The Neuroscience of Transformers
Abstract: Neuroscience has long informed the development of artificial neural networks, but the success of modern architectures invites, in turn, the converse: can modern networks teach us lessons about brain function? Here, we examine the structure of the cortical column and propose that the transformer provides a natural computational analogy for multiple elements of cortical microcircuit organization. Rather than claiming a literal implementation of transformer equations in cortex, we develop a hypothetical mapping between transformer operations and laminar cortical features, using the analogy as an orienting framework for analysis and discussion. This mapping allows us to examine in greater depth how contextual selection, content routing, recurrent integration, and interlaminar transformations may be distributed across cortical circuitry. In doing so, we generate a broad set of predictions and experimentally testable hypotheses concerning laminar specialization, contextual modulation, dendritic integration, oscillatory coordination, and the effective connectivity of cortical columns. This proposal is intended as a structured hypothesis rather than a definitive account of cortical computation. Placing transformer operations and cortical architectonics into a common descriptive framework sharpens questions, reveals new functional correspondences, and opens a productive route for reciprocal exchange between systems neuroscience and modern AI. More broadly, this perspective suggests that comparing brains and architectures at the level of computational organization can yield genuine insight into both.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
The neuroscience of transformers — explained simply
What is this paper about?
This paper asks a big, exciting question: can the way modern AI models called “transformers” work help us understand how the brain works? The authors don’t claim the brain literally runs the same equations as a transformer. Instead, they suggest a clear analogy: a small unit of the brain called a cortical column (a tiny, layered “mini-processor”) may organize information in a way that’s similar to how transformers use attention to choose and combine information.
Their goal is to use this analogy to sharpen questions about the brain, propose testable ideas for experiments, and inspire a two-way exchange between neuroscience and AI.
1) Big-picture overview
Transformers are the AI engines behind systems like advanced chatbots and LLMs. They use a mechanism called “self‑attention” to decide, at each step, which pieces of information are most relevant to focus on.
The paper proposes that parts of the brain’s cortex might implement a similar idea: context-dependent information routing. In everyday terms, that means “who listens to whom, how strongly, and when,” depending on the situation. The authors map the main pieces of a transformer to the layers and connections inside a cortical column and show how this view can generate new, testable predictions about brain function.
2) Key questions and objectives
The paper sets out to answer, in simple terms:
- Could a cortical column act like a transformer block, using context to route information?
- If so, what brain parts correspond to the transformer’s main ingredients (like queries, keys, values, attention, and feed‑forward processing)?
- How might brain features—like different layers, dendritic “gates,” brain rhythms, and feedback signals—implement attention-like selection?
- What predictions does this make about which layers do what, how signals combine, and how different brain areas coordinate?
The overall objective is to provide a structured hypothesis that guides future experiments and connects AI ideas with real brain biology.
3) What approach did they use?
This is a conceptual, not experimental, paper. The authors build a careful mapping between a transformer’s parts and the brain’s wiring. They explain both sides in accessible terms:
- Transformers in everyday language:
- Think of a classroom where every student can “pay attention” to any other student’s notes.
- Each student asks a question (a “query”), everyone shares a short label describing what they have (a “key”), and the actual content they can offer (a “value”).
- If a student’s question matches someone’s label, they pay more attention to that person’s content. The “attention” scores decide who listens to whom and by how much.
- Transformers repeat this pattern in layers and often use several “heads,” like having multiple, parallel focus strategies at once.
- Brain side in everyday language:
- A cortical column is like a small neighborhood of neurons stacked in layers (upper, middle, deep), strongly connected inside and across the sheet of cortex.
- The middle layer (layer 4) often receives sensory input (like signals from the eyes via the thalamus) — think of this as the “incoming mail.”
- Upper layers (layers 2/3) and deep layers (layers 5/6) share lots of side-to-side and top-down connections — think of this as the neighborhood chatting with other neighborhoods and getting instructions from “downtown.”
- Neurons can “gate” inputs — like a volume knob — depending on the combination of signals they receive, especially on their different parts (dendrites). This is where multiplicative modulation (attention-like weighting) can happen.
- Brain rhythms (like gamma waves) can act like timing signals that open or close these gates together, helping groups sync up.
