WAFT-Stereo: Warping-Alone Field Transforms for Stereo Matching
Abstract: We introduce WAFT-Stereo, a simple and effective warping-based method for stereo matching. WAFT-Stereo demonstrates that cost volumes, a common design used in many leading methods, are not necessary for strong performance and can be replaced by warping with improved efficiency. WAFT-Stereo ranks first on ETH3D (BP-0.5), Middlebury (RMSE), and KITTI (all metrics), reducing the zero-shot error by 81% on ETH3D, while being 1.8-6.7x faster than competitive methods. Code and model weights are available at https://github.com/princeton-vl/WAFT-Stereo.
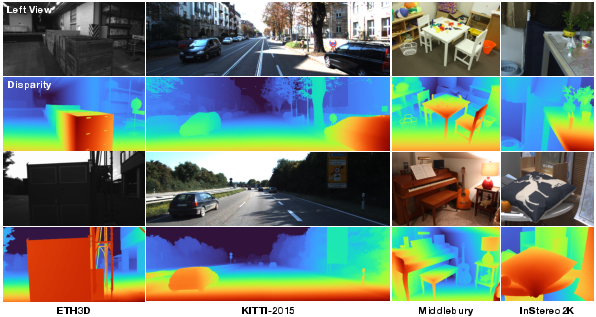
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces WAFT‑Stereo, a new way for computers to figure out depth from two photos taken side‑by‑side (like your two eyes). This task is called “stereo matching.” WAFT‑Stereo shows you can get top accuracy and speed without a common heavy tool called a “cost volume.” Instead, it uses a lighter trick called “warping” plus a smart two‑step guessing process to find how far things shift between the left and right images and turn that into depth.
What questions are the authors trying to answer?
- Do we really need big, memory‑hungry “cost volumes” to get the best stereo results?
- Can a simpler, faster method based on “warping” match or beat the best systems?
- How can we handle very large pixel shifts (common in stereo) without getting lost?
- Can a model trained only on synthetic (computer‑made) images work well on real photos (zero‑shot generalization)?
How did they approach the problem?
Think of stereo matching like this: you have a left photo and a right photo of the same scene. Objects appear slightly shifted between them. That sideways shift (called “disparity”) tells you how far away things are—bigger shift means closer.
Most leading methods:
- Build a “cost volume,” which is like a giant stack of guesses for every pixel across many possible shifts.
- This stack is powerful but very big and slow, so it’s usually built at low resolution, which can blur fine details.
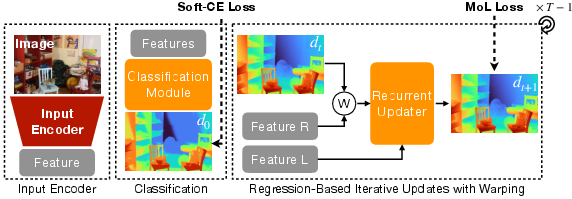
WAFT‑Stereo does it differently:
- Warping instead of cost volumes:
- Imagine sliding (warping) the right image features horizontally to line up with the left image using the current guess, then comparing. You do this repeatedly, refining the guess each time.
- This uses far less memory because you’re not storing a huge stack—just aligning and checking at full detail.
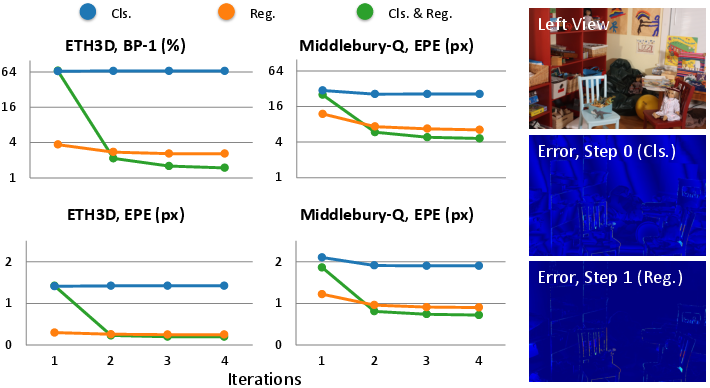
- Two‑step prediction: classification before fine‑tuning
- Step 1 (Classification): The model first picks a rough “bin” for the disparity (like choosing a bucket among preset ranges). This is good for very large shifts because it gives a stable starting point.
