A Theoretical Framework for Modular Learning of Robust Generative Models
Abstract: Training large-scale generative models is resource-intensive and relies heavily on heuristic dataset weighting. We address two fundamental questions: Can we train LLMs modularly-combining small, domain-specific experts to match monolithic performance-and can we do so robustly for any data mixture, eliminating heuristic tuning? We present a theoretical framework for modular generative modeling where a set of pre-trained experts are combined via a gating mechanism. We define the space of normalized gating functions, $G_{1}$, and formulate the problem as a minimax game to find a single robust gate that minimizes divergence to the worst-case data mixture. We prove the existence of such a robust gate using Kakutani's fixed-point theorem and show that modularity acts as a strong regularizer, with generalization bounds scaling with the lightweight gate's complexity. Furthermore, we prove that this modular approach can theoretically outperform models retrained on aggregate data, with the gap characterized by the Jensen-Shannon Divergence. Finally, we introduce a scalable Stochastic Primal-Dual algorithm and a Structural Distillation method for efficient inference. Empirical results on synthetic and real-world datasets confirm that our modular architecture effectively mitigates gradient conflict and can robustly outperform monolithic baselines.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a big, practical question: Instead of training one giant, expensive AI model on everything, can we build a strong model by combining several small, specialized models (experts)—and make sure this combo works well no matter how the data changes? The authors design a mathematical framework for doing exactly that, and they prove that this “modular” approach can be both reliable and, in some cases, even better than training one giant model from scratch.
What questions does it ask?
In simple terms, the paper focuses on four main questions:
- Can we combine small expert models (like one for math, one for code, one for writing) into one system that performs as well as a big model?
- Can we pick the combination in a way that’s robust—meaning it works well for any mix of tasks, even if the mix changes later?
- Can we bound (predict) how well this method will generalize to new data based on the simplicity of the “combiner,” not the size of the experts?
- Is there a clear reason why this modular method could beat a single big model trained on all the data together?
How do the authors approach the problem?
Modular experts and a “gate”
Think of a team of specialists: a math expert, a coding expert, a writing expert, and so on. For each input (like a sentence), a lightweight “gate” assigns weights to these experts—basically, how much to listen to each one. The final answer is a weighted blend of all experts’ outputs.
This gate:
- Looks at the input and assigns nonnegative weights to experts that add up to 1 (so the final result is still a valid probability distribution).
- Is small and fast to learn compared to the experts, which are “frozen” (already trained).
Mathematically, the combined model is like:
- Combined output = sum over experts of [gate weight × expert output].
Training as a game versus a tricky opponent
The authors imagine an adversary who picks the worst-possible mixture of tasks (for example, 70% coding, 10% math, 20% writing—except you don’t know these numbers). The goal is to learn one gate that performs well even against this “worst-case” mix. This setup is called a minimax game:
- We choose the gate to minimize the loss.
- The adversary chooses the mixture of tasks to maximize the loss.
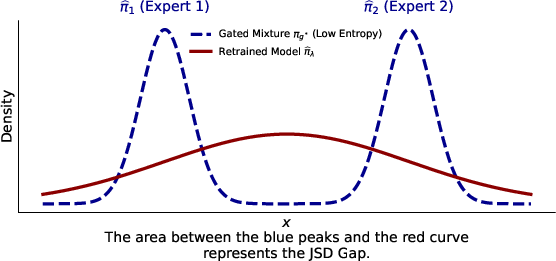
The “loss” is measured by KL divergence—a way of measuring how different two probability distributions are (you can think of it as how surprised the model would be by the real data). The paper also uses the Jensen–Shannon Divergence (JSD), which measures how different the sources (tasks) are from each other—their “diversity.”
Guarantees that a good gate exists
Using a well-known math result (Kakutani’s fixed-point theorem), the authors prove that:
- A stable solution exists: there is at least one gate and one “worst-case” mixture that balance each other (a saddle point).
- The performance of this robust gate can be bounded in terms of:
- How good the experts are individually,
- How much the experts overlap (do they make similar predictions?),
- How diverse the tasks are (measured by JSD).
Important insight: Modularity acts like a strong regularizer. That is, how much data you need scales with the gate’s complexity (small), not the size of the experts (huge).