- The proposed mapping (analogy):
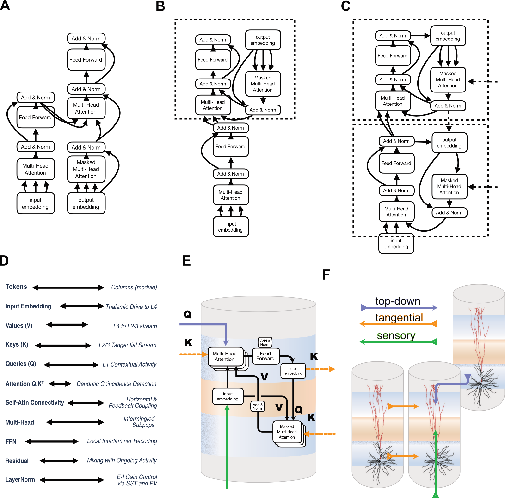
- Tokens (the things that interact in a transformer) ≈ cortical columns spread across the cortex.
- Values (the content you might want) ≈ signals traveling from the middle layer up to upper layers (layer 4 to layers 2/3).
- Keys (labels about what’s available) ≈ side-to-side signals in upper layers that share each column’s current state with neighbors.
- Queries (the current questions or goals) ≈ top-down signals arriving on the tops of neurons (into layer 1 and the tips of dendrites), carrying context like “what task am I doing?” or “what am I expecting?”
- Attention weights (who listens to whom, and how strongly) ≈ multiplicative gates set by how well queries and keys match, implemented by dendritic nonlinearities and gain control (the brain’s “volume knobs”), sometimes coordinated by rhythms.
- Multi-head attention (several focus strategies in parallel) ≈ different subgroups of neurons within a column, each sampling different contextual connections.
- Feed-forward network (recode-and-transform step in transformers) ≈ local reprocessing within the column’s layers that reshapes the representation before sending it on.
- Residual connections and normalization (stability and balance mechanisms in transformers) ≈ mixing old and new activity and using inhibitory circuits to keep activity levels in a useful range.
Important note: The authors don’t say the brain calculates the exact transformer equations. They say the brain may implement the same computational principle: context-dependent, multiplicative routing of information.
4) Main ideas and why they matter
Because this is a hypothesis paper, the “findings” are conceptual, not new experimental data. The main contributions are:
- A fresh mapping from transformer parts to cortical microcircuits:
- Middle layer input (values), upper layer lateral signals (keys), top-down context (queries), and dendritic gating (attention) fit together into a plausible brain version of self‑attention.
- Multiple neuron subgroups within one column can act like multiple “attention heads.”
- A realistic twist for early sensory areas:
- In early vision (like primary visual cortex), some attention patterns may be “hard-wired” by long-range horizontal connections and coordinated by brain rhythms. That’s like having a partly fixed attention plan (“attention-free” transformer variant) that’s fast and efficient for natural patterns (e.g., grouping edges into contours).
- Clear, testable predictions:
- Layer roles: different layers should show different “query‑key‑value” contributions (e.g., top-down context arriving in the very top layer; lateral keys in upper layers; feedforward values from middle layer).
- Dendritic and gain mechanisms: attention-like effects should depend on dendritic nonlinearities and inhibitory/excitatory balance.
- Rhythms and coordination: certain brain rhythms should gate or boost these interactions when grouping information across space or features.
- Effective connectivity: who influences whom — and when — should shift with task demands in a way that matches “attention” patterns.
- Multi-head behavior: nearby neurons that look similar for simple stimuli should diverge in more complex tasks as different “heads” lock onto different relationships.
Why this matters:
- For neuroscience: It provides a concrete blueprint linking powerful AI ideas to detailed brain circuitry, guiding new experiments (e.g., layer-specific recordings, rhythmic perturbations, dendritic measurements).
- For AI: It suggests biologically inspired design tweaks — like using local gating, oscillation-like timing, or more realistic feedback — that might improve robustness, efficiency, or adaptability.
5) What could this mean going forward?
If the brain really uses transformer-like computational organization, even in a loose, biological way, then:
- Neuroscientists get a unifying framework to interpret complex cortical interactions and to design experiments that specifically test attention-like routing across layers and areas.
- AI researchers get inspiration for new architectures that incorporate brain-style gating, rhythms, and feedback to handle context and long-range dependencies more naturally (and potentially more efficiently).