- Step 2 (Regression): Then it fine‑tunes the result with a few small, precise updates.
- Simple, efficient design:
- They adapt a strong image backbone (DepthAnythingV2) with small, efficient “LoRA” adapters instead of extra heavy modules.
- They add a few high‑resolution processing blocks to keep fine details sharp.
In everyday terms: rather than checking every possible shift in a giant ledger (cost volume), they repeatedly slide one image to line up with the other, first get a good ballpark, then polish the answer.
What did they find, and why does it matter?
Main findings:
- State‑of‑the‑art accuracy without cost volumes:
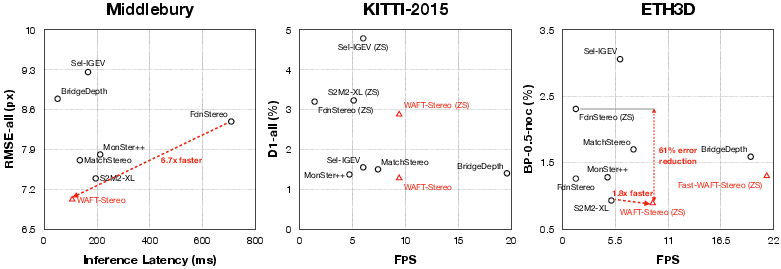
- WAFT‑Stereo ranks first on well‑known benchmarks (ETH3D, KITTI, Middlebury) using the same backbone that others use, showing the gains come from the method, not just bigger models.
- Much faster:
- On qHD inputs (960×540), it runs around 10 frames per second on an NVIDIA L40 GPU—about 1.8× to 6.7× faster than strong competitors. With a smaller backbone, it reaches about 21 FPS.
- Strong zero‑shot generalization:
- Trained only on synthetic data, it still tops ETH3D and reduces error by up to 81% compared to the best previous zero‑shot method.
- It also beats leading methods on KITTI in the zero‑shot setting.
Why this matters:
- Getting rid of cost volumes means you can keep higher resolution and finer details while using less memory and time.
- The two‑step “rough bin then refine” approach helps the model handle big shifts quickly and reliably.
- Strong zero‑shot performance means less need for expensive, hard‑to‑collect real‑world training data with perfect depth labels.
What could this change going forward?
- Faster, more accurate depth for real‑time uses:
- Self‑driving cars, robots, and AR/VR can benefit from high‑quality depth at higher speeds and lower memory cost.
- Simpler building blocks:
- Using warping plus standard neural network parts makes stereo systems easier to build, maintain, and scale.
- Better generalization:
- Training mainly on synthetic data yet working well on real scenes can reduce data collection hurdles and speed up progress.
In short, WAFT‑Stereo shows that a simpler, warping‑based design with a smart two‑step guess‑and‑refine strategy can beat cost‑volume methods in both accuracy and speed, and it works surprisingly well even without real‑world training data.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps and open questions that remain unresolved in the paper and could guide future work:
- Architecture/generalization beyond rectified stereo:
- The method assumes perfectly rectified, calibrated stereo with purely horizontal disparities; robustness to mild vertical disparities, lens distortion, or rectification/calibration errors is not evaluated, nor is extension to full 2D correspondence for unrectified pairs.
- Occlusion and visibility reasoning:
- No explicit occlusion modeling (e.g., left–right consistency checks, visibility masks, or forward–backward checks) is used; the impact of occlusions on warping-based updates and outlier rates is not quantified, and whether occlusion-aware warping would reduce errors remains unexplored.
- Radiometric/illumination robustness:
- The model underperforms on scenes with substantial illumination differences (e.g., Middlebury Classroom2E), but there is no systematic evaluation of photometric robustness (exposure, color shifts, HDR, noise, blur) or study of illumination-invariant features/augmentations to mitigate this failure mode.
- Disparity range and discretization:
- Sensitivity to maximum disparity () and bin count () beyond coarse ablations is unclear; adaptive binning strategies (e.g., content- or camera-conditioned , non-uniform bins, temperature scaling) are not explored, and behavior under extreme baselines or very large disparities is not characterized.
