- The paper introduces FreeDom, a retrieval-augmented test-time adapter that fuses textual and visual support for few-shot open-vocabulary segmentation.
- It retrieves class prototypes using k-nearest neighbor search in a joint embedding space, boosting mIoU performance by up to +18.4% with a single support image.
- The method supports varied support regimes and personalized segmentation, enabling dynamic adaptation without extensive retraining or large-scale annotations.
Retrieval-Augmented Adaptation for Few-Shot Open-Vocabulary Segmentation
Introduction
Open-vocabulary segmentation (OVS) leverages large-scale vision-LLMs (VLMs) for pixel-level prediction over arbitrary, user-specified class sets. Despite the generalization capacity enabled by VLMs, OVS remains significantly behind fully supervised approaches, especially on segmentation granularity and ambiguous categories due to (1) the coarse image-level supervision in pretraining, and (2) inherent ambiguity in natural language prompts. The paper "Retrieve and Segment: Are a Few Examples Enough to Bridge the Supervision Gap in Open-Vocabulary Segmentation?" (2602.23339) systematically investigates few-shot OVS and introduces FreeDom, a retrieval-augmented test-time adapter that fuses textual and visual support to construct an adaptive, per-image classifier. This method enables continual support expansion and application to fine-grained and personalized segmentation, addressing key limitations in open-world pixel-level recognition.
FreeDom: Architecture and Algorithmic Contributions
FreeDom utilizes frozen vision and text encoders (e.g., OpenCLIP, DINOv3.txt), augmenting zero-shot textual support with a dynamic set of pixel-annotated images for some or all categories. Visual features are pooled from support masks and combined with textual class features via learned fusion. At inference, the method retrieves relevant class prototypes from both modalities to assemble a lightweight linear classifier tuned per test image.
The retrieval is executed at the patch or region (when mask proposals are available) level, using k-nearest neighbor search in the joint visual-textual embedding space. The classifier's cross-entropy loss incorporates class-relevance weighting, derived from the image-level similarity between the test image and each class prototype. This ensures adaptation focuses primarily on classes actually present in the image and suppresses spurious predictions from unrelated support exemplars.
The method generalizes to various support regimes:
- Full support: All classes have text and at least one visual exemplar.
- Partial visual support: Only some classes have visual exemplars, all have text.
- Partial textual support: Only some classes have text, all have visual exemplars.
- Zero-shot: Only text is available.
Dynamic expansion and continual adaptation to new support instances is supported without retraining the underlying backbone, and fusion is performed via learned, not heuristic, mixing.
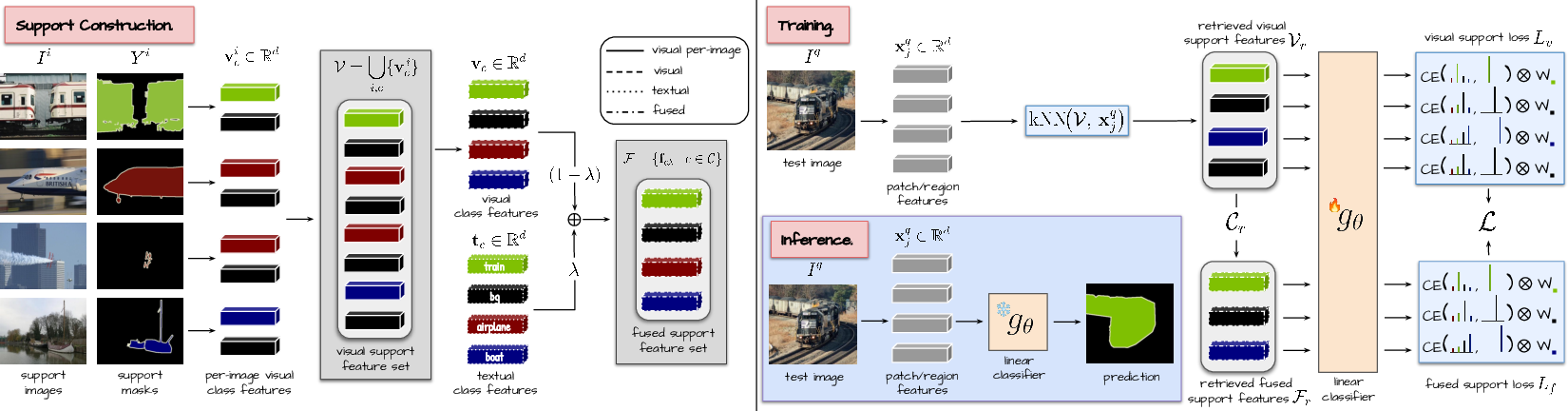
Figure 1: Overview of FreeDom with full textual and visual support: per-class visual features are aggregated and fused with text; retrieval and test-time adaptation construct a specialized classifier per test image.
Segmentation with Multimodal Support: Fusion and Retrieval
The fusion mechanism is crucial for leveraging the complementary strengths of textual and visual support. For each class, visual prototypes are aggregated and then blended with the text prototype via a tunable mixing coefficient. Class relevance scores, computed by comparing the test image's pooled feature with each text prototype, modulate the contribution of each support class to adaptation.
The retrieval step guarantees that only relevant prototypes — those closest in the embedding space to the test image's features — participate in classifier training, effectively mitigating noise from visually distant or contextually irrelevant classes. Varying the number of neighbors (K) demonstrates that moderate values suffice for stable, strong performance gains, and the adaptation is robust to typical hyperparameter choices.
Experimental Results and Analysis
Bridging the Zero-Shot–Supervised Segmentation Gap
FreeDom achieves significant improvements over prior retrieval-augmented and baseline methods, both in terms of mean Intersection-over-Union (mIoU) and qualitative segmentation quality. With even a single annotated support image per class, FreeDom narrows the mIoU gap with fully supervised segmentation by several points. For B=1 (one support image per class), FreeDom boosts mIoU by +7.3% (OpenCLIP) and +18.4% (DINOv3.txt) over zero-shot segmentation.
On six OVS benchmarks (PASCAL VOC, Cityscapes, ADE20K, etc.) and with both patch- and region-level (e.g., with SAM 2.1 proposals) adaptation, FreeDom consistently outperforms competitors including kNN-CLIP and FreeDA, especially as the size of the support set increases.

