- The paper introduces RSI, reducing the Hadamard product complexity in TT formats from quartic to cubic scaling.
- It combines randomized TT sketching with interpolative decomposition to maintain low bond dimensions during nonlinear operations.
- Benchmark results demonstrate that RSI achieves competitive accuracy with significant improvements in runtime and memory usage.
Recursive Sketched Interpolation: Efficient Hadamard Products of Tensor Trains
Introduction
The paper "Recursive Sketched Interpolation: Efficient Hadamard Products of Tensor Trains" (2602.17974) addresses the computational bottleneck in performing Hadamard (element-wise) products between tensors represented in the tensor train (TT) format. While the TT format substantially reduces the storage and computational complexity in high-order tensor computations, existing approaches to compute the Hadamard product scale at least as O(χ4) in the bond dimension χ, which becomes prohibitive for large χ. The authors propose Recursive Sketched Interpolation (RSI), a novel algorithm combining randomized TT sketching and interpolative decomposition (ID) to reduce the complexity to O(χ3), thus closing a significant gap in the TT toolbox for nonlinear operations.
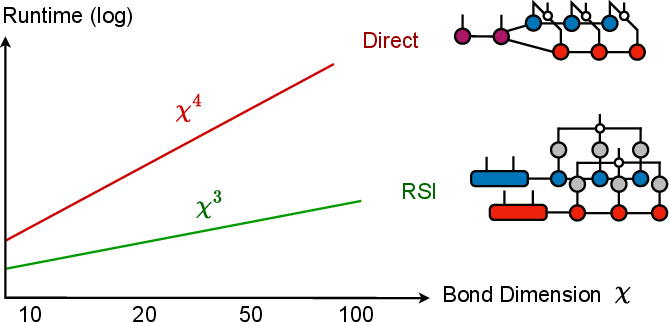
Figure 1: RSI achieves cubic (χ3) scaling for Hadamard product of TTs, compared to quartic scaling of the direct (Kronecker-based) method; tensor diagrams illustrate computational workflows.
Background
The TT/MPS formalism represents a high-order tensor as a contraction of a chain of third-order tensors (TT-cores) with internal bond dimensions. Known for its effectiveness in many-body quantum physics, scientific computing, and machine learning, the TT format enables efficient linear algebra routines (e.g., DMRG, operator application) that typically scale as O(χ3). However, nonlinear operations, especially Hadamard products, are less amenable to efficient contraction due to the inability to contract over physical indices and the resulting intermediate rank blow-up.
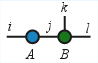
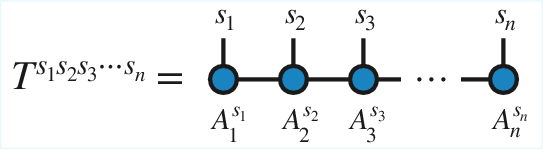
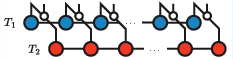
Figure 2: The contraction ∑jAijBjkl visualized with tensor network diagram notation—a foundation for representing TT and its algebraic operations.
Conventional methods compute the Hadamard product by core-wise Kronecker products and then compress the result using TT-rounding (SVD-based truncation). This results in a TT with bond dimension χ2 before truncation, demanding O(χ4) time and memory.
Alternative approaches, such as tensor cross interpolation (TCI/TT-cross), amortize some of the cost by adaptively selecting tensor slices via interpolative decomposition, but still require querying O(χ2) entries per core, each costing O(χ2) contraction, again leading to O(χ4) complexity.
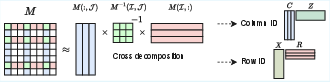
Figure 3: Schematic of cross/interpolative decomposition on matrix M; TT-cross generalizes this to tensors for efficient low-rank approximations.
Randomized numerical linear algebra—specifically, sketching methods—enables further dimension reduction by projecting high-dimensional data into lower-dimensional subspaces using random projections, which preserve the relevant range with high probability. Prior work has successfully applied such sketching to speed up TT rounding, contractions, and learning, motivating integration with interpolative decomposition for accelerating nonlinear operations.
RSI Algorithmic Framework
The core insight of RSI is to maintain manageable bond dimensions throughout computation by never forming the full redundant product tensor. Each iteration performs:
- TT Sketching: Contract all TT-cores except two with a random tensor (sketch), producing low-dimensional “slices” retaining critical interpolation geometry.
- Sketched Hadamard Product and ID: Form the Hadamard product of corresponding sketched tensors and perform a row-ID to extract the interpolation matrix, which becomes a TT-core of the output.
- Re-Interpolate Inputs: Align input TTs’ indexing structure according to pivots (‘skeleton indices’) selected in the output, enabling recursion across the chain.
The process recursively constructs the output TT core-by-core, with a mixed forward–backward sweep for sketch construction and efficient Khatri–Rao updating. Notably, the sketch dimension k is only required to be proportional to the target bond dimension χmax, providing a tunable accuracy/efficiency trade-off.

Figure 4: Workflow visualization of the first RSI iteration: sketching, Hadamard product of sketches, and ID yield the first output TT-core.
