Benchmarking Political Persuasion Risks Across Frontier Large Language Models
Abstract: Concerns persist regarding the capacity of LLMs to sway political views. Although prior research has claimed that LLMs are not more persuasive than standard political campaign practices, the recent rise of frontier models warrants further study. In two survey experiments (N=19,145) across bipartisan issues and stances, we evaluate seven state-of-the-art LLMs developed by Anthropic, OpenAI, Google, and xAI. We find that LLMs outperform standard campaign advertisements, with heterogeneity in performance across models. Specifically, Claude models exhibit the highest persuasiveness, while Grok exhibits the lowest. The results are robust across issues and stances. Moreover, in contrast to the findings in Hackenburg et al. (2025b) and Lin et al. (2025) that information-based prompts boost persuasiveness, we find that the effectiveness of information-based prompts is model-dependent: they increase the persuasiveness of Claude and Grok while substantially reducing that of GPT. We introduce a data-driven and strategy-agnostic LLM-assisted conversation analysis approach to identify and assess underlying persuasive strategies. Our work benchmarks the persuasive risks of frontier models and provides a framework for cross-model comparative risk assessment.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but important question: Can today’s most advanced AI chatbots change people’s political opinions, and how do they compare to regular campaign ads? The authors test several top “frontier” LLMs—the kinds of AI that can chat with you—to see how persuasive they are on two hot topics: immigration and raising the minimum wage.
What questions did the researchers ask?
In plain terms, the paper tries to answer:
- Are modern AI chatbots more persuasive than typical human-made campaign ads?
- Which AI models are the most persuasive?
- Do certain ways of prompting the AI (like telling it to use more facts and numbers) make it better at persuasion?
- What kinds of conversation strategies help the AI change minds?
How did they do the research?
The big idea
The researchers ran two large online studies with 19,145 participants. They randomly assigned people (think “coin flip”) to different conditions—like watching a neutral video, seeing a human-made ad, or chatting with an AI—and then measured if their opinions shifted right after.
What is an LLM and a “prompt”?
- An LLM is an AI chatbot that can read and write text very well.
- A “prompt” is the instruction you give the chatbot. For example:
- Plain prompt: “Please persuade the person.”
- Information prompt: “Use facts, numbers, and evidence to persuade.”
Topics and stances
People discussed:
- Immigration: whether “illegal immigrants should be eligible for in-state college tuition.”
- Minimum wage: whether “the federal minimum wage should be raised to $15/hour.”
The AI tried to persuade people toward or against these policies, depending on the study setup.
The models they tested
The researchers compared several leading models from different companies:
- Anthropic: Claude Sonnet 4 and Claude Sonnet 4.5
- Google: Gemini 2.5 Flash and Gemini 3
- OpenAI: GPT‑4.1 and GPT‑5
- xAI: Grok 4
Study 1 (August 2025)
- Compared human ads vs. AI chat for immigration.
- Compared different AI models for both immigration and minimum wage.
- Found a technical glitch for the human minimum-wage ad, so they used a careful statistical method to compare to similar ad results from a past study.
Study 2 (November 2025)
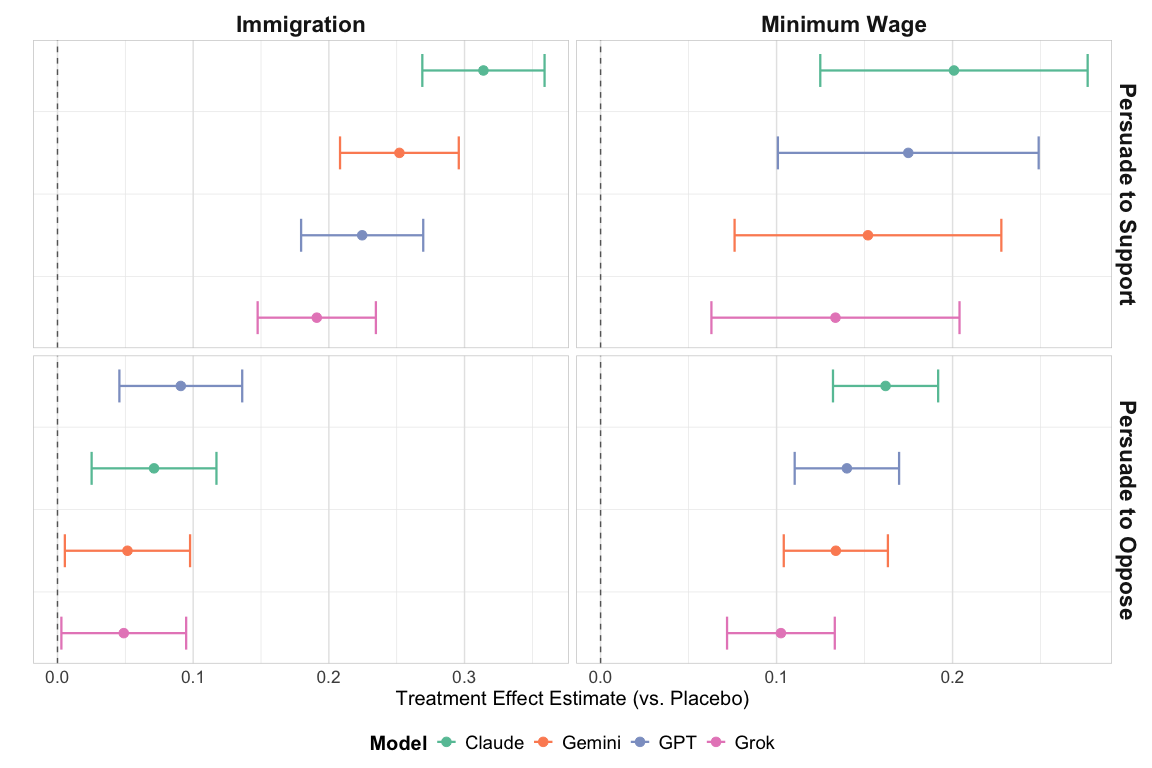
- Focused on newer, more powerful models (Claude 4.5, Gemini 3, GPT‑5, Grok 4).
