Contact-Anchored Policies: Contact Conditioning Creates Strong Robot Utility Models
Abstract: The prevalent paradigm in robot learning attempts to generalize across environments, embodiments, and tasks with language prompts at runtime. A fundamental tension limits this approach: language is often too abstract to guide the concrete physical understanding required for robust manipulation. In this work, we introduce Contact-Anchored Policies (CAP), which replace language conditioning with points of physical contact in space. Simultaneously, we structure CAP as a library of modular utility models rather than a monolithic generalist policy. This factorization allows us to implement a real-to-sim iteration cycle: we build EgoGym, a lightweight simulation benchmark, to rapidly identify failure modes and refine our models and datasets prior to real-world deployment. We show that by conditioning on contact and iterating via simulation, CAP generalizes to novel environments and embodiments out of the box on three fundamental manipulation skills while using only 23 hours of demonstration data, and outperforms large, state-of-the-art VLAs in zero-shot evaluations by 56%. All model checkpoints, codebase, hardware, simulation, and datasets will be open-sourced. Project page: https://cap-policy.github.io/


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a new, simpler way to tell robots what to do so they can handle new places and objects without extra training. Instead of giving the robot a written instruction like “pick up the red mug,” the robot is told “touch here” by marking a small 3D point on the object. The authors call this idea Contact-Anchored Policies (CAP). Think of it like dropping a tiny GPS pin exactly where the robot should make contact.
What questions did the researchers ask?
- Can a robot learn useful hands-on skills (like picking up objects or opening/closing cabinets) better if we give it a precise touch-point instead of a sentence?
- Will this approach work in new rooms, with new objects, and on different robot arms without retraining (“zero-shot”)?
- Can we build the robot’s skills as small, reliable tools (pick, open, close) and then chain them together for longer tasks (like cleaning a table)?
- Can a simple simulator help us improve the robot quickly in a way that actually matches real-world results?
How did they do it?
They used three main ideas: precise contact hints, a compact learning model, and fast simulation practice.
1) Precise “contact anchors” instead of language
