- The paper introduces DIET, a novel framework that distills streaming interaction data into a compact synthetic memory, capturing training dynamics with only 1-2% of the original data.
- The paper leverages a bi-level meta-learning optimization with continual memory fusion and influence-aware updating to dramatically reduce training time and memory overhead.
- The paper validates DIET's high fidelity and cross-architecture transfer through extensive experiments, achieving near-maximal AUC and LogLoss on benchmarks like KuaiRand, Tmall, and Taobao.
DIET: Continual Streaming Dataset Distillation for Recommender Systems
Streaming behavioral logs in large-scale recommender systems (RS) create a scenario where model architectures must be iteratively evaluated and updated using enormous historical datasets. Existing paradigms, which rely on full-data retraining for each architectural change, suffer from severe computational inefficiency. Heuristic data-reduction strategies—such as sampling or coreset selection—distort the temporal and distributional structure of behavioral logs, leading to degraded approximation of the optimization trajectories induced by the complete data. This paper formalizes streaming dataset distillation for recommender systems, requiring the construction of an evolving, compact synthetic dataset that continually approximates the training effects of full historical interactions.
DIET Framework
DIET (Distilling Dataset Continually for Recommender Systems) is introduced as a unified, continual streaming dataset distillation approach. Distilled data are maintained as an evolving boundary memory, updated on a stagewise basis to closely reflect training dynamics over continuously arriving data blocks (Figure 1).
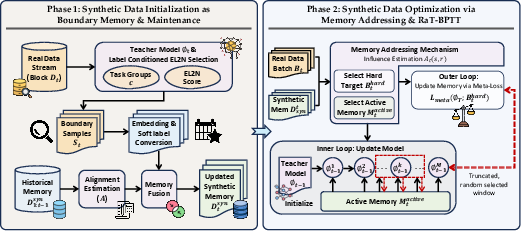
Figure 1: DIET operates in two phases: (1) boundary memory construction by selecting influential samples; (2) continual refinement of the synthetic memory via influence-aware addressing.
Boundary Memory Initialization
Initialization is performed by selecting task-conditioned influential samples within each block, leveraging label-conditioned EL2N scores over reference model checkpoints. This ensures that infrequent, high-utility behavioral events are appropriately represented, directly addressing extreme data sparsity and heterogeneity. Rather than static selection, synthetic samples comprise embedding-soft label pairs extracted via the reference model, providing a dense, semantically meaningful distillation substrate even over ultra-sparse categorical spaces.
Memory Fusion and Evolution
Rather than myopically focusing on current block data, DIET performs continual memory fusion—aligned and training-influential synthetic samples from historical distilled sets are merged with newly selected memory at each stage. Influence estimation functions, guided by reference model states, ensure that only samples with persistent boundary alignment are retained, thereby compressing long-term behavioral structure into a fixed-size synthetic set.
Influence-Guided Bi-level Optimization
Optimization proceeds via a two-level meta-learning loop:
- Inner loop: A proxy model (initialized from the previous reference checkpoint) is updated over the currently active synthetic memory subset. Active units are selected via responsibility scores traced through influence estimation.
- Outer loop: Synthetics are meta-updated by differentiating through the inner loop, using a hard target set selected based on minimal deficiency (lowest alignment with current memory). Truncated backpropagation (RaT-BPTT) is used to control memory and time overhead.
Training Protocol
Once the distilled stream is constructed, candidate recommender architectures are trained in a warmup-style regime: dense parameters are fit on the synthetic data, while sparse embeddings are transferred from the reference model. This protocol enables rapid iteration over multiple architectures without repeated access to historical logs.
Empirical Evaluation
Comparative Fidelity and Generalization
DIET demonstrates substantially higher fidelity in preserving full-data model behavior as compared to static selection methods (random, EL2N, cluster-based), as quantified by the cross-model ranking correlation measured between distilled-data and full-data runs (Figure 2).
