Reviving ConvNeXt for Efficient Convolutional Diffusion Models
Abstract: Recent diffusion models increasingly favor Transformer backbones, motivated by the remarkable scalability of fully attentional architectures. Yet the locality bias, parameter efficiency, and hardware friendliness--the attributes that established ConvNets as the efficient vision backbone--have seen limited exploration in modern generative modeling. Here we introduce the fully convolutional diffusion model (FCDM), a model having a backbone similar to ConvNeXt, but designed for conditional diffusion modeling. We find that using only 50% of the FLOPs of DiT-XL/2, FCDM-XL achieves competitive performance with 7$\times$ and 7.5$\times$ fewer training steps at 256$\times$256 and 512$\times$512 resolutions, respectively. Remarkably, FCDM-XL can be trained on a 4-GPU system, highlighting the exceptional training efficiency of our architecture. Our results demonstrate that modern convolutional designs provide a competitive and highly efficient alternative for scaling diffusion models, reviving ConvNeXt as a simple yet powerful building block for efficient generative modeling.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Reviving ConvNeXt for Efficient Convolutional Diffusion Models”
Overview: What is this paper about?
This paper is about making high-quality image-generating AI models faster and easier to train. The authors show that a type of neural network called a ConvNet (short for “convolutional network”) can be used to build efficient diffusion models that create images, rivaling models based on Transformers. Their new model is called FCDM (Fully Convolutional Diffusion Model), and it brings back a modern ConvNet design named ConvNeXt for image generation.
Goals: What questions did the researchers ask?
The researchers wanted to find out:
- Can a model that only uses convolutions (not Transformers) generate images just as well?
- Can such a model be trained with less computing power, fewer training steps, and on fewer GPUs?
- Can we design a simple, scalable architecture with only a couple of “knobs” to tune (so it’s easy to grow the model bigger or smaller)?
Methods: How did they build and test the model?
To understand the approach, here are a few simple ideas:
- Diffusion models: Imagine starting with a noisy picture and “cleaning” it bit by bit until it becomes a clear, realistic image. That’s how diffusion models generate pictures.
