Global-Aware Edge Prioritization for Pose Graph Initialization
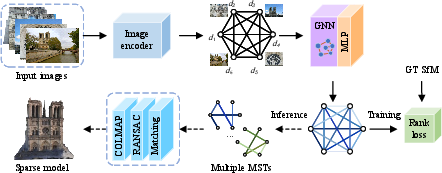
Abstract: The pose graph is a core component of Structure-from-Motion (SfM), where images act as nodes and edges encode relative poses. Since geometric verification is expensive, SfM pipelines restrict the pose graph to a sparse set of candidate edges, making initialization critical. Existing methods rely on image retrieval to connect each image to its $k$ nearest neighbors, treating pairs independently and ignoring global consistency. We address this limitation through the concept of edge prioritization, ranking candidate edges by their utility for SfM. Our approach has three components: (1) a GNN trained with SfM-derived supervision to predict globally consistent edge reliability; (2) multi-minimal-spanning-tree-based pose graph construction guided by these ranks; and (3) connectivity-aware score modulation that reinforces weak regions and reduces graph diameter. This globally informed initialization yields more reliable and compact pose graphs, improving reconstruction accuracy in sparse and high-speed settings and outperforming SOTA retrieval methods on ambiguous scenes. The ode and trained models are available at https://github.com/weitong8591/global_edge_prior.












Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Global-Aware Edge Prioritization for Pose Graph Initialization — A Simple Explanation
What is this paper about?
When you build a 3D model from many photos (like making a 3D map of a building from tourist pictures), the computer must figure out which photos go together and how the cameras were positioned. This early step creates a “pose graph,” where:
- each photo is a point (a node), and
- a line between two photos (an edge) means “these two likely see the same part of the scene.”
Checking every possible photo pair is too slow, so most systems only check a small set. This paper proposes a smarter way to choose those pairs by looking at the whole collection at once (not just photo-by-photo), so the system gets a strong, reliable starting graph and builds better 3D models faster.
What questions does the paper try to answer?
The authors focus on three simple questions:
- How can we pick the most useful photo pairs to check, using information from the entire set of photos, not just from one photo at a time?
- Can we train a model to “guess” which pairs are trustworthy by learning from past 3D reconstructions?
- Can we build a small but strong connection network (the pose graph) that stays stable even when things are tricky (few checks allowed or many look‑alike photos)?
How did they do it? (Methods in everyday terms)
Think of each photo as a town and each possible connection as a road. We want to build just enough roads to connect all towns so people can travel easily—without building every possible road.
The approach has three main parts:
- Step 1: Predict which photo pairs are good matches using global reasoning
- Each photo is turned into a compact “fingerprint” (an image descriptor).
- A Graph Neural Network (GNN)—you can imagine it as a “group discussion” among photos—looks at all photos together and predicts how reliable each possible pair is for building 3D.
- How is it trained? The model learns from previous 3D projects using two automatic signals:
- How many “inlier” matches a pair had during a robust matching step (RANSAC). More inliers → more reliable.
- How many 3D points both photos saw in common in a finished reconstruction. More shared points → more useful in the big picture.
- Instead of predicting exact numbers, the model learns to rank pairs (who should be first, second, third…), which is what we really care about.
- Step 2: Build the initial pose graph with multiple minimum spanning trees (MSTs)
- A minimum spanning tree connects all towns with the fewest roads and smallest total “cost.” Here, edges with higher predicted reliability get lower cost, so the “best” edges are chosen.
- One tree alone can be fragile—if one wrong edge breaks, whole regions might fall apart. So they build several MSTs that don’t reuse the same edges and then combine them. This gives backup routes without adding too many edges.
- Step 3: Make the graph tighter with connectivity-aware score boosting
- After building the first tree, the method checks how far apart photos are in the current graph (in “hops”).
- If two parts of the graph are far apart, it slightly boosts edges that would connect them directly, reducing the longest path in the network.
- To stay safe, it only boosts very promising candidates (top ones per photo) and ignores low-confidence edges.
- Scaling to large photo sets
- For very big collections, they split the problem into smaller chunks (graph clustering), run the predictor on each chunk, and then combine results.
What did they find, and why is it important?