Learning and making it fast
They propose:
- A stochastic primal–dual algorithm: Imagine two players—one adjusts the gate, the other picks the mixture of tasks. Each takes small steps to improve. Over time, they converge to the stable solution.
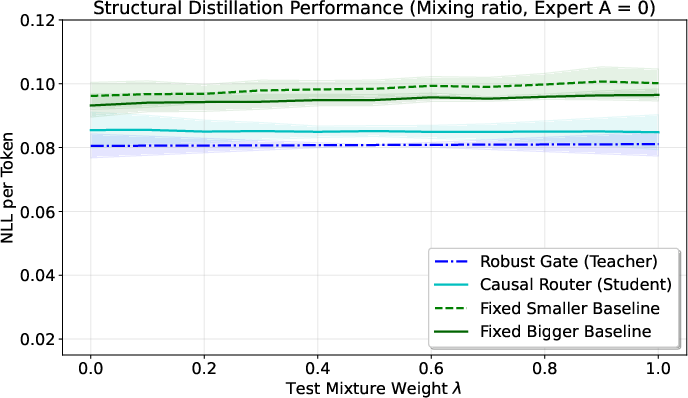
- Structural distillation: The gate may need to “peek” at the whole sequence to assign weights, but real-time text generation needs decisions one token at a time. Structural distillation turns the original gate into a fast, causal “router” that works during generation without looking ahead.
What did they find?
For a known mix of tasks
If you already know the mixture (say, exactly 40% math, 60% writing), a simple constant gate (fixed weights) does pretty well: it blends experts using those same proportions and achieves at most the weighted-average of each expert’s error.
A single robust gate exists, with clear advantages
For unknown (and changing) mixtures, they prove a robust gate exists. Its worst-case error can be bounded by three meaningful pieces:
- A “capacity cost” term that depends on the individual expert errors,
- A “separability gain” from task diversity (JSD)—diversity helps the gate,
- An “overlap gain” when experts agree a lot—agreement helps reduce cost.
Three intuitive cases:
- Disjoint experts (like non-overlapping subjects): Diversity is high, which helps the gate cancel out the capacity cost. The system stays strong even when tasks are very different.
- Identical experts: The gate doesn’t hurt you; you get the same performance as a single expert.
- Overlapping experts with different quality: The gate acts like a smart ensemble, emphasizing better experts in the right places.
When prior knowledge helps
If you know ahead of time that some mixes are unlikely (for example, code will be at most 5% of your data), you can restrict the adversary to a smaller set of mixtures. The paper proves this always improves the worst-case guarantee. They also show how to adjust the algorithm to enforce such constraints.
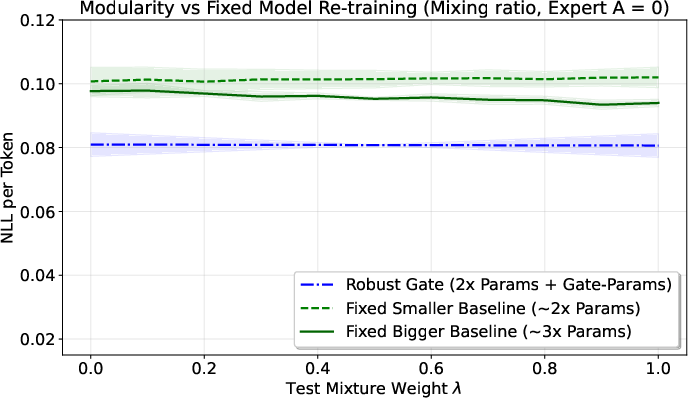
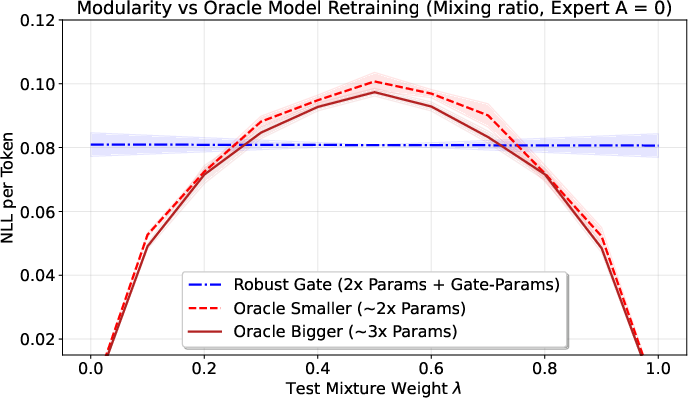
Why modular can beat retraining
If you train one big model on all data at once (monolithic training), the tasks can “interfere” with each other. The paper shows a clean formula: the average per-task error equals “how well you fit the overall mixture” plus the JSD (the tasks’ diversity). That means even a very strong single model hits a floor set by the data’s diversity.
