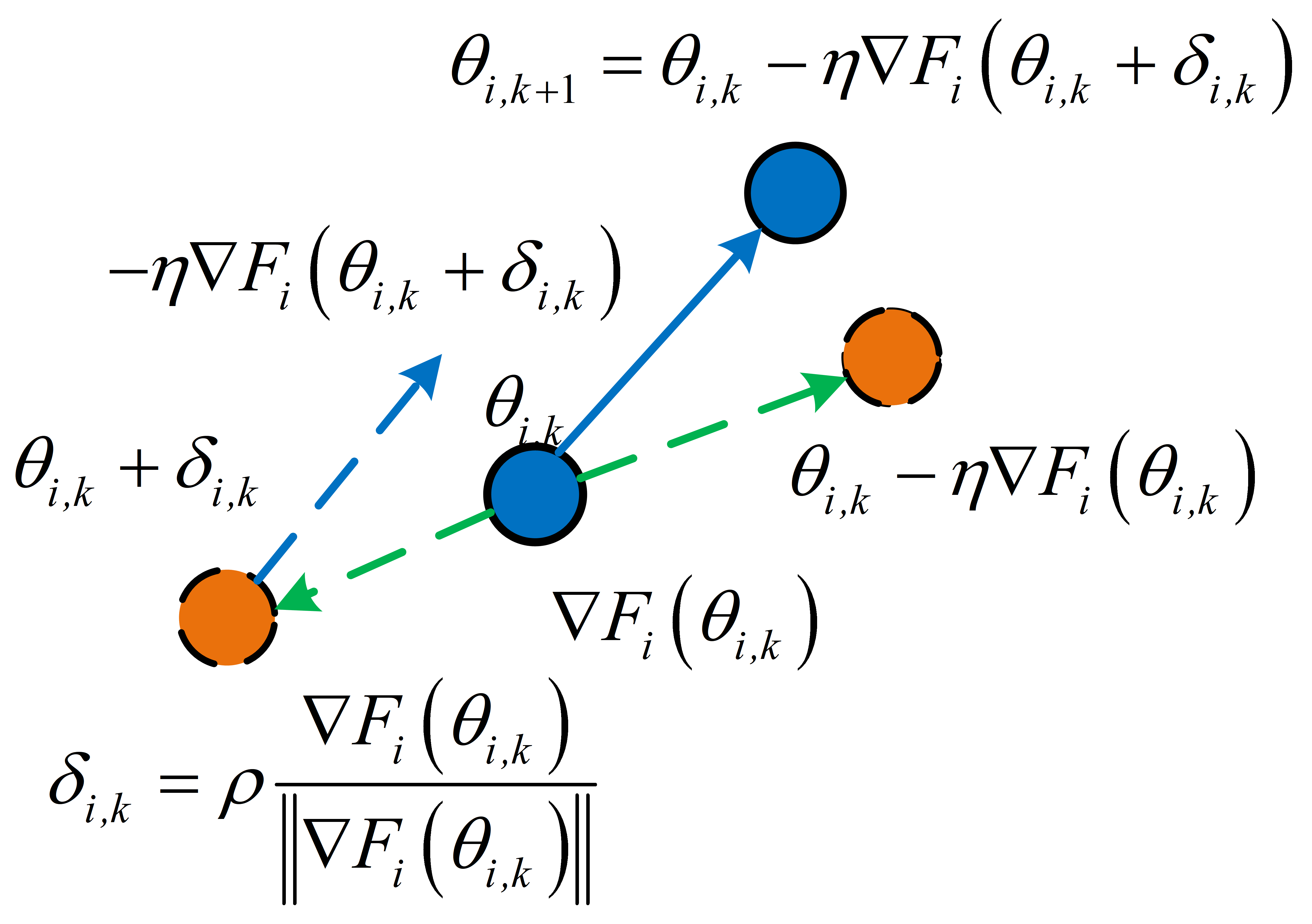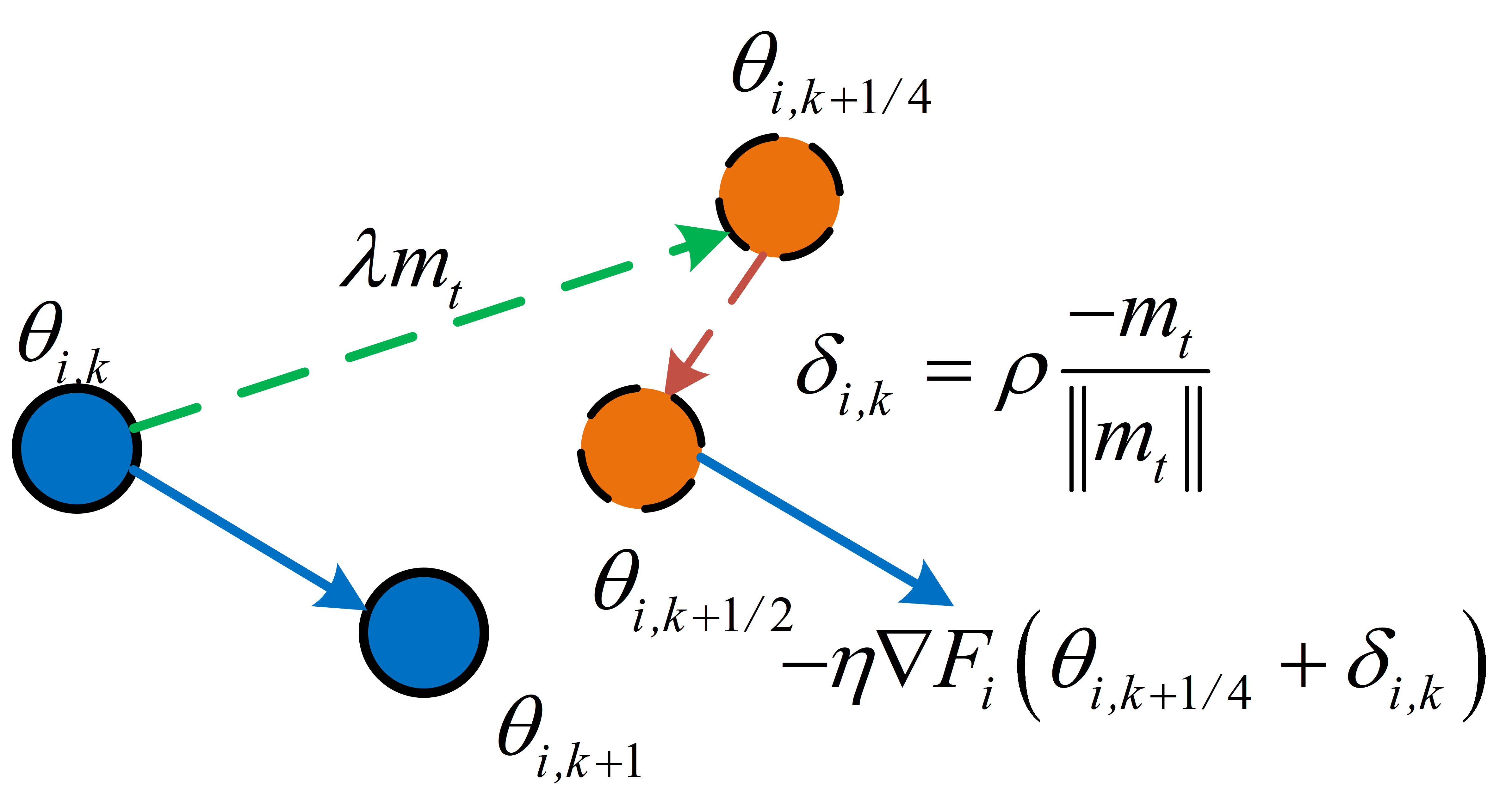FedNSAM:Consistency of Local and Global Flatness for Federated Learning
Published 27 Feb 2026 in cs.LG and cs.AI | (2602.23827v1)
Abstract: In federated learning (FL), multi-step local updates and data heterogeneity usually lead to sharper global minima, which degrades the performance of the global model. Popular FL algorithms integrate sharpness-aware minimization (SAM) into local training to address this issue. However, in the high data heterogeneity setting, the flatness in local training does not imply the flatness of the global model. Therefore, minimizing the sharpness of the local loss surfaces on the client data does not enable the effectiveness of SAM in FL to improve the generalization ability of the global model. We define the \textbf{flatness distance} to explain this phenomenon. By rethinking the SAM in FL and theoretically analyzing the \textbf{flatness distance}, we propose a novel \textbf{FedNSAM} algorithm that accelerates the SAM algorithm by introducing global Nesterov momentum into the local update to harmonize the consistency of global and local flatness. \textbf{FedNSAM} uses the global Nesterov momentum as the direction of local estimation of client global perturbations and extrapolation. Theoretically, we prove a tighter convergence bound than FedSAM by Nesterov extrapolation. Empirically, we conduct comprehensive experiments on CNN and Transformer models to verify the superior performance and efficiency of \textbf{FedNSAM}. The code is available at https://github.com/junkangLiu0/FedNSAM.
The paper introduces FedNSAM, which integrates global Nesterov momentum with sharpness‐aware minimization to reconcile local and global flatness in federated learning.
It provides a rigorous theoretical analysis showing tighter convergence bounds and up to 3× faster convergence compared to established federated learning baselines.
Empirical results on CIFAR100 and Tiny ImageNet demonstrate that FedNSAM achieves substantial accuracy improvements and robust performance under highly non-IID data distributions.
Consistency of Local and Global Flatness in Federated Learning: The FedNSAM Algorithm
Motivation: Flatness Distance and Loss Landscape Misalignment
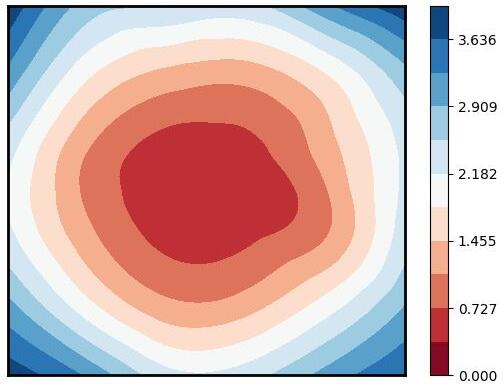
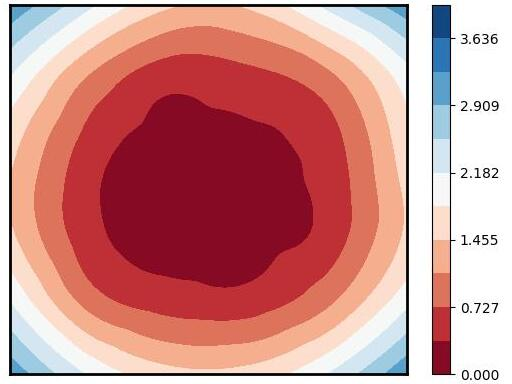
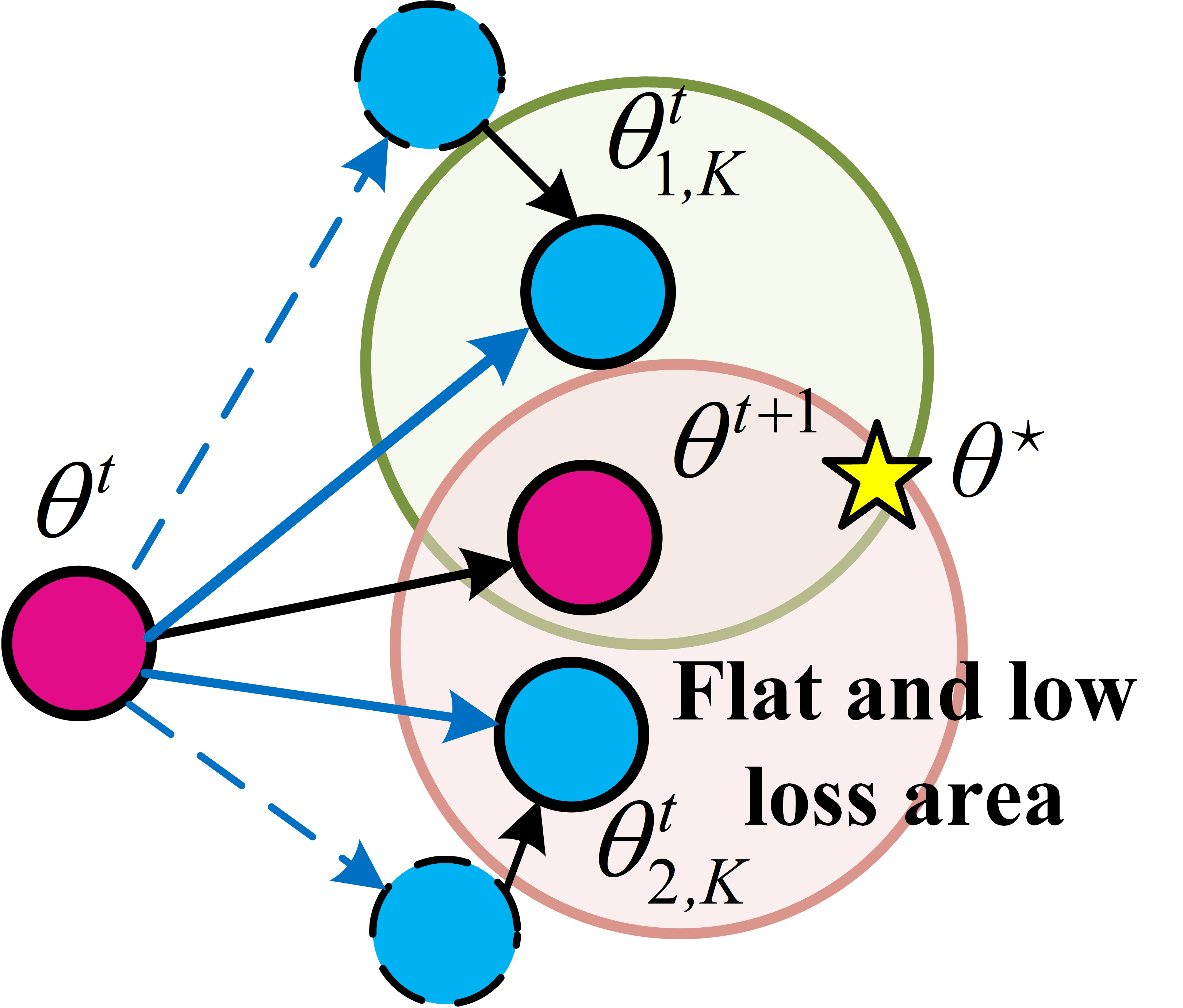
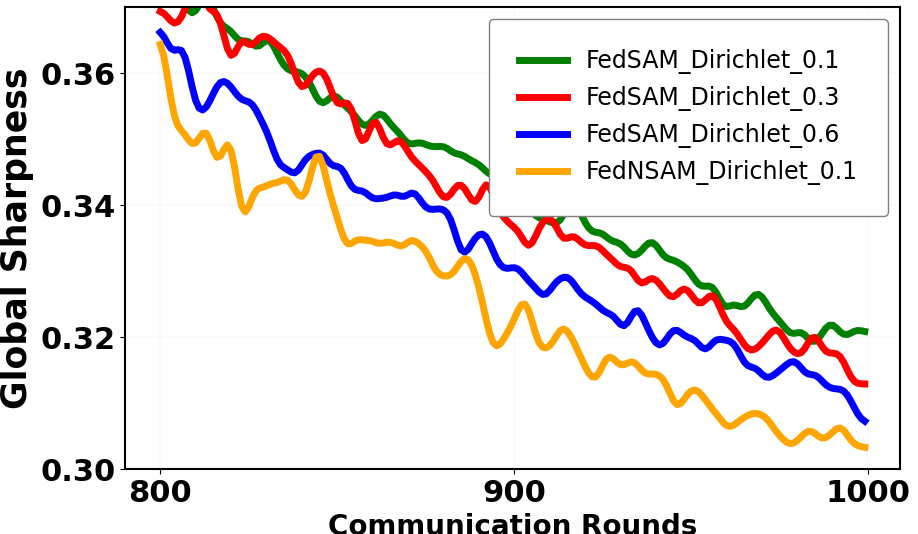
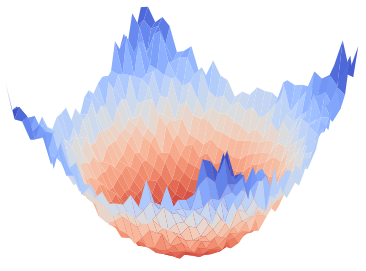
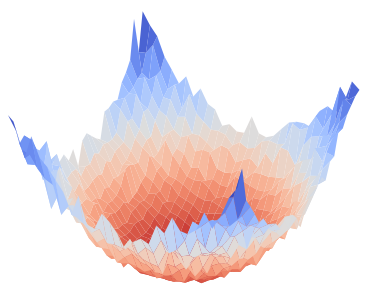
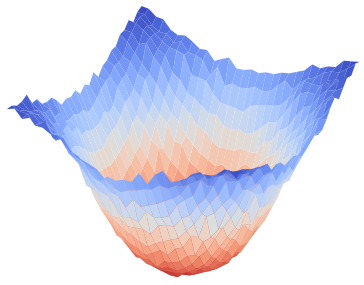