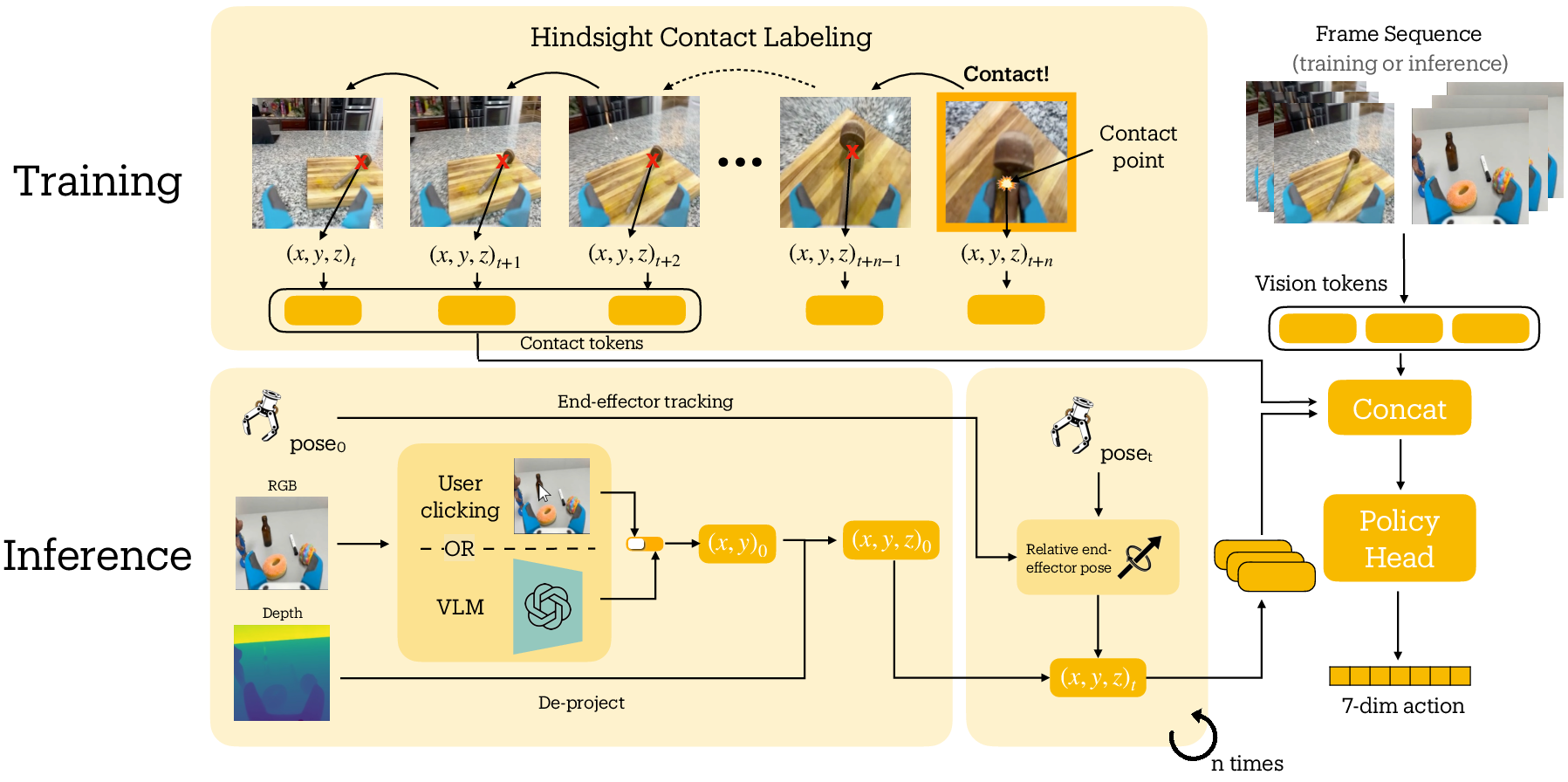
- A contact anchor is just a 3D point where the robot should touch the object (like the point between the gripper fingers when they touch a handle).
- During training, they find the exact moment the gripper makes contact (for example, when the gripper stops closing) and record that 3D point. Then they “rewind” through the video and position that same point in earlier frames, so the robot learns to approach it smoothly.
- During use, the robot gets its contact point by either a quick human click on the image, or an AI model that points to the right place after a short text prompt (e.g., “point to the red mug”).
Why this helps: Language is fuzzy (“grab the handle on the left”), but contact is precise. Robots need exact positions to succeed at physical tasks.
2) A small, efficient learning model trained from demonstrations
- The team used a compact “behavior cloning” model (it learns by copying human examples).
- Humans collected about 23 hours of demos using a 3D-printed handheld gripper with an iPhone mounted on it. The same camera view is used later on the real robot, so what the robot “sees” matches the training.
- The model takes in the camera image plus the contact point and predicts how to move the gripper next. It’s much smaller than giant language-based robot models, so it’s faster and doesn’t need massive computing power.
3) Practice in a fast, lightweight simulator (EgoGym)
- They made a simple simulation (like a “video game” practice room) that quickly generates many different scenes and objects.
- They used it to test models often, spot failure patterns, and fix issues before real-world trials.
- Importantly, success in their simulator matched success in the real world, which helped them improve quickly.
What did they find, and why is it important?
Here are the headline results, summarized in one place for clarity:
- With just 23 hours of training demos, CAP worked zero-shot in new rooms and objects.
- On single tries (no retries), CAP succeeded around:
- 83% on picking up objects
- 81% on opening doors/drawers
- 96% on closing doors/drawers
- With automatic checks and retries, success rose to about:
- 90% pick, 91% open, 98% close
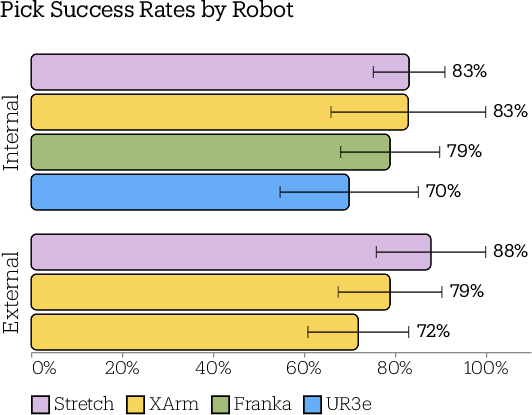
- CAP beat much larger, state-of-the-art language-based models by a big margin (up to 56% better in their tests), while using far less data and compute.
- CAP worked on different robot arms (Stretch, Franka, XArm, UR3e) without retraining—just by converting the predicted gripper motions to each robot’s joints.
