- The paper presents PRNPE, integrating preconditioning with robust neural posterior estimation to improve calibration in misspecified simulators.
- It employs summary-based weighting via SMC-ABC or forest-proximity methods to localize training on relevant regions and mitigate prior-predictive degeneracy.
- Empirical evaluations on synthetic and real-world models demonstrate that PRNPE achieves near-nominal calibration and enhanced predictive accuracy.
Preconditioned Robust Neural Posterior Estimation Under Model Misspecification
The paper, "Preconditioned Robust Neural Posterior Estimation for Misspecified Simulators" (2602.18004), presents a systematic study and methodological advance to address the dual challenges of model misspecification and pathological prior-predictive behavior in simulation-based Bayesian inference (SBI). Through theoretical development and comprehensive empirical evaluation, the authors propose a two-stage methodology leveraging preconditioning and robust neural posterior estimation to improve both calibration and predictive accuracy in scenarios where simulators are misspecified or prior distributions are broad and lead to extreme simulated summaries.
Simulation-Based Inference and Its Pathologies
SBI enables posterior inference for intractable likelihoods by training neural conditional density estimators—commonly normalizing flows—on simulated joint pairs of parameters and summary statistics. Neural posterior estimation (NPE) aims to mitigate the curse of dimensionality inherent to traditional methods (e.g., ABC), often yielding substantially improved efficiency and scalability. However, two primary failure modes threaten the reliability of NPE:
- Prior-predictive degeneracy: Weak priors or heavy-tailed simulators result in simulated summaries that are extreme or numerically pathological, destabilizing training and causing the neural estimator to waste capacity on irrelevant regions.
- Model misspecification: When the observed data distribution is outside the support of the simulator, standard neural density estimators are forced to extrapolate, leading to unreliable and overconfident posteriors. Such situations are endemic in scientific application domains where complex phenomena are only partially captured by mechanistic simulators.
The paper rigorously characterizes these issues via the concept of incompatible summaries, underlining scenarios where the observed summaries are in the tail or outside the support of the simulation model (see Lemma 1 and formal bounds on the amortisation gap).
Preconditioning: Theory and Implementation
Addressing prior-predictive failures, the authors build on the preconditioning framework developed in [wang_preconditioned_2024], extending it to the misspecified regime. The key is to focus the neural density estimator's capacity on the region of summary space that is relevant to the observed data. This localization is performed by defining summary-based weighting functions, wy(s), that concentrate the training distribution ptrain(θ,s) near the observed summary sy.
The main implementations explored are:
The authors prove that preconditioning with summary-only weights wy(s) maintains conditional invariance: the target conditional p(θ∣s) remains unshifted on the support of wy, ensuring no new biases arise due to the localization of the training distribution.
Robust Amortized Neural Posterior Estimation
Preconditioning alone cannot repair the failure in regions where the observation lies outside the support of the generative model. To address such incompatibility, the paper integrates robust neural posterior estimation (RNPE) [ward_robust_2022] into the pipeline.
RNPE postulates an explicit error model in summary space (e.g., spike-and-slab on the discrepancy between observed and simulated summaries) and marginalizes over denoised latent summaries, thereby decoupling parameter inference from irrelevant mismatches between simulation and reality. The robustification is particularly critical for correct posterior uncertainty quantification, as standard neural approaches are otherwise susceptible to catastrophic overconfidence under misspecification [kleijn_bernstein-von-mises_2012, schmitt_detecting_2024].
The resulting methodology—PRNPE (Preconditioned Robust Neural Posterior Estimation)—consists of two stages:
- Preconditioning (via SMC-ABC or forest-proximity): Resample or reweight simulations to localize the training set near sy,
- RNPE: Fit a flexible conditional flow estimator using the preconditioned dataset, then denoise the observation via the explicit summary error model to generate posterior samples.
This pipeline is shown in detail in Algorithm 1 of the paper.