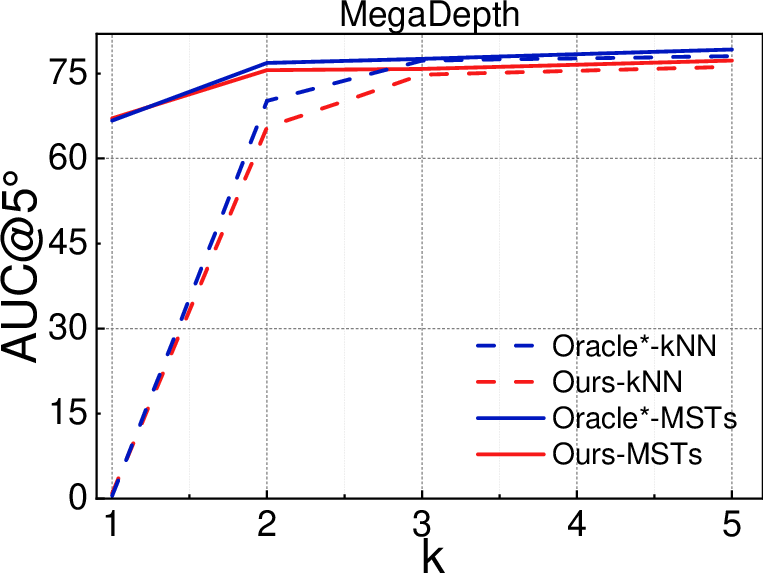
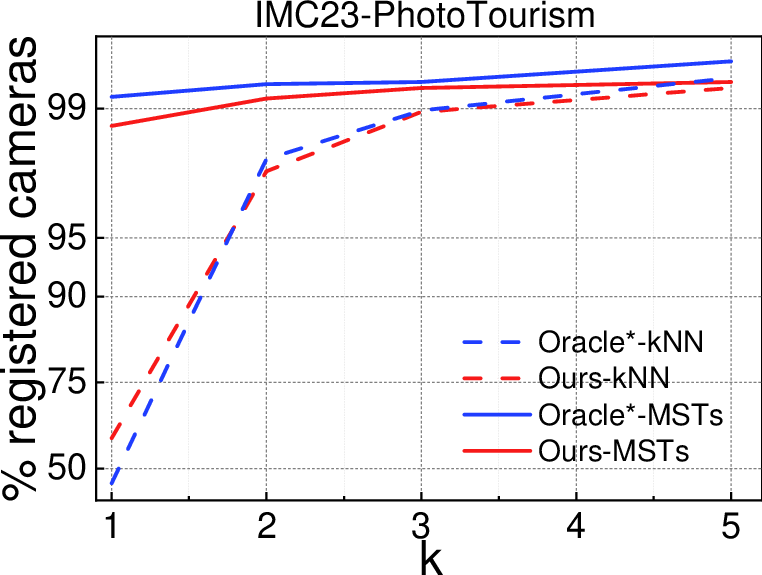
Across several big benchmarks, the method outperforms strong baselines, especially when the graph must be very small (few edges checked) or when scenes are tricky:
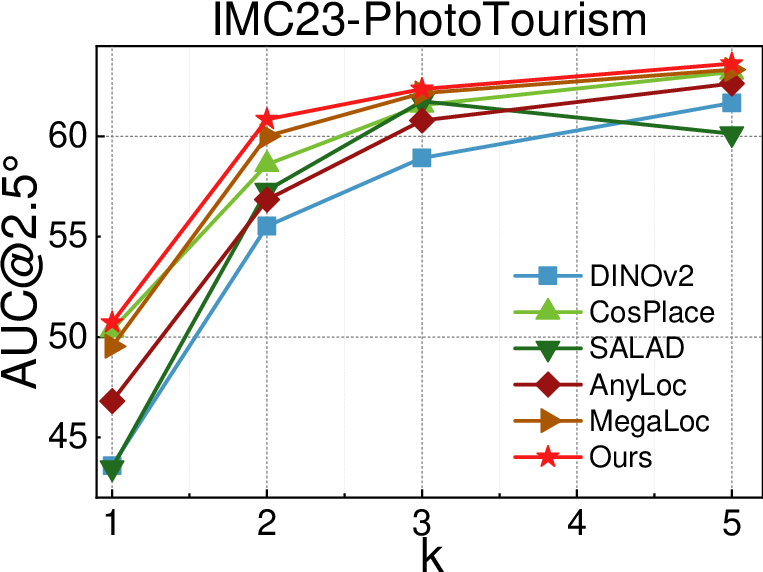
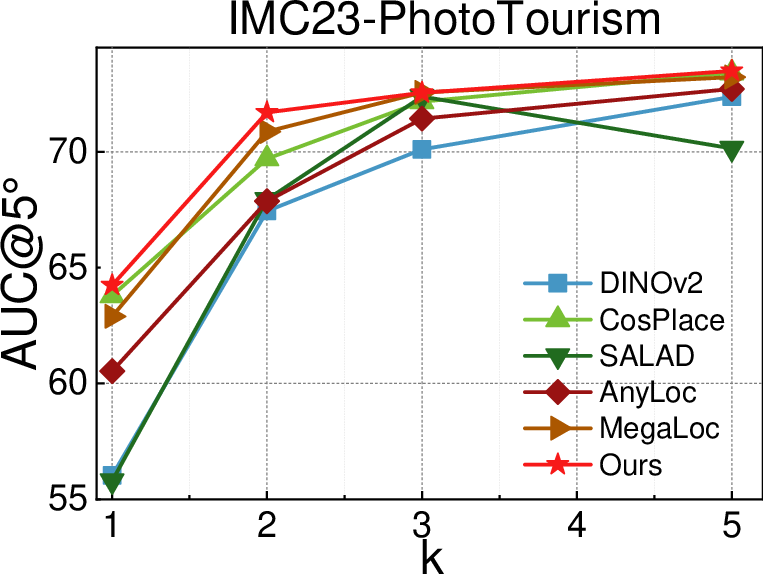
