- The paper introduces a neural vocoder using range-null decomposition, enabling interpretable modeling and reduced computational cost for audio synthesis.
- It leverages hierarchical subband modeling and a Multiple-Condition-as-Data-Augmentation strategy to adapt to diverse mel-spectrogram configurations.
- Empirical evaluations reveal state-of-the-art performance, with lightweight models outperforming baselines on metrics like PESQ, MCD, and subjective tests.
Scalable Neural Vocoder from Range-Null Space Decomposition
Introduction and Motivation
The paper "Scalable Neural Vocoder from Range-Null Space Decomposition" (2603.08574) proposes a neural vocoder architecture based on explicit signal decomposition in the time-frequency (T-F) domain, leveraging classical range-null decomposition (RND) theory. This framework addresses three critical issues in mainstream neural vocoding: opaque black-box modeling, lack of scalability to diverse mel-spectrogram configurations, and suboptimal parameter-performance tradeoffs in T-F architectures. Traditional approaches often map mel-spectrograms to waveform or spectrogram targets via complex neural networks, risking significant distortion of acoustic information and requiring retraining for each input configuration. The proposed RND-based method offers interpretable modeling, efficient deployment, and robust scalability by decomposing the target spectrogram into range-space and null-space components, thereby improving quality while reducing computational complexity.
Range-Null Decomposition Framework
The cornerstone of this work is the application of RND theory to the vocoder task. Given that mel-spectrograms are generated by a linear transformation and subsequent compression of the spectral magnitude (with phase discarded), the target spectrogram can be decomposed into the range-space—recoverable via the pseudo-inverse operation—and the null-space, which contains spectral details not captured by the mel transformation and must be inferred. The process can be formally written as:
∣S~∣=A†A∣S∣+(I−A†A)∣S~∣null
where A is the mel-filter matrix and A† is its pseudo-inverse. The null-space module is realized by a neural network and tasked with generating the fine spectral details, including phase information and high-frequency dynamics lost in mel compression.
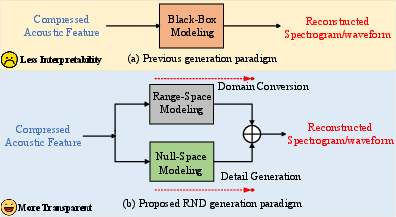
Figure 1: Comparison of prior T-F domain vocoder architectures (black-box modeling) with the proposed RND pipeline, decomposing signal reconstruction into range-space pseudo-inverse transformation and null-space spectral detail generation.
This structure is fundamentally more interpretable, as it enforces lossless transmission of acoustic information captured by the mel-spectrogram and isolates the nonlinear network modeling to the detail-infill stage.
Subband Hierarchical Modeling
To fully exploit spectral priors, RNDVoC divides the frequency axis into hierarchically arranged subbands—modeling correlations within and across these bands. This dual-path approach employs a Band-aware Encoding Module (BAEM) for input feature extraction, narrow-band modules for temporal modeling, and cross-band modules for inter-band correlation modeling. Parameter sharing across regions reduces computational cost and enables lightweight deployment.
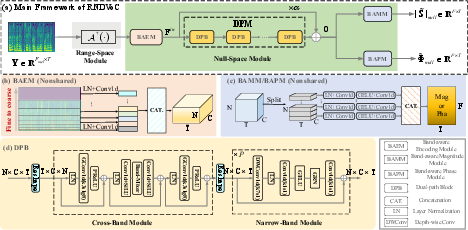
Figure 2: RNDVoC framework diagram illustrating the pseudo-inverse range-space projection, band-aware encoding, and detailed dual-path module structure for null-space modeling.
Experiments demonstrate that increasing the number of subbands leads to substantial improvements in PESQ, MCD, UTMOS, and periodicity metrics without increasing parameter count, establishing subband scaling as an efficient model scaling paradigm.
