The Geometry of Efficient Nonconvex Sampling
Abstract: We present an efficient algorithm for uniformly sampling from an arbitrary compact body $\mathcal{X} \subset \mathbb{R}n$ from a warm start under isoperimetry and a natural volume growth condition. Our result provides a substantial common generalization of known results for convex bodies and star-shaped bodies. The complexity of the algorithm is polynomial in the dimension, the Poincaré constant of the uniform distribution on $\mathcal{X}$ and the volume growth constant of the set $\mathcal{X}$.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
Imagine you have a strange, wiggly shape in very high dimensions (not just a flat drawing). You want to pick a point uniformly at random from inside that shape—every spot inside should be equally likely. That’s called “sampling uniformly from a set.” It’s easy for simple shapes (like balls or boxes), but can be hard for complicated, nonconvex shapes (think of shapes with holes or narrow tunnels).
This paper shows how to efficiently sample from a very large family of such complicated shapes, as long as they satisfy two natural geometric conditions. It extends earlier results that worked mainly for convex shapes (no caves or holes) or star-shaped ones, and it does so with strong accuracy guarantees.
The big questions they asked
- Can we sample uniformly from many nonconvex shapes in a reasonable amount of time, using only a simple yes/no test that tells us whether a point is inside the shape?
- Is a well-connected shape (no bad bottlenecks), together with a “not-too-skinny” growth property, enough to guarantee fast sampling?
- Can we generalize the best known methods for convex shapes to much more general shapes?
How their method works (in everyday terms)
Think of exploring a dark cave with a flashlight turned off. You can only ask: “Am I still inside the cave?” (That’s the yes/no “membership” test.) You want to wander around so that your positions are spread out uniformly.
The algorithm they analyze is called In-and-Out. It works like this:
The In-and-Out algorithm in plain words
- Start at a point inside the shape (a reasonable place to start—this is the “warm start”).
- Repeat many times:
- Take a small “noisy” step (like a tiny random nudge in a random direction).
- Then take another similar step and check: are you inside the shape?
- If you’re not inside, try that second step again (up to a set number of tries).
- If you’re inside, accept the new point and move on.
This two-step (out then back) motion simulates a mathematically ideal process that spreads out points nicely. The extra rule “try again up to N times” keeps the algorithm practical.
Two conditions that make it work
To make sure this random wandering doesn’t get stuck or waste tons of time, the shape needs two geometric properties:
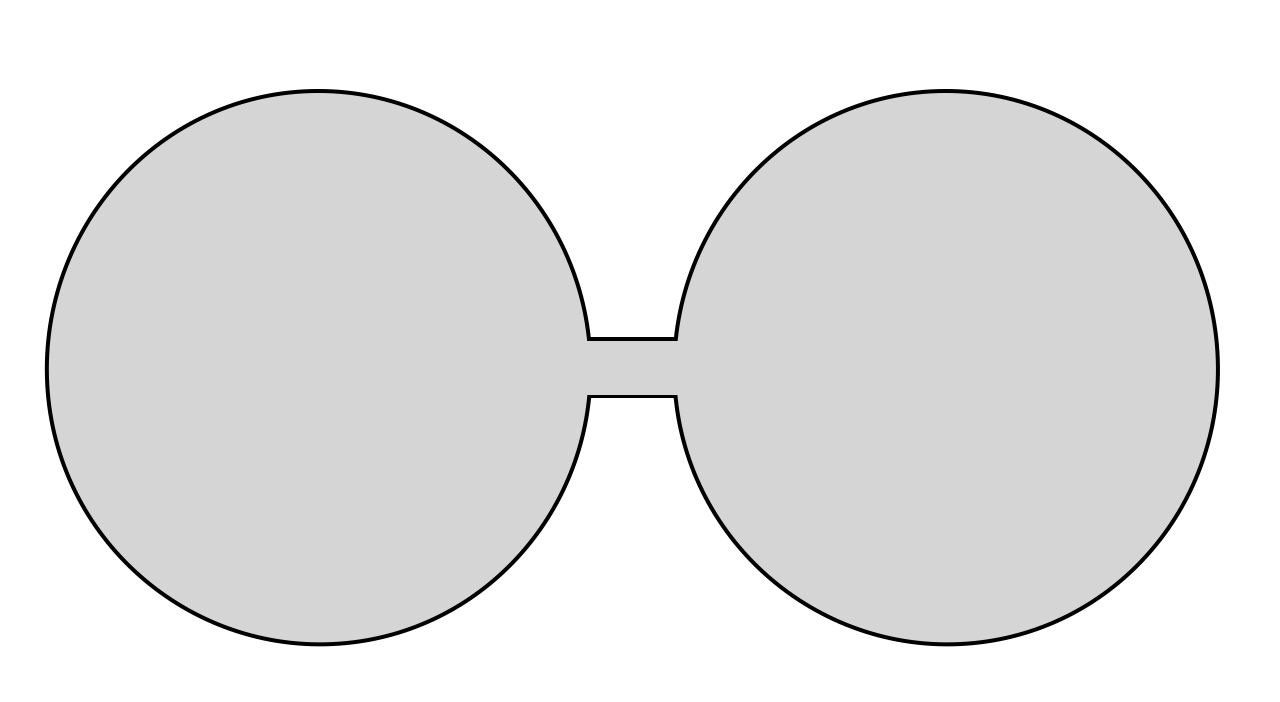
- No bottlenecks (Isoperimetry / Poincaré inequality):
- Picture a dumbbell: two big rooms connected by a very thin hallway. It’s hard to move from one room to the other by small random steps. The paper requires that the shape doesn’t have such super-thin bottlenecks. This is what the Poincaré inequality guarantees: the shape is “well-connected,” so the random walk can mix quickly across the whole shape.
- Controlled thickening (Volume growth condition):
- Imagine “thickening” the shape by a tiny amount, like putting a thin “padding” all around it. If adding a tiny layer makes the volume explode, the shape is extremely skinny (like a long thin straw), which makes random steps keep falling out. The volume growth condition says that when you thicken the shape by a distance t, its volume grows in a controlled, not-too-fast way. This rules out extremely skinny shapes that are hard to navigate.