- Tested persuasion in both directions:
- Persuade to support the policy
- Persuade to oppose the policy
- Did not include human ads here because Study 1 already showed AI outperforming them.
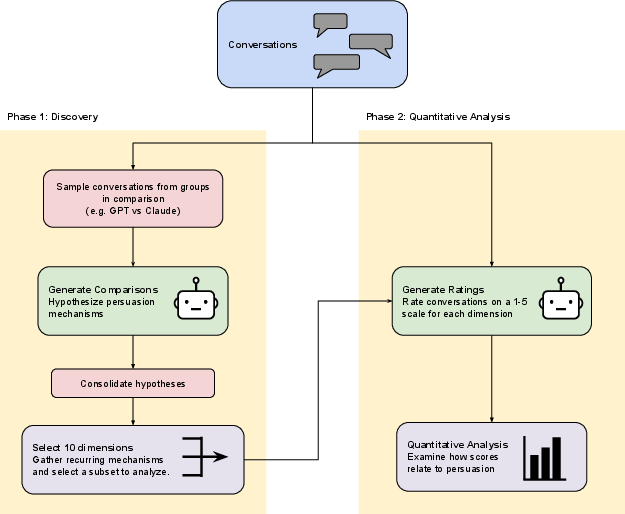
How they analyzed conversations
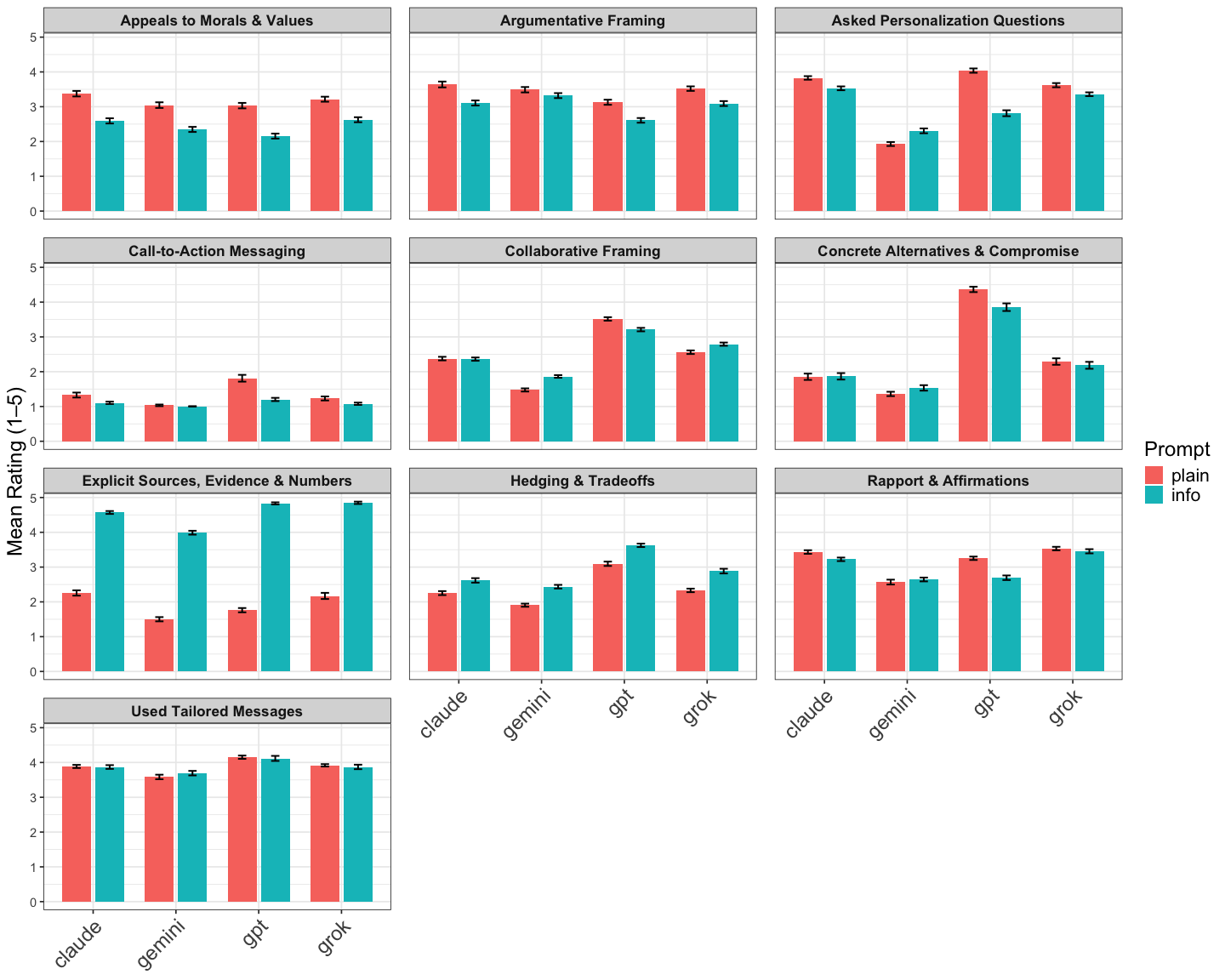
They used AI to help review and rate 4,790 chatbot conversations to spot which persuasion strategies showed up (like using moral appeals or giving a call to action). Think of it as having a very careful, consistent “coach” read every chat and score the tactics used.
