- The paper unifies scale-space theory and diffusion probabilistic models by introducing a generalized framework that degrades both resolution and noise.
- It introduces Flexi-UNet, a multi-resolution architecture that dynamically adapts processing blocks to enhance computational efficiency while maintaining image quality.
- Empirical results on ImageNet and CelebA demonstrate significant compute savings and competitive generation quality, validating the framework’s multi-scale capabilities.
Scale Space Diffusion: A Unified Framework for Multi-Scale Generative Modeling
Introduction
"Scale Space Diffusion" (2603.08709) proposes a generalized formulation unifying scale-space theory and the forward process of denoising diffusion probabilistic models (DDPMs). The work presents both a mathematical formalization of this unification and a practical deep learning instantiation leveraging a novel architecture, Flexi-UNet, which enables efficient and effective multi-scale image generation. The paper introduces new theoretical insights, a broadened generative process model, and demonstrates empirical gains in computational efficiency with competitive generation quality.
Theoretical Framework and Motivation
The paper begins by establishing a tight connection between information hierarchies in diffusion timesteps and scale-space (multiresolution) image representations. The authors formalize and quantify the observation that highly noised intermediate diffusion states retain progressively less information, to the point that late-stage states are equivalent in information content to very low-resolution images. This is analytically supported by modeling the proportion of "signal-dominated" pixels as a function of diffusion step t and, independently, the amount of information as a function of decreasing resolution (modeled as proportional to image area). The results show nearly identical information decay in both cases, justifying unifying these representations.
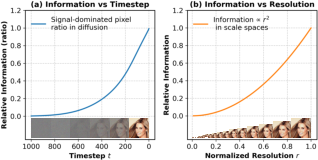
Figure 1: The quantitative relationship between the amount of information in a diffusion state at timestep t (left) and in images at varying scales (right) motivates fusing diffusion and scale-space processes.
Generalized Linear Diffusion Processes
The standard DDPM forward process is extended by replacing the scalar attenuation factor with a general linear operator Mt. In practice, setting Mt as a resolution-changing operator (such as downsampling with blurring) yields a family of forward processes where the data is degraded in resolution as well as by noise. This leads to non-isotropic, resolution-dependent posteriors in the generative process. Crucially, the derivation ensures that the entire probabilistic framework (forward, marginal, and reverse processes) holds under general choices of Mt, as long as the covariance and mean terms are propagated consistently.