- Warping resolution and high-frequency detail:
- Warping is performed at half resolution; the trade-off between warp resolution, high-resolution processing blocks, and subpixel accuracy on thin structures or high-detail regions is not quantified across different scales (e.g., full-res warping vs. current setting).
- Convergence behavior and iteration scheduling:
- Although classification accelerates convergence, there is no analysis of failure-to-converge cases, per-scene/per-pixel convergence rates, or adaptive/early-exit iteration policies that could further reduce latency without sacrificing accuracy.
- Handling textureless, repetitive, and reflective regions:
- Performance on low-texture, repeated patterns, specular/transparent surfaces, and non-Lambertian cues is not separately analyzed; whether hybrid designs (e.g., lightweight cost-volume cues) help ambiguity resolution remains an open question.
- Encoder dependence and adaptation strategy:
- The approach relies heavily on DepthAnythingV2 backbones and LoRA adapters; the generality to other encoders (especially lightweight/mobile ones), sensitivity to LoRA rank, and comparison with full fine-tuning or alternative adapters are not thoroughly studied.
- Scalability to very high resolutions:
- Attention-based recurrent modules can scale quadratically with tokens; memory/latency behavior at 1080p–4K inputs and in multi-GPU or memory-limited settings is not reported, despite warping itself scaling linearly with resolution.
- Training data composition and domain shift:
- Strong zero-shot performance depends on large synthetic mixtures (~3.3M pairs); the minimal data requirements, scaling laws, and the effect of specific domains/components (e.g., scene types, textures, photometric variability) are not disentangled, and data-efficient training strategies are not explored.
- SceneFlow-only overfitting:
- The model severely overfits when trained only on SceneFlow; the paper does not investigate targeted augmentations, curriculum strategies, or diversity priors that would mitigate this overfitting without requiring much larger datasets.
- Self-/semi-supervised learning on real data:
- The method does not explore photometric or geometric self-supervised losses, pseudo-labeling, or consistency regularizers to leverage unlabeled real stereo, which could further improve sim-to-real generalization.
- Uncertainty estimation and calibration:
- Although the classifier outputs a disparity distribution and the regressor uses a Mixture-of-Laplace loss, the paper does not evaluate predictive uncertainty quality (e.g., calibration, correlation with errors) or its utility for downstream tasks (e.g., confidence-aware fusion).
- Robustness to camera variations:
- Generalization across different baselines, focal lengths, sensor characteristics, and rectification pipelines is not systematically assessed; it remains unclear how to set or adapt and bins when camera intrinsics vary widely.
- Bidirectional reasoning and symmetry:
- Only right-to-left backward warping is used; the potential benefits of symmetric left/right processing, consistency regularization, or fusion of bidirectional estimates are not examined.
- Integration with geometric priors:
- No explicit smoothness/edge-aware priors, planar/affine priors, or global regularization are used; whether incorporating lightweight geometric constraints could reduce outliers without losing efficiency is an open question.
- Fairness and ablation breadth in comparisons:
- While backbones are matched in some comparisons, the paper does not fully control for training budget/data variations across baselines; a more rigorous apples-to-apples evaluation (equal data, iterations, and compute) is not provided.
- Deployment constraints:
- Inference is profiled on an NVIDIA L40; memory/latency/power on embedded GPUs, mobile NPUs, and CPUs are not reported, leaving practical deployability and quantization/pruning strategies unaddressed.
- Extension beyond two-view stereo:
- The method is not evaluated for multi-view stereo or for combining stereo with temporal cues (e.g., video-based refinement), which could test whether warping-only designs scale to larger correspondence problems.
- Theoretical understanding:
- There is no theoretical analysis of convergence or error bounds for warping-only iterative refinement with a classification warm start; conditions under which warping fails (e.g., large occlusions, strong photometric shifts) are not formally characterized.
Practical Applications
Below we translate the paper’s findings into concrete applications. WAFT‑Stereo’s key practical advantages are (a) a cost‑volume‑free, high‑resolution warping design that cuts memory/compute, (b) a classification‑before‑regression update that handles large disparities with fewer iterations, and (c) strong sim‑to‑real generalization from synthetic training. These enable faster, more scalable stereo depth in real systems.
