Learning Without Training
Abstract: Machine learning is at the heart of managing the real-world problems associated with massive data. With the success of neural networks on such large-scale problems, more research in machine learning is being conducted now than ever before. This dissertation focuses on three different projects rooted in mathematical theory for machine learning applications. The first project deals with supervised learning and manifold learning. In theory, one of the main problems in supervised learning is that of function approximation: that is, given some data set $\mathcal{D}={(x_j,f(x_j))}_{j=1}M$, can one build a model $F\approx f$? We introduce a method which aims to remedy several of the theoretical shortcomings of the current paradigm for supervised learning. The second project deals with transfer learning, which is the study of how an approximation process or model learned on one domain can be leveraged to improve the approximation on another domain. We study such liftings of functions when the data is assumed to be known only on a part of the whole domain. We are interested in determining subsets of the target data space on which the lifting can be defined, and how the local smoothness of the function and its lifting are related. The third project is concerned with the classification task in machine learning, particularly in the active learning paradigm. Classification has often been treated as an approximation problem as well, but we propose an alternative approach leveraging techniques originally introduced for signal separation problems. We introduce theory to unify signal separation with classification and a new algorithm which yields competitive accuracy to other recent active learning algorithms while providing results much faster.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Clear, Simple Summary of “Learning Without Training”
What is this paper about?
This dissertation explores how to make machines learn from data without the usual long, complicated “training” process. Instead of relying on trial-and-error methods like gradient descent (which can be slow, unstable, and get stuck), it uses direct mathematical recipes to build accurate models quickly. It focuses on three areas:
- Supervised learning on complicated, high‑dimensional data
- Transfer learning (reusing what you learned in one place to help in another)
- Fast, accurate classification with active learning (smartly choosing which labels to ask for)
What questions does it try to answer?
In simple terms, the paper asks:
- Can we build good prediction models directly from data without heavy training?
- How can we reuse what we learned on one kind of data to help with another (transfer learning)?
- Can we classify data well by asking for only a few labels, and do it very fast?
Key Ideas and Approach (Explained Simply)
1) Learning without training: a direct recipe
Think of trying to predict something (like weather) from many inputs. The usual way is to pick a model (like a neural network) and “train” it by slowly tweaking numbers to reduce error. That can take a long time and may fail.
This work offers a different path: constructive approximation. Instead of training, it uses a ready‑made formula that averages nearby data points using a carefully designed “smoothing stencil” (called a kernel). It’s like taking a blurry picture on purpose—but with a smart blur that keeps important details and sharp edges where they matter. The recipe depends on how smooth the true function is near each point, so it adapts locally rather than using one global error score that can hide local problems.
Key takeaway: you can often compute a high‑quality predictor directly from the data using a special averaging formula—no iterative training loop required.
2) Beating the “curse of dimensionality” with manifolds
High‑dimensional data (many features) is hard to handle because you need tons of samples to cover all possibilities. But in real life, data often lies on a much simpler, curved surface inside that big space, called a manifold. For example, photos of a rotating object live on a low‑dimensional “surface” of possibilities.
This work uses the manifold idea to reduce complexity. It borrows tools from geometry and physics—especially the idea of heat flow on a surface. Imagine placing heat at a point on a surface and watching it spread out. That pattern tells you about the shape of the surface. Using related math (graph Laplacians and heat kernels), the author builds localized, shape‑aware averaging tools that work on the manifold the data actually lives on. This gives better approximations with fewer data points.
3) Transfer learning as “lifting” between surfaces
Transfer learning asks: if I know something on one surface (manifold), can I use it to help on another? The paper treats this as lifting a function from one surface to another, like mapping a weather pattern from one map to a new map with a different projection. It studies:
- Where on the target surface this lifting is possible if you only see part of the data
- How the smoothness (how “wiggly” the function is) changes under the lift It even connects this to famous inverse problems (like reconstructing an image from its X‑ray scans), showing that transfer learning and these inverse tasks share the same underlying math.
4) Fast classification via “signal separation” and active learning
Imagine a music track with two instruments mixed together. Signal separation tries to pull them apart. The paper treats classification similarly: each class is like an instrument, and data from each class comes from its own “region” in space. Using this viewpoint, the author designs a method for active learning: instead of labeling everything, you smartly ask for a few labels that teach you the most. The result is a new algorithm that reaches accuracy similar to other modern methods but much faster.
What did the paper find?
- Direct, training‑free formulas can be just as accurate as trained models in many cases.
- They come with guarantees: the error shrinks at a known rate that depends on how smooth the true function is and how many data points you have.
- They are “local”: they keep sharp features where needed instead of blurring everything to please a global error score.
- They avoid common training problems like getting stuck in bad solutions, picking learning rates, or deciding when to stop.
- On manifolds, these methods handle high‑dimensional data more efficiently.
