LagerNVS: Latent Geometry for Fully Neural Real-time Novel View Synthesis
Abstract: Recent work has shown that neural networks can perform 3D tasks such as Novel View Synthesis (NVS) without explicit 3D reconstruction. Even so, we argue that strong 3D inductive biases are still helpful in the design of such networks. We show this point by introducing LagerNVS, an encoder-decoder neural network for NVS that builds on `3D-aware' latent features. The encoder is initialized from a 3D reconstruction network pre-trained using explicit 3D supervision. This is paired with a lightweight decoder, and trained end-to-end with photometric losses. LagerNVS achieves state-of-the-art deterministic feed-forward Novel View Synthesis (including 31.4 PSNR on Re10k), with and without known cameras, renders in real time, generalizes to in-the-wild data, and can be paired with a diffusion decoder for generative extrapolation.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
Imagine you took a few photos of a room and then wanted to see what the room looks like from a new angle you didn’t actually photograph. That’s the goal of Novel View Synthesis (NVS): making a realistic new picture of a scene from a new camera position using just a few existing images.
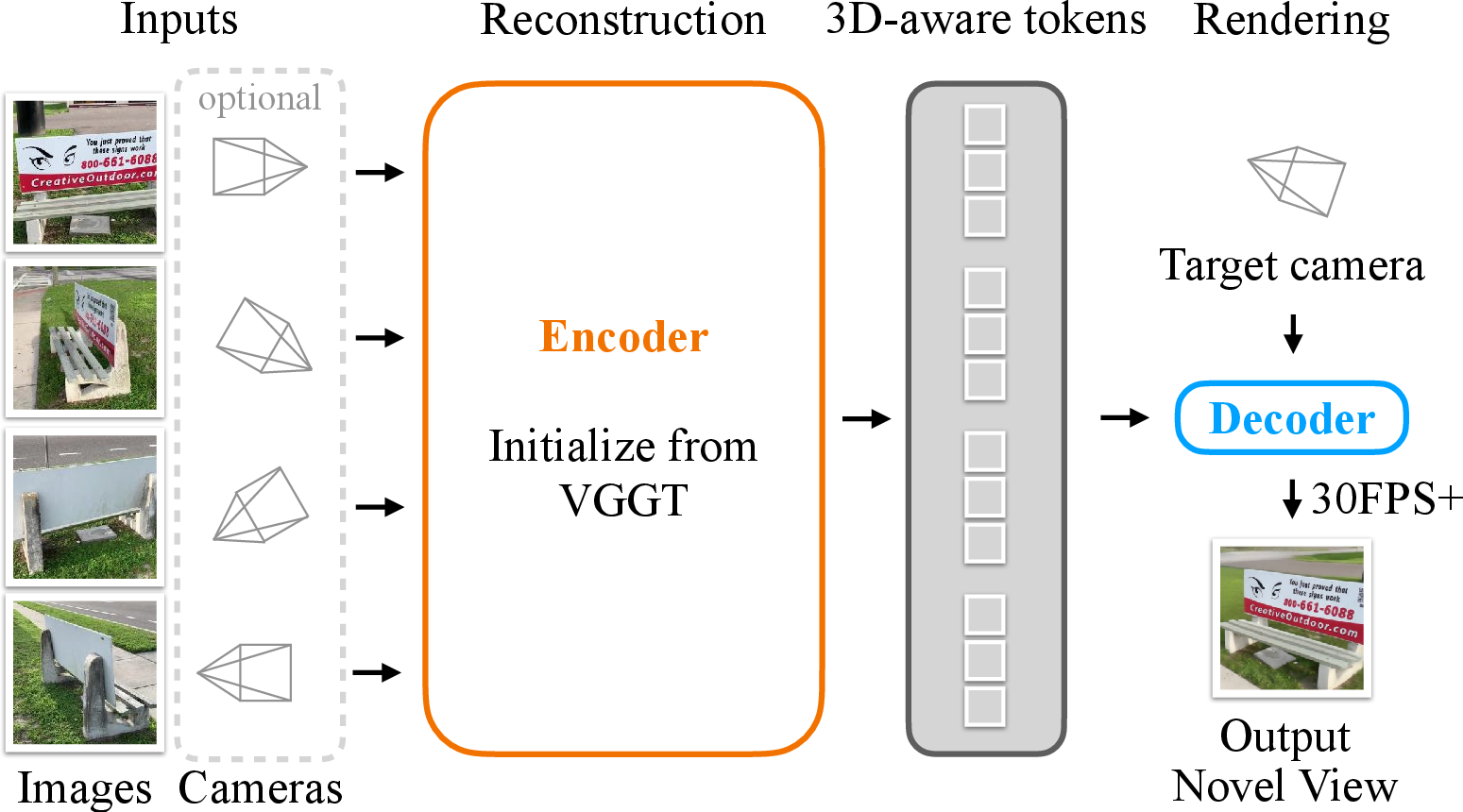
This paper introduces LagerNVS, a fast, neural network–based method that creates these new views in real time. It doesn’t build a full 3D model first. Instead, it learns to “paint” the new view directly, while still using a strong sense of 3D learned from other tasks.