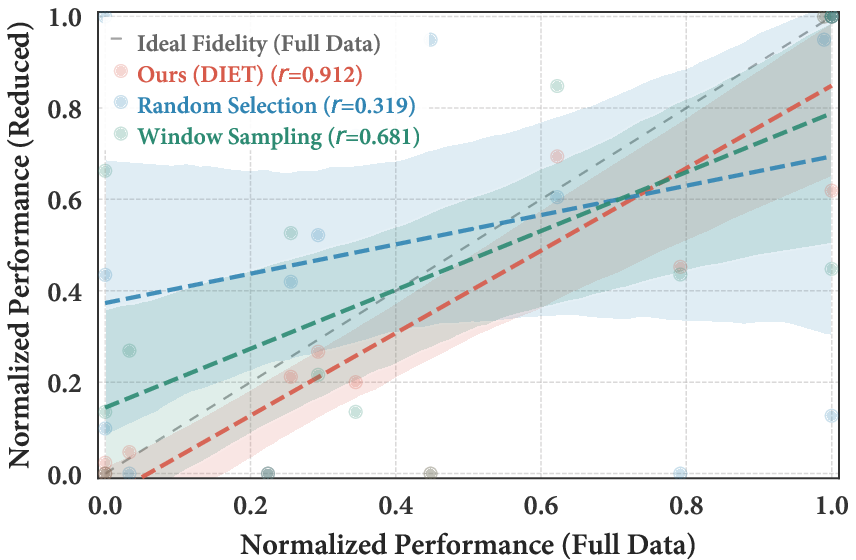
Figure 2: Correlation between performance on reduced and full datasets; DIET shows superior fidelity versus all selection baselines.
On benchmarks including KuaiRand, Tmall, and Taobao, DIET achieves near-maximal AUC and LogLoss with only 1-2% of training data, matching or exceeding the results of full-data baselines. Notably, cross-architecture transfer remains robust: synthetic datasets distilled via one architecture generalize seamlessly to others (e.g., WuKong trained on DCN-distilled data recovers almost all of the full-data performance, see Table 1 and Figure 3). At moderate or high distilled ratios, superior reference model capacity yields even further gains—sometimes exceeding the full-data upper bound due to noise suppression and denoising effects.
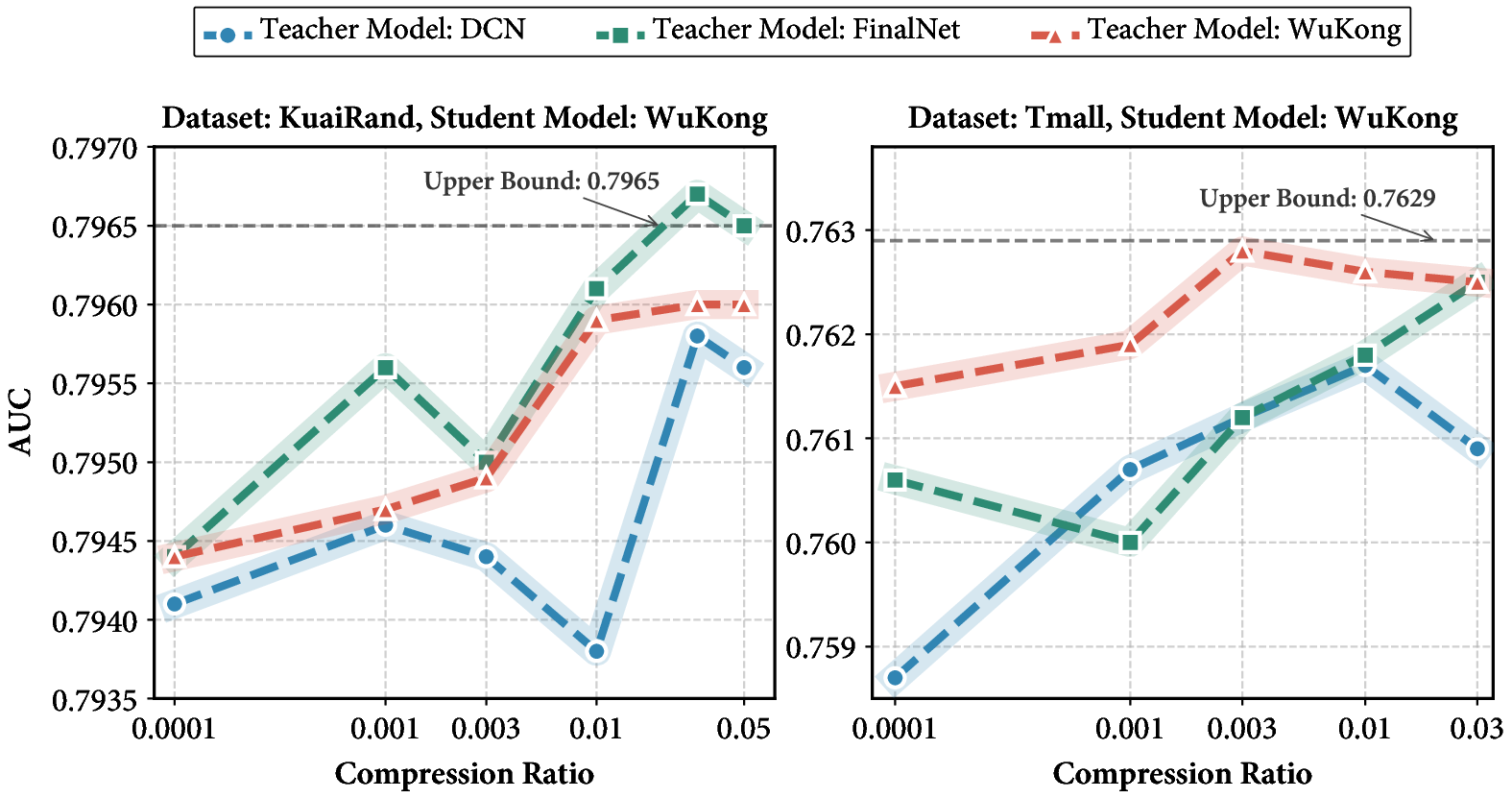
Figure 3: Model performance across different compression ratios. DIET maintains fidelity under aggressive reduction and generalizes across candidate architectures; full-data upper bound shown as dotted line.
Component Ablation and Efficiency
Ablation studies indicate that continual memory fusion and bi-directional memory addressing (target/hard sample and responsible synthetic unit selection) are essential; removing either degrades AUC by up to 0.4 points. Time and space overhead analysis confirms that the distillation cost is incurred only once, and downstream training time/memory is dramatically reduced (by up to 60×), with amortized cost per model iteration approximately negligible given the enormous reduction in raw data access.
Theoretical and Practical Implications