- Letting an AI vision-LLM choose the contact point performed almost as well as a human click, making the system more fully automatic.
- An “ablation” test showed why contact matters: removing the contact point and using only the image dropped performance a lot (e.g., close task fell from 96% to 58%).
- The simulator’s scores lined up with real-world scores, so it was useful for improving the system.
- They chained skills to do longer tasks: e.g., “get coffee beans from a cabinet” (open → pick → drop → close) and “clear a table” (multiple picks and drops). The table-cleaning ran 10/10 successfully; the cabinet task mostly worked but sometimes stopped early when a checker mistakenly thought the door was fully open.
Why this matters:
- Precision beats vagueness: Touch-point instructions give robots the concrete information they need.
- Small and efficient: You don’t need huge models and mountains of data to get strong, general performance.
- Modular tools: Having reliable small skills (pick/open/close) that can be combined is practical and easier to improve.
What could this change in the future?
- Faster progress with fewer resources: Labs and schools can build useful robot skills without massive budgets, because CAP needs less data, smaller models, and lighter compute.
- Easier to adapt: Since CAP is trained from a handheld tool that sees the world like the robot does, it can jump to different robot bodies with minimal fuss.
- More robust home helpers: This could make home robots better at common chores, from tidying up to fetching items, by simply pointing to where they should touch.
- Building longer tasks: A high-level planner (like a smart director) can call these reliable skills in sequence, so robots handle multi-step jobs.
- Future upgrades: CAP could grow to handle two-handed tasks, multiple contact points at once, or learn to retry and correct itself without an external checker.
In short, this paper argues that telling robots exactly where to touch is a powerful, simple idea. It makes robot actions clearer, training lighter, and results stronger—bringing practical, general-purpose manipulation a step closer.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of unresolved issues and concrete directions that the paper leaves open for future work:
- Contact representation is limited to a single 3D point; no contact frame, normal, or uncertainty is modeled. Study whether augmenting anchors with orientation, local surface geometry, or a distribution over candidate contacts improves performance on tasks requiring specific approach angles or sliding/rolling contact.
- No support for multi-contact or sequential contact planning. Develop architectures that predict/ingest multiple simultaneous or temporally ordered anchors (e.g., two-hand grasps, two-point door manipulation, regrasping).
- Bimanual manipulation is out of scope. Explore extension of CAP to coordinated dual-arm control with inter-contact constraints.
- Contact-only conditioning may be insufficient for tasks requiring force or compliance. Incorporate tactile/force signals, impedance control targets, or learned force profiles alongside contact anchors.
- Inference relies on manual or VLM-generated clicks and depth deprojection; robustness to anchor-selection errors and depth noise is not characterized. Quantify sensitivity to pixel/metric error, missing/invalid depth, and occlusions; develop self-correcting anchor refinement during execution.
- Anchor tracking assumes accurate extrinsics and forward kinematics; calibration error sensitivity is unreported. Systematically measure degradation under extrinsic/KF drift and propose online calibration or visual servoing fallback.
- Hindsight contact labeling depends on gripper-aperture heuristics or manual annotation; label accuracy is unvalidated. Provide quantitative agreement with ground-truth contact (e.g., via IMU/tactile or high-speed video) and assess its impact on policy quality.
- ARKit odometry is used for back-projection during training; residual drift and relabeling error are not quantified. Benchmark relabeling error vs. trajectory length and introduce error-aware training (e.g., anchor noise augmentation).
- The anchor is frozen post-grasp; tasks involving post-contact sliding or continuous motion along surfaces (e.g., wiping, peeling, cable routing) are unsupported. Investigate dynamic anchor updates along a contact manifold.
- Action representation and architecture choice (VQ-BeT) are not ablated. Compare to diffusion/transformer hybrids, continuous heads, or tokenization schemes under identical conditioning to isolate modeling effects.
- No language-conditioning baseline within the same architecture. Train a language-conditioned variant (same backbone/params) to concretely attribute gains to contact conditioning vs. model size/data.
- Data scaling laws are unknown. Vary demonstration hours and environment diversity to characterize performance vs. data, and identify where returns diminish for each task category.
- Dataset biases and coverage are under-specified (object materials, translucency, deformability, mass, friction, handle types, latching mechanisms). Report distributional stats and test on systematically difficult strata (transparent, reflective, deformable, heavy, hinged with latches).