- Using heat‑kernel and Laplacian ideas, they build approximations that respect the data’s true shape.
- This helps dodge the curse of dimensionality and needs fewer samples for good accuracy.
- For transfer learning, the paper pinpoints where and how functions can be carried from one surface to another.
- It clarifies the relationship between the function’s smoothness on the source and target.
- It links transfer learning to classic inverse problems, opening new ways to reuse solutions.
- For active learning in classification, the new signal‑separation‑inspired algorithm is competitive in accuracy and significantly faster than many recent methods.
Why is this important?
- Speed and stability: Skipping long training makes models faster to build and less fragile.
- Better use of data: Local, geometry‑aware methods can capture fine details and work well with fewer samples.
- Smarter reuse: The transfer learning viewpoint helps move knowledge between tasks more reliably, especially when data is incomplete.
- Cheaper labeling: The active learning approach reduces how many labels you need without losing accuracy.
Bottom line
This dissertation shows that you can often “learn without training” by using smart mathematical constructions. By respecting the local smoothness of data and the low‑dimensional surfaces it lives on, you can build accurate, fast, and reliable predictors; transfer knowledge between tasks; and classify data with far fewer labels—all while avoiding many pitfalls of standard training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights what remains missing, uncertain, or unexplored based on the provided dissertation text. Each point is framed to be concrete and actionable for future work.
- The constructive trigonometric approximation framework assumes periodic domains (
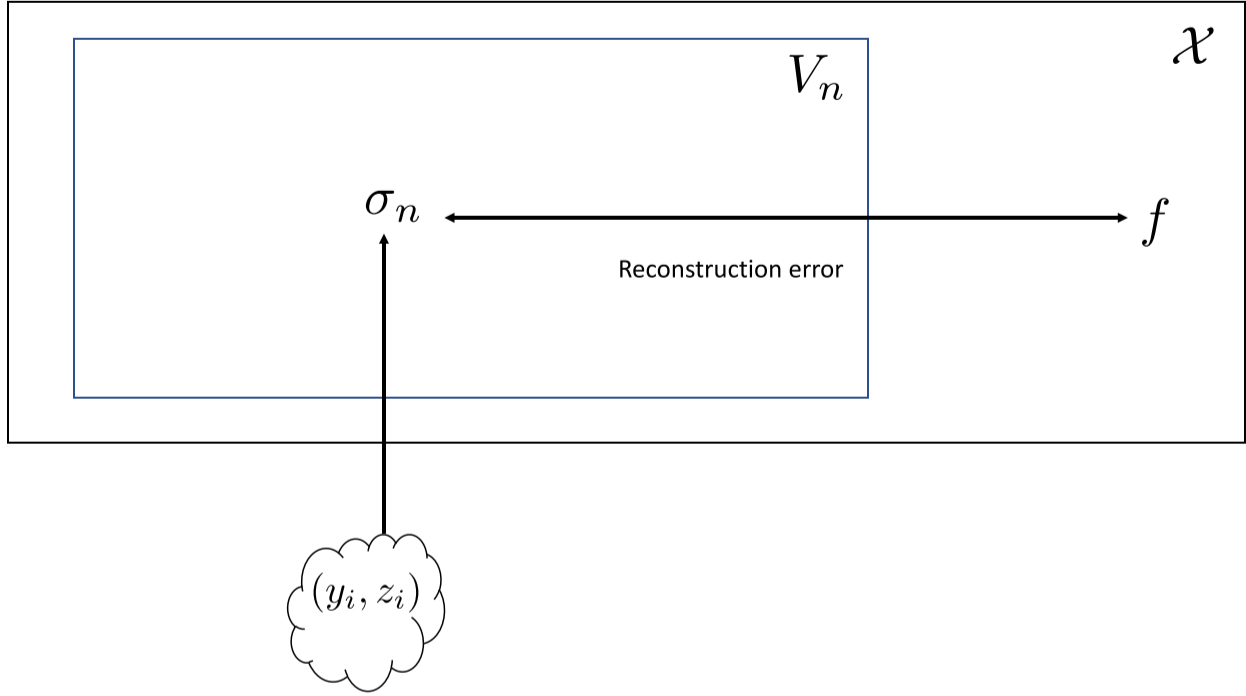
T^d) and uniform sampling (marginal distribution equal to the Lebesgue probability measure onT^d); how to extend the theory and guarantees (e.g., Theorem 3.5 and bound||\tilde{\sigma}_n - f||_\infty \lesssim n^{-\gamma}) to non-periodic domains, unknown supports, manifolds with boundaries, and non-uniform sampling distributions. - The discretized reconstruction operator
\tilde{\sigma}_n(x) = (1/M) \sum_{j=1}^M y_j \Phi_n(x - x_j)is analyzed under noiseless labels; rigorous high-probability error bounds under label noisey_j = f(x_j) + \epsilon_j(including sub-Gaussian and heavy-tailed noise) are not provided, nor are noise-robust variants of the operator. - The dependence of sample complexity
M \gtrsim n^{d+2\gamma} \log non dimensiondand smoothness\gammais stated without explicit constants or practical guidance; data-driven procedures to selectn(bandwidth) andM(sample size) adaptively to unknown local smoothness and heterogeneous sampling densities are missing. - The choice of the smoothing function
hin the kernel\Phi_nand its impact on approximation quality, stability, localization, and computational complexity is not characterized; criteria or automated selection strategies forhare not developed. - The “good approximation” bound
E_n(f) \le ||f - \sigma_n(f)|| \lesssim E_{n/2}(f)is stated globally, but a formal local-approximation theory (spatially adaptive rates that depend on the local smoothness or singularity structure off) is not established beyond the qualitative example withf(\theta) = |\cos \theta|^{1/4}. - Robustness of the constructive approach to misspecification of the sampling distribution (e.g., clustered or highly non-uniform
x_j), outliers, and adversarial noise is not analyzed; weighted or preconditioned versions of\tilde{\sigma}_nto correct for sampling biases remain an open design question. - The integral identity used to represent trigonometric expansions as neural networks (via