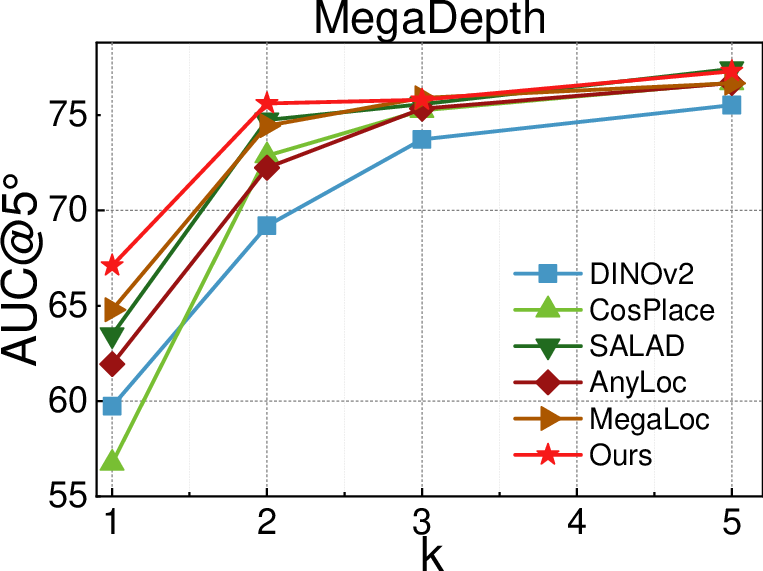
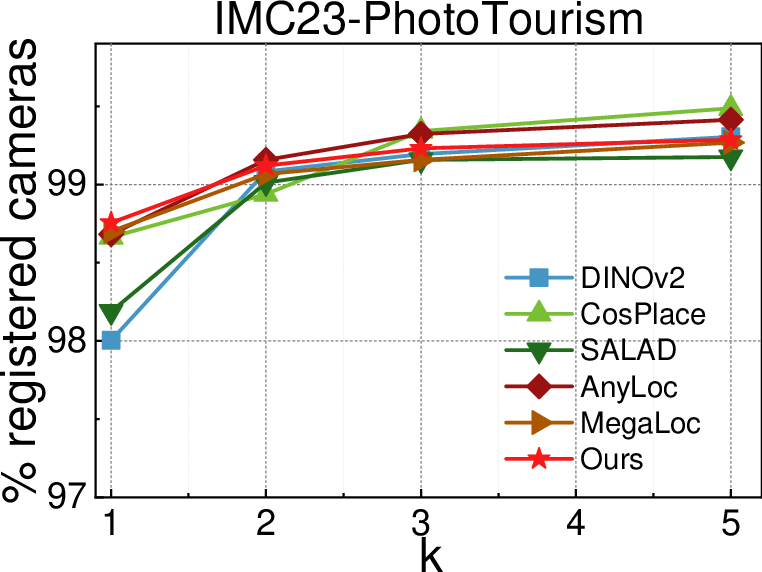
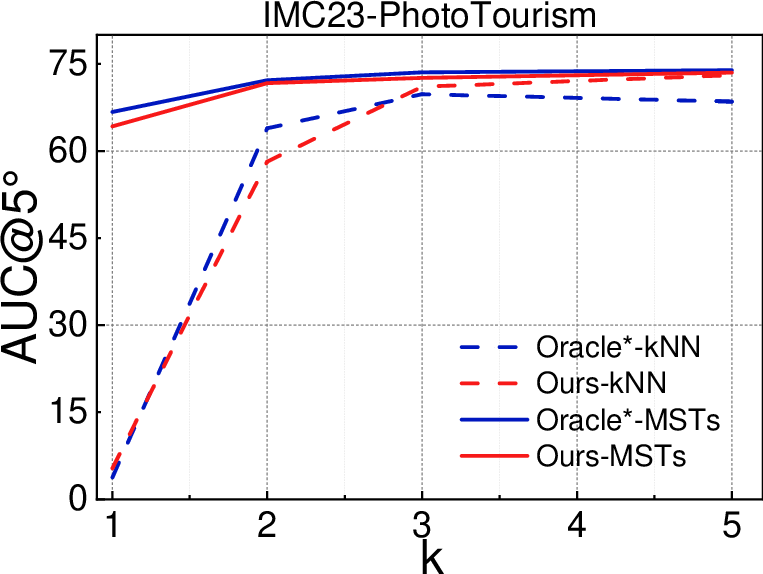
- Better accuracy with fewer checks
- On large datasets (PhotoTourism and MegaDepth), they get more accurate camera poses, especially when only 1–2 MSTs are used (the “sparse regime”). That means better 3D quality while checking fewer pairs.