Multi-Condition Data Augmentation and Scalability
A major advancement is the Multiple-Condition-as-Data-Augmentation (MCDA) strategy, which transforms the inference-stage multi-condition adaptation problem into training-stage data augmentation. During training, the model is exposed to mel-spectrograms generated using a pool of filter configurations—varied in number of bands and maximum frequency. At inference, any mel configuration within the range can be projected to the common linear-scale domain, allowing a single model to handle diverse input types without retraining. The MCDA strategy achieves robust generalization to both seen and unseen mel configurations.
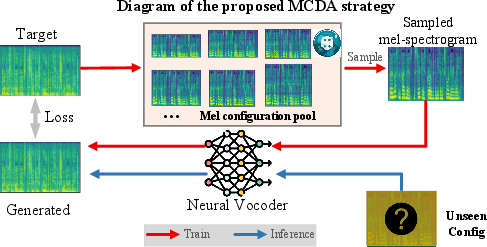
Figure 3: MCDA training strategy enables scalable inference under arbitrary mel-spectrogram configurations by randomizing filter selection during training.
Loss Function Innovations: Omnidirectional Phase Loss
Effective phase modeling remains a key challenge in T-F vocoding, given the periodic and wrapped nature of phase. RNDVoC introduces an omnidirectional phase loss, realized as fixed 3×3 convolution kernels traversing all eight adjacent T-F bins. This loss efficiently captures local differential relationships in both time and frequency directions, outperforming prior anti-wrapping losses and yielding superior phase reconstruction.
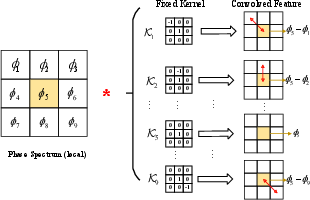
Figure 4: Omnidirectional phase loss leverages neighborhood relations in the T-F domain for improved phase reconstruction.
Empirical Evaluation: Numerical Results
Extensive experiments on LJSpeech, LibriTTS, EARS, VCTK, and MUSDB18 reveal the superiority of the RNDVoC approach. The shared-parameter RNDVoC achieves state-of-the-art performance with only 3.14M parameters and 8.17% of BigVGAN's computational complexity, outperforming all T-F domain GAN and diffusion baselines. The method maintains performance across out-of-distribution datasets and exhibits strong perceptual preference in AB and MUSHRA tests, especially for musical signals rich in harmonics.
- On LibriTTS, RNDVoC-shared attains PESQ 4.226 and MCD 1.914, exceeding BigVGAN at equivalent training steps.
- MUSHRA ratings confirm statistically significant improvement over baseline GAN vocoders.
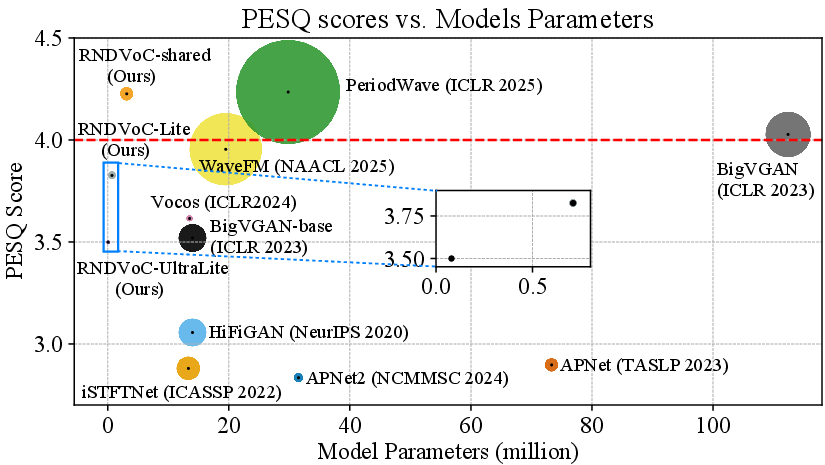
Figure 5: Comparative visual analysis of model parameters, PESQ scores, and computational complexity; RNDVoC offers high quality at low complexity.