e^{i k \cdot x}expressed with activation\phi) is a theoretical bridge, but finite, discrete, training-free network constructions (depth/width bounds, parameter quantization, and hardware-friendly architectures) implementing\tilde{\sigma}_nare not specified. - There is no empirical evaluation comparing the constructive approximation method against standard ERM-trained neural networks across real datasets (accuracy, runtime, memory), nor ablations that isolate the contribution of periodicity, kernel choice, and sampling distribution.
- The dimension-independent existence bound on spheres (e.g.,
||f - \sum_{k=1}^N a_k |x \cdot y_k||| \lesssim N^{-(d+3)/(2d)}) contrasts with dimension-dependent constructive bounds (\lesssim N^{-2/d}), but a pathway to close this gap with constructive, data-driven methods achieving dimension-independent rates is not articulated. - For spherical constructions requiring quadrature nodes exact for certain polynomial degrees, algorithms to obtain such nodes from scattered data and conditions under which approximate quadratures suffice (with quantified degradation in rates) are not provided.
- The manifold learning discussion highlights sensitivity of the two-step pipeline (manifold estimation → function approximation) to parameters and noise, but does not provide a training-free function approximation method that bypasses explicit manifold estimation while preserving guarantees, nor guidelines to select diffusion scales, neighborhood radii, or eigen-truncation levels with provable risk control.
- Assumptions such as Gaussian upper bounds on heat kernels and finite speed of propagation are invoked for localized kernels; practical verification procedures for these assumptions on unknown manifolds from finite samples (including curved, non-compact, and boundary manifolds) are not given.
- The transfer learning project (lifting functions between manifolds, with partial data) lacks concrete algorithms and conditions for when the lifting is well-defined (e.g., identifiability and invertibility of the lifting operator), stability bounds under sampling and label noise, and precise characterizations of target subsets where lifting is possible.
- Relationships between local smoothness of
fand its lifted counterpart (regularity transfer laws) are described qualitatively; precise theorems, rates, and counterexamples for different manifold geometries and sampling regimes are not provided. - For inverse problems (e.g., inverse Radon transform) linked to transfer learning, there are no explicit sample complexity results, noise stability bounds, or guarantees under partial angular/radial coverage; algorithms bridging classical inversion formulas with data-driven lifting operators need development.
- The classification via active learning and signal separation analogy (supports of class distributions as “point sources”) is introduced, but the assumptions required (e.g., separability conditions, mixture models, support geometry) and formal performance guarantees (sample/query complexity, label efficiency, consistency) are not specified.
- The active learning query strategy (how to select points to query the oracle
ffor maximal information) is not detailed; stopping criteria with theoretical guarantees, robustness to label noise, extension to multi-class and imbalanced settings, and scalability in high dimensions remain open. - The critique of ERM and global loss functionals (insensitivity to local artifacts) motivates local methods, but a principled local risk functional, optimization-free estimator, or hybrid approach with explicit generalization bounds is not developed.
- The analysis of gradient descent shortcomings (local minima, dead-on-arrival, false stabilization) lacks proposed remedies integrated with the dissertation’s constructive approach (e.g., initialization schemes, training-free alternatives, certified stopping criteria) and formal convergence guarantees for specific architectures and losses.
- The nonlinear width lower bounds underscore the curse of dimensionality, but the dissertation does not characterize function classes (e.g., compositional, sparse, low-rank, or manifold-plus-sparsity) where training-free constructive methods can achieve dimension-free or improved widths with explicit algorithms and guarantees.
