FedBCD:Communication-Efficient Accelerated Block Coordinate Gradient Descent for Federated Learning
Published 5 Mar 2026 in cs.LG and cs.AI | (2603.05116v1)
Abstract: Although Federated Learning has been widely studied in recent years, there are still high overhead expenses in each communication round for large-scale models such as Vision Transformer. To lower the communication complexity, we propose a novel Federated Block Coordinate Gradient Descent (FedBCGD) method for communication efficiency. The proposed method splits model parameters into several blocks, including a shared block and enables uploading a specific parameter block by each client, which can significantly reduce communication overhead. Moreover, we also develop an accelerated FedBCGD algorithm (called FedBCGD+) with client drift control and stochastic variance reduction. To the best of our knowledge, this paper is the first work on parameter block communication for training large-scale deep models. We also provide the convergence analysis for the proposed algorithms. Our theoretical results show that the communication complexities of our algorithms are a factor $1/N$ lower than those of existing methods, where $N$ is the number of parameter blocks, and they enjoy much faster convergence than their counterparts. Empirical results indicate the superiority of the proposed algorithms compared to state-of-the-art algorithms. The code is available at https://github.com/junkangLiu0/FedBCGD.
The paper introduces FedBCGD, a novel block-coordinate gradient descent approach that partitions model updates to reduce upload costs by 1/N.
It leverages global block-wise momentum and control variates to mitigate gradient noise and client drift, ensuring accelerated convergence under heterogeneous data.
Empirical results show up to 7.3x speedup over FedAvg and effective scaling to architectures like ResNet and ViT for federated learning tasks.
Communication-Efficient Federated Learning via Accelerated Block Coordinate Gradient Descent
Introduction and Context
Federated Learning (FL) faces persistent communication bottlenecks, particularly with large-scale neural architectures such as Vision Transformers and deep CNNs. The reliance on full-model communication at each aggregation round magnifies these challenges, especially under heterogeneous client resources and constrained uplinks. The paper "FedBCD: Communication-Efficient Accelerated Block Coordinate Gradient Descent for Federated Learning" (2603.05116) introduces a novel class of Block Coordinate Gradient Descent (BCGD) algorithms—FedBCGD and the accelerated FedBCGD+—that target communication efficiency without sacrificing convergence characteristics or resilience to data heterogeneity.
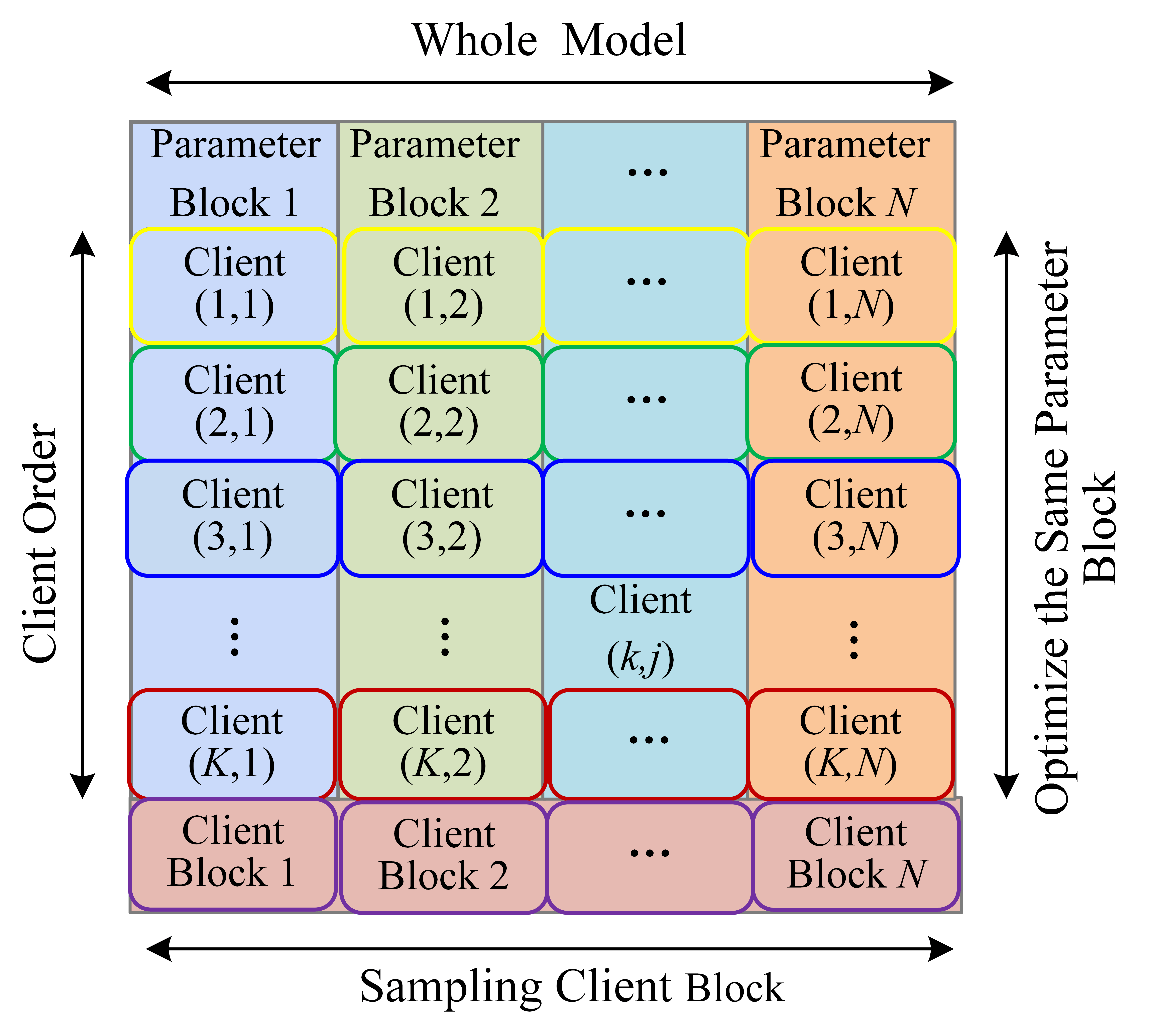
FedBCGD Framework: Block Parameter Decomposition
FedBCGD proposes a decomposition of the global model into N disjoint parameter blocks, potentially with heterogeneous sizes determined by network architecture or client upload capacity. Each FL client is assigned responsibility for optimizing a given parameter block and an additional small set of shared parameters (e.g., classifier head), ensuring critical global structure is incorporated in each local update. Communication is restricted to only the assigned parameter block and the shared block, delivering an immediate N1 reduction in upload communication relative to full-model approaches.
Figure 1: High-level architecture of the FedBCGD framework, depicting block-wise parameter partitioning and selective communication.
Figure 2: Illustration of client-to-block mapping in FedBCGD. Clients are grouped, and each group manages a distinct parameter block for upload and aggregation.
Local updates employ full-model optimization, but crucially, only a block subset is synchronized with the server, maximizing both statistical and communication efficiency.
Algorithmic Innovations
FedBCGD: Design and Aggregation
The baseline FedBCGD algorithm departs from traditional parameter freezing schemes that degrade convergence in block-sparse synchronization. Instead, while clients update all model parameters locally, the upload is restricted to the assigned block and shared block. On the server, aggregation is augmented by a global block-wise momentum mechanism, which accelerates convergence by exploiting historical update velocity.
FedBCGD+: Acceleration via Variance Reduction and Drift Control
FedBCGD+ further extends the design for enhanced resilience to client drift and stochastic gradient noise. Key elements include:
Stochastic Variance Reduction: Inspired by SVRG, clients apply control variates to reduce the variance of stochastic updates.
Drift Compensation: SCAFFOLD-style control variates offset divergence between client-local and global objectives, effectively countering the negative impact of non-iid data distributions.
Fast Theoretical Convergence: The additional control mechanisms yield improved rates in both strongly convex and non-convex regimes.
Theoretical Guarantees: Communication Complexity and Convergence
Rigorous convergence analysis demonstrates that both FedBCGD and FedBCGD+ attain superior communication complexity over canonical approaches. For models partitioned into N blocks, communication cost per iteration for each client drops from O(d) (in FedAvg/SCAFFOLD) to O(d/N).
Key theoretical results:
FedBCGD (Strongly Convex):
Communication complexity: O(μSTϵσ2+G2d+αμNϵσ+Gd+μNβlogϵ1d)
Communication cost is $1/N$ of FedAvg's, with N the number of blocks.