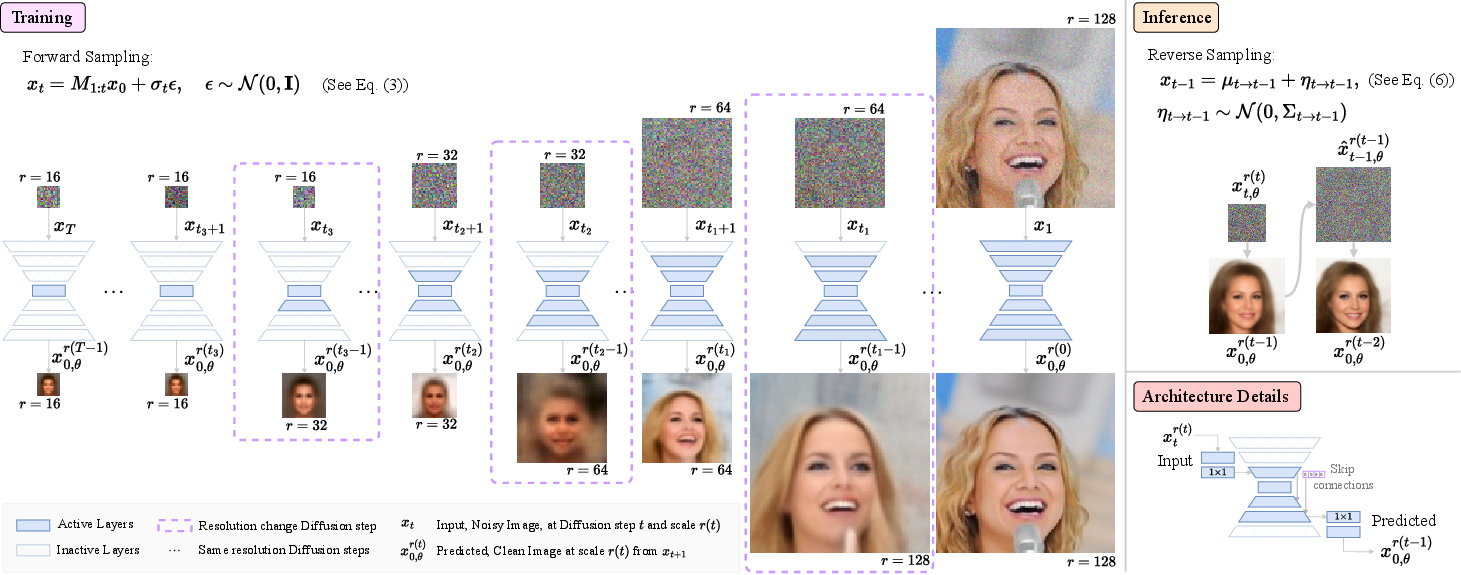
Figure 2: Training overview—noisy images at step t are sampled at resolution r(t), with the model predicting the clean image at the next (higher) resolution using only the necessary computational blocks.
The case where Mt is the identity recovers ordinary DDPM; setting Mt as a spatially blurring operator matches Blurring Diffusion [hoogeboom2022blurring]. The forward and reverse conditionals under this process are derived and practically implemented using implicit linear operators and the Lanczos algorithm for sampling non-isotropic Gaussian noise.
Flexi-UNet: Multi-Resolution Denoising Architecture
To realize this generalized process, the authors propose the Flexi-UNet. Unlike standard UNet-based DDPMs (which operate at a fixed resolution and process all intermediate states identically), Flexi-UNet dynamically selects relevant blocks depending on the current state’s resolution. For resolution-preserving diffusion steps, the architecture acts as a standard symmetric UNet. For upsampling (resolution-increasing) transitions, only a subset of deeper layers is used, with skip connections to inactive encoder blocks zero-filled. One-by-one convolutions handle channel dimension adaptation. This ensures efficient computation and parameter sharing across the multi-scale process.

Figure 3: Generated samples at all intermediate scales during generation—top: ImageNet-64, bottom: CelebA-256, demonstrating scale-consistent progression.
Empirical Results: Efficiency and Quality Tradeoff
Experiments are conducted on unconditional CelebA and ImageNet generation at 642, 1282, and 2562 resolutions, with several variants controlling the number of scales (levels) used. In all cases, the model achieves significant reductions in compute (GFLOPs) and wall-clock training time compared to standard DDPM and Blurring Diffusion baselines. As the number of scales increases (deeper hierarchy), efficiency improves, but with some increase in FID reflecting quality tradeoff. Notably, SSD (6L),2562 reduces training time by over 50% compared to DDPM at only a moderate FID increase. The approach also matches or outperforms blurring models in both compute and quality at low to moderate scale depth.
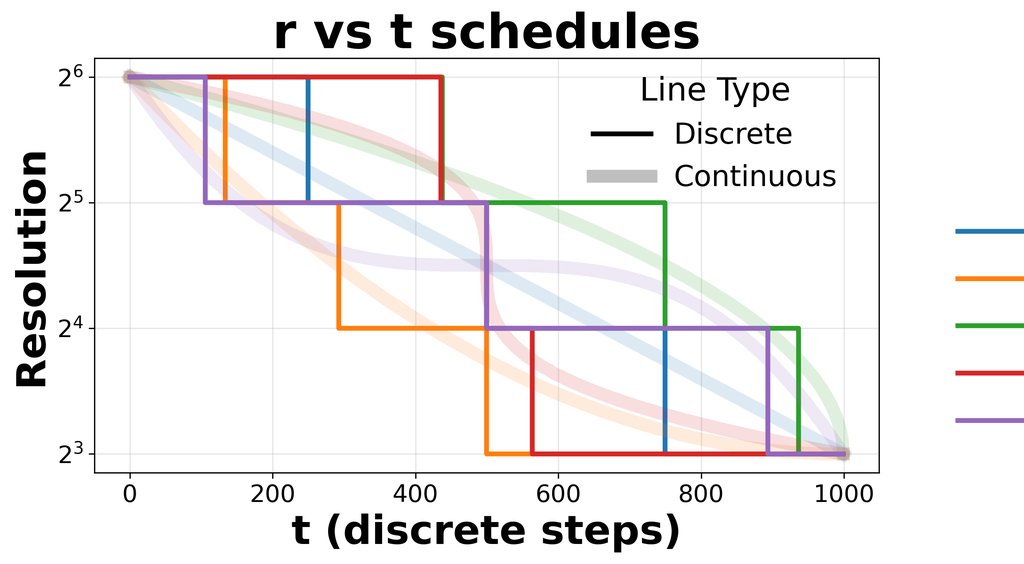
Figure 4: Effects of different resolution schedules r(t) and corresponding FID and training time—faster training is achieved by spending fewer steps at high resolutions, at a cost to sample quality.