- Methods to estimate or learn smoothness parameters (e.g.,
\gammainW_\gamma) from data and to adapt reconstruction bandwidthsnlocally (spatial bandwidth selection) are not provided; designing adaptive estimators with oracle inequalities remains an open problem. - Computational aspects (time/space complexity, parallelization, GPU/TPU implementation) for the constructive operators and manifold kernels are not analyzed; practical pipelines and engineering considerations to make “learning without training” scalable to modern datasets are not addressed.
Glossary
- Active Learning: A learning paradigm where the algorithm can query an oracle for labels to maximize information gain. "Active learning incorporates ideas from both unsupervised and supervised learning."
- Atlas: A collection of local coordinate charts that cover a manifold, used to perform computations locally. "One approach is to estimate an atlas of the manifold, which thereby allows function approximation to be conducted via local coordinate charts."
- Banach space: A complete normed vector space often used as the setting for function approximation. "We assume that f belongs to some class of functions called the universe of discourse X (typically a Banach space),"
- Barron Space: A function space characterized by integrability of the Fourier transform with polynomial weight, used in neural network approximation theory. "We say that f: \mathbb{R}d\to \mathbb{R} belongs to the Barron Space with parameter s>0, denoted by B_s, if it satisfies the following norm condition"
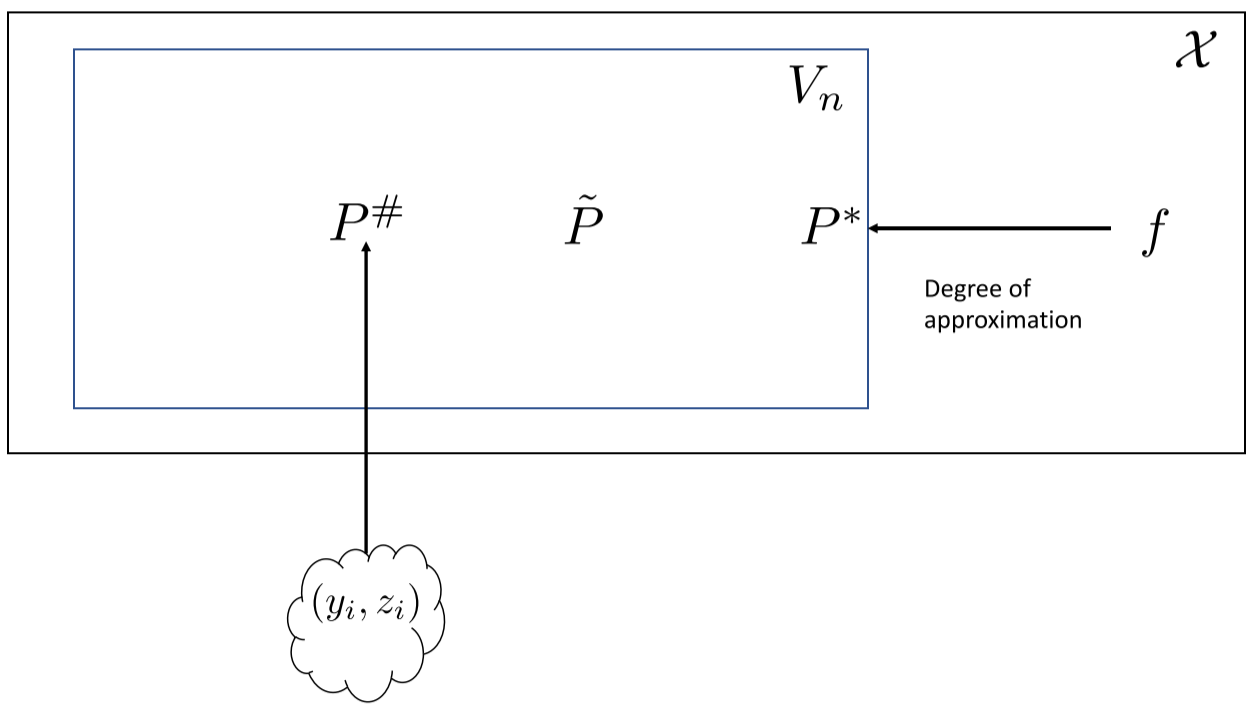
- Best approximation: The element of a hypothesis space closest to the target function in a chosen norm. "The best approximation, P*=\argmin_{P\in V_n}E_n(f), is the model from V_n that minimizes the degree of approximation."
- Chebyshev expansion: A series representation of a function in terms of Chebyshev polynomials, used for approximation. "For example, a shifted average of the partial sums of the Chebyshev expansion of f can be used in the uniform approximation case (p=\infty)."
- Classification: A task where the target function outputs discrete class labels. "In classification problems, the function f is discrete, taking on only some finite set of values called class labels."