FedBCGD+ (Strongly Convex):
Communication complexity: O((SM+μβ)dlogϵ1) with S sampled clients and M total clients.
In the non-convex regime, FedBCGD+ achieves O(ϵβF(SM)2/3N−1/3d), improving upon all prior block-sparse or drift-controlled FL results.
Empirical Evaluation
(Systematic empirical assessment covers both synthetic and standard FL benchmarks, including CIFAR-10/100 and Tiny ImageNet, using LeNet-5, VGG-11/19, ResNet-18, ViT-Base.)
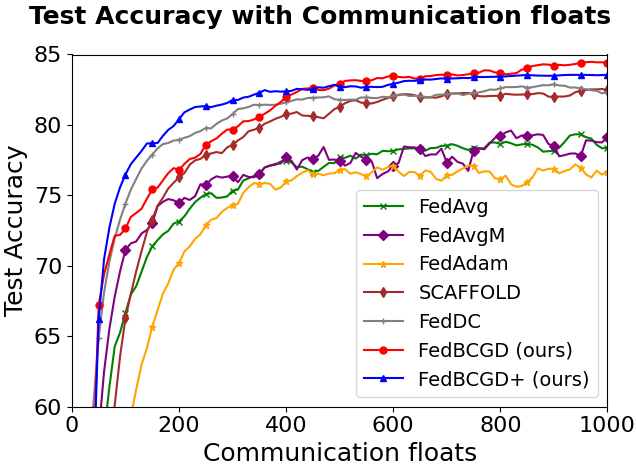
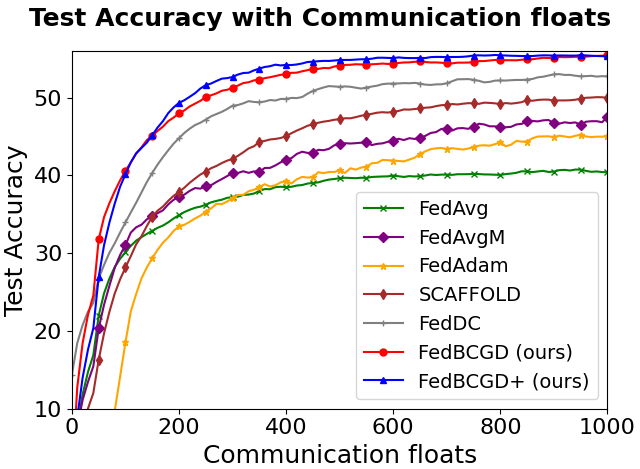
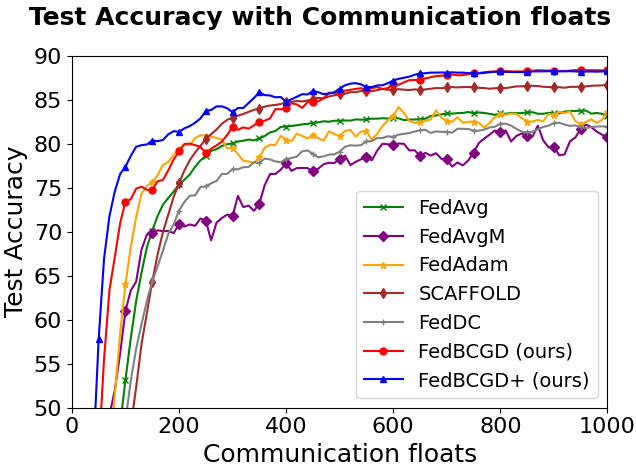
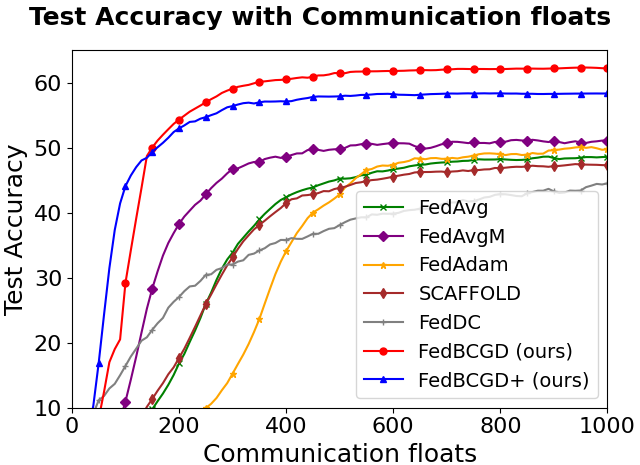