What did they find?
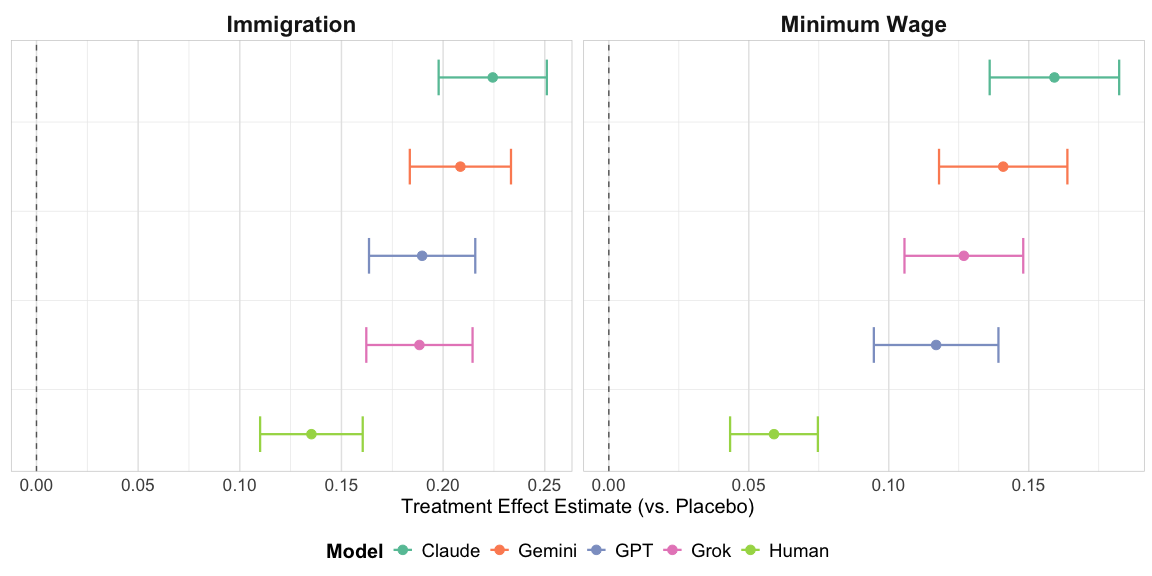
1) AI chatbots are more persuasive than typical campaign ads
Across issues, AI chats moved opinions more than human-made ads. This is a big shift from earlier studies that found little difference.
2) Some AI models persuade more than others
A stable pattern emerged in both studies:
- Claude models were the most persuasive.
- GPT and Gemini were in the middle.
- Grok was the least persuasive (but still better than human ads in Study 1).