In contrast, the modular approach turns that same diversity into an advantage—because the gate can separate tasks and route inputs to the right expert. Bottom line: when tasks are quite different, a modular system can outperform a single retrained model.
They also show a “safety” result: in certain nice, linear settings, the modular blend exactly matches what you’d get by retraining on the mixture. So you don’t lose out when tasks are easy to combine.
Real-world tests
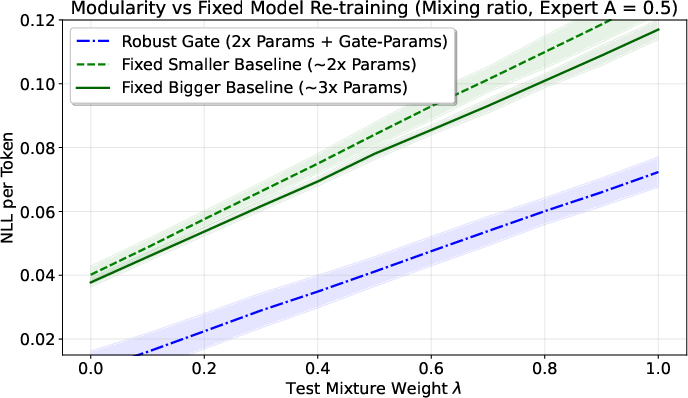
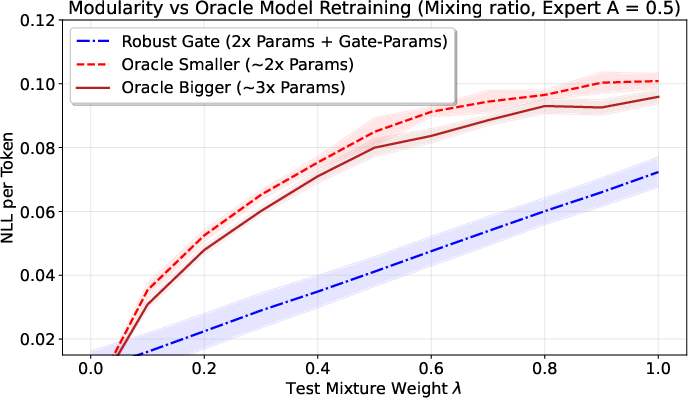
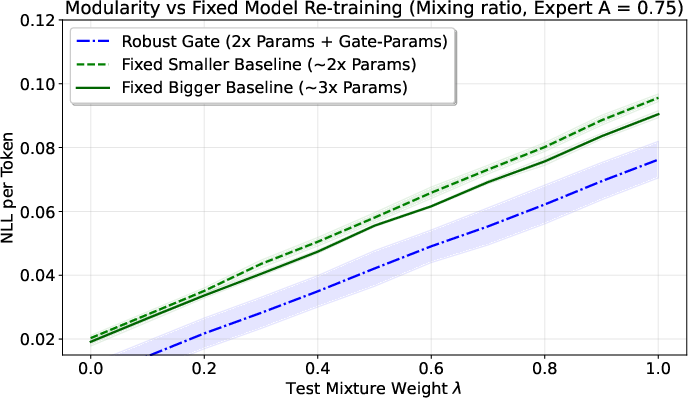
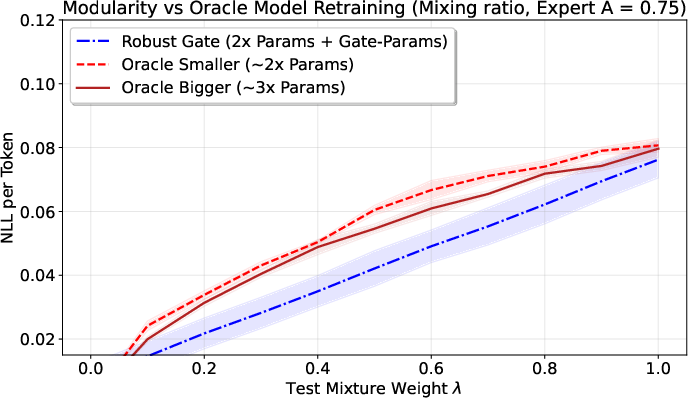
On both synthetic data and real datasets (like Wikipedia, Code, FineWeb), their approach:
- Reduces “gradient conflict” (when learning signals from different tasks fight each other),
- Robustly beats baseline methods, especially when tasks interfere a lot.
