Transformers for dynamical systems learn transfer operators in-context
Abstract: Large-scale foundation models for scientific machine learning adapt to physical settings unseen during training, such as zero-shot transfer between turbulent scales. This phenomenon, in-context learning, challenges conventional understanding of learning and adaptation in physical systems. Here, we study in-context learning of dynamical systems in a minimal setting: we train a small two-layer, single-head transformer to forecast one dynamical system, and then evaluate its ability to forecast a different dynamical system without retraining. We discover an early tradeoff in training between in-distribution and out-of-distribution performance, which manifests as a secondary double descent phenomenon. We discover that attention-based models apply a transfer-operator forecasting strategy in-context. They (1) lift low-dimensional time series using delay embedding, to detect the system's higher-dimensional dynamical manifold, and (2) identify and forecast long-lived invariant sets that characterize the global flow on this manifold. Our results clarify the mechanism enabling large pretrained models to forecast unseen physical systems at test without retraining, and they illustrate the unique ability of attention-based models to leverage global attractor information in service of short-term forecasts.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper explores a simple but surprising idea: a small AI model called a transformer can learn to predict how a physical system will change over time, even when the test system is different from the one it was trained on. The authors show that the transformer does this by “figuring things out on the fly” from the recent history it sees at test time. This is called in-context learning. They also explain how the model uses its attention to piece together a hidden picture of the system and apply a general “flow rule” to make short-term forecasts.
What questions does the paper ask?
The paper looks at three main questions:
- Can a small transformer trained on one system predict the future of a different system without retraining?
- What strategy does the transformer use during testing to adapt to new systems from just a short context?
- Why does the model sometimes get better at predicting other systems early in training, and then worse, and then better again (a behavior called “double descent”)?
How did they study it?
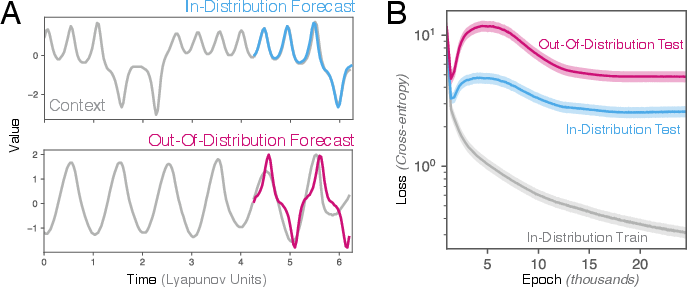
The authors trained a small transformer (like a simplified GPT) on a single time series: just one number changing over time from one known physical system. That number was turned into “tokens,” similar to how LLMs read words. During testing, they gave the model a short history (the “context”) from either:
- the same system but a new trajectory (in-distribution, or ID), or
- a completely different system (out-of-distribution, or OOD).
Then they watched how well the model predicted the next step, and what patterns its attention focused on.
To understand what the model was doing, they used three key ideas:
- Delay embedding: Using the last several values (like snapshots at different times) to reconstruct a hidden, higher-dimensional picture of the system. Think of it as piecing together a 3D object from a series of 2D photos taken over time.
- Markov chains: A way to describe “what comes next” based on the recent past. If a system needs more past steps to predict the future, it’s more complex.
- Transfer operators: A “map of movement” that says how the system flows from one region of its state space to another. Imagine a city map showing the probability of moving from one neighborhood to another in the next minute—this captures the system’s dynamics over short times.
They ran these experiments across 100 different pairs of systems and also tested a well-known system called Lorenz-96, whose complexity can be easily controlled.
Key ideas explained simply
- Dynamical system: A set of rules that tells how something changes over time (like weather or a swinging pendulum).
- In-context learning: The model learns to adapt during testing from the context it sees, without changing its weights.
- Attention: The model’s way of deciding which past moments matter most for predicting the next step.
- Attractor: The set of states a system tends to visit again and again (its “favorite places”).
- Invariant set: A region the system stays in (or returns to) for a long time.
- Transfer operator: A probabilistic rule for how the system moves around its state space from one moment to the next.
What did they find?
- Transformers can predict new, unseen systems: Even small transformers trained on one system made better-than-baseline forecasts on different systems. This shows real in-context generalization.
