Are Video Reasoning Models Ready to Go Outside?
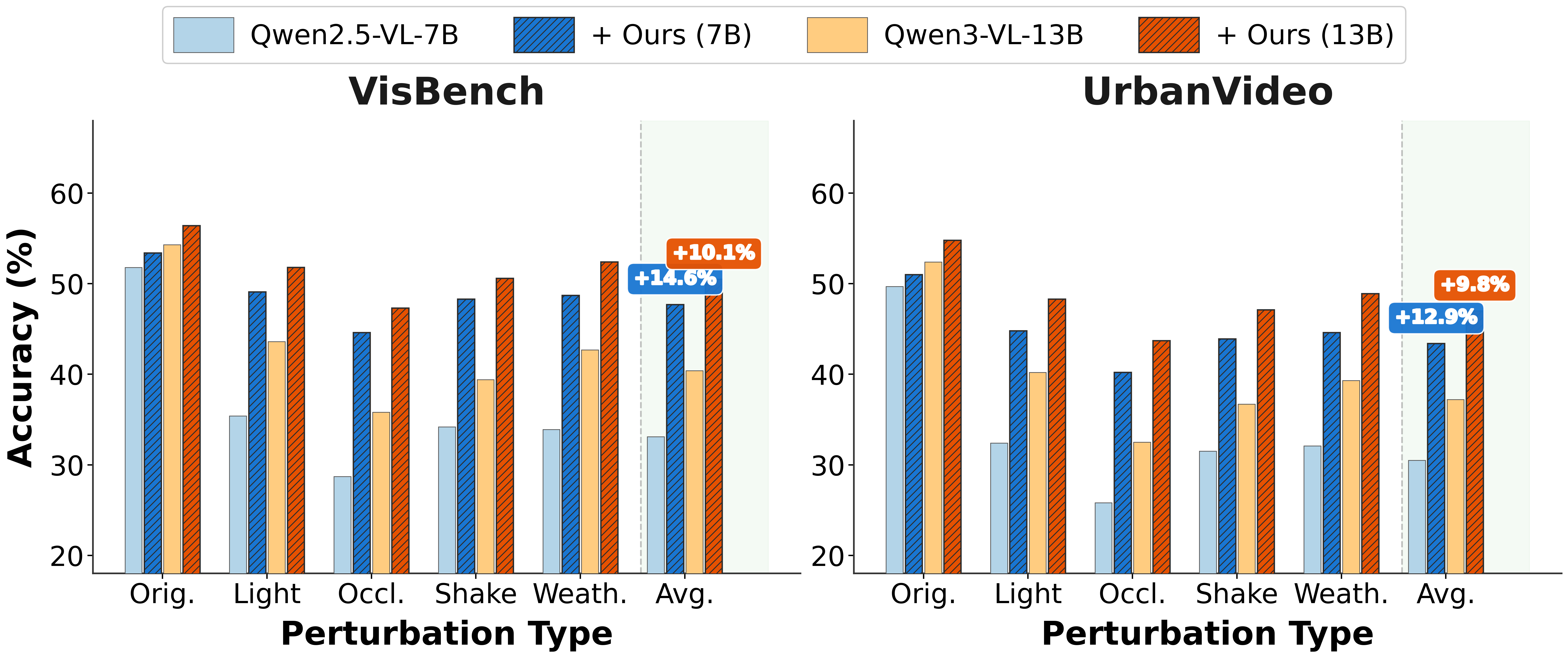
Abstract: In real-world deployment, vision-LLMs often encounter disturbances such as weather, occlusion, and camera motion. Under such conditions, their understanding and reasoning degrade substantially, revealing a gap between clean, controlled (i.e., unperturbed) evaluation settings and real-world robustness. To address this limitation, we propose ROVA, a novel training framework that improves robustness by modeling a robustness-aware consistency reward under spatio-temporal corruptions. ROVA introduces a difficulty-aware online training strategy that prioritizes informative samples based on the model's evolving capability. Specifically, it continuously re-estimates sample difficulty via self-reflective evaluation, enabling adaptive training with a robustness-aware consistency reward. We also introduce PVRBench, a new benchmark that injects real-world perturbations into embodied video datasets to assess both accuracy and reasoning quality under realistic disturbances. We evaluate ROVA and baselines on PVRBench, UrbanVideo, and VisBench, where open-source and proprietary models suffer up to 35% and 28% drops in accuracy and reasoning under realistic perturbations. ROVA effectively mitigates performance degradation, boosting relative accuracy by at least 24% and reasoning by over 9% compared with baseline models (QWen2.5/3-VL, InternVL2.5, Embodied-R). These gains transfer to clean standard benchmarks, yielding consistent improvements.
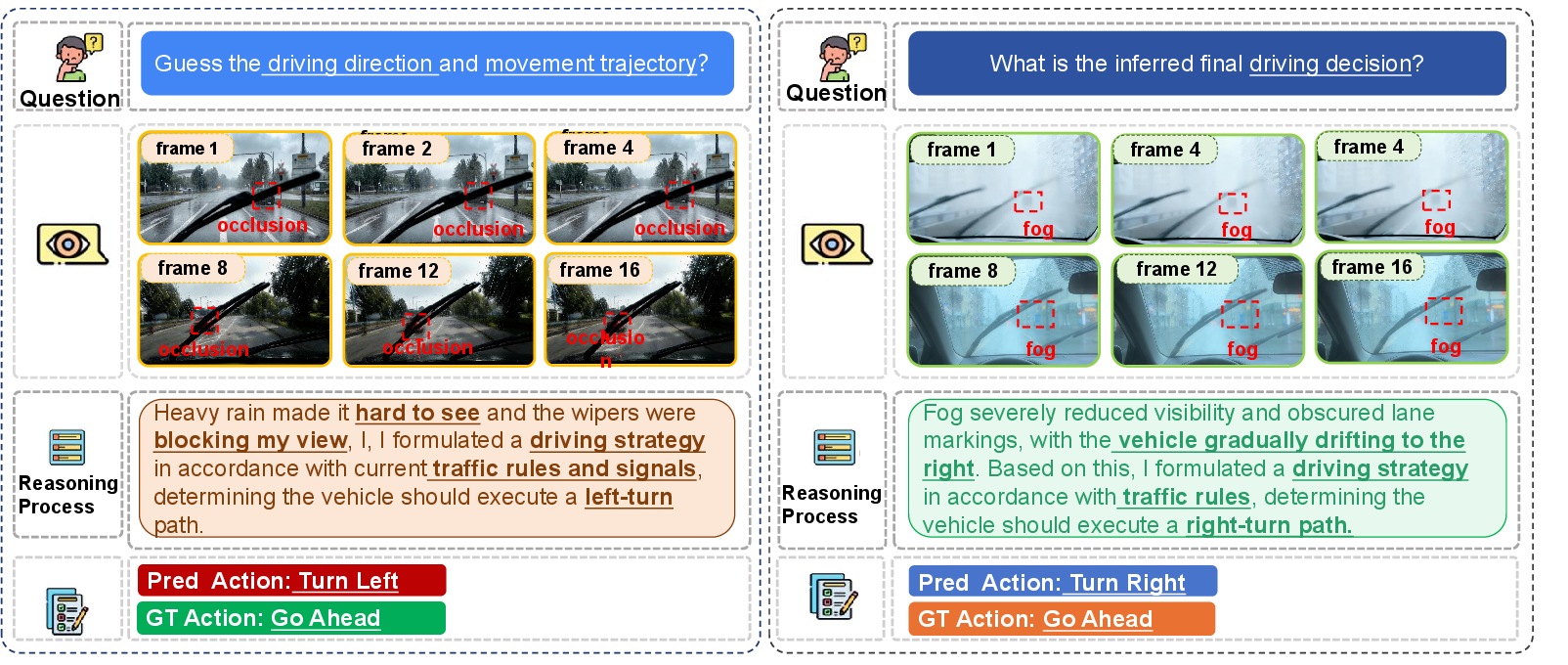


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question: Can today’s AI models that watch videos and answer questions handle the messiness of the real world—like rain, fog, shadows, people walking in front of the camera, or a shaky camera? The authors find that many models do well on clean, perfect videos, but stumble when things get messy. So they build a new training method, called ROVA, and a new test set, called PVRBench, to make and measure models that are tougher and more reliable in real-world conditions.
