Soft Contamination Means Benchmarks Test Shallow Generalization
Abstract: If LLM training data is polluted with benchmark test data, then benchmark performance gives biased estimates of out-of-distribution (OOD) generalization. Typical decontamination filters use n-gram matching which fail to detect semantic duplicates: sentences with equivalent (or near-equivalent) content that are not close in string space. We study this soft contamination of training data by semantic duplicates. Among other experiments, we embed the Olmo3 training corpus and find that: 1) contamination remains widespread, e.g. we find semantic duplicates for 78% of CodeForces and exact duplicates for 50% of ZebraLogic problems; 2) including semantic duplicates of benchmark data in training does improve benchmark performance; and 3) when finetuning on duplicates of benchmark datapoints, performance also improves on truly-held-out datapoints from the same benchmark. We argue that recent benchmark gains are thus confounded: the prevalence of soft contamination means gains reflect both genuine capability improvements and the accumulation of test data and effective test data in growing training corpora.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple but important question: Are today’s AI “test scores” really showing deep, flexible intelligence, or are they partly inflated because the AIs have already seen problems very similar to the test questions during training?
The authors focus on “soft contamination,” which means the training data includes test-like questions that aren’t exact copies, but have the same meaning. Think of it like practicing with a worksheet that’s not word-for-word the same as your exam, but the problems are basically identical.
The main questions the paper asks