Together, these conditions say: “The shape is well-connected and not too skinny.” With them, the random steps are likely to stay near the shape and get accepted often enough to be efficient.
What they proved and why it matters
- They proved that the In-and-Out algorithm can sample uniformly from a very broad class of nonconvex shapes efficiently—meaning the time it takes grows like a polynomial in:
- the dimension n,
- a number that measures how well-connected the shape is (the Poincaré constant),
- numbers that capture how fast the shape’s volume grows when you thicken it,
- and the accuracy you want (they get a dependence on log(1/accuracy), which is very good).
- The output is guaranteed to be very close to truly uniform in a strong sense (Rényi divergence, which is stricter than the more familiar total variation). In simple terms: the difference between what the algorithm returns and perfect uniform is provably tiny.
- The algorithm only needs a membership test (“is this point inside?”). It doesn’t need extra structure or formulas for the shape.
- It generalizes and improves earlier results:
- For convex shapes, it matches the known approach (with slightly more steps: roughly proportional to n³ instead of n²).
- For star-shaped shapes, it improves the accuracy dependence from something like “polynomial in 1/ε” to “polynomial in log(1/ε),” which is a big improvement.
Why this is important
Uniform sampling is a key tool across math, algorithms, statistics, optimization, and machine learning. It helps with:
- Estimating volumes,
- Approximating integrals and averages,
- Exploring complicated feasible regions in optimization or design.
Before this work, fast, rigorous sampling mostly required convexity or very specific structures. This paper shows that as long as your shape is well-connected and not too skinny, you can sample from it efficiently—even if it has holes, bumps, or nonconvex parts. That makes the method applicable to many more real-world and theoretical problems.
Final takeaway
The paper’s message is simple but powerful: if a high-dimensional shape has no serious bottlenecks and doesn’t grow volume too wildly when you thicken it, then a practical, membership-oracle-only random walk (In-and-Out) can sample nearly uniformly from it in polynomial time, with strong accuracy guarantees. This significantly broadens the shapes we can handle efficiently and tightens the theory connecting geometry to algorithmic sampling.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open directions that the paper leaves unresolved; each item is phrased to be actionable for future research.
- Warm start availability: The algorithm requires an -warm start on , but no method is given to obtain such a start for general nonconvex sets under only membership access, isoperimetry, and volume-growth assumptions. Can one design an annealing, core-finding, or exploration scheme that guarantees a polynomial-time warm start under the same assumptions?
- Verifying assumptions from oracles: The guarantees depend on the Poincaré constant and the volume-growth parameters , yet the paper does not provide procedures to estimate or certify these constants using only a membership oracle. Can we (a) approximate and efficiently, (b) certify when they are “small enough,” or (c) design robust, adaptive variants that work without knowing them a priori?