What the researchers set out to do (plain goals)
The authors aimed to:
- Build a system that makes new views quickly (real-time) without first constructing a detailed 3D model.
- Keep the quality high by giving the system a “3D sense” learned from previous 3D tasks.
- Figure out which network design works best for both quality and speed.
- Make it work in many situations (indoors, outdoors, wide images, 360° images), even when the exact camera settings aren’t known.
How it works (simple explanation of the approach)
Think of the system as having two main parts: an “encoder” that studies the input photos and a “decoder” that uses those notes to draw the new view.
- Encoder (learning strong 3D instincts):
- The encoder is initialized from a powerful model called VGGT that was trained to understand 3D (like depth and camera positions) from images.
- Even though LagerNVS doesn’t build a full 3D model, it uses VGGT’s “3D-aware features” — basically, it learns good internal notes about the scene’s shapes and layouts.
- If the cameras for the input photos are known, those are added in a simple way so the model can use them; if not, it can still work.
- Decoder (painting the new view):
- To tell the decoder where to “stand” and “look,” the new camera is turned into a kind of map that says, for each output pixel, which direction into the 3D scene that pixel is looking (think: a grid of tiny arrows showing the viewing directions).
- A transformer network (a type of neural network that’s good at focusing attention on relevant information) uses these directions and the encoder’s features from the input photos to generate the new image.
- Two decoder styles are tested: “full attention” (slightly better quality, slower when many photos are used) and “cross-attention” (a bit faster, slightly less accurate). Both are still fast.
- Training (how it learned):
- The system is trained by comparing its predicted new view to the real one and adjusting itself to minimize differences (using standard image similarity measures).
- It’s trained on a big mix of datasets so it learns to handle many kinds of scenes and camera setups.
- The whole model is fine-tuned end-to-end, which turns out to be important for keeping colors, textures, and reflections accurate (not just shapes).
