- The paper presents GEPA, a prompt optimisation method that significantly improves error detection in medical notes using a Pareto frontier for prompt evolution.
- It leverages the diverse MEDEC dataset and multiple LLM configurations, with GEPA-optimised GPT-5 nearly matching clinician-level accuracy.
- Empirical results show reduced false positives and enhanced specificity, demonstrating GEPA’s superiority over baseline prompt strategies and multi-agent systems.
Importance of Prompt Optimisation for Error Detection in Medical Notes Using LLMs
Background and Motivation
The identification of errors in medical text is critical for patient safety and the reliability of clinical workflows. Despite advances in LLMs, robust error detection remains insufficiently addressed, especially in settings requiring precise reasoning across complex medical narratives. LLM capabilities are limited by training data biases and prompt design; thus, systematic prompt optimisation approaches are necessary for both frontier models (e.g., GPT-5) and privacy-preserving SLMs such as Qwen3. The MEDEC benchmark dataset provides controlled evaluation of error detection performance, capturing both exam-style text (MS) and authentic clinical notes (UW) with injected errors. Previous benchmarks demonstrate that frontier LLMs achieve suboptimal performance and suffer from significant distributional shifts between MS and UW subsets.
Dataset and Experimental Workflow
The study utilizes MS training and validation splits from the MEDEC dataset for prompt optimisation via GEPA, and evaluates on MS and UW test splits. Error detection is formulated as a binary classification: narratives are either correct or contain exactly one clinically meaningful error. The experiments include seven LLMs (GPT-5, Grok-4, Gemini-2.5-Pro, Claude-Sonnet-4.5, and Qwen3 variants) evaluated in 28 reflector–inference configurations.
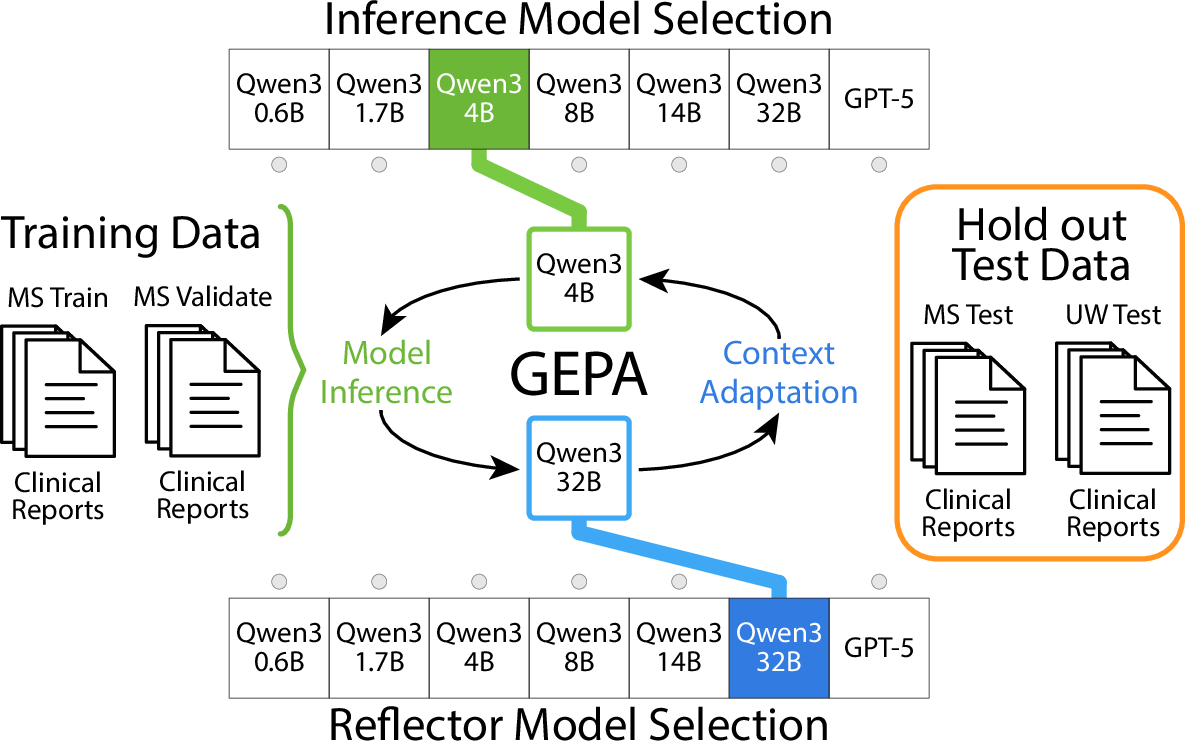
Figure 1: The experimental pipeline uses MEDEC dataset subsets for GEPA-driven prompt optimisation, leveraging both commercial frontier and open-source local models.