- Curse of dimensionality: The phenomenon where the complexity or data requirements grow exponentially with dimension. "First, we examine a phenomenon known as the curse of dimensionality."
- Dead on arrival: An initialization pathology where a neural network outputs a constant due to poor parameter initialization. "The phenomenon has become known as dead on arrival."
- Degree of approximation: The minimal distance between a function and a hypothesis space under a norm. "The degree of approximation is defined to be the least possible distance from V_n to f."
- Diffusion geometry: A framework using diffusion processes (e.g., heat kernels) to analyze geometric structure in data. "The special issue \cite{achaspissue} of Applied and Computational Harmonic Analysis (2006) provides a great introduction on diffusion geometry."
- Diffusion maps (Dmaps): A manifold learning method based on diffusion processes to embed high-dimensional data. "diffusion maps (Dmaps) \cite{coifmanlafondiffusion}"
- Empirical risk: A loss computed on the available dataset that approximates the expected loss. "Instead, one typically seeks to find a minimizer of the empirical risk, which is a discretized version of the generalization error based on the data."
- Empirical risk minimization: The paradigm of training models by minimizing empirical loss over the dataset. "Both questions are essential to the performance of machine learning algorithms trained by empirical risk minimization"
- Eigendecomposition: Decomposition of an operator into eigenvalues and eigenfunctions/vectors, used for manifold analysis. "It has been shown that the so-called graph Laplacian (and the corresponding eigendecomposition) constructed from data points converges to the manifold Laplacian and its eigendecomposition"
- Exclusive-OR function: A nonlinearly separable boolean function used to test universality of models. "it is known that if \phi(t)=t, then there is no network which can reproduce even the exclusive-OR function."
- False stabilization: Apparent convergence of an optimization process that later continues changing. "this runs into the issue of false stabilization, or reaching a point where the iterations seem to converge to a point but in actuality will continue changing given enough iterations."
- Fourier coefficients: Integrals defining the frequency components of a function on the torus. "The Fourier coefficients of a function f\in L1(\mathbb{T}d) are defined by"
- Fourier projection: The projection of a function onto trigonometric polynomials via its Fourier coefficients. "The best approximation in the sense of the global L2 norm is given by the Fourier projection, defined by"
- Gaussian upper bounds: Bounds on the heat kernel exhibiting Gaussian decay, linked to wave propagation properties. "equivalent to the so called Gaussian upper bounds on the heat kernels."
- Generalization error: The expected loss over the true data distribution, not just the training set. "The primary approach to select a model from V_n is to introduce the notion of a generalization error, which is given as a loss functional"
- Graph Laplacian: A discrete Laplacian constructed from data points that approximates the manifold Laplacian. "It has been shown that the so-called graph Laplacian (and the corresponding eigendecomposition) constructed from data points converges to the manifold Laplacian and its eigendecomposition"
- Gradient descent: An iterative optimization method that updates parameters in the negative gradient direction. "we will limit our discussion to a commonly used method known as gradient (or steepest) descent."
- Heat kernel: The fundamental solution to the heat equation on a manifold, used for approximation and embeddings. "Another important tool is the theory of localized kernels based on the eigen-decomposition of the heat kernel."
- Hessian locally linear embedding (HLLE): A variant of LLE that uses Hessian-based constraints for dimensionality reduction. "Hessian locally linear embedding (HLLE) \cite{david2003hessian}"
- Hypothesis spaces: Families of functions chosen to model the target function. "then decide on some hypothesis spaces V_n of functions to model f by"
- Isomaps: A nonlinear dimensionality reduction method preserving geodesic distances. "including Isomaps \cite{tenenbaum2000global}"
- Kolmogorov function: An activation function that yields universal approximation with shallow networks. "Any activation function which yields a family of universal approximator neural networks is called a Kolmogorov function."
- Laplace-Beltrami operator: The intrinsic Laplacian on a Riemannian manifold. "heat kernel corresponding to the Laplace-Beltrami operator on the manifold."
- Laplacian eigenmaps (Leigs): A spectral embedding method using the graph Laplacian’s eigenvectors. "Laplacian eigenmaps (Leigs) \cite{belkinlaplacian}"
- Learning rate: The step size parameter in iterative optimization updates. "where \eta is called the learning rate, or step size."
- Local tangent space alignment (LTSA): A manifold learning technique that aligns local tangent spaces. "local tangent space alignment (LTSA) \cite{zhang2004principal}"
- Locally linear embedding (LLE): A manifold learning algorithm preserving local linear relationships. "locally linear embedding (LLE) \cite{roweis2000nonlinear}"
- Localized kernels: Kernels concentrated around points used for local approximation and multi-resolution analysis. "the theory of localized kernels based on the eigen-decomposition of the heat kernel."
- Manifold assumption: The hypothesis that data lie near a low-dimensional manifold in high-dimensional space. "This has become known as the manifold assumption."
