing analytic optimism formulas that rigorously link rank to generalization error. The results demonstrate that minimum optimism coincides with true rank, supporting prediction-oriented selection rules fundamentally superior to classical parameter-count approaches. Extensive empirical and real-data evidence confirm theoretical claims and highlight implications for practical neural network compression, ensemble learning, and robust model selection in high-dimensional structured prediction.