- Generalization across gripper morphologies is not assessed. Evaluate transfer to different end-effector geometries (e.g., suction, parallel-jaw with different finger spacing, multi-finger hands) without retraining, and/or learn gripper-conditional adapters.
- Only three atomic tasks (Pick/Open/Close) are tested. Extend to precise insertions, tool use, pouring, peg-in-hole, cable manipulation, and deformable-object tasks to stress anchor sufficiency.
- Long-horizon composition via tool-calling is demonstrated on two scenarios with 10 trials each; reliability and error propagation are not analyzed. Evaluate at scale (tasks × scenes), add formal failure recovery and task-level planning under uncertainty (e.g., POMDP planning with verifier feedback).
- VLM verifier exhibits false positives that cause unsafe transitions and collisions; no calibrated metrics are reported. Quantify verifier precision/recall by stage, introduce uncertainty thresholds, and integrate safety constraints (e.g., collision monitoring, precondition checks).
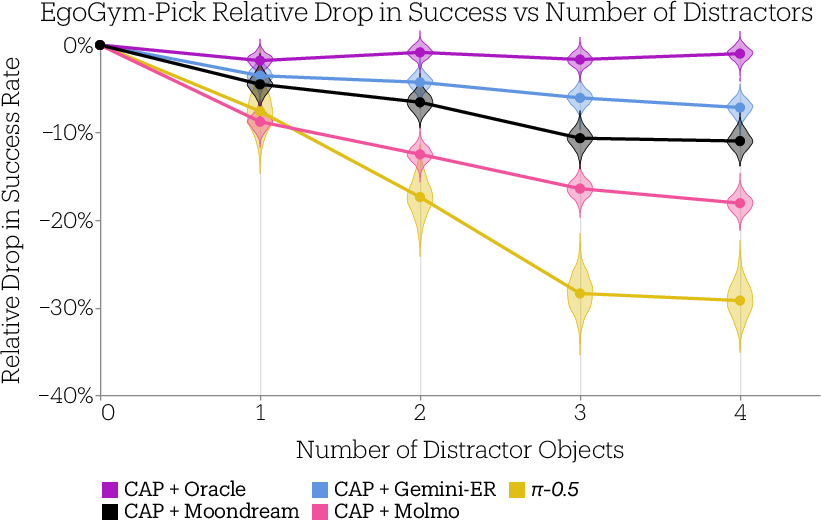
- EgoGym–real correlation is based on four checkpoints and one task; external validity is limited. Expand to multiple tasks and embodiments, report confidence intervals and rank correlations, and test whether checkpoint improvements in sim predict real gains across diverse shifts.
- EgoGym trades photorealism for diversity but does not quantify which domain randomizations matter most. Perform ablations on texture/object/lighting/physics randomizations to identify the minimal sim setup that best predicts real performance.
- Sim is used only for evaluation/analysis, not for policy improvement. Explore sim-augmented training (e.g., domain-randomized pretraining, offline RL with sim rewards, sim-to-real data augmentation for rare failures).
- Perception stack is tied to iPhone RGB-D on-wrist; sensor modality and placement generalization are untested. Evaluate with conventional wrist cameras, stereo, depth-less RGB, or external cameras, and study robustness to FOV, resolution, and exposure changes.
- Inference runs at up to 2 Hz on CPU; latency and control stability are not analyzed. Characterize closed-loop performance vs. control rate and propose lightweight accelerations (e.g., smaller encoders, quantization, on-device compilers).
- Distractor analysis is limited to object count; effects of heavy occlusion, similar-look distractors, and adversarial clutter are unreported. Construct targeted robustness suites (e.g., same-shape/confuser objects, background patterning, partial occlusions).
- Success metrics are binary and task-level; no reporting of path efficiency, cycle time, contact forces, or near-miss safety events. Add richer metrics and standardized reporting to enable safety- and efficiency-oriented optimization.
- Baseline coverage is narrow and may be confounded by embodiment and sensing differences. Include more matched baselines (same sensors/effectors), and report ablations where CAP uses external cameras or different grippers for apples-to-apples comparisons.
- Reliance on depth for anchor deprojection excludes transparent/reflective surfaces where consumer depth fails. Evaluate RGB-only anchor inference (e.g., monocular depth, learned anchor predictors) and fusion strategies for unreliable depth.
- No learned anchor predictor is provided; anchor selection remains external (oracle/VLM). Train an anchor-proposal module end-to-end with CAP (possibly uncertainty-aware), and compare to VLM clicks on autonomy, latency, and robustness.
- Safety and failure recovery are not formalized. Integrate safety monitors (force/torque thresholds, collision detection), define safe fallback behaviors, and evaluate under perturbations and adversarial failures.
- Calibration and deployment friction for new robots are underexplored. Provide and validate an automated extrinsic calibration pipeline and quantify the one-time setup burden vs. performance across sites.
- Limited ablations on data processing (e.g., static-frame filtering) suggest benefits, but broader preprocessing choices (color jitter, viewpoint augmentation, temporal subsampling) are untested. Systematically evaluate their impact on generalization.
- Open-door/close-door performance is reported but not broken down by articulation properties (hinge stiffness, friction, opening angle limits). Build articulation-aware evals to probe limits and guide controller adaptations.
Practical Applications
Below is a structured synthesis of practical applications that can be derived from the paper’s findings, methods, and innovations. Each application lists relevant sectors, examples of tools/products/workflows that could be built, and key assumptions/dependencies that affect feasibility.
Immediate Applications
These can be piloted or deployed with today’s capabilities (as demonstrated in the paper: 52M-parameter models, ~23 hours of data, on-device inference, cross-embodiment generalization, VLM prompting, verifier-guided retries, and EgoGym simulation-in-the-loop).
- Home and office service robotics for “Pick–Open–Close” tasks
- Sectors: Robotics, consumer, facility services, hospitality
- Tools/products/workflows: CAP-driven skills on mobile manipulators (e.g., Stretch-like platforms) for picking clutter, opening/closing cabinets/drawers, tidying desks/kitchens
- Assumptions/dependencies: Eye-in-hand RGB-D (or equivalent depth) with reliable pose tracking; 6+ DoF arm and compliant gripper; safe contact policies; on-device inference (CPU/GPU/Neural Engine)
- Facilities and hospitality operations (daily restocking and access tasks)
- Sectors: Hospitality, retail backrooms, offices, property management
- Tools/products/workflows: CAP-Open/Close to operate cabinet doors/drawers; CAP-Pick to handle supplies and small items; verifiers for retry until done
- Assumptions/dependencies: Handles and furniture within seen geometry distributions; calibrated camera-to-gripper setup; reasonable lighting and depth sensing
- Light logistics and retail backroom manipulation
- Sectors: Retail/logistics
- Tools/products/workflows: CAP-Pick for shelf-to-tote moves, item relocation, opening supply drawers; VLM-generated contact prompts for item targeting from natural descriptions
- Assumptions/dependencies: Moderate clutter; objects within mass and size limits of compliant fingers; reliable depth on matte/opaque items
- Cross-embodiment deployment for system integrators
- Sectors: Robotics system integration, manufacturing cells, labs
- Tools/products/workflows: One CAP checkpoint re-used across Franka/XArm/UR3e with IK adapters; fast arm-swaps for pilots; common eye-in-hand sensor rigs
- Assumptions/dependencies: Accurate IK; respect for arm kinematics and reach; consistent eye-in-hand calibration; contact anchor tracking via robot kinematics
- Low-cost data collection pipeline for rapid adaptation
- Sectors: Robotics R&D, startups, enterprise automation teams
- Tools/products/workflows: Handheld CAP gripper + iPhone + AnySense app to gather targeted demos for a new site; SAM2-based gripper state labeling; MoCo pretraining; VQ-BeT training; quick iteration
- Assumptions/dependencies: Staff time to collect a few hours of high-quality demonstrations; basic ML training infra; SAM2 segmentation quality
- Simulation-in-the-loop regression testing and model selection (EgoGym)
- Sectors: Robotics software, MLOps/DevOps for robotics
- Tools/products/workflows: EgoGym procedural scenes as a fast, generalization-sensitive metric; CI pipelines that gate policy changes on EgoGym success curves; failure-mode discovery pre-deployment
- Assumptions/dependencies: Sim-to-real correlation similar to reported (established for CAP-Pick); coverage of targeted scene/object diversity; API integration into CI
- Long-horizon task composition via tool-calling
- Sectors: Robotics, software, smart-home
- Tools/products/workflows: High-level VLM planner orchestrating CAP-Pick/Open/Close plus base navigation and Drop scripts for composite tasks (e.g., fetch from cabinet, table cleanup)