- Manifold learning: Techniques that infer manifold structure from data and use it for tasks like approximation. "The purpose of this section is to introduce a relatively new paradigm of manifold learning."
- Marginal distribution: The distribution of a subset of variables (e.g., inputs) derived from a joint distribution. "Let the marginal distribution of the points {x_j} be \mu_d*."
- Mean-squared-error (MSE): A common loss function measuring squared differences between predictions and targets. "Many choices can be used for such a loss functional, but perhaps the most common example is mean-squared-error (MSE), which is given as"
- Maximum variance unfolding (MVU): A dimensionality reduction method equivalent to a semidefinite program. "maximum variance unfolding (MVU) which is also known as semidefinite programming (SDP)"
- Moving least-squares: A local regression technique used for approximation on manifolds. "Approximations utilizing estimated coordinate charts have been implemented, for example, via deep learning \cite{cloninger-net,coifman_deep_learn_2015bigeometric,schmidt2019deep}, moving least-squares"
- Nonlinear width: A measure of the best possible approximation error achievable by any continuous parameterization and reconstruction. "The nonlinear Lp width is defined by"
- Oracle: A ground-truth function that can be queried at a cost to obtain labels in active learning. "we are also given f called an oracle in this context."
- Quadrature formula: A numerical integration rule exact for polynomials up to a given degree. "which admit a quadrature formula exact for integrating spherical polynomials of a certain degree"
- Radial basis function (RBF) networks: Networks using radially symmetric basis functions for approximation. "when one considers approximation by radial basis function (RBF) networks, it is observed in many papers (e.g., \cite{eignet})"
- Radon transform: An integral transform mapping a function to its integrals over hyperplanes, appearing in inverse problems. "such as the inverse Radon transform"
- Rectified linear unit (ReLU): A piecewise-linear activation function defined as max(0, x). "Another example is the popular choice of activation function known as the rectified linear unit (ReLU), defined by"
- Regression: A task where the target function outputs continuous values, possibly with noise. "In regression problems the function f may take on any value on a continuum"
- Remez algorithm: An iterative method to compute near-best polynomial approximations in the uniform norm. "the process may be aided by methods such as the Remez algorithm."
- Semidefinite programming (SDP): Convex optimization over positive semidefinite matrices, used in MVU. "maximum variance unfolding (MVU) which is also known as semidefinite programming (SDP) \cite{weinberger2005nonlinear}"
- Shallow neural network: A single-hidden-layer neural network used for function approximation. "A shallow neural network is a function approximation model typically taking the form"
- Sigmoidal activation function: An S-shaped nonlinearity used in neural networks. "the function \phi(x)=\tanh(x) is a sigmoidal activation function"
- Sobolev space: A function space with integrable derivatives up to a certain order. "The Sobolev space with parameters r,p on a set \mathbb{X}\subseteq \mathbb{R}d is defined as Wd_{r,p}(\mathbb{X})="
- Stone-Weierstrass theorem: A theorem guaranteeing uniform approximation of continuous functions by polynomials. "From the Stone-Weierstrass theorem, we know that if f\in \mathcal{X}, then for any \epsilon>0 there exists n and P\in V_n such that"
- Supervised Learning: A paradigm where models learn from labeled data to predict outputs for unseen inputs. "Supervised Learning: The main goal of supervised learning is to generate a model to approximate a function f on unseen data points."
- Transfer learning: Leveraging knowledge from one domain to improve performance in another domain. "The second project deals with transfer learning, which is the study of how an approximation process or model learned on one domain can be leveraged to improve the approximation on another domain."
- Trigonometric polynomials: Finite sums of complex exponentials used to approximate periodic functions. "We introduce the approximation of multivariate 2\pi-periodic functions by trigonometric polynomials."
- Universal approximation property: The ability of a hypothesis family (e.g., networks) to approximate any continuous function on compact sets. "We say that a sequence of hypothesis spaces, {V_n}, satisfies a universal approximation property if"
- Universe of discourse: The function space within which the target function is assumed to reside. "We assume that f belongs to some class of functions called the universe of discourse \mathcal{X}"
- Variational modulus of smoothness: A quantity measuring function smoothness used in approximation bounds for multilayer networks. "In \cite{mhaskar-multilayer}, degree of approximation results were shown for multilayer neural networks in terms of a variational modulus of smoothness."
- Wave propagation: The physical phenomenon whose finite speed property relates to kernel localization on manifolds. "finite speed of wave propagation."
Practical Applications
Immediate Applications
Below is a concise list of near-term, deployable uses that build on the paper’s constructive approximation, manifold-based methods, and fast active learning insights. Each item includes the sector(s), a brief description of how it would work in practice, and key assumptions/dependencies.