Figure 6: AB preference scores for GAN-based vocoders, RNDVoC-shared demonstrates consistent subjective advantage.
Lightweight Vocoder Design
Further parameter reduction yields RNDVoC-Lite (0.71M) and RNDVoC-UltraLite (0.08M), both surpassing HiFiGAN-V2 (0.92M) in PESQ and VISQOL, confirming effectiveness for edge deployment. The RND module itself—tested as a plug-in for APNet and APNet2—improves transmission fidelity and mitigates artifact generation in weak models.
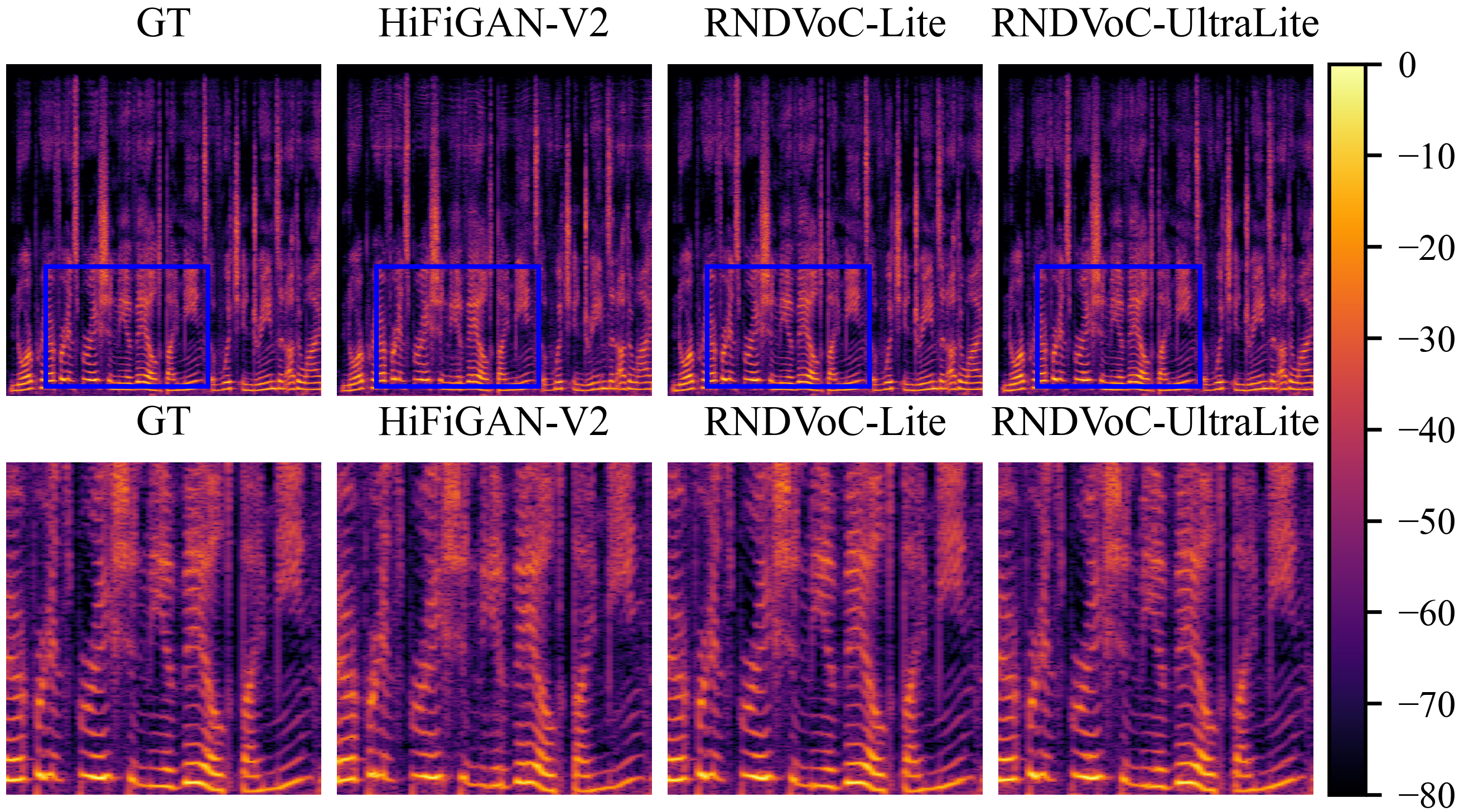
Figure 7: Spectral visualizations show that lightweight RNDVoC variants preserve harmonic detail better than HiFiGAN-V2.