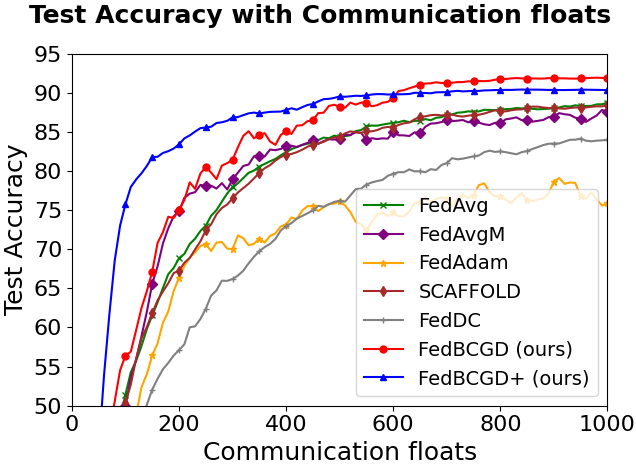
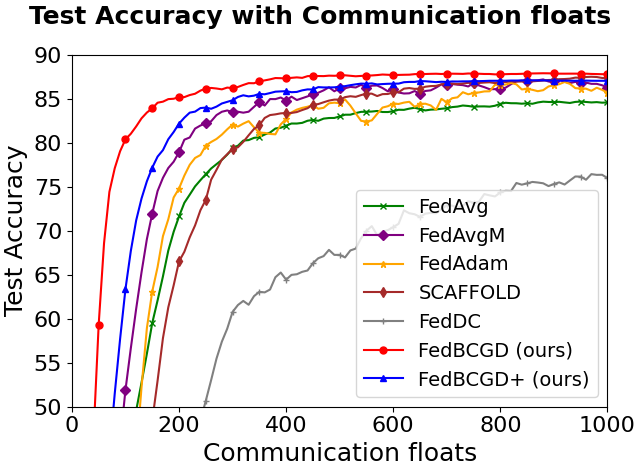
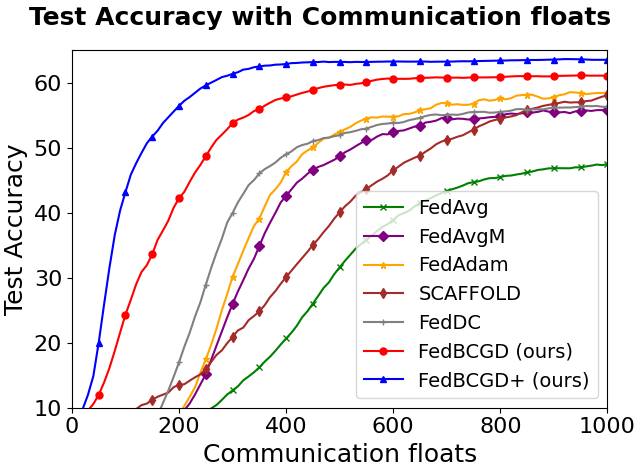
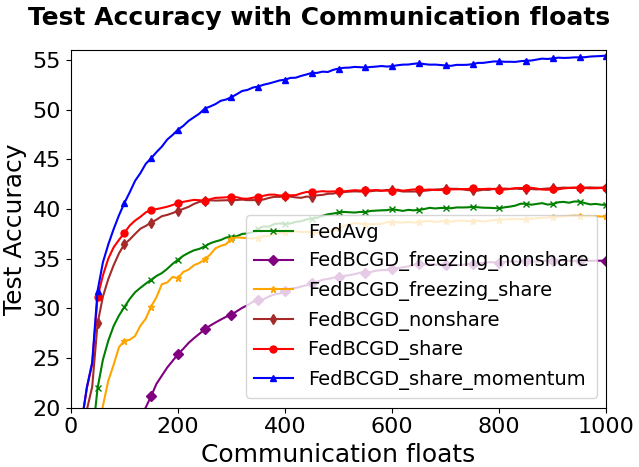
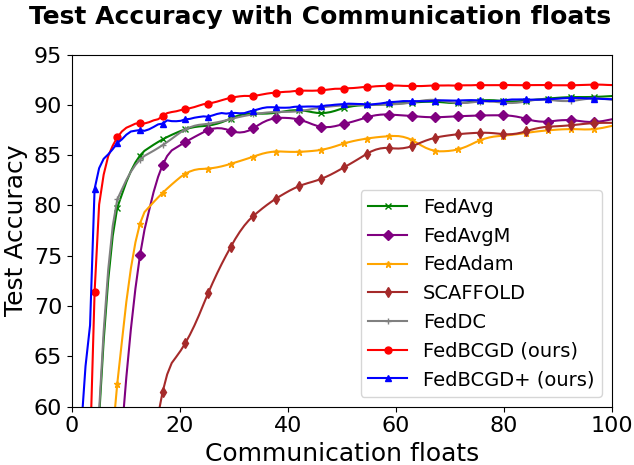
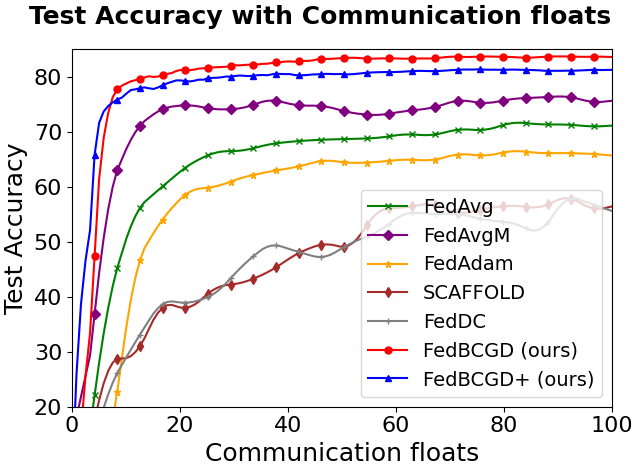
Figure 3: Testing accuracy vs. communication cost for FedBCGD, FedBCGD+, and several baselines on CIFAR-10/100 with LeNet-5, VGG, and ResNet-18 architectures under partial (10%) client participation and ρ=0.6 heterogeneity.
Key observations:
FedBCGD achieves substantial reduction in communication rounds and total broadcasted floats required to reach target accuracy compared to FedAvg, FedAdam, SCAFFOLD, and others.