- Training-free regression for periodic/time-angle signals
- Sectors: signal processing, robotics, geoscience, telecom, energy
- What: Use the constructive “good approximation” operator (σₙ) with localized trigonometric kernels to fit periodic or angular signals (e.g., phase, direction, cyclical time features) directly from sampled data—no gradient-based training.
- Tools/workflow: Precompute kernel Φₙ; compute σ̃ₙ(x)=M⁻¹∑ⱼyⱼΦₙ(x−xⱼ); optionally wrap as a fixed-weight “network” for deployment; integrate into Python/R pipelines for fast, training-free regression.
- Assumptions/dependencies: Target is (approximately) periodic or defined on tori/angles; mild smoothness on f; sample budget M scales with frequency budget n and effective dimension d via M≳n{d+2γ}log n; data roughly cover the domain (no large holes).
- On-device, low-power inference with fixed networks (no training)
- Sectors: embedded/IoT, mobile, robotics
- What: Replace trained regressors with fixed-weight networks derived from σ̃ₙ, enabling deterministic, low-latency inference on constrained hardware.
- Tools/workflow: Offline construction of weights via kernel discretization; deploy with quantization; integrate into microcontroller ML stacks (e.g., TensorFlow Lite Micro) since runtime is just linear ops.
- Assumptions/dependencies: Domain structure is known or approximable (e.g., periodic coordinates or graph-based coordinates); sufficient coverage in the calibration dataset.
- Fast active learning for classification via signal-separation principles
- Sectors: remote sensing (hyperspectral), document classification, cybersecurity (anomaly/malware), manufacturing QA
- What: Use the paper’s active learning algorithm that treats class supports analogously to signal sources, prioritizing queries that separate supports; competitive accuracy with markedly lower compute time.
- Tools/workflow: Plug-in acquisition strategy for pool-based active learning loops (e.g., scikit-learn, PyTorch Lightning); deploy to reduce labeling costs in high-volume pipelines.
- Assumptions/dependencies: Classes correspond to distinguishable supports in feature space; an oracle for labels is available; feature scaling/metric selection amplifies support separation.
- Semi-supervised learning on graphs/manifolds using localized kernels
- Sectors: healthcare (risk stratification using patient similarity graphs), recommender systems, social networks, e-commerce
- What: Build label propagation/regression on graph Laplacians using heat-kernel-based localized frames; avoids heavy global loss minimization and adapts to manifold structure.
- Tools/workflow: Construct kNN graph → compute (approximate) Laplacian eigensystem or heat kernel → apply localized kernel synthesis for interpolation; use libraries for spectral graph methods.
- Assumptions/dependencies: Graph captures manifold geometry (e.g., meaningful affinity kernel); sufficient sampling and connectivity; Gaussian upper bounds (or practical proxies) hold approximately.
- Local-error-aware model diagnostics and post-processing
- Sectors: software/MLOps, regulated industries (finance, healthcare)
- What: Apply σₙ-based local approximations to assess and correct global-model artifacts (e.g., ringing near singularities or sharp transitions); improves reliability without retraining.
- Tools/workflow: Post-hoc local smoothing/denoising with constructive kernels; targeted refinement near detected singularities; CI/CD hooks for model health checks.
- Assumptions/dependencies: Access to residuals or validation data; local smoothness varies across domain; computational budget for local reconstructions.
- Rapid baselines and AutoML components for high-dimensional problems
- Sectors: enterprise AI platforms, consulting/analytics
- What: Add “learning without training” baselines to AutoML for quick feasibility checks and as strong non-optimized benchmarks (especially where domain geometry is known or estimable).
- Tools/workflow: Auto-select periodic/angular embeddings or construct graphs; choose n via held-out error; deploy as a baseline or ensemble component.
- Assumptions/dependencies: Reasonable manifold/periodicity proxies; moderate sample sizes to estimate kernels reliably.
- Limited-angle or sparse-view tomographic reconstruction (partial transfer)
- Sectors: medical imaging (CT), industrial NDT, geophysics
- What: Use the transfer-learning-as-lifting viewpoint to identify regions in the image domain where reliable inversion from partial Radon data is possible; guide reconstruction and uncertainty maps.
- Tools/workflow: Map sinogram subsets → reconstruct only guaranteed regions; overlay confidence; integrate with existing iterative solvers to prioritize where physics permits stable lifting.
- Assumptions/dependencies: Known forward operator (Radon), partial data patterns compatible with theoretical lifting domains; acceptance of region-restricted reconstructions in practice.
Long-Term Applications
These opportunities require additional research, scaling, or integration before mainstream deployment, but they flow naturally from the dissertation’s theoretical advances.
- General-purpose “learning without training” libraries for arbitrary manifolds
- Sectors: software tooling, scientific ML
- What: A production-grade library that constructs localized kernels on unknown manifolds from data (via graph Laplacians/heat kernels) and performs training-free regression/classification with theoretical error guarantees.