A detailed computational analysis reveals each step incurs at most O(d2χ3) cost (external dimension d), establishing end-to-end O(nd2χ3) runtime for order-n tensor trains—matching typical linear TT operations and decisively outperforming previous element-wise product algorithms.
Benchmark Results
RSI is systematically benchmarked against established methods (direct Kronecker-based, TCI/TT-cross) in several high-impact scenarios. For moderate-sized quantum many-body states (20-site Heisenberg chain, physical dimension d=3), RSI matches the direct method and TCI in relative Frobenius error for identical output rank, while exhibiting strictly superior runtime scaling. The small, controlled increase in interpolation error (relative to SVD-based rounding) is offset by dramatic decreases in execution time and memory consumption.
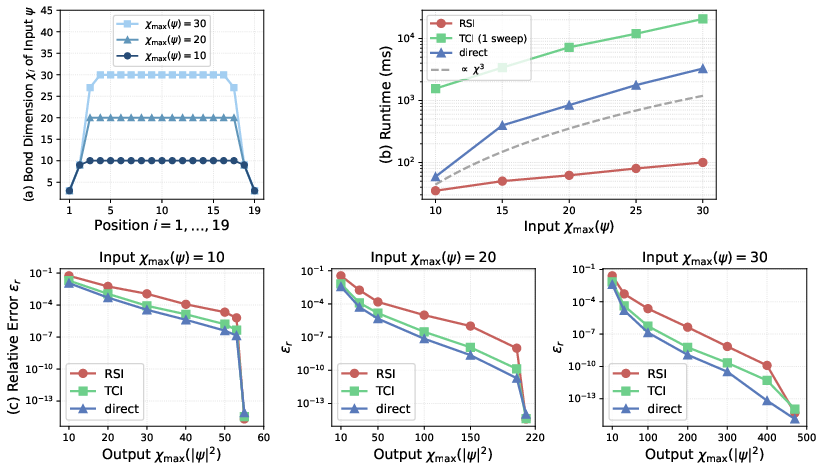
Figure 5: The bond dimension profiles χi of the MPS wavefunction for χmax=10,20,30.
For 50-site systems, where both Kronecker and TCI become impractical, RSI remains tractable and yields physical observables (e.g., energy expectation values) almost indistinguishable from the exact, as quantified by the observable deviation Z.
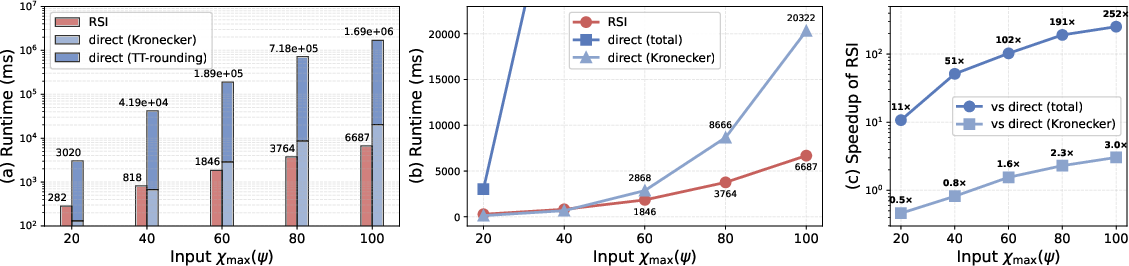
Figure 6: (a) RSI runtime grows gently with χ, while the direct method’s time is dominated by the TT-rounding/ SVD step; (b) isolated Kronecker product cost; (c) RSI speedup scaling.
Applied to smooth QTT-represented functions (e.g., Gaussians), RSI's accuracy is essentially optimal and robust across diverse shapes (shifting means, variances, multi-factor Hadamard products), achieving errors near machine precision with minimal computational overhead. In harder cases—highly oscillatory functions—RSI retains favorable complexity but accuracy degrades commensurately with the complexity of the tensor geometry, reflecting the limitations of the basic sketch (Khatri–Rao of random Gaussians). Oversampling in the sketch dimension marginally helps but does not close the gap, suggesting room for further refinement.
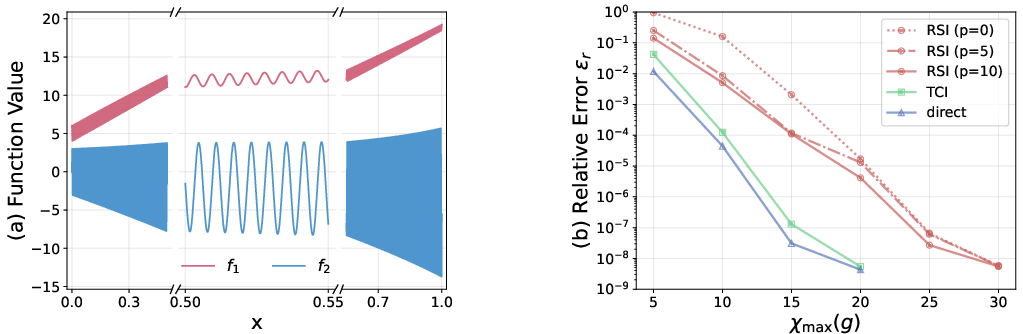
Figure 7: (a) Two highly oscillatory functions f1, f2 and the fine-scale structure they entail; (b) convergence of relative error ϵr for various oversampling ratios and methods.