Figure 2: Qualitative comparison of textual-only, visual-only, and multimodal FreeDom support: only the fused approach reliably resolves semantic ambiguities and improves mask alignment.
Robustness to Partial Support and Personalized Segmentation
Under partial visual support (i.e., only a subset of classes have visual exemplars), FreeDom smoothly degrades and maintains performance even as fewer classes are supported, outperforming methods dependent on complete support for all classes. A pseudo-labeling mechanism for classes lacking visual support further mitigates this degradation, leveraging zero-shot predictions to synthesize prototypes from the query image itself.
Similarly, in partial textual support regimes, replacing missing text features with a neutral average prototype preserves adaptation quality without significant bias.
Personalized segmentation — segmenting specific object instances rather than broad categories — is naturally supported in FreeDom: simply appending exemplar masks for a particular instance enables accurate segmentation without any architectural change. This is confirmed both qualitatively and quantitatively.

Figure 3: Personalized segmentation: by appending instance-specific examples, FreeDom distinguishes between generic class and personalized object, enabling fine-grained adaptive masks.
Mask-level Inference and Qualitative Behavior
Mapping adaptation from patch-level to mask-level (region proposals via strong foundation models like SAM 2.1) produces more accurate segmentation boundaries and further increases mIoU, with FreeDom benefiting most from strong underlying features. The method is robust to support image and prototype selection, and ablation studies demonstrate the necessity of class relevance weighting, learned fusion, and intelligent retrieval.





