- Convolutions: Think of a sliding window or small magnifying glass moving over parts of an image to understand local details. ConvNets use this idea to process images efficiently.
- Transformers: These are powerful models that look at relationships across the whole image at once, but they often need lots of computing power.
What the authors did:
- They took ConvNeXt (a modern ConvNet design) and adapted it for image generation with diffusion. This included:
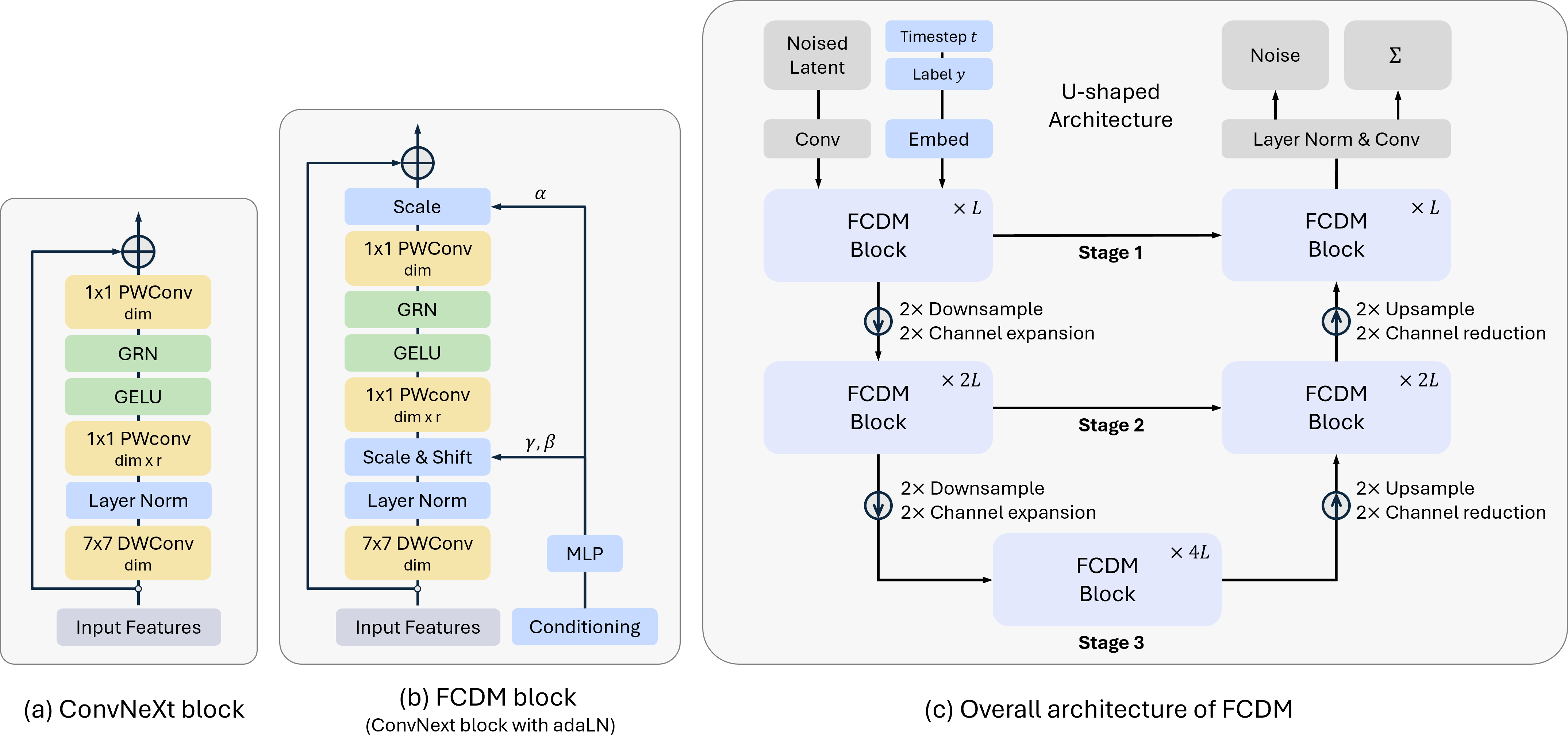
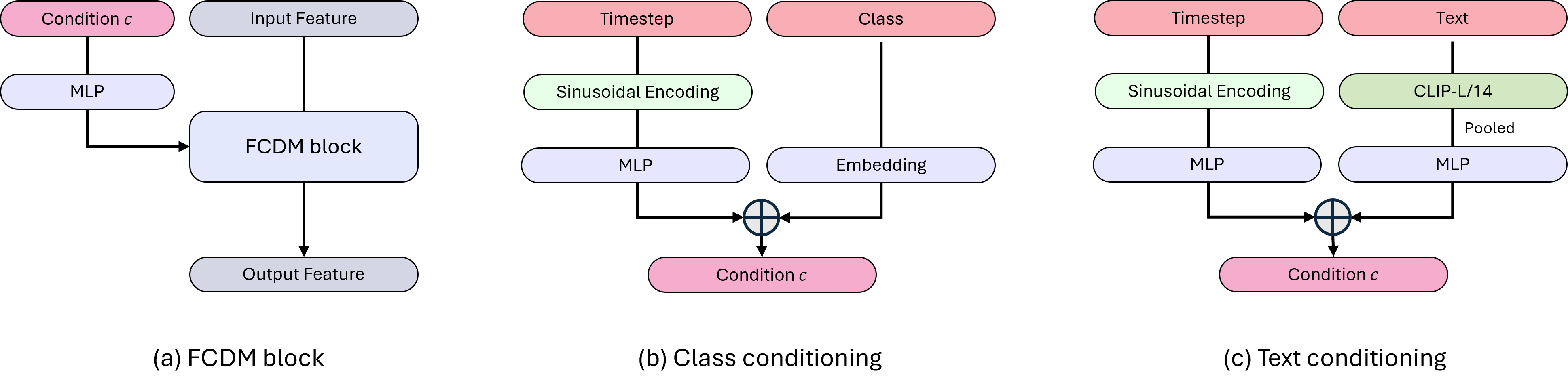
- Adding “conditioning”: extra instructions (like the class label and the current diffusion timestep) are injected so the model knows what to draw and how far along the “cleaning” process it is. They do this using a technique called Adaptive LayerNorm (AdaLN), which gently adjusts features based on these instructions.
- Using big, efficient filters: A 7×7 depthwise convolution for local details, followed by small 1×1 pointwise convolutions to mix channels (like rearranging color/feature combinations).
- Reducing redundancy with GRN (Global Response Normalization): This is a lightweight way to keep feature channels diverse so the model doesn’t waste effort repeating similar information.
- A U-shaped architecture: Picture a “down-and-up” path. The model first shrinks the image to capture broad context (downsampling), then expands it back to full size (upsampling), with “skip connections” that carry fine details forward like a bridge between matching layers.
- Easy scaling: The model is controlled by only two tuning knobs:
- L: number of blocks (how many layers)
- C: number of channels (how wide each layer is)
- At each step where the image is downscaled by 2×, both L and C are doubled. This makes it simple to build small, medium, large, or extra-large versions.
- Fair testing: They followed the same training setup used for popular Transformer-based diffusion models (like DiT), trained on the ImageNet dataset at 256×256 and 512×512 resolutions, and compared results using common metrics.
To help with terms, here’s a quick guide:
- FLOPs: A measure of how much computation a model uses (lower is more efficient).
- Throughput: How many training steps per second (higher is faster).
- FID (Fréchet Inception Distance): A score for image quality and realism (lower is better).
Results: What did they find, and why does it matter?