- Both fields benefit: better brain models to explain behavior and neural data, and smarter AI that borrows effective tricks from biology.
The authors emphasize that this is a structured hypothesis, not the final word. But putting transformers and cortical columns in the same “computational conversation” is a promising path to new insights in both brain science and artificial intelligence.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what the paper leaves unresolved or insufficiently specified.
- Lack of a quantitative, testable formalization of the mapping
- No explicit biophysical or rate-model instantiation that implements a transformer-like block with measurable inputs/outputs across laminae and columns.
- Absent benchmarks showing that a column-level circuit can approximate transformer computations on tasks.
- Unspecified temporal dynamics of a “forward pass”
- The proposal treats recurrent laminar loops as a quasi-static transform, but does not define the timescale (e.g., per gamma cycle, per theta cycle) or the dynamical mechanism that yields one effective “layer” update.
- No account of how masking, causal order, and sequence processing emerge from cortical dynamics over time.
- Biological implementation of and softmax-like normalization
- It is unclear whether dendritic coincidence and gain modulation can compute a bilinear similarity and produce a normalized weighting akin to softmax.
- No concrete mechanism for the exponential weighting or precise divisive normalization that would approximate softmax attention.
- Empirical identification of “queries,” “keys,” and “values” in cortex
- No operational definition of how to extract , , and signals from layer-specific activity in vivo (e.g., with laminar probes, calcium imaging, or intracellular recordings).
- Absent criteria and analysis pipelines to distinguish vs. vs. in recorded population activity.
- Multi-head attention as subpopulations: validation and separability
- No method to identify putative “heads” (distinct subpopulations) and test their relative independence, orthogonality, or specialization.
- No prediction for the number of heads per column, how heads share/compete for synapses, or how “head dropout” (selective silencing) affects behavior.
- Connectivity constraints vs. all-to-all self-attention
- The cortex has sparse, patchy long-range and dense local connections, not all-to-all graphs; feasibility of approximating global attention with realistic wiring and delays is not established.
- No mechanism for rapid, flexible reconfiguration of “who attends to whom” across distant columns within physiological latency limits.
- Positional encoding and sequence order
- The mapping does not specify how cortical circuits represent position in a sequence (positional encodings), particularly for non-topographic domains (e.g., language, abstract tasks).
- No account of how relative/absolute positional information is integrated into //.
- Cross-attention and decoder mapping
- The correspondence between transformer cross-attention (conditioning on another stream) and specific laminar/subcortical pathways is not concretely defined.
- The proposed “decoder-like autoregressive” role of L5 lacks behavioral/physiological evidence linking it to causal masking or next-step prediction.
- Early sensory “attention-free” variant vs. flexible attention in association cortex
- Criteria for when routing is “hard-wired” (fixed matrices) vs. dynamically computed are not specified, nor are measurable signatures differentiating these regimes.
- No developmental or task-dependent account of how circuits transition between these regimes.
- Oscillatory gating as attention
- The link between gamma-phase synchrony and attention-like multiplicative routing is hypothesized but lacks a quantitative model predicting laminar phase relationships, frequency bands, and causal perturbation effects (e.g., phase-specific stimulation tests).
- LayerNorm analogues via E–I balance: specificity and tests
- It is unclear whether inhibitory circuits implement normalization with the same functional properties as LayerNorm (e.g., per-token re-centering and rescaling).
- No falsifiable predictions (e.g., perturb interneuron classes and test scale/variance stabilization of columnar responses).
- Token definition and granularity
- Whether a “token” is a macrocolumn, minicolumn, or functional assembly is not resolved; criteria to map tokens to anatomical units across areas and species are missing.
- How the brain forms/adjusts token sets across tasks and modalities is not specified.
- Learning and credit assignment for //-like pathways
- Transformers use gradient-based credit assignment; the paper does not specify biologically plausible plasticity rules that would learn //-like transformations and “head” specializations.
- No role for apical dendrites, neuromodulators, or cortico-thalamic loops in biologically plausible credit assignment is concretized.
- Role of thalamus and thalamic reticular nucleus (TRN)
- The mapping treats thalamus as an input embedding but does not model thalamo-cortical/reticulo-thalamic gating as part of attention-like routing.
- No predictions on how thalamic perturbations alter attention weights or “head” engagement.