Immediate Applications
- Drop‑in acceleration for existing stereo depth pipelines
- Sectors: software, robotics, automotive, mapping
- What it enables: Replace 3D cost‑volume modules in production stereo stacks (e.g., robotics perception pipelines, 3D reconstruction back‑ends) with WAFT‑Stereo to reduce latency and memory while preserving or improving accuracy.
- Tools/workflows: ROS node for “stereo_rectify → WAFT‑Stereo → depth map → point cloud”; OpenCV/PyTorch integration; plugin for existing MVS/SLAM systems.
- Assumptions/dependencies: Rectified, calibrated stereo; GPU/accelerator availability; careful max‑disparity/bin settings; QA around illumination/camera sync edge cases.
- Real‑time stereo perception for autonomous driving and mobile robots
- Sectors: automotive, robotics, logistics
- What it enables: Near‑real‑time depth (≈10–21 FPS at qHD on modern GPUs) for obstacle detection, free‑space estimation, and path planning; improved detail retention at high resolution.
- Tools/workflows: Replace stereo components in ADAS/AV stacks; on‑robot inference nodes for obstacle avoidance and collision mitigation.
- Assumptions/dependencies: Robustness to motion blur/lighting variations still requires validation; latency figures depend on hardware (e.g., L40 GPU) and iteration count.
- UAV/drone obstacle avoidance and mapping
- Sectors: aerospace, energy, infrastructure inspection, agriculture
- What it enables: Faster depth for low‑altitude flight, terrain following, and dense mapping; improved power efficiency due to reduced memory/compute.
- Tools/workflows: Lightweight onboard stereo module for SLAM/mapping; export to mesh/DEM for inspection reports.
- Assumptions/dependencies: Good calibration and sufficient texture; low‑light or specular scenes may need additional sensors/illumination.
- AR/VR occlusion, anchoring, and effects with dual‑camera devices
- Sectors: consumer electronics, media
- What it enables: High‑resolution depth for realistic occlusions, surface anchoring, and spatial effects on devices with stereo cameras (or add‑on stereo rigs).
- Tools/workflows: Unity/Unreal plugin to ingest stereo frames and output per‑frame depth; post‑process into meshes for AR overlays.
- Assumptions/dependencies: Device must support stereo capture and rectification; verify performance on mobile NPUs/GPUs (desktop results won’t directly transfer).
- Industrial manipulation and bin‑picking
- Sectors: manufacturing, warehousing
- What it enables: Fast, fine‑detail depth for grasp planning; fewer iterations than regression‑only methods reduce cycle times.
- Tools/workflows: Depth front‑end feeding grasp planners; integration with hand‑eye calibration routines.
- Assumptions/dependencies: Reflective/transparent objects remain challenging; may need domain‑specific training or sensor fusion.
- Shelf analytics and volumetric measurement
- Sectors: retail, logistics
- What it enables: Accurate geometry for stock level estimation and package dimensioning with low‑latency stereo rigs.
- Tools/workflows: Stereo kiosk/robot workflows with WAFT‑Stereo → point‑cloud metrics → ERP integration.
- Assumptions/dependencies: Controlled lighting improves stability; policy constraints for in‑store imaging may favor on‑device processing (supported by reduced compute/memory).
- Construction progress tracking and site safety
- Sectors: AEC (architecture, engineering, construction)
- What it enables: Frequent, fast scanning with stereo cameras on helmets/robots for progress quantification and hazard detection.
- Tools/workflows: Site walk → WAFT‑Stereo depth → alignment to BIM for variance reports; near‑real‑time safety alerts.
- Assumptions/dependencies: Dust/low light may degrade texture; multi‑view fusion may be needed for completeness.
- Agricultural row navigation and yield estimation
- Sectors: agriculture
- What it enables: Robust under-vegetation geometry capture at higher resolution for plant/row detection and canopy volume estimates.
- Tools/workflows: On‑tractor stereo module integrated with guidance systems; drone crop scouting.
- Assumptions/dependencies: Seasonal lighting variability; foliage motion may require temporal filtering.