Ablation and Design Analysis
Module-wise ablation validates that both narrow-band and cross-band modeling are essential for artifact reduction and spectral accuracy. The shared parameter regime further enhances inference speed and memory efficiency. Fixed pseudo-inverse projection outperforms learnable alternatives, emphasizing the benefit of maintaining strict orthogonality in signal decomposition.
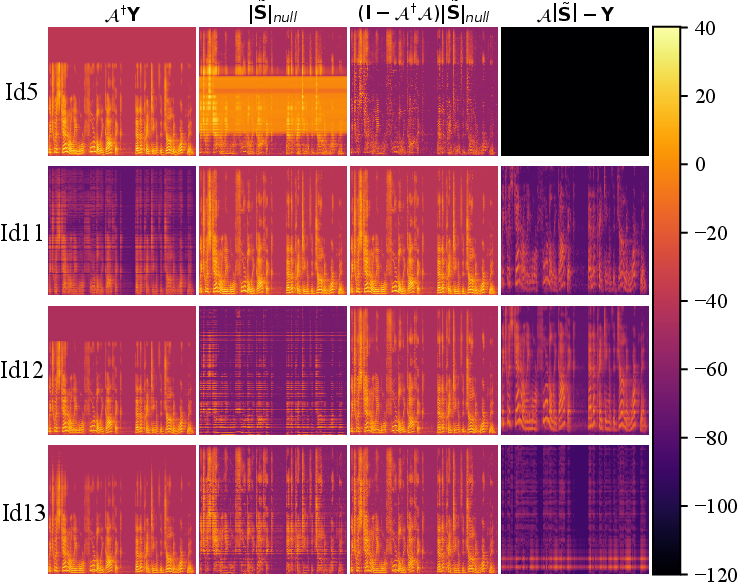
Figure 8: Range-space, null-space, and reconstruction error visualizations highlight the effectiveness of orthogonal decomposition.
Practical and Theoretical Implications
The explicit decomposition into range and null spaces provides theoretical guarantees for lossless information transmission on the compressed mel-spectrogram content, while modular null-space modeling isolates the detail generation task. This paradigm enhances interpretability and robustness, and MCDA extends practical deployment to diverse real-world input conditions.
Subband scaling—an efficient alternative to parameter scaling—enables high-fidelity generation with minimal computational footprint. The plug-and-play value of RND is established for existing T-F domain vocoders, and lightweight deployment is viable without compromise in fidelity.
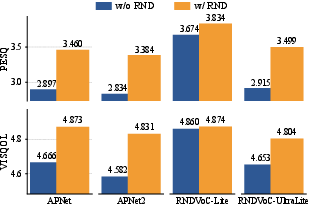
Figure 9: Performance improvements for APNet/APNet2 upon integration of the RND strategy.
Future Directions
The current study focuses on mel-spectrogram input and linear degradation models, suggesting future extension to more general acoustic features and nonlinear degradation scenarios. Further exploration of MCDA over broader extraction pipelines, joint optimization of subband division, and deployment in speech restoration or neural audio codec domains are promising avenues.
Conclusion
The RNDVoC framework introduces principled signal decomposition to neural vocoding, achieving transparent modeling, scalable inference, and state-of-the-art quality at drastically reduced complexity. Through hierarchical subband modeling, loss innovations, and plug-and-play modularity, the approach sets new standards for both interpretability and efficiency in T-F domain speech and audio synthesis, with broad implications for deployment and future research in generative modeling (2603.08574).