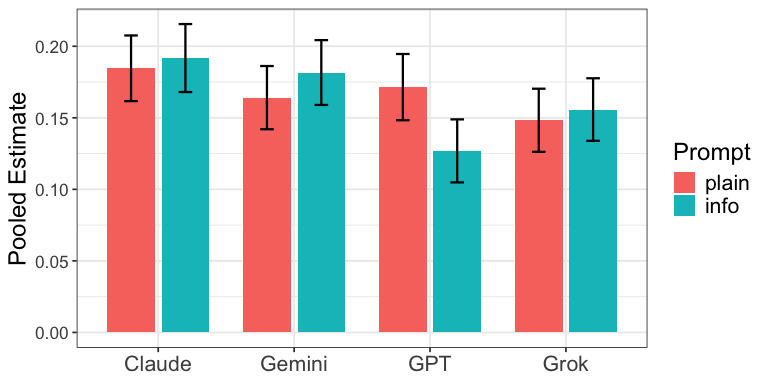
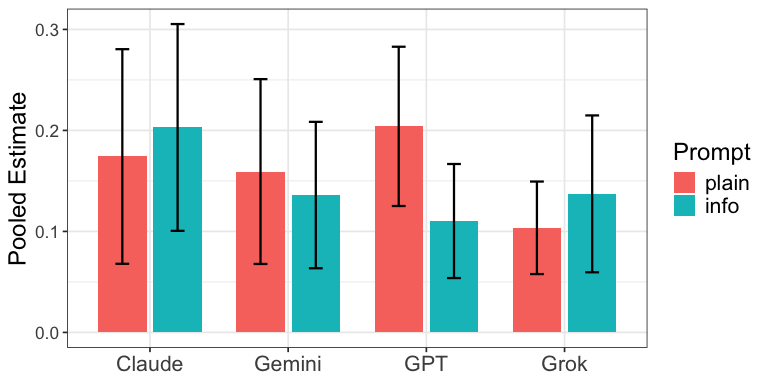
3) “Information prompts” don’t help uniformly
Telling the AI to use lots of facts and numbers helped some models but hurt others:
- Helped Claude and Grok.
- Reduced persuasiveness for GPT.
- Mixed results for Gemini. Bottom line: the best prompting strategy depends on the specific model.
4) Persuasion was stronger when arguing for the policy
Across both topics, chatbots moved opinions more when pushing toward the “support” side (the more Democratic/liberal position) than when pushing toward “oppose” (the more Republican/conservative position). Because people’s starting positions weren’t randomly assigned, this difference might be due to who was easier to persuade, the issues chosen, or model behavior—not just the models themselves.
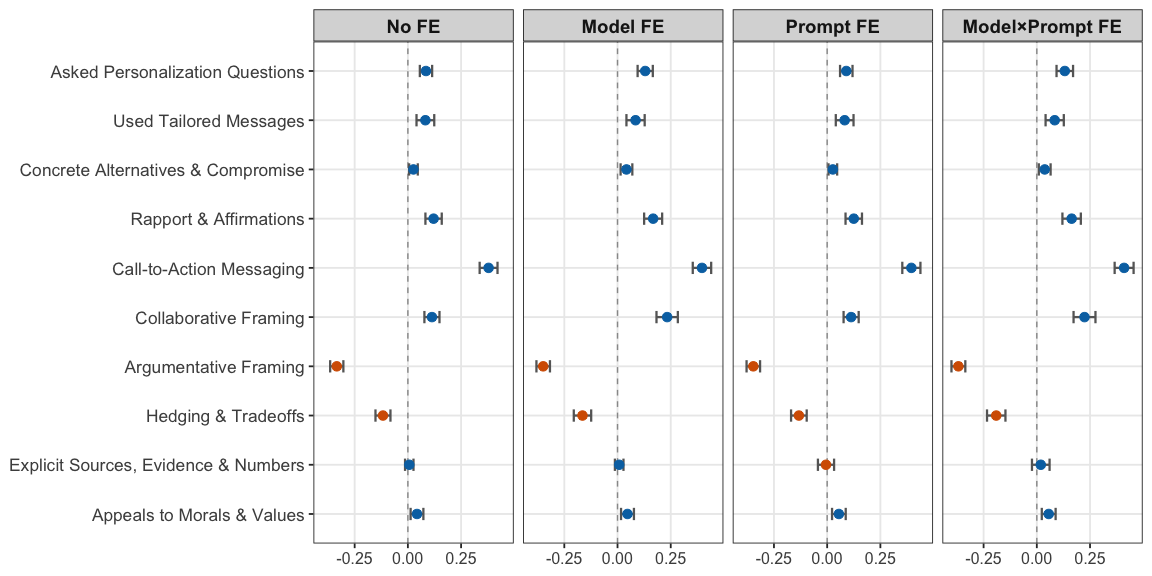
5) Which conversation strategies worked?
From the AI-assisted analysis:
- Strongly positive: “Call-to-action messaging” (e.g., suggesting concrete steps like contacting a representative or signing a petition) was most linked to bigger opinion shifts.
- Not clearly helpful: “Explicit sources and numbers” didn’t show a meaningful positive link—explaining why information prompts weren’t always better.
- Negative: “Argumentative framing” (directly challenging the person) and “hedging/tradeoffs” (showing lots of uncertainty) were linked to weaker persuasion.
Note: These are associations, not guaranteed cause-and-effect.
Why does this matter?
- Scale and speed: AI chatbots can hold convincing conversations with huge numbers of people very quickly. If misused, this could enable mass persuasion campaigns.