- Early “double descent” in OOD: As training goes on, performance on the training system improves, then briefly worsens on test data (overfitting), and later improves again (classical double descent). But for different systems (OOD), there’s an earlier, separate hump: performance first improves, then degrades, then improves again. This suggests the model temporarily picks up general patterns useful across systems before overfitting to the specific training system.
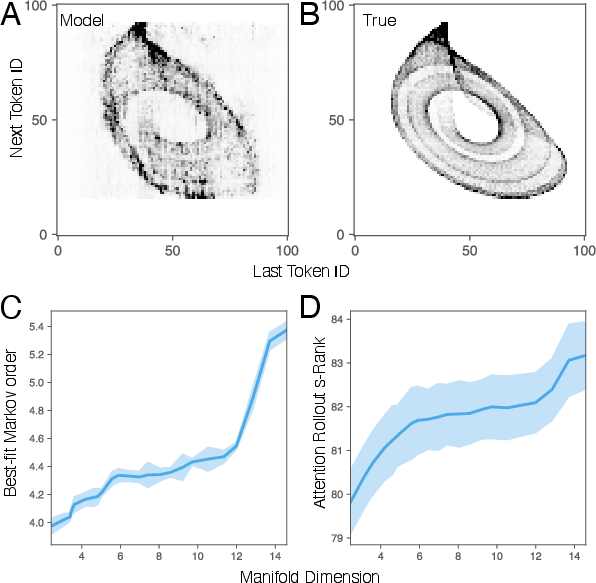
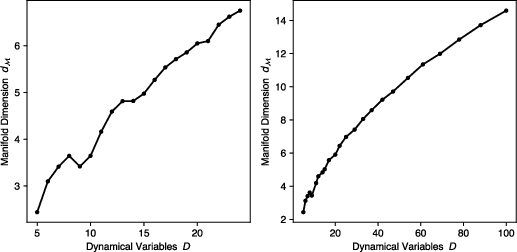
- The model reconstructs hidden dimensions using delays: By looking at time delays (past values), the transformer builds a higher-dimensional picture of the system’s “shape” (its attractor). When the test system is more complex, the model effectively uses more “past steps,” just like a higher-order Markov chain would. This matches a classic theory (Takens’ theorem) that says you can rebuild hidden dynamics from enough delays.
- Attention reflects the system’s complexity: The transformer’s attention patterns spread across more positions when the test system has a higher-dimensional attractor. A measure called “stable rank” of the attention rollout increased with complexity, showing the model was using richer internal representations when it needed to.
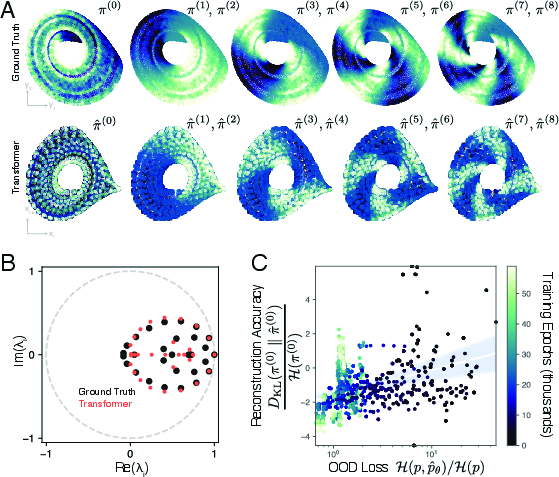
- The model learns a transfer-operator-like rule in-context: When the authors built a “movement map” from the model’s predictions and compared it to the true map computed from the full system, they found the important parts matched—especially the biggest timescales and the long-lived regions (almost-invariant sets). As the model’s OOD performance improved, its learned “stationary distribution” (the places the system spends most time) got closer to the true one. In short, the transformer seems to detect the system’s global structure and use that to make better short-term forecasts.
Why is this important?
- It explains how foundation models can adapt to new physics at test time: The transformer doesn’t just memorize one system; it learns how to read the context to rebuild the system’s hidden structure (via delay embedding) and then applies a general forecasting rule (via a transfer operator). That’s a powerful, system-agnostic strategy.
- It highlights the role of attention in scientific prediction: Because attention compares all pairs of past tokens, the model naturally captures global patterns—like detecting long-lived regions—rather than just local slopes or short-term trends.