Why does this matter?
This work suggests a practical and greener path forward for large models:
- Train small experts on their own data (which can help with privacy and access control),
- Freeze them,
- Learn a lightweight gate that combines them robustly.
Key benefits:
- Lower cost and energy: You don’t keep retraining a giant model; you only train small experts and a small combiner.
- Easy updates: Add a new expert without forgetting old skills.
- Robustness to shifts: If the mix of tasks changes (as it often does in the real world), the gate is built to handle it.
- Solid theory and practice: The authors provide existence proofs, performance bounds, efficient training and inference methods, and empirical wins.
In short, this paper lays a strong theoretical and practical foundation for building powerful, flexible AI systems out of smaller, specialized parts—and doing so in a way that’s more reliable, efficient, and future-proof than the “one giant model” approach.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper. Each point is written to be concrete and actionable for future research.
- Original versus linearized game: The robust existence and saddle-point guarantees are proven for the linearized payoff $L(\lambda,g)=\sum_k \lambda_k\,(\sfp_k\parallel \pi_g)$, not the original minimax objective $(\sfp_\lambda\parallel \pi_g)$. It remains unclear:
- Under what conditions the saddle points of the linearized and original games coincide.
- How large the optimality gap between the two formulations can be, and how to bound it.
- Whether convergence guarantees for algorithms targeting the linearized game translate to the original objective.
- Global normalization constraint and finite support: The gate space $1$ is defined via a global normalization constraint and assumes finite (or countable) support $\sX_0=\bigcup_k \mathrm{supp}(\sfp_k)$. Open questions:
- Is the global constraint necessary if and each is a valid distribution, or is it redundant/inconsistent in continuous or large discrete spaces?
- How to generalize the existence and compactness arguments to continuous/separable $\sX_0$, realistic for language generation.
- Practical enforcement of in large-scale autoregressive models without enumerating $\sX_0$.
- From non-causal gates to causal routers: The paper proposes “Structural Distillation” to convert non-causal gates to causal routers for autoregressive inference, but:
- No algorithmic details, training objectives, or architectures are specified.
- No theoretical bounds on distillation-induced performance degradation (e.g., increase in $(\sfp_\lambda\parallel \pi_g)$) are provided.
- No latency/compute trade-off analysis or guarantees for top- causal routing are given.
- Generalization guarantees are referenced but not instantiated:
- The abstract mentions bounds scaling with gate complexity and an “expert coincidence norm” , which is not defined or measured.
- Explicit vector-valued Rademacher complexity bounds, sample complexity rates, and dependence on (number of experts), overlap, and diversity are absent.
- Procedures to estimate or upper-bound and to diagnose when modularity acts as a “strong regularizer” are missing.
- Estimating KL and JSD at scale: The framework relies on $(\sfp_k\parallel \pi_g)$ and $^\lambda(\{\sfp_k\})$, but:
- There are no sample complexity or finite-sample error bounds for estimating KL/JSD in high-dimensional sequence spaces.
- Robustness of the minimax solution to estimation noise, heavy-tailed token distributions, and length variability is unaddressed.
- Practical estimators (e.g., plug-in, importance-weighted, or model-based) and their bias/variance properties are not studied.
- Optimization details and convergence:
- The “Stochastic Primal-Dual” algorithm is not specified (updates for , constraint handling for , step sizes, variance reduction, stopping criteria).
- No convergence rates (ergodic or last-iterate), oracle complexity, or sample-level complexity are given—particularly critical for large and massive datasets.
- Handling non-convex parametric gates (e.g., neural networks) remains open—existence/optimality and convergence guarantees are limited to the convex gate space used in theory.