Analogy: The encoder is like a student who has already practiced 3D sketching a lot, so they recognize shapes from photos. The decoder is the student’s hand, drawing the same scene from a new spot based on those notes. Because the student has strong 3D instincts, the drawing comes out more realistic even without building a full 3D sculpture first.
What they found (main results and why they matter)
Here are the key outcomes:
- Better quality than previous methods that skip explicit 3D:
- LagerNVS beats the previous best “direct rendering” approach (LVSM) on a standard benchmark (RealEstate10k) by about +1.7 dB PSNR (a common image-quality score), reaching about 31.4 PSNR. This means noticeably cleaner, more accurate images.
- Fast and practical:
- It can render 512×512 images at over 30 frames per second on a single powerful graphics card (H100), even with up to 9 input photos — fast enough for interactive use.
- Works in more scenarios:
- It handles normal photos, 360° scenes, different aspect ratios, and even cases where the input camera settings are not given.
- It can do single-view NVS for small camera moves (if you only have one input image).
- Strong 3D pretraining is crucial:
- Using the 3D-aware encoder (from VGGT) and fine-tuning it end-to-end made a big difference. Starting from scratch or using generic 2D features (like DinoV2) led to worse results.
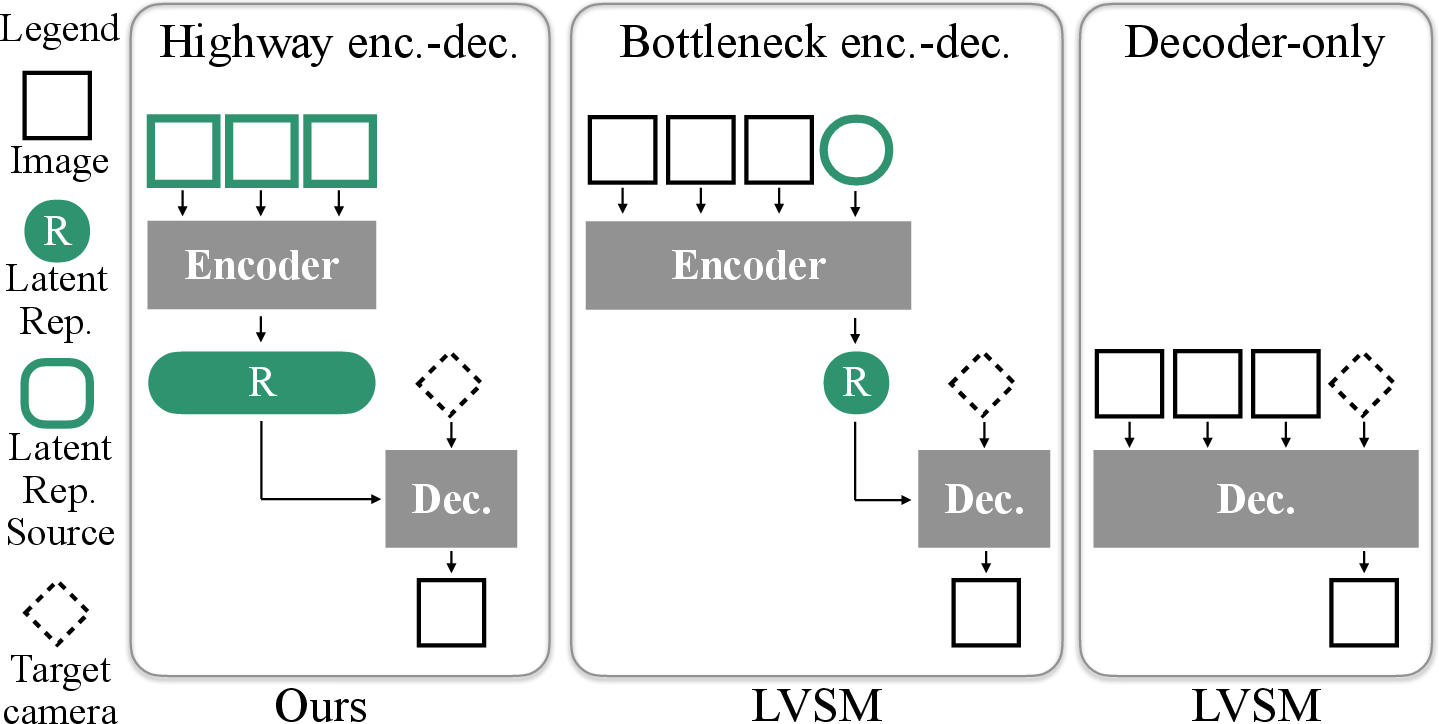
- Best architecture choice:
- Among three designs — “decoder-only,” “bottleneck encoder-decoder,” and “highway encoder-decoder” — the “highway” version (which passes lots of information from input photos to the decoder) gave the best mix of quality and speed.
- Outperforms methods that do build an explicit 3D model on the fly:
- Compared to fast 3D Gaussian Splatting methods (which do create a 3D representation quickly), LagerNVS often produced sharper details, handled thin structures and reflections better, and dealt more gracefully with parts of the scene not visible in any input photo.
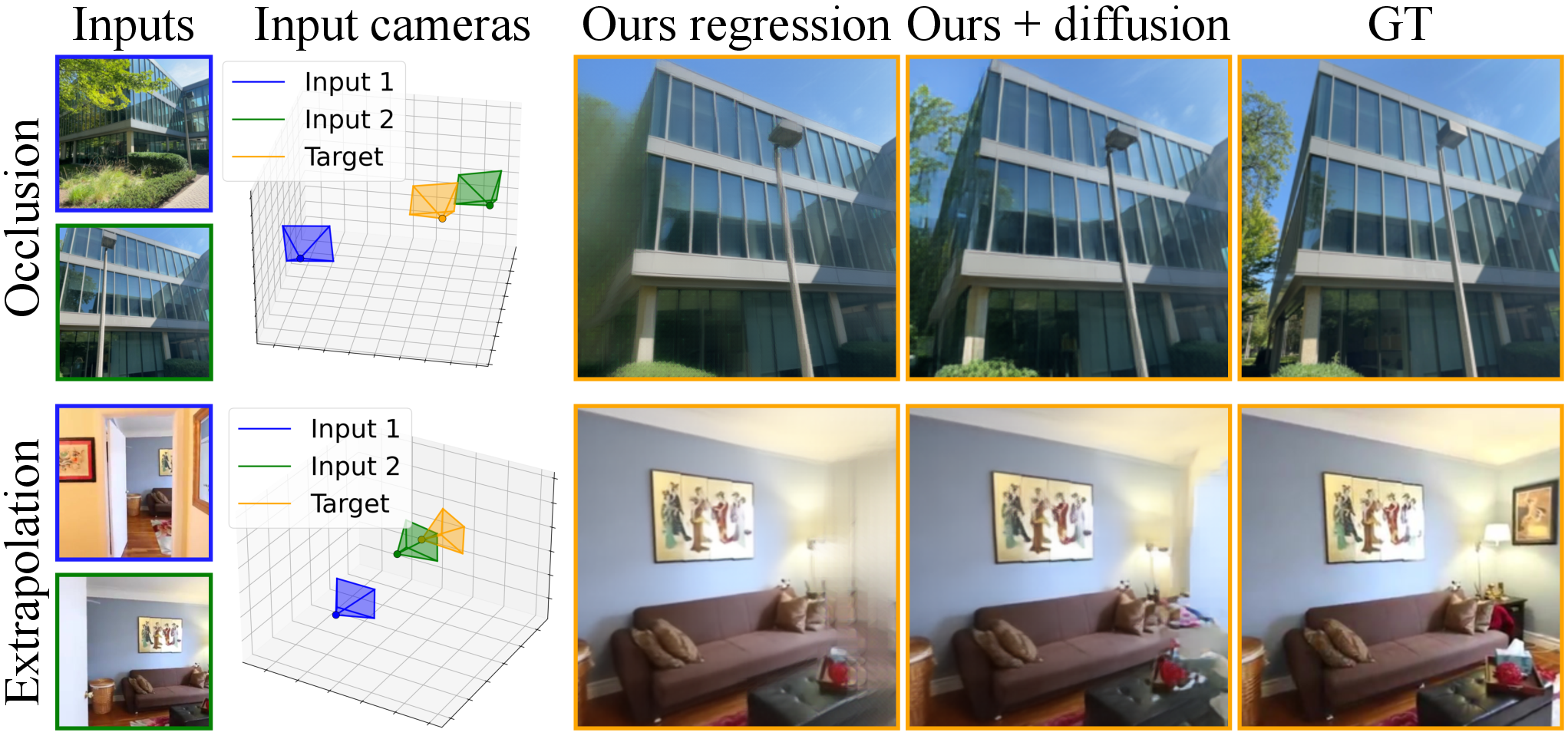
- Can be made generative for tricky cases:
- When the new view shows parts of the scene that were never seen before, guessing becomes necessary. The authors show their decoder can be turned into a diffusion model (a kind of generator) to “hallucinate” plausible content in those areas, reducing blur and filling gaps more intelligently.