- Parameter-free/adaptive tuning: The step size and trial threshold depend on unknown global constants and a compounded quantity that itself depends on , , and . Can we develop an adaptive In-and-Out that tunes and online from acceptance/rejection statistics while retaining polynomial guarantees?
- Tightness of n3 iteration complexity: The analysis yields an dependence (versus for convex bodies). Is this gap fundamental for nonconvex sets under the given assumptions, or is it an artifact of proof techniques (e.g., the use of Gaussian tails)? Establish sharper upper bounds or matching lower bounds.
- Minimal geometric conditions: The paper shows isoperimetry alone is insufficient and adds the volume-growth condition. Are there weaker, alternative, or more intrinsic geometric conditions (e.g., positive reach, rolling-ball conditions, curvature bounds, thickness/width profiles, or external cone conditions) that suffice and are easier to verify/estimate?
- Beyond uniform distributions: The work focuses on the uniform distribution . Can the approach extend to nonconvex supports with non-uniform densities (e.g., piecewise smooth potentials, truncated logconcave distributions, or densities with discontinuities on nonconvex domains) while retaining polynomial complexity?
- Rounding/preconditioning for nonconvex sets: For convex sets, isotropic transformations improve complexity. Is there a membership-oracle-based preconditioning for nonconvex sets that provably reduces and/or (or their surrogates), and can it be computed in polynomial time?
- High-probability runtime guarantees: The total number of oracle calls is controlled in expectation; strong high-probability bounds on the total runtime (not just success probability of completing iterations) are not provided. Can we derive tail bounds for total work or design failure-free implementations with comparable complexity?
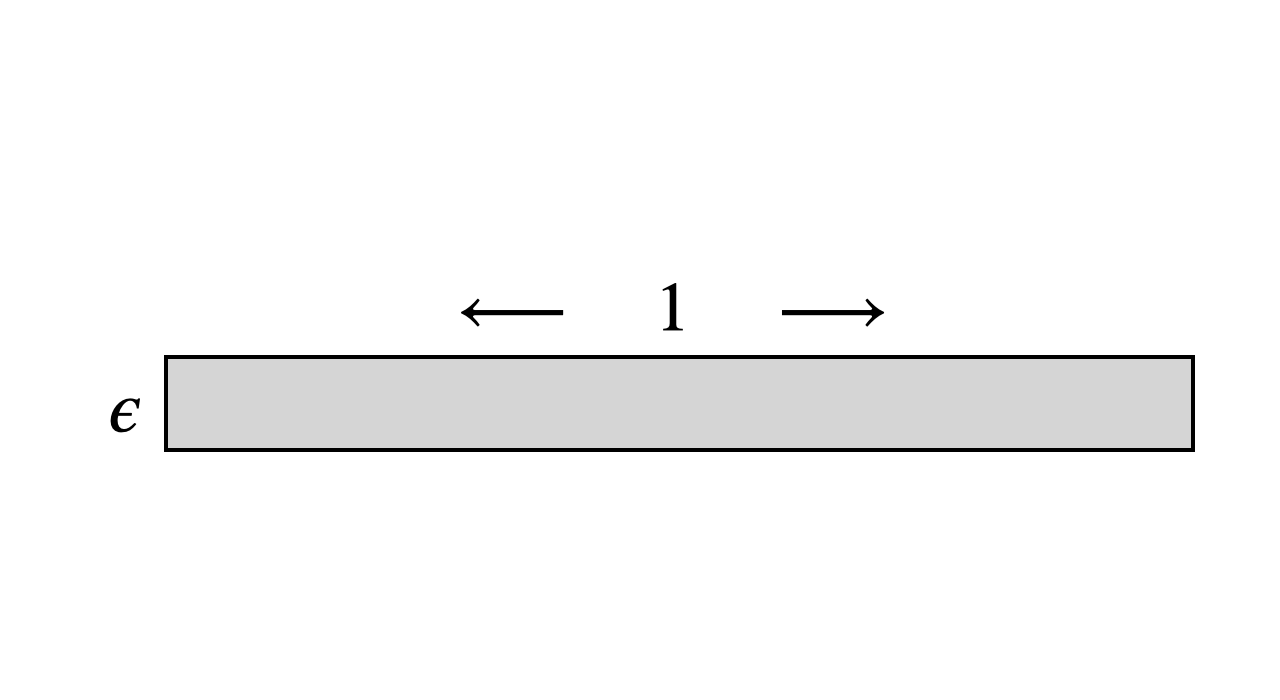
- Necessity and lower bounds tied to volume growth: The cylinder example motivates the volume-growth parameter , but formal lower bounds showing that any membership-only, local sampler must incur complexity growing with (or related geometry) are missing. Can we prove such information-theoretic or oracle lower bounds?