- Assumptions/dependencies: Reliable vision-LLMs (e.g., GPT-4o, Gemini Robotics-ER 1.5) for contact-point proposals and verification; retry loops; safeguards against verifier false positives
- User-guided “contact prompting” UX for reliable intent specification
- Sectors: Consumer robotics, B2B robotics
- Tools/products/workflows: Tap-to-select contact point interface; VLM “point to X” automation; standardized contact-anchored API replacing fragile free-form commands
- Assumptions/dependencies: Depth availability at the clicked pixel; occlusions handled; stable camera intrinsics; user or VLM chooses a valid contact on the intended object
- On-device preview and preflight validation with iPhone app
- Sectors: Field operations, QA, education, consumer
- Tools/products/workflows: Real-time on-phone inference showing predicted motions and gripper actions before commanding a robot; safe PTAs (pre-task assessments)
- Assumptions/dependencies: ARKit tracking stability; latency acceptable for preview; similar vantage to robot’s eye-in-hand camera
- Academic teaching, replication, and benchmarking
- Sectors: Academia, workforce development
- Tools/products/workflows: Course modules using open-sourced CAP code, data, and EgoGym; student labs on data collection with handheld gripper; reproducible utility-model baselines
- Assumptions/dependencies: Access to modest GPUs; 3D printing resources; off-the-shelf arms or sim-only exercises
- Energy- and cost-efficient edge deployment
- Sectors: Robotics platforms, embedded/edge AI
- Tools/products/workflows: CAP policies (52M params) running at 2 Hz on CPU/NUC or on mobile Neural Engines; improved battery life; privacy-preserving on-device inference
- Assumptions/dependencies: Performance sufficient for target tasks; thermal budgets; conservative safety margins
- Procurement and policy evaluation playbooks
- Sectors: Public sector, enterprise procurement, safety/compliance
- Tools/products/workflows: Incorporate EgoGym-like generalization tests and CAP-style utility model evaluations into RFPs; emphasize compositional, verifiable skills over monolithic models
- Assumptions/dependencies: Availability of standard scenes/tasks; acceptance that sim metrics correlate with real performance; vendor transparency
- Accessibility and eldercare assistance (pilot deployments)
- Sectors: Healthcare (non-clinical), assistive tech, aging-in-place
- Tools/products/workflows: CAP for fetching objects, opening drawers/doors; human-in-the-loop contact prompting; conservative retry with verification
- Assumptions/dependencies: Strict safety layers; slow speeds and force limits; curated home layouts; reliable depth on common household objects
Long-Term Applications
These require additional research, scaling, hardware integration, regulatory maturation, or robustness improvements (e.g., multi-contact, heavier loads, extreme clutter, safety-critical environments).
- Multi-contact and bimanual manipulation
- Sectors: Manufacturing, service robotics, research
- Tools/products/workflows: CAP extended to multiple simultaneous anchors or distributions over contacts; bimanual coordination (e.g., hold-and-unscrew, two-hand cabinet operation)
- Assumptions/dependencies: New model interfaces for multi-anchor conditioning; richer data; tactile and force sensing integration; coordinated control policies
- Complex assembly/disassembly and tool use
- Sectors: Light manufacturing, repair, maker spaces
- Tools/products/workflows: Contact-sequence graphs for multi-step assemblies; CAP-conditioned actions informed by tool affordances; planner that composes contact anchors for substeps
- Assumptions/dependencies: Large-scale task-structured data; reasoning over fasteners/constraints; robust detection of partial progress and failures
- Robust fully autonomous home/office agents
- Sectors: Consumer robotics, commercial buildings
- Tools/products/workflows: End-to-end autonomy combining CAP skills with high-reliability contact prompting and self-verification; lifelong learning with EgoGym-like digital twins
- Assumptions/dependencies: Stronger VLMs/verifiers with low false positives; integrated safe RL or corrective learning; reliable long-horizon memory and scheduling
- Industrial O&M (operations and maintenance)
- Sectors: Energy (substations, renewables), utilities, industrial facilities
- Tools/products/workflows: Operating panels, enclosures, and valves; opening industrial cabinets; inspection tasks tethered to contact anchors; digital procedures
- Assumptions/dependencies: Ruggedized sensors; handling reflective/transparent surfaces; torque/force requirements beyond current grippers; strict safety and certification
- Healthcare supply chain and clinical logistics
- Sectors: Healthcare systems, pