- The paper introduces a vendor-independent, open-source platform for continuous, reproducible quantum benchmarking across diverse hardware architectures.
- The methodology integrates unified benchmark definitions, schema-validated data storage, and an interactive web front-end to ensure transparent and traceable performance comparisons.
- Empirical results demonstrate high correlations between benchmark outcomes and two-qubit gate fidelity, validating the Metriq Score as a key metric for NISQ devices.
The present quantum computing hardware ecosystem is marked by rapid hardware evolution and notable fragmentation of benchmarking efforts. Heterogeneous architectures, inconsistent error models, and disparities in API interfaces across providers frustrate reliable cross-platform performance comparison and reproducibility. The "Metriq: A Collaborative Platform for Benchmarking Quantum Computers" (2603.08680) directly addresses this by introducing a vendor-independent, open-source framework for continuous, reproducible, and extensible quantum benchmarking. Metriq is built around three core co-evolving components: the metriq-gym runner for unified benchmark definition and execution, metriq-data as a schema-validated, versioned repository for results, and metriq-web as an open front-end for interactive data exploration and dissemination.
The platform’s programmatic modularity is designed to ensure decoupling between execution, data storage, and presentation, thereby fostering traceability and transparent provenance tracking. This infrastructure enables the community to interrogate, extend, and reproduce benchmarks—counterbalancing the opacity and instability of both vendor- and publication-based ad hoc benchmarking practices.
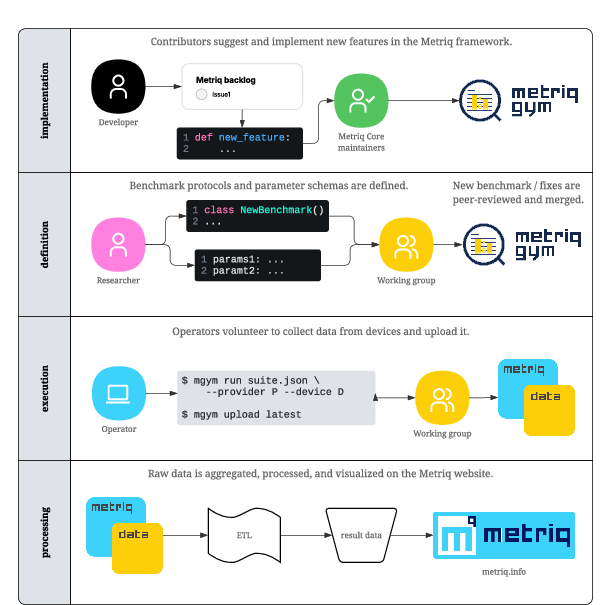
Figure 1: Developer and user workflow in Metriq, highlighting modular separation of benchmark definition, execution, data aggregation, and web-based dissemination.
Benchmark Suite Construction and Methodology
Metriq presents a curated, intentionally opinionated initial benchmark suite, spanning both system-level and application-inspired protocols. All benchmarks are defined in a single explicit schema and executed through a homogeneous interface, allowing precise reproducibility and cross-hardware comparability.
Key system-level protocols include:
- BSEQ (Bell State Effective Qubits): Quantifies maximum device-wide entanglement through CHSH inequality violations, employing edge coloring for efficient parallel measurement partitioning.

Figure 2: Edge coloring for BSEQ benchmark, visualizing partitioning of couplings to enable parallel CHSH tests.
- EPLG (Error Per Layered Gate): Extends beyond quantum volume, utilizing simultaneous randomized benchmarking across qubit chains to produce continuously valued, connectivity-aware error rates.
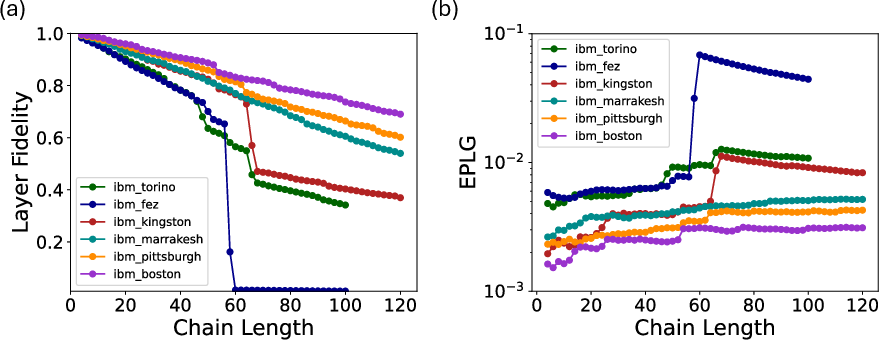
Figure 3: (a) Layer fidelity and (b) EPLG as a function of chain length, demonstrating rapid fidelity degradation in the presence of weak gate links.