- Privacy‑preserving on‑prem analytics via depth‑only processing
- Sectors: smart buildings, public safety, policy
- What it enables: Local conversion of images to depth to reduce PII in downstream analytics (people counts, distance monitoring), aligning with privacy guidelines.
- Tools/workflows: Edge gateways that discard RGB after depth computation; depth‑only event streams to cloud.
- Assumptions/dependencies: Stakeholder acceptance of synthetic‑trained models; on‑device compute budgets.
- Faster academic experimentation and teaching
- Sectors: academia, education
- What it enables: A simpler, cost‑volume‑free baseline for stereo research and coursework; easier to modify and scale with standard ViT/ResNet blocks.
- Tools/workflows: Coursework labs comparing warping vs. cost volumes; ablations on classification‑before‑regression; LoRA fine‑tuning exercises.
- Assumptions/dependencies: Availability of backbone weights (e.g., DepthAnythingV2) under compatible licenses.
- Synthetic‑only training to reduce real data collection
- Sectors: R&D, startups
- What it enables: Competitive zero‑shot performance trained on synthetic mixtures, lowering data acquisition and annotation costs.
- Tools/workflows: Synthetic data pipeline (domain randomization) → WAFT‑Stereo pretraining → targeted small real fine‑tune.
- Assumptions/dependencies: Synthetic realism/diversity is key; residual domain gaps (e.g., illumination) may need small on‑site adaptation.
- Acceleration for multi‑view stereo and photogrammetry back‑ends
- Sectors: geospatial, VFX
- What it enables: Replace per‑pair stereo modules to cut batch render times, especially in high‑resolution reconstructions.
- Tools/workflows: Integrations with COLMAP‑style MVS; batched processing on GPUs.
- Assumptions/dependencies: Non‑rectified/projective pairs must be rectified; large baselines may demand tuning of disparity bins and search ranges.
Long‑Term Applications
- Edge and mobile deployment (embedded GPUs/NPUs, ASIC/FPGA)
- Sectors: consumer electronics, robotics
- What it enables: The warping‑centric design is hardware‑friendly (bilinear sampling, concatenation), making it a candidate for low‑power accelerators.
- Dependencies: Kernel optimization on mobile NPUs; mixed‑precision stability; memory bandwidth constraints.
- Certified stereo modules for safety‑critical automotive use
- Sectors: automotive (ISO 26262)
- What it enables: Path to certifiable, simpler architectures (no large 3D cost volumes) with predictable memory footprints.
- Dependencies: Extensive corner‑case validation (glare, snowfall); formal verification and fail‑operational design.
- Hybrid LiDAR‑stereo fusion and multi‑sensor perception
- Sectors: automotive, robotics, drones
- What it enables: Use fast stereo for dense geometry with sparse LiDAR for scale/robustness; reduced LiDAR cost/weight in some platforms.
- Dependencies: Time sync and calibration; robust fusion frameworks; dynamic‑scene handling.
- Video‑temporal stereo and 4D reconstruction
- Sectors: AR/VR, VFX, research
- What it enables: Extend the iterative warping scheme with temporal cues (optical flow) for more stable, temporally consistent depth.
- Dependencies: Model extensions and training on stereo‑video; drift/temporal consistency losses.
- Medical stereo (endoscopy, surgical robotics)
- Sectors: healthcare
- What it enables: Low‑latency surgical scene depth with better detail around fine structures.
- Dependencies: Domain‐specific training, photometric invariance, regulatory approval.
- Aerial and satellite stereo mapping with large baselines
- Sectors: geospatial, defense, environmental monitoring
- What it enables: Classification‑before‑regression may help handle very large disparities in satellite/airborne pairs after rectification.
- Dependencies: Sensor models and rectification for push‑broom cameras; radiometric normalization; high‑res memory scaling.
- Underwater and adverse‑weather stereo
- Sectors: marine robotics, public safety
- What it enables: A starting point for robust depth with additional photometric/contrast normalization and learned priors.
- Dependencies: Specialized training data; domain adaptation to turbidity and scattering.
- Event‑camera stereo and high‑speed scenes
- Sectors: robotics, UAVs
- What it enables: Adapt warping‑only updates to asynchronous event streams for micro‑latency depth in fast motion.