Empirical Evaluation and Numerical Results
The paper presents experiments on two synthetic misspecified models and a real-world mechanistic model to validate the efficacy of PRNPE:
1. Contaminated Weibull Example
A one-dimensional Weibull model is contaminated with a small proportion of negative outliers, making one summary (the sample minimum) incompatible with the model (since Weibull distributions are strictly positive). The baseline NPE and RNPE produce unreliable and miscalibrated posteriors due to the influence of the extreme (heavy-tailed) simulated minima. In contrast, both variants of PRNPE—especially when combined with forest-proximity preconditioning—produce accurate and well-calibrated posteriors, with empirical coverage close to the 95% nominal level.
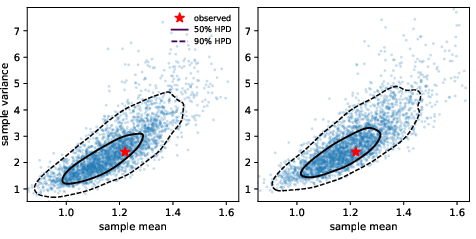
Figure 2: Posterior predictive distributions for compatible summaries (xˉ,s2) using PRNPE with SMC-ABC (left) and forest-proximity (right); contours indicate 50% and 90% HPD regions, star marks observed summary.
2. Sparse Vector Autoregressive Model under Drift
A 6-dimensional VAR(1) model is subjected to a mean-drift misspecification, rendering the mean summary incompatible. PRNPE with SMC-ABC filters out extreme mean discrepancies; the robust inference step recovers accurate posteriors for parameters associated with compatible summaries (e.g., off-diagonal transition coefficients and noise scale σ), achieving near-perfect calibration and sharp posterior predictive fit.
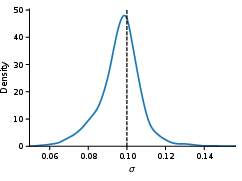
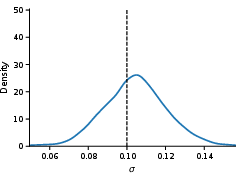
Figure 3: Posterior predictive distributions for pooled standard deviation in the SVAR example with PRNPE (left: SMC-ABC, right: forest-proximity); dashed horizontal line is the observed summary.
3. Biphasic Tumor Growth Model (BVCBM) Calibration
For empirical time-series data from tumor growth, PRNPE leads to superior posterior predictive fit compared to both traditional NPE and robust-only methods, robustly handling intrinsic model discrepancies and the wide prior range imposed for scientific transparency.
Strong numerical results—PRNPE (forest-proximity) achieves lowest median predictive distances in all but one dataset—provide strong evidence of the method's robustness and accuracy under practically relevant misspecification scenarios.
Theoretical and Practical Implications
The theoretical innovation of this work is the explicit amortisation gap bound that quantifies how preconditioning reduces the error in amortized inference by controlling the moments of distance between training and observed summaries. This insight offers clear guidance for deciding when and how to precondition, with summary-based resampling providing a practical mechanism for loss localization without introducing bias in the conditional target.
Practically, the approach does not require intricate tuning or prior redesign, making it compatible with amortized and sequential pipelines. It also complements recent advances in domain adaptation for amortized inference [elsemuller_does_2025, mishra_robust_2025] and robust error modeling [ward_robust_2022, ocallaghan_robust_2025], and is extensible to high-dimensional, real-world settings as demonstrated.
Future Directions
Possible expansions include:
- Semi-amortized inference: Defining weights to cover unions of observations, extending robustness across datasets.
- Improved weight smoothing: Combining SMC-ABC and forest-proximity to mitigate spiky weights and enable deeper randomization in forest splits.
- Self-consistency regularization: Integrating loss penalties for marginalization errors [schmitt_leveraging_2024, mishra_robust_2025] in conjunction with preconditioning.
- Alternative robustification: Employing optimal transport calibration [wehenkel_addressing_2025], learnt robust summaries [huang_learning_2023], or meta-uncertainty approaches [schmitt_meta-uncertainty_2023].
Conclusion
The PRNPE methodology provides a principled, theoretically-justified, and empirically-validated solution for simulation-based inference under both pathological priors and model misspecification. By restricting model capacity to the relevant summary neighborhood and introducing robust error modeling, PRNPE yields accurate, calibrated, and predictive posteriors where standard neural and ABC methods fail, setting a new benchmark for reliability in likelihood-free scientific inference.