- Feature access for gating: The gate is “input-dependent” but experts are treated as black boxes. Unresolved:
- Whether can/should access per-expert scores (e.g., log-likelihoods, token logits) to improve routing, and how to calibrate cross-expert scores.
- What input features suffice for performant routing when expert outputs are inaccessible, and how to learn them under distribution shift.
- How miscalibration across experts affects optimal gating and guarantees.
- Formal modular-versus-monolithic comparison: While the paper gives a lower bound for monolithic retraining (JSD interference), it lacks:
- A theorem directly comparing the robust gated model’s risk to the retrained monolithic model’s risk, with clear sufficient conditions for strict dominance.
- Tight, instance-dependent conditions (in terms of , overlap, and ) guaranteeing modular superiority.
- Prior knowledge on mixtures (restricted ): The projection idea and Lipschitz bound are presented, but:
- Computing or bounding the Lipschitz constant in practice (for high-dimensional sequence models) is not addressed.
- Efficient projection algorithms onto complex convex sets (e.g., budget, fairness, or quality constraints) and their impact on training are unspecified.
- The gap between the linearized least-favorable and the true worst-case mixture for the original objective remains unquantified.
- Uniqueness and stability of equilibria:
- Conditions for uniqueness of the saddle point are not analyzed.
- Sensitivity of to small perturbations in data, experts, or priors (e.g., stability bounds) is unaddressed.
- Support mismatches and zero-probability events:
- When experts assign zero probability to events supported by other sources, KL can be infinite; smoothing or calibration strategies are not discussed.
- Guarantees requiring strictly positive probabilities are restrictive; relaxing them and quantifying the impact remains open.
- Sequential/conditional modeling: The theory is expressed over distributions but LLMs are conditional next-token models :
- Extensions of existence, bounds, and minimax guarantees to conditional/autoregressive settings are lacking.
- How gating evolves across positions , interacts with hidden states, and maintains causality and normalization is not formalized.
- Scalability and inference cost:
- How to route and aggregate experts efficiently at inference (compute/memory budgets, batching, caching) is not studied.
- Trade-offs among accuracy, sparsity (top-1/top- routing), and latency—and their theoretical or empirical characterization—are missing.
- Practical acquisition of and : The guarantees hinge on expert errors and source diversity:
- Methods to estimate $\epsilon_k=(\sfp_k\parallel \pi_k)$ and reliably from finite data are not provided.
- How uncertainty in these quantities affects bounds, saddle points, and algorithm behavior is unquantified.
- Robustness beyond convex mixtures: The ambiguity set is the convex hull of sources; however:
- Behavior and guarantees under shifts outside $\mathrm{conv}\{\sfp_k\}$ (novel domains, adversarial drift) are not addressed.
- Extensions to richer ambiguity sets (e.g., -divergence balls, Wasserstein balls) and their computational implications remain open.
- Handling heterogeneous experts: Real experts may differ in tokenization, vocabulary, normalization, calibration, and conditioning:
- How to align vocabularies and normalize outputs to form a valid mixture is not discussed.
- The impact of heterogeneous pretraining (architectures/training regimes) on gate optimality and bounds is unstudied.
- Tightness and computability of the main bound: The robust bound uses a specific witness :
- Criteria and algorithms to construct tighter witnesses (or certify tightness) are not provided.
- How bound tightness varies with overlap and diversity in realistic data is not empirically or theoretically explored.
- Gradient conflict and continual modular updates: The paper claims mitigation of gradient conflict but:
- Provides no theoretical explanation or conditions under which routing alleviates interference (e.g., in multi-task optimization).
- Does not analyze how adding new experts or updating gates over time affects guarantees (e.g., catastrophic forgetting avoided in routing but not quantified).
- Least-favorable mixture as a training target: Recommending for monolithic retraining is intriguing, yet:
- The relationship between the linearized and the truly worst-case mixture for the original KL objective is not characterized.
- Empirical protocols and guarantees for training on $\sfp_{\lambda^*}$ (and its generalization to unseen mixtures) are not established.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented now using the paper’s framework, algorithms, and insights.
- Robust modular LLM assembly for enterprises (software)
- Description: Combine frozen, domain-specific experts (e.g., code, math, legal, customer support) with a lightweight gate trained via the paper’s Stochastic Primal-Dual (SPD) algorithm to deliver consistent performance under unknown or shifting query mixes.