- Dependencies: New feature encoders for events; hybrid frame‑event training.
- Standardized, lower‑cost 3D capture for content creation
- Sectors: media, metaverse
- What it enables: Commodity stereo rigs producing production‑grade meshes when paired with improved, efficient depth.
- Dependencies: Tooling for calibration, temporal fusion, and mesh texturing.
- Policy and procurement frameworks favoring on‑device processing
- Sectors: public sector, smart cities
- What it enables: Adoption of privacy‑preserving, compute‑efficient depth sensors for people‑flow and infrastructure monitoring.
- Dependencies: Clear guidance on synthetic‑data use, bias assessments, and energy budgets.
- Foundation‑style training for geometry with synthetic data
- Sectors: academia, AI platforms
- What it enables: Scalable, synthetic‑first training regimes (as shown by strong zero‑shot results) for broader geometry tasks (multi‑view, monocular depth).
- Dependencies: Dataset diversity and realism; benchmarks that reflect real deployment conditions (illumination changes, non‑Lambertian surfaces).
Cross‑cutting assumptions and dependencies
- Stereo inputs must be rectified and cameras calibrated; epipolar alignment quality strongly affects results.
- Performance claims (≈10–21 FPS at qHD) were profiled on an NVIDIA L40 with BF16; embedded/mobile throughput will be lower unless optimized.
- Choice of backbone (e.g., DepthAnythingV2) and LoRA fine‑tuning affects latency and licensing; verify model licenses for commercial use.
- Robustness limitations remain under severe illumination changes, glare, low‑texture, and transparent/reflective surfaces; consider fusion (IR/active sensors) or domain adaptation.
- Iteration count and disparity bin configuration trade speed for accuracy; deployment should expose these as tunables.
Glossary
- AdamW optimizer: A variant of the Adam optimization algorithm that decouples weight decay from the gradient update to improve generalization. "using AdamW optimizer"
- Backward warping: A warping technique that samples the target feature/image at coordinates mapped backward from the reference using the current motion estimate. "it backward-warps the target-view feature map using the current flow estimate"
- Bilinear sampling: An interpolation method that samples values at non-integer coordinates by linearly blending the four nearest pixels. "computed via bilinear sampling"
- BP-X: A benchmark metric (Bad Pixel at threshold X) measuring the percentage of pixels with error exceeding X pixels. "We follow the benchmark protocols and report BP-0.5, BP-1, and BP-2"
- Convex upsampling: An upsampling technique that reconstructs high-resolution predictions via convex combinations of neighborhood features/weights. "upsampled to the input resolution via convex upsampling"
- Cost volume: A 3D tensor storing matching costs between features across disparity candidates, used to find correspondences in stereo/flow. "cost volumes, a common design used in many leading methods"
- D1: The KITTI stereo metric counting pixels with error > 3 pixels and > 5% of ground-truth disparity. "report D1 for KITTI-2015"
- Disparity: The horizontal pixel shift between corresponding points in rectified stereo images, inversely related to depth. "The horizontal motion, or disparity, can be directly converted to depth."
- DPT head: A Dense Prediction Transformer head that upsamples and aggregates transformer features for dense outputs. "We use a fully trainable DPT head"
- Epipolar line: The line in the second view along which a corresponding point must lie in rectified stereo geometry. "along the horizontal epipolar line."