Temporal scaling analysis confirms that wall-clock training cost grows more slowly with output resolution in the proposed method than for fixed-resolution DDPM baselines.
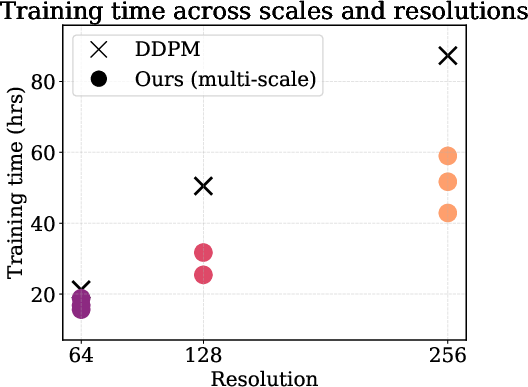
Figure 5: Wall-clock training time as a function of output resolution for various models—Scale Space Diffusion scales considerably more efficiently than alternatives.
Qualitative inspection of generation trajectories reveals highly consistent and plausible images at all intermediate scales, supporting the claim that the proposed generative process maintains semantically-aligned content throughout the multi-scale trajectory.
Analysis and Ablations
The design space of resolution schedules (r(t)) is thoroughly explored. Schedules that bias computation toward lower resolutions yield substantial acceleration but higher FID; more steps at the native resolution optimize sample quality but at greater cost. The Flexi-UNet is compared to naive full-UNet schedules, demonstrating slightly better sample quality and substantial inference savings.
The necessity of sampling noise from the correct non-isotropic posterior covariance is empirically validated: isotropic approximations degrade output images, supporting the theoretical derivation.
Implications for Theory and Practice
From a theoretical perspective, the work demonstrates that diffusion-based generative modeling can be formulated within a general family of scale-space processes. This provides a solid foundation for future probabilistic modeling on adaptive or dynamic spatial representations and could be extended beyond vision to any domain where resolution or scale-hierarchy is intrinsic. The Flexi-UNet framework provides a practical path to compute- and memory-efficient generative models, especially advantageous for high-resolution synthesis, multi-scale tasks, or real-time settings. The formal connection to Gaussian pyramids and classical scale-space opens the door to incorporating decades of multi-scale theory into the modern generative paradigm.
Future Directions
The generality of the unified framework allows straightforward inclusion of other linear or structured degradations and potentially the adaptation of the scheduling function for curriculum learning or adaptation to downstream tasks. The method is also compatible with recent developments in architectures (e.g., attention-based or transformer-based models) and accelerated diffusion samplers. The information-theoretic analysis could inform future work on progressive generation tasks, image compression, or scale-adaptive semantic modeling.
Conclusion
"Scale Space Diffusion" systematically unifies scale-space theory and diffusion generative modeling. By mathematically integrating resolution changes into the diffusion process and enabling efficient architecture support through Flexi-UNet, the paper sets a new paradigm for scalable, multi-resolution probabilistic generative modeling. The approach achieves strong efficiency gains while maintaining competitive generation quality, with broad implications for theory and practice in scalable deep generative models.