- Energy and latency constraints
- Feasibility of fast, multiplicative routing at scale under biological energy budgets and conduction delays is not evaluated.
- No trade-off analysis of accuracy vs. wiring cost vs. speed relative to transformer performance.
- Robustness and noise
- Transformers assume precise real-valued computations; the mapping does not analyze how stochastic spiking and synaptic noise impact attention-like weighting and downstream decoding accuracy.
- Area- and species-specific variability
- The mapping is cortex-centric and vision-leaning; its extension to auditory, somatosensory, multimodal association, and prefrontal areas is not specified.
- No analysis of how species differences in laminar architecture affect the proposed computations.
- Memory and FFN equivalence
- The proposal equates FFN with local “recoding,” but does not specify the expansion/compression ratios, latency, or the memory-like behavior (e.g., key-value storage) and where it resides biologically.
- Developmental and experience-dependent shaping
- Mechanisms by which horizontal/feedback connectivity learns the “attention matrix” from natural statistics are not modeled (e.g., plasticity timelines, rules, and critical periods).
- No predictions for how deprivation or altered statistics reshape //-like interactions.
- Disambiguation from alternative theories
- The proposal overlaps with predictive coding, canonical microcircuit, and mixed-selectivity frameworks; it lacks definitive experiments that would distinguish a transformer-like account from these alternatives.
- Experimental protocols and metrics are underspecified
- While the paper claims “broad predictions,” concrete, falsifiable experiments are not enumerated (e.g., perturb L1 apical input to test -like signals; silencing specific L2/3 tangential pathways to disrupt ; measuring changes in multiplicative gain and downstream routing).
- No quantitative metrics for “attention weight” recovery from neural data (e.g., inferring an effective attention matrix from simultaneous multi-column recordings).
- Global context and long-range integration
- How cortex integrates very distant tokens (columns) rapidly without exhaustive wiring is not addressed (e.g., via hub areas, polysynaptic pathways, or thalamo-cortical loops).
- No account of how global context scales with cortical distance and network state.
- Task generality and domain transfer
- The mapping’s ability to handle tasks where transformers excel (e.g., long-context language modeling, variable-length reasoning) is untested; required cortical analogues (e.g., working memory buffers, recurrence depth) are unspecified.
- Formal performance equivalence
- No theoretical results show that a biologically constrained laminar circuit can approximate a transformer block within bounded error on defined function classes, given realistic connectivity and dynamics.
- Representational diagnostics
- Methods to test whether cortical population codes exhibit attention-like compositionality (e.g., context-dependent mixing analogous to multi-head factorization) are not proposed.
- Soft vs. hard attention boundary conditions
- The paper proposes both “static” and “dynamic” gating but does not define measurable thresholds or task conditions that switch between them, nor circuit mechanisms controlling this switch (e.g., neuromodulators, PFC inputs).
- Causal masking and next-step prediction
- The neural mechanism implementing causal masking (preventing future information leakage) is not detailed; predictions for laminar timing differences or inhibitory gating that enforce causality are absent.
- Positively identifying residual pathways
- “Residual” is mapped to persistent activity/mixing, but no tests specify how to isolate residual-like contributions (e.g., transient vs. sustained components) in laminar recordings and perturbations.
Practical Applications
Immediate Applications
The paper proposes a transformer-to-cortex mapping as a structured hypothesis that clarifies how multiplicative, attention-like routing and laminar microcircuits might align. The following near-term applications leverage this framework without requiring radical new biology or hardware.
- Neuroscience experiment design toolkit for “Q–K–V” in cortex (academia, healthcare/neurotech)
- What: Turn the mapping into concrete, testable paradigms: laminar probe experiments to dissociate values (L4→L2/3), keys (tangential L2/3/5), and queries (L1 feedback); perturbation studies to test multiplicative gating via apical dendrites; oscillation-phase–locked routing tests.
- Tools/workflows: Protocol templates for laminar electrophysiology and two-photon imaging; optogenetic protocols targeting L1 vs L2/3; analysis code to compute attention-like “effective connectivity” matrices from spike-field/laminar signals; preregistered hypothesis libraries derived from Table 1–2 mappings.
- Assumptions/dependencies: Availability of laminar probes/optogenetics; reliable assignment of laminar signals to Q/K/V roles; gamma/theta coupling as a proxy for gating.