- Stronger graphs than standard methods
- Choosing edges via multiple MSTs gives more globally connected graphs than the usual “connect to your k closest neighbors” trick. This reduces long, shaky chains and creates better overall structure.
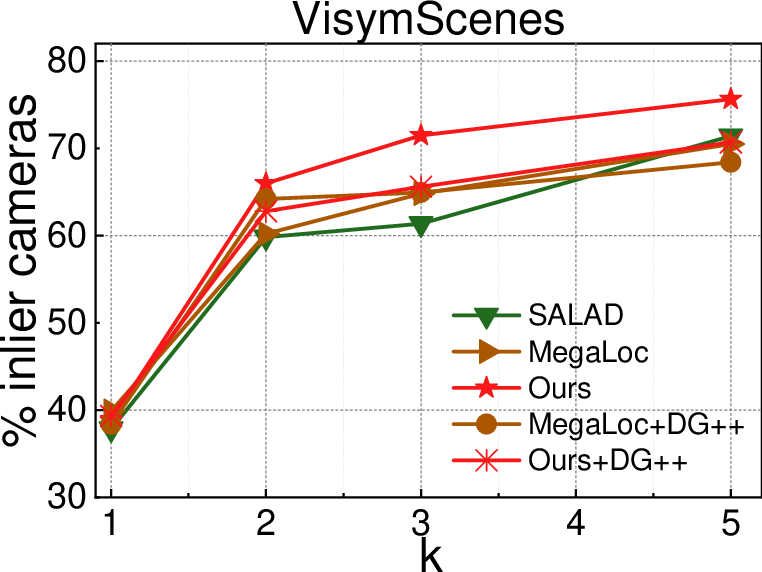
- Robust to confusing, look‑alike photos
- On a tough dataset with “doppelganger” images (different places that look very similar), their method reconstructs more correct cameras than top image-retrieval systems. It even rivals or surpasses a specialist “doppelganger” filter in tests.
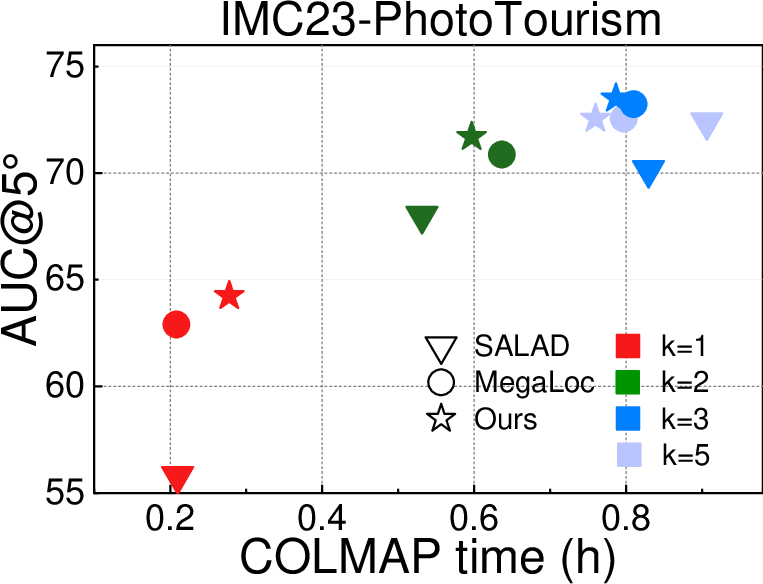
- Good speed–quality trade-off
- The extra prediction step is small compared to the heavy parts of 3D reconstruction, and better initial edges can make the later steps faster and more stable.
Why does this matter?
- Stronger starts make better 3D models. If you pick good pairs early, later steps have fewer errors to fix.
- It saves time and compute, which helps in real-world uses like mapping, augmented reality, robotics, and self-driving—especially when you must work fast or have limited resources.
- It handles confusing scenes better (like cities with many similar-looking buildings), making reconstructions more reliable.
- It’s easy to plug into existing 3D pipelines: the method only changes how you choose which image pairs to verify, not the rest of the process.
In short, this paper shows how thinking globally—ranking all possible photo pairs by their overall usefulness and building multiple, smartly chosen “backbone” connections—leads to more reliable and efficient 3D reconstructions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Scalability to very large image sets: The method assumes a complete graph and computes per-edge features for all pairs; the paper provides no complexity analysis or empirical scaling beyond N≈500 (where METIS is used), nor strategies for candidate pruning when N reaches 10k–100k images.
- Ambiguity in candidate generation: The pipeline alternately describes operating on a complete graph and “given a set of input image pairs,” leaving unclear how candidate pairs are formed at inference for large-scale settings without incurring O(N2) costs.
- Distance-modulation cost and complexity: The connectivity-aware modulation requires repeated shortest-path computations; the paper lacks time/memory complexity bounds, algorithmic details (e.g., BFS vs. APSP), and scaling measurements for large graphs and multiple MST iterations.
- Hyperparameter sensitivity and adaptivity: Key parameters (λ in score modulation, number of MSTs k, “top-5 candidates per image” update rule, and 0.9 rank threshold) are not systematically analyzed; no adaptive or data-driven tuning strategies are provided.
- Graph-theoretic guarantees: There is no theoretical analysis proving that union-of-k MSTs plus distance modulation decreases graph diameter, improves robustness to edge failures, or optimizes global SfM objectives (e.g., conditioning of motion averaging).
- Modulation signal design: The use of unweighted hop-count distances ignores edge confidence; it is unclear whether weighted shortest paths, centrality, community structure, or alternative global criteria (e.g., minimizing diameter directly) would yield better connectivity and robustness.
- Diversity and redundancy in multi-MST selection: Masking previously selected edges enforces edge-disjoint trees but does not guarantee diversity across clusters or baselines; there is no study of diversity constraints (e.g., orthogonality, matroid constraints) or coverage objectives.
- Budget fairness and cost–accuracy trade-offs: Comparisons with kNN are not normalized for equivalent verification budgets; a principled framework for equalizing edge counts and computational costs across selection strategies is missing.
- Labeling and supervision quality: Geometry-derived labels (RANSAC inliers and “joint 3D points” v_ij) require running SfM and may be noisy; the 1000-inlier normalization threshold appears ad hoc and dataset-specific. Robustness to label noise, low-overlap scenes, and cross-domain shifts is not analyzed.
- Domain generalization breadth: The model is trained on MegaDepth and evaluated on PhotoTourism and VisymScenes; generalization to indoor, aerial/UAV, endoscopic, or multi-sensor datasets (e.g., fisheye, rolling shutter) is unexplored.
- Integration with global SfM pipelines: Despite motivations in global SfM, evaluations are limited to COLMAP (incremental). Performance with global pipelines (e.g., GLOMAP) and motion averaging steps is missing.
- Retrieval/reranking baselines: The paper does not compare against strong pairwise rerankers (e.g., Patch-NetVLAD, VOP) or methods that exploit overlap prediction; the extent to which global edge prioritization improves over advanced reranking remains unclear.
- Feature and edge representation: Edge features use only endpoint embeddings and cosine similarity; the benefit of incorporating patch-level overlap estimates, predicted baselines, spatial priors (GPS/EXIF), or geometric proxies (e.g., homography cues) is not explored.
- End-to-end training and joint optimization: The encoder is largely frozen and trained separate from matching; whether end-to-end training with local matching networks (e.g., LightGlue) and rank supervision improves performance remains untested.
- Uncertainty calibration: Predicted ranks are used with hard thresholds (e.g., 0.9) without calibration analysis (e.g., ECE) or uncertainty-aware selection/verifier scheduling.
- Interaction with downstream verification: The paper does not quantify how the initialization affects the number of verified edges, failure rates in RANSAC, or sensitivity to early pruning; a study of end-to-end effects on edge acceptance would be valuable.
- Quantitative connectivity metrics: While the method claims diameter reduction and stronger connectivity, the paper does not report graph metrics (diameter, average shortest path, clustering coefficients) before/after modulation and across k.
- Runtime breakdown at scale: The runtime table is limited and CPU-only for COLMAP; there is no breakdown of GNN inference, multi-MST selection, and distance computations on large scenes or GPU-based SfM pipelines.
- Ambiguous/distractor handling: The interaction with Doppelganger++ is minimal (no benefit from applying DG++ post hoc); a principled fusion of global edge ranks with doppelganger detection or other ambiguity filters is not investigated.
- Sequential/temporal data: The method ignores temporal priors in video sequences; integrating temporal adjacency and testing on sequential datasets is an open direction.
- Message passing architecture choices: Only two iterations with simple MLPs are used; ablations on the number of layers/iterations, attention-based GNNs, or heterogeneous graphs (node/edge types) are absent.
- Robustness to camera intrinsics and calibration noise: Effects of incorrect intrinsics, lens distortion, rolling shutter, and varying focal lengths on edge ranking and MST selection are not studied.
- Verification scheduling: The framework does not exploit rank information to order/early-stop geometric verification (e.g., Bayesian early termination, adaptive RANSAC iterations), leaving potential efficiency gains unexplored.
- Evaluation metrics breadth: Results focus on relative pose AUC and registration rate; missing are 3D accuracy metrics (e.g., reprojection error, point cloud quality), loop-closure consistency, and drift analyses.
- Failure mode characterization: The appendix shows qualitative failures but lacks systematic analysis linking error cases to graph properties (e.g., long chains, weak regions), rank errors, or MST structure.
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed now by plugging the paper’s “global edge prioritization” module into existing Structure-from-Motion (SfM) and photogrammetry workflows.