- Tools/products: Open-source package (e.g., “NoTrain”), automated graph construction, scalable spectral approximations (Nyström, randomized eigensolvers), hyperparameter selection for n, γ, and sample budgets.
- Assumptions/dependencies: Robust, scalable estimation of manifold geometry under noise; validated Gaussian bounds or substitutes; guidelines for sample complexity in diverse domains.
- Safe and certifiable transfer learning via manifold lifting
- Sectors: healthcare (cross-site model adaptation), autonomous systems, finance (cross-market transfer)
- What: Formalize and implement transfer procedures that only act on target subdomains where lifting is provably defined, with local smoothness-preserving guarantees—reducing negative transfer.
- Tools/products: “Transfer eligibility maps” for target data; conservative adaptation workflows in MLOps; explainable transfer reports for regulators.
- Assumptions/dependencies: Existence and identifiability of lifting maps; methods to estimate local smoothness and overlap between source/target manifolds; labeled or structured partial data.
- Physics-guided inverse problem solvers with partial-data guarantees
- Sectors: medical imaging, materials science, seismology
- What: Embed lifting-based constraints and local smoothness relations into solvers for limited/contaminated measurements (e.g., limited-angle CT, sparse MRI), focusing reconstruction where theory guarantees stability.
- Tools/products: Hybrid iterative solvers with lifting constraints; region-specific confidence intervals; operators integrated with hospital PACS/industrial QA systems.
- Assumptions/dependencies: Accurate forward operators and noise models; validated mappings from measurement space to reconstruction subdomains.
- Low-power, training-free edge AI co-processors
- Sectors: semiconductors, IoT, wearables
- What: Hardware accelerators specialized to fixed-kernel constructive inference (convolutions with data-derived kernels), enabling real-time edge analytics without cloud training or updates.
- Tools/products: ISA extensions for kernel synthesis and evaluation; memory-efficient kernel storage; co-design of data collection and kernel construction pipelines.
- Assumptions/dependencies: Stable kernel derivation offline; standardized representations across deployments; ecosystem and tooling to adopt new hardware capabilities.
- Active learning for scientific discovery and experiment design
- Sectors: materials discovery, biology, chemistry
- What: Use support-separation principles to choose minimal, most-informative experiments (label queries) that delineate regimes or phases, accelerating discovery with fewer trials.
- Tools/products: Lab-in-the-loop active learning platforms with acquisition strategies grounded in support separation; integration with ELNs and automation.
- Assumptions/dependencies: Features reflect underlying physics (separable supports); reliable measurement oracles; mechanisms to update supports as new data arrives.
- Privacy-preserving/federated constructive learning
- Sectors: healthcare, finance, mobile platforms
- What: Compute localized kernels and fixed models on-device or on-prem, then share only aggregated kernel summaries; avoids sharing raw data and bypasses training-phase leakage.
- Tools/products: Federated protocols for sharing kernel moments or quadrature weights; differential privacy add-ons.
- Assumptions/dependencies: Secure aggregation; theoretical understanding of privacy leakage from shared kernel summaries.
- Robust ML that avoids global-loss pitfalls
- Sectors: regulated AI, safety-critical systems
- What: Replace or augment global-loss minimization with locally adaptive constructive methods that preserve important local features (edges, singularities, rare events).
- Tools/products: Hybrid pipelines that switch to constructive approximations near detected irregularities; certification suites for local error bounds.
- Assumptions/dependencies: Reliable detection of non-smooth regions; calibration of local vs global trade-offs; domain-specific validation.
- Cross-modal and multi-sensor alignment via manifold lifting
- Sectors: autonomous vehicles, remote sensing, AR/VR
- What: View cross-modal alignment (e.g., LiDAR↔camera) as lifting between manifolds; design algorithms that identify subspaces of safe transfer and preserve local smoothness for fusion.
- Tools/products: Sensor fusion modules with lifting eligibility checks; per-region confidence maps; failure-aware fallbacks.
- Assumptions/dependencies: Sufficient overlapping structure between modality manifolds; synchronization and calibration quality; computationally tractable lifting estimators.
- Curriculum and pedagogy: algorithmic alternatives to training
- Sectors: education, workforce upskilling
- What: Teach constructive approximation and manifold-based learning as practical alternatives to black-box training, highlighting sample complexity and local-error behavior.
- Tools/products: Course modules, interactive notebooks, and lab assignments; benchmarking kits comparing training-free and trained models.
- Assumptions/dependencies: Access to datasets with periodic/manifold structure; instructor familiarity with spectral/graph methods.
These applications collectively highlight a path toward faster, more explainable, and resource-efficient machine learning pipelines—particularly in settings where domain geometry can be leveraged and where global empirical-risk optimization is costly or brittle.
Collections
Sign up for free to add this paper to one or more collections.