The MEDEC dataset captures diverse error types, with significant differences in distribution between its MS and UW splits.
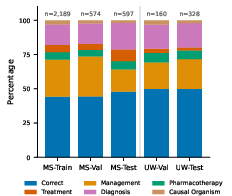
Figure 2: Distribution of sample categories across different splits in the MEDEC dataset, illustrating data heterogeneity and domain shift.
Genetic-Pareto (GEPA) Prompt Optimisation
GEPA is a reflective prompt evolution algorithm, alternating inference on mini-batches with feedback-driven prompt revision. The paradigm separates the inference model (deployed for clinical use) and reflector model (used during optimisation), allowing for cross-model prompt evolution. Prompt candidates are maintained on a Pareto frontier, with validation performance driving selection. Rich, natural language feedback is provided to the reflector, explicitly encoding both error identification and clinical reasoning gaps. GEPA enables flexible optimisation: strong frontier models (e.g., GPT-5) can reflect for smaller, locally deployed models (e.g., Qwen3), addressing privacy, security, and context window constraints.
Empirical Results
Baseline evaluations with the P1 prompt reveal that frontier LLMs outperform local SLMs on MS data, but all models exhibit accuracy degradation on the out-of-distribution UW split. Notably, Gemini-2.5-Pro underperforms across both splits, while Claude-Sonnet-4.5 displays an inverse performance trend. GEPA optimisation delivers systematic accuracy improvements for most reflector–inference pairs, with the largest gains observed for the largest LLMs.
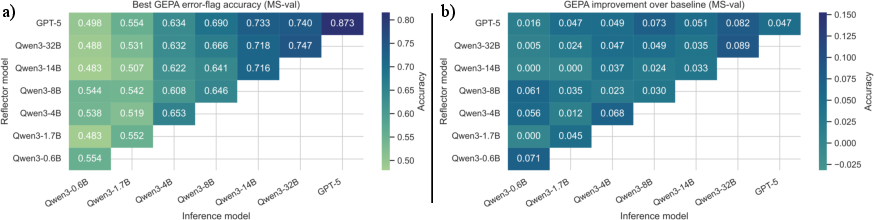
Figure 3: GEPA optimisation increases error detection accuracy for numerous reflector–inference pairs and yields substantial improvements over baseline prompts.
GEPA-driven prompt evolution achieves state-of-the-art performance on MEDEC, surpassing previous approaches including MediFact and multi-agent debate systems. The optimised GPT-5 model attains accuracy approaching medical doctor benchmarks (MS+UW weighted accuracy: 0.785 versus doctor's 0.796/0.716).
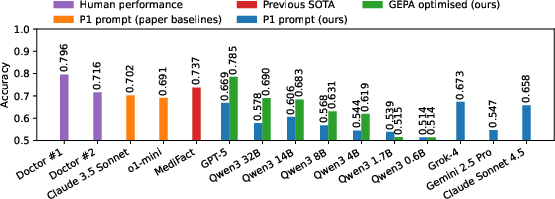
Figure 4: Comparison of combined MEDEC test set accuracy for multiple models and approaches, highlighting the superior performance of GEPA-optimised GPT-5.
Detailed pairing results illustrate that GEPA leverages larger reflectors to enhance both frontier and SLMs, and prompt transfer generalises from MS to UW splits.