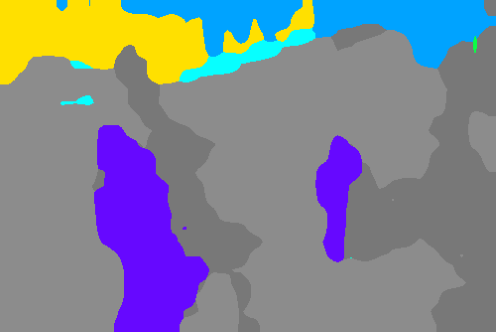



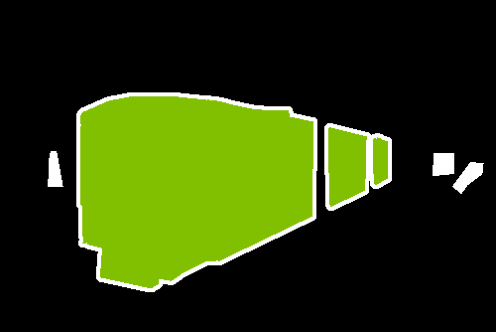





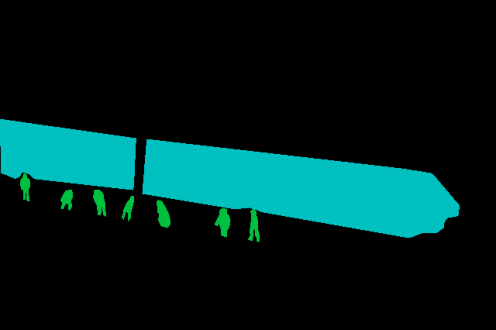


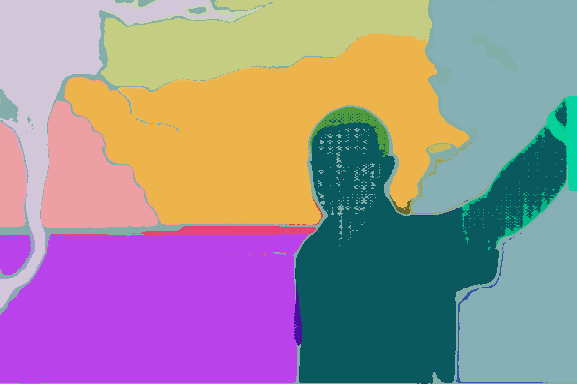


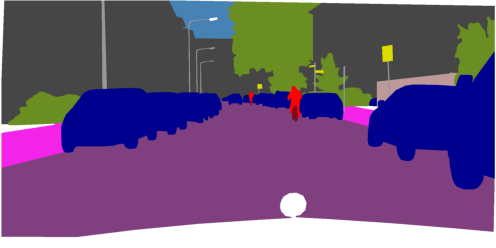

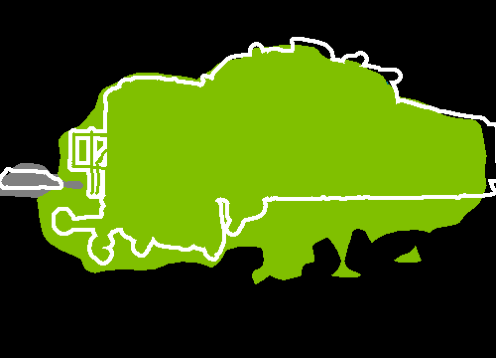

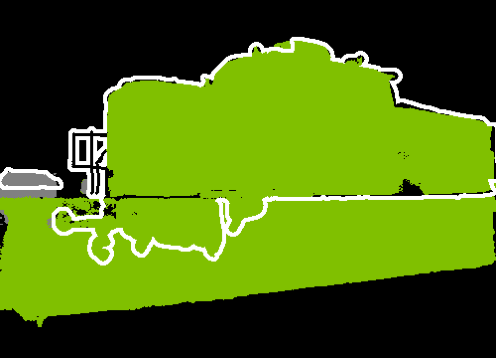
Figure 4: Patch-level vs. mask-level FreeDom on DINOv3.txt: region-based inference incorporates higher-level structure, producing sharper and more coherent segmentation masks.


