- Bold drop-in pose-graph initializer for COLMAP and similar SfM toolchains Replaces kNN-based image-pair selection with GNN-ranked, multi-MST selection and connectivity-aware score modulation to reduce verification workload and improve reconstruction accuracy, especially in sparse/high-speed settings and ambiguous scenes. Sectors: software, academia, AEC/surveying, cultural heritage. Tools/products/workflows: open-source code and trained models; pre-step that computes image embeddings, predicts edge scores with the GNN, builds the union of k MSTs, then runs standard matching/RANSAC/BA only on selected pairs. Assumptions/dependencies: compatible image encoder (e.g., DINOv2/SALAD/MegaLoc); local features/matchers (e.g., SuperPoint+LightGlue, SIFT) still required; GPU for descriptor extraction/GNN if run at scale; parameters k and λ require light tuning.
- Cloud photogrammetry cost and runtime reduction Prioritize only globally useful image pairs for geometric verification to cut CPU/GPU time in large-scale pipelines (e.g., city blocks, construction sites), without compromising or even improving accuracy. Sectors: software/SaaS photogrammetry, mapping, AEC, media/VFX. Tools/products/workflows: microservice for “edge scoring + multi-MST construction” wrapped around COLMAP/RealityCapture-style pipelines; batch inference across jobs; graph clustering (e.g., METIS) for large N. Assumptions/dependencies: cost savings scale with dataset size and ambiguity; requires integration into existing job schedulers; descriptor computation remains a nontrivial cost.
- Robust reconstruction in visually ambiguous environments (doppelgangers, repeated facades) Pre-verification filtering via globally aware edge scores avoids distractor matches, improving completeness/accuracy in dense urban and repetitive indoor scenes. Sectors: urban mapping, heritage digitization, retail/e-commerce catalogs with repetitive items. Tools/products/workflows: replace or complement Doppelganger++-style filters with learned pre-selection; use connectivity-aware modulation to shorten long chains and reduce graph diameter. Assumptions/dependencies: still relies on downstream verification to remove residual outliers; model generalization to new domains may benefit from light fine-tuning.
- Visual Positioning System (VPS) map-building improvements (offline) Faster, more reliable reference map construction from crowdsourced or fleet-collected images; benefits pose-graph connectivity and loop robustness in complex venues. Sectors: AR/VR, indoor/outdoor localization, navigation. Tools/products/workflows: deploy as an offline preprocessing stage for database/map updates; re-rank loop-closure candidates by global utility before verification. Assumptions/dependencies: map-building is typically offline and can use GPUs; quality still depends on coverage/overlap.
- Construction progress and drone survey turnarounds Accelerate site recon from unordered drone shots while maintaining accuracy; particularly valuable when verification budgets are tight or datasets are sparse. Sectors: AEC/surveying, infrastructure inspection. Tools/products/workflows: drop-in initializer for photogrammetry jobs; parameter presets for “sparse budget” (small k) with strong global connectivity. Assumptions/dependencies: no guarantee of reduced image count; benefits come from better pair selection and graph health, not acquisition changes.
- Crowdsourced and archival photo 3D recon (museums, tourism boards) Improve reconstructions from heterogeneous, noisy collections with varied viewpoints and duplicates. Sectors: cultural heritage, tourism, digital archives. Tools/products/workflows: batch processing on archival sets; automatic suppression of misleading pairs; diagnostics on graph connectivity to guide curation. Assumptions/dependencies: archival images may have extreme domain shifts; consider fine-tuning encoder/GNN if needed.
- Dataset curation and “graph health” diagnostics Use predicted edge scores and connectivity measures (e.g., graph diameter, weak regions) to automatically flag under-constrained components, tune k and λ, and predict reconstruction risk before heavy compute. Sectors: academia, industry R&D, platform QA. Tools/products/workflows: small dashboard exposing graph statistics (diameter, components, per-node degree, “weak region” alerts) and k–accuracy/cost trade curves. Assumptions/dependencies: requires storing/visualizing graph metrics; simple to add once scoring is available.
- Research baseline for learning-to-rank with geometry supervision Adopt the released code/models as a baseline for edge-ranking research, ablation studies (e.g., different backbones, losses), and new SfM initialization tasks. Sectors: academia, industrial research labs. Tools/products/workflows: ready-to-run repository; extendable to alternative supervision signals and encoders; reproducible experiments on MegaDepth/PhotoTourism/VisymScenes. Assumptions/dependencies: GPU availability for training; adherence to dataset licenses.
- Faster, more reliable mobile photo-scanning via cloud backends Consumer scanning apps can offload images and use global edge prioritization in their server-side recon, returning models faster with fewer “failed scans” in cluttered scenes. Sectors: consumer/daily life, creator economy. Tools/products/workflows: API endpoint that performs embedding + GNN ranking + MST; existing apps (e.g., Polycam-like services) integrate as a pre-processing step. Assumptions/dependencies: relies on cloud execution; on-device execution is currently heavyweight (see long-term on-device item).