- How common is “soft contamination” in modern AI training data?
- Does training on problems that are semantic duplicates (same idea, different wording) of test questions boost scores?
- If you train on duplicates of some test questions, does performance also improve on other, unseen questions from the same test?
- Do these gains show real, general ability, or are they mostly “shallow generalization” (getting better at a particular style of test without improving overall reasoning)?
How they studied it (in everyday language)
The team used an open model called Olmo3, where the training data is public. This matters because you can check exactly what the model has (and hasn’t) seen.
Here’s what they did:
- Finding look‑alike questions:
- They took well-known reasoning and coding tests (benchmarks) such as MBPP (small Python tasks), CodeForces (competitive programming), MuSR (multi-step logic stories), and ZebraLogic (logic grid puzzles).
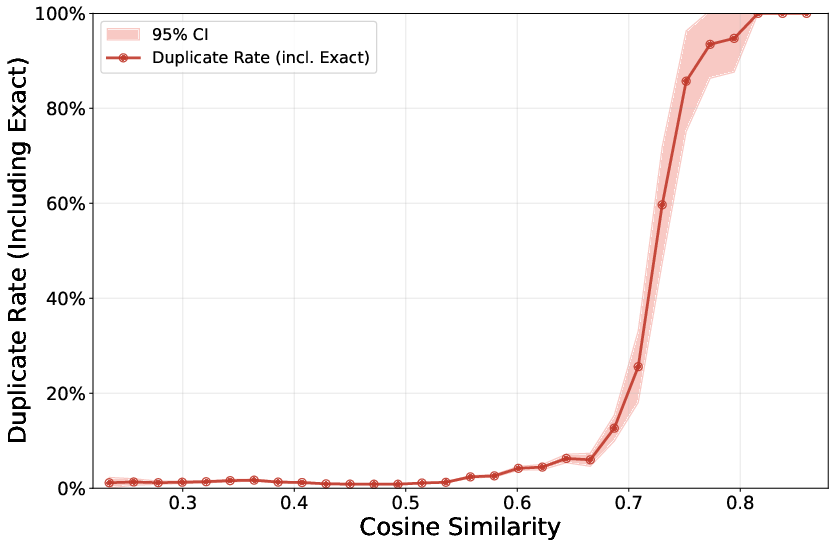
- They turned both the training text and the test questions into “embeddings.” You can imagine embeddings as putting every sentence on a map where similar sentences sit close together.
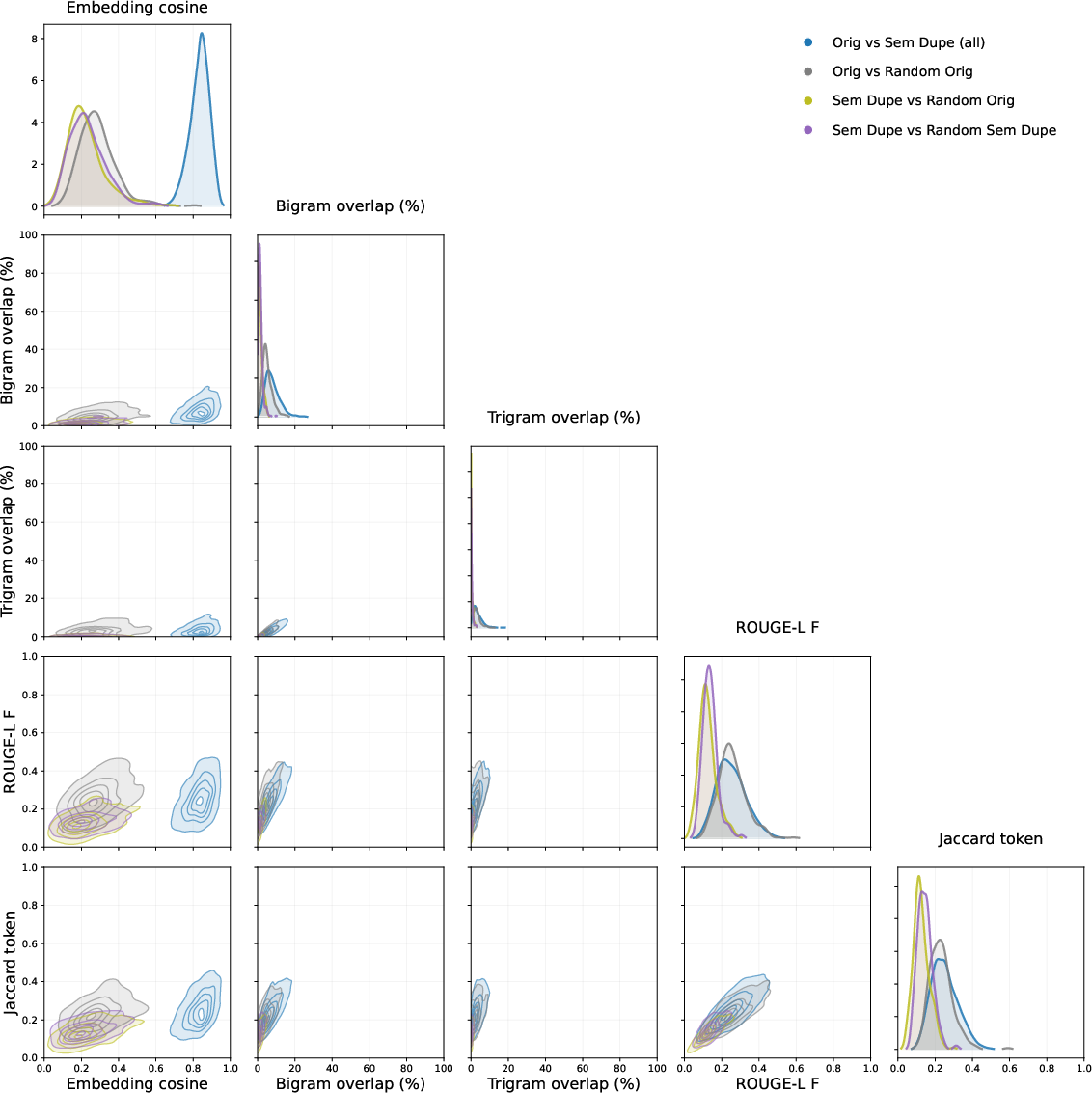
- They measured “cosine similarity” between points on this map. High similarity means the two texts are very close in meaning, even if the words differ.
- For the most similar pairs, they used a strong LLM to judge whether the training sample was a “semantic duplicate” of the test item (same idea/content, not necessarily the same words).
- Creating synthetic duplicates:
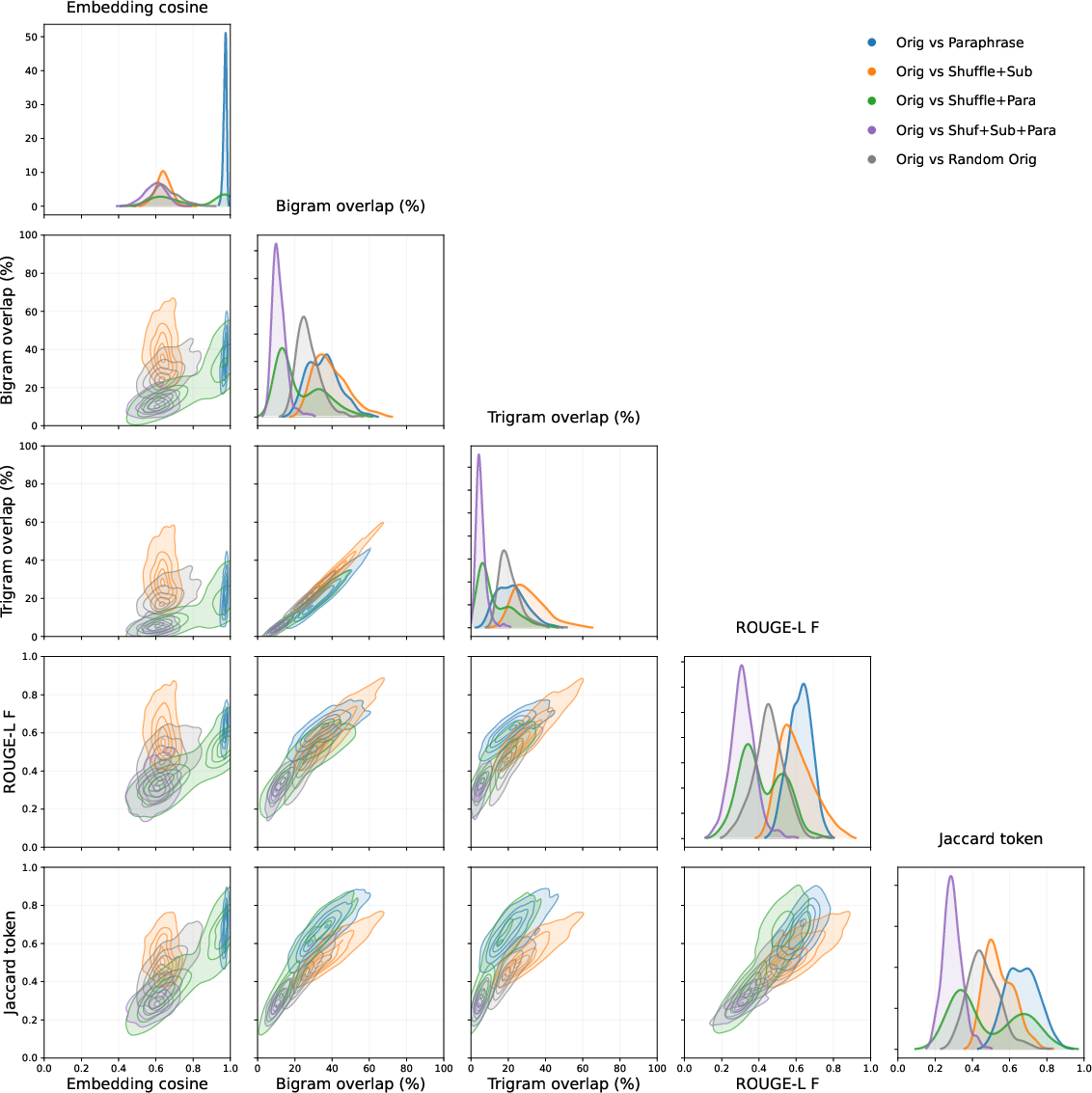
- For some benchmarks, they also made their own semantic duplicates by rephrasing or slightly changing the details while keeping the core logic the same (like swapping names or paraphrasing).