- It guides how to build and train better models: More context and attention can help models exploit global information, which is useful in chaotic or complex systems (like weather, turbulence, or plasma). It also warns that over-training on one system may reduce the model’s ability to generalize early on, suggesting careful monitoring and stopping criteria.
- It bridges ideas from math and machine learning: The paper connects modern attention models with classic tools in dynamical systems (delay embedding, transfer operators), showing that transformers can implement these strategies in-context, naturally and adaptively.
Takeaway
A small transformer trained on one physical system can learn to forecast different systems by:
- using the recent history to rebuild a hidden, higher-dimensional picture of the dynamics, and
- applying a transfer-operator-like “movement rule” to predict short-term changes.
This explains why large pretrained models often handle new, unseen scientific problems so well—and suggests that attention-based models have a special knack for using global structure to make accurate local predictions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future work could address to validate, generalize, and mechanistically ground the paper’s claims.
- Generality across system classes: The study focuses on deterministic ODEs; it does not examine stochastic, non-autonomous, hybrid/discontinuous, delay differential, Hamiltonian/conservative, or stiff systems, leaving unknown whether the in-context transfer-operator mechanism holds across these regimes.
- Partial observability assumptions: Only a single observed coordinate is used; the sensitivity of the results to the choice of measurement function (e.g., non-smooth, non-invertible, or nonlinear observations) and to multi-channel observations is not tested.
- Quantization effects: The impact of uniform scalar quantization (V=100 bins), bin range choices, and mean scaling on (i) embedding quality, (ii) transfer-operator estimation, and (iii) OOD performance is not characterized; ablations over V and encoding schemes (e.g., µ-law, log returns, delta tokens) are missing.
- Sampling rate and lag selection: The method assumes evenly spaced sampling; sensitivity to sampling rate mismatch between Train-ID and Test-OOD, aliasing, and the choice of lag τ used in Ulam’s operator is unexplored.
- Context length requirements: The relationship between context length C and required delay-embedding dimension is not quantified; minimum context thresholds and failure modes when remain unknown.
- Estimating Markov order: The procedure to select the effective Markov order k (used to approximate transformer dynamics) is heuristic; an adaptive or principled model selection method (and its sample complexity) is not provided.
- Stability of embedding under noise: Robustness to observational noise, missing data beyond padding, and nonstationarity (drifts, regime shifts) is not evaluated; Takens-style guarantees may break under quantization and noise.
- Long-horizon forecasting: The approach is assessed primarily by next-token cross-entropy; the effect of operator approximation on long-horizon trajectories (error growth, attractor retention, recurrence statistics) is not measured.
- Metric choice: Evaluation relies on token-level cross-entropy and KL divergence between invariant measures; standard dynamical metrics (RMSE in state space, Lyapunov exponent estimates, prediction horizon, hitting/mixing times) are absent.
- Baselines: Comparisons are limited to naive mean regression; stronger baselines (AR(k), SINDy, Koopman/EDMD, Neural ODEs, RNNs/LSTMs, Neural Operators) are missing, so relative gains of transformers over established operator-learning methods remain unclear.
- Architectural dependence: Results use a small, two-layer, single-head transformer with ALiBi; the effect of depth, width, number of heads, positional encoding type (ALiBi vs absolute/rotary), and tying/untying input-output embeddings on in-context operator learning is not studied.
- Attention mechanism necessity: It is hypothesized that quadratic attention enables global attractor inference; whether similar behavior emerges with linear attention variants, state-space models (e.g., SSMs), or convolutional architectures is unknown.
- Training regimen sensitivity: The observed early double descent in OOD loss is not analyzed under different optimizers, learning-rate schedules, regularization (e.g., weight decay), batch sizes, or data volumes; causal factors behind the secondary double descent remain speculative.
- Transfer-operator discretization: Ulam’s method with K-means partitions is used; sensitivity to partition size K, partition strategy (e.g., adaptive grids, diffusion maps), lag τ, and deflation procedure on the operator spectrum and eigenfunctions is not quantified.
- Eigenfunction similarity: Beyond matching leading eigenvalues, quantitative similarity of eigenfunctions (e.g., overlap metrics, alignment errors, mode localization) between ground truth and transformer-implied operators is not assessed.