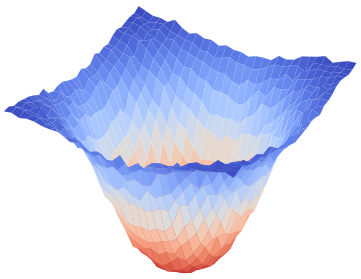
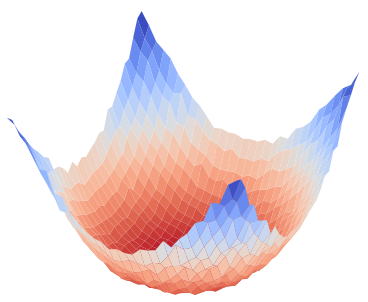
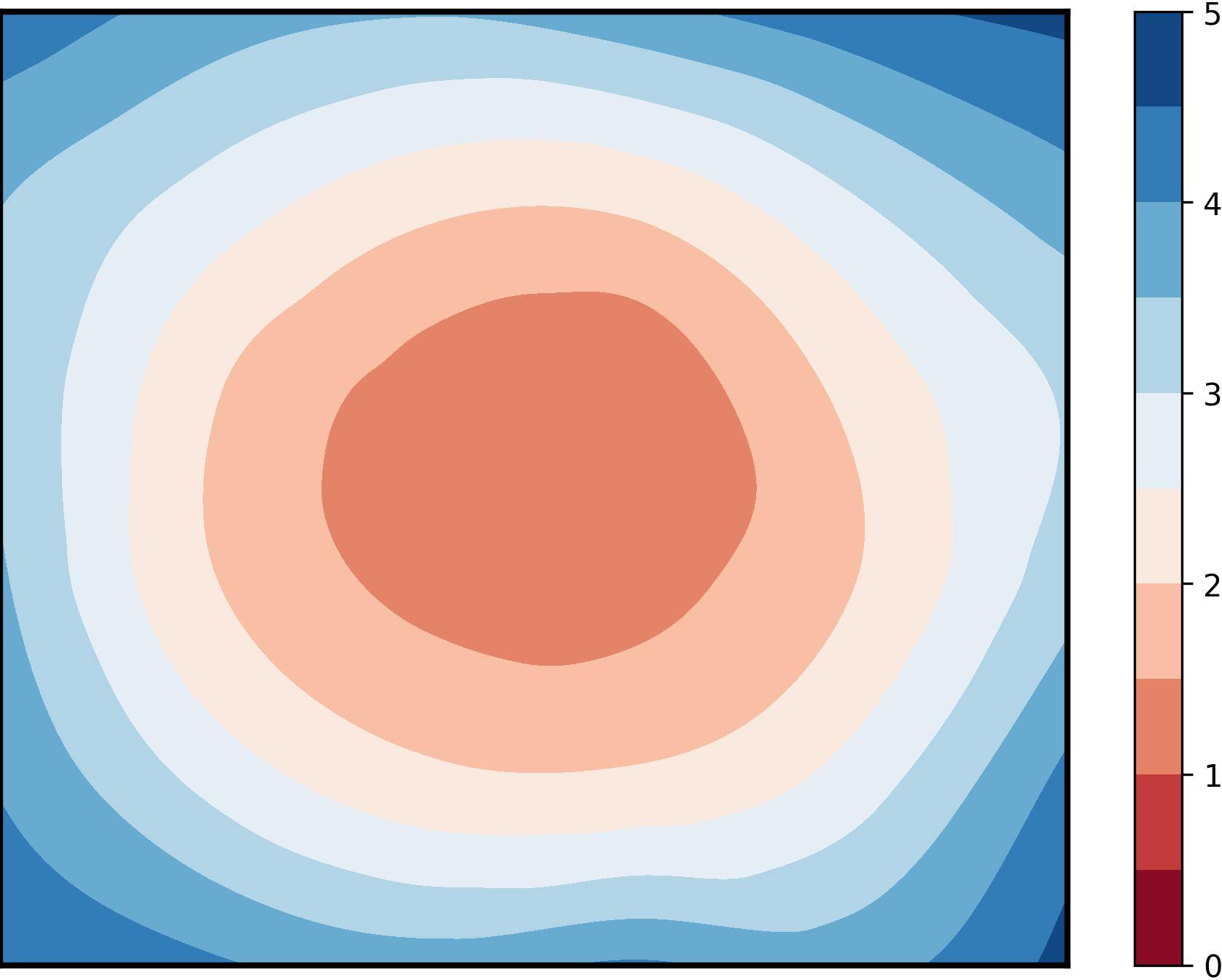
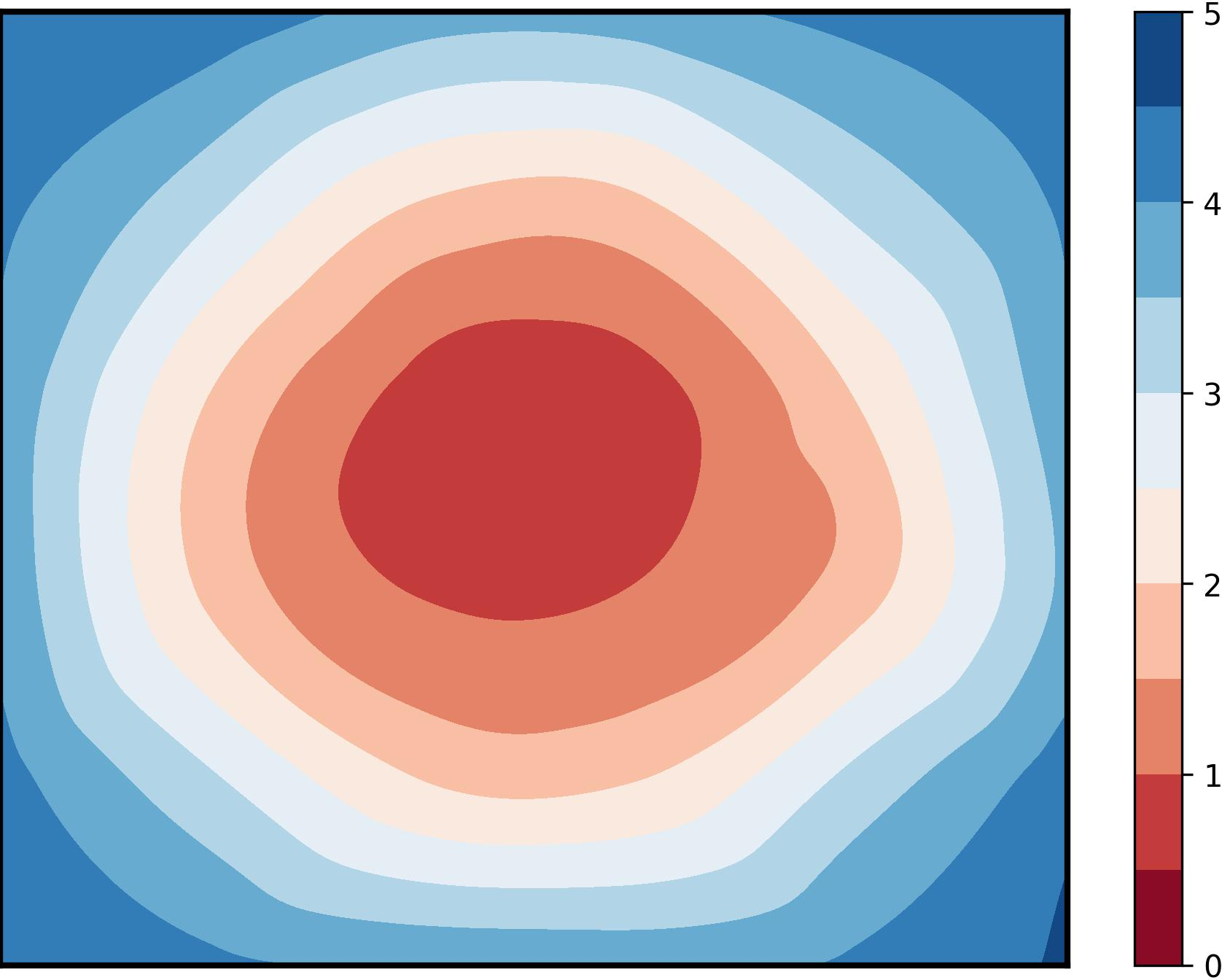
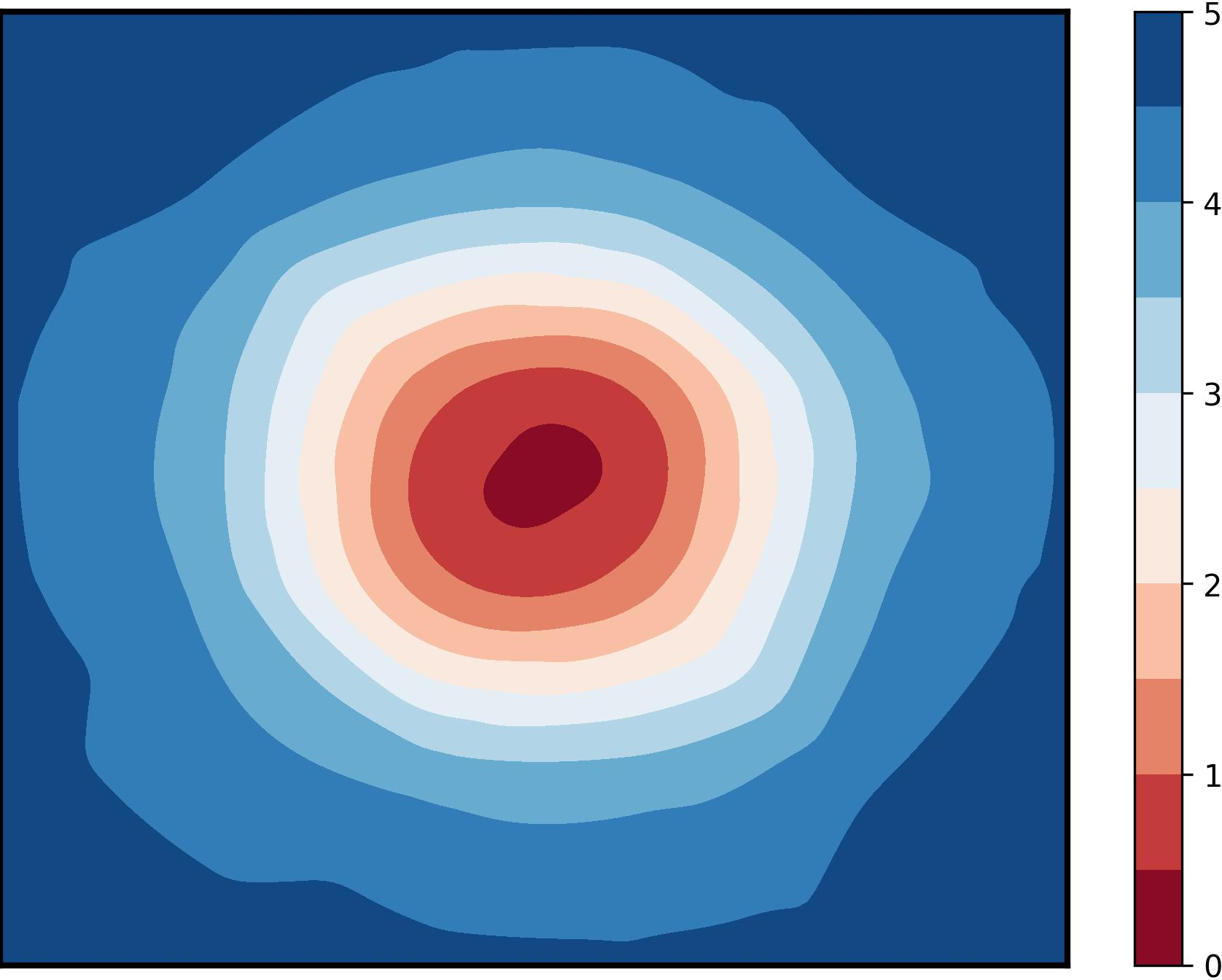
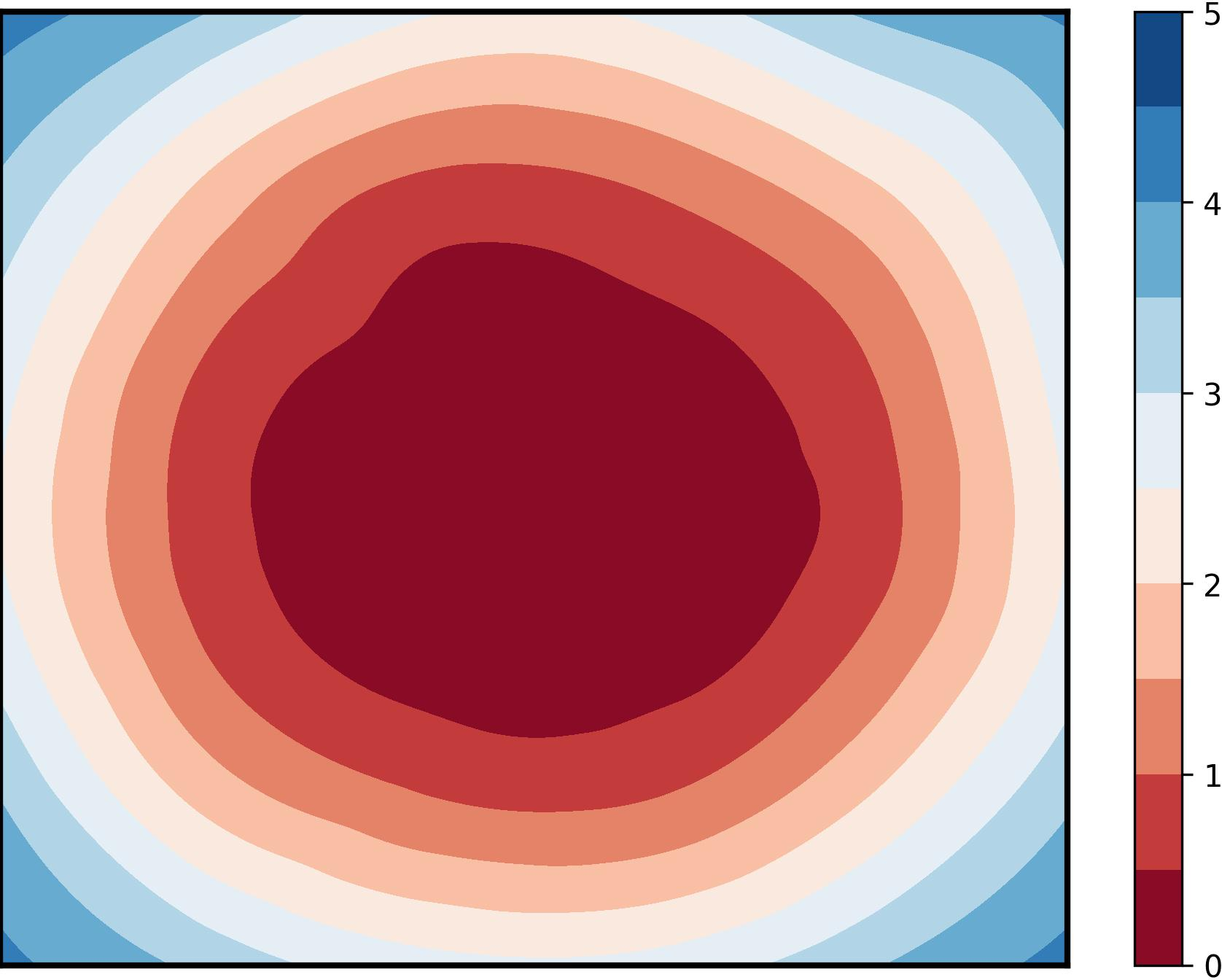
Federated Learning (FL) critically suffers from optimization misalignment induced by local data heterogeneity and multi-step client updates. Sharpness-aware minimization (SAM) has been adopted by FL algorithms to