- Tools/workflows: Gate training with the SPD algorithm; Structural Distillation to a causal router for low-latency inference; telemetry to monitor domain mix.
- Assumptions/dependencies: Access to expert models’ token-level log-likelihoods/logits; interoperability across experts; modest compute to host multiple experts; small domain-annotated calibration data.
- Replace heuristic dataset weighting with principled gating (foundation models, ML platforms)
- Description: Stop hand-tuning fine-tuning weights across datasets; instead, train per-domain experts and use a robust gate to combine them for any future mixture of data.
- Tools/workflows: DRO-style gate trainer; support for the restricted mixture set Λ if business priors on test mixtures are known; evaluation using the paper’s JSD-based geometry analyzer.
- Assumptions/dependencies: Availability of separate domain-specific finetunes; access to per-domain loss signals; organizational buy-in for modular training and serving.
- Distribution-shift defense for content generation and search (media, search, e-commerce)
- Description: Use the robust gate to dynamically reweight experts based on inputs, mitigating failures when user traffic shifts (e.g., sudden spike in coding or multilingual queries).
- Tools/workflows: Adversarial mixture simulation to harden the gate; monitoring of “least-favorable” mixtures λ* to guide data collection or staffing.
- Assumptions/dependencies: Ability to log per-expert performance per segment; gate normalization constraint satisfied at serving time (Z_g=1).
- Privacy-respecting modular composition (healthcare, finance)
- Description: Data owners train local experts behind privacy boundaries; a central gate combines their outputs without sharing raw data.
- Tools/workflows: Secure inference orchestration; audit trails for gate decisions; domain contracts/licensing for expert use.
- Assumptions/dependencies: Legal agreements and APIs that expose model probabilities; strict access controls; harmonized tokenization.
- Compliance and safety overlays (regulated sectors; safety engineering)
- Description: Gate utility experts together with safety/compliance experts (e.g., HIPAA, GDPR, FINRA) to maintain guardrails across varying request mixes and contexts.
- Tools/workflows: Safety expert providing likelihoods for safe responses; gate constraint sets Λ reflecting risk posture; red-teaming using λ* scenarios.
- Assumptions/dependencies: Reliable safety experts; clear compliance policies; logging for audits.
- Multilingual and code-switching assistants (education, customer support)
- Description: Route user inputs across language experts to handle code-switching and maintain fluency, leveraging the gate’s robustness to unknown mixtures.
- Tools/workflows: Language-ID features; Structural Distillation for real-time routing; error analytics per language.
- Assumptions/dependencies: Strong monolingual experts; consistent likelihood calibration across languages; low-latency routing.
- Robotics and autonomous systems policy mixing (robotics)
- Description: Gate among task-specific probabilistic policies (navigation, manipulation, safety) to maintain robust control under changing environment mixtures.
- Tools/workflows: Router over policy experts; simulation of worst-case mixtures λ*; safety verification of gate complexity.
- Assumptions/dependencies: Policies expose likelihoods; safe fallback strategies; verification budget.
- Adaptive tutoring across subjects (education)
- Description: Gate math, writing, coding tutors to match evolving student needs without retraining a monolithic model.
- Tools/workflows: Student profile features for routing; small per-subject datasets to calibrate gate; per-subject performance dashboards.
- Assumptions/dependencies: High-quality subject experts; transparency of gate decisions for educators.
- Least-favorable mixture analysis to set static training targets (MLOps, data ops)
- Description: Use λ* from the linearized game to choose principled aggregate training weights for a single static model when multi-expert serving is infeasible.
- Tools/workflows: λ*-optimizer (mirror descent + projection to Λ); loss-geometry reports; governance to approve training mixtures.
- Assumptions/dependencies: Reliable per-domain losses; Lipschitz bound estimates; alignment between static training and deployment traffic.
- Energy and cost reduction via modular updates (energy, sustainability, IT procurement)
- Description: Add new capabilities by training a new small expert plus the gate rather than retraining a large monolithic model, reducing compute and carbon footprint.
- Tools/workflows: Cost/energy calculator; modular deployment playbooks; change management for incremental expert additions.
- Assumptions/dependencies: Serving infra supports multi-expert calls or distilled router; accurate cost accounting; model licensing that permits modular reuse.