- Sample complexity: The number of samples needed to reliably estimate the transformer-implied operator (and its spectrum) from finite contexts is not derived; finite-size and sparsity effects on the inferred operator are uncharacterized.
- Theoretical guarantees: A formal link between attention rollout stable rank and manifold dimension is asserted empirically but not proven; necessary and sufficient conditions for successful in-context delay embedding and operator recovery are lacking.
- Mechanistic circuits: The internal circuit responsible for operator approximation (e.g., which heads/MLP paths implement delay embedding vs transition estimation) is not identified; causal ablations (head removal, neuron knockout) are not performed.
- Scaling laws: Claims that more context improves performance are not accompanied by scaling curves showing how OOD generalization and operator fidelity scale with C, model size, dataset length, and vocabulary size.
- Temperature and decoding: The impact of sampling temperature and greedy vs stochastic decoding on operator estimation and forecast stability is not studied.
- Train–test distribution mismatch: While OOD systems differ, their structural similarity (e.g., dissipative chaotic attractors) may bias results; performance on substantially different classes (e.g., integrable systems, piecewise-linear maps) is not reported.
- Initial condition dependence: OOD performance may depend on the test trajectory’s initial condition relative to attractor regions seen in Train-ID; sensitivity to initial condition selection is not explored.
- Nonstationary forcing: The method assumes time-invariant dynamics; extension to systems with time-dependent parameters or exogenous inputs (and how transformers infer non-autonomous operators) is untested.
- Multiscale and high-dimensional PDEs: Although motivated by PDE use cases, experiments stay on ODEs; whether univariate token streams can capture spatiotemporal manifold structure of PDEs (and required context scaling with spatial resolution) is unresolved.
- Operator locality vs globality: It is unclear whether the transformer-implied operator captures global attractor structure or is effectively local around the context window; tests using mixing times, escape probabilities, and global recurrence are missing.
- k-gram aggregation bias: The operator inferred by grouping contexts with the same k-gram may be biased by non-uniform context distributions; the effect of this aggregation on transition estimates is not analyzed.
- Token scaling across OOD: Mean scaling s is computed from the training series; whether this scaling mismatches OOD magnitudes and harms operator recovery (and whether per-series or adaptive scaling would help) is not investigated.
- Symmetry handling: Paired eigenfunctions due to symmetry are noted, but how the transformer handles broken symmetries or identifies symmetry classes is not studied.
- Data diversity and selection: The ODE database composition, diversity, and selection criteria are not detailed; potential selection bias (e.g., favoring low-dimensional dissipative systems) could inflate OOD generalization estimates.
- Robustness to missing data: Padding is used for NaNs, but the effect of realistic missing-data patterns (block gaps, irregular sampling) on embedding and operator estimation is not tested.
- Causal attribution of OOD gains: The correlation between improved OOD loss and lower KL divergence to the invariant distribution is suggestive but not causal; interventions that directly alter the learned operator (e.g., targeted regularization) to test causality are not performed.
- Practical computational limits: The claimed quadratic attention benefits are not weighed against memory/time costs; whether the operator-learning behavior persists at larger context sizes without prohibitive compute is unclear.
- Application to control: The inferred operator is only used for forecasting; whether it supports control/reinforcement tasks (e.g., planning via transfer-operator manipulation) is an open direction.
Practical Applications
Immediate Applications
Below are specific, deployable applications that leverage the paper’s findings about in-context delay embedding and transfer-operator learning in transformers.
- Zero-shot short-term forecasting with compact transformers (weather, energy, finance, industrial operations)
- Description: Deploy small, two-layer transformer forecasters on univariate streams to produce short-horizon predictions for systems not seen in training (e.g., localized weather nowcasting, grid load spikes, intraday financial signals, process temperatures/pressures).
- Tools/Workflows: Quantize the time series into tokens; use 512-token sliding contexts; autoregressive sampling; early stopping tuned for OOD performance; monitor validation loss on held-out OOD streams.
- Assumptions/Dependencies: Stationary sampling rate and adequate context length; noise not overwhelming underlying dynamics; target systems share broad dynamical characteristics with training; consistent quantization and scaling.
- Regime and metastability detection from single sensors (manufacturing maintenance, ICU monitoring, grid stability, traffic operations)
- Description: Identify long-lived “almost-invariant” states and regime transitions from univariate signals by extracting the model-implied transfer operator and its leading eigenfunctions.