On ResNet-18/CIFAR-100, FedBCGD delivers up to 7.3x speedup over FedAvg in reaching 40% accuracy.
FedBCGD+ exhibits further improvement in convergence speed, particularly under high heterogeneity and non-convex objectives.
Both FedBCGD and FedBCGD+ can attain final testing accuracy exceeding that of centralized SGD, indicating regularization and generalization benefits of block-wise asynchrony.
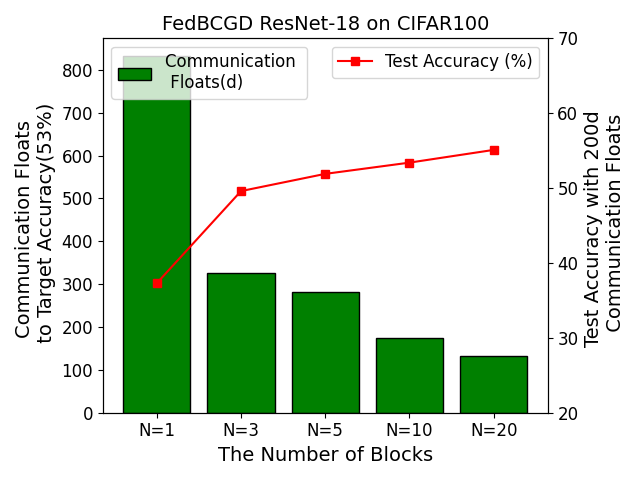
Figure 4: The effect of varying block number N on FedBCGD acceleration, highlighting a non-monotonic tradeoff and optimal block sizes.