Application to Nonlinear PDEs and Convolution
The practical impact of RSI is strongest in high-dimensional scientific computing workflows, especially in numerical solutions of nonlinear PDEs (e.g., in fluid dynamics, quantum many-body problems), and in fast evaluation of convolutions in the TT (or QTT) format via the Fourier transform and element-wise multiplication.
In PDEs such as active matter models, RSI efficiently computes nonlinear terms requiring Hadamard products (e.g., Dxx⋅Dxx for orientation tensors), delivering accurate low-rank approximations that agree with the dense counterpart for practically relevant TT ranks.

Figure 8: Snapshots of concentration c, velocity u, and orientation D at a representative simulation time-step extracted from the Well PDE dataset.
For convolution, integration with fast TT-based FFT algorithms enables highly efficient FFT-conv-product-FFT−1 workflows using RSI as the nonlinear core, retaining the accuracy of TT representation throughout.

Figure 9: End-to-end convolution workflow in QTT: FFT, RSI-based Hadamard product, and inverse FFT.
Extension to General Nonlinear Maps
RSI further generalizes to the application of arbitrary pointwise nonlinearities to TT-represented tensors (e.g., G=g(T)), simply by modifying the elementwise operation in the sketched step. The experiments demonstrate the computation of the ReLU function on a QTT as a prototypical nonlinearity, with bond dimension-dependent accuracy performance comparable to TCI, but with improved scaling.
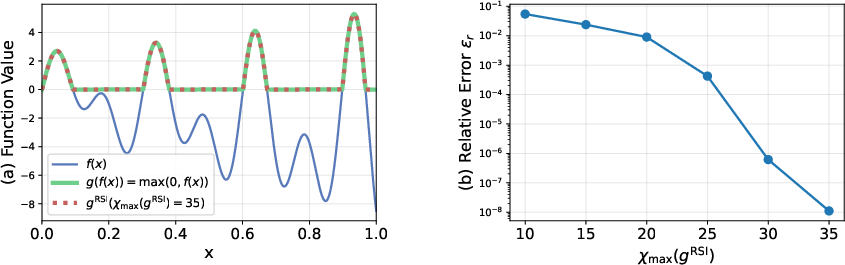
Figure 10: Approximation of g(f(x)) for ReLU and a smooth function, exhibiting convergence as χmax increases.
Theoretical and Practical Implications
The principal technical contribution—enabling cubic χ scaling for nonlinear TT operations—extends established randomized linear algebra techniques into a computational regime previously closed off by intermediate tensor rank explosion. This development closes a gap in the TT/MPS algorithmic toolbox, with immediate consequences for high-dimensional PDE solvers, quantum simulations, manifold learning, and functional tensorized models.
Practically, researchers can now incorporate nonlinearities into their TT-based pipelines without incurring exponential costs. The accuracy/runtime trade-off is tunably controlled by parameters such as sketch dimension and rank truncation, and further improvements (e.g., custom sketches adapted to function structure) appear tractable.
Theoretically, RSI's structure highlights the connections and trade-offs between randomized sketching and adaptive interpolation in tensor settings, potentially enabling future advances in more general classes of tensor networks (e.g., PEPS, TTNS).
Conclusion
RSI unifies randomized tensor-train sketching and interpolative decomposition into an efficient, robust framework for Hadamard product and nonlinear map computation on TT-tensors, reducing the complexity from quartic to cubic in the bond dimension. Extensive benchmarks validate both the superior scalability and competitive accuracy of this approach, with immediate applicability across computational science and engineering. Future research will benefit from exploring structured sketching, further generalizations, and integration into end-to-end scientific pipelines, especially for function learning and quantum simulation.
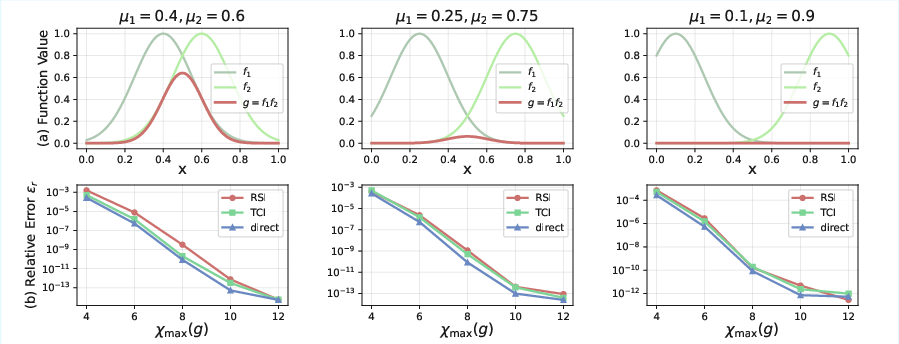
Figure 11: Illustration of Gaussian inputs and the correspondence of approximation error as a function of rank for RSI and baseline methods.