Theoretically, DIET demonstrates that sequential boundary-aligned distillation can capture high-frequency and tail event dynamics in sparse, high-dimensional data, providing strong empirical evidence that optimization-aligned synthetic memory updates surpass simple diversity- or representativeness-based selection. Practically, DIET offers a scalable, model-agnostic distillation protocol easily integrated into industrial RS pipelines, enabling:
- Fast, reference model-agnostic architecture search and hyperparameter optimization under tight compute constraints.
- Efficient deployment into settings with privacy or data access restrictions, where sharing the synthetic memory is preferred over raw event logs.
Moreover, synthetic datasets can be re-used across candidate architectures and future data regimes, suggesting the possibility of standardized, publicly shareable synthetic RS benchmarks.
Future Directions
There remain several compelling avenues for follow-up:
- Distillation under distributional drift: Refinement of online memory addressing strategies under extreme or adversarial non-stationarity.
- Algorithmic acceleration: Further reduction in meta-optimization cost via better truncation or second-order approximations.
- Extension to generative, sequence-based, or multi-modal recommendation architectures, with possible adoption in LLM-driven or end-to-end generative RS frameworks.
Conclusion
DIET establishes a high-fidelity, efficient mechanism for continually distilling large-scale streaming interaction data into compact synthetic memories for RS, preserving both training dynamics and downstream model performance under extreme data reduction. Its generality and effectiveness position streaming dataset distillation as a cornerstone for practical, scalable, and reproducible RS development moving forward.