- Fine-tuning experiments (extra coaching):
- They “fine-tuned” the model—gave it extra practice—on:
- exact duplicates of test items,
- semantic duplicates of test items,
- and “closest neighbors” (things that looked similar by embeddings but weren’t confirmed duplicates).
- They then checked:
- performance on the specific questions that had duplicates in training (“seen”),
- performance on other, held-out questions from the same benchmark (“unseen”),
- and performance on different but related benchmarks (to test broader generalization).
- They used Chain-of-Thought (step-by-step reasoning) generated by a stronger “teacher” model to make the training more useful, and used a lightweight fine-tuning method (LoRA).
- Ecologically valid test (realistic contamination rate):
- Based on how often they found semantic duplicates “in the wild,” they built a training set with a small, realistic amount of contamination (about 5% of the fine-tuning data) and measured how much this boosted scores.
Key terms explained simply:
- Benchmark: a standard test used to compare AI models.
- Contamination: when training includes test items (or close equivalents). “Soft” contamination = same meaning, different wording.
- Embeddings and cosine similarity: a way to detect meaning-level similarity by placing texts on a map and measuring closeness.
- Fine-tuning: extra practice to improve on particular kinds of tasks.
- Shallow generalization: doing better on similar questions from the same test, without getting better at truly new kinds of problems.
- OOD (out-of-distribution) generalization: transferring skills to different, unfamiliar tasks.
What they found and why it matters
Here are the main findings:
- Soft contamination is common:
- MBPP (small coding tasks): For every MBPP problem, they found at least one semantic duplicate among the top 100 closest training samples. In other words, test-like problems were present in the training data.
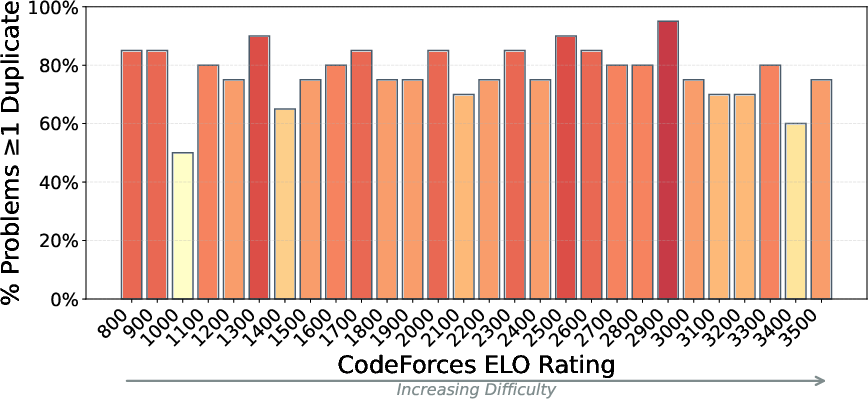
- CodeForces (competitive programming): About 78% of problems had at least one semantic duplicate among the top 100 matches.
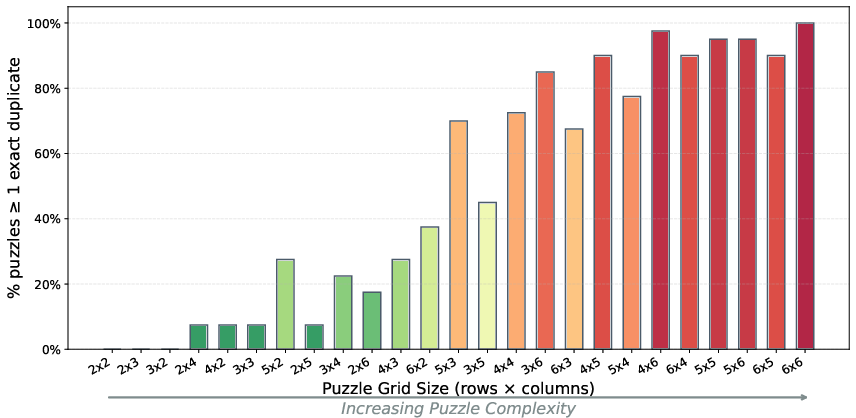
- ZebraLogic (logic puzzles): They found many exact duplicates (word-for-word copies) in the model’s fine-tuning data, with at least 49.5% of puzzle tasks appearing verbatim among the top matches in one dataset. This likely helped push the model’s reported score up in that benchmark.
