Detect Anything in Real Time: From Single-Prompt Segmentation to Multi-Class Detection
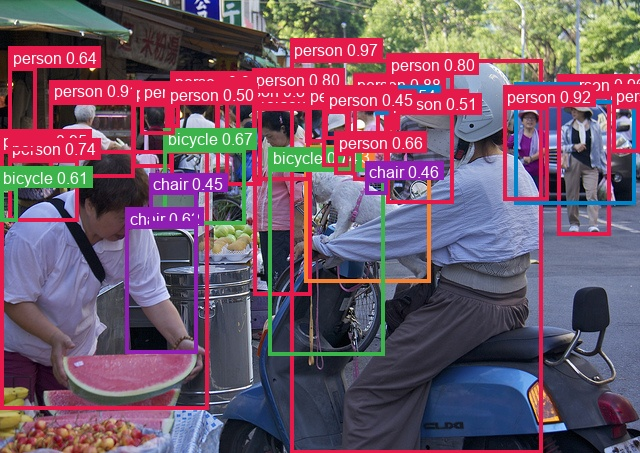
Abstract: Recent advances in vision-language modeling have produced promptable detection and segmentation systems that accept arbitrary natural language queries at inference time. Among these, SAM3 achieves state-of-the-art accuracy by combining a ViT-H/14 backbone with cross-modal transformer decoding and learned object queries. However, SAM3 processes a single text prompt per forward pass. Detecting N categories requires N independent executions, each dominated by the 439M-parameter backbone. We present Detect Anything in Real Time (DART), a training-free framework that converts SAM3 into a real-time multi-class detector by exploiting a structural invariant: the visual backbone is class-agnostic, producing image features independent of the text prompt. This allows the backbone computation to be shared between all classes, reducing its cost from O(N) to O(1). Combined with batched multi-class decoding, detection-only inference, and TensorRT FP16 deployment, these optimizations yield 5.6x cumulative speedup at 3 classes, scaling to 25x at 80 classes, without modifying any model weight. On COCO val2017 (5,000 images, 80 classes), DART achieves 55.8 AP at 15.8 FPS (4 classes, 1008x1008) on a single RTX 4080, surpassing purpose-built open-vocabulary detectors trained on millions of box annotations. For extreme latency targets, adapter distillation with a frozen encoder-decoder achieves 38.7 AP with a 13.9 ms backbone. Code and models are available at https://github.com/mkturkcan/DART.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces DART, which stands for “Detect Anything in Real Time.” It’s a way to make a powerful computer vision model (called SAM3) much faster at finding many kinds of objects in images and videos—without retraining it. The key idea is simple: instead of running the heavy image-processing part over and over for each object type (like “person,” “car,” “dog”), DART runs that part once, then reuses the result to check for all the classes at the same time.
Key questions the researchers asked
- How can we make a “promptable” model (one that takes text like “find all the cats”) detect many object types at once quickly?
- Can we do this without retraining the model (which would require lots of data and compute)?
- What smart engineering changes can give big speedups while keeping accuracy high?
How they did it (in plain language)
Think of the model like a two-stage process:
- A big “image scanner” that turns the picture into a rich set of visual features (like a map of what’s where).
- A “question answerer” that uses those features plus a text prompt (like “cat,” “car,” or “person”) to find and score boxes around matching objects.
Here’s the trick: the image scanner doesn’t care what you’re looking for—it processes the image the same way no matter the class. That means:
- You only need to run the scanner once per image, not once per class. It’s like scanning a page one time, then asking many questions about it.
- You can “batch” the questions (class names) together and handle them in one go instead of one by one.
To make this fast on real hardware, they also:
- Removed extra steps they didn’t need for detection-only tasks (like detailed pixel masks).
- Deployed the model with TensorRT in “FP16” (half-precision) to speed things up, but carefully “rewired” the attention parts so the hardware uses the correct fast-and-accurate kernels. (Analogy: they rearranged the recipe steps so the kitchen’s specialized tools kick in.)
- Split the system into two engines—one for the scanner and one for the question answerer—so they can run in a pipeline on video. While the “question answerer” finishes frame t, the “scanner” can already start frame t+1. (Think of an assembly line where one station starts the next item while the other finishes the current one.)
- Explored pruning (removing small parts of the scanner that don’t change results much) and an optional “adapter distillation” trick. Adapter distillation is like teaching a smaller, faster scanner to produce features similar to the big scanner, by training a tiny adapter that translates its outputs to what the rest of the system expects—without changing the rest of the model.
Main results and why they matter
Here are the standout results, explained simply:
- Big speedups without retraining:
- Sharing the image scanner across classes and batching the text prompts makes multi-class detection much faster.
- At 3 classes, the speed increases about 5.6×; at 80 classes, about 25×—all without changing the model’s learned weights.
- Real-time performance with high accuracy:
- On a standard test set (COCO), DART reaches about 55.8 AP (a common accuracy score) at around 15.8 frames per second for 4 classes at high image resolution—on a single consumer GPU (RTX 4080).
- That accuracy even beats some systems that were trained specifically for open-vocabulary detection using lots of labeled data.
- Careful engineering makes FP16 both fast and correct:
- By restructuring the “attention” math, they ensure the hardware uses safe, fused operations. This keeps the results accurate while getting the speed benefits of half-precision numbers.
- Adapter distillation for extreme speed:
- If you need even lower delay, you can swap in a smaller scanner and train only a tiny adapter. Keeping the rest of the system frozen, they achieve about 38.7 AP with a very fast 13.9 ms scanner—much better than trying to retrain the whole pipeline end-to-end on limited data, which performed poorly.
- Trade-offs:
- Lowering image resolution boosts speed but hurts small-object detection most. So, it’s a balance: faster vs. catching tiny things.
Why this matters: You can get flexible, “open-vocabulary” detection (type any class name you want) running fast enough for real-time uses—like robots, assistive tools, or monitoring—without expensive retraining.
What this could mean going forward
- Easier deployment: Because DART doesn’t require retraining, teams can bring powerful, flexible detectors to real-world apps quickly, even on commodity hardware.
- Broad applicability: The same “share the scanner and batch the questions” idea should work for other similar models, not just SAM3.
- Responsible use: Faster, more flexible detection can help good causes (safety, accessibility, environmental monitoring), but it can also be misused for surveillance. The authors encourage careful consideration of privacy and consent.
In short, DART shows that with smart reuse (scan once, ask many times), careful batching, and hardware-aware tweaks, you can turn a slow “one-class-at-a-time” system into a fast, many-class detector—keeping strong accuracy and avoiding retraining.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved and could guide follow-up research.
- Generalization beyond SAM3: The approach is argued to apply to other promptable V+L architectures (e.g., SAM2, Grounding DINO), but there is no empirical validation, implementation guidance, or accuracy/latency results for these models.
- Open-world robustness: Evaluation is limited to COCO val2017; there is no assessment on long-tail or open-world benchmarks (e.g., LVIS, ODinW, Objects365, ODinW domain shifts), nor on out-of-distribution images or domains (e.g., aerial, medical, non-photographic).
- Prompt sensitivity and language coverage: Robustness to natural-language variability (synonyms, multi-word phrases, attributes, negation, ambiguous/overlapping labels), multilingual prompts, and adversarial or noisy prompts is untested.
- Cross-class interference: The impact of large, overlapping vocabularies (e.g., “person” vs “man/woman,” “car” vs “vehicle”) on false positives/negatives, score calibration, and per-class NMS is not analyzed.
- Class scaling limits: The maximum batchable prompt count Nmax for the encoder-decoder is not specified or characterized (memory footprint, latency growth, VRAM fragmentation), especially for hundreds/thousands of classes.