- Mirror Circuit Benchmarking: Robustly probes circuit inversion and echo-like fidelity, providing an efficient means to verify scalable circuit execution under hardware noise models.
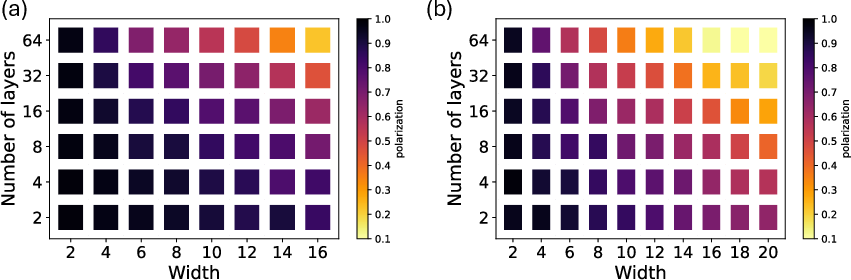
Figure 4: Mirror circuit benchmarking on ibm_fez: experiment (b) versus device-matched noisy simulation (a), showing polarization decay across widths and layers.
- CLOPS (Circuit Layer Operations Per Second): Measures throughput of parallel circuit-layer execution, providing hardware- and stack-level insights into gate speed and runtime overheads.
Application-inspired protocols include quantum machine learning (QML) kernels (probing energy-efficient kernel estimation), linear-ramp QAOA (scalable combinatorial optimization), quantum Fourier transform (QFT) tasks, and wormhole-inspired teleportation (WIT), among others.
To enable systematic, quantitative device comparison, the Metriq Score is introduced: a composite, scale- and task-weighted index aggregating raw outcomes from the benchmark suite. The construction proceeds via (i) within-benchmark aggregation weighted by circuit width, (ii) normalization against a platform-designated baseline, and (iii) across-benchmark aggregation with weights proportional to effective problem scale, paralleling established classical benchmarking methodologies. This approach maintains interpretability and linearity while explicitly encoding judgments about the relative importance of wide and deep circuits, without conflating physically distinct subsystems.
Empirical Insights and Data-Driven Relationships
Benchmarks were executed across more than ten quantum computers from leading hardware vendors, including IBM, Quantinuum, Rigetti, IQM, OriginQ, and others. Notably, the curated cross-platform dataset enabled quantitative analysis of inter-benchmark relationships. Significant findings include:
- Strong rank correlations between interference-style benchmarks (e.g., Mirror Circuits and QML Kernel, ρ≈0.99), underscoring shared sensitivity to circuit-level noise and two-qubit gate fidelity.
- BSEQ showcases robust correlation with scaling performance on variational optimization (e.g., LR-QAOA), reflecting dependence on high-quality long-range entanglement.
- Metriq Score exhibits monotonic, high correlation (ρ>0.98) with vendor-reported two-qubit gate fidelity across platforms, substantiating the centrality of two-qubit performance as a limiting factor for NISQ algorithms.
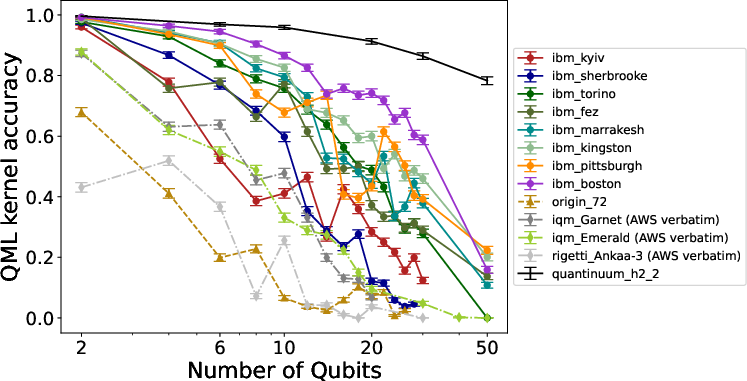
Figure 5: QML kernel benchmark accuracy as a function of qubit count, highlighting platform differences and the effects of compilation modes (e.g., verbatim compilation).
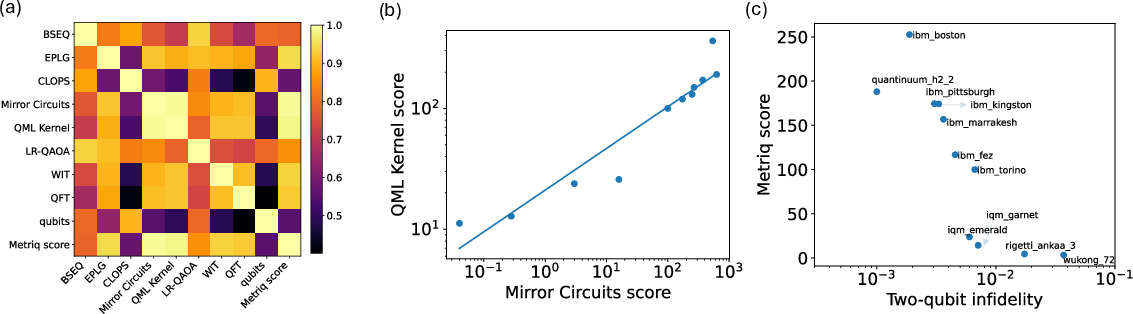
Figure 6: Correlation matrix across benchmark outcomes and Metriq Score, quantitatively highlighting proxy relationships and primary bottlenecks.
Benchmarking Economics and Practical Constraints
Benchmarking cost remains a practical concern, with disparate pricing models (per-shot, per-gate, per-task) across quantum cloud providers. Metriq's design includes detailed cost estimation and accounting utilities, informing experiment planning and guiding the selection of benchmark configurations that are both meaningful and resource-efficient.
Circuit Compilation, Error Mitigation, and Methodological Rigor
The platform underscores that circuit compilation and error mitigation pipelines are integral parts of the benchmarking process. The study demonstrates that lack of proper compilation control (e.g., unsupported barriers) can yield spurious, artificially high accuracy metrics, obfuscating real device noise. The use of verbatim compilation—to guarantee structural fidelity and compiler transparency—proved essential for valid cross-platform comparisons, especially in symmetry-sensitive protocols like QML kernel estimation.
Integration of quantum error mitigation (QEM) is outlined as a future avenue, noting both the opportunities for mitigation-enabled benchmarks and the challenges associated with increased execution cost and provider-dependent workflow support.
Forward Outlook: Towards Logical Benchmarking and Community Integration
Current Metriq benchmarking primarily targets physical qubits in gate-based architectures. The imminent emergence of devices supporting fault-tolerant logical qubits motivates extensions to the platform for benchmarking logical-level metrics (e.g., logical error rate, logical Bell pair generation, code distance scaling). Such development necessitates deeper coordination with device-level syndrome extraction protocols and decoding latency/pathways, with attention to code-family-specific resource scaling and algorithmic primitives.
Metriq's holistic, schema-driven approach is inherently suited to the integration of logical benchmarks and dynamic circuit capabilities, with ongoing efforts to extend provider coverage, simulate analog modalities, and support vendor-agnostic resource estimation.
Figure 7: Metriq.info, the public interactive web portal for collaborative exploration of cross-platform quantum benchmarking data.
Conclusion
Metriq (2603.08680) establishes a robust, extensible foundation for reproducible, quantitative, and community-driven benchmarking of quantum computers. The platform's modular tooling, public datasets, and scalar summary metrics collectively coalesce to support ecosystem-level scientific inference, detailed workload assessment, and empirical hardware comparison beyond the limited scope of prior efforts. Metriq stands as an open invitation for community stewardship and ongoing refinement—anchoring empirical work in quantum information science as device architectures, error models, and system integration practices continue their rapid development.