- Democratic risks: If powerful AI tools are controlled by bad actors, they could manipulate public opinion, distort debates, or even influence elections.
- Policy and safety: We need better rules, monitoring, and safeguards to reduce these risks while allowing legitimate political speech.
Final thoughts and impact
This paper shows that today’s frontier AI models can be more persuasive than standard campaign ads and that their power varies by brand and by how they are prompted. It also reveals which conversation strategies are tied to bigger opinion shifts. The takeaway is clear: as AI gets smarter, its ability to influence people grows—and society needs plans to manage that influence responsibly.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
The following list distills what remains missing, uncertain, or unexplored in the paper and suggests concrete directions for future research:
- External validity: results are based on Prolific samples in an online survey; generalizability to the broader electorate, offline contexts, and other countries remains untested.
- Human vs. AI benchmarking mismatch: AI treatments were interactive multi-turn text chats while human treatments were 30–60 second videos; effects may reflect modality and exposure dosage rather than inherent AI superiority.
- Missing human benchmark for Minimum Wage: due to a technical failure, the “human” minimum wage condition was imputed from a prior study with a different sample; residual confounding may bias the AI-vs-human comparison.
- Single human ad exemplar: comparisons hinge on one (or very few) human ads; it is unclear whether higher-quality or better-targeted human messages would narrow the AI advantage.
- Exposure dosage not equated: conversations varied in turns and word counts and differed markedly from the brief human ads; the dose–response relationship of persuasion to message length/turns is unknown.
- Immediate, not durable, outcomes: only post-treatment attitudes were measured; the longevity, decay, or backlash of LLM-induced attitude changes is unknown.
- No behavioral endpoints: downstream behaviors (e.g., information seeking, donations, petition-signing, turnout, vote choice) were not measured; attitudinal shifts may not translate into actions.
- Limited issue scope: only two issues (immigration, minimum wage) were tested; it is unclear if results generalize to other salient or identity-laden topics (e.g., abortion, guns, climate).
- Stance asymmetry not causally identified: larger effects when moving toward the policy-supporting (Democratic) position may reflect model bias, participant susceptibility, or issue choice; stance was not randomly assigned among a common pool, preventing causal attribution.
- Participant heterogeneity underexplored: differential susceptibility by partisanship, ideology strength, political knowledge, media consumption, demographics, or psychographics was not systematically analyzed.
- Microtargeting not tested: the persuasive gains from explicit microtargeting using personal data, and the privacy–persuasion trade-off, remain unknown.
- Personalization intensity not manipulated: although models sometimes personalized, the causal effect of varying personalization levels (e.g., none vs light vs heavy) on persuasion was not tested.
- Medium effects unexamined: results come from a Qualtrics chatbox; effectiveness across platforms (messaging apps, social networks), device types, and UI features (typing indicators, avatars, timing) is unknown.
- Disclosure and credibility cues: participants knew they were interacting with an AI chatbot; the effects of disclosure (AI vs human), endorsements, source labels, or provenance signals on persuasion were not evaluated.
- Truthfulness and accuracy: the factual correctness of AI messages was not assessed; interactions between message veracity (or misinformation) and persuasive impact are unknown.
- Multi-modal persuasion absent: only text was tested; the incremental or synergistic effects of voice, images, and video (deepfakes, voice clones) are unmeasured.
- Non-English contexts: effects in other languages and cultural settings are unexplored.
- Model versioning and reproducibility: API settings, system prompts, and sampling parameters (e.g., temperature) were not fully detailed or stress-tested; upgrades may shift results, complicating replication and auditing.
- Open-source models excluded: conclusions may not extend to widely deployable open-source models or fine-tuned local models.
- Narrow prompting space: only “plain” vs “information-based” prompts were compared; other strategies (e.g., narrative transport, identity-based appeals, moral reframing, inoculation, motivational interviewing) were not causally evaluated.
- Strategy analysis is correlational: identified conversational strategies were associated with outcomes, but not randomized; causal effects of specific strategies remain unknown.
- Evaluator bias in strategy coding: GPT-5.x was used to discover and rate strategies, with limited human validation; potential model-family bias and construct validity need stronger, preregistered human-coded audits.
- Strategy discovery scope: emergent strategies were derived from specific model–prompt comparisons and small batches; rare or context-dependent strategies may have been missed.
- Multiple testing and researcher degrees of freedom: numerous model, issue, stance, and strategy comparisons were reported without explicit multiplicity adjustments; the robustness of inferences to correction is uncertain.
- Mechanistic explanations for model ranking: why Claude outperforms GPT/Gemini and Grok is not identified (architecture, safety policies, response style, verbosity, refusal behavior); ablation or controlled generation studies are needed.
- Guardrails and adversarial stress tests: susceptibility to jailbreaks, safety filter bypass, and persuasion using misinformation or unethical tactics was not evaluated.