- 80-class throughput: While a >25× speedup is claimed at 80 classes, actual end-to-end FPS and memory usage for that setting (and how many encoder-decoder passes are required) are not reported.
- Score calibration at scale: The presence token gating is used without studying inter-class score calibration as N grows; methods for temperature scaling, class-dependent thresholds, or joint calibration are not explored.
- Detection vs. segmentation: The mask head is removed for speed, but strategies to retain multi-class segmentation (e.g., selective masks, shared mask decoding, sparse per-class mask refinement) with shared backbone are not investigated.
- Encoder-decoder bottleneck: Beyond ~16 classes the encoder-decoder dominates latency; concrete techniques to reduce its per-class cost (e.g., layer pruning, low-rank adapters, query pruning, grouped or hierarchical decoding) are proposed as future work but not attempted.
- Hierarchical or two-stage class selection: No mechanism is provided to shortlist candidate classes (e.g., CLIP image-text prefiltering or retrieval) before expensive encoder-decoder passes for very large vocabularies.
- Multi-scale or feature-pyramid enhancements: Small-object recall drops sharply at lower resolution; multi-scale inference, dynamic resolution, or true multi-level FPN/feature fusion to recover AP_S at real-time speeds is unexplored.
- Dynamic token sparsification: Methods like spatial token pruning, routing, or early-exit in the encoder-decoder to reduce cost while preserving accuracy are not evaluated.
- Sub-block pruning limitations: ViT sub-block pruning yields little latency gain because global-attention blocks are protected; alternative structured compression (e.g., low-rank factorization, kernel-level fusion, window size tuning, mixed sparsity) is not explored.
- Quantization beyond FP16: INT8/BF16/FP8 quantization (with calibration-aware attention kernels) and their accuracy–latency trade-offs are not studied, despite the focus on compiler-level deployment.
- Numerical portability: The FP16 graph restructuring is tightly coupled to TensorRT’s pattern matching; reproducibility across compilers/hardware backends (ONNX Runtime, TVM, DirectML, Metal, AMD GPUs) and across TRT versions is untested.
- RoPE modification impact: Switching from complex to real-valued RoPE is justified by feature cosine similarity, but its impact on downstream detection AP (especially for small/rare objects) is not quantified.
- Video-specific accuracy: Inter-frame pipelining improves latency, but temporal stability (jitter, missed detections on motion blur, identity consistency), potential temporal smoothing, or feature reuse across frames are not evaluated.
- Throughput under contention: Performance under GPU contention (multi-process, mixed workloads), PCIe bottlenecks, and varying batch/stream configurations is not characterized.
- Runtime memory profiling: Peak VRAM usage of split engines, FPN tensor sizes, and batched text embeddings for large class sets are not reported; memory–latency trade-offs to guide deployment on 8–12 GB GPUs remain unknown.
- Fair speed–quality comparison: AP-versus-FPS comparisons against purpose-built open-vocabulary detectors on the same hardware, resolution, and preprocessing are absent, limiting the strength of claims about surpassing prior work.
- Failure mode analysis: There is no qualitative/quantitative error analysis (confusions, localization errors, open-vocab hallucinations) across class sizes, resolutions, and vocab sizes to inform targeted improvements.
- Adapter distillation scope: Adapter training uses only COCO train2017 (unlabeled) with L2 feature matching; the effect of larger/diverse unlabeled corpora, richer objectives (e.g., decoder-logit KL, attention alignment, contrastive distillation), or better adapter designs is unexplored.
- Student backbone search: The trade-offs across a broader set of lightweight backbones, neural architecture search for adapter–backbone co-design, and Pareto-optimal choices under deployment constraints are not investigated.
- Presence token preservation: While full-pipeline distillation breaks the presence token, mechanisms to preserve or re-learn it in low-cost students (e.g., auxiliary presence-supervision, constrained distillation) are not tested.