Why it matters: You get high-quality, real-time new views without the extra complexity of building a full 3D model. It’s more flexible and robust, and it can still imagine missing parts when switched to a generative mode.
What this could mean going forward (simple implications)
- Strong 3D instincts help, even without building explicit 3D: Training on 3D tasks first (like VGGT did) gives the model a better “feel” for shape and depth, which makes new view synthesis more accurate and reliable.
- Real-time, high-quality view changes are within reach: This is useful for AR/VR, robotics, video editing, and games — anywhere you want to move a virtual camera around a real scene quickly.
- Fewer constraints: It works even if you don’t know exact camera settings and across many types of images and scenes, making it easier to use in the real world.
- Generative add-on can fill in the unknown: With diffusion, the system can plausibly complete unseen parts, which is important when you only have a few photos.
- Future direction: Combining 3D-aware pretraining, efficient decoders, and generative tools could lead to even more realistic and flexible systems that feel like moving through a real place using just a handful of pictures.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed so future work can act on each point:
- Dependence on VGGT pre-training: Performance strongly relies on VGGT’s 3D-supervised features; it is unclear how robust LagerNVS is when VGGT is out-of-distribution, or whether alternative/self-supervised 3D pretraining could match performance without this dependency.
- No explicit 3D output: The latent representation is not decodable to explicit geometry (e.g., depth, normals, meshes), limiting editability, relighting, or physical consistency. Methods to extract or regularize explicit 3D from the latent features are not provided.
- Multi-view consistency across rendered trajectories: The paper does not evaluate consistency when rendering long camera paths (temporal flicker, geometry drift). Training objectives and metrics for enforcing/measuring cross-view consistency are missing.
- Operating without source cameras: While the model “can operate without cameras,” the accuracy/robustness limits are not quantified across baselines, baselines distances (wide/low-overlap), and scene types. Failure modes and required overlap are not characterized.
- Camera model simplification: Intrinsics are reduced to horizontal/vertical FOV with the principal point assumed centered and no lens distortion. Handling general intrinsics (off-center principal point, skew), fisheye/GoPro distortion, rolling shutter, and calibrated 360 cameras is not addressed.
- Dynamic/nonrigid scenes: Training assumes (approximately) static scenes. How the method handles moving objects, nonrigid motion, or time-varying illumination is unexplored.
- Deterministic regression limitations: The L2+perceptual objective blurs ambiguous/occluded regions. The diffusion variant is only a preliminary proof-of-concept (pixel-space, small model, 60k steps), with no quantitative evaluation of fidelity, diversity, nor cross-view consistency of sampled results.
- Scaling with number of source views: Decoder complexity is O(V) (cross-attn) or O(V2) (full-attn). Real-time is shown up to 9 views at 512×512 on an H100, but scalability to larger V (and degradation in quality/speed/memory) is not characterized.
- Resolution scaling: Real-time results are given at 512×512. The speed/quality trade-offs at higher resolutions (e.g., 1024×1024, 2K) are not reported; potential aliasing and tile/patch artifacts with the 8×8 patching are unstudied.
- Hardware dependency and deployability: Real-time claims are on an H100 GPU. Latency, memory, and throughput on commodity GPUs, edge devices, or mobile hardware are not evaluated.
- Encoding latency and streaming: “Encoding requires mere seconds” is not quantified, and no strategies are given for streaming/incremental encoding or amortizing encoding over online video capture.
- Camera pose noise robustness: For the “with cameras” setting, sensitivity to pose errors (e.g., typical SfM/SLAM noise) is not measured, nor are mechanisms to handle partially wrong/noisy intrinsics/extrinsics.
- View selection and weighting: The highway encoder-decoder leverages all source tokens, but there is no policy for view selection, redundancy handling, or attention-based weighting under varying overlap or conflicting inputs.
- Camera-ray encoding choices: Plücker encoding is adopted without ablation against alternatives (e.g., ray direction + origin, spherical rays, epipolar encodings). Impact on generalization and accuracy is unknown.