Long-Term Applications
Below are forward-looking applications that require further research, scaling, standardization, or ecosystem development.
- Standardized modular AI marketplaces (platform economy, policy)
- Description: A market where data owners sell domain experts and integrators deploy robust gates with statistical equilibrium guarantees; prices reflect expert quality and overlap/diversity.
- Tools/products: Marketplace protocols, model cards with expert coincidence norms and JSD geometry, licensing frameworks, gate training kits.
- Assumptions/dependencies: API standards for exposing calibrated probabilities; interoperable tokenization; governance for fair competition and privacy.
- Hardware and serving optimizations for routers (software, hardware)
- Description: Specialized accelerators and server runtimes optimized for causal routers and multi-expert inference; batching and caching strategies that minimize latency/cost.
- Tools/products: Router kernels, scheduling algorithms, streaming inference engines for gated mixtures.
- Assumptions/dependencies: Widespread availability of logprobs/logits; memory-friendly expert footprints; vendor support.
- Automated domain lifecycle: detect drift → spin up expert → gate (MLOps)
- Description: Continuous monitoring of traffic geometry (via JSD), automatic triggering of new expert training, and gate retraining without catastrophic forgetting.
- Tools/workflows: Drift detectors using JSD/overlap, automated expert training pipelines, governance for promotion to production.
- Assumptions/dependencies: Reliable domain labeling; capacity to train experts on demand; careful evaluation to avoid spurious domains.
- Cross-modal modular generative systems (multimodal AI)
- Description: Gate across text, code, vision, and speech experts with unified likelihood calibration to produce coherent multimodal outputs under variable input mixes.
- Tools/products: Cross-modal gate training methods; calibration schemes to compare heterogeneous likelihoods.
- Assumptions/dependencies: Comparable probabilistic outputs across modalities; new theory for continuous supports and multi-token synchronization.
- Public-sector procurement and sustainability policy (policy, government)
- Description: Guidance and requirements that favor modular architectures to lower energy use, enable privacy-respecting collaboration, and maintain robustness under shifting public-service workloads.
- Tools/workflows: Auditable robustness reports (worst-case bounds), energy accounting standards for modular vs monolithic options.
- Assumptions/dependencies: Policy adoption; auditability of gates and experts; public datasets for benchmarking.
- Fairness and demographic robustness via modular composition (health equity, civic tech)
- Description: Train demographic- or context-specific experts to ensure equitable performance, with the gate providing worst-case guarantees across protected groups.
- Tools/workflows: Fairness-aware gate objectives; constraints on Λ reflecting demographic priors; continuous disparity monitoring.
- Assumptions/dependencies: Ethically trained experts; strong safeguards against stereotyping; stakeholder oversight.
- Safety-critical certification of gated systems (medical devices, aviation)
- Description: Formal verification of the gate’s worst-case risk bounds and overlap/diversity behavior; certification for regulated deployments.
- Tools/workflows: Verified implementations of SPD and Structural Distillation; model acceptance tests using least-favorable mixtures.
- Assumptions/dependencies: Traceability and determinism in serving; conservative gate complexity; regulator engagement.
- Open-source libraries and benchmarks for robust modularity (academia, OSS)
- Description: Reference implementations of the SPD algorithm, normalized gate spaces, λ*-estimators, and Structural Distillation; benchmark suites measuring robustness under mixture shifts.
- Tools/workflows: Standard datasets partitioned into domains; geometry metrics (JSD, overlap gains); reproducible evaluation protocols.
- Assumptions/dependencies: Community maintenance; broad expert model availability; standardized logging of per-token probabilities.
- Knowledge management across enterprises (knowledge ops)
- Description: Gate department-specific knowledge bases and experts (HR, Legal, Engineering, Sales) to deliver accurate responses across varying internal request mixes.
- Tools/workflows: Enterprise router integrating domain watchers; access control; lineage and compliance tracking.
- Assumptions/dependencies: Consistent model interfaces; structured documentation; internal privacy controls.
Cross-cutting assumptions and dependencies
- Expert availability and calibration: Requires access to multiple high-quality, pre-trained experts that expose consistent token-level log-probabilities or logits.
- Gate training signals: Needs per-domain datasets or proxies to estimate losses; the SPD algorithm assumes access to domain-wise feedback during training.