The main goals, in plain words
- Find out how much video-understanding AI breaks when videos are affected by real-life problems like bad weather, occlusions (things blocking the view), odd lighting, or camera shake.
- Build a new way to train models so they keep giving good answers—and good reasoning—even when videos are messy.
- Create a fair, realistic test to check if models can still think clearly when videos are disturbed.
How they approached the problem
Their approach has three main ideas:
- ROVA training (think: practicing with messy videos on purpose)
- Imagine learning to drive: you don’t only practice on sunny, empty roads—you also practice at night, in rain, and when there’s glare. ROVA does that for AI. It makes “corrupted” versions of normal videos by adding realistic problems: fog, rain, shadows, moving blockers, or shuffled timing. This helps the model learn to ignore distractions and focus on what matters.
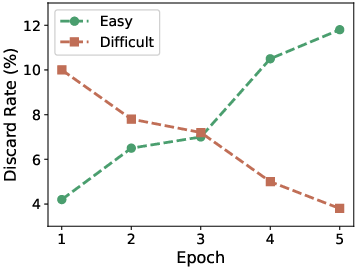
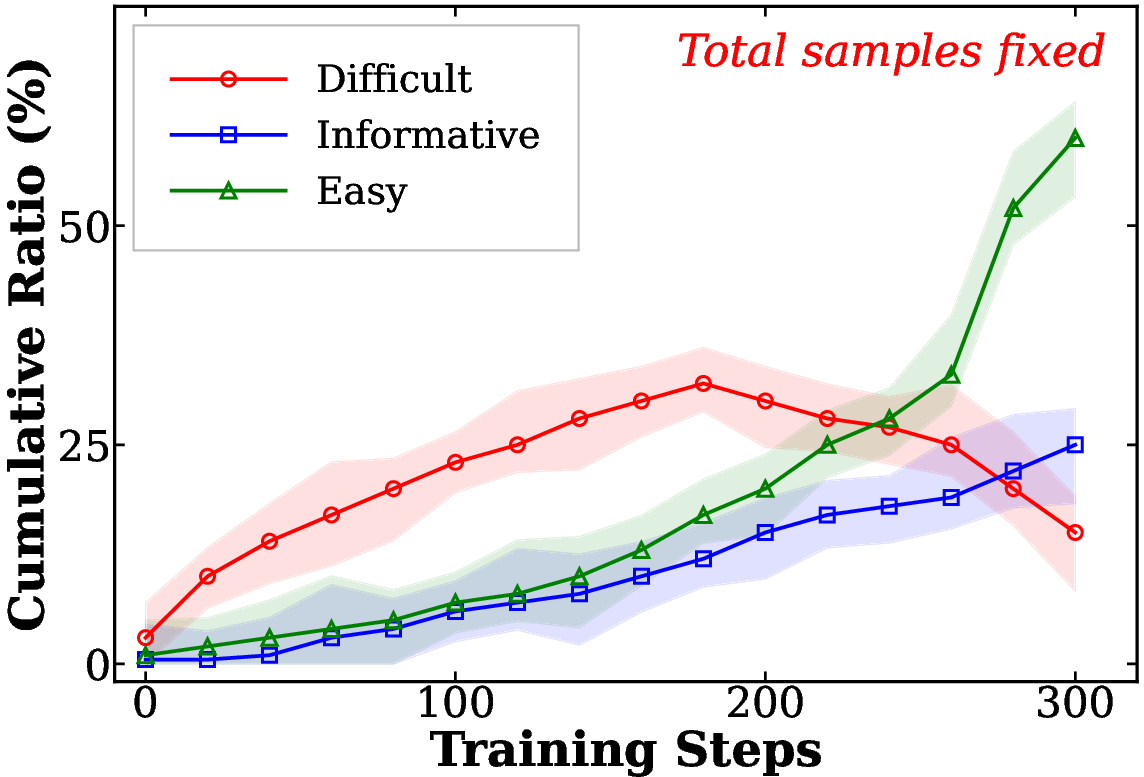
- Self-reflective practice (think: picking the right difficulty level)
- When the model trains, it compares its answers on a clean video and a messy version of the same video. If a question is:
- Too easy: it’s skipped (no need to waste time).
- Too hard: it’s saved for later, when the model is stronger.
- Just right (challenging but doable): it’s used for training right now.
- This is like a student choosing practice problems that are neither trivial nor impossible, and returning to the tough ones later.
- Consistency training with two branches (think: matching answers across clean and messy views)
- The model watches two versions of the same video: clean and corrupted. It’s rewarded when:
- It follows the required output format (first explain, then answer).
- Its final answer is correct.
- Its explanation and answer are consistent between the clean and messy videos.
- This is like being asked: “Explain your thinking—and make sure you’d say the same thing even if the video is foggy or shaky.”
To train and judge this properly, they use a reward-based learning method (a kind of “points for good behavior”), and they also use a strong AI “judge” to check how clear and consistent the model’s reasoning is.