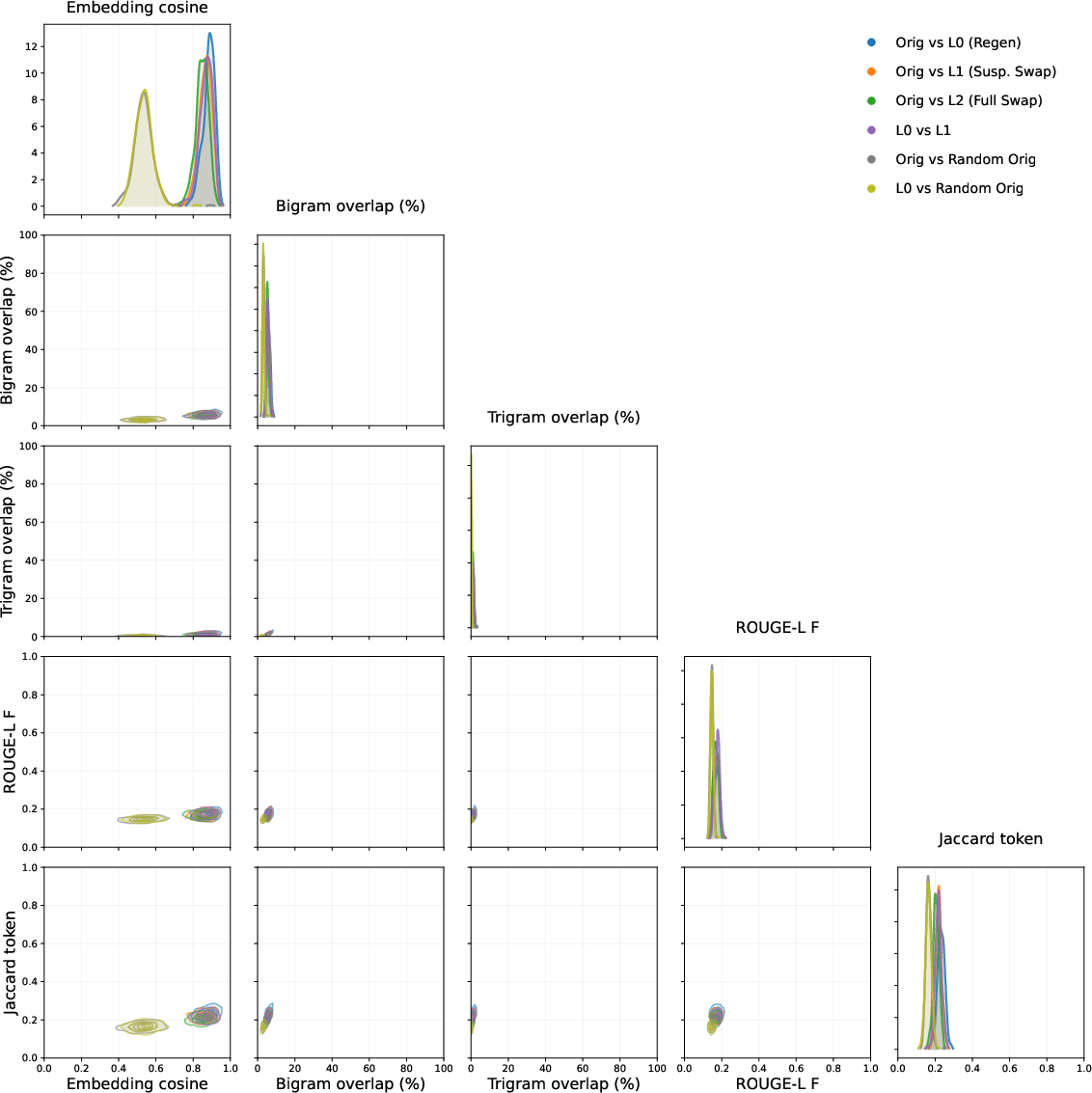
- MuSR (multi-step reasoning stories): They did not find semantic duplicates in the training data, making it a cleaner test-bed for experiments.
- Training on duplicates boosts scores—often beyond the exact items:
- When they fine-tuned on exact duplicates or semantic duplicates of half the items in a benchmark, performance improved not only on the duplicated (“seen”) items, but also on the other, “unseen” half from the same benchmark. In some cases (like MuSR), the gains were large (around +20%) for both seen and unseen items.
- Training only on “close neighbors” (high similarity but not confirmed duplicates) didn’t help much.
- Gains are usually “shallow,” not broadly general:
- Improvements tended to stick to the same benchmark. When they tested on a different but related benchmark (same domain), scores usually did not rise. That suggests the model learned the style of a particular test rather than a deep, transferable skill.
- Example: Fine-tuning on MuSR didn’t reliably improve performance on a similar logic benchmark called TrueDetective.
- Even small, realistic amounts of contamination can raise scores:
- In a “realistic” setting (about 5% of the fine-tuning data being semantic duplicates for half the benchmark), the model’s score rose by about 12% on seen MuSR items and about 6% on unseen items from the same benchmark. Scores on a different benchmark in the same domain didn’t improve, reinforcing the “shallow” pattern.
- Not all benchmarks behaved the same way:
- ZebraLogic: Exact duplicates gave big boosts; semantic duplicates helped less and sometimes even hurt, depending on how the duplicates were created.
- MBPP: Exact duplicates mainly helped the seen half; semantic duplicates gave more moderate, broader gains, and unexpectedly improved a different coding benchmark (HumanEval), possibly because the synthetic duplicates were high-quality and demanded some generalization.
Why this matters:
- If training data quietly contains test-like items, then rising benchmark scores don’t only reflect better general reasoning—they also reflect models getting more “practice tests” built into their training. That can make progress look faster or deeper than it is.
What this means going forward
- For researchers and evaluators:
- Benchmark scores should be interpreted with caution. Some of the apparent progress may come from models absorbing test-like material during training.
- Auditing training data for soft contamination is hard but important. Simple “exact match” filters miss many semantic duplicates.
- Consider using cleaner benchmarks, rotating questions, or testing with tasks less likely to appear online or be paraphrased.