- Counter-messaging and inoculation: the durability of AI persuasion under fact-checks, inoculation messages, or competing campaign messages is unknown.
- Social amplification and network effects: impacts of AI-generated content when algorithmically amplified or coordinated (flooding campaigns, astroturfing) were not studied.
- Polarization effects: outcomes beyond mean attitude change (e.g., attitude extremity, affective polarization, dehumanization) were not measured.
- Comparative human baselines incomplete: no comparison to high-impact human tactics (live canvassing, phonebanking, peer-to-peer texting), which might rival or exceed AI chat persuasion.
- Cost-effectiveness: cost per persuaded individual for AI vs. human methods (considering API costs, scaling, targeting) was not estimated.
- Election-cycle context: effects may vary with salience, timing, and real-world events; contextual moderation was not examined.
- Spillovers and cross-issue priming: whether persuasion on one issue shifts views on adjacent issues or party evaluations is unknown.
- Regulatory and mitigation efficacy: the paper identifies risks but does not experimentally test mitigation levers (rate limits, provenance, disclosures, content filters, auditing regimes) or their impact on both persuasion and user welfare.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with today’s models and infrastructure, organized by sector and noting key dependencies.
- Persuasion risk audits for LLM products (Software/Platforms, AI developers)
- What: Integrate a “Persuasion Risk Audit” into model evaluations, comparing model–prompt combinations and flagging political contexts where persuasive impact exceeds pre-set thresholds.
- Tools/workflows: Risk scoring pipelines using the paper’s cross-model benchmarking approach; prompt A/B harness; dashboards tracking model rankings and prompt interactions.
- Dependencies/assumptions: Requires access to model APIs and logs; effects measured on Prolific in two U.S. issues may not fully generalize cross-issue/country; re-benchmarking needed as models iterate.
- Model selection as a policy knob in political contexts (Software/Platforms, Compliance)
- What: Choose less persuasive models (e.g., lower-ranked in paper) or restrict prompt types for politically sensitive features.
- Tools/workflows: Model routing rules keyed to topic detection; “civic-safe mode” that falls back to less persuasive models or neutral templates.
- Dependencies/assumptions: Topic classification must be reliable; model rankings may shift; legal and product policy alignment needed.
- Prompt governance tailored by model (Software/Platforms, AdTech)
- What: Establish model-specific prompt policies given the paper’s finding that “information prompts” help some models (Claude/Grok) but harm others (GPT).
- Tools/workflows: “Model–Prompt Compatibility Scanner” that tests prompt templates against persuasion benchmarks before deployment.
- Dependencies/assumptions: Continuous testing required as models and prompts evolve; risk of overfitting to benchmarked issues.
- Strategy-aware safety filters (Software/Platforms, Security)
- What: Detect and throttle conversations exhibiting high-risk persuasive strategies (e.g., “Call-to-Action Messaging”), especially around political topics.
- Tools/workflows: Classifiers trained via the paper’s LLM-assisted strategy ratings to monitor “call to action,” “argumentative framing,” and hedging patterns.
- Dependencies/assumptions: False positives risk; needs transparency and appeal mechanisms; may implicate free-speech concerns.
- Election-period assistant modes (Platforms, Policy/Compliance)
- What: Activate time-bound stricter policies (e.g., reduce/neutralize political persuasion, add disclosures, rate limit) during defined election windows.
- Tools/workflows: Feature flags for “election mode,” automatic labeling (“AI-generated political content”), consent gates.
- Dependencies/assumptions: Clear legal definitions of “political content”; coordination with regulators; jurisdiction-specific requirements.
- Conversational analysis pipeline for research and QA (Academia, QA teams)
- What: Use the paper’s two-phase LLM-assisted pipeline to discover emergent strategies and rate conversations at scale without a fixed taxonomy.
- Tools/workflows: Small-batch qualitative discovery (e.g., GPT-5-mini), followed by quantitative ratings (e.g., GPT-5) on large logs; human spot checks.
- Dependencies/assumptions: LLM raters can be biased; requires calibration and periodic human validation; compute costs.
- Campaign and advocacy compliance testing (Civic tech, Political consulting—with strict ethics/legal compliance)
- What: Internally validate that content complies with platform and legal constraints; avoid high-risk strategies (e.g., aggressive argumentative framing) shown to correlate with backlash.
- Tools/workflows: Pre-flight content checks using the strategy analyzer; prompt libraries tuned for neutrality or supportive information where allowed.
- Dependencies/assumptions: Must adhere to campaign finance and election laws; findings from two issues may not generalize to all topics.
- Consumer protection: phishing/scam detection using persuasion signatures (Security, Email/Chat platforms, Finance)
- What: Apply the strategy detectors to flag high-risk “call-to-action” and tailored persuasion in phishing/scam messages.
- Tools/workflows: Inbound message scoring for urgency and personalization patterns; layered with URL/domain reputation.
- Dependencies/assumptions: Political persuasion signals overlap with benign messages; tuning needed to minimize false positives.