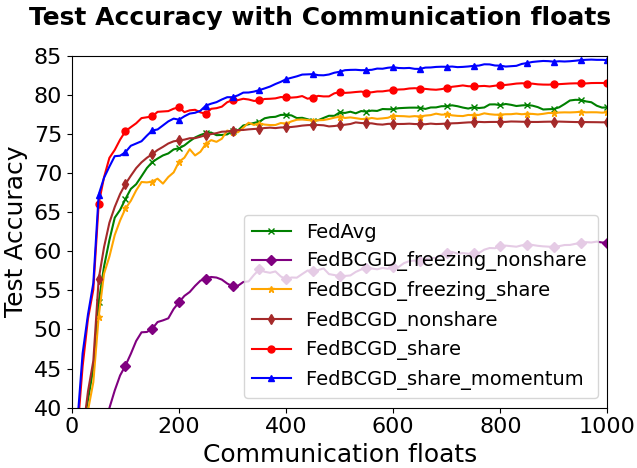
Freezing unassigned local parameters (as in naïve block-coordinate updates) degrades both convergence and final accuracy due to inter-block drift and underutilization of client data.
Transmission of shared classifier parameters is essential; omitting these impairs global performance, especially under high heterogeneity.
Introduction of block-wise momentum on the server side significantly accelerates convergence.
Figure 5: Performance comparison of various block-sharing and momentum settings in LeNet-5 on CIFAR-10 and CIFAR-100.
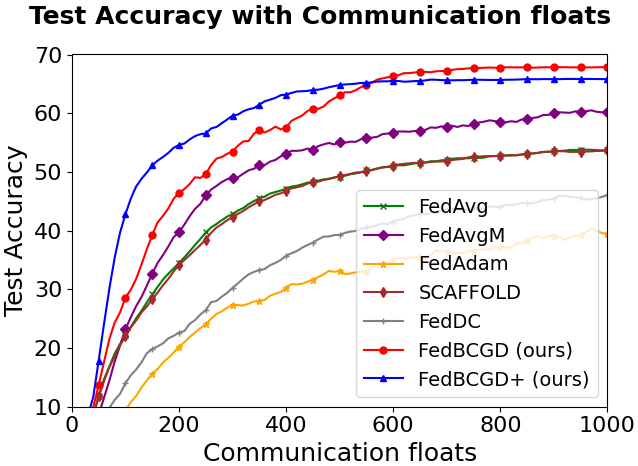
Large-Scale Applicability: ViT-Base and Communication Scaling
Experiments with ViT-Base on Tiny ImageNet and CIFAR100 confirm that FedBCGD scales to modern large-parameter neural architectures. The communication cost reductions persist, with over 11.5x faster convergence on Tiny ImageNet relative to FedAvg.
Figure 6: Test accuracy vs. communication volume for ViT-Base on CIFAR100 and Tiny ImageNet (E=1, ρ=0.6, N=6), demonstrating robust scaling of FedBCGD and FedBCGD+.
Practical and Theoretical Implications
Practically, the decoupling of update and upload responsibilities enables:
FL deployment under diverse device bandwidth constraints by block-size-aware client-to-block assignment.
Scalable training of overparameterized neural networks (including transformers) across cross-device and cross-silo settings.
Theoretically, the results indicate that:
Block-wise model synchronization need not induce substantial convergence or accuracy degradation if suitably designed—contradicting the expectation that aggressive communication reduction must degrade statistical performance.
Stochastic variance reduction and drift control allow near-optimal communication rates in the presence of non-iid data, challenging previous communication-accuracy tradeoff assumptions.
Future Directions
Open questions emerging from this work include:
Dynamic, data-driven strategies for block partitioning and assignment, potentially leveraging network topology, model interpretability, or empirical Fisher information.
Extension to hierarchical or multi-tier FL settings, as well as integration with modern compression or quantization approaches for further communication efficiency.
Investigation into the interplay between block-wise synchronization and optimization landscape traversal, especially in overparameterized or sparse regimes.
Conclusion
The FedBCGD and FedBCGD+ algorithms establish a rigorous and practical pathway for achieving communication-efficient federated optimization at scale. By partitioning models into blocks and sharing only minimal critical parameter subsets, they sidestep both uplink bottlenecks and the accuracy degradation traditionally associated with aggressive communication-saving schemes. Theoretical and empirical results substantiate both their statistical and efficiency benefits, opening new avenues for scalable, heterogeneous, and privacy-preserving federated learning (2603.05116).
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.