The main results show the new FCDM is highly efficient while generating high-quality images:
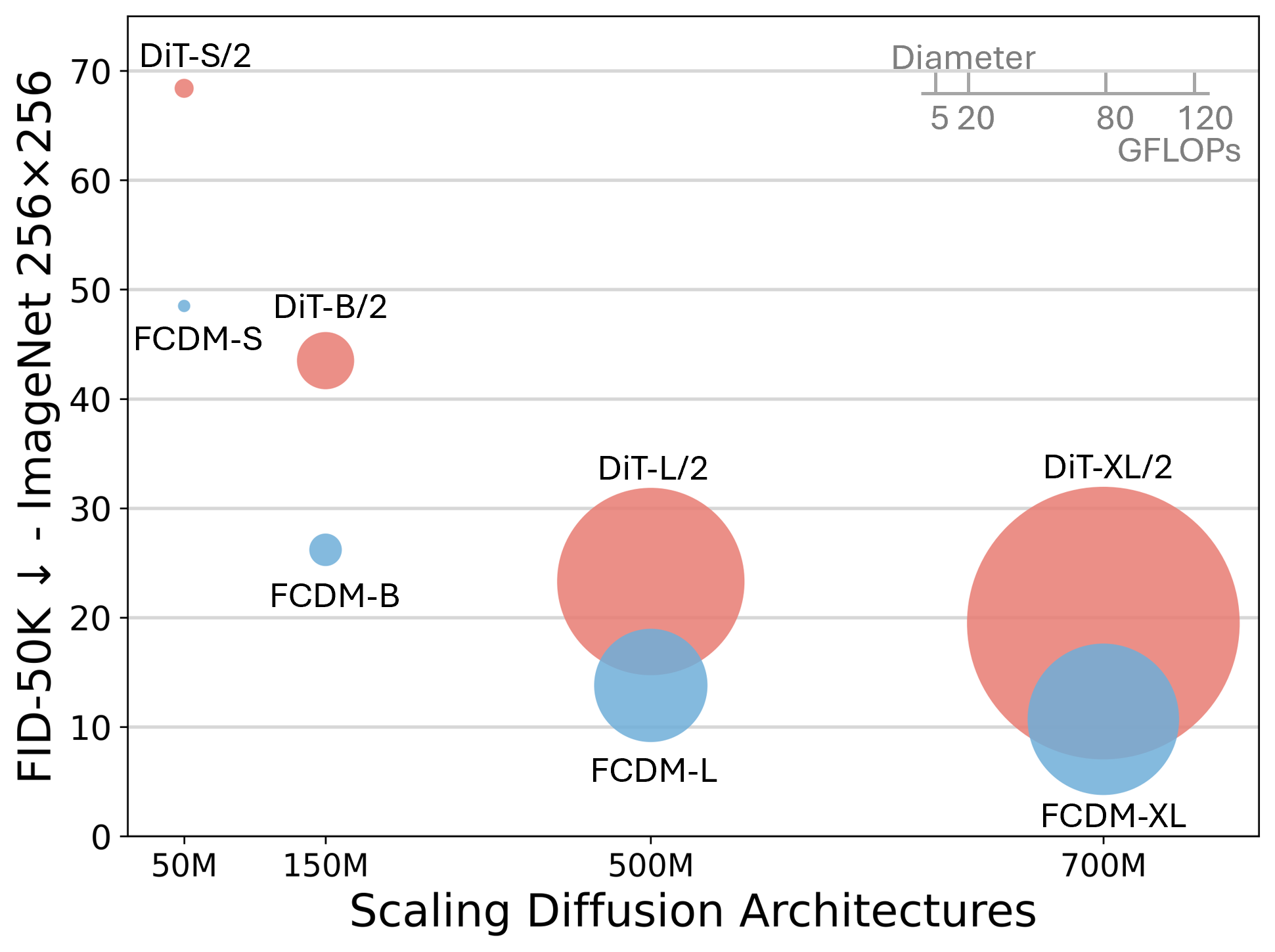
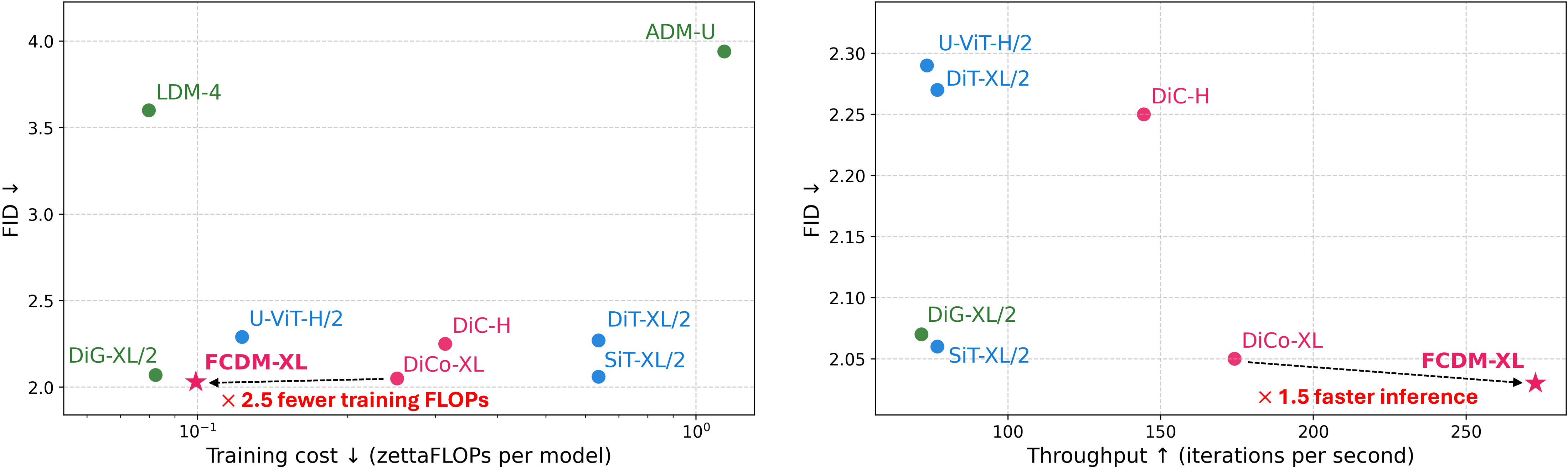
- Less compute, faster training: Compared to a strong Transformer model (DiT-XL/2), FCDM-XL uses about 50% fewer FLOPs and reaches equally good or better quality with far fewer training steps:
- At 256×256 resolution: about 7× fewer training steps.