- Transformer-informed analysis of neural data (academia)
- What: Use self-attention metrics to model and visualize inter-column interactions, multi-head-like subpopulations, and oscillatory gating in existing datasets (V1/V2/V4 laminar MEAs, ECoG, laminar fMRI).
- Tools/workflows: RSA/CCA pipelines aligning “attention weights” with measured effective connectivity; model-based system identification where transformer blocks serve as priors on laminar coupling; open-source Python notebooks (PyTorch/JAX + MNE).
- Assumptions/dependencies: Sufficient SNR/resolution to estimate laminar-specific interactions; careful control of stimulus statistics to probe predicted “hardwired attention” in early cortex.
- Attention-free early vision blocks for edge models (software/AI, robotics/edge computing, energy)
- What: Replace dynamic self-attention in early stages with fixed, anatomically inspired lateral connectivity (structured, patchy adjacency) plus gain control—matching the paper’s “attention-free transformer variant” for predictable sensory statistics.
- Tools/products: Vision models with static lateral kernels + phase/gain gates (e.g., ConvNets with lateral message passing; ViT variants with fixed sparse attention masks); deployment on mobile/embedded SoCs to cut latency and energy.
- Assumptions/dependencies: Task domains with strong spatial regularities (e.g., industrial inspection, autonomous navigation in structured environments); careful tuning of normalization/gating to prevent brittleness.
- Multiplicative gating and normalization motifs as standard layers (software/AI)
- What: Incorporate biologically inspired gain modulation, dendritic-like multiplicative gating, and E–I normalization into transformer blocks to improve stability, controllability, and robustness without heavy retraining.
- Tools/products: “ColumnarAttentionLayer” libraries (PyTorch/JAX) with explicit lateral masks, multi-timescale residuals, and inhibitory normalization; drop-in modules for ViT/LLM fine-tuning.
- Assumptions/dependencies: Compatibility with modern training stacks; empirical validation that added inductive biases don’t harm benchmark performance.
- Interdisciplinary teaching and communication (education, policy)
- What: Use the module-level cortical mapping to teach transformers and laminar cortex together, improving literacy in AI-for-neuroscience and neuroscience-for-AI courses; inform funding panels of concrete, testable bridges.
- Tools/products: Course packs with paired transformer/cortex schematics; interactive demos of Q–K–V vs. laminar flows; seminar series and white papers guiding neuro-AI funding calls.
- Assumptions/dependencies: Instructor adoption; sustained interest from agencies and centers.
- Clinical hypothesis generation for neuromodulation (healthcare/neurotech)
- What: Frame TMS/tES/DBS protocols around “query-like” top-down modulation (L1/apical targets) vs. “key/value-like” lateral/thalamo-cortical drives to test context-sensitive routing effects on perception/attention.
- Tools/workflows: Closed-form predictions for oscillation-phase–specific stimulation; outcome measures based on figure–ground segregation and attentional gain.
- Assumptions/dependencies: Coarse spatial specificity of noninvasive methods; ethical oversight; translation from animal laminar results to human cortex.
- Benchmarking “biologically plausible attention” (academia, software/AI)
- What: Curate benchmark tasks that differentiate dynamic attention from “attention-free” routing in predictable vs. unpredictable regimes; quantify trade-offs in data efficiency and energy use.
- Tools/products: Public datasets with controlled statistics (e.g., contour integration, collinearity); leaderboards comparing fixed vs. learned attention masks and multi-head diversity metrics.
- Assumptions/dependencies: Community buy-in; clear metrics for routing fidelity and robustness.
Long-Term Applications
These require further experimental validation of the mapping, new hardware or clinical capabilities, or significant algorithmic development.
- Neuromorphic transformer hardware with dendritic gating (hardware/semiconductors, energy, robotics)
- What: Architect chips that realize attention via dendrite-like compartmentalization, multiplicative gating, and oscillation-synchronized routing; support fixed lateral matrices in “early” stages and dynamic attention higher up.
- Tools/products: Next-gen Loihi/SpiNNaker-class devices; compiler flows from transformer graphs to multi-compartment spiking substrates; co-design with low-power sensors for embedded perception.