- Token budget and memory: The number and spatial arrangement of encoder tokens (from VGGT) are not optimized/ablated. Content-adaptive token pruning/compression and their impact on quality and latency are unexplored.
- Dataset composition and bias: The 13-dataset mix is only summarized; there is no analysis of which datasets contribute most to generalization, nor assessment of bias (e.g., indoor-heavy vs outdoor, lighting diversity, non-Western scenes).
- Photometric inconsistency handling: The loss assumes photometric consistency; robustness to exposure/white balance differences, motion blur, noise, and HDR scenes is not analyzed; no normalization or photometric-correction module is proposed.
- Scale parameter w: The introduced scene-scale input is relegated to the supplement; there is no ablation of how w is set/learned, its sensitivity, or its effect on metric consistency across scenes.
- Comparison to per-scene optimized methods: A thorough quality–compute trade-off with per-scene optimized NeRF/3DGS methods (under matched time/compute budgets) is absent, leaving unclear where LagerNVS sits for high-fidelity offline use.
- Thin structures and high-frequency details: While improved vs some baselines, a systematic failure analysis for fine geometry (e.g., wires, foliage) and high-frequency textures is not provided.
- Generalization boundaries: Qualitative generalization to “in-the-wild” is shown, but quantitative benchmarks for challenging regimes (nighttime, outdoor urban, reflective/translucent scenes, extreme baselines) are limited.
- Diffusion integration for real-time: The generative extension’s sampling speed and feasibility for interactive applications are not addressed; architectural changes (e.g., latent diffusion, distillation) to achieve real-time sampling are unexplored.
- Joint tasks and supervision: The paper hints that future 3D backbones should preserve appearance; however, concrete strategies to co-train encoders on geometry and appearance (rendering losses, multi-task heads) and their effect on NVS remain open.
- Downstream usability: Whether the latent representation supports downstream tasks (e.g., depth/normal prediction, pose refinement, object insertion, relighting) is not studied; interfaces from the latent to such tasks are missing.
- Training efficiency and scaling laws: Beyond high-level comparisons to SVSM, there is no systematic study of encoder/decoder capacity, training compute vs performance, or data-scaling laws tailored to this architecture.
Practical Applications
Overview
LagerNVS introduces a fully neural, feed‑forward, encoder–decoder architecture for novel view synthesis (NVS) that renders new viewpoints directly from images without explicit 3D reconstruction. Key practical innovations include:
- A “highway” encoder–decoder that amortizes per-scene compute (encode once, render many views) for real‑time decoding.
- 3D‑aware latent features via pre‑training on a 3D reconstruction model (VGGT), then end‑to‑end fine‑tuning for appearance and camera conditioning.
- Operation with or without known source cameras, generalization to diverse image types (ego‑centric, 360°, non‑square), and single‑view NVS for small motions.
- A lightweight decoder capable of 30+ FPS at 512×512 with up to 9 source images on a single H100 GPU; encoding takes seconds.
- Optional diffusion fine‑tuning to hallucinate unseen content when deterministic regression is insufficient.
Below are actionable applications grouped by near‑term deployability and longer‑term opportunities.
Immediate Applications
These can be deployed with the current method (deterministic LagerNVS) and typical GPU resources; integration work and dataset adaptation may be needed.
- Free‑viewpoint previsualization and virtual cinematography (Media & Entertainment, Software)
- What: Interactive “virtual camera” moves from a handful of set photos or short clips; real‑time viewport for directors and VFX previz teams.
- Tools/workflows: Unity/Unreal plugin that (1) ingests 2–9 frames, (2) runs a scene encode pass, (3) enables interactive camera rendering via Plücker ray maps; cloud API for previz.
- Assumptions/dependencies: Mostly static scenes; best quality with moderate baseline overlap; 512×512 real‑time on datacenter GPUs (H100/A100); consumer GPUs will be slower or lower‑res.
- E‑commerce “turntable” product views from few images (Retail, Advertising)
- What: Generate smooth, interactive viewpoints of products from 3–9 catalog photos without building explicit 3D assets.
- Tools/workflows: Batch encoder in a content pipeline; web viewer streams novel views on demand; fallback to multi‑angle captures for shiny/transparent items.
- Assumptions/dependencies: Controlled lighting improves realism; static object; reflective/refractive materials may need more views or diffusion variant.
- Real estate and interior design walkthroughs from short video captures (Real Estate, AEC)
- What: Quickly produce interactive viewpoints of rooms from phone video; augmenting listings and client reviews.
- Tools/workflows: Mobile capture → server‑side encode → browser client for interactive view control; optional camera‑free mode for user‑friendly workflow.
- Assumptions/dependencies: Static scenes; moving people/objects can cause artifacts; 360° coverage improves results; 512×512 may be adequate for browsing but not for final marketing stills.
- Cultural heritage and museum digitization from crowd‑sourced photos (Cultural Heritage, Education)
- What: Generate novel viewpoints for artifacts or exhibits using internet photos with unknown cameras.
- Tools/workflows: Ingestion of unordered, unposed images; encode once; host an interactive kiosk or web viewer.
- Assumptions/dependencies: Varying focal lengths and lighting introduce appearance shifts; scenes must be mostly static.