- At 512×512 resolution: about 7.5× fewer training steps.
- Strong performance and speed: FCDM consistently gets better or comparable FID scores and higher throughput across sizes (Small, Base, Large, XL).
- Easier to train: The biggest version (FCDM-XL) can be trained on a 4-GPU setup, which is much more accessible than huge GPU clusters.
- Simple design wins: Ablation studies (tests where they swap parts in/out) show:
- Larger kernels (like 7×7) help capture broader context and improve quality.
- GRN boosts channel diversity more efficiently than heavier attention modules.
- The inverted bottleneck (expand channels inside the block) is important for performance.
- Adding certain extra modules from other models actually made things worse, so the simpler FCDM block is both faster and better.
Why it matters:
- Training fast with less compute means lower costs and energy use.
- It makes cutting-edge image generation more accessible to smaller labs, companies, and hobbyists.
- It challenges the common idea that “bigger Transformers” are always the way to go.
Impact: What does this mean for the future?
This work suggests that modern ConvNets are still powerful for generative modeling and can be a smart alternative to Transformers when efficiency matters. Possible implications include:
- More sustainable AI: Lower compute and energy costs help the environment and broaden access.
- Wider adoption: Smaller teams can train strong models without massive hardware.
- New directions: Combining FCDM with improved training methods or scaling it further could push performance even higher. It could also be adapted for text-to-image tasks and other media types.
In short, the paper shows that bringing back ConvNeXt for diffusion models can make image generation faster, cheaper, and still high quality—proving that convolutional designs are far from obsolete.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper, intended to guide future research.
- Limited evaluation scope (dataset/task): Results are shown only for class-conditional ImageNet at 256×256 and 512×512; generalization to other datasets (e.g., LAION, COCO), domains (medical/satellite), and tasks (unconditional generation, inpainting, super-resolution, editing) is untested.
- Multimodal conditioning: The backbone is evaluated primarily with class/time conditioning via AdaLN; it is unclear how well FCDM integrates text conditioning (e.g., CLIP/T5) with spatial cross-attention, and how it scales to long prompts or complex compositional queries.
- Latent-space dependency: FCDM is trained in VAE latent space, but the encoder/decoder choice and configuration are not specified in the main text; the sensitivity of performance/efficiency to different autoencoders (capacity, compression ratio, perceptual loss) is unknown.
- Pixel-space applicability: It is unclear whether the reported efficiency and convergence advantages hold for pixel-space diffusion (where long-range dependencies and receptive field demands are stronger).
- High-resolution scaling (>512): The limits of convolutional locality for 1024+ resolutions (global coherence, fine details) are not evaluated; questions remain about whether large/dilated kernels or hybrid attention are needed at ultra-high resolutions.
- Long-range dependency modeling: Beyond 7×7 depthwise convolutions, the paper does not test dilations, large-kernel conv variants, or selective/global attention add-ons; the trade-offs for capturing global structure remain underexplored.
- Training objective/solver compatibility: FCDM is validated with ADM-style DDPM training and 250-step sampling; its performance with alternative objectives and solvers (EDM-2, flow matching, rectified flows, consistency training, score distillation, few-step distillation) is unknown.
- Inference-time efficiency: Throughput is reported in training iterations/sec and FLOPs, but not as end-to-end generation latency per image for typical sampler settings (with/without guidance); speed-quality trade-offs (vs steps or solver choice) are not quantified.
- Guidance behavior: The effect of classifier-free guidance scale on FID/IS/coverage is not systematically explored; 256 uses guidance whereas 512’s main comparisons use no guidance, complicating cross-setting conclusions.
- Comparison fairness to optimized Transformers: The baseline DiT may not use more advanced attention kernels/architectures (e.g., FlashAttention-2, NATT, gated linear attention); how much these optimizations shrink the FCDM advantage is not assessed.
- Compute and energy accounting: FLOPs are reported, but wall-clock training time, energy consumption, and memory footprint (train/infer) across hardware (A100, consumer GPUs, TPUs, CPUs) are not systematically benchmarked.
- Data efficiency and scaling laws: Claims of “Easy Scaling” (two hyperparameters L and C) lack a formal compute–data–performance scaling analysis; data efficiency in low-data regimes and optimal compute allocation (depth vs width vs resolution) remain open.
- Robustness and generalization: OOD robustness, distribution shift, adversarial sensitivity, and compositional generalization are not evaluated; no human preference or aesthetic quality assessments are provided.
- Ablation depth and stability: Key ablations run only for 200K iterations; whether conclusions persist at longer training (≥1M steps) is unknown; training stability at extreme depths/widths (e.g., gradient pathology, normalization dynamics) is not analyzed.