- Assumptions/dependencies: Mature device models for multiplicative synapses and oscillatory coordination; software stacks for training/inference on neuromorphic substrates; robust benchmarks showing energy/performance gains.
- Cortically modular foundation models (software/AI, cross-domain applications)
- What: Build large models that explicitly separate column-like modules with laminar roles, multi-scale attention (within/between modules), and strong top-down feedback; target data efficiency, robustness, and interpretability.
- Tools/products: Hierarchically stackable “cortical modules” with explicit lateral graphs; training curricula that mirror cortical development (from “hardwired” early routing to flexible higher-level attention); evaluation on compositional generalization and continual learning.
- Assumptions/dependencies: Evidence that these constraints improve or match SOTA at lower compute; scalable optimization for recurrent/feedback-rich architectures.
- Brain–AI co-simulation platforms (academia, software tools)
- What: Unified simulators that map transformer blocks to biophysical column models, enabling in silico experiments where perturbations in one domain predict effects in the other.
- Tools/products: Hybrid simulators coupling PyTorch/JAX to NEURON/BRIAN; “compile-to-cortex” toolchains that translate transformer layers into laminar circuit motifs for hypothesis testing.
- Assumptions/dependencies: Efficient surrogates for biophysical dynamics; standardized data formats for laminar recordings and model states.
- Precision neuromodulation of “query” pathways for cognition (healthcare/neurotech)
- What: Therapies that target apical dendrite–dominated top-down pathways to correct context-routing deficits (e.g., attention disorders, schizophrenia); closed-loop stimulation synchronized to oscillatory gates.
- Tools/products: High-resolution cortical stimulation (intracortical arrays, ultrasound neuromodulation); real-time decoding of routing states; individualized stimulation schedules.
- Assumptions/dependencies: Strong causal evidence linking apical gating to cognitive symptoms; safe, precise human-accessible targeting of lamina-specific pathways; regulatory approvals.
- Sensorimotor stacks for embodied agents with cortical-style routing (robotics, autonomous systems)
- What: Perception–planning–control stacks where early sensory modules use fixed lateral routing and higher association modules use dynamic attention with feedback, improving rapid feedforward estimates plus iterative refinement.
- Tools/products: Real-time controllers with two-timescale processing (fast feedforward estimate, slower recurrent integration); robustness to occlusion and clutter via grouping-like lateral links.
- Assumptions/dependencies: Seamless integration of recurrent feedback with safety-critical control; convincing gains over existing transformer-based policies.
- Standards and governance for neuro-grounded AI (policy, standards)
- What: Guidelines for when biological plausibility should inform safety claims, interpretability, and energy targets; shared benchmarks for “effective connectivity interpretability” in large models.
- Tools/products: Policy frameworks tying funding and evaluation to neuro-AI integration goals; standard reporting of routing graphs and gain-control diagnostics in foundation models.
- Assumptions/dependencies: Community consensus on the value of neuro-grounding; measurable links between neuro-inspired design and societal outcomes.
- Data-efficient education and assistive tech via cortical inductive biases (education, accessibility)
- What: Learning systems for low-resource settings that leverage fixed early routing and strong top-down priors to reduce sample complexity; assistive perception apps that remain robust on-device.
- Tools/products: Lightweight vision/LLMs for classrooms and accessibility tools running offline; curriculum learning aligned to cortical module maturation.
- Assumptions/dependencies: Demonstrated sample and energy efficiency advantages; usable developer tooling for constrained hardware.
- Cross-species comparative modeling of cognition (academia, healthcare)
- What: Use the shared transformer–cortex framework to interpret species differences in laminar/lateral wiring as differences in attention capacity and context routing, informing translational models of cognition and disease.
- Tools/products: Comparative datasets (mouse/ferret/primate) analyzed with transformer-based effective connectivity; disease models framed as routing/gating failures.
- Assumptions/dependencies: High-quality cross-species laminar data; alignment methods that generalize across anatomies.
Notes on feasibility across applications:
- Core dependency: empirical support that cortical circuits realize attention-like multiplicative routing as mapped (Q/K/V, multi-head diversity, oscillatory gating).
- Transfer assumption: biologically inspired constraints will yield advantages in robustness, energy, or data efficiency for engineered systems.
- Hardware constrains pace: neuromorphic embodiments and lamina-specific clinical interventions are multi-year endeavors requiring co-design across disciplines.