Long-Term Applications
Below are opportunities that require additional research, engineering, scaling, or domain extension before broad deployment.
- Real-time SLAM loop-closure candidate selection with global edge reasoning Adapt the GNN + connectivity-aware scoring to streaming settings to prioritize loop closures that shrink pose-graph diameter on the fly. Sectors: robotics, autonomous systems, AR devices. Tools/products/workflows: incremental/online GNN, dynamic MST/forest maintenance, latency-aware edge scoring; integration with VIO/VSLAM back-ends. Assumptions/dependencies: requires low-latency embeddings, lightweight/quantized models, and incremental graph updates; careful resource management on embedded hardware.
- Active acquisition and next-best-view planning guided by connectivity Use distance-modulated scores to propose viewpoints that close long chains and strengthen weak regions during capture, reducing shots needed for a well-conditioned graph. Sectors: robotics, drones, AEC/surveying, digital twins. Tools/products/workflows: bidirectional feedback loop between capture system and pose-graph health; online estimation of “graph benefit” from a candidate shot. Assumptions/dependencies: needs predictive models of view overlap and on-site planning; hinges on reliable global estimates early in capture.
- Cross-modal pose graphs (camera–LiDAR, multi-spectral, thermal) Extend “edge prioritization” beyond images to heterogeneous constraints and multi-sensor descriptors. Sectors: autonomous driving, defense, inspection. Tools/products/workflows: multimodal encoders, cross-modal message passing, unified edge-utility scores, multi-modal MST construction. Assumptions/dependencies: training data with cross-modal ground truth; robust multi-sensor embedding learning.
- Internet-scale, distributed 3D reconstruction from web-scale photo sets Scale GNN inference and multi-MST selection across millions of images via hierarchical clustering/partitioning and distributed compute. Sectors: mapping, tech platforms, research benchmarks. Tools/products/workflows: distributed embedding extraction, METIS-like hierarchical partitioning, model sharding, overlap handling across partitions. Assumptions/dependencies: cluster orchestration, fault tolerance, and privacy/compliance for user-contributed images.
- Energy- and carbon-aware photogrammetry standards and procurement Formalize “global edge prioritization” as a recommended practice to reduce compute and energy in public-sector mapping and heritage digitization. Sectors: policy/government, environmental compliance. Tools/products/workflows: cost/energy reporting for k MST configurations; standardized metrics for pose-graph compactness vs. accuracy; procurement checklists. Assumptions/dependencies: third-party validation of savings; acceptance by agencies and vendors; alignment with sustainability frameworks.
- Privacy-preserving and on-device edge ranking Bring embedding and GNN inference on-device (or via federated learning) to keep images local while still guiding efficient recon. Sectors: consumer, enterprise with privacy constraints. Tools/products/workflows: model compression/quantization, mobile-friendly encoders, sparse graph sampling on-device. Assumptions/dependencies: hardware acceleration (NPUs), memory-efficient clustering, and energy constraints.
- Quality control automation in 3D content pipelines (media/gaming/digital twins) Enforce “graph health” gates (diameter thresholds, weak-region detection) before expensive texturing/meshing; trigger targeted re-capture or additional matching where needed. Sectors: media/VFX, gaming, industrial digital twins. Tools/products/workflows: CI/CD-like stages for 3D asset creation; automated remediation tickets for problematic regions. Assumptions/dependencies: integration with DCC tools and asset management; thresholds tuned to content standards.
- Multi-robot and cross-session map merging with prioritized inter-session edges When fusing sessions or robots, score cross-session pairs by global utility to ensure robust connectivity across teams and times. Sectors: robotics, logistics, infrastructure inspection. Tools/products/workflows: cross-session embedding normalization, inter-session MSTs, conflict resolution among heterogeneous sensors. Assumptions/dependencies: consistent calibration/metadata; careful handling of seasonal/appearance changes.
- Formal API/productization of a “Graph-Aware Matcher” library Package the method as a supported SDK/API with presets for sparse, balanced, and high-ambiguity regimes, plus analytics on accuracy–cost trade-offs. Sectors: software vendors, systems integrators. Tools/products/workflows: language bindings (C++/Python), telemetry for runtime/cost vs AUC, deployment guides for cloud and on-prem. Assumptions/dependencies: long-term maintenance, model updates as encoders evolve (e.g., new vision foundation models).
Glossary
- Area Under the Recall Curve (AUC): A scalar metric summarizing recall over varying thresholds; used here to evaluate relative pose accuracy. "we report Area Under the Recall Curve (AUC) at and "
- bundle adjustment: A nonlinear optimization that refines camera poses and 3D points jointly to minimize reprojection error. "Incremental pipelines register images sequentially with repeated bundle adjustment; they are robust in practice but can drift and scale poorly."