- For the public and policymakers:
- Strong benchmark results do not always mean an AI can handle truly new, different problems. Some improvements are “tuned” to the test.
- Better measurement can prevent overconfidence about what AI can do in unfamiliar situations.
- For model builders:
- Be transparent about data sources and decontamination efforts. Open data (like Olmo3’s) allows meaningful checks and avoids misleading conclusions.
The simple takeaway
Today’s AI models often score higher on popular tests partly because their training data contains many problems that are the same in meaning as the test questions. Training on these near-copies boosts test scores—sometimes even on new questions from the same test—but usually does not help much on different tests. This means some benchmark gains reflect “shallow generalization” to a test’s style, not broader, out-of-distribution reasoning ability.
Knowledge Gaps
Below is a concise, actionable list of knowledge gaps, limitations, and open questions left unresolved by the paper.
- External validity to frontier models and corpora: How do soft-contamination rates and effects scale in much larger, closed-source, multilingual corpora used by frontier systems, and across additional domains beyond English text and Python code?
- Sampling bias in prevalence estimates: The study embeds only 1% of base pretraining data and examines the top 0.1% cosine-similarity neighbors (top-100 per item). What are contamination rates with larger corpus coverage, more neighbors, and confidence intervals derived from a formal sampling framework?
- Encoder and similarity metric dependence: Would results replicate with alternative embedding models (including code- or logic-aware encoders), cross-encoder re-ranking, locality-sensitive hashing, or structure-aware similarity (ASTs for code, graph/constraint features for logic puzzles)?
- Chunking and formatting effects: How do chunk length, sliding windows, and alignment of prompt–response vs input–output formats affect detection sensitivity for semantic duplicates?
- Annotation reliability and bias: The semantic-duplicate labels come from a single LLM (Gemini) with no human adjudication or inter-annotator agreement. What is the precision/recall of the labeling pipeline against a human-validated gold set, and how robust are results across multiple labelers/models?
- Taxonomy-to-impact mapping: The paper distinguishes exact/equivalent/subset/superset duplicates but does not quantify how each category differentially affects benchmark performance. Which duplicate types drive gains, and by how much?
- False-negative and false-positive rates: The detection method likely misses many duplicates (and may admit spurious matches), but rates are not quantified. Can a controlled benchmark with known semantic duplicates establish method recall/precision?
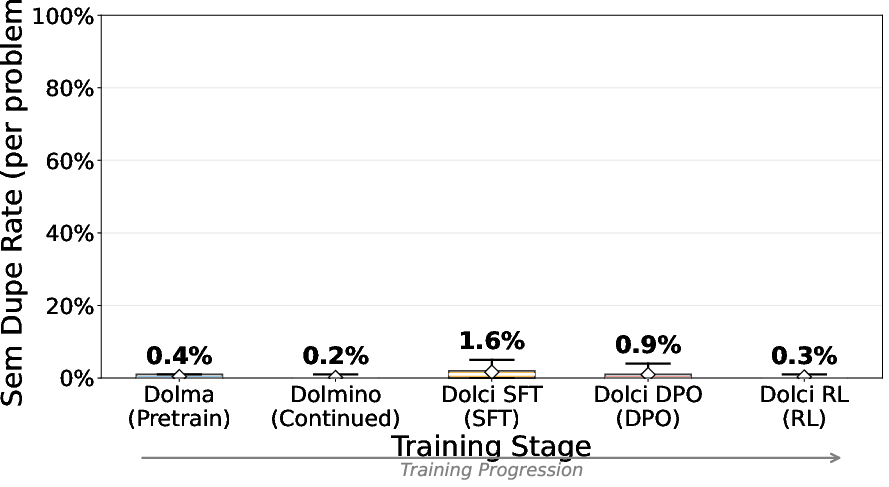
- Provenance analysis: What fraction of duplicates arise from web scraping vs synthetic pipelines (SFT/DPO/RLHF) vs RL environments? Which data sources and pipeline stages most strongly contribute to contamination?
- Stage-specific effects: The study observes duplicates in RL datasets and semantic duplicates across stages, but does not isolate the relative contribution of exposure during pretraining vs SFT vs DPO vs RL to shallow generalization.
- Dose–response curves: Beyond a few points (e.g., “ecologically valid” finetuning with 5% swap), what is the quantitative relationship between contamination rate, number of exposures, and gains on seen and unseen benchmark items?
- Ecological validity calibration: The mapping from “~4 per 10,000 semantic duplicates in top 0.1%” to using 5% duplicate swaps in finetuning is not fully justified. How should per-item duplicate frequency translate to realistic corpus-level contamination during pretraining and instruction tuning?
- Mechanisms of shallow generalization: What representations or heuristics are learned from semantic duplicates that yield within-benchmark gains but minimal cross-benchmark transfer? Can probing or mechanistic analyses reveal template/strategy acquisition?
- ZebraLogic degradation with semantic duplicates: Why did some semantic-duplicate finetuning variants harm performance despite stable general benchmarks? Are there evaluation artifacts, misaligned CoT traces, or harmful paraphrases/constraints causing negative transfer?
- CoT teacher dependence: Performance improved with better teacher CoT, but the paper does not disentangle gains from duplicate exposure vs CoT quality. What are the effects with no CoT, self-generated CoT, and varying teacher strengths?
- Robustness and statistical reliability: Many results rely on single runs; variance, confidence intervals, and seed sensitivity are not systematically reported. How stable are the findings across seeds, hyperparameters, and alternative LoRA settings?
- Cross-benchmark transfer characterization: Aside from a few “mirror” benchmarks, there is no systematic mapping between benchmark similarity and transfer. What similarity measures predict transfer vs non-transfer, and how consistent are effects across more pairs (e.g., GSM8K–SVAMP, MMLU subsets, math suites)?