promote flat loss landscapes and improve generalization, but empirical evidence shows that minimizing local sharpness does not guarantee global flatness under highly non-IID distributions. The paper introduces the notion of flatness distance, which quantitatively characterizes the divergence between local and aggregated global minimum regions. As heterogeneity increases, the global loss surface becomes significantly sharper, and the flat regions identified by local SAM optimization become non-overlapping, precluding the global model from residing in any local flat minimum. This results in substantial generalization degradation.
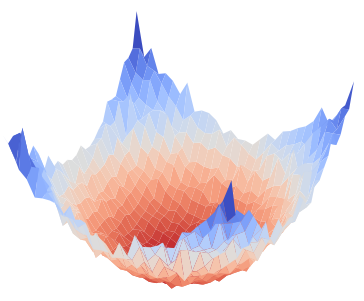
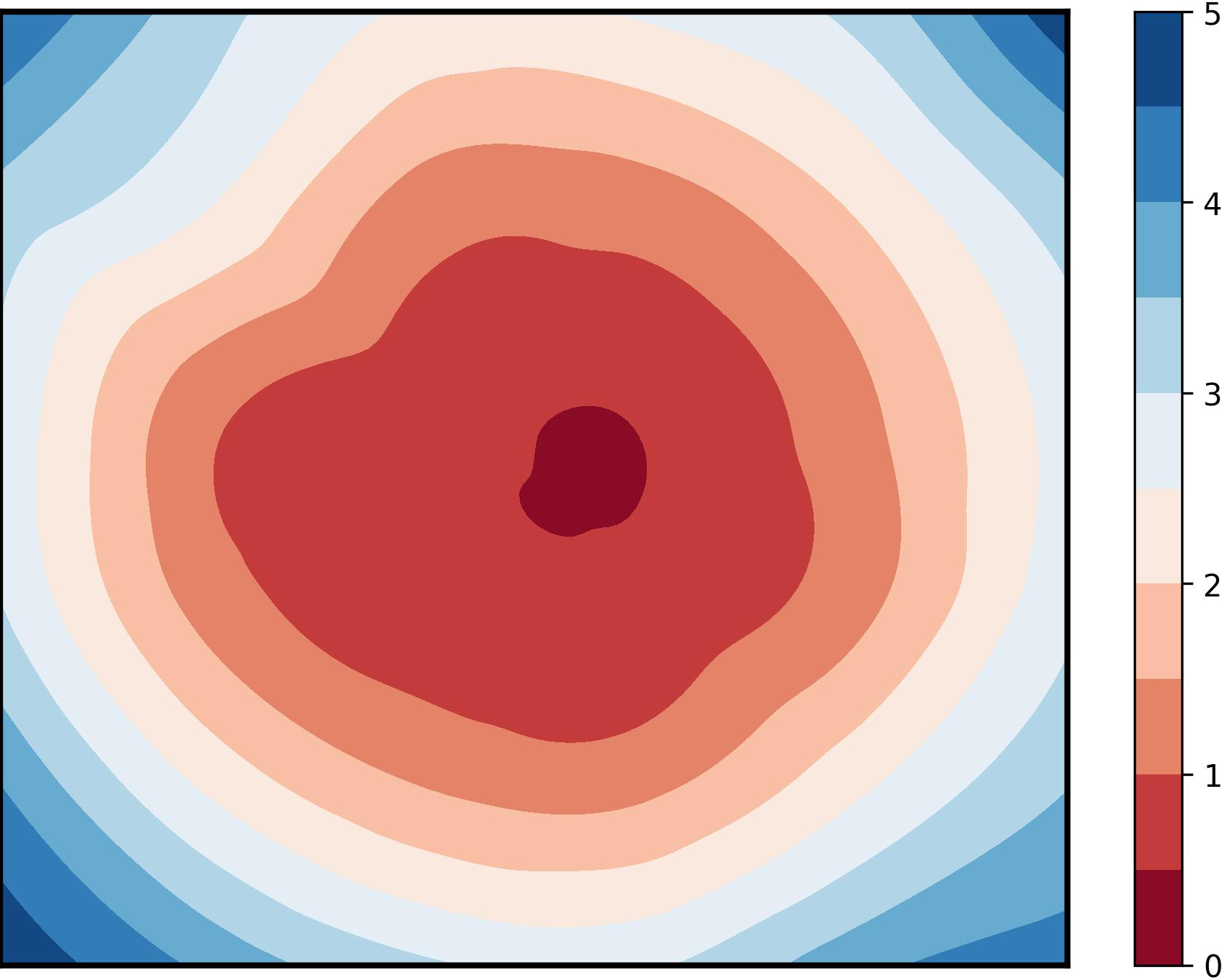
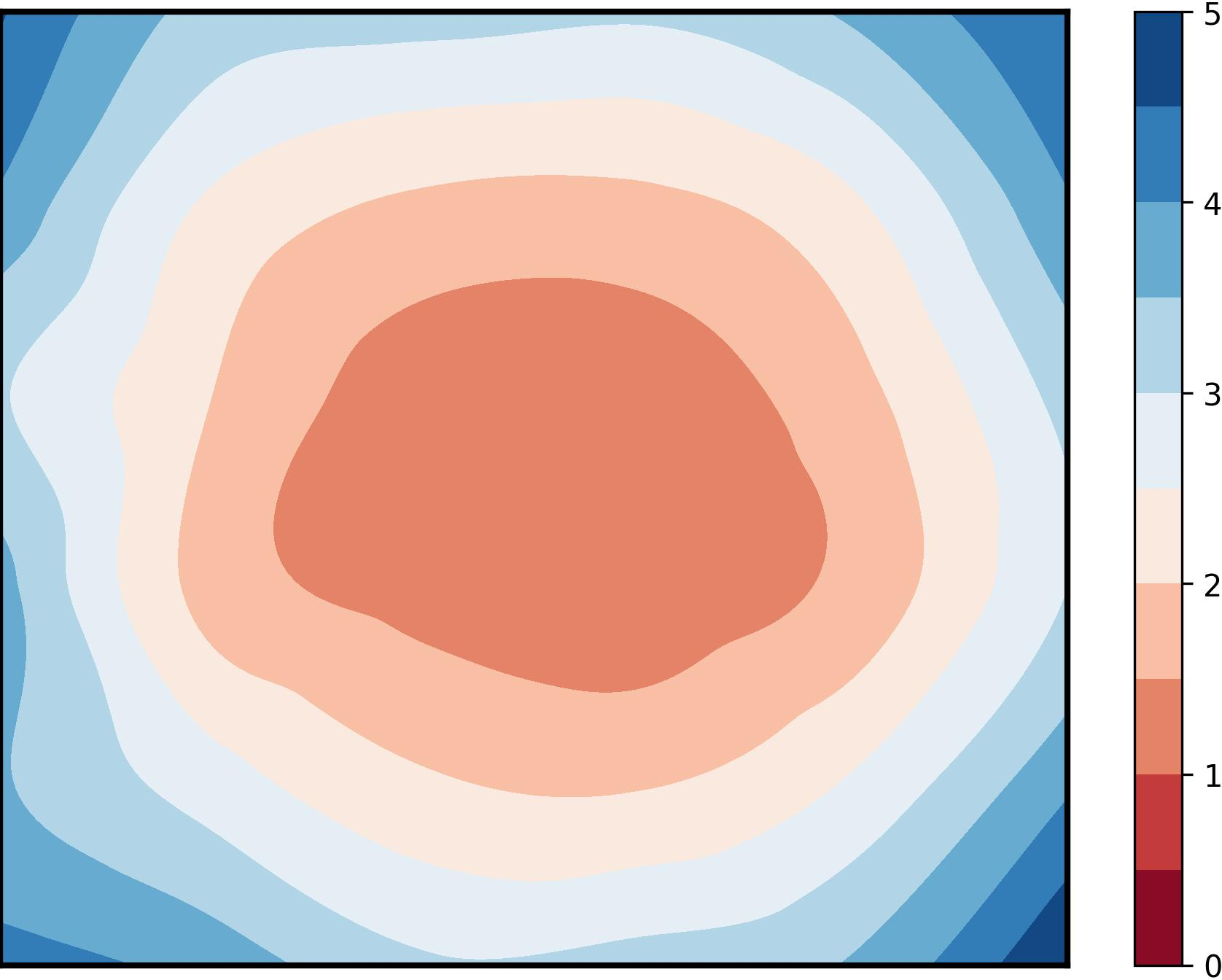
Figure 1: Visualization of global training loss surfaces for FedSAM under low (0.6) and high (0.1) heterogeneity, and the corrected global flatness alignment achieved by FedNSAM.