- GRN vs CCA analysis: The paper shows GRN reduces channel redundancy visually, but lacks quantitative diagnostics (e.g., channel utilization metrics, mutual information, effective rank) and sensitivity to GRN hyperparameters.
- Architecture search space: The U-shaped design doubles L and C at each downsample by construction; alternatives (stage-wise L, constant C, bottleneck placements, skip connection patterns, stride strategies) are not examined beyond brief ablations.
- Conditioning design variants: Only AdaLN with zero-initialized alpha is tested; alternatives (FiLM, SPADE-like spatial modulation, per-block vs per-stage conditioning, RMSNorm/GroupNorm, pre/post-norm variants) are not evaluated.
- Noise schedules and parameterizations: Only ADM’s linear schedule and covariance parameterization are used; the impact of modern schedules (cosine, EDM) and parameterizations (v-prediction, epsilon vs x0) on FCDM’s efficiency/quality is unexplored.
- Evaluation metrics: The study focuses on FID/IS and precision/recall; broader metrics (CLIP score/semantic alignment, diversity measures, memorization/nearest-neighbor analyses, human studies) are missing.
- Few-step/distilled models: Whether FCDM distills effectively to few-step samplers (e.g., progressive distillation, consistency/rectified-flow distillation) and how its conv structure affects distillation stability is unknown.
- Memory–batch size interactions: The observed efficiency on 4×4090 GPUs is promising, but the relationship between batch size, gradient checkpointing, activation recomputation, and final quality is not characterized.
- Fair tuning across backbones: Hyperparameters (LR, weight decay, EMA, augmentations) are held DiT-like; whether FCDM (or DiT) benefits from backbone-specific tuning (e.g., data augmentation policies for ConvNets) is not examined.
- Extension to video, 3D, and audio: It is unclear whether the reported efficiency advantages translate to spatiotemporal (video diffusion), volumetric (3D), or waveform/spectrogram (audio) generative settings.
- Failure mode analysis: The paper lacks qualitative/quantitative analysis of failure cases (mode collapse pockets, texture bias, global structure errors), making it hard to target architectural improvements.
- Reproducibility specifics: Critical implementation details (VAE architecture, latent scaling, exact tokenizer/embedding configs for any text experiments, evaluation seeds/scripts) are not fully specified in the main text; standardized FLOPs/throughput reporting protocols would aid fair comparison.
Practical Applications
Below is a concise analysis of practical applications enabled by the paper’s core contributions: a fully convolutional diffusion backbone (FCDM) that delivers DiT-level image generation quality with roughly 50% of the FLOPs, 7–7.5× fewer training steps to reach competitive FID, simplified scaling with only two hyperparameters, and strong throughput/memory efficiency (trainable on 4 consumer GPUs).
Immediate Applications
These applications can be deployed now with modest adaptation, using the released PyTorch implementation and standard latent-diffusion tooling.
- Cost-efficient class-conditional image generation at scale
- Sectors: software, media/entertainment, advertising, e-commerce
- Tools/products/workflows: swap DiT/U-ViT backbones with FCDM in latent-diffusion pipelines for batch generation of 256–512 px images (e.g., catalog imagery, background variations, style variants); deploy FCDM-XL for best throughput at high resolution
- Assumptions/dependencies: availability of a high-quality VAE/latent space; optimized depthwise convolution kernels on target GPUs; quality targets acceptable for class-conditional (not text-to-image) use; 50K–250-step sampling budgets match latency constraints
- Lower-cost synthetic data generation for training discriminative models
- Sectors: software, robotics, manufacturing, retail
- Tools/products/workflows: use FCDM to balance underrepresented classes, perform domain randomization, and augment long-tail categories; integrate into data curation pipelines to refresh synthetic sets frequently
- Assumptions/dependencies: class labels aligned with target taxonomy; domain shift controlled (may require fine-tuning on in-domain data); governance for synthetic data usage
- High-throughput 512×512 batch image generation for campaigns and A/B testing
- Sectors: advertising tech, marketing analytics
- Tools/products/workflows: nightly generation jobs that exploit FCDM’s smaller throughput drop at 512 px (≈2× vs. ≈4× for DiT); rapid creative variant exploration under fixed compute budgets
- Assumptions/dependencies: acceptable latency/quality trade-offs; class-conditional prompts mapped to brand taxonomies
- Rapid prototyping and model scaling with minimal hyperparameter search
- Sectors: software, academia, startups
- Tools/products/workflows: leverage the “Easy Scaling Law” (only channels C and blocks L) for quick sweeps; AutoML or grid searches over {C,L} to meet cost/quality targets under strict GPU-hour budgets
- Assumptions/dependencies: target tasks are well-served by latent diffusion; experiment management and early-stopping criteria in place
- Academic accessibility and teaching
- Sectors: academia, research labs
- Tools/products/workflows: run state-of-the-art generative modeling experiments on 4× RTX 4090 or a single A100 40GB; adopt FCDM as an efficient baseline for coursework and reproducibility studies
- Assumptions/dependencies: access to ImageNet-like data (or institutional datasets); adherence to dataset licensing
- On-premise image generation for privacy-sensitive environments
- Sectors: finance, government, enterprise IT
- Tools/products/workflows: deploy class-conditional generative services behind the firewall with lower capex/opex; use FCDM’s memory/compute efficiency to fit existing on-prem GPU nodes
- Assumptions/dependencies: models trained on de-identified data; internal label ontologies available; security policies permit on-prem training/inference
- Fine-tuning and domain adaptation with reduced compute
- Sectors: manufacturing, retail, creative studios
- Tools/products/workflows: swap-in FCDM backbones for faster LoRA/fine-tuning cycles on domain-specific datasets (e.g., new product lines, seasonal styles), shortening iteration loops
- Assumptions/dependencies: availability of labeled in-domain data; lightweight conditioning aligned with labels or metadata
- Green AI and cost governance in MLOps
- Sectors: cloud platforms, enterprise MLOps, sustainability offices
- Tools/products/workflows: codify FCDM as the default “efficient backbone” in internal model registries; integrate energy/cost dashboards highlighting FLOP and throughput savings; set procurement guidelines favoring convolutional backbones when quality is comparable
- Assumptions/dependencies: organizational mandate for carbon/cost reporting; standardization of metering FLOPs and energy
Long-Term Applications
These require additional research, scaling, or integration (e.g., new conditioning, new modalities, or specialized hardware).