- Sports broadcasting “free‑viewpoint” replays using sparse cameras (Media & Sports Tech)
- What: Provide alternative angles for replays when only a few cameras are available.
- Tools/workflows: Per‑play encode; live‑production control UI to place virtual cameras; low‑latency decoding.
- Assumptions/dependencies: Motion violates static‑scene assumption—use on short temporal windows or static segments; quality depends on overlap and occlusions.
- Robotics situational awareness via cross‑view rendering (Robotics, Defense, Public Safety)
- What: Render alternate viewpoints from front/side cameras for teleoperation and hazard inspection.
- Tools/workflows: On‑robot or edge server encode on arrival; teleop UI queries virtual camera poses in real time.
- Assumptions/dependencies: Static or quasi‑static environments; compute budget on‑board may limit resolution/fps; for large occlusions, consider diffusion variant or add more sensors.
- Rapid asset inspection and documentation (Energy, Infrastructure, Construction)
- What: Drone or handheld captures of equipment (e.g., turbines, substations) produce interactive viewpoints for inspection reports.
- Tools/workflows: Encode per asset; render viewpoints highlighting suspected areas; integrate into CMMS dashboards.
- Assumptions/dependencies: Static equipment; small numbers of images; surfaces with repeating patterns may challenge geometry inference.
- Education and training content with interactive views (Education, Publishing)
- What: Deliver lightweight, interactive “look‑around” experiences for lab apparatus, historical sites, or art pieces without full 3D modeling.
- Tools/workflows: LMS plugins that request novel views from a hosted service based on preset or user‑controlled cameras.
- Assumptions/dependencies: Static scenes; moderate resolution acceptable; content provenance and rights for training and deployment imagery.
- Developer tooling and APIs for NVS (Software)
- What: Provide a service/API (“Neural Viewport”) where clients upload images and query viewpoint renders.
- Tools/workflows: REST/gRPC endpoints; client SDKs (WebGL/WebGPU, Unity/Unreal); batch encoding with caching for fast subsequent queries.
- Assumptions/dependencies: Cloud GPUs; storage for per‑scene latent features; governance around image content and privacy.
- Academic benchmarking and analysis (Academia)
- What: Evaluate encoder‑decoder designs, 3D‑aware pre‑training, and dataset mixing strategies for NVS.
- Tools/workflows: Use released code/checkpoints to replicate ablations (highway vs bottleneck, cross vs full attention); establish new real‑time feed‑forward NVS baselines.
- Assumptions/dependencies: Access to mixed multi‑view datasets; compute for end‑to‑end fine‑tuning; proper metrics and model cards.
- Governance and policy pilots for view synthesis (Policy)
- What: Draft guidelines for disclosure and provenance when using NVS in media, advertising, or public communications.
- Tools/workflows: Require content labeling in outputs; incorporate model cards and dataset documentation in procurement; watermarking policies for generative variants.
- Assumptions/dependencies: Organizational adoption; alignment with regional regulations on synthetic media and privacy.
Long‑Term Applications
These require further research (e.g., diffusion integration, dynamic scenes, higher resolutions), scaling, or domain transfer.
- Generative free‑viewpoint video for unobserved content (Media, AR/VR)
- What: Fully hallucinate unseen regions realistically via diffusion‑augmented LagerNVS (as demonstrated in the paper prototype).
- Tools/workflows: Dual‑mode pipelines: deterministic for well‑constrained views; diffusion for extrapolation/occlusion; UI to sample multiple plausible outcomes.
- Assumptions/dependencies: Stable diffusion training for video consistency; controls for realism vs. faithfulness; content moderation safeguards.
- Mobile/on‑device AR “parallax from one photo” (Consumer, Mobile)
- What: Create subtle 3D parallax or small view changes from a single image in AR apps.
- Tools/workflows: Distilled or quantized models; encoder on server, low‑latency decoder on device; fallback to deterministic small baseline moves.
- Assumptions/dependencies: Aggressive model compression; hardware accelerators (NPUs); quality degrades on large motions.
- Dynamic scene NVS and live events (Media, Telepresence, Autonomy)
- What: Handle people/objects in motion to generate free‑viewpoint sequences in real time.
- Tools/workflows: Temporal encoders, motion‑aware features, or hybrid explicit‑latent approaches; streaming encodes per time window.
- Assumptions/dependencies: New training data and objectives; balancing latency with temporal coherence; higher compute budgets.
- High‑resolution, photoreal virtual production (Film/TV)
- What: Move beyond 512×512 to 2K/4K with real‑time decoding for LED volume or virtual scouting.
- Tools/workflows: Multi‑GPU inference, tiled rendering with seam correction; learned supersampling; custom kernels.
- Assumptions/dependencies: Engineering for memory/throughput; perceptual tuning for moiré/reflections; contractual requirements for scene faithfulness.
- Safety‑critical cross‑view prediction for robots and autonomous systems (Robotics, Transportation)
- What: Predict visibility around corners or from alternative vantage points for planning; use NVS as an auxiliary module for occlusion reasoning.
- Tools/workflows: Uncertainty estimates, ensemble or diffusion‑based hypothesis generation; tight integration with perception/planning stacks.
- Assumptions/dependencies: Certification constraints; explicit fail‑safes when ambiguity is high; dynamic scenes research.
- Medical and scientific imaging view synthesis (Healthcare, Research)
- What: Generate alternate views from limited scans (e.g., endoscopy, microscopy) to aid navigation or education.
- Tools/workflows: Domain‑specific pre‑training and strict validation; uncertainty reporting; use for teaching and planning rather than diagnosis initially.
- Assumptions/dependencies: Regulatory approval; appropriate datasets; robust handling of specularities and tissue motion.
- Infrastructure digital twins and city‑scale view services (Public Sector, Smart Cities)
- What: Rapid free‑viewpoint visualization of public spaces from sparse captures (drones, dashcams) for planning and citizen engagement.
- Tools/workflows: Scalable encoding for large areas; map‑aligned camera sampling; public web viewers with provenance tagging.
- Assumptions/dependencies: Privacy preservation (face/license plate obfuscation); legal frameworks for data capture/use; handling dynamic elements.
- Standardized benchmarks and audits for NVS faithfulness and bias (Policy, Academia)
- What: Establish evaluation protocols for view fidelity vs. hallucination, and dataset biases (e.g., indoor dominance).
- Tools/workflows: Curated test suites with known coverage/occlusion statistics; reporting standards and content credentials.
- Assumptions/dependencies: Cross‑industry collaboration; alignment with synthetic media regulations.
- Hybrid pipelines combining latent NVS with explicit 3D (Software, VFX, CAD)
- What: Use fast latent NVS for interactivity, then refine/validate with explicit 3D (e.g., Gaussians/NeRFs) offline for final shots or measurements.
- Tools/workflows: Switchable backend; automatic region‑of‑interest escalation to explicit recon when required.
- Assumptions/dependencies: Consistency across representations; scheduling and caching strategies.
- Training and foundation model research (Academia, AI Labs)
- What: Investigate encoders that preserve appearance (add rendering heads during pre‑training), scaling laws for highway architectures, and cross‑modal conditioning (language, semantics).
- Tools/workflows: Large, diverse dataset mixtures; systematic ablations; open benchmarks for with/without cameras and unordered inputs.
- Assumptions/dependencies: Compute and data access; reproducibility and licensing compliance.
Cross‑Cutting Dependencies and Assumptions
- Scene characteristics: Best for static or quasi‑static scenes; large occlusions/unknown regions need diffusion; reflective/translucent materials are harder.
- Inputs: Works with 1–9 source views; performance improves with overlap; known cameras help but are not required.
- Compute: Real‑time 30+ FPS at 512×512 tested on an H100; expect reduced throughput on consumer GPUs or higher resolutions.
- Quality controls: Deterministic models regress to the mean in ambiguous regions; diffusion adds realism but requires safeguards and may reduce faithfulness.
- Data and rights: Training and deployment must respect image licensing; policy frameworks should require provenance and disclosure for synthesized views.
- Integration: For engines (Unity/Unreal), provide Plücker ray map camera interface; cache per‑scene latent features to amortize encode cost.
- Safety and ethics: Label synthesized content; avoid deceptive use in news or legal evidence without disclosure; implement privacy protections when using in‑the‑wild images.
Glossary
- 3D Gaussians: An explicit 3D scene representation where scene properties are modeled by Gaussian primitives used for rendering. "Neural Radiance Fields~\cite{mildenhall20nerf:} and 3D Gaussians~\cite{kerbl233d-gaussian} fit (encode) explicit 3D scene representations"
- 3D inductive biases: Architectural or training choices that bias a model toward understanding 3D structure and geometry. "we argue that strong 3D inductive biases are still helpful in the design of such networks."
- 3DGS: Abbreviation for 3D Gaussian Splatting; a rendering paradigm using 3D Gaussian primitives. "Occlusion coverage is possible with feed-forward 3DGS~\cite{szymanowicz24splatter,szymanowicz25flash3d}"
- AdamW: An optimizer that decouples weight decay from gradient-based updates for improved training stability. "We use AdamW optimizer and cosine learning rate decay with linear warmup."
- adaLN-zero: A conditioning mechanism (Adaptive LayerNorm-Zero) for diffusion models enabling timestep conditioning with zero-initialized modulation. "and add adaLN-zero~\cite{peebles23scalable} conditioning on the denoising timestep."
- auto-decoding: Optimization-based fitting where latent codes are learned per-instance without an encoder network. "Early neural approaches like LFN~\cite{sitzmann21light} used auto-decoding to fit compact light field representations."
- bottleneck encoder-decoder: An architecture that compresses scene information to a fixed-size latent before decoding, limiting information flow. "We further distinguish `bottleneck' encoder-decoders, where the latent tokens are constrained to a fixed dimension before being decoded~\cite{jin25lvsm:}"
- cross attention: Attention mechanism where queries attend to separate key–value sets, often used to fuse different modalities or inputs. "followed by cross attention between these and the scene tokens"
- denoising diffusion: A generative modeling framework that iteratively removes noise to sample from learned data distributions. "fine-tune the decoder with a denoising diffusion objective."