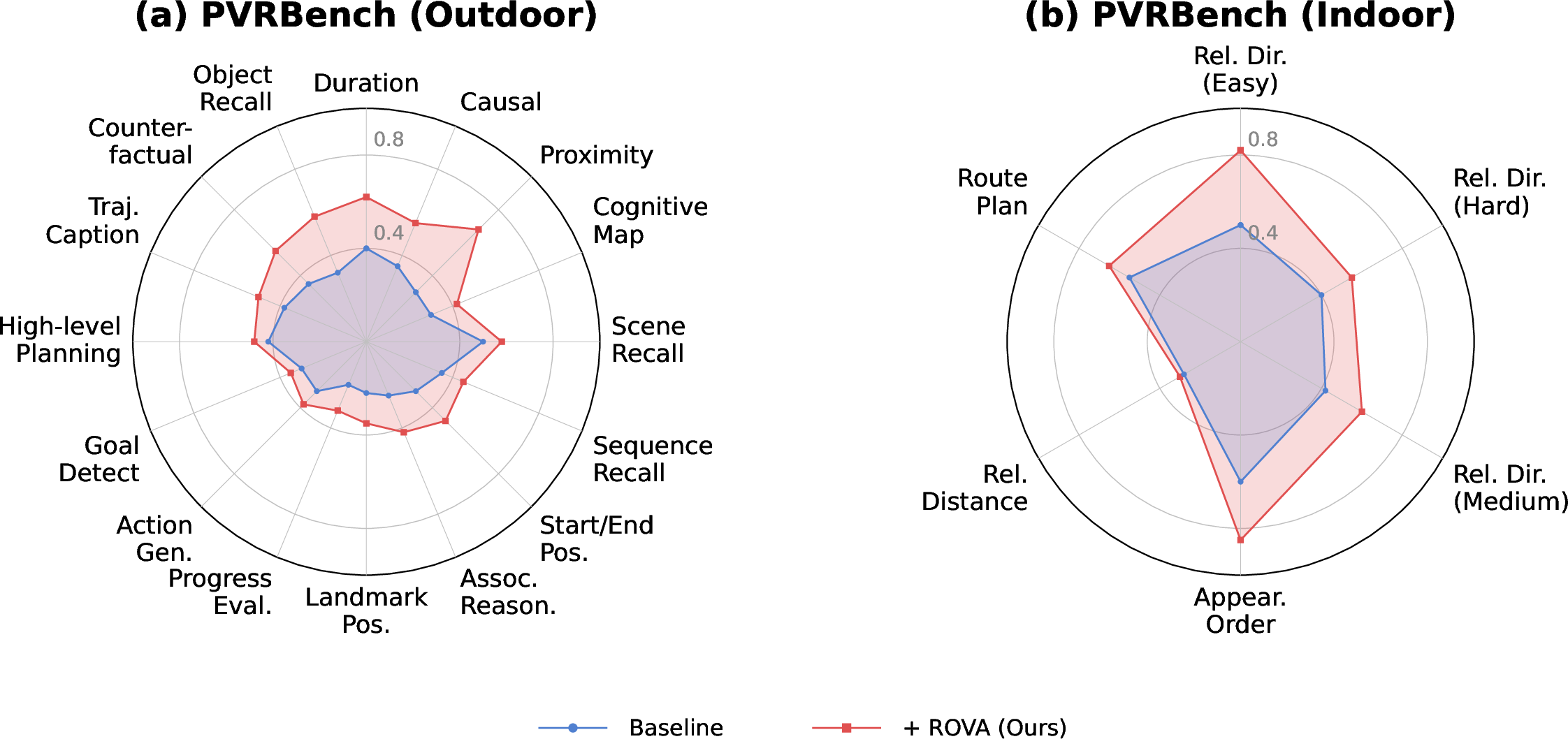
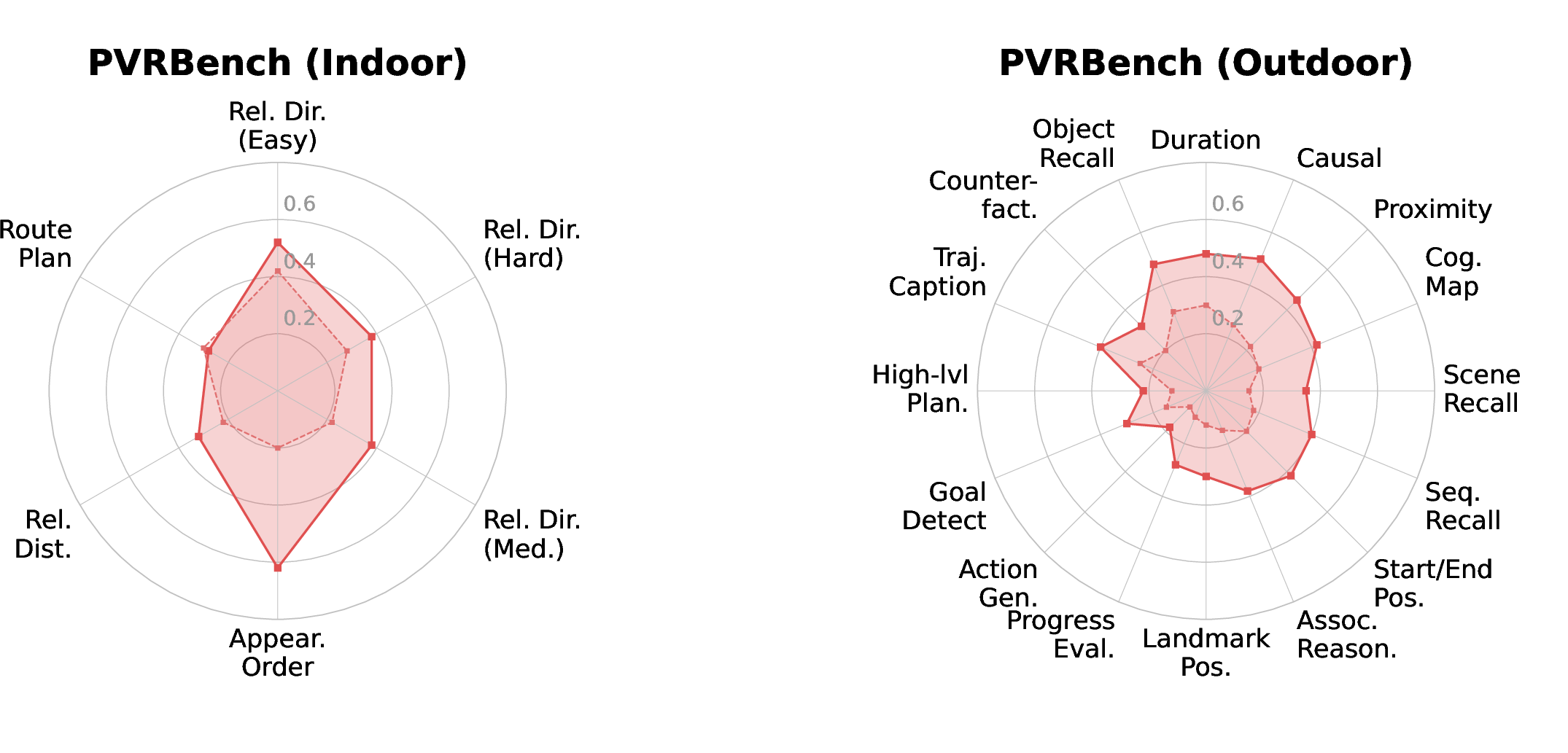
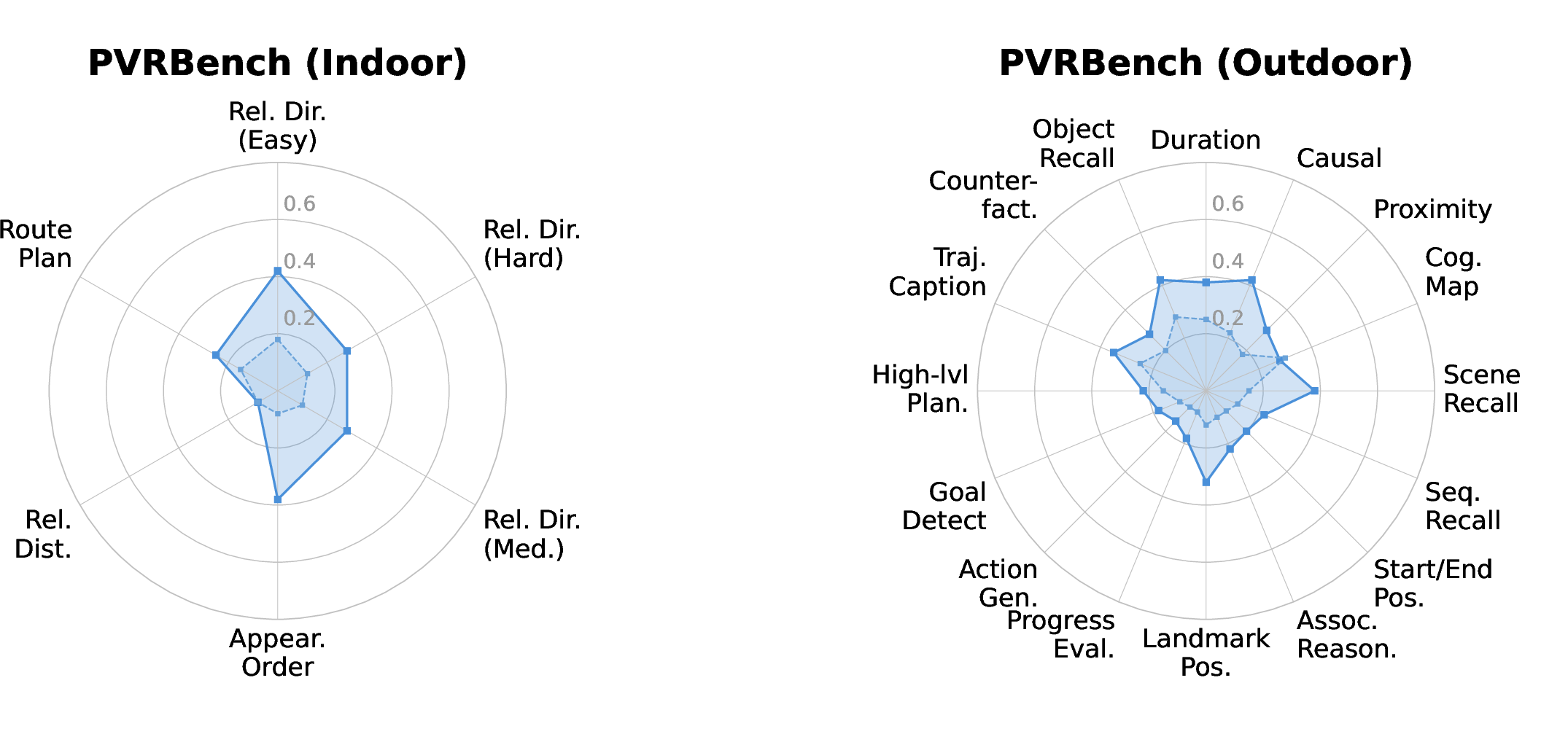
The new benchmark: PVRBench
The authors built PVRBench to test whether models can still reason reliably when videos aren’t perfect. It includes:
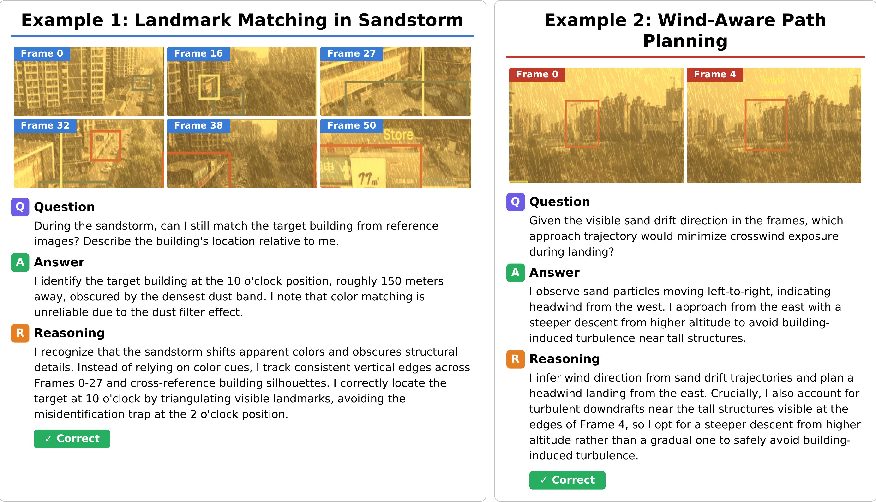
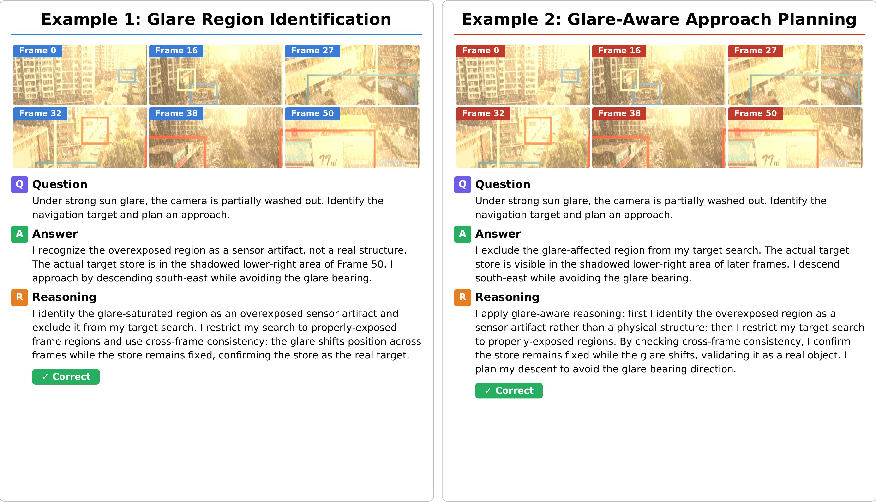
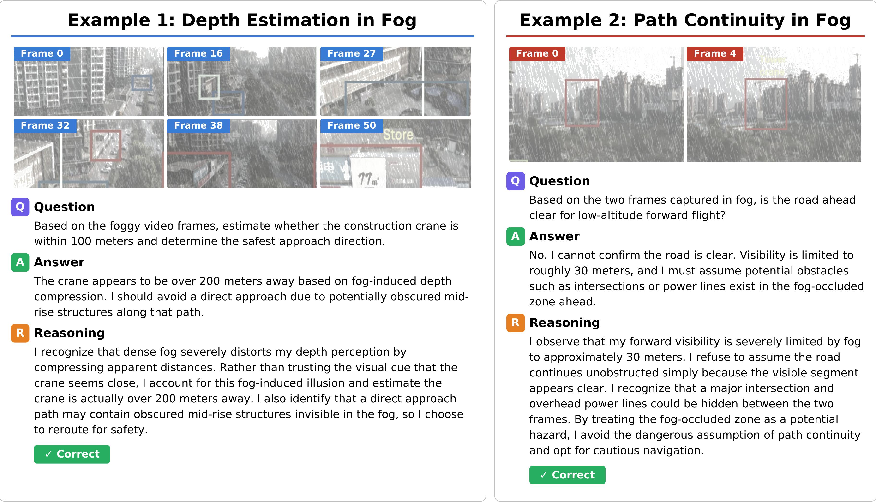
- 12 realistic disturbance types in four groups: lighting (dusk/night/overexposed/shadow), camera motion (translation/zoom/rotation/shake), occlusion (static/dynamic), and weather (fog/rain/snow).
- Over 9,000 videos and 52,000 questions across 27 different scenes (indoor, outdoor, and robot/embodied tasks).
- Measurements for both:
- Final answers (right or wrong)
- Reasoning quality (how steady, coherent, and evidence-based the explanations are)
In short, PVRBench doesn’t just ask, “Did you guess right?” It also asks, “Did you think clearly?”
What they found and why it matters
- Many strong models struggle outside the “clean” lab world.
- On messy videos, even top proprietary models (like GPT-4o and Gemini) drop by about 10–17% in answer accuracy and 10–14% in reasoning quality.
- Open-source models do worse, often losing up to 35% accuracy and around 26% reasoning quality.
- ROVA makes models much more robust.
- Across multiple models and datasets (PVRBench, UrbanVideo, VisBench), ROVA reduces the performance drop and improves both answers and explanations.
- Compared to strong open-source baselines, ROVA boosts:
- Answer accuracy by about 24% (relative improvement)
- Reasoning quality by over 9%
- These gains don’t just help in messy conditions—they also transfer to clean videos, so the model improves overall.
- It’s efficient as well as effective.
- Even though ROVA compares clean and messy videos (which sounds more expensive), its smart sample selection saves time by skipping unhelpful cases and revisiting tough ones later.
- In one setup, it achieved better accuracy than a bigger, heavily trained model while using far fewer compute hours and much less training data.
Why this research is important
- Real-world readiness: If we want AI to help with navigation, robotics, video analysis, or safety tasks, it must cope with rain, fog, glare, motion, and blockers. ROVA trains for that reality.
- Better thinking, not just better guessing: By checking that the model’s explanations stay steady across clean and messy videos, ROVA encourages deeper, more stable reasoning—not just memorizing answers.
- Practical testing: PVRBench gives researchers a common, realistic way to measure whether their models can handle real-world video problems, helping the whole field make fair comparisons and faster progress.
In simple terms: the big takeaway
Most video AI models are great in “perfect” conditions—but the real world is messy. This paper shows how to train models to stay accurate and think clearly even when videos are foggy, shaky, dark, or partially blocked. Their training recipe (ROVA) and their test (PVRBench) make AI more dependable outside the lab, which is exactly where we need it.
Knowledge Gaps
Unresolved limitations, knowledge gaps, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Real-world validation gap: PVRBench perturbations are synthetic; robustness on genuinely corrupted real videos (e.g., real fog/rain, lens dirt, sensor noise, rolling shutter) is unverified.
- Limited perturbation compositions: Each video is corrupted by a single style; combined/compounded disturbances (e.g., low light + rain + camera shake + occlusion) are not systematically tested.
- Temporal corruption realism: Temporal “shuffling” is an unrealistic artifact; more realistic temporal issues (frame drops/duplication, motion blur, rolling shutter, variable frame rate, desynchronization) are not modeled.
- Severity calibration: The distribution and severity levels of perturbations are not calibrated to real-world frequency or intensity; no stress tests across graded severities are reported.
- Anchor correctness risk: The clean-branch output is treated as the anchor during alignment; if the clean prediction is wrong, the perturbed branch may be forced to match an incorrect output. How to detect/mitigate erroneous anchors is not addressed.
- Reward design sensitivity: The weights for reasoning vs. answer alignment (α_r, α_a), KL penalties, and GRPO hyperparameters lack sensitivity analyses; stability and convergence under different settings remain unclear.
- LLM-as-judge reliability: Reasoning metrics and some rewards depend on an LLM judge; there is no human-grounded validation (e.g., correlation with expert annotations, inter-annotator agreement) or robustness to prompt variations.
- Cost and reproducibility of LLM-judging: The compute/cost overhead, API variance, and reproducibility of LLM-judged metrics/rewards across time and versions are not quantified or controlled.
- Circularity in self-reflection: The model self-evaluates difficulty and confidence, risking bias amplification and confirmation effects; comparisons to external difficulty estimators or teacher models are missing.
- Curriculum hyperparameters: Thresholds (e.g., confidence τ), memory size/eviction K_max, and re-evaluation cadence lack principled selection or ablation; effects on robustness and convergence are underexplored.
- Catastrophic forgetting: Discarding “easy” samples may erode base competencies over time; retention/forgetting under the proposed curriculum is not measured.
- Robustness–sensitivity trade-off: Enforcing invariance across clean/perturbed inputs may cause spurious invariance (e.g., ignoring genuinely new or altered scene elements). No tests measure over-robustness or hallucination in dynamic-change settings.
- Task/format scope: Evaluation centers on multiple-choice QA; generalization to open-ended responses, stepwise chain-of-thought grading, and embodied action/planning/execution (with downstream task success) is not examined.
- Confidence calibration and abstention: Model calibration, uncertainty, and selective prediction under corruptions are not evaluated (e.g., ECE, risk-coverage).
- Baseline coverage: Empirical comparisons omit strong robustness baselines such as adversarial video training, consistency/feature-level alignment methods, and test-time adaptation specialized for videos.
- Representation-level alignment: The method aligns outputs; whether aligning intermediate representations (e.g., feature or token-level) yields better stability or transfer is not investigated.
- Domain and sensor breadth: Training uses an outdoor-focused subset; robustness across diverse indoor/egocentric domains, sensors (e.g., different FOVs, mobile cameras), and codecs is insufficiently validated.
- Long-horizon and streaming settings: Robustness for long videos, online/streaming inference, latency constraints, and memory footprints are not assessed.
- Generalization to unseen perturbation families: Coverage omits many real-world artifacts (sensor noise/ISO, compression artifacts, color cast, HDR blooming/flares, dirt/smudges); transfer to such unseen families is untested.
- Depth-aware mask generation details: The depth estimation/source and its errors’ impact on perturbation realism are unspecified; failure modes of depth-conditioned masks are not analyzed.
- Annotation robustness under corruption: It is unclear whether ground-truth answers remain unambiguous under heavy perturbation; no quality audit or ambiguity analysis is provided.
- Style overlap between training and evaluation: Training and PVRBench share perturbation families; risk of overfitting to style distributions persists despite dynamic sampling. Systematic holdout-style evaluations are limited.
- Perturbation parameter disclosure: The reproducibility of the masking pipeline (code, seeds, parameter ranges) and its determinism are not fully detailed.
- Safety-critical evaluation: No analysis of risk-sensitive metrics (e.g., severe error rates) in embodied or driving-like scenarios where robustness failures have high consequences.
- Fairness considerations: No assessment of whether perturbations disproportionately degrade performance on specific demographics/scenes or amplify biases.
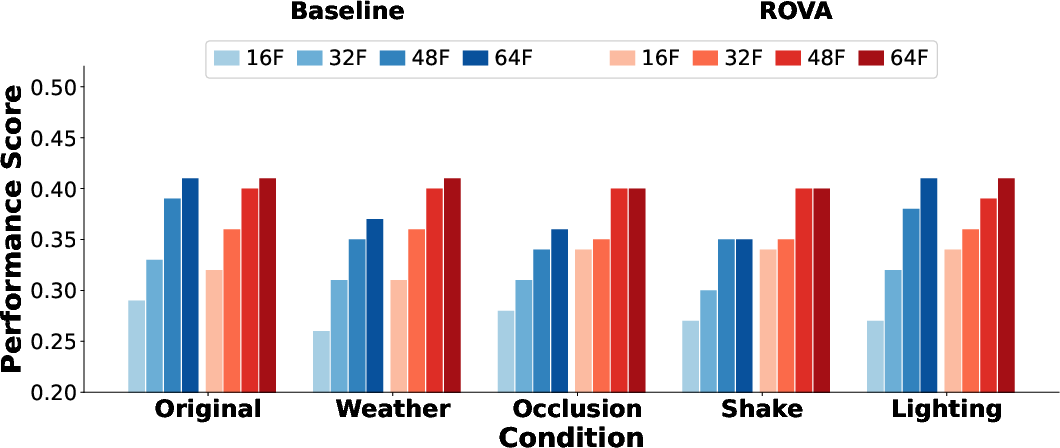
- Interaction with frame sampling: The approach fixes frame counts (often 16–64); robustness to different sampling rates/policies and variable-length inputs is not explored.
- Alternative self-reflection designs: Using teacher models, committee-based judges, or uncertainty ensembles for difficulty estimation is untested.
- Memory buffer policies: The impact of metadata-only storage, mask regeneration fidelity, and memory prioritization strategies (e.g., age, style diversity) is not studied.
- KL reference model ambiguity: The choice and role of F_ref in the GRPO KL penalty are not fully specified; how the reference is constructed or updated remains unclear.
Practical Applications
Immediate Applications
Below are practical uses that can be deployed now using the paper’s methods (ROVA) and resources (PVRBench), with sector tie-ins, potential tools/workflows, and feasibility assumptions.
- Robustify existing video-language products with ROVA fine-tuning
- Sectors: automotive (ADAS commentary, tele-ops dashboards), robotics (warehouse pickers, mobile AMRs), drones (inspection/reporting), security/CCTV analytics, retail loss prevention, sports analytics, public safety monitoring.
- Tools/Workflows: integrate ROVA’s structured spatio-temporal corruption pipeline and dual-branch GRPO training into current VLM training; use open-source judges (e.g., Qwen3-13B) or GPT-4o for reward signals; export improved VLM checkpoints.
- Assumptions/Dependencies: access to base VLM weights and RL fine-tuning stack; moderate GPU budget (dual-branch RL, group sizes, reward evaluation); availability of video-QA style supervision or synthetic QA generation; acceptable latency/throughput for deployment.
- Pre-deployment robustness gates using PVRBench in CI/CD
- Sectors: software/ML Ops, autonomy/robotics vendors, cloud AI APIs, gov/enterprise procurement.
- Tools/Workflows: add PVRBench to nightly regression; set quantitative gates on accuracy and reasoning metrics (Fragility, Consistency, Belief, Recovery, Attention); ship a “robustness dashboard.”
- Assumptions/Dependencies: adopt benchmark license and data; stable evaluation harness; thresholds calibrated to use case risk.
- Structured corruption augmentation for broader video models (beyond QA)
- Sectors: computer vision (classification, detection, tracking), media analytics, sports tech.
- Tools/Workflows: use ROVA’s weather/occlusion/lighting/camera-motion masks and temporal shuffles as training augmentations; keep labels consistent for detection/segmentation tasks.
- Assumptions/Dependencies: corruption parameters tuned so labels remain valid; augmentations complement rather than replace domain data.
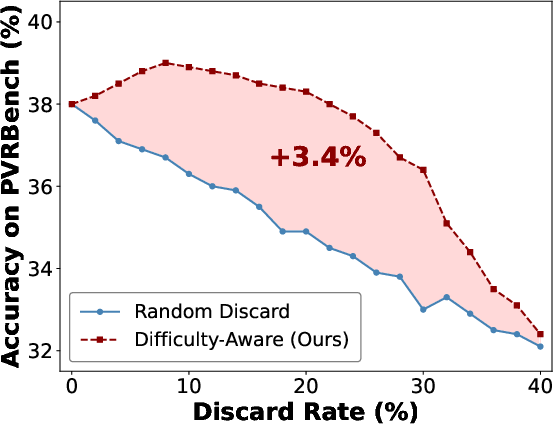
- Compute- and data-efficient training via self-reflective curriculum
- Sectors: startups, labs, teams with constrained compute.
- Tools/Workflows: implement the paper’s difficulty-aware sample triage (easy discard threshold, memory buffer for “too hard” samples, periodic re-eval); track discard rates and difficulty mix as training KPIs.
- Assumptions/Dependencies: reliable difficulty estimation via prompts and probability scores; minimal extra overhead from periodic re-evaluation; careful thresholding to avoid data under-exposure.
- Field operations assistants robust to rain, glare, occlusion, camera shake
- Sectors: utilities (power lines, pipelines), construction, mining, agriculture (drone and rover footage), maritime inspection.
- Tools/Workflows: fine-tune a VLM with ROVA on domain video-QA; deploy for mission summaries, anomaly spotting, and bilingual narration.
- Assumptions/Dependencies: on-device or edge inference constraints; ensure safety-critical decisions are kept “advisory” unless validated.
- Safer, more reliable dashcam and bodycam video summarization
- Sectors: consumer dashcams, fleet telematics, public safety.
- Tools/Workflows: ROVA-tuned VLMs that keep reasoning stable under night-time, fog, heavy rain, glare, and occlusions; generate event timelines and scene descriptions.
- Assumptions/Dependencies: privacy and compliance; falsification risk mitigations (human oversight).
- Home and small-business security clip triage
- Sectors: smart home, SMB security.
- Tools/Workflows: replace brittle clip-labeling pipelines with ROVA-trained VLMs to reduce false alerts during low-light, motion blur, or partial occlusion; surface “reasoning reports.”
- Assumptions/Dependencies: consumer-grade cameras often have heavy compression/artifacts—may require fine-tuning with device-specific samples.
- Robust video tutoring and feedback for sports and education content
- Sectors: edtech (lab demos, experiments), sports coaching apps.
- Tools/Workflows: apply structured augmentations to train assistants that explain steps accurately despite shaky cams or lighting changes; use reasoning score metrics to select/approve outputs.
- Assumptions/Dependencies: domain prompts and QA data; balance between robustness and style/engagement.
- Academic benchmarking and method comparison on realistic perturbations
- Sectors: academia, research labs.
- Tools/Workflows: adopt PVRBench to test new VLM architectures, reward designs, and curriculum strategies; report PVRBench metrics alongside clean-set results.
- Assumptions/Dependencies: consistency of LLM-as-judge configurations; reproducibility using fixed perturbation masks.
- Vendor assessment and procurement checklists using robustness metrics
- Sectors: enterprise IT, public sector, insurers.
- Tools/Workflows: require vendors to report PVRBench performance and reasoning metrics; compare offerings under standardized corruption conditions.
- Assumptions/Dependencies: acceptance of LLM-as-judge scoring; mapping metrics to organizational risk thresholds.
Long-Term Applications
The following opportunities require additional research, domain adaptation, scaling, or standardization before broad deployment.
- Certification frameworks for safety-critical multimodal systems
- Sectors: autonomous driving, industrial robotics, public infrastructure.
- Tools/Workflows: extend PVRBench into an auditable certification suite with broader tasks, scenario coverage, and third-party audits; define pass/fail and confidence intervals for reasoning robustness.
- Assumptions/Dependencies: community and regulatory buy-in; expanded real-world perturbation models (e.g., lens fouling, sensor dropouts); independent assessors.
- Continual/online robustness learning in the wild
- Sectors: robotics, smart city cameras, retail analytics.
- Tools/Workflows: adapt self-reflective evaluation + memory buffer for on-device or federated lifelong learning; schedule deferred training in low-load windows.
- Assumptions/Dependencies: safe RL and drift detection; privacy-preserving data pipelines; safeguards against catastrophic forgetting or reward hacking.
- Domain-specialized medical and surgical video assistants
- Sectors: healthcare (endoscopy, laparoscopic surgery, telemedicine).
- Tools/Workflows: tailor structured perturbations (smoke, occlusion by instruments, fluids) and reward judges for clinical semantics; robust step-by-step reasoning and error flagging.
- Assumptions/Dependencies: clinical datasets, approvals, and validation; rigorous bias and safety analyses; integration with surgeon-in-the-loop UX.
- Robust AR/XR scene understanding for wearables and glasses
- Sectors: consumer AR, enterprise maintenance/training, accessibility.
- Tools/Workflows: low-latency, on-device inference using ROVA-trained models that maintain consistent reasoning under head motion, dim lighting, or partial occlusion; edge offload for heavy sequences.
- Assumptions/Dependencies: model compression and hardware acceleration; battery/thermal budgets; robust streaming reward signals for future on-device adaptation.
- Digital-twin perturbation services for enterprise datasets
- Sectors: manufacturing, logistics, energy, defense training sims.
- Tools/Workflows: service/platform that injects PVRBench-style spatio-temporal corruptions aligned to scene geometry, enabling robustness training without exposing real incidents.
- Assumptions/Dependencies: accurate depth/layout estimation or 3D twins; validated realism of perturbations; IP and data-sharing agreements.
- Cross-task extensions: detection, tracking, and policy learning with consistency rewards
- Sectors: surveillance, sports broadcast automation, robot perception-control stacks.
- Tools/Workflows: adapt dual-branch alignment and reward modeling to detection/tracking outputs (e.g., box/track consistency across corruptions) and to perception-to-action policies (reasoning-to-control alignment).
- Assumptions/Dependencies: reward definitions for non-QA tasks; stable optimization under GRPO-style updates; multi-object ground truth.
- Robustness-aware copilots for teleoperation and supervisory control
- Sectors: logistics teleop, construction, remote inspection.
- Tools/Workflows: copilots that detect reasoning fragility spikes (metric-driven) and escalate to human operators; explain “belief” and “recovery” states.
- Assumptions/Dependencies: HRI design; thresholds tuned to minimize nuisance alerts; liability frameworks.
- Insurance and risk-pricing models informed by robustness scores
- Sectors: insurance for fleets, robotics, and facilities.
- Tools/Workflows: incorporate PVRBench-like metrics into underwriting for AI-enabled systems; premium adjustments based on verified robustness.
- Assumptions/Dependencies: actuarial validation linking metrics to incident rates; accepted auditing standards.
- Regulatory guidelines and public-sector benchmarks for AI vision robustness
- Sectors: transportation authorities, city surveillance, procurement agencies.
- Tools/Workflows: policy documents recommending minimum robustness thresholds; public leaderboards for systems used in public programs; incentives for transparent reporting.
- Assumptions/Dependencies: cross-agency coordination; privacy and fairness safeguards; ongoing benchmark maintenance.
- Multimodal household robots with disturbance-aware cognition
- Sectors: consumer robotics, elder care, hospitality.
- Tools/Workflows: integrate ROVA-trained perception with planning; maintain consistent reasoning under clutter, occlusion, and lighting variation; reason about uncertainty to choose safer actions.
- Assumptions/Dependencies: integration with control/planning stacks; low-latency video processing; extensive household data and simulation-to-real transfer.
- Real-time on-device reward estimation and judge distillation
- Sectors: mobile AI, embedded robotics.
- Tools/Workflows: distill LLM-as-judge into compact reward models for continual/self-supervised on-device adaptation; approximate reasoning consistency cheaply at the edge.
- Assumptions/Dependencies: high-quality distillation datasets; managing drift and compounding bias; efficient GRPO or alternative optimizers for embedded hardware.
Glossary
- Ablation study: A research method that systematically removes or alters components of a system to measure their individual contributions. "Ablation study of the reward model on PVRBench using commercial and open source VLMs."
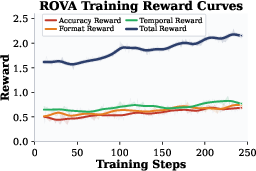
- Accuracy reward: A reinforcement learning signal that grants credit when the model’s final answer matches the ground truth. "Accuracy Reward. The accuracy reward evaluates whether the extracted answer is semantically consistent with the ground truth ."
- Advantage (reinforcement learning): A baseline-normalized quantity indicating how much better an action (or output) is relative to average, used to reduce variance in policy gradients. "The advantage corresponding to output is calculated from the associated reward set :"
- Alignment reward: A reward component that encourages the perturbed-input output to align with the clean-input output in both reasoning and answer. "Alignment Reward. For each output pair , the alignment reward is decomposed into reasoning and answer components:"
- Attention (reasoning metric): A benchmark measure assessing how well the reasoning process focuses on relevant visual evidence. "To quantify reasoning reliability, PVRBench introduces five complementary metrics (Fragility, Consistency, Belief, Recovery, and Attention; see \cref{tab:benchmark}) that assess the quality and stability of intermediate reasoning, as well as final-answer accuracy."
- Belief (score): A benchmark measure capturing the confidence or internal coherence of the model’s stated reasoning. "To quantify reasoning reliability, PVRBench introduces five complementary metrics (Fragility, Consistency, Belief, Recovery, and Attention; see \cref{tab:benchmark}) that assess the quality and stability of intermediate reasoning, as well as final-answer accuracy."
- Consistency (reasoning metric): A benchmark measure evaluating the stability of a model’s reasoning and conclusions under perturbations. "To quantify reasoning reliability, PVRBench introduces five complementary metrics (Fragility, Consistency, Belief, Recovery, and Attention; see \cref{tab:benchmark}) that assess the quality and stability of intermediate reasoning, as well as final-answer accuracy."
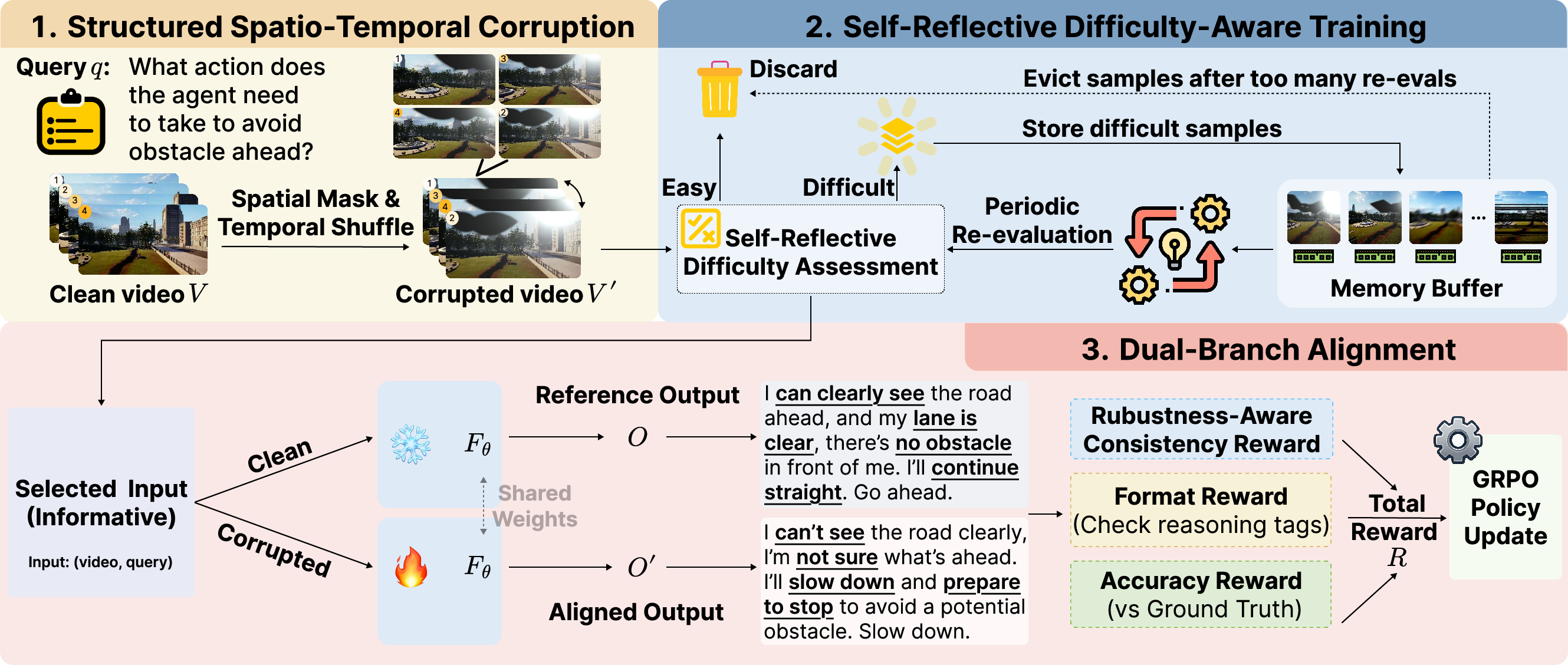
- Curriculum learning: A training strategy that orders samples from easy to hard over time to stabilize learning. "Unlike curriculum learning, which follows a fixed, easy-to-hard schedule, this self-reflective evaluation estimates the difficulty and informativeness of each video–query instance based on the model’s current capability, enabling an adaptive curriculum that prioritizes informative samples while deferring overly difficult ones through memory replay."
- Data augmentation: Techniques that artificially expand and diversify training data by applying transformations or corruptions. "Several works~\citep {mao2022understanding,zhao2023evaluatingadversarialrobustnesslarge,sheng2025rtptimprovingadversarialrobustness,oh2025understanding,agarwal-etal-2025-mvtamperbench,schiappa2023robustnessanalysisvideolanguagemodels} have explored robustness to distribution shifts and adversarial inputs through data augmentation~\citep{duan2023improvevideorepresentationtemporal}, test-time adaptation~\citep{zhao2024testtimeadaptationclipreward}, and transfer-based strategies~\citep{Tong2025zero,cai2025clapisolatingcontentstyle}."
- Distribution shift: A change between the training data distribution and the deployment data distribution that can degrade performance. "Several works~\citep {mao2022understanding,zhao2023evaluatingadversarialrobustnesslarge,sheng2025rtptimprovingadversarialrobustness,oh2025understanding,agarwal-etal-2025-mvtamperbench,schiappa2023robustnessanalysisvideolanguagemodels} have explored robustness to distribution shifts and adversarial inputs through data augmentation~\citep{duan2023improvevideorepresentationtemporal}, test-time adaptation~\citep{zhao2024testtimeadaptationclipreward}, and transfer-based strategies~\citep{Tong2025zero,cai2025clapisolatingcontentstyle}."
- Dual-branch alignment: A training design that processes clean and corrupted inputs in parallel branches and enforces output consistency between them. "ROVA trains the model through a dual-branch alignment mechanism that aligns representations from clean and partially perturbed video inputs."
- Format reward: A reward term that checks whether outputs follow a required structure or template. "Format Reward. The model is required to generate an output consisting of an embodied reasoning process followed by a final answer , enclosed within and <answer></answer> tags, respectively."
- Fragility (reasoning metric): A benchmark measure indicating how easily a model’s reasoning degrades when inputs are perturbed. "To quantify reasoning reliability, PVRBench introduces five complementary metrics (Fragility, Consistency, Belief, Recovery, and Attention; see \cref{tab:benchmark}) that assess the quality and stability of intermediate reasoning, as well as final-answer accuracy."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that optimizes policies using rewards normalized within groups, akin to PPO but with group-relative advantages. "This robustness-aware consistency alignment is guided by reward modeling over reasoning and answer consistency, and optimized using group relative policy optimization."
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from a reference distribution, commonly used as a regularization penalty. "and $D_{\text{KL}\big( F_\theta \| F_{\text{ref} \big)$ denotes the KL-divergence penalty term."
- LLM-as-judge: A paradigm where a LLM is used to evaluate or score outputs (e.g., reasoning quality) instead of hard-coded rules. "To assess reasoning process quality, we leverage a powerful vision-language foundational model (e.g., GPT-4o) to score reasoning traces in coherence, perturbation awareness, and evidence grounding via a structured template (see~\cref{tab:prompt_reasoning}), following the LLM-as-judge paradigm~\citep{zheng2023judging, he2024videoscore}."
- Memory buffer (temporal): A storage mechanism that keeps difficult training samples for later re-evaluation and training. "excessively difficult ones are stored in a temporal memory buffer for later revisiting."
- Memory eviction: The policy of removing samples from a memory buffer when certain criteria (e.g., maximum re-evaluations) are exceeded. "To prevent this, we impose a maximum re-evaluation threshold and evict entries exceeding it:"
- Memory replay: Reusing stored experiences or samples at later training stages to improve learning stability and performance. "enabling an adaptive curriculum that prioritizes informative samples while deferring overly difficult ones through memory replay."
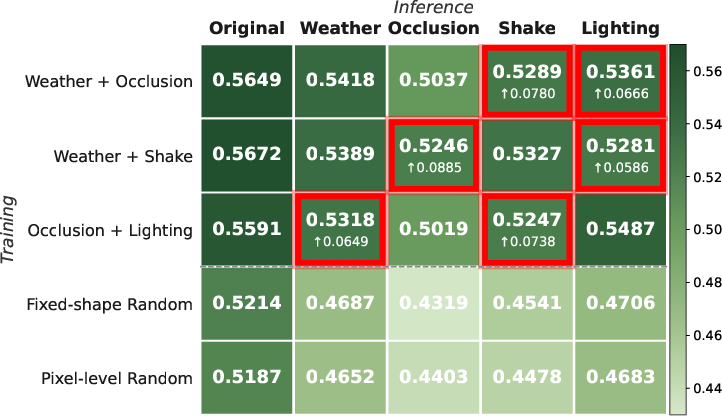
- Out-of-distribution (OOD): Data points that come from a distribution different from the training set, often used to test generalization. "Models trained on two mask styles are evaluated on in-domain and held-out OOD perturbations (highlighted in red)."
- Perturbation-invariant representation learning: Learning features that remain stable under input corruptions or disturbances. "our approach promotes perturbation-invariant representation learning while preserving essential visual semantics."
- Recovery (reasoning metric): A benchmark measure of how well a model can regain correct reasoning after being disrupted by perturbations. "To quantify reasoning reliability, PVRBench introduces five complementary metrics (Fragility, Consistency, Belief, Recovery, and Attention; see \cref{tab:benchmark}) that assess the quality and stability of intermediate reasoning, as well as final-answer accuracy."
- Reward modeling: The process of defining and computing reward signals (possibly via learned or heuristic judges) to guide optimization of complex outputs. "The training objective enforces consistency between two branches using the proposed reward modeling combined with GRPO~\citep{shao2024deepseekmath}."
- Robustness-aware consistency reward: A reward that explicitly encourages consistent outputs between clean and corrupted inputs to improve robustness. "To address this limitation, we propose ROVA, a novel training framework that improves robustness by modeling a robustness-aware consistency reward under spatio-temporal corruptions."
- Self-reflective evaluation: A mechanism where the model evaluates its own performance on samples to estimate difficulty and guide data selection. "Specifically, it continuously re-estimates sample difficulty via self-reflective evaluation, enabling adaptive training with a robustness-aware consistency reward."
- Spatio-temporal corruption: Structured perturbations that affect both spatial content within frames and temporal ordering across frames. "Overview of ROVA: (1) structured spatio-temporal corruption that generates realistic perturbations, (2) self-reflective evaluation with difficulty-aware online training that adaptively prioritizes informative samples, and (3) dual-branch alignment reward modeling that enforces output consistency between clean and perturbed inputs."
- Temporal coherence: The property that effects or perturbations remain consistent across adjacent frames in a video. "Notably, all perturbations are spatially aware and temporally coherent, capturing realistic video disturbances."
- Temporal shuffling: Randomly permuting the order of video frames to disrupt temporal information. "We first design a structured spatio-temporal corruption pipeline that models four realistic disturbances, including weather, lighting, occlusion, and camera motion, using style-specific, cross-frame coherent masks for spatial perturbations and temporal shuffling to disrupt temporal order."
- Test-time adaptation: Techniques that adapt a model at inference time to better handle new data distributions without full retraining. "Several works~\citep {mao2022understanding,zhao2023evaluatingadversarialrobustnesslarge,sheng2025rtptimprovingadversarialrobustness,oh2025understanding,agarwal-etal-2025-mvtamperbench,schiappa2023robustnessanalysisvideolanguagemodels} have explored robustness to distribution shifts and adversarial inputs through data augmentation~\citep{duan2023improvevideorepresentationtemporal}, test-time adaptation~\citep{zhao2024testtimeadaptationclipreward}, and transfer-based strategies~\citep{Tong2025zero,cai2025clapisolatingcontentstyle}."
- Zero-shot learning: Solving tasks without using any task-specific labeled examples during training, often relying on generalization from prior knowledge. "A few prior studies~\citep{mao2022understanding,zhou2024revisitingadversarialrobustnessvision,zhang2024benchmarkinglargemultimodalmodels} have explored improving the robustness of VLMs through generic data augmentation, random frame masking, zero-shot, or adversarial training."
Collections
Sign up for free to add this paper to one or more collections.