- Content moderation and labeling on social media (Social media, AdTech)
- What: Detect mass deployment of persuasive AI content and label or downrank coordinated campaigns.
- Tools/workflows: Cross-post clustering + strategy signature detection; public ad libraries listing AI-generated political content.
- Dependencies/assumptions: Access to content/meta-data; privacy and speech considerations; adversarial adaptation by bad actors.
- Digital literacy tools for users (Daily life, Education)
- What: Browser extensions or assistant features that highlight persuasive tactics in real time and summarize arguments in neutral language.
- Tools/workflows: On-page detectors for “call to action,” moral-value appeals, and argumentative framing; “skeptic mode” summarization.
- Dependencies/assumptions: UX must avoid alert fatigue; multilingual adaptation; on-device inference or privacy-preserving APIs.
- Enterprise AI use policies (Enterprise IT/HR/Compliance)
- What: Configure AI copilots to avoid political persuasion in the workplace; block political topics or enforce neutral, information-only responses.
- Tools/workflows: Topic filters + fallback prompts; logs for audit; employee notifications and training.
- Dependencies/assumptions: Accurate topic detection; cultural and legal differences across regions; periodic audits.
- Public-health and civic messaging pilots (Public sector, NGOs)
- What: In ethical, non-political contexts, test which strategies (e.g., clear calls to action) increase pro-social engagement (e.g., vaccination appointments, civic participation).
- Tools/workflows: A/B trials with strategy tagging; pre-registration and IRB oversight; outcome tracking (clicks/appointments).
- Dependencies/assumptions: Political findings may not transfer fully; safeguard against manipulation; ensure factual integrity and consent.
Long-Term Applications
These use cases require further research, scaling, policy development, or multi-stakeholder coordination before broad deployment.
- Standardized persuasion benchmarks and certification (Policy, Standards bodies, AI labs)
- What: A public “Persuasion Risk Leaderboard” with third-party audits across issues, demographics, and languages; certification for low-risk modes.
- Tools/workflows: Shared datasets; blind external evaluations; incident reporting channels.
- Dependencies/assumptions: Governance and funding for independent evaluators; buy-in from model providers.
- Dynamic model training to minimize political persuasion (AI developers, Safety)
- What: Train or fine-tune models to reduce persuasive strength in political domains while retaining general helpfulness (e.g., via RL from human/constitutional feedback).
- Tools/workflows: Domain detectors + loss shaping; adversarial red teaming focused on political persuasion strategies.
- Dependencies/assumptions: Trade-offs between helpfulness and safety; drift across model updates; requires new training data.
- Real-time cross-platform monitoring for coordinated mass persuasion (Platforms, Regulators)
- What: Joint systems to detect and respond to large-scale AI-driven persuasion operations (e.g., foreign interference).
- Tools/workflows: Federated signals exchange; standardized risk scores; shared takedown/labeling protocols.
- Dependencies/assumptions: Legal frameworks for data sharing; international cooperation; robust privacy safeguards.
- Causal strategy experimentation at scale (Academia, Labs, Platforms)
- What: Randomly assign persuasive strategies in controlled studies to establish causal effects beyond correlational findings.
- Tools/workflows: Registered trials; multi-issue, multi-country panels; behavioral outcomes (donations, turnout) not just attitudes.
- Dependencies/assumptions: IRB/ethics approvals; recruitment diversity; higher costs and longer timelines.
- Personalized counter-persuasion “cognitive immune systems” (Consumer protection, Assistive AI)
- What: User-configurable assistants that anticipate personal persuasion vulnerabilities and proactively inoculate (e.g., prebunking).
- Tools/workflows: Private user profiles; on-device modeling; explanatory feedback and source triangulation.
- Dependencies/assumptions: Strong privacy controls; avoidance of paternalism; evidence that prebunking generalizes.
- Legal and regulatory frameworks for AI political persuasion (Policy, Election integrity)
- What: Statutes/regulations defining AI political content, disclosure mandates, consent requirements, and election-period restrictions.
- Tools/workflows: Compliance SDKs; transparency APIs; public registries for AI-generated political ads/conversations.
- Dependencies/assumptions: Balancing free-speech rights; jurisdictional variation; enforcement capacity.
- Workforce and civic education curricula (Education, Public sector)
- What: Courses and certifications on AI persuasion risks, detection, and ethical communication for journalists, public servants, educators, and students.
- Tools/workflows: Open curricula built on the paper’s strategy taxonomy and benchmarking methods; simulation labs.
- Dependencies/assumptions: Curriculum updates as models evolve; teacher training; assessment frameworks.
- Polarization and downstream behavior monitoring (Academia, Platforms, Policy)
- What: Extend benchmarks to measure not just attitude shifts but polarization and behavioral outcomes over time.
- Tools/workflows: Longitudinal panels; multi-issue batteries; platform-integrated opt-in measurement.