- Intersections and other set operations: The paper shows volume growth is preserved under unions and exclusions, but not under intersections (or other operations such as morphological transforms). Can we characterize when intersections preserve bounded volume growth and quantify the resulting ?
- Robustness to approximate oracles: Practical membership tests are often noisy or approximate. How sensitive are the guarantees to oracle errors, and can one design robust variants with provable stability to bounded noise in membership queries?
- Alternatives to Gaussian proposals: The analysis uses Gaussian steps and rejection until re-entry. Would alternative kernels (e.g., Ball Walk, Hit-and-Run variants for nonconvex sets, reflected or projected proposals, nonlocal “teleport” moves) lead to better acceptance rates or improved dependence on , , and ?
- Bias from finite-trial rejection: With a finite trial threshold , the resulting Markov chain is biased and does not have as its stationary distribution; the paper controls the output’s Rènyi divergence but does not characterize the chain’s stationary bias. Can we quantify the stationary distribution induced by finite , or remove bias via coupling/correction steps while preserving complexity?
- Log factors and dependence on : The dependence and linear dependence on the Rènyi index may be improvable. Can we reduce the powers (e.g., to ) and the dependence on via refined failure-control or per-iteration analysis?
- From isoperimetry to log-Sobolev or other inequalities: The proof leverages Poincaré inequality for convergence. Would stronger functional inequalities (e.g., modified log-Sobolev) yield faster convergence (fewer factors), or can weaker inequalities (e.g., Cheeger) suffice with different algorithms?
- Quantifying constants for typical nonconvex families: Beyond worst-case bounds, there is no empirical or average-case study of and for natural nonconvex families (e.g., unions of convex sets with controlled overlaps, sets with holes/channels). Can we tabulate or bound these constants in common constructions to guide practical parameter choices?
- Cold-start strategies without convex cores: For star-shaped or convex bodies, there are known warm-start strategies. For general nonconvex sets not expressible via large convex cores, can we design annealing schemes (e.g., gradually expanding ) with polynomial control to reach warmness?
- Handling rough boundaries: The analysis assumes “sufficiently regular surface” (finite surface area). How does the algorithm perform for sets with rough or fractal boundaries, or with large Minkowski content? Can the volume-growth condition be adapted to such cases?
- Dimension in tail bounds: The escape probability bound uses , which drives the scaling. Is there a way to reduce effective dimension in these tails (e.g., via random projections, anisotropic proposals, or geometric decompositions) to improve scaling?
- Practical diagnostics and stopping rules: The paper gives theoretical stopping conditions via and . Can we create data-driven diagnostics (e.g., based on acceptance rates, test functions, or coupling) that certify proximity to uniformity on without knowing these constants?
- Extensions to other geometries: The framework is Euclidean with isotropic Gaussian proposals. Can it be generalized to other norms, Riemannian manifolds, or constraint sets where the natural “ball” in the volume-growth condition is not Euclidean?
- Tradeoffs under unions/exclusions: The union and exclusion lemmas can inflate (e.g., by a volume ratio). Can we derive tighter composition bounds (perhaps using overlap geometry or interface regularity) to prevent exponential blow-up under repeated set operations?
- Exactness versus efficiency: Is there a way to make the algorithm exact (unbiased) without sacrificing polynomial complexity (e.g., via retrospective sampling, accept–reject envelopes, or coupling from the past) under the same geometric assumptions?
- Bridges to hardness results: While worst-case nonconvex sampling is hard, where precisely do the proposed assumptions sit between hardness and tractability? Can we delineate the boundary by constructing families of sets that separate necessity of isoperimetry and volume growth (or show each is tight up to constants)?
Practical Applications
Immediate Applications
Below are concrete, deployable uses that can leverage the paper’s “In-and-Out” sampler now, assuming you can implement a membership oracle for your set X and have a feasible warm start (an initial point in X). In each item, we note sector links, typical tools/workflows, and key dependencies/assumptions that affect feasibility.
- Monte Carlo over nonconvex feasible regions (computational science and engineering)
- What: Uniformly sample from complex viable domains (unions/differences of convex sets) to estimate volumes, integrals, probabilities, or to perform uncertainty/sensitivity analysis limited to feasible regions.
- Sectors: Aerospace, mechanical/chemical engineering, operations research.
- Workflow/tools: Implement membership oracle via simulator/constraint-evaluator; use samples for Monte Carlo volume estimates or UQ; integrate into Python/Julia/C++ stacks.
- Assumptions/dependencies: The feasible region should have “no severe bottlenecks” (moderate Poincaré constant) and reasonable volume growth (no very thin tunnels). A warm start is required; often available from an existing feasible solution.
- Robotics: uniform coverage of collision-free configuration spaces (C-spaces)
- What: Generate uniform samples in nonconvex, obstacle-rich C-spaces for benchmarking planners (PRM/RRT), coverage analysis, initialization, and occupancy modeling.
- Sectors: Robotics, autonomous systems.
- Workflow/tools: Membership oracle = collision checker; warm start from an existing feasible configuration; plug-in sampler for MoveIt/OMPL.
- Assumptions/dependencies: C-space should avoid extreme narrow passages (those hurt isoperimetry/volume growth). For very high-DOF robots, Õ(n3) cost and collision-check cost may dominate.
- Verification and stress-testing of cyber-physical systems (CPS)
- What: Uniformly sample from the “safe set” of operating conditions (defined by nonlinear constraints) to stress-test controllers and safety monitors without bias to any subregion.
- Sectors: Automotive, aerospace, industrial automation.
- Workflow/tools: Membership oracle implemented by a constraint checker or simulator (e.g., Simulink/Modelica); use samples to create test suites.
- Assumptions/dependencies: Safe set must be well-connected without thin, long corridors; warm start from a known safe trajectory/state.
- Software testing and fuzzing with real-valued constraints
- What: Generate uniform test inputs satisfying complex numeric preconditions (e.g., geometry invariants, business rules) to improve coverage and fairness in testing.
- Sectors: Software, fintech/insurtech, scientific computing.
- Workflow/tools: Oracle is a predicate/contract/assertion; integrate sampler as a generator into property-based testing (e.g., Hypothesis/QuickCheck) or fuzzers.
- Assumptions/dependencies: Predicates define a compact feasible region; need at least one feasible input (warm start). Performance depends on acceptance rate (a proxy for volume growth).
- Bayesian inference with constrained priors
- What: Draw prior or prior-predictive samples uniformly from nonconvex parameter regions (e.g., stability constraints in control, shape constraints in econometrics).
- Sectors: Control engineering, econometrics, systems biology.
- Workflow/tools: Oracle checks constraints (e.g., spectral radius < 1, positivity/monotonicity, boundedness); use samples for prior diagnostics or likelihood-free checks.
- Assumptions/dependencies: Region must be compact and well-behaved (Poincaré inequality). For very high dimensions or regions with bottlenecks, mixing can degrade.
- Design of experiments (DoE) and feasible design exploration
- What: Uniformly sample candidate designs satisfying all constraints to build surrogate models and perform global sensitivity analysis over the actual feasible domain.
- Sectors: Aerospace, automotive, chemical process design.
- Workflow/tools: Oracle via physics-based simulator or rules engine; couple uniform samples with surrogate modeling (GPs, RFs).
- Assumptions/dependencies: Feasible set connectivity/volume growth reasonable; warm start can be a legacy design.
- Computer graphics and geometry processing
- What: Uniform point sampling in complex 3D shapes with holes and non-star-shaped features for rendering, subsurface scattering, or meshing.
- Sectors: Gaming/VFX, CAD/CAM.
- Workflow/tools: Oracle is point-in-solid via winding/voxel or SDF; use sampler for uniform surface/volume point clouds.
- Assumptions/dependencies: While simpler 3D methods exist, this algorithm ensures unbiased uniformity even for complicated CSG unions/differences; 3D cost is modest.
- Power systems: feasible operating point sampling
- What: Uniformly sample AC power-flow feasible operating points to stress-test stability margins and probabilistic security.
- Sectors: Energy, grid operations.
- Workflow/tools: Oracle is “solves AC power flow and satisfies constraints”; use samples for risk metrics and contingency analysis.
- Assumptions/dependencies: Feasible set often nonconvex; method applicable for modest system sizes and regions without extreme bottlenecks; warm start from a known feasible OPF solution.
- Healthcare planning (e.g., radiation therapy)
- What: Explore uniform samples of feasible treatment plans that meet dose-volume constraints to understand tradeoffs and support shared decision-making.
- Sectors: Healthcare.
- Workflow/tools: Oracle via dose-calculation and constraint evaluation; present feasible plan distributions to clinicians.
- Assumptions/dependencies: High-dimensional plan spaces can contain narrow feasible corridors (harmful to mixing); use in subproblems/regions where isoperimetry is reasonable and a baseline plan exists.
- Portfolio analysis with nonlinear continuous constraints
- What: Uniformly sample portfolio weights within complex continuous constraints (e.g., nonlinear risk/return regions, turnover limits modeled continuously) for unbiased stress-tests.
- Sectors: Finance, asset management.
- Workflow/tools: Oracle checks continuous constraints; integrate with risk engines; use samples for scenario analysis and reporting.
- Assumptions/dependencies: Discrete/integer constraints are incompatible; region must be compact, continuous, and sufficiently well-conditioned; warm start from a feasible portfolio.
- Academic use: benchmarking and education beyond convexity
- What: Create new benchmarks for high-dimensional nonconvex sampling; teach geometry and isoperimetry with hands-on samplers.
- Sectors: Academia, education.
- Workflow/tools: Open-source “Uniform Nonconvex Sampler” with a membership-oracle interface; share standard nonconvex test sets (unions/differences, holes).
- Assumptions/dependencies: Provide reference oracles and warm starts with datasets to ease adoption.
Notes on deployment
- Parameterization: Theory uses Poincaré and volume-growth constants to set step size and iteration counts. Practically, you can tune step size by monitoring acceptance/attempts per iteration; if acceptance collapses, your set likely violates the volume-growth assumption (e.g., very thin features).
- Warm starts: Required. In practice, obtain them from existing feasible solutions or short local-search procedures.
- Diagnostics: True Rényi divergence is not directly observable; use standard MCMC diagnostics (autocorrelation, effective sample size, R-hat across chains, geometric coverage checks).
- Cost model: Complexity scales as Õ(n3) iterations times the cost of one membership query and O(n) arithmetic; total cost also depends on acceptance behavior (influenced by α, β).
Long-Term Applications
These opportunities require additional research, scaling, or methodological extensions (e.g., estimating geometric constants, improving warm starts, or handling harsher geometries).
- High-DOF robotics with narrow passages and contact-rich tasks
- What: Uniform sampling in C-spaces with severe bottlenecks (poor isoperimetry), to improve planner completeness and verification.
- Potential tools/workflows: Preconditioning via clearance-maximizing transforms; adaptive step-size control; decomposition of C-space into unions with better local constants.
- Dependencies/assumptions: Need methods to detect/mitigate bottlenecks, estimate effective geometric constants online, or partition C-space; possibly combine with roadmap guidance.
- Molecular conformational space exploration
- What: Uniform sampling of conformational basins defined by energy thresholds (nonconvex, high-dimensional) to complement biased dynamics.
- Potential tools/workflows: Oracle via fast energy evaluation; region partitioning (by torsion sets); hybrid with umbrella sampling/metadynamics.
- Dependencies/assumptions: Energy landscapes can have extremely thin channels; may require region decomposition and warm starts in each basin; need verification that subregions satisfy isoperimetry/volume growth.
- Generative design and AI-assisted engineering
- What: Uniform exploration of feasible design spaces to train/evaluate generative models that respect constraints by construction.
- Potential tools/workflows: Membership oracles via fast surrogate models; active learning to refine constraint boundaries; coupling uniform samples with diffusion or flow-based models.
- Dependencies/assumptions: Must control oracle error (surrogate misclassification biases uniformity); need bias correction schemes; scalable warm-start generation for large design spaces.
- Large-scale power systems and market-clearing feasibility analysis
- What: Systematic uniform sampling of high-dimensional feasible operating regions for probabilistic security assessment and market design stress-tests.
- Potential tools/workflows: Parallel/cluster implementations; region partitioning (zonal); adaptive tuning driven by observed acceptance stats; integration into EMS/SCADA analytics.
- Dependencies/assumptions: Needs scalable membership oracles (fast AC PF or convex relaxations with certification), better step-size control, and automatic estimators for α, β, and effective Poincaré constants.
- Formal safety certification via uniform coverage
- What: Use uniform samples from safety sets to provide coverage guarantees in certification workflows for autonomous systems.
- Potential tools/workflows: Combine with reachability/verification tools; stratify region to ensure coverage of rare boundary conditions.
- Dependencies/assumptions: Requires theoretical characterization that the certified safe set satisfies Poincaré/volume-growth; development of coverage metrics aligned with certification standards.
- Fairness auditing and policy compliance spaces in ML
- What: Uniform sampling from continuous relaxations of fairness-constraint regions to audit model behavior without bias toward “easy” subregions.
- Potential tools/workflows: Define continuous, compact surrogate sets for constraints; build oracles from data-driven estimators; integrate into auditing dashboards.
- Dependencies/assumptions: Mapping discrete constraints to compact continuous regions; ensuring geometric conditions; ensuring oracle calibration.
- Hybrid and discrete-continuous systems (software verification)
- What: Sampling from continuous relaxations of invariant sets for state-space exploration in hybrid systems.
- Potential tools/workflows: Construct compact over-approximations satisfying volume-growth; use uniform samples to steer search into underexplored regions.
- Dependencies/assumptions: Requires principled relaxations that retain meaningful coverage; geometric conditions may be violated near switching boundaries.
- Products and ecosystem build-out
- What: Robust “Nonconvex Sampler SDK” with:
- A simple membership-oracle API.
- Adaptive tuning of step size and trial thresholds guided by observed acceptance.
- Optional preconditioning (e.g., near-isotropic transforms) to improve mixing.
- Partition-and-merge support to handle unions/differences at scale.
- Dependencies/assumptions: Research-grade features include online estimation of volume-growth proxies, and detection of poor isoperimetry (bottlenecks) with automated mitigations.
Cross-cutting assumptions and dependencies
- Membership oracle availability and cost: The sampler only needs a yes/no membership check, but total runtime scales with oracle cost and dimension.
- Warm start: A feasible initial point is required; methods to find warm starts for general nonconvex sets are context-dependent and may dominate runtime.
- Geometric conditions: Practical performance relies on moderate Poincaré constants (no dumbbells/narrow bottlenecks) and controlled volume growth (avoid very thin structures like long slender cylinders). The paper shows these conditions hold for many unions/differences of “nice” sets and for star-shaped/convex sets.
- Parameter tuning: Theoretical settings depend on unknown constants; operationally, use acceptance rates and per-iteration trial counts to tune step size and thresholds; consider region decomposition if acceptance is persistently poor.
- Dimensionality: Iteration complexity is Õ(n3); for very high dimensions, preconditioning to near-isotropy or dimensionality reduction (when justified) becomes important.
Glossary
- absolute continuity: A measure-theoretic relation where one distribution assigns zero probability to every set that another does; denoted ρ ≪ π. "Given distributions ρ, π on Rn, recall we say ρ is absolutely continuous with respect to π, denoted by ρ \ll π"
- Brunn–Minkowski theorem: A fundamental result in convex geometry relating volumes of Minkowski sums; here used to control volume growth of convex bodies. "the Brunn-Minkowski theorem implies that convex bodies satisfy the volume growth condition with α = 1"
- Cheeger isoperimetry: A notion capturing bottlenecks in a space; poor Cheeger isoperimetry corresponds to slow mixing and a large Poincaré constant. "poor Cheeger isoperimetry (i.e., large Poincar\n""" e constant)"
- compact body: A closed, bounded set with non-empty interior in Rn. "an arbitrary compact body X ⊂ Rn"
- convex body: A compact, convex set with non-empty interior in Rn. "sampling from a (near-)isotropic convex body X ⊂ Rn"
- convex core: For a star-shaped body, a non-empty convex subset from which all points in the body are visible. "the convex core (the non-empty subset of the star-shaped body that can ``see'' all points in the body)"
- Euclidean ball (ℓ2-ball): The set of points within a given Euclidean distance from a center; denoted B(0,t). "B_t ≡ B(0,t) is the ℓ_2-ball of radius t"
- Gaussian tail probability: The probability that a Gaussian vector’s norm exceeds a threshold; here Q_m(r) = Pr(∥Z∥ ≥ r). "we define the Gaussian tail probability Q_m : [0,∞) → [0,1] by: Q_m(r) := Pr(|Z|\ge r)"
- Hausdorff measure: A generalization of length/area/volume used to measure (n−1)-dimensional surface area. "where d H{n-1}(x) is the (n-1)-dimensional Hausdorff measure."
- Hölder continuity: A smoothness condition weaker than Lipschitz continuity, controlling how fast a function can change. "under weaker smoothness assumption such as H\"older continuity of ∇ f"
- In-and-Out algorithm: A two-step Gaussian proposal-and-rejection sampler implementing a proximal scheme for uniform sampling from X. "The In-and-Out algorithm is the following iteration."
- isoperimetry: Geometric boundary-to-volume relations that govern mixing and sampling difficulty. "the isoperimetry of the target distribution is a crucial ingredient for efficient sampling."
- isotropic (near-isotropic): A shape or distribution whose covariance is close to a multiple of the identity. "(near-)isotropic convex body X ⊂ Rn"
- Kannan–Lovász–Simonovits (KLS) conjecture: A conjecture bounding the Poincaré constant of log-concave measures in terms of covariance. "The Kannan-Lovasz-Simonovitz (KLS) conjecture states that if π is logconcave, then (π) = O(|\Sigma|_op)"
- Kullback–Leibler (KL) divergence: A measure of discrepancy between probability distributions; the q→1 limit of Rényi divergence. "The limit q → 1 is the Kullback-Leibler (KL) divergence or relative entropy"
- Langevin dynamics: A diffusion process used for sampling from target distributions via stochastic differential equations. "from the perspective of sampling via continuous-time diffusion processes such as the Langevin dynamics"
- Lebesgue measure: The standard notion of volume on Euclidean space used to define densities. "where d is the Lebesgue measure on Rn"
- Lipschitzness: A uniform bound on a function’s rate of change; here used for ensuring rejection-sampling efficiency. "or Lipschitzness of f"
- logconcave distribution: Distributions whose log-density is concave; a central class with strong isoperimetry properties. "logconcave probability distributions"
- membership oracle: A black-box function returning whether a point lies in X, used to implement geometric algorithms. "with only membership oracle access to the body X"
- Minkowski sum: The pointwise sum of two sets, used to define enlargements X ⊕ B_t. "⊕ is the Minkowski sum between sets."
- M-warm (warmness): A bounded-density-ratio condition ensuring the start distribution is not too concentrated relative to the target. "Suppose x_0 ∼ ρ_0 is M-warm with respect to π."
- operator norm: The largest singular value (eigenvalue for symmetric matrices); here of the covariance matrix. "(π) = O(|\Sigma|_op)"
- outer isoperimetry: The ratio of a body’s surface area to its volume, used to control volume growth. "the outer isoperimetry of X to be the ratio of the surface area to volume"
- Pinsker’s inequality: Relates total variation distance to KL divergence, giving TV ≤ sqrt(KL/2). "by Pinsker's inequality, we have 2 TV(ρ, π)2 ≤ KL(ρ \,|\, π)"
- Poincaré constant: The best constant in the Poincaré inequality, quantifying isoperimetry/mixing properties. "the Poincar\n""" e constant is O(1)"
- Poincaré inequality (PI): A functional inequality bounding variance by expected gradient norm, central to mixing rates. "Recall we say a probability distribution π on Rn satisfies a Poincar\n""" e inequality (PI)"
- Proximal Sampler: An idealized algorithm that samples from regularized distributions each iteration; In-and-Out implements it approximately. "The Proximal Sampler algorithm has a convergence guarantee under Poincar\n""" e inequality"
- pushforward (by a Lipschitz mapping): The distribution obtained by transforming a random variable; PI is stable under such maps. "pushforward by a Lipschitz mapping"
- Radon–Nikodym derivative: The density of a measure with respect to another (e.g., with respect to Lebesgue measure). "probability density function (Radon-Nikodym derivative)"
- rejection sampling: A sampling technique that accepts or rejects proposals based on a criterion to simulate a target distribution. "via rejection sampling with a threshold N on the number of trials"
- Rényi divergence: A family of divergences generalizing KL, parameterized by order q > 1. "with a guarantee in R\n""" enyi divergence"
- star-shaped body: A set where every point is visible from at least one point in a common core; generalizes convexity. "a body X ⊂ Rn is star-shaped"
- total variation distance: The maximum difference in probabilities assigned to events by two distributions. "ε > 0 is the final error parameter in total variation distance"
- volume growth condition: A bound controlling how fast Vol(X ⊕ B_t)/Vol(X) grows with t, parameterized by (α, β). "We say a compact body X ⊂ Rn satisfies an (α,β)-volume growth condition"
- warm start: An initial distribution close to the target, typically ensuring faster convergence. "from a warm start"
Collections
Sign up for free to add this paper to one or more collections.