- Production-grade text-to-image with fully convolutional backbones
- Sectors: media, design tools, social platforms
- Tools/products/workflows: integrate CLIP/text encoders and multimodal conditioning into FCDM; build FCDM-based SDXL/DiT replacements for large content platforms
- Assumptions/dependencies: conditioning stacks and training recipes adapted beyond ImageNet; validation on human preference metrics and safety filters
- On-device or near-edge generative imaging
- Sectors: mobile, AR/VR, embedded vision
- Tools/products/workflows: deploy compact FCDM variants for photo editing, generative fill, and style transfer on mobiles or edge servers; exploit conv-friendliness for acceleration on NPUs/DSPs
- Assumptions/dependencies: robust kernel support for depthwise convolutions on mobile NPUs; distilled/quantized models; careful thermal/energy constraints
- Video and spatiotemporal diffusion with convolutional U-shaped designs
- Sectors: film/animation, gaming, simulation, telepresence
- Tools/products/workflows: extend FCDM to 2D+time or 3D convolutions for video generation, temporal super-resolution, or motion-conditioned synthesis
- Assumptions/dependencies: scalable temporal conditioning, memory optimizations, and datasets; evaluation beyond image FID (e.g., FVD)
- Generative modeling in healthcare and scientific imaging under constrained compute
- Sectors: healthcare, life sciences, microscopy, remote sensing
- Tools/products/workflows: hospital-grade augmentation, denoising, reconstruction using FCDM backbones trainable on modest on-prem clusters; federated or privacy-preserving training
- Assumptions/dependencies: domain-specific VAEs or pixel-space training; clinical validation and regulatory approvals; robust bias/safety evaluation
- Sustainable datacenter inference and specialized accelerators
- Sectors: cloud hardware, semiconductor, hyperscalers
- Tools/products/workflows: co-design inference stacks or ASICs that favor depthwise/pointwise convolutions and GRN; deploy carbon-aware schedulers prioritizing FCDM-like graphs
- Assumptions/dependencies: hardware and compiler support for large-kernel depthwise convs; industry adoption and software ecosystem maturity
- Large-scale synthetic data platforms for robotics and autonomy
- Sectors: robotics, automotive, drones
- Tools/products/workflows: recurrently refresh synthetic corpora for perception models (rare events, extreme conditions) using FCDM-powered generators to lower cost and increase update cadence
- Assumptions/dependencies: strong domain adaptation (style/lighting/physics); validation loops that quantify real-to-sim transfer gains
- Safety, governance, and policy frameworks for democratized generative training
- Sectors: public policy, research funding bodies, compliance
- Tools/products/workflows: policy guidance that recognizes efficiency as a pathway to broader participation; risk controls, red-teaming, and dataset governance that scale with lowered compute barriers
- Assumptions/dependencies: multi-stakeholder standards; monitoring pipelines for content safety and misuse
- Integration with fast-sampling and distillation techniques
- Sectors: all sectors deploying diffusion in production
- Tools/products/workflows: combine FCDM with consistency/distillation methods (e.g., consistency models, progressive distillation) for ultra-low-latency generation
- Assumptions/dependencies: adaptation of distillation objectives to FCDM blocks; maintenance of quality under aggressive sampler reduction
- Tooling ecosystems and SDKs around FCDM
- Sectors: developer platforms, open-source
- Tools/products/workflows: first-class FCDM support in libraries (e.g., Diffusers), recipe cards (training configs, EMA schedules), and architecture search utilities targeting FLOP/latency budgets
- Assumptions/dependencies: community adoption; standardized benchmarks beyond ImageNet (e.g., COCO, LAION subsets) to validate generality
Key cross-cutting assumptions and dependencies:
- Generalization beyond ImageNet class-conditional tasks must be empirically validated for each domain (e.g., text-to-image, medical, video).
- Latent-diffusion quality depends on the VAE; some domains may need pixel-space or domain-specific VAEs.
- Efficiency benefits rely on well-optimized depthwise/pointwise convolution kernels on target hardware; results may vary across GPU/TPU/NPU stacks.
- Quality/latency trade-offs hinge on sampling steps and guidance; product requirements may require additional optimization (distillation, schedulers).
- Data licensing, safety, and bias considerations remain essential when scaling generative pipelines.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from the gradient-based update of Adam to improve generalization. "we use AdamW~\citep{kingma2015adam, loshchilov2019decoupled} with a fixed learning rate of "
- Adaptive LayerNorm (AdaLN): A variant of layer normalization whose scale and shift are modulated by a conditioning signal (e.g., time or class). "we replace LayerNorm with Adaptive LayerNorm (AdaLN), as shown in Figure~\ref{fig:architecture}~(b)."
- Class-conditional: A generative modeling setup where outputs are conditioned on discrete class labels. "We train class-conditional latent FCDMs at and resolutions"
- Classifier-free guidance: A sampling technique that combines conditional and unconditional predictions to control fidelity–diversity trade-offs. "evaluate it with classifier-free guidance~\citep{ho2021classifierfree}."
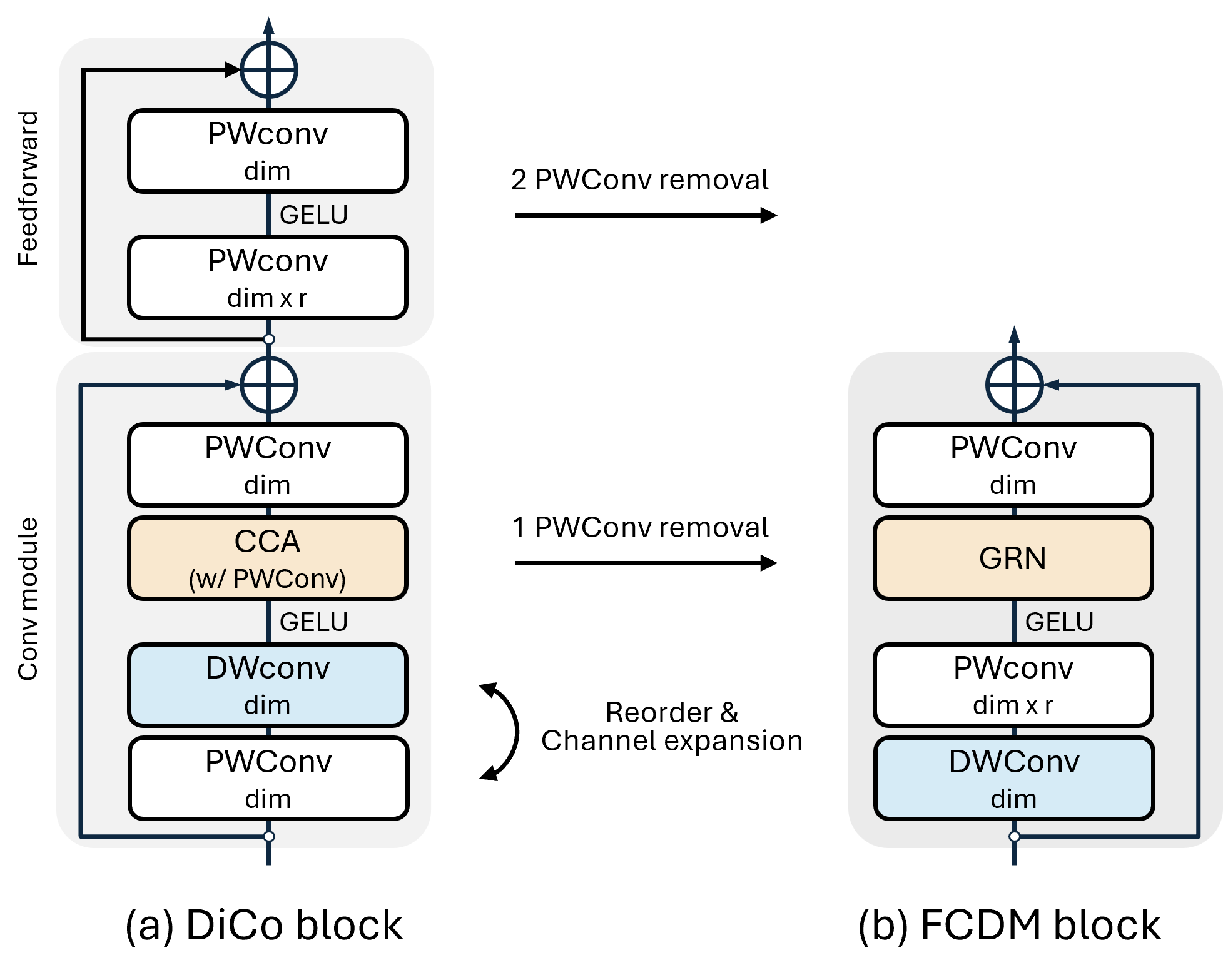
- Compact Channel Attention (CCA): A lightweight attention mechanism intended to diversify and emphasize informative channels. "DiCo introduces the compact channel attention (CCA) mechanism to promote diverse channel activations."
- Conditional injection: The mechanism for injecting conditioning information (e.g., class, timestep) into network layers. "we reassemble ConvNeXt with conditional injection, carefully preserving its core design"
- ConvNeXt: A modern convolutional network architecture that adopts design choices inspired by vision transformers. "We propose a Fully Convolutional Diffusion Model (FCDM), reviving the ConvNeXt architecture~\citep{liu2022convnet, woo2023convnext} and adapting it for conditional diffusion generation."