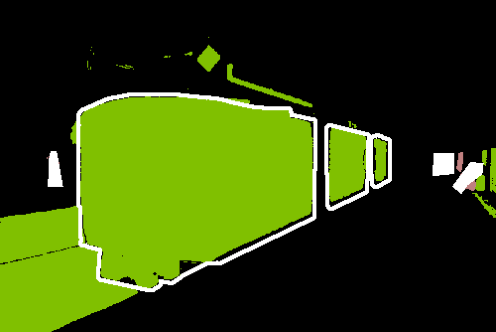

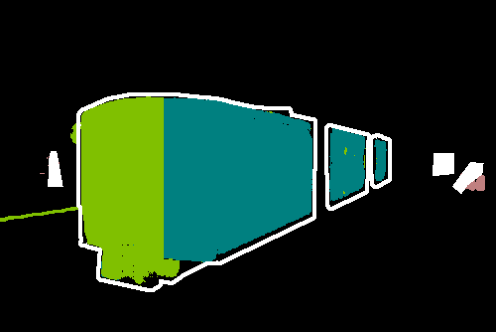
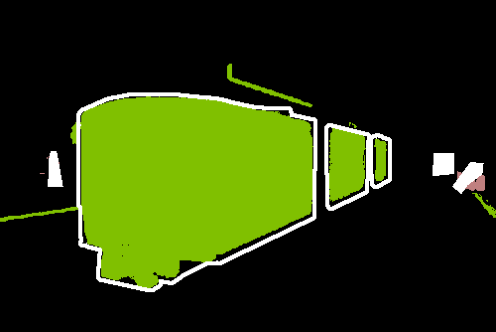

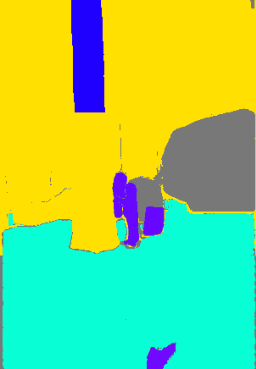








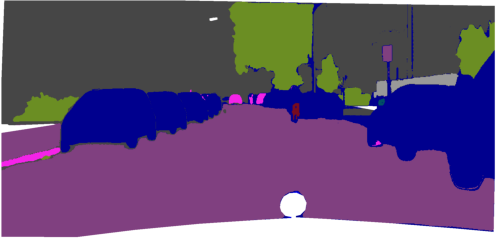
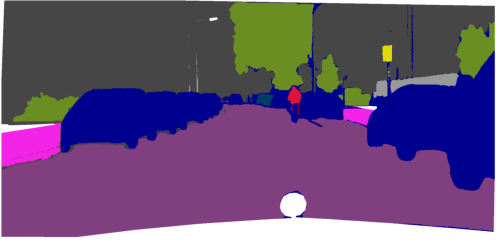
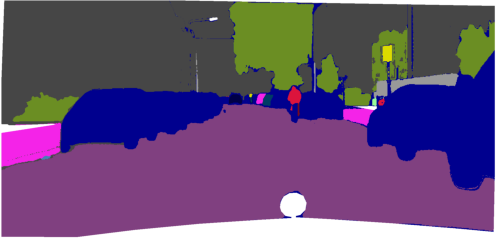

