- The paper demonstrates that realistic federated learning deployments substantially reduce the effectiveness of poisoning attacks compared to idealized research conditions.
- It employs TFLlib to evaluate backdoor and byzantine attacks across diverse datasets and models under random client selection and hybrid heterogeneity.
- Findings reveal that single-point metrics misrepresent risk, advocating for multi-metric evaluations capturing stability, utility impact, and attack stealthiness.
Security Risks of Federated Learning in Practice: Analysis and Implications
Introduction
This paper systematically investigates the disconnect between the research literature on federated learning (FL) security—specifically poisoning attacks—and the realities of practical, large-scale FL deployments (2603.20615). The authors introduce TFLlib, a comprehensive measurement library, and use it to empirically evaluate existing attack strategies under realistic constraints, including random client selection, hybrid heterogeneity (statistical, device, communication), and stringent utility-aware reporting metrics. The findings indicate substantial overestimation of attack risk in prior literature, stemming from idealized assumptions about adversarial power, data homogeneity, and evaluation protocols.
Systematization of Research-to-Practice Gaps
Three key mismatches between academic research and practical FL deployments are identified:
- Threat Model Simplification: Prior work assumes unrealistically high adversarial presence, deterministic aggregation participation, and access to benign updates. In contrast, production FL platforms have low malicious ratios, random client selection, and often lack secure aggregation.
- Evaluation Scope Limitations: Security assessments in the literature are dominated by image tasks, i.i.d. data, and homogenous architectures (mostly CNNs). Real deployments span text, tabular, and image data, with a diversity of models (MLPs, CNNs, Transformers) and clients exhibiting cross-cutting heterogeneity.
- Metric Myopia: Research commonly focuses on single-point metrics (e.g., final round attack success rate, ASR) and neglects temporal variation, utility loss, and attack stealthiness, which are critical in real-world scenarios.
These mismatches are systematically contrasted in the paper, arguing that they cause a distorted understanding of FL poisoning threat landscapes.
TFLlib: Practical FL Security Risk Evaluation
To address the evaluation gaps, the authors develop TFLlib (Figure 1), a modular FL measurement framework designed to:
- Support a diverse suite of datasets (tabular, image, text) and models (MLP, CNN, Transformer),
- Simulate cross-device, asynchronous FL with hybrid client heterogeneity, and
- Implement both byzantine and backdoor attack families under realistic threat models.
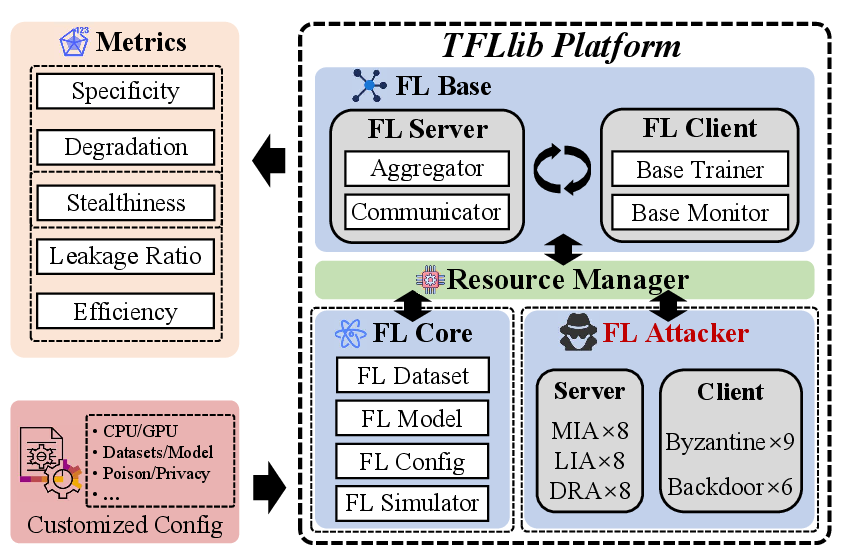
Figure 1: System Design of TFLlib, illustrating data/model diversity and joint management of statistical, device, and communication heterogeneity.
The framework facilitates parallel experimentation at scale and provides refined, utility-aware security metrics such as:
- Backdoor Specificity Accuracy (BSA) and Variance (BSV): Mean/variance of ASR over the converged training window,
- Byzantine Degradation Accuracy (BDA) and Variance (BDV): Benign utility drop and its volatility over time,
- Main Task Accuracy and Variance (ACC, ACCV): Quantifying stealth penalty paid by effective attacks.
Empirical Findings: Attacks in Practice vs. Literature
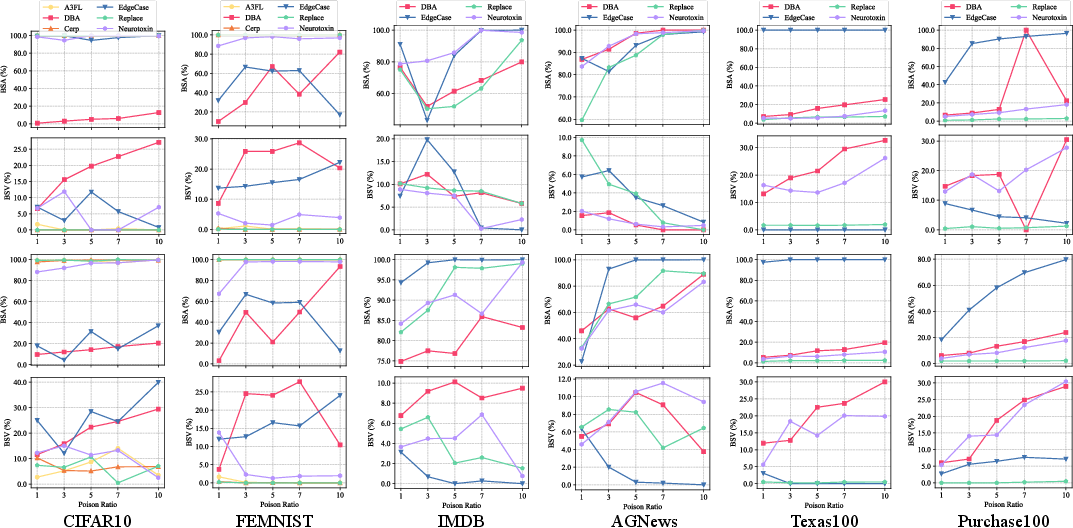
Extensive evaluation across multiple datasets and modalities demonstrates a strong divergence between practical and idealized settings. Under idealized research conditions (e.g., fixed adversary participation, no client heterogeneity), several backdoor attacks reach near-saturating BSA, with minimal stability issues and little main task degradation. However, under practical settings, performance degrades markedly:
Attack Stealthiness
Evaluation of stealth metrics reveals that many apparently successful attacks in the literature would, in fact, incur operationally obvious utility penalties or are temporally unstable when faced with realistic client dynamics.
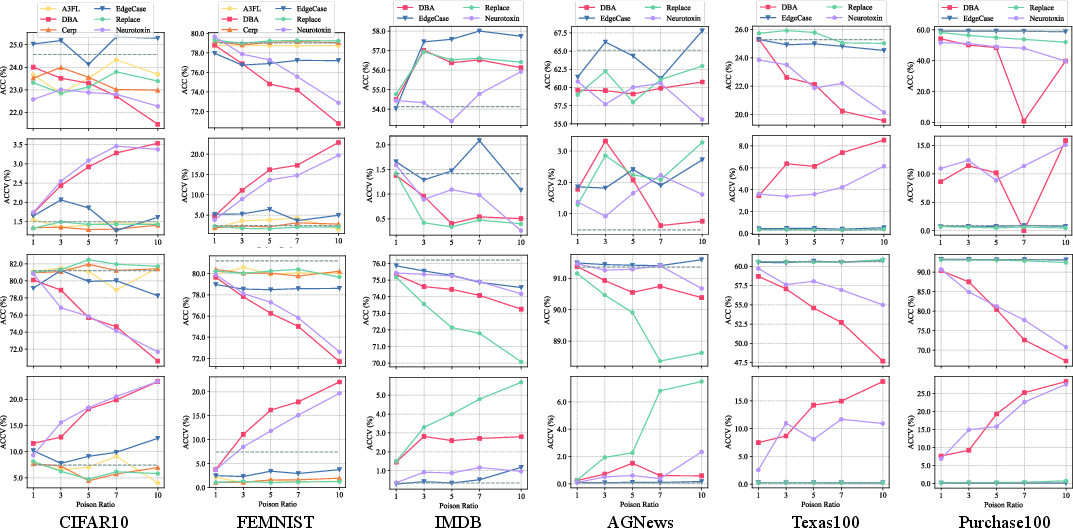
Figure 3: Backdoor stealthiness metrics show that attacks achieving momentarily high specificity often induce large or volatile benign-task accuracy drops, which would be noticed in practice.
Metric Implications
The authors emphasize that reporting only end-of-training ASR is systematically misleading: strong but transient attacks, or those visible via utility loss, are mischaracterized as high-risk when they are unlikely to succeed undetected in sensible deployments. Multi-metric reporting (effectiveness, stability, utility impact) is necessary to faithfully assess risk.
Theoretical and Practical Implications
The study's results reshape the lens through which FL poisoning risks should be evaluated and managed:
- For FL Security Algorithm Designers: Threat models and benchmarks must reflect realistic, practical system conditions (random client selection, hybrid heterogeneity, model/data diversity). Defensive claims against artificially strengthened attacks are uninformative for production.
- For FL System Providers: Benchmarks from academic papers should not be loosely mapped to deployment risk estimations. Instead, local risk measurement should use the system's own heterogeneity, participation policies, and performance goals.
- For Both Communities: Focusing on the joint reporting of sustained attack effectiveness, stability, and utility cost guides resource allocation toward actual threats. Overengineered defenses for risks that vanish under realistic constraints should be avoided.
Future Work
The authors note the need to extend TFLlib and the principled evaluation philosophy to privacy-focused attacks (e.g., inference, inversion) and to more completely characterize defense cost vs. utility tradeoffs across heterogeneous scenarios. Additionally, they recommend further empirical study of how architecture diversity (MLPs, CNNs, Transformers) modulates vulnerability profiles.
Conclusion
This work provides a rigorous, measurement-driven foundation for evaluating poisoning security in federated learning. By systematically deconstructing research-to-practice gaps and empirically measuring attack viability under operational constraints with TFLlib, the field is enabled to move toward security assessments and mitigation strategies that reflect the true risk landscape facing deployed FL systems. Alignment between practical deployment properties and security evaluation protocols is essential to avoid both over- and under-estimating adversarial risk in production federated learning.