Glossary
- Apical dendrites: The upper branches of pyramidal neurons that receive distal inputs, often integrating top-down signals and modulating somatic output. "The apical dendrites of lamina 5 pyramidal neurons deserve special mention."
- Attractor states: Stable patterns of neural activity toward which a recurrent network tends, often used to model memory and decision dynamics. "attractor states, probabilistic population codes, and canonical microcircuits,"
- Attention-free transformer: A variant where routing is structurally hardwired rather than computed via dynamic dot-product attention. "These regions likely employ an 'attention-free' transformer variant,"
- Autoregressive (component/input): A process that conditions current predictions on previous outputs, often implemented with masked attention. "deep layers (L5/6) correspond to the decoder-like autoregressive component,"
- Basal/perisomatic input: Synaptic inputs near the cell body and basal dendrites, influencing neuron spike generation. "basal/perisomatic input."
- Canonical microcircuit: A stereotyped arrangement of cortical layers and connections thought to implement common computations across cortex. "attractor states, probabilistic population codes, and canonical microcircuits,"
- Classical receptive field: The spatial region of a stimulus that directly drives a neuron’s firing under simple conditions. "manifesting as similar classical receptive fields"
- Cortical column: A vertical, locally interconnected module in cortex spanning layers, hypothesized to be a functional unit. "we treat a cortical column and its laminar microcircuit as a functional module,"
- Cortical laminae: The layered (laminar) structure of neocortex, with distinct inputs, outputs, and cell types across six layers. "the common analogy between âlayersâ in deep networks and cortical laminae, the 6-layered structure of the neocortex, is limited"
- Cross-attention: An attention mechanism where one sequence attends to another (e.g., decoder attending to encoder outputs). "The decoder is conditioned on encoder output via cross-attention."
- Credit assignment: The problem of determining how to assign responsibility for outcomes to specific neural elements during learning. "attention and credit assignment."
- Dendritic integration: The nonlinear processing and summation of synaptic inputs along dendrites. "exhibit complex dendritic integration"
- Dendritic nonlinearities: Nonlinear response properties of dendrites (e.g., spikes, plateau potentials) that enable multiplicative or gated computations. "local gain modulation and dendritic nonlinearities act as gates that weight these inputs multiplicatively,"
- Direct fit: The idea that deep learning systems fit complex functions directly to large amounts of naturalistic data without explicit structure. "modern deep learning can be understood as a form of âdirect fitâ to natural data"
- Effective connectivity: The influence one neural element exerts over another, considering direction and context (beyond mere anatomical connections). "the effective connectivity of cortical columns."
- E--I gain control (excitatory–inhibitory gain control): Regulation of neural response amplitude via balanced excitation and inhibition. "LayerNorm corresponds to E--I gain control mediated by inhibitory interneuron circuitry."
- Extra-classical receptive field: Contextual modulations of a neuron’s response from stimuli outside its classical receptive field. "classical and extra-classical receptive field structure in V1"
- Feed-forward recoding: Local processing that remaps representations via nonlinear expansion and compression, akin to transformer FFNs. "âfeed-forward recodingâ"
- Figure--ground segregation: The visual process of distinguishing objects (figure) from background (ground). "figure--ground segregation in V1"
- Foundation models: Large, general-purpose models trained on broad data and adaptable to many downstream tasks. "âfoundation modelsâ"
- Gain modulation: Multiplicative scaling of neuronal responses by contextual signals, implementing gating or attention-like effects. "gain modulation + dendritic nonlinearities as multiplicative gates"
- Gamma-band oscillations: Neural rhythms around 30–80 Hz associated with attention, binding, and routing of information. "gamma-band oscillations induce phase-locked synchronization"
- Gestalt principles: Perceptual organization rules (e.g., collinearity, continuation) guiding grouping in vision. "Gestalt principles such as collinearity and contour continuation"
- Horizontal collaterals: Lateral axonal branches of cortical neurons connecting neighboring columns within the same layer. "tangential L2/3 interactions mediated by horizontal collaterals of supragranular pyramidal neurons."
- Infragranular laminae: Deep cortical layers (L5/6) involved in outputs to subcortical targets and feedback within cortex. "influences the infragranular laminae,"
- Inhibitory interneuron circuitry: Networks of inhibitory neurons that sculpt and stabilize cortical activity and gain. "inhibitory interneuron circuitry."
