- The paper introduces a hybrid pipeline that combines VFMs for robust point cloud estimation with a diffusion-based artifact fixer to enhance 3D reconstruction quality.
- It leverages random sample drop and weighted gradient techniques during 3DGS optimization to maintain both structural and textural integrity under sparse input conditions.
- Empirical results show significant improvements in PSNR and SSIM over baseline methods across multiple datasets, demonstrating the method’s robustness and practical impact.
Introduction and Motivation
The S2D framework addresses persistent limitations in explicit 3D reconstruction, particularly with 3D Gaussian Splatting (3DGS), which suffers severe degradation under sparse input conditions. Standard 3DGS pipelines require many images to avoid visual artifacts during view interpolation and extrapolation, which is impractical in many real-world scenarios due to the increased capture and computational burdens. Previous approaches, including feed-forward models and generative novel-view synthesis (NVS) strategies, have failed to yield artifact-free, photorealistic, and 3D-consistent results in the sparse input regime. S2D proposes a hybrid explicit-generative pipeline that leverages both visual geometry foundation models (VFMs) for robust 3D point cloud estimation, and a novel one-step diffusion-based artifact fixer, to achieve high-fidelity 3DGS reconstruction from minimal views.
S2D Pipeline: Architecture and Methodology
The S2D framework consists of two key components: (i) sparse-to-dense lifting via a diffusion-based artifact fixer, and (ii) a tailored 3DGS scene optimization strategy designed for sparse and dense hybrid supervision. Figure 1 details the high-level architecture and artifact fixer model design.
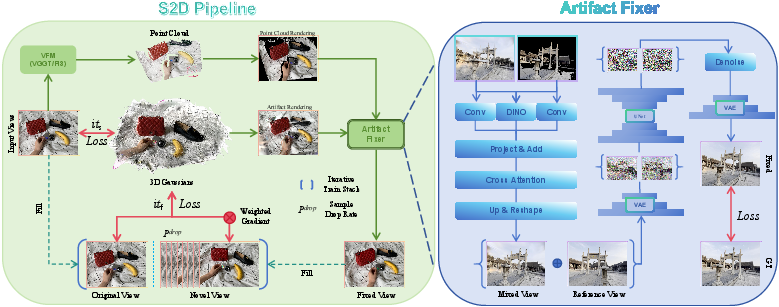
Figure 1: S2D reconstruction pipeline and model architecture of artifact fixer.
Point Cloud Estimation and Novel View Rendering
Given any number of input images and their associated camera poses, S2D employs a state-of-the-art visual geometry foundation model—such as π3 or MapAnything—to reconstruct a point cloud for the scene. These dense point clouds are naturally robust to sparse input, as they are view-independent and structurally consistent, despite their lack of photorealism due to aliasing and quantization errors.
One-Step Diffusion-Based Artifact Fixer
S2D introduces a one-step latent diffusion model as an artifact fixer, which processes synthesized novel views. The fixer is guided by both the point cloud rendering from the target viewpoint (structural guidance) and a nearby reference view image (textural guidance). The mixing module, as shown in the architecture, combines DINO features extracted from both guides, leveraging cross-attention to produce a mixed latent input for efficient and single-step denoising. The model further employs targeted loss terms, including DINO loss, SSIM, LPIPS, L2, and adversarial loss, to balance perceptual and structural fidelity.
Reconstruction Strategy: Random Sample Drop and Weighted Gradient
S2D augments the 3DGS optimization loop to avoid overfitting and inconsistency in regions unconstrained by input images. Novel views generated via artifact fixing, along with original inputs, are inserted into the supervision set. To prevent imbalance due to the disproportionate number of novel views, a stochastic sample drop scheme proportional to parameter α ensures robust optimization stability (Figure 2). Pixelwise gradient weighting, modulated by a confidence map derived from point cloud visibility, reduces adverse impact from regions susceptible to unresolved artifacts.
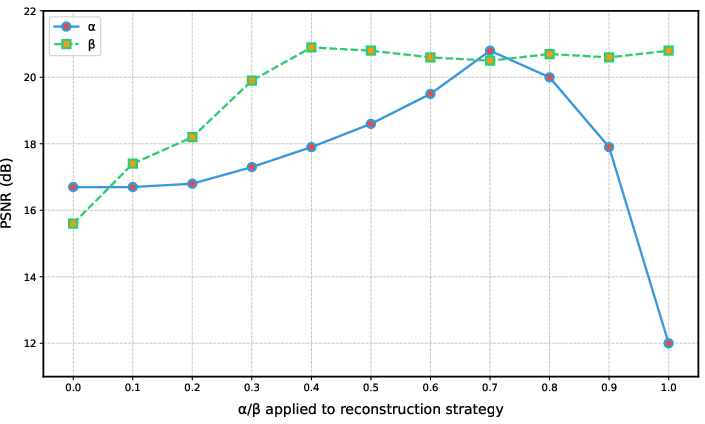
Figure 2: Evaluation on parameter α (references-to-novel sample ratio) and β (minimum weight for novel views) for stable optimization.
This reconstruction process produces a 3DGS scene with extended, artifact-free camera trajectories, from extremely sparse inputs.
Empirical Results
S2D’s performance is systematically evaluated across varied datasets (3DOVS, MIP360, DL3DV-960, RE10K, and Waymo), spanning a range of scene complexity and input sparsity.
Sparse Reconstruction Quality
In extremely sparse-view settings (as little as one or two images), S2D exhibits substantial gains in both photometric and perceptual metrics compared to baseline 3DGS and recent feed-forward or generative NVS methods. For instance, on 3DOVS with a single input image, S2D achieves a PSNR of 21.41 and SSIM of 0.77, compared to 10.12 and 0.30, respectively, for baseline 3DGS. The improvement is consistent across datasets and input densities (Figure 3, Figure 4).

Figure 3: Qualitative results in different situations—including in-the-wild and demanding sparse input scenarios—demonstrate the stability and photorealism of S2D reconstructions, even with severe input reduction.
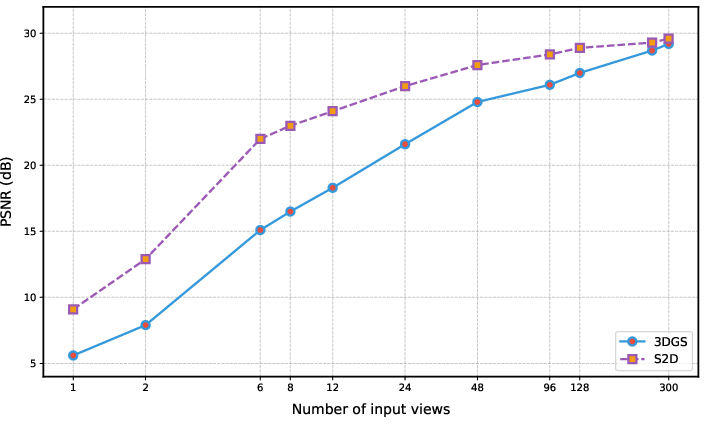
Figure 4: Reconstruction quality versus input density, showing S2D's consistent improvement relative to conventional 3DGS, particularly in the low-input regime.
Ablation and Robustness
S2D’s superior performance is attributed to the effectiveness of its dual-guidance fixing and hybrid supervision. Ablation studies validate that artifact removal is strongest when both point cloud and reference texture are integrated through the mixing module, and when optimization benefits from random sample drop with weighted gradients (Figures 4 and 5).

Figure 5: Ablation on artifact removal; dual-guidance mixing with DINO features yields maximal artifact suppression and structural restoration.

Figure 6: Ablations on reconstruction strategy—weighted gradient (WG) and random sample drop (RSD) are key to minimizing inconsistency and preserving high-frequency textures.
Artifact fixer training on synthetic corruptions at varied intensities, and diverse perturbations of 3DGS renderings, ensures resilience to real-world degradation (Figure 7).

Figure 7: Training data with different artifact intensities and perturbation strategies for improving artifact fixer's robustness.
Domain Applications
On driving datasets (Waymo, NuScenes), S2D not only outperforms methods such as DIFIX, StreetCrafter, and video diffusion-based SEVA in both structural quality and FID, but also displays strong scene-level consistency in view extrapolation over long trajectories (Figure 8).

Figure 8: DiffusionGS results and driving scene comparisons—S2D provides perceptually superior reconstructions in complex autonomous driving scenarios.
Failure Modes and Limitations
Where input images are both extremely sparse and lack discriminative texture, the underlying VFM may yield fragmentary point clouds, degrading guidance quality (Figure 9). However, the modularity of S2D allows for VFM swapping as advances occur.

Figure 9: Example of point cloud under extreme sparse, low-texture condition, illustrating guidance failure case.
Implications and Outlook
S2D demonstrates that explicit 3DGS representations can benefit substantially from generative priors, particularly via strong geometric and textural guidance provided by state-of-the-art diffusion models and visual geometry transformers. The methodology sets a new benchmark for minimal-input 3D reconstruction, lowering data requirements and increasing the practicality of explicit scene representations for simulation, robotics, and VLS systems. The proposed framework anticipates advances in geometric foundation models and denoising networks, being modular enough to integrate improved backbone architectures. Future work may address residual failure cases by integrating learned spatial priors for more robust point cloud estimation and extending cross-attention mechanisms for even stronger structure–texture disentanglement.
Conclusion
S2D establishes a new standard for minimal-input, high-fidelity 3DGS reconstruction by bridging foundation model-derived point clouds and diffusion-based artifact correction, underpinned by a robust hybrid supervision strategy. The approach is empirically validated to surpass prior SOTA in extreme sparse-view settings, generalizes across scene types, and maintains competitive inference efficiency. The practical implication is the substantial broadening of 3DGS use cases under minimal data constraints, with potential to impact autonomous systems, digital twins, and immersive environment construction (2603.10893).