- Feature-space warping: Aligning feature maps (rather than raw images) using the current motion/disparity estimate to facilitate matching. "replaces cost-volume indexing with feature-space warping"
- Ground-truth disparity: The reference (true) disparity values used for supervision during training. "the ground-truth disparity as"
- Hidden state: The internal recurrent representation carried across iterations in the updater module. "the hidden state"
- Iterative refinement: An approach that progressively improves predictions by repeatedly updating estimates (e.g., disparity) over multiple steps. "iterative refinement framework"
- KL divergence: A measure of difference between two probability distributions, often used as a loss equivalent to soft cross-entropy. "soft cross-entropy loss (equivalently, KL divergence up to a constant)"
- Latency: The time taken to process an input, typically measured per frame or per stereo pair. "The latency grows almost linearly with the number of iterative updates"
- LoRA: Low-Rank Adapters; a parameter-efficient fine-tuning technique that injects low-rank trainable matrices into a frozen backbone. "fine-tune the pre-trained encoder with LoRA"
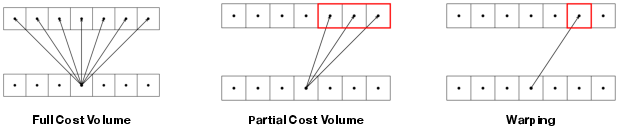
- Look-up radius: The search window size around a current estimate when constructing or indexing partial cost volumes. "look-up radius (partial cost volume)"
- MACs: Multiply–Accumulate operations; a proxy for computational cost used to compare model efficiency. "uses fewer MACs."
- Mixture-of-Laplace (MoL) loss: A probabilistic regression loss modeling errors as a mixture of Laplace distributions to better capture heavy tails. "supervised by a Mixture-of-Laplace loss"
- Non-occluded (noc): Pixels that are visible in both views and thus have valid correspondences for evaluation. "non-occluded pixels"
- Optical flow: The apparent 2D motion field between two images; stereo disparity can be seen as its 1D horizontal component. "Stereo matching can be understood as a special case of optical flow"
- Optimal transport: A framework for aligning distributions (e.g., matching probabilities) that can initialize disparity from cost volumes. "applies an optimal transport algorithm"
- Pareto frontier: The set of methods that are not dominated in both accuracy and efficiency in trade-off analyses. "remains on the Pareto frontier when considering accuracy–efficiency trade-offs."
- Partial cost volume: A reduced cost volume that evaluates matching costs only within a small window around the current estimate. "partial cost volumes compute costs only in a small window around the current disparity estimate"
- Patchifier: A preprocessing step that splits high-resolution features/images into non-overlapping patches for transformer processing. "apply an patchifier before the ViT blocks"
- Probabilistic Mode Concentration (PMC) loss: A loss encouraging the predicted matching distribution to concentrate around the correct mode. "supervised by the Probabilistic Mode Concentration (PMC) loss."
- qHD: Quarter High Definition; an input resolution around 960×540 used for real-time benchmarking. "processes qHD stereo pairs at 10 FPS"
- RAFT paradigm: A family of iterative matching methods that refine predictions via recurrent updates guided by correlation or warping. "adopt the RAFT paradigm"
- Rectified images: Stereo images that have been warped so corresponding points lie on the same horizontal scanline. "given two rectified images"
- Recurrent updater: The iterative module (e.g., GRU/transformer-based) that refines disparity by consuming aligned features and hidden states. "a recurrent updater that takes backward-warped right view features as input"
- ResNet blocks: Residual convolutional blocks used to preserve and refine high-resolution details in the update module. "replace the high-resolution skip connection with several ResNet blocks"
- RMSE: Root Mean Square Error; a measure of average squared error used as an evaluation metric. "report BP-2, BP-4, and RMSE"
- Sim-to-real generalization: The ability of a model trained on synthetic data to perform well on real-world datasets without fine-tuning. "achieves strong sim-to-real generalization"
- Soft cross-entropy loss: A cross-entropy computed against a soft (smoothed) target distribution rather than a one-hot label. "supervised by a soft-cross-entropy loss"
- Soft-argmax: A differentiable approximation of argmax that computes the expectation over class indices weighted by probabilities. "derives the initial disparity estimate via soft argmax."
- Softmax normalization: Converting raw logits into a probability distribution by exponentiating and normalizing. "matching probabilities after softmax normalization"
- U-Net: A U-shaped encoder–decoder CNN with skip connections, commonly used for dense prediction tasks. "includes a small U-Net"
- Vision Transformer (ViT): A transformer architecture that operates on image patches for vision tasks. "a ViT-small"
- Warping: Aligning one view to another using a disparity/flow estimate to facilitate matching or refinement. "Warping offers two key advantages over cost volumes."
- Zero-shot: Evaluation without training/fine-tuning on the target dataset; often training on synthetic data only. "evaluated in the zero-shot setting"
Collections
Sign up for free to add this paper to one or more collections.