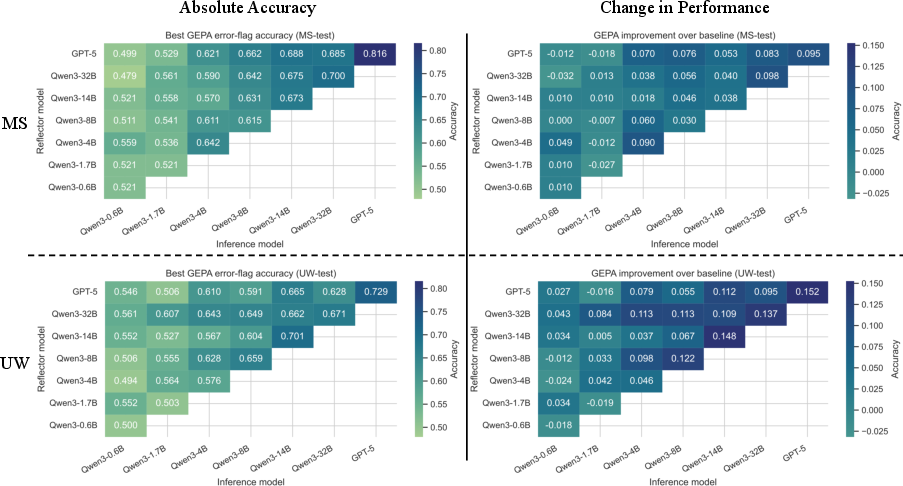
Figure 5: GEPA prompt optimisation across reflector/inference pairings for both MEDEC-MS and MEDEC-UW test sets, demonstrating generalisation and improvement versus baseline.
Confusion matrix analysis shows that GEPA-optimised models achieve better specificity, reducing over-prediction of errors and false positive rates. Prompts evolved through GEPA explicitly instruct conservative classification strategies, justify decision thresholds, and encode domain-specific medical knowledge.
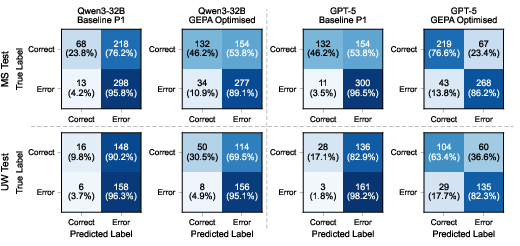
Figure 6: Confusion matrices for Qwen3-32B and GPT-5 before and after GEPA optimisation, indicating improved balance in error detection and reduction in false positives.
Additionally, results for Qwen3 variants demonstrate that GEPA delivers accuracy improvements even for small models constrained by compute and context window.
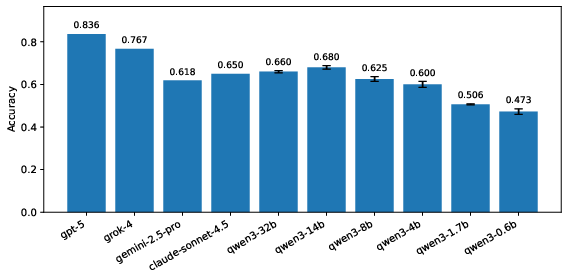
Figure 7: Validation performance on MEDEC-MS using the P1 prompt for Qwen3 models averaged across random seeds.
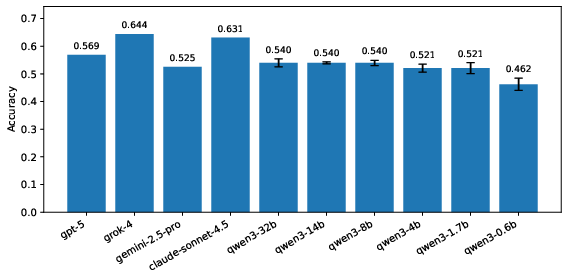
Figure 8: Validation performance on MEDEC-UW using the P1 prompt for Qwen3 models, with variability across seeds.
Implications and Future Directions
Automated prompt optimisation via GEPA enables LLMs—including both frontier and locally deployed SLMs—to approach clinician-level performance in error detection tasks, with accuracy improvements that can transfer across domain shifts. This approach circumvents the requirements and governance issues associated with gradient-based fine tuning, offering short, auditable, and modifiable prompts. In practical terms, it aligns well with ELCAP guidelines for background AI systems that continuously monitor for errors while maintaining clinical authority.
Theoretically, GEPA demonstrates that prompt evolution can outperform RL-based prompt optimisers and multi-agent systems, suggesting that rich feedback mechanisms and Pareto frontier selection are critical for robust task alignment in medical NLP. For future developments, integration with domain-specific reflective feedback, adaptive reflector selection, and expansion to other clinical NLP tasks (e.g., correction, summarization, reasoning) are promising.
Conclusion
The paper rigorously demonstrates that prompt optimisation using Genetic-Pareto reflective evolution substantially enhances LLM error detection performance in medical notes. GEPA increases accuracy for frontier and local models, generalises across data distributions, and achieves state-of-the-art results on the MEDEC benchmark. The approach offers practical auditability and adaptability, presenting a viable route to deploy AI-based error detection in clinical practice. Prompt engineering remains a decisive factor in LLM performance for complex medical reasoning tasks.