- Normalization and causality: Structural Distillation is required to convert non-causal gates into causal routers for autoregressive inference with strict normalization ().
- Compute and latency trade-offs: Multi-expert serving introduces overhead; distilled routers and batching strategies are key to practicality.
- Legal and licensing: Modular composition depends on licensing terms that permit mixing and serving multiple third-party experts.
- Monitoring geometry: Estimating Jensen-Shannon Divergence and overlap requires domain telemetry; accuracy of these estimates impacts guarantees and routing quality.
Glossary
- Berge's Maximum Theorem: A result ensuring continuity and compactness properties of solution sets to optimization problems, used to argue existence of best responses. "Berge's Maximum Theorem implies"
- Distributionally Robust Optimization (DRO): An optimization paradigm that seeks solutions performing well under worst-case distributional shifts within an ambiguity set. "akin to Distributionally Robust Optimization (DRO)"
- Hausdorff distance: A metric measuring how far two subsets of a metric space are from each other, used here to bound improvements when restricting mixtures. "is the Hausdorff distance between the sets."
- Jensen-Shannon Decomposition Identity: An equality decomposing average per-domain KL into mixture KL plus the Jensen–Shannon divergence, highlighting interference in monolithic training. "governed by the Jensen-Shannon Decomposition Identity"
- Jensen–Shannon Divergence (JSD): A symmetrized, smoothed divergence measuring the diversity among distributions; the average KL of sources to their mixture. "Jensen-Shannon Divergence (JSD)"
- Kakutani's fixed-point theorem: A set-valued generalization of Brouwer’s theorem guaranteeing fixed points for upper hemicontinuous correspondences on compact convex sets; used to show existence of a robust gate. "using Kakutani's fixed-point theorem"
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from another, also called relative entropy; convex in its second argument. "joint convexity of the KL divergence"
- linearized game: An auxiliary zero-sum formulation where the objective is linear in the adversary’s mixture weights, aiding existence and analysis. "the linearized game"
- Lipschitz continuity: A smoothness condition bounding how fast a function can change with its input; here, loss w.r.t. mixture weights is assumed Lipschitz. "is -Lipschitz with respect to the -norm:"
- LogSumExp: A smooth maximum operator log(∑ e{·}) that often appears as a capacity cost term in bounds. "Capacity Cost (LogSumExp)"
- Meta-Pi network: A historical architecture that combines expert outputs via a gating mechanism, emphasizing robustness across datasets. "Meta-Pi network"
- Mixture of Experts (MoE): An architecture that combines specialized sub-models via a trainable router to divide tasks across experts. "Mixture of Experts (MoE)"
- minimax game: A robust optimization framework where a learner minimizes a loss against an adversary that maximizes it over uncertainty sets. "formulate the problem as a minimax game"
- no-regret algorithm: An online learning procedure whose average regret vanishes over time; used to compute adversarial mixtures. "no-regret algorithm provides a statistically principled alternative."
- probability simplex (simplex): The set of nonnegative vectors summing to one; represents all possible mixture weights. "the full simplex "
- Rademacher complexity (vector-valued): A capacity measure quantifying how well a function class can fit random signs; extended here to vector outputs to bound generalization. "using vector-valued Rademacher complexity"
- saddle point: A pair of strategies (for player and adversary) where neither can unilaterally improve the game value; certifies minimax optimality. "admits a saddle point"
- softmax weights: A normalized exponential weighting scheme that emphasizes lower-loss experts via exponentials of performance. "the softmax weights ."
- Stochastic Primal-Dual algorithm: An optimization method that updates primal and dual variables simultaneously using stochastic estimates to solve constrained saddle-point problems. "We introduce a Stochastic Primal-Dual algorithm"
- Structural Distillation: A technique for transferring structure from a non-causal or complex model to a simpler, deployable one while preserving behavior. "a Structural Distillation method"
- Tychonoff's theorem: A topological theorem stating that any product of compact spaces is compact; used to prove compactness of a product of simplices. "by Tychonoff's theorem."
- value-based routing: A routing strategy that selects actions or experts to maximize a scalar reward signal, often analyzed via regret. "value-based routing"
- zero-sum game: A game where one player’s gain is exactly the other’s loss; used to model adversarial robustness. "two-player, zero-sum game"
Collections
Sign up for free to add this paper to one or more collections.