- Dependencies/assumptions: Attrition and consent management; complex causal inference; mixed-methods needs.
- Generalized persuasion-risk scanners for messaging ecosystems (Security, Telecom)
- What: Ecosystem-level tools that score persuasion intensity across email, SMS, chat for consumer protection and compliance.
- Tools/workflows: Privacy-preserving, on-device or federated detection; explainable risk flags.
- Dependencies/assumptions: Vendor cooperation; regulatory allowances; minimizing over-blocking.
- Multilingual and cross-cultural adaptation (Global platforms, NGOs)
- What: Replicate and adapt the benchmarking framework to multiple languages and cultures to avoid region-specific blind spots.
- Tools/workflows: Local partnerships; culturally sensitive strategy labels; regional evaluation hubs.
- Dependencies/assumptions: Translation quality; cultural variation in strategy efficacy; equitable funding.
- Safe civic conversational agents (Civic tech, Public sector)
- What: Government- or NGO-backed assistants that provide neutral civic information while minimizing persuasive strategies, especially calls to action, in political contexts.
- Tools/workflows: Certified low-persuasion models; transparent prompts; appeals and auditing interfaces.
- Dependencies/assumptions: Trust and adoption; procurement standards; continuous evaluation.
Notes on general assumptions across applications:
- The paper’s effects were measured on two issues with Prolific participants and immediate post-treatment attitudes; real-world and behavioral effects may differ.
- Model rankings and prompt interactions are time-sensitive; frontier capability jumps necessitate continuous re-benchmarking.
- LLM-assisted strategy ratings are useful but can reflect rater-model bias; human validation and triangulation are recommended.
- Ethical, legal, and speech considerations are central in political contexts; deployments should undergo legal review and independent oversight.
Glossary
Claude models: Frontier LLMs developed by Anthropic, considered to be highly persuasive in political contexts. Example: "Specifically, Claude models exhibit the highest persuasiveness, while Grok exhibits the lowest."
Dataset: A collection or set of data. In the context of AI experiments, it refers to the structured information used for training or evaluation purposes. Example: "We used the most advanced models available at the time of the survey."
GPT (Generative Pre-trained Transformer): A type of LLM developed by OpenAI, known for its advanced reasoning and intelligence capabilities. Example: "OpenAI's GPT-5, launched in August 2025, which OpenAI claimed has 'PhD-level intelligence' in various domains."
Grok: A model developed by xAI that reportedly had lower performance compared to other models in persuasion tasks. Example: "Claude Sonnet 4 produced the strongest persuasive effects...while Grok 4 exhibited the weakest effects."
Humanity's Last Exam: A hypothetical benchmark designed to assess AI models' cross-domain reasoning and knowledge. Example: "Released in July 2025, xAI’s Grok 4 achieved an accuracy of 50.7% on Humanity's Last Exam."
LLMs: Advanced artificial intelligence systems capable of understanding and generating human-like text, used in persuasion and interactive conversations. Example: "Concerns persist regarding the capacity of LLMs to sway political views."
Meta-analysis: A statistical method that combines the results of multiple scientific studies. Example: "To estimate the overall persuasion effect while accounting for heterogeneity across different issues and stances, we pooled the estimates using a random-effects meta-analysis model."
OpenAI: A research organization focused on developing artificial intelligence in a manner that benefits all of humanity, known for its GPT models. Example: "OpenAI's GPT-5, launched in August 2025, achieved state-of-the-art performance."
Plain Prompt: A type of prompting strategy in AI where the model is asked to persuade the subject without receiving any additional details or tips. Example: "Plain Prompt: The chatbot was asked to persuade the subject, without receiving any additional details or tips on how to persuade."
Prolific: An online platform for recruiting participants for research studies, used in the experiments described in the paper. Example: "Participants (N=12,988) recruited from Prolific were asked to complete a survey on the Qualtrics platform."
Qualtrics: A widely-used software platform for conducting surveys and experiments, mentioned in the context of participant assignment to different conditions. Example: "Participants engaged in interactive, text-based conversations with an AI chatbot that presented pro-immigration arguments."
Random-effects model: A statistical tool used to analyze the variation across different studies or experiments, accounting for heterogeneity. Example: "We pooled the two persuasion stances using the same random-effects meta-analysis."
Simulation: The imitation of a real-world process or system over time, used to study the performance and variations of AI models. Example: "Shortly after we launched Study 1, a new wave of frontier models was released."
Tradeoffs: The balance or compromise between competing factors or strategies, often acknowledged in AI conversation analysis as a persuasive element. Example: "The negative associations are plausible...whereas 'Hedging {paper_content} Tradeoffs' reflects uncertainty in the model's argument."
xAI: An organization mentioned as a developer of the Grok model, focusing on artificial intelligence technology. Example: "Released in July 2025, xAI’s Grok 4 achieved an accuracy of 50.7% on Humanity's Last Exam."
Collections
Sign up for free to add this paper to one or more collections.