- Tools/Workflows: Build a “metastability detector” that computes the empirical operator from the transformer’s multistep predictions on delay embeddings; trigger alerts when eigenmodes shift.
- Assumptions/Dependencies: Sufficient data to estimate eigen-spectrum; delays chosen to capture relevant dynamics; regimes are reflected in the single measured variable.
- Latent dimension estimation via attention rollout stable rank (instrumentation planning, robotics, environmental sensing)
- Description: Use the stable rank of attention rollout to infer the effective latent dimensionality of the underlying attractor, guiding how many delays or additional sensors to deploy.
- Tools/Workflows: “DimRank meter” that computes attention rollout and provides d_latent estimates; adjust embedding order or sensor count accordingly.
- Assumptions/Dependencies: Correlation between stable rank and attractor dimension holds for the target domain; adequate context; transformer capacity sufficient to express latent structure.
- Training and model selection for OOD generalization (ML Ops for time-series platforms)
- Description: Exploit the early double-descent signature to choose early stopping points that improve OOD performance; align improvements with operator-invariant distributions.
- Tools/Workflows: Training monitors that track (i) OOD validation loss and (ii) KL divergence between ground-truth and model-implied invariant distributions; automated early-stopping rules.
- Assumptions/Dependencies: Availability of small OOD validation sets; ability to approximate invariant distribution on held-out data; acceptance of ID–OOD trade-offs.
- Operator-aware interpretability and trust reports (academia, regulatory compliance)
- Description: Provide interpretable summaries of the learned dynamics by comparing eigen-spectra of model-implied and ground-truth transfer operators, exposing dominant timescales and metastable regions.
- Tools/Workflows: “Operator Lens” plugin that estimates Ulam matrices, eigenvalues/eigenvectors, and produces side-by-side spectra and KL divergence diagnostics.
- Assumptions/Dependencies: Ground-truth or high-fidelity reference operators available for comparison; domain expertise to interpret spectra.
- Low-resource edge forecasting with compact models (IoT, smart buildings, agriculture)
- Description: Run the compact transformer on embedded devices for local predictions from single sensors (e.g., HVAC load, soil moisture, vibration signals).
- Tools/Workflows: On-device quantization, streaming contexts, temperature-controlled sampling; lightweight inference libraries.
- Assumptions/Dependencies: Memory/compute budget supports 2-layer causal transformer; reliable sampling cadence; moderate noise environments.
- Data collection protocols optimized for delay embedding (data engineering)
- Description: Improve forecast and regime-detection performance by prioritizing long uninterrupted contexts and consistent sampling rates to enable effective time-delay embeddings.
- Tools/Workflows: Guidelines for minimum context length vs. expected attractor dimension; quantization policies; time-synchronization procedures.
- Assumptions/Dependencies: Operational ability to collect long contiguous sequences; domain-appropriate sampling frequency.
- Drift/OOD detection via invariant distribution mismatch (risk management, anomaly detection)
- Description: Detect distributional drift by monitoring KL divergence between baseline invariant distribution and the model-implied invariant distribution during inference.
- Tools/Workflows: “Distribution drift monitor” that periodically recomputes empirical operator and flags significant KL increases; integrate with incident response.
- Assumptions/Dependencies: Reliable baseline invariant distribution; enough data in current regime to estimate operators; tolerance thresholds calibrated to domain risk.
- Instructional modules for dynamical systems and SciML (education, academia)
- Description: Use the open-source code and analyses to teach delay embedding, transfer operators, and in-context learning mechanisms with hands-on labs.
- Tools/Workflows: Jupyter notebooks reproducing experiments (attention rollout, eigen-spectra, double descent); course assignments.
- Assumptions/Dependencies: Access to the repository and Python environment; basic familiarity with time-series ML.
Long-Term Applications
These applications require scaling, additional research, integration work, or domain validation before widespread deployment.
- Cross-domain foundation models that generalize via operator learning (weather/climate, fluid dynamics, plasma, seismology)
- Description: Large scientific foundation models that adapt to unseen physical systems by in-context delay embedding and transfer-operator estimation, enabling robust zero-shot forecasting across PDE families and scales.