- COLMAP: A widely used SfM and MVS pipeline for feature matching, reconstruction, and evaluation. "COLMAP reconstruction~\cite{schonberger2016structure} performance using pose graphs constructed from multiple MSTs guided by baseline embedding similarities or our learned global edge ranks."
- DINOv2-SALAD: A visual feature pipeline combining DINOv2 features with SALAD token aggregation for robust image descriptors. "DINOv2-SALAD~\citep{izquierdo2024optimal} aggregates patch tokens via optimal transport,"
- DoppelGanger++: A doppelganger filtering method that removes visually similar but geometrically inconsistent image pairs. "Applying DoppelGanger++ on top of our scores provides no further benefit,"
- Doppelganger detection: Techniques to detect and remove visually similar yet geometrically unrelated image pairs to prevent false matches. "Doppelganger detection~\citep{cai2023doppelgangers, xiangli2025doppelgangers++} removes visually similar but geometrically inconsistent pairs."
- geometric verification: The process of validating feature matches (often via robust estimation) to confirm geometric consistency between image pairs. "Since geometric verification is expensive, SfM pipelines restrict the pose graph to a sparse set of candidate edges,"
- Graph Neural Network (GNN): A neural architecture that performs message passing over graphs to learn context-aware representations. "we train a Graph Neural Network (GNN) with SfM-derived supervision to predict globally informed edge scores."
- graph clustering: Partitioning a large graph into smaller subgraphs to improve scalability and memory efficiency during processing. "To scale to large image collections, we employ graph clustering~\citep{chen2020graph, damblon2025learning}."
- graph diameter: The maximum shortest-path distance (in hops) between any two nodes in a graph, indicating overall connectivity tightness. "and (3) connectivity-aware score modulation that reinforces weak regions and reduces graph diameter."
- Kruskal’s algorithm: A greedy algorithm for computing a minimum spanning tree by adding edges in order of increasing weight without forming cycles. "Each MST is found by Kruskalâs algorithm~\citep{kruskal1956shortest}."
- LambdaRank: A learning-to-rank approach that optimizes ranking metrics by modeling the impact of pairwise swaps on the objective. "we adopt NDCGLoss2++~\citep{wang2018lambdaloss}, built upon the LambdaRank algorithm~\citep{burges2006learning, burges2010ranknet},"
- LightGlue: A modern learned feature matcher that efficiently establishes correspondences between images. "For COLMAP, we use SuperPoint~\citep{detone2018superpoint} and LightGlue~\citep{lindenberger2023lightglue} on MegaDepth and IMC23."
- METIS: A graph partitioning library used to divide large graphs into smaller, balanced parts with minimal edge cuts. "we use METIS~\citep{karypis1997metis} for graph partitioning,"
- Minimum Spanning Trees (MSTs): Sparse subgraphs connecting all nodes with minimal total edge weight, ensuring global connectivity. "To enforce global connectivity in a principled way, we adopt Minimum Spanning Trees (MSTs)."
- motion averaging: A global SfM strategy that jointly estimates camera motions by averaging relative poses across the pose graph. "typically through motion averaging on an initial pose graph,"
- Normalized Discounted Cumulative Gain (NDCG): A ranking quality metric that weights relevance by position in the ranked list, normalized by the ideal ordering. "The quality of a predicted ranking is commonly evaluated in information retrieval with Normalized Discounted Cumulative Gain (NDCG)~\citep{jarvelin2002cumulated}."
- NDCGLoss2++: A differentiable loss approximating NDCG for training learning-to-rank models. "Since NDCG is non-differentiable, we adopt NDCGLoss2++~\citep{wang2018lambdaloss},"
- orthogonal trees: Multiple spanning trees constructed to be complementary (minimally overlapping) for robustness and efficiency. "and \citet{gan2024efficient} build orthogonal trees from engineered similarities to accelerate verification."
- pose graph: A graph where nodes are images (cameras) and edges encode relative poses; foundational for SfM initialization. "The pose graph is a core component of Structure-from-Motion (SfM), where images act as nodes and edges encode relative poses."
- RANSAC: A robust estimator that fits models to data with outliers by iteratively sampling minimal sets and scoring consensus. "we first perform keypoint detection, feature matching, and relative pose estimation with RANSAC."
- Structure-from-Motion (SfM): The process of reconstructing 3D structure and camera poses from images. "Structure-from-Motion (SfM) pipelines estimate camera poses and 3D structure from images~\citep{ullman1979interpretation,schonberger2016structure},"
- SuperPoint: A learned interest point detector and descriptor used for feature matching in SfM. "For COLMAP, we use SuperPoint~\citep{detone2018superpoint} and LightGlue~\citep{lindenberger2023lightglue} on MegaDepth and IMC23."
- two-view geometry: The geometric relationship (e.g., relative pose, epipolar constraints) between two images of the same scene. "Large values of correlate with stable two-view geometry,"
Collections
Sign up for free to add this paper to one or more collections.