- Covariance parameterization (): The specific form in which a diffusion model parameterizes the noise covariance it predicts. "ADMâs covariance parameterization , and their timestep/label embedding method."
- DDPM sampling steps: The number of iterative denoising steps used during sampling in denoising diffusion probabilistic models. "We sample 50K images with 250 DDPM sampling steps, and compute the metrics using OpenAIâs official TensorFlow evaluation toolkit~\citep{dhariwal2021diffusion}."
- Depthwise convolution: A convolution that applies a separate spatial filter to each input channel, reducing computation. "the original ConvNeXt~\citep{liu2022convnet, woo2023convnext} block begins with a 77 depthwise convolution, followed by layer normalization"
- Diffusion Transformer (DiT): A fully transformer-based backbone for diffusion models that replaces convolutions with attention blocks. "DiT~\citep{peebles2023scalable} introduced a fully transformer-based diffusion backbone, replacing convolutions with end-to-end transformer blocks."
- Exponential Moving Average (EMA): A running average of model parameters with exponential decay to stabilize training and evaluation. "We use an exponential moving average (EMA) of model weights with a decay factor of 0.9999"
- Feed-forward module: A pointwise channel-mixing block (often two 1×1 convolutions or an MLP) used within larger architectures. "DiCo includes an additional feed-forward module composed of two 11 pointwise convolutions"
- Flow matching: A training objective that aligns learned continuous-time flows with data distributions for generative modeling. "SiT~\citep{ma2024sit} extended DiT to flow matching~\citep{lipman2023flow, liu2023flow}, surpassing DiT across model scales."
- FLOPs: Floating point operations; a measure of computational cost for training or inference. "We find that using only 50 of the FLOPs of DiT-XL/2, FCDM-XL achieves competitive performance"
- Fréchet Inception Distance (FID): A metric that quantifies the distance between real and generated image distributions using features from an Inception network. "Our primary metric is Fréchet Inception Distance (FID)~\citep{heusel2017gans}, following the standard evaluation protocol."
- Global Response Normalization (GRN): A normalization technique that rescales features based on their global responses to reduce channel redundancy. "the Global Response Normalization (GRN)~\citep{woo2023convnext} in between mitigates channel redundancy."
- Gradient checkpointing: A memory-saving technique that recomputes some activations during backpropagation at the cost of extra compute. "trains at approximately 0.9 iterations per second (with gradient checkpointing) at resolution"
- Inception Score (IS): A metric that evaluates image quality and diversity via the predictive confidence and entropy of an Inception classifier. "As secondary metrics, we also report Inception Score (IS)~\citep{salimans2016improved} and Precision/Recall~\citep{kynkaanniemi2019improved}."
- Inverted bottleneck: A block design that first expands the channel dimension (for richer computation) and later reduces it. "our design adopts the inverted bottleneck structure of ConvNeXt, introducing an early channel expansion that allows for richer channel computation within the block."
- Latent space: A compressed representation space in which models can operate more efficiently than in pixel space. "Evaluated methods operate in the latent space."
- Layer normalization (LayerNorm): A normalization method that standardizes activations across the feature dimension within a layer. "followed by layer normalization~\citep{ba2016layer}."
- Linear variance schedule: A schedule where the diffusion noise variance increases linearly across timesteps. "a linear variance schedule ( to )"
- Patch embeddings: The process of converting image patches into token embeddings for transformer-based models. "With the incorporation of patch embeddings in the Vision Transformer (ViT)~\citep{dosovitskiy2021an, liu2021swin}, Transformers~\citep{vaswani2017attention} began to be actively explored in computer vision as well."
- Pointwise convolution: A 1×1 convolution that mixes information across channels without spatial aggregation. "Two subsequent 11 pointwise convolutions handle channel expansion and reduction with a ratio of "
- Precision/Recall: Complementary metrics that assess sample fidelity (precision) and coverage/diversity (recall) in generative modeling. "As secondary metrics, we also report Inception Score (IS)~\citep{salimans2016improved} and Precision/Recall~\citep{kynkaanniemi2019improved}."
- Separable convolutions: Convolutions factorized into depthwise and pointwise operations to reduce computation. "adapted 33 separable convolutions and proposed compact channel attention to mitigate channel redundancy."
- Skip connections: Connections that pass features directly from earlier to later layers to preserve information and ease optimization. "with skip connections bridging the encoder and decoder stages."
- Throughput: The rate of training iterations processed per second; an efficiency indicator. "Even at this resolution, FCDM surpasses models trained for 3M iterations with only 1M iterations and achieves the best efficiency in FLOPs and throughput."
- U-Net: An encoder–decoder CNN architecture with symmetric skip connections widely used in image synthesis and segmentation. "we organize ConvNeXt blocks within a U-Net hierarchy, with skip connections bridging the encoder and decoder stages."
- U-shaped architecture: A symmetric encoder–decoder network topology that integrates global and local features via skips. "arranged in an easily scalable U-shaped architecture."
- Vision Transformer (ViT): A transformer architecture for vision that processes images as sequences of patch tokens. "Vision Transformer (ViT)~\citep{dosovitskiy2021an, liu2021swin}"
Collections
Sign up for free to add this paper to one or more collections.