- Tools/Workflows: “OperatorGPT” with extended contexts, multi-resolution tokenization, mixed-modality inputs; evaluation suites comparing learned spectra to physical operators.
- Assumptions/Dependencies: Scalable training corpora across physics domains; longer contexts and larger models; rigorous validation and uncertainty quantification.
- Adaptive digital twins for complex assets (manufacturing lines, power plants, aircraft)
- Description: Digital twins that infer latent manifolds and metastable states online from limited sensors, adapting to new regimes without retraining and guiding operational decisions and maintenance scheduling.
- Tools/Workflows: “Adaptive Twin Engine” integrating operator inference, regime maps, and intervention simulators; continuous learning pipelines.
- Assumptions/Dependencies: Robust real-time estimation in noisy, nonstationary settings; safety and reliability guarantees; integration with control systems.
- Operator-informed autonomous control of chaotic systems (robotics, fusion, grid stability)
- Description: Controllers that exploit operator eigenmodes to avoid unstable regions and steer systems toward favorable metastable sets; model-predictive control using in-context learned dynamics.
- Tools/Workflows: RL/MPC hybrids that query learned operators; certification via formal verification of safety constraints.
- Assumptions/Dependencies: High-confidence operator estimates under uncertainty; fast inference loops; regulatory approval for safety-critical deployment.
- Universal univariate forecasters for healthcare monitoring (wearables, ICU devices)
- Description: Predict multi-system physiological states (arrhythmias, respiratory events, sleep stages) from single-sensor streams by reconstructing latent dynamics and regimes.
- Tools/Workflows: Edge-friendly medical forecasters; clinical dashboards highlighting regime transitions; post-market surveillance tools.
- Assumptions/Dependencies: Handling nonstationarity and artifacts; clinical validation and FDA/CE approvals; privacy-preserving data pipelines.
- Policy frameworks mandating operator-level interpretability in critical forecasts (energy, transportation, finance)
- Description: Governance standards requiring reporting of the learned operator spectrum, metastable sets, and drift indicators for ML-based predictive infrastructure.
- Tools/Workflows: Compliance toolkits (operator reports, KL drift auditing, spectral stability checks) integrated into model governance platforms.
- Assumptions/Dependencies: Consensus on interpretability metrics; standardized estimation protocols; industry buy-in.
- Sensor network design guided by latent dimension estimates (smart cities, environmental monitoring)
- Description: Optimize sensor placement, count, and sampling rates using attention-rollout-derived latent dimension estimates to ensure adequate embedding and observability.
- Tools/Workflows: Design optimization solvers that incorporate d_latent estimates; scenario planning for budget-constrained deployments.
- Assumptions/Dependencies: Stable correlation between attention-based dimension estimates and true system observability; generalization across heterogeneous terrains.
- Commercial analytics products for regime mapping and operator-based anomaly detection (industrial SaaS, finance tech)
- Description: Offer dashboards that visualize global attractors, metastable regions, and dominant timescales, with alerts when operator spectra change.
- Tools/Workflows: “Global Attractor Explorer” and “Regime Map” products; integrations with data warehouses and ops tooling.
- Assumptions/Dependencies: Reliable operator estimation at enterprise data scales; clear ROI; customer-specific customization.
- Scientific discovery tools for complex systems (neuroscience, ecology, systems biology)
- Description: Use in-context operator learning to reveal almost-invariant sets and transition structures from observational time series, guiding hypotheses about mechanisms and control.
- Tools/Workflows: Cross-disciplinary analysis pipelines combining delay embeddings with operator spectra; hypothesis-generation notebooks.
- Assumptions/Dependencies: Adequacy of univariate proxies to reflect multi-scale dynamics; careful treatment of noise and nonstationarity; domain-specific validation.