- Breadth of benchmarks: Results focus on MBPP, CodeForces, ZebraLogic, and MuSR. How prevalent and impactful is soft contamination in widely-used reasoning/math benchmarks (e.g., GSM8K, MMLU, MATH, HumanEval++, APPS), and in non-text modalities?
- Difficulty and length effects: The paper finds little relation between CodeForces ELO and duplicate presence but does not deeply analyze problem complexity, length, or compositionality. Are harder, longer, or more compositional items less affected by soft contamination?
- Alternative structure-aware detectors: For code, AST- and CFG-based matching; for logic puzzles, constraint-structure matching; for math, solution-tree/derivation alignment. Do these methods improve detection coverage beyond embedding cosine similarity?
- Benchmark design under contamination: The paper argues benchmarks are confounded but does not propose concrete, tested designs (procedural generation, dynamic private evals, decoy templates, distribution-shifted variants) to resist soft contamination.
- Auditing and reporting standards: How should labs measure and report semantic-duplicate exposure (by stage, source, and benchmark), and adjust scores accordingly? What minimum transparency is needed to interpret benchmark claims?
- Quantifying shallow generalization: The concept is introduced but lacks a formal metric. Can a standardized protocol quantify “shallow” vs “OOD” generalization (e.g., within-benchmark vs cross-benchmark deltas conditioned on exposure)?
- Close-neighbor finetuning null results: Finetuning on high cosine-similarity neighbors did not improve benchmark scores, but the reasons are unclear (insufficient closeness, format mismatch, or noisy neighbors). What neighbor selection criteria make this treatment effective?
- Multilingual and other programming languages: Semantic duplicates and their effects may differ in other languages (natural and programming). How do contamination rates and gains vary across Java/CPP/JS and non-English benchmarks?
- Scaling detection to full corpora: Embedding and annotating trillions of tokens remains computationally prohibitive. What approximate or multi-stage pipelines (e.g., n-gram prefiltering + cross-encoding + human audit) achieve scalable, high-recall detection?
Practical Applications
Immediate Applications
The paper’s methods and findings can be operationalized today in several concrete settings. Below are targeted use cases, mapped to sectors, with likely tools/workflows and key assumptions.
- Contamination audit pipeline for LLM training and eval data (industry, academia; software/AI)
- Use case: Detect exact and semantic overlaps between training corpora and evaluation sets to avoid inflated scores and misinterpretation.
- Tools/workflows: Embed corpora and benchmarks with a strong text-embedding model; nearest-neighbor search by cosine similarity; sample top-0.1% neighbors; LLM-based adjudication of “semantic duplicate” type and confidence; reports with per-benchmark contamination rates and “duplicate exposure index.”
- Assumptions/dependencies: Access to (or cooperation for) training data; embedding model quality affects recall; significant compute/storage for embedding large corpora; human/LLM adjudication quality and threshold choices matter.
- Upgraded data curation and decontamination beyond n-grams (industry; software/AI)
- Use case: Prevent both exact and soft contamination across pretraining, SFT, DPO, RL pipelines.
- Tools/workflows: Integrate embedding-based decontamination stages; maintain “evaluation quarantine” blocklists; periodic scans against known benchmarks; versioned logs and CI checks for each data stage (e.g., Dolma-like base, Dolci-like SFT/DPO/RL).
- Assumptions/dependencies: Modifiable MLOps pipelines; increased costs for embedding/indexing; residual false negatives likely.
- Contamination-aware scoring and reporting (industry, academia; software/AI)
- Use case: Publish benchmark scores adjusted for contamination and shallow generalization.
- Tools/workflows: Stratify evaluations into seen/unseen w.r.t. semantic duplicates; exclude contaminated items or report both raw and adjusted metrics; include “shallow generalization” disclosures in model cards.
- Assumptions/dependencies: Reliable contamination detection; community acceptance of adjusted metrics.
- Dynamic/rotating evaluations to stay ahead of contamination (industry, academia; software, education, coding)
- Use case: Reduce leakage by refreshing test suites using parametric generation (e.g., logic-tree regeneration for reasoning, paraphrased/translated variants for coding).
- Tools/workflows: MuSR-style logic-tree pipelines; MBPP-style paraphrase/regenerate code tasks with new IO specs; human vetting; scheduled test rotation.
- Assumptions/dependencies: Quality-controlled generation pipelines; manpower for review; ongoing maintenance.
- Procurement and model selection guardrails (industry, public sector; cross-sector)
- Use case: Require vendors to supply contamination audits and adjusted results when comparing models for purchase or deployment.
- Tools/workflows: RFP templates mandating audit scripts, contamination rates per benchmark, and adjusted scores; acceptance criteria tied to “unseen-only” performance.
- Assumptions/dependencies: Vendor cooperation; standard audit formats; legal agreements for limited data access.
- Task-focused fine-tuning with controlled duplication (industry; software, customer support, documentation)
- Use case: For fixed-distribution enterprise tasks (e.g., internal codebase helpers, recurring support intents), intentionally include semantic duplicates in SFT to boost in-distribution performance.
- Tools/workflows: Curate task-specific semantic variants; LoRA SFT with CoT traces; keep a strictly separate sequestered eval set; report that gains are distribution-specific.
- Assumptions/dependencies: Acceptance that improvements may be shallow; compliance/ethics for any proprietary or test-like content; continual monitoring for unintended spillovers.
- Education exam/content integrity checks (education; edtech, testing)
- Use case: Avoid training leaks into live or future exam banks and practice materials.
- Tools/workflows: Embed exam items and edtech content; scan curriculum/training sets for semantic proximity; rotate items; publish integrity statements.
- Assumptions/dependencies: Access to protected item banks; risk of false negatives; governance for item rotation.
- Clinical/financial deployment hygiene (healthcare, finance; regulated AI)
- Use case: Ensure capability claims are not confounded by exposure to test-like cases; protect against overconfidence in OOD generalization.
- Tools/workflows: Maintain internal, fresh-case eval suites; run contamination scans against all training/SFT/RLHF datasets; mandate contamination-adjusted model cards before go-live.
- Assumptions/dependencies: Data privacy controls; cross-functional governance; cost of repeated eval cycles.
- RLHF/SFT reward-data audits (industry; software/AI)
- Use case: Prevent leakage of evaluation tasks into reward or preference datasets that silently inflate benchmark scores.
- Tools/workflows: Embed and scan reward model training sets; remove semantic duplicates of eval items; maintain audit trails across SFT/DPO/RL stages.
- Assumptions/dependencies: Full visibility into human feedback and RL datasets; extra latency in release cycles.
- CI/CD contamination gate for open-source projects (academia, OSS; software)
- Use case: Keep evaluation suites clean as repositories evolve (e.g., coding benchmarks, logic puzzles).
- Tools/workflows: Lightweight embedding index of test directories; PR checks that warn on semantically similar additions; maintain whitelist/blacklist of sources.
- Assumptions/dependencies: Compute budget for CI; small-team capacity to adjudicate alerts.
- Model card extensions (industry, academia; software/AI)
- Use case: Increase transparency by documenting contamination and shallow generalization risks.
- Tools/workflows: Add sections reporting exact/semantic contamination estimates, detection methods, adjusted scores, and test-set governance.
- Assumptions/dependencies: Organizational willingness to disclose; consolidated measurement practices.
Long-Term Applications
As the ecosystem matures, the paper points to several developments that require further research, scaling, or standardization.
- Standards and certification for contamination audits (policy, industry; cross-sector)
- Use case: ISO-like or NIST-style norms requiring semantic contamination audits and contamination-adjusted reporting for major benchmarks.
- Tools/workflows: Standardized audit protocols, artifact formats, and third‑party certification schemes.
- Assumptions/dependencies: Multi-stakeholder consensus; regulator and buyer demand.
- Centralized benchmark registries and escrowed test banks (policy, academia; healthcare, education, software)
- Use case: Protect high-stakes evaluations by access-controlled test items, monitored usage, and periodic renewals.
- Tools/workflows: Registry governance; secure test distribution; audit logs of access/use.
- Assumptions/dependencies: Funding and neutral stewardship; trust from labs and institutions.
- Trillion-scale semantic dedup and streaming decontamination (industry; software/AI infrastructure)
- Use case: Run embedding and nearest-neighbor scans on multi-trillion-token corpora during data ingestion.
- Tools/workflows: Vector search at cluster scale (e.g., FAISS/ScaNN-like plus sharding); approximate NN; incremental indexing; hardware acceleration.
- Assumptions/dependencies: Large compute and storage budgets; robust privacy/IP controls; sustained engineering.
- Contamination-aware training objectives and curricula (industry, academia; software/AI)
- Use case: Reduce overfitting to benchmark-like clusters during pretraining/SFT by penalizing or rebalancing near-duplicate exposure.
- Tools/workflows: Sampling policies that downweight high-similarity items; loss regularizers against benchmark-like neighborhoods; active learning to prioritize diverse samples.
- Assumptions/dependencies: Empirical validation that objectives improve OOD generalization without harming utility.
- Shallow generalization risk forecasting (industry; software/AI)
- Use case: Predict how corpus growth may inflate specific benchmarks via semantic overlap before training.
- Tools/workflows: Pretraining-corpus scans against target benchmarks; “expected benchmark lift from duplication” dashboards; scenario analysis for data additions.
- Assumptions/dependencies: Access to data snapshots; reliable overlap-to-gain models across domains.
- Sector-specific OOD evaluation frameworks (policy, academia; healthcare, finance, law, robotics)
- Use case: Design evaluations emphasizing real novelty and distributional shifts relevant to each domain.
- Tools/workflows: Task generators (logic trees for reasoning, parametric case synthesis in medicine/finance), shift-aware scoring, continual refresh pipelines.
- Assumptions/dependencies: Domain experts; alignment with regulatory expectations; validated psychometrics.
- Public contamination-adjusted leaderboards (policy, academia; software/AI)
- Use case: Independent leaderboards that report both raw and contamination-adjusted metrics, highlighting shallow vs broad generalization.
- Tools/workflows: Shared auditing toolchains; submission rules requiring audit artifacts; periodic benchmark refresh.
- Assumptions/dependencies: Community adoption; hosting and maintenance funding.
- Legal/IP and exam-leak compliance monitors (policy, education; publishing, testing)
- Use case: Detect near-duplicate use of copyrighted or protected test content in training pipelines.
- Tools/workflows: Embedding scans against rights-protected corpora; compliance dashboards; takedown and retraining protocols.
- Assumptions/dependencies: Rights-holder cooperation; legal clarity on “semantic duplication.”
- Research programs on “shallow vs. deep” generalization metrics (academia; software/AI theory)
- Use case: Develop quantitative measures (e.g., duplicate exposure index, semantic overlap coefficient) and causal tests of within-benchmark vs OOD gains.
- Tools/workflows: Open datasets with labeled duplicate relationships; ecologically valid fine-tuning simulators; cross-corpus replication studies.
- Assumptions/dependencies: Shared benchmarks and data access; funding for large-scale measurement.
- Robust evaluation for embodied and planning systems (academia, industry; robotics, autonomous systems)
- Use case: Create procedurally varied tasks that minimize reuse of familiar templates and emphasize transfer.
- Tools/workflows: Task randomization frameworks; synthetic environment generators; behavior-driven detection of shallow policies.
- Assumptions/dependencies: Simulation fidelity; bridge-to-real validation.
Notes on feasibility: Many immediate applications rely on having at least partial access to training and fine-tuning data or on vendor cooperation; embedding-based detection accuracy and compute costs are key constraints. Long-term applications require standardization, scalable infrastructure, and community governance to ensure that evaluations track genuine OOD capabilities rather than shallow generalization from corpus growth.
Glossary
- Chain-of-Thought (CoT): A prompting and supervision technique where models produce explicit intermediate reasoning steps before final answers. "generate Chain-of-Thought (CoT) reasoning traces."
- cosine similarity: A vector-space similarity measure computed as the cosine of the angle between two embeddings. "calculate the cosine similarity between data points."
- decontamination: The process of removing test items or their duplicates from training data to avoid leakage. "Typical `decontamination' filters use -gram matching"
- deduplication: Methods for detecting and removing duplicate entries in datasets. "undetectable by typical deduplication methods."
- Direct Preference Optimization (DPO): An alignment method that trains models from preference comparisons rather than explicit labels. "after DPO training as 28.4\%"
- ecologically valid: Reflecting realistic, real-world conditions when designing experiments or evaluations. "we also design the first (to our knowledge) ecologically valid finetuning study of the effect of training-exposure to semantic duplicates."
- Elo score: A rating system for problem difficulty or participant skill, used here to stratify CodeForces tasks. "We plot Elo scores on the x-axis."
- embedding distance: A distance (or dissimilarity) measure in embedding space used as a proxy for semantic difference. "by using their embedding distance to benchmark data"
- embedding neighbors: Data points that are close to a target example in embedding space. "while finetuning on close embedding neighbors has no effect."
- embeddings: Vector representations of text used to capture semantic content for retrieval or analysis. "All embeddings were done in FP16 precision."
- empirical risk minimization (ERM): A learning principle that minimizes average loss over training data, assuming train and test come from the same distribution. "then the deviation from the assumptions of empirical risk minimization should be explicitly noted"
- exact duplicate: A training example that is (nearly) word-for-word identical to a test item. "An exact duplicate of test data is an example in the training corpus which is syntactically identical (perhaps up to some number of -grams) to some item in a relevant test set."
- FP16 precision: Half-precision floating-point (16-bit) arithmetic used to speed up and reduce memory for large-scale computations. "All embeddings were done in FP16 precision."
- heuristic semantic distance: A proxy measure of meaning-level difference used to guide search for semantically similar items. "using a heuristic semantic distance to guide search"
- in-benchmark generalization: Performance transfer from some items of a benchmark to other, held-out items within the same benchmark. "tests in-benchmark generalization (training on duplicates of some benchmark items improves performance on other held-out items from the same benchmark)"
- LoRA: Low-Rank Adaptation; a parameter-efficient fine-tuning method that injects small trainable rank decompositions into weight matrices. "use LoRA \citep{DBLP:conf/iclr/HuSWALWWC22} to finetune Olmo3 Instruct."
- Massive Text Embedding Benchmark (MTEB): A large benchmark suite for evaluating text embedding models across many tasks. "At time of writing this model is number 2 on the Massive Text Embedding Benchmark (MTEB) leaderboard"
- membership inference: Techniques to infer whether a particular example was included in a model’s training set, often used to diagnose memorization. "memorization testing using âmembership inferenceâ style techniques"
- n-gram matching: Detecting overlaps based on contiguous sequences of n tokens to identify duplicates or leaks. "Typical `decontamination' filters use -gram matching"
- out-of-distribution (OOD) generalization: The ability of a model to perform well on data drawn from a different distribution than its training data. "biased estimates of out-of-distribution (OOD) generalization."
- reinforcement learning (RL): A training paradigm that optimizes behavior via reward signals; here, a stage of instruction tuning. "after RL training as 32.9\%."
- semantic duplicate: A training example that conveys the same meaning as a test item despite surface differences. "A semantic duplicate of test data is an example in the training corpus which has the same meaning (in some sense) as some item in a relevant test set"
- shallow generalization: Benchmark-specific gains arising from exposure to benchmark-like data, not broad capability improvements. "diagnose what we call shallow generalization on benchmarks"
- soft contamination: Training-data contamination involving semantic rather than exact duplicates of test items. "We study this `soft' contamination of training data by semantic duplicates."
- stratified reservoir sampling: A sampling technique combining stratification and reservoir sampling to preserve proportional representation across sub-sources. "we employ a stratified reservoir sampling strategy that preserves the corpus's hierarchical structure"
- string space: The space of literal token sequences, as opposed to meaning-based representations. "are not close in string space."
- supervised fine-tuning (SFT): Post-training on labeled examples to adapt a base model to desired behaviors. "after SFT training as 18\%"
- teacher model: A stronger or reference model used to generate supervision signals (e.g., solutions or reasoning traces) for student-model training. "we first get a teacher model to generate Chain-of-Thought (CoT) \citep{wei2022chain} reasoning traces."
- temperature (sampling): A parameter controlling randomness in probabilistic decoding; higher values yield more diverse outputs. "we use a temperature of 0.7"
- within-distribution generalization: Generalizing to other samples drawn from the same data distribution as the training set. "limited to a combination of within-distribution generalization and generalization across semantic duplicates."
Collections
Sign up for free to add this paper to one or more collections.