- diffusion decoder: A view-rendering module trained as a diffusion model to hallucinate plausible content in ambiguous regions. "and can be paired with a diffusion decoder for generative extrapolation."
- encoder-decoder: A two-stage model where inputs are first encoded into a latent representation, which is then decoded into outputs. "In contrast, encoder-decoder architectures~\cite{sajjadi2022srt,jin25lvsm:,jiang25rayzer:} separate encoding from viewpoint-conditioned decoding."
- fields-of-view: Angular extents of the camera in horizontal and vertical directions characterizing intrinsics. " are the horizontal and vertical fields-of-view (the optical center is assumed to be at the image center)."
- FlashAttention: An optimized attention kernel that reduces memory and improves speed for transformer attention. "We use a ViT-B~\cite{dosovitskiy21an-image} transformer for our decoder with FlashAttention~\cite{dao2022flashattention,dao2023flashattention2,shah24flashattention-3:} attention kernels."
- full attention: Standard self-attention where all tokens attend to all others in the sequence. "The first variant has complexity and uses full attention on the concatenation of target camera and scene tokens"
- Gaussian splat renderer: A renderer that projects and blends 3D Gaussian primitives to form images. "and uses a Gaussian splat renderer for the decoder."
- Gaussian-ray alignment: A constraint aligning predicted Gaussians with camera rays, often yielding sharp but less occlusion-robust reconstructions. "AnySplat and Flare force Gaussian-ray alignment"
- gradient checkpointing: A memory-saving technique that recomputes activations during backpropagation. "as well as gradient checkpointing for reduced memory usage."
- highway encoder-decoder: An encoder-decoder design that preserves rich feature pathways (without tight bottlenecks) from encoder to decoder. "We further distinguish
bottleneck' encoder-decoders, andhighway' encoder-decoders, where the decoder can access all image features directly." - latent 3D representation: A feature-based scene encoding that captures 3D information without explicit geometry for direct view synthesis. "Other approaches extract a latent 3D representation of the scene that can be decoded directly into new views"
- LayerNorm: Layer normalization technique applied to stabilize and accelerate training. "and normalize with LayerNorm~\cite{ba16layer} to improve learning stability."
- light field: A function describing radiance along rays in space, enabling view synthesis without explicit geometry. "These representations can be viewed as an encoding of the scene's light field"
- LPIPS: Learned Perceptual Image Patch Similarity; a metric for perceptual similarity between images. "Perceptual Similarity (LPIPS~\cite{zhang18the-unreasonable})."
- MLP (Multi-Layer Perceptron): A feed-forward neural network with one or more hidden layers. "we modify it by adding a 2-layer Multi-Layer Perceptron (MLP) that projects the camera parameters"
- Neural Radiance Fields: A neural representation that models scene radiance and density to render novel views via volume rendering. "Neural Radiance Fields~\cite{mildenhall20nerf:}"
- Peak Signal-to-Noise Ratio (PSNR): A standard image quality metric based on logarithmic scale of signal-to-noise. "Peak Signal-to-Noise Ratio (PSNR)"
- perceptual loss: A training loss computed in deep feature space to align perceptual similarity. "and perceptual~\cite{johnson16perceptual} losses"
- photometric losses: Image-space reconstruction losses penalizing pixel-wise differences between rendered and ground-truth images. "and trained end-to-end with photometric losses."
- Plucker coordinates: A 6D representation of 3D lines/rays using direction and moment, enabling ray-based conditioning. "in Plucker coordinates, namely "
- Plucker ray map: A dense image where each pixel stores its camera ray in Plücker coordinates. "we represent it densely in the form of a Plucker ray map"
- QK-norm: Query-Key normalization in attention to stabilize training and improve convergence. "We use QK-norm~\cite{henry20query-key}, and gradient clipping for improved training stability"
- register tokens: Learned tokens appended to sequences that aggregate or carry global information through transformers. "Four additional register tokens~\cite{darcet24vision} are concatenated to these."
- SSIM: Structural Similarity Index; a metric assessing perceived image quality based on structural information. "Structural Image Similarity (SSIM~\cite{wang04bimage})"
- transformer: An attention-based neural network architecture effective for sequence-to-sequence modeling and image synthesis. "We design the decoder as a transformer network"
- unit quaternion: A normalized four-parameter representation of 3D rotation. "q \in \mathbb{S}3$, is the camera rotation (expressed as a unit quaternion)"
- ViT-B: Vision Transformer-Base model variant, specifying model size in the ViT family. "We use a ViT-B~\cite{dosovitskiy21an-image} transformer for our decoder"
- zero-shot generalization: Model ability to perform well on unseen domains/tasks without further training. "multi-view geometry models~\cite{wang2025vggt,mast3r,wang24dust3r:} have shown the benefits of training on large collections of data, particularly for zero-shot generalization."
Collections
Sign up for free to add this paper to one or more collections.