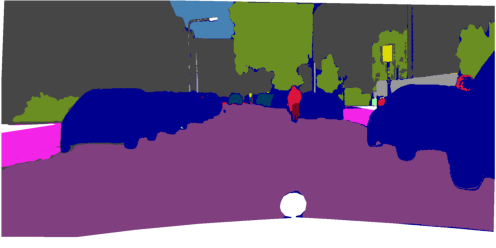
Figure 5: Qualitative comparisons show FreeDom's fused support resolves ambiguity and context confusion, outperforming zero-shot and alternative retrieval-augmented baselines.
Theoretical and Practical Implications
FreeDom's design aligns with current trends in scalable open-world perception and retrieval-based model augmentation. By decoupling adaptation from expensive backbone retraining and instead relying on efficient retrieval and fusion, the approach allows continual support expansion, domain transfer, and rapid adaptation to novel or fine-grained categories. The ability to fall back on zero-shot text-based prototypes where visual exemplars are missing preserves the core open-vocabulary property.
This paradigm suggests that scalable segmentation in open or dynamic environments does not fundamentally require large-scale pixelwise annotation, provided a minimal set of support exemplars can be efficiently incorporated at test time. As foundation VLMs grow stronger and multimodal retrieval improves, the supervision gap between open-vocabulary and closed set models will likely continue to narrow.
Moreover, FreeDom's architectural modularity makes it amenable to extension: integration with memory-augmented retrieval, efficient region proposal generators, or emerging text-to-mask generative priors are natural next steps.
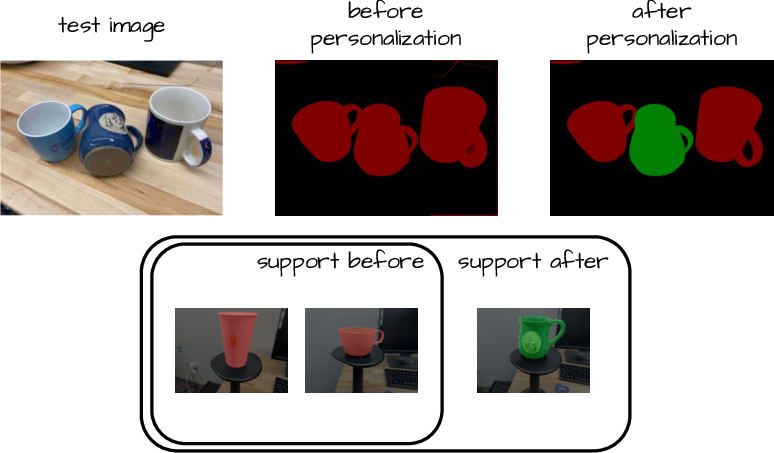
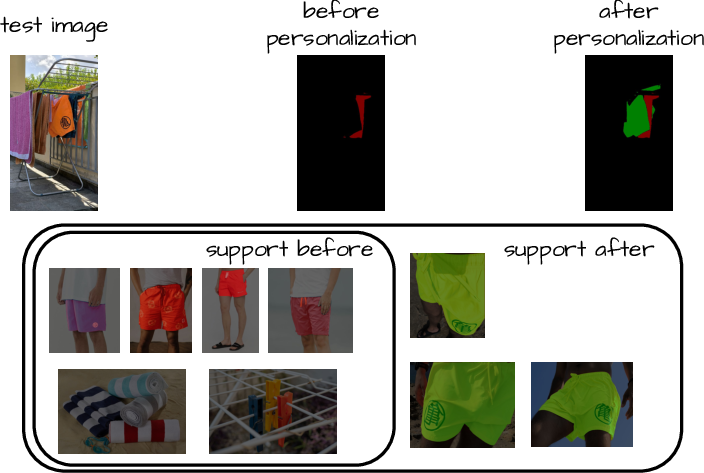
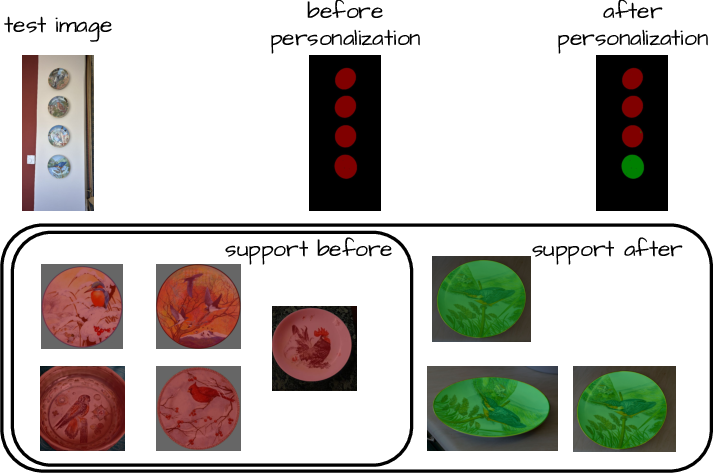
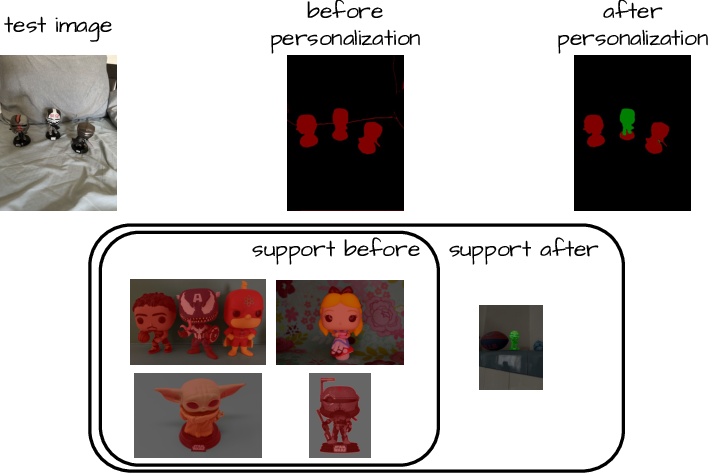
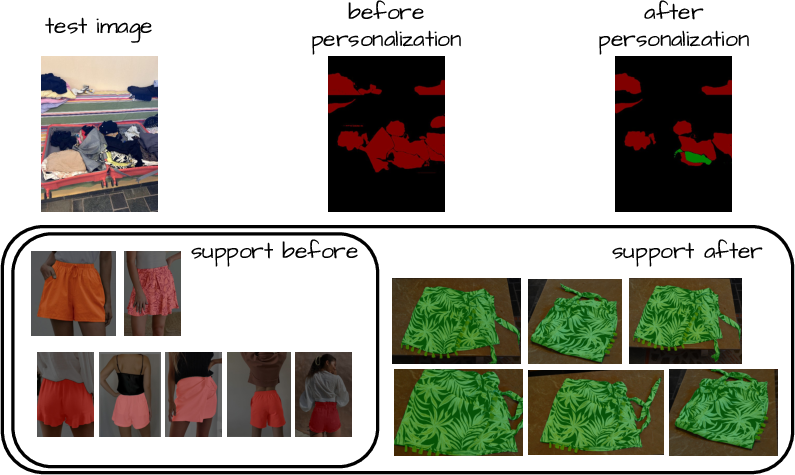
Figure 6: Continuous visual support expansion: as more annotated exemplars are added, segmentation accuracy improves organically, highlighting FreeDom's suitability for learning in evolving open-world contexts.
Conclusion
This work establishes a strong framework for bridging the supervision gap in open-vocabulary segmentation by introducing FreeDom, a retrieval-augmented, multimodal test-time adapter. FreeDom fuses textual and visual support via learned mechanisms and constructs sample-specific classifiers by leveraging efficient prototype retrieval. The method consistently outperforms state-of-the-art OVS competitors and narrows the gap to fully supervised segmentation with remarkably small support sets. Its dynamic nature enables efficient adaptation in settings ranging from generic OVS to personalized, instance-level tasks, and opens a path for scalable, flexible perception systems in continually changing environments (2602.23339).