FedNSAM: Global Nesterov Momentum Correction for Federated SAM
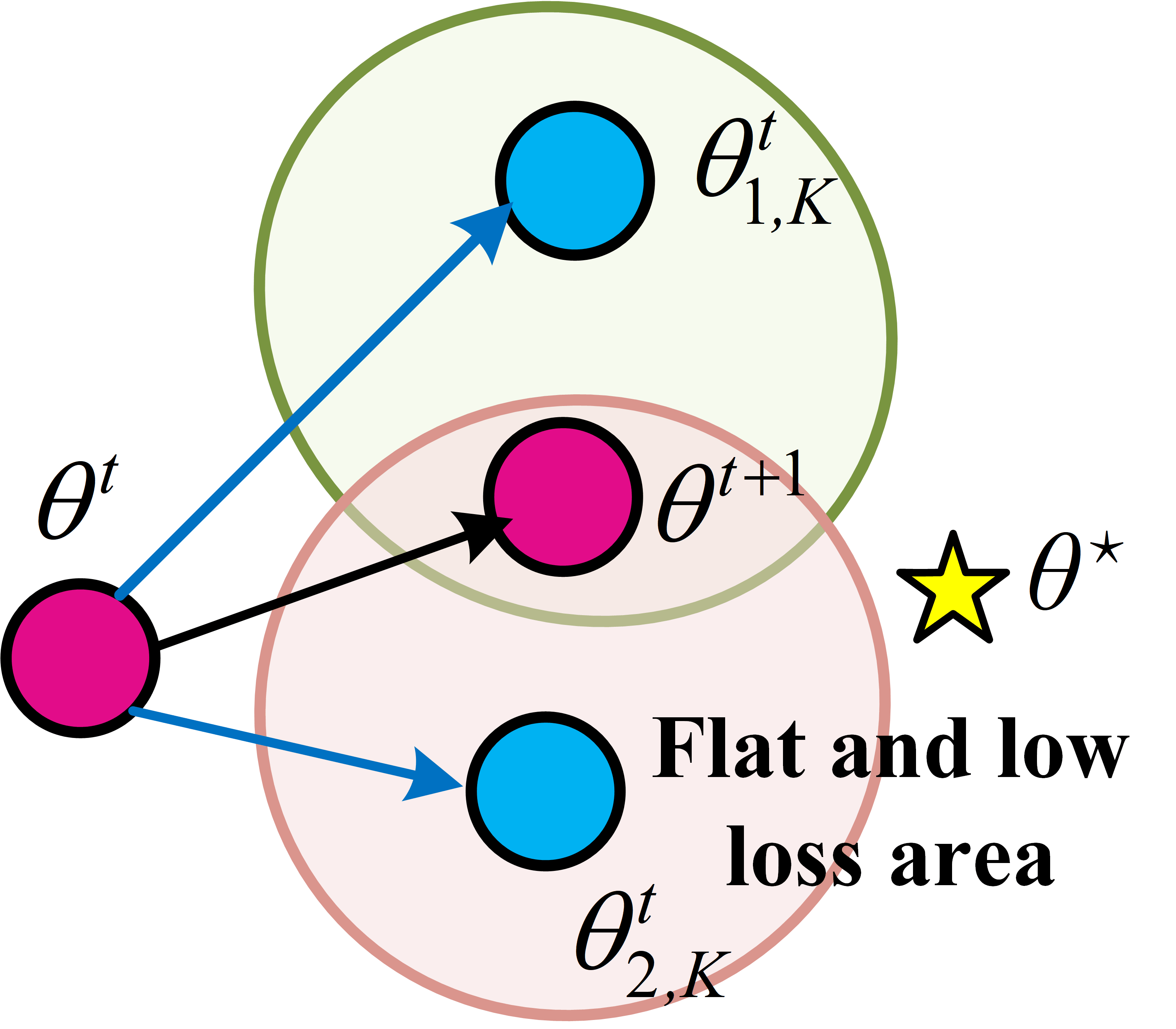
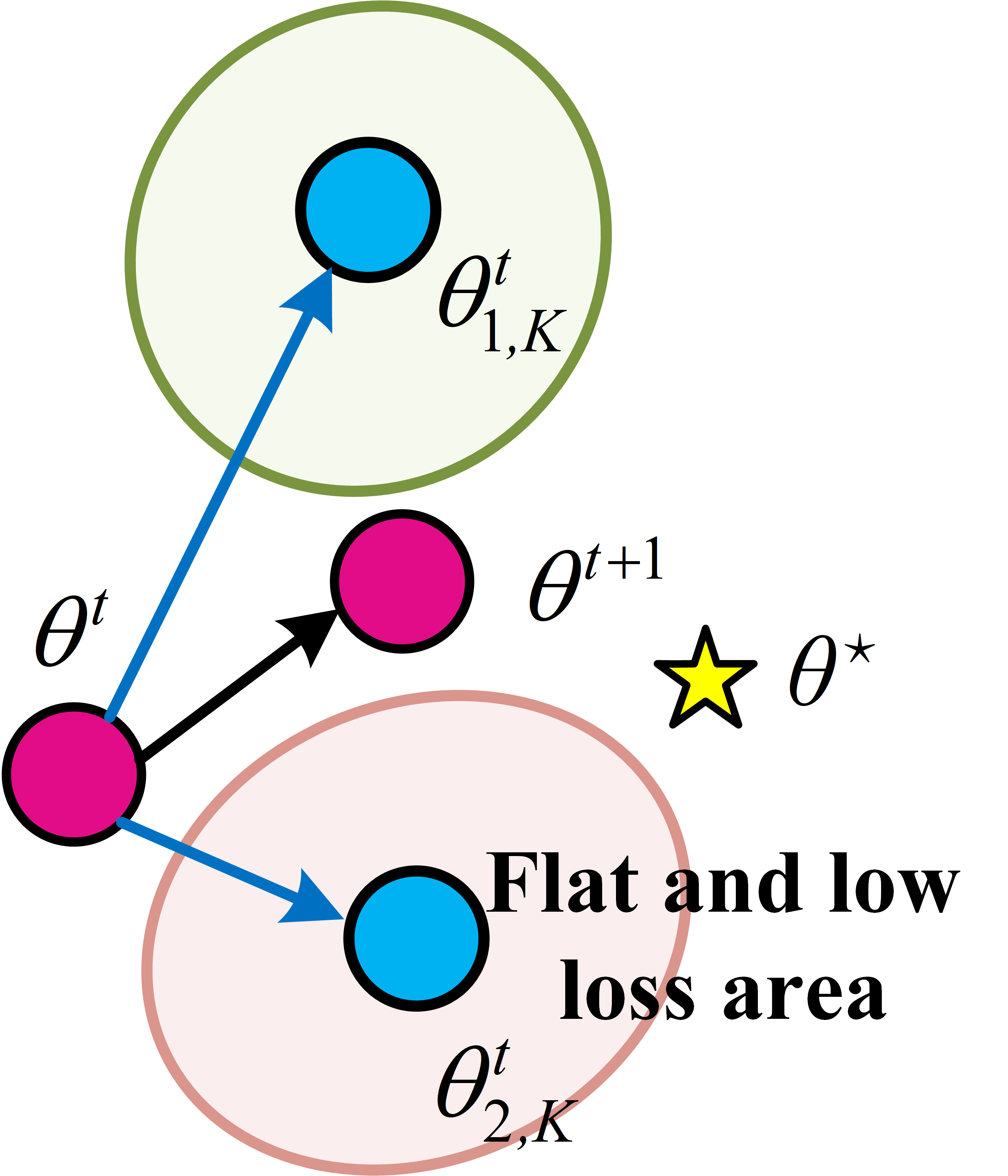
To reconcile local-global loss landscape inconsistencies, the FedNSAM algorithm augments local SAM updates with global Nesterov momentum extrapolation. This mitigates the flatness distance by aligning client-side sharpness-aware perturbations across communication rounds using an exponentially weighted global momentum vector. Specifically, FedNSAM applies Nesterov acceleration, using global momentum as the direction for both extrapolation and sharpness-aware perturbation within the local update procedure. This harmonizes the search for flat minima across clients and efficiently guides convergence toward flatter global minima.
Figure 2: Comparison between FedSAM local updates (a) and FedNSAM updates with global Nesterov momentum correction (b).
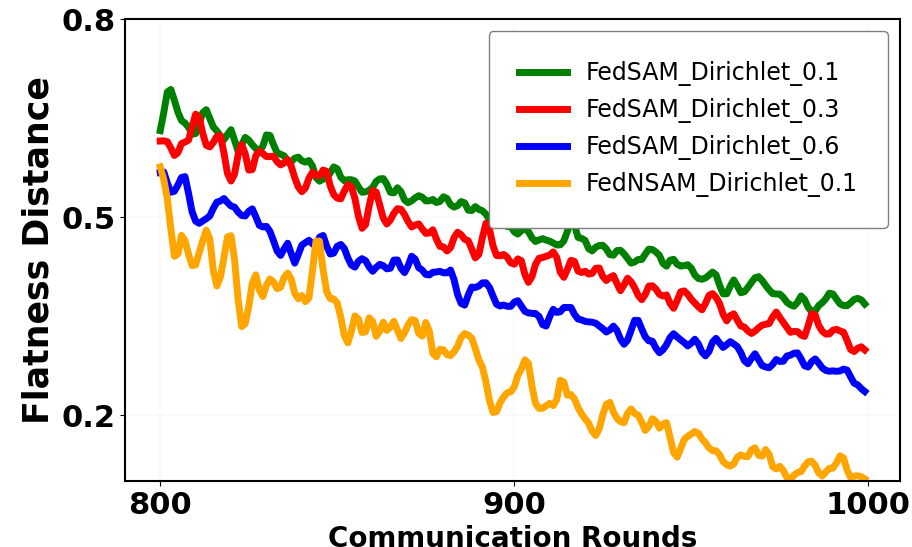
Theoretical Analysis: Convergence and Flatness Distance Bounds
Comprehensive non-convex convergence analysis establishes that FedNSAM achieves a rate of
O(LF/TKS(1−λ)), strictly tighter than FedSAM's previously established bounds. The upper bound for the flatness distance ΔD in FedNSAM is contingent on both client heterogeneity (σg2) and the momentum parameter λ, but benefits directly from exponential averaging, reducing the impact of stochastic gradient noise and partial participation. As a consequence, FedNSAM provides theoretically guaranteed improved alignment between local and global flat regions.
Figure 3: Flatness distance and global sharpness during federated training for varying heterogeneity levels and algorithmic choices.
Empirical Results: Robust Generalization Across Architectures and Participation Scenarios
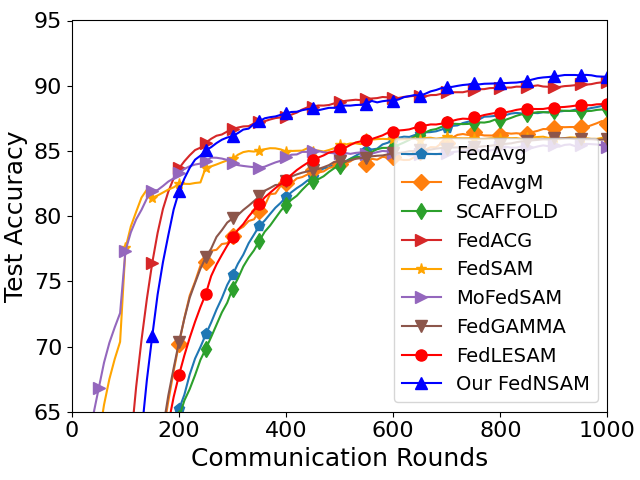
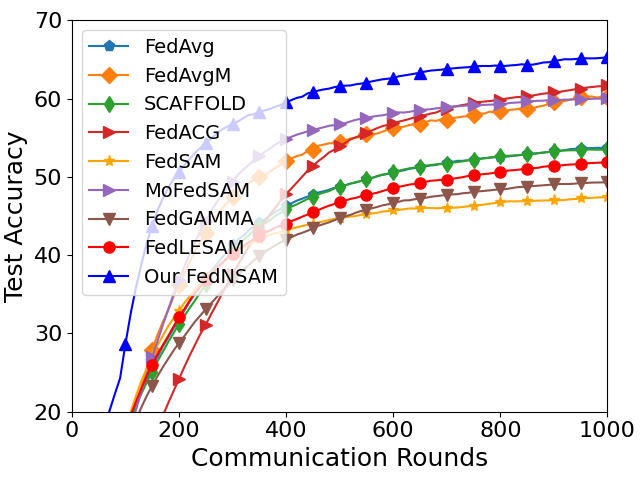
Extensive experiments demonstrate that FedNSAM consistently outperforms classical FL baselines (FedAvg, FedAvgM, SCAFFOLD, FedACG) and SAM-based variants (FedSAM, MoFedSAM, FedGAMMA, FedLESAM) in both accuracy and convergence speed. On CIFAR100 and Tiny ImageNet, FedNSAM yields substantial performance improvements—FedNSAM achieves 66.04% test accuracy on CIFAR100 with ResNet-18 under low heterogeneity, compared to FedSAM's 47.83%—and converges up to 3× faster. Notably, FedNSAM maintains superior accuracy under extremely low participation (2%) and strongly non-IID data splits, validating its stability and scalability.
Figure 4: Convergence trajectories for FedNSAM and baselines with ResNet-18 on CIFAR10 and CIFAR100, demonstrating accelerated convergence and improved final accuracy.
FedNSAM also consistently demonstrates greater generalization in vision transformer architectures (ViT-Base, Swin-Small, Swin-Base), obtaining test accuracies up to 71.23% with significantly fewer communication rounds.
Loss Surface Analysis: Flat Minima Attainment by FedNSAM
Visualization of global training and testing loss surfaces (CIFAR100, Dirichlet-0.1, ResNet-18) reveals that FedNSAM uniquely achieves broad, flat minima in both training and validation landscapes, whereas SAM-based and momentum-corrected baselines exhibit sharp loss surfaces indicative of poor generalization. These results substantiate FedNSAM's ability to systematically align client minima and maintain global flatness even in adverse heterogeneity scenarios.
Figure 5: Global training and testing loss surface plots for FedNSAM and baselines, highlighting FedNSAM's attainment of flatter and more generalizable minima.
Ablation Studies and Nesterov Momentum Effects
Ablation experiments confirm that FedNSAM's momentum-based extrapolation consistently enhances baseline methods in accuracy and convergence rounds. Variant studies further demonstrate FedNSAM's performance advantages when integrated into SCAFFOLD and FedDyn frameworks, underscoring its adaptability and the critical role of momentum correction in FL landscape alignment.
Implications and Future Directions
The FedNSAM framework addresses the pivotal issue of misaligned loss flatness in federated optimization, offering algorithmic and theoretical advances regarding global generalization guarantees under severe client-side heterogeneity. The momentum-based harmonization strategy exemplifies an efficient mechanism for aligning sharpness-aware perturbations and extrapolations in decentralized settings. Practically, FedNSAM enables robust distributed training in highly non-IID, low-participation regimes, directly relevant for real-world FL deployments in healthcare, finance, and edge computing. Theoretically, the convergence and flatness distance analysis extend current understanding of federated landscape geometry and optimization dynamics.
Future work can exploit FedNSAM's momentum correction principles in privacy-preserving and communication-limited federated setups, hybridizing with weight averaging or second-order preconditioning to further enhance generalization and robustness. Federated learning for foundation models and adaptable large-scale architectures will particularly benefit from extensions of flatness alignment mechanisms.
Conclusion
FedNSAM systematically harmonizes local and global loss landscape flatness in federated learning via global Nesterov momentum extrapolation, providing improved convergence, significantly enhanced generalization across architectures, and robustness to data heterogeneity and partial participation. The formalization of flatness distance and its reduction establishes a new standard for sharpness-aware federated optimization (2602.23827).
“Emergent Mind helps me see which AI papers have caught fire online.”
Philip
Creator, AI Explained on YouTube
Sign up for free to explore the frontiers of research
Discover trending papers, chat with arXiv, and track the latest research shaping the future of science and technology.Discover trending papers, chat with arXiv, and more.