- Keys (K): In attention, vectors representing content addresses used to match queries for selecting values. "Keys (K) correspond to tangential L2/3 interactions mediated by horizontal collaterals of supragranular pyramidal neurons."
- Layer normalization (LayerNorm): A normalization technique stabilizing activations by normalizing across features within a layer. "LayerNorm corresponds to E--I gain control mediated by inhibitory interneuron circuitry."
- Lateral geniculate nucleus (LGN): A thalamic relay nucleus providing visual input to primary visual cortex. "the projection from the lateral geniculate nucleus (LGN) of the thalamus"
- Masked Multi-Head Attention: Attention mechanism that prevents attending to future positions, enabling autoregressive generation. "Masked Multi-Head Attention"
- Mixed selectivity: Neurons encoding nonlinear combinations of multiple task variables, supporting flexible computation. "mixed selectivity"
- Multi-Head Attention (MHA): Parallel attention mechanisms operating over the same inputs to capture diverse relationships. "The architectural hallmark of modern transformersâMulti-Head Attention (MHA)âfinds a robust biological analogue"
- Neuromodulation: Regulation of neural circuit function by neurotransmitters and neuromodulators affecting excitability and plasticity. "diverse neurotransmitter systems and neuromodulation"
- Non-classical receptive field: Context-driven influences on a neuron’s response not accounted for by its classical receptive field. "they diverge sharply in their non-classical receptive fields,"
- Patchifier: A component that splits inputs (e.g., images) into patches treated as tokens for transformer processing. "Tokens are discrete symbols/patches chosen by a tokenizer/patchifier"
- Patchy connectivity: Non-uniform, clustered lateral connections linking columns with similar features. "according to the structured patchy connectivity of cortex,"
- Predictive coding: A framework positing hierarchical prediction and error signaling, often mapped to cortical layers. "predictive-coding-inspired accounts of laminar message passing"
- Probabilistic population codes: Representations in which populations of neurons encode probability distributions over variables. "attractor states, probabilistic population codes, and canonical microcircuits,"
- Queries (Q): In attention, vectors expressing what information to retrieve, matched against keys to weight values. "Queries (Q) correspond to contextual feedback terminating in L1 on distal apical tufts of L2/3 and L5 pyramidal neurons."
- Residual pathway: Skip connections that add inputs to outputs of layers to ease optimization and preserve information. "Residual corresponds to persistent recurrent activity maintaining an ongoing representational state."
- Retinotopic map: Spatial mapping of the visual field onto the cortical surface, preserving neighborhood relations. "retinotopic or somatotopic maps."
- Self-attention: Mechanism where elements of a sequence attend to each other to compute context-aware representations. "The transformer replaces the recurrent and convolutional backbones that dominated earlier sequence models with a self-attention mechanism"
- Softmax attention: Attention weights computed via a softmax over similarity scores (e.g., dot products of Q and K). "Exact Q,K,V matrices + softmax attention"
- Somatotopic map: Spatial mapping of body surface onto cortical areas, preserving anatomical layout. "retinotopic or somatotopic maps."
- Supragranular laminae: Upper cortical layers (L2/3) involved in intracortical communication and feedforward outputs. "The supragranular laminae implement the next step, a multi-head attention block."
- Supralinear calcium events: Nonlinear calcium signals in dendrites that can amplify coincident inputs. "supralinear calcium events driven by coincident apical and basal/perisomatic input."
- Tangential connectivity: Lateral (horizontal) connections within cortical layers linking neighboring columns. "Tangential L2/3 interactions mediated by horizontal collaterals of supragranular pyramidal neurons."
- Thalamic drive: Inputs from the thalamus that provide sensory signals to cortex. "this thalamic drive constitutes only a small fraction of all synapses"
- Top-down projections: Feedback signals from higher to lower cortical areas conveying context, goals, or predictions. "receives top-down projections from higher-order areas,"
- Topographic map: Ordered mapping of sensory dimensions across cortical space. "columnar structure laid out over a topographic map"
- Values (V): In attention, vectors containing the information to be routed once weighted by attention scores. "Values (V) correspond to the canonical L4L2/3 feedforward pathway."
Collections
Sign up for free to add this paper to one or more collections.