- NMS design: The choice of per-class versus class-agnostic NMS in a batched open-vocabulary setting and its impact on inter-class suppression is not justified or ablated; learning-based NMS alternatives are not considered.
- End-to-end latency on CPUs/edge: Results target a single RTX 4080; performance on edge GPUs, mobile NPUs, or CPU-only environments (and corresponding compiler paths) is unreported.
- Incremental class updates: Although text embeddings are cached, strategies for streaming dynamic vocabularies (add/remove classes at runtime) without re-exporting TRT engines or incurring memory fragmentation are not detailed.
- Theoretical bound and modeling: The pipelining formula is presented without a full derivation or accounting for kernel launch, stream synchronization, and data transfer overheads; a formal model to predict throughput under varying N and resolutions could enable principled scheduler design.
Practical Applications
Overview
This paper introduces DART, a training-free framework that converts promptable single-prompt segmentation models (specifically SAM3) into a real-time, multi-class, open-vocabulary detector by exploiting a class-agnostic visual backbone, batched multi-class decoding, detection-only inference, TensorRT FP16 deployment with graph restructuring, split-engine design, and inter-frame pipelining. It also shows a complementary “adapter distillation” path for lightweight backbones with a frozen encoder–decoder. Below are concrete, real-world applications and workflows enabled by these findings.
Immediate Applications
These can be deployed now using the released code/models and standard NVIDIA GPU tooling.
Industry
- Real-time, open-vocabulary video analytics on existing camera fleets (smart cities, retail, logistics)
- Sector: Smart cities, retail loss prevention, warehouse operations, traffic management
- Workflow/product: DART-based VMS plugin that shares the backbone per frame, batches class prompts, caches text embeddings, and runs TRT FP16 split engines with pipelining. Operators can change class lists (e.g., “person, forklift, pallet, spill”) without retraining.
- Assumptions/dependencies: NVIDIA GPU with TensorRT; SAM3 weights; detection-only mode (no masks) for max speed; class counts within the encoder–decoder batch limit (Nmax); real-time tested on RTX 4080; small-object recall drops at lower resolutions.
- On-robot perception for selective, task-specific detection
- Sector: Robotics, autonomous mobile robots (AMRs), drones, manufacturing inspection
- Workflow/product: ROS2 node exposing a DART microservice; batched prompts enable per-task, on-the-fly vocabularies (e.g., “missing screw, bent bracket, loose cable”); inter-frame pipelining reduces latency for navigation cameras.
- Assumptions/dependencies: NVIDIA GPU (desktop or Jetson with TensorRT); latency budget shaped by resolution and class count; domain shift can affect open-vocab accuracy.
- Edge appliance for dynamic retail/industrial inventory monitoring
- Sector: Retail planogram compliance, industrial asset tracking
- Workflow/product: Appliance with split-engine TRT deployment; store associates can update vocabularies (e.g., “out-of-stock product tags”) via UI; cache text embeddings to avoid rebuilds.
- Assumptions/dependencies: GPU memory budget for high resolutions; sustained performance relies on detection-only mode and NMS tuning.
- Privacy-preserving selective redaction at the edge
- Sector: Compliance, security, transportation
- Workflow/product: Real-time detector to redact user-specified categories (“faces”, “license plates”, “badges”) by drawing boxes and blurring live video streams; leverage backbone sharing + batch prompts for multiple sensitive classes.
- Assumptions/dependencies: Correct prompt wording; open-vocabulary sensitivity; legal/policy frameworks for consent and retention.
- Fast-turnaround migration to smaller backbones via adapter distillation
- Sector: Embedded vision, cost-constrained deployments
- Workflow/product: Replace ViT-H with RepViT/TinyViT/EfficientViT plus a 5M-parameter FPN adapter trained in ~2 GPU-hours; retain frozen SAM3 encoder–decoder to keep detection quality substantially higher than end-to-end distillation baselines.
- Assumptions/dependencies: Accuracy/latency trade-off (e.g., RepViT-M2.3 ≈38.7 AP at ~14 ms backbone); domain-specific tuning may be needed; encoder–decoder becomes the bottleneck beyond ~8 classes.
Academia
- Benchmarking open-vocabulary detection without detection training
- Sector: Computer vision research
- Workflow/product: Use DART to study open-vocab detection transfer (55.8 AP on COCO with no detection training), compare to trained detectors; ablate class batching, resolution, and precision paths.
- Assumptions/dependencies: Availability of SAM3 checkpoint; adherence to COCO protocols.
- Methodological template for deployment-aware model design
- Sector: Efficient AI, systems for ML
- Workflow/product: Course labs and reproducible demos illustrating backbone sharing, batched cross-attention, TRT FP16 graph restructuring (real-valued RoPE, explicit attention), and split engines.
- Assumptions/dependencies: NVIDIA stack (ONNX, TensorRT); familiarity with MHA fusion constraints.
- Rapid dataset annotation acceleration
- Sector: Data labeling platforms
- Workflow/product: Integrate DART as an interactive pre-annotator for arbitrarily named classes; human-in-the-loop confirmation boosts throughput for bespoke categories.
- Assumptions/dependencies: Domain shift can reduce precision; detection-only boxes (masks can be re-enabled at added cost if needed).
Policy
- Risk assessment of low-cost, flexible surveillance
- Sector: Public policy, municipal procurement
- Workflow/product: Use DART to evaluate how open-vocabulary detection lowers deployment cost/complexity; inform procurement checklists and DPIA templates that mandate on-device redaction and consent mechanisms.
- Assumptions/dependencies: Requires multidisciplinary review (legal, ethics); open-vocab prompts expand potential target sets.
- Privacy-by-design enforcement pilots
- Sector: Transportation, public spaces
- Workflow/product: Pilot edge-only detection/redaction pipelines (no raw video storage) that exploit split-engine designs and prompt caching for dynamic policies (e.g., redact “faces” after-hours, “license plates” always).
- Assumptions/dependencies: Operational readiness of GPU edge nodes; governance of prompt lists; accuracy thresholds for policy compliance.
Daily Life
- Accessibility aids that detect user-named objects
- Sector: Assistive technology
- Workflow/product: Mobile/edge app that lets a user say “find my keys/wallet/mug” and runs DART on-device or on a nearby GPU; inter-frame pipelining supports smooth guidance.
- Assumptions/dependencies: Hardware constraints on mobile; likely needs smaller backbone via adapter distillation; safety-critical settings require validation.
- Hobbyist and maker projects (drones, home robots, AR)
- Sector: Consumer robotics, AR overlays
- Workflow/product: Open-source toolkit with a DART node for Jetson/NVIDIA GPUs; overlays bounding boxes for text-specified classes; supports quick vocabulary changes for demos.
- Assumptions/dependencies: Performance varies on embedded GPUs; class batching limited by memory; careful prompt engineering improves results.
Long-Term Applications
These require further research, scaling, engineering hardening, or non-NVIDIA support to be broadly feasible.
Industry
- Cross-vendor, cross-accelerator deployment (non-NVIDIA, CPU, mobile NPUs)
- Sector: Edge AI platforms, OEMs
- Workflow/product: Reproduce safe FP16/INT8 attention on alternative compilers (e.g., TVM, OpenVINO) and NPUs; extend graph restructuring patterns and fused-kernel guarantees beyond TensorRT.
- Assumptions/dependencies: Availability of accumulation-safe MHA kernels; ONNX/operator support for real-valued RoPE; vendor collaboration.
- Encoder–decoder optimization for large class vocabularies
- Sector: Large-scale retail/search, media analytics
- Workflow/product: Distill/prune the 6+6-layer encoder–decoder or design adaptive prompt schedulers to push beyond Nmax without linear latency growth; explore presence-gating aware batching.
- Assumptions/dependencies: Careful retention of presence token behavior; new training or calibration data may be required.
- Multi-camera, fleet-scale analytics with dynamic vocab orchestration
- Sector: Smart cities, enterprise security
- Workflow/product: Central controller that routes class vocabularies per camera scene; pipelines overlap across streams while sharing text caches; integrates tracking/ReID.
- Assumptions/dependencies: Scheduler sophistication; bandwidth/latency constraints; fairness and bias audits for open-vocab operation.
- Real-time inspection with multi-scale, small-object enhancements
- Sector: Manufacturing, agriculture, utilities (e.g., powerline/drone inspection)
- Workflow/product: Augment DART with multi-scale FPN or tiling to recover small-object recall at speed; domain-tuned adapter distillation for embedded payloads.
- Assumptions/dependencies: Architectural changes (multi-scale) or tiling strategies; additional training data or calibration.
Academia
- Generalization of the “class-agnostic backbone” optimization to broader VLMs
- Sector: Vision–language research
- Workflow/product: Apply the DART hierarchy to SAM2, Grounding DINO variants, or future promptable models; formalize invariants and provide standardized deployment recipes.
- Assumptions/dependencies: Backbone/text interaction must remain class-agnostic at the feature stage; graph patterns differ per model.
- Robustness and fairness studies for open-vocabulary detection
- Sector: Responsible AI
- Workflow/product: Benchmarks measuring prompt sensitivity, demographic bias, and domain shift across classes and languages; propose presence-gating safeguards.
- Assumptions/dependencies: Curated evaluation sets; multilingual text encoders.
- Compiler-aware model design patterns for ViTs
- Sector: Systems for ML
- Workflow/product: Design attention/positional encodings that are natively compiler-discoverable (no need for graph rewrites) and accumulation-safe; establish deployment-time correctness tests (cosine similarity thresholds).
- Assumptions/dependencies: Coordination with framework/ONNX standards bodies and kernel providers.
Policy
- Standards and certification for open-vocabulary detection systems
- Sector: Regulation, standards bodies
- Workflow/product: Certification schemes mandating on-device processing, prompt logging, redaction defaults, and human oversight for open-vocab deployments; publish latency/accuracy disclosures.
- Assumptions/dependencies: Consensus among regulators/industry; test suites that reflect real-world risk.
- Governance for dynamic prompt control and audit
- Sector: Enterprise compliance
- Workflow/product: Policy tooling that whitelists allowed prompts, version-controls vocabularies, and audits detections (with hash-based logs) to prevent misuse.
- Assumptions/dependencies: Secure key management; integration with VMS/IT systems.
Daily Life
- On-device AR glasses with natural-language object detection
- Sector: Consumer electronics
- Workflow/product: Low-power, privacy-preserving AR overlays that render boxes for user-spoken categories; leverage adapter-distilled backbones + optimized encoders on NPUs.
- Assumptions/dependencies: Efficient encoder–decoder designs for NPUs; low-latency ASR/NLP integration.
- Personalized, domain-adapted detection for the home
- Sector: Smart home
- Workflow/product: Quick adapter training using a handful of user images (no labels) to adapt features while keeping the encoder–decoder frozen; vocabularies like “my dog’s bowl” or “child’s backpack”.
- Assumptions/dependencies: Unsupervised/weakly supervised adapter objectives; guardrails to prevent overfitting and privacy leakage.
- Context-aware, energy-saving camera pipelines
- Sector: IoT/energy
- Workflow/product: Event-driven scheduling that reduces resolution or pauses decoding when presence gating is low; wakes up full pipeline on triggers; shares backbone across tasks.
- Assumptions/dependencies: Reliable presence signals; edge orchestrators; acceptable accuracy impact.
Notes on Feasibility and Dependencies
- Hardware/software stack: Current gains rely on NVIDIA GPUs, ONNX export, and TensorRT 10.x with FP16 fused-attention kernels. Correctness depends on graph restructuring (explicit attention, real-valued RoPE) to avoid FP16 accumulation errors.
- Model availability: Requires SAM3 weights for training-free deployment; adapter distillation needs only unlabeled images but benefits from domain-relevant data.
- Performance envelopes: Real-time performance varies with resolution and number of classes; encoder–decoder becomes the bottleneck as class count grows; small-object recall falls sharply at low resolutions.
- Functionality trade-offs: Detection-only mode removes the mask head for speed; if instance segmentation masks are needed, expect additional latency.
- Open-vocabulary caveats: Prompt phrasing, language, and domain shift affect precision/recall; presence gating must be preserved for reliable scoring; bias and privacy considerations are paramount, especially in public spaces.
Glossary
- Adapter distillation: A distillation approach that freezes the encoder-decoder and trains a small adapter to project student backbone features into the teacher’s feature space. "For extreme latency targets, adapter distillation with a frozen encoder-decoder achieves 38.7 AP with a 13.9\,ms backbone."
- Accumulation-safe fused kernels: Specialized fused attention kernels that internally accumulate in FP32 to maintain numerical stability in FP16 deployment. "only ensuring that every attention layer dispatches to accumulation-safe fused kernels restores correctness."
- Attention graph restructuring: Modifying the attention computation graph to match compiler patterns so fused, numerically safe kernels are used in deployment. "The ViT-H backbone, however, requires attention graph restructuring."
- Batched multi-class decoding: Processing multiple class prompts in a single forward pass by stacking them along the batch dimension in the decoder. "Combined with batched multi-class decoding, detection-only inference, and TensorRT FP16 deployment,"
- BlockPruner: A pruning method that removes transformer blocks using reconstruction loss as a criterion, originally for LLMs. "BlockPruner~\cite{zhong2024blockpruner} removes transformer blocks based on reconstruction loss, originally targeting LLMs."
- COCO val2017: A standard object detection benchmark split (5,000 images, 80 classes) used for evaluation. "On COCO val2017 (5{,}000 images, 80 classes), DART achieves 55.8 AP at 15.8\,FPS (4 classes, 10081008) on a single RTX~4080"
- Contrastive text encoder: A text encoder trained with contrastive objectives to map class names into token embeddings that align with image features. "a contrastive text encoder that maps class names to 256-dimensional token sequences"
- Cross-attention: An attention mechanism where queries attend to keys/values from another modality or source, used to fuse image and text features. "a 6-layer transformer encoder fuses image and text features via cross-attention over spatial tokens"
- Cross-modal attention: Attention that integrates information from different modalities (e.g., text and image) within a transformer. "fuses text and image features through cross-modal attention in a DETR-like architecture."
- Cross-modal transformer decoding: A decoding stage where text and image features interact via transformer layers to produce detections/segmentations. "combining a ViT-H/14 backbone with cross-modal transformer decoding and learned object queries."
- CUDA streams: Concurrent execution contexts on the GPU that enable overlapping computation (e.g., across pipeline stages). "The backbone and encoder-decoder run on separate CUDA streams"
- cuBLAS: NVIDIA’s GPU-accelerated BLAS library used by compilers/runtimes to execute matrix operations efficiently. "PyTorch~2.0 compilation~\cite{ansel2024pytorch2} provides an alternative via cuBLAS with FP32 accumulation."
- DETR-like architecture: A detection architecture inspired by DETR that uses transformer encoders/decoders and learned queries. "in a DETR-like architecture."
- Detection-only inference: An inference mode that outputs bounding boxes without computing segmentation masks to reduce latency. "Combined with batched multi-class decoding, detection-only inference, and TensorRT FP16 deployment,"
- Encoder-decoder: A transformer structure where an encoder processes inputs and a decoder uses learned queries with cross-attention to produce outputs. "a 6+6-layer transformer encoder-decoder with cross-modal attention"
- Feature Pyramid Network (FPN): A multi-scale feature representation method that combines features at different resolutions. "extracts three FPN feature levels"
- FPN adapter: A lightweight projection module that maps student backbone features to the teacher’s FPN feature space for compatibility. "training only a lightweight FPN adapter (38.7 AP) substantially outperforms full-pipeline distillation"
- FP16 (half precision): A 16-bit floating-point format used to accelerate inference but susceptible to accumulation errors in deep networks. "Deep residual vision transformers are vulnerable to FP16 accumulation error."
- Fused SDPA: Compiler/operator fusion of scaled dot-product attention into a single kernel for efficiency. "fused SDPA operators that decompose into non-canonical subgraphs."
- Global attention: Attention applied across the full spatial extent (as opposed to local/windowed), enabling cross-window information flow. "32 blocks with windowed/global attention"
- Greedy sub-block pruning (SBP): An iterative pruning method removing attention/MLP sub-blocks that minimally increase reconstruction loss. "Greedy sub-block pruning (SBP-)"
- Inter-frame pipelining: Overlapping different pipeline stages across consecutive video frames to reduce per-frame latency. "and inter-frame pipelining."
- Learned object queries: Learnable embeddings in the decoder that query the encoded features to produce object predictions. "and 200 learned object queries with per-query box regression and presence prediction heads."
- Mask prediction head: The segmentation component that predicts instance masks from decoder features; can be removed for detection-only runs. "the mask prediction head can be removed entirely."
- Multi-head attention (MHA): An attention mechanism with multiple parallel attention heads to capture diverse relationships. "Hardware inference compilers fuse multi-head attention (MHA) into kernels that internally accumulate in FP32"
- Non-maximum suppression (NMS): A post-processing step that removes redundant overlapping detections based on confidence. "and classes with low presence probability are filtered before NMS."
- ONNX: An open format for representing machine learning models that enables interoperability and deployment. "complex-valued RoPE (no ONNX equivalent)"
- Open-vocabulary detection: Detecting objects specified by arbitrary text categories at inference time, not limited to a fixed label set. "Open-vocabulary detection."
- Presence token: A learned token/head used to predict whether a class is present, aiding class scoring and filtering. "the decoder's learned presence token remains available for scoring class existence"
- Presence-gating: A mechanism that uses the presence prediction to gate detections, affecting final outputs. "EfficientSAM3 numbers are with presence-gating disabled."
- Prompt-in-the-loop: A training/inference paradigm where text prompts condition the model throughout the pipeline. "following the prompt-in-the-loop paradigm of EdgeSAM"
- Real-valued RoPE: A reformulation of rotary positional embeddings using real-valued cosine/sine buffers to enable deployment compatibility. "real-valued RoPE via precomputed / buffers"
- Rotary Positional Embedding (RoPE): A positional encoding technique that rotates query/key vectors to inject position information. "2D RoPE"
- Scaled dot-product attention (SDPA): The core attention operation computing scaled QKT, softmax, and multiplication by V. "fused SDPA operators that decompose into non-canonical subgraphs."
- Split-engine design: Deploying separate inference engines (e.g., backbone and encoder-decoder) that exchange intermediate tensors for flexibility. "Split-Engine Design for Open Vocabulary"
- TensorRT (TRT): NVIDIA’s high-performance deep learning inference optimizer and runtime. "TensorRT~\cite{tensorrt} accelerates neural networks through graph fusion and kernel autotuning."
- ViT-H/14: A large Vision Transformer variant (H-size, 14-pixel patch) used as the image backbone. "a 439M-parameter ViT-H/14 backbone"
- Windowed attention: Attention computed within local spatial windows to reduce computational cost. "32 blocks with windowed/global attention"
Collections
Sign up for free to add this paper to one or more collections.