Glossary
- ALiBi: An additive bias to attention logits that encodes relative position by penalizing larger lags, enabling long-context extrapolation without explicit embeddings. "Positional information is encoded using ALiBi, an additive attention-logit bias"
- almost-invariant sets: Regions of state space where trajectories remain for long times before transitioning, associated with subdominant eigenfunctions of a transfer operator. "almost-invariant sets"
- attention rollout matrix: A depth-aggregated matrix that quantifies effective attention flow across token positions by composing per-layer attention and residual paths. "we calculate the attention rollout matrix "
- attractor: A set toward which a dynamical system evolves over time, capturing its long-term behavior. "the true attractor of Test-OOD"
- bias-variance tradeoff: The tension where models with too little capacity underfit (high bias) and those with too much capacity overfit (high variance), affecting generalization. "consistent with the classical bias-variance tradeoff"
- causal self-attention: Attention restricted to past positions to preserve autoregressive causality in sequence models. "single-head causal self-attention"
- decoder-only transformer: A unidirectional transformer architecture that predicts next tokens autoregressively without an encoder. "Our model is a decoder-only transformer"
- deflated operator: A modified linear operator from which the dominant (stationary) mode has been removed to expose subdominant dynamics. "by applying power iteration to a deflated operator that removes the stationary mode"
- delay embedding: Reconstruction of a system’s state space from a single observed variable by stacking time-lagged copies. "lift low-dimensional time series using delay embedding"
- double descent: A risk curve phenomenon where test error decreases, increases, and then decreases again as model capacity or training progresses. "epoch-wise double descent"
- Grassberger-Procaccia algorithm: A method to estimate the fractal (correlation) dimension of an attractor from time series data. "perform the Grassberger-Procaccia algorithm separately for each trajectory"
- in-context learning: A model’s ability to adapt to new tasks by using the input context at test time, without weight updates. "in-context learning of dynamical systems"
- in-distribution (ID) generalization: Generalization to data drawn from the same distribution as training data. "known as in-distribution (ID) generalization"
- KL divergence: A measure of dissimilarity between probability distributions, often used to compare learned and true distributions. "the KL divergence "
- Lorenz-96 system: A canonical high-dimensional chaotic dynamical system used to study predictability and scaling with dimension. "we generate new Test-OOD trajectories using the Lorenz-96 system"
- Markov chain: A stochastic process where the next state depends only on a fixed number of previous states (its order). "a -order Markov chain "
- Markov operator: A linear operator that advances probability densities under a Markov process, represented by a row-stochastic matrix. "we treat it as a Markov operator"
- metastable: Describing states or distributions that persist for long times before transitioning to other states. "long-lived metastable distributions"
- out-of-distribution (OOD) generalization: Generalization to data drawn from a different distribution than the training data. "out-of-distribution (OOD) generalization"
- Perron-Frobenius operator: The linear operator that propagates probability densities under a dynamical system. "associated with the Perron-Frobenius operator propagating the dynamics"
- power iteration: An iterative algorithm to compute dominant eigenvectors/eigenvalues of a matrix. "We solve this using power iteration"
- Radau IIA method: An implicit Runge–Kutta scheme suitable for stiff differential equations. "using the implicit Radau IIA method"
- relative positional embedding: Encoding that represents positions relative to each other rather than absolute indices, aiding generalization across lengths. "with relative positional embedding akin to the T5 family"
- row-stochastic transition matrix: A matrix whose rows sum to one, describing probabilities of transitioning from each state. "This row-stochastic transition matrix describes the model-implied dynamics"
- stable rank: A scale-invariant surrogate for matrix rank defined by the squared Frobenius norm divided by the spectral norm squared. "We compute the stable rank of the rollout matrix"
- stationary distribution: An invariant probability distribution that remains unchanged under the dynamics of a Markov process or operator. "the stationary distribution "
- symbolic dynamics: Representation of continuous trajectories as sequences of discrete symbols via partitioning of state space. "Partition and symbolic dynamics."
- Takens' theorem: A result guaranteeing that generic delay embeddings reconstruct the dynamics of a smooth system from a single observable. "This result is consistent with Takens' theorem"
- transfer operator: A linear operator (e.g., Perron-Frobenius) that advances distributions under a dynamical system’s flow or map. "transfer-operator forecasting strategy"
- Ulam's method: A numerical scheme that approximates the transfer operator by discretizing state space and counting transitions. "using Ulam's method"
- Voronoi cells: Regions of space partitioned by proximity to a set of centers, used here to discretize state space. "Voronoi cells $B_i \equiv \{y}:\arg\min_j\|{y}-{c}_j\| = i\}$"
- weight-tied: Sharing parameters between layers or projections, typically tying output projection weights to input embeddings. "The output projection is weight-tied to the input embedding matrix."
Collections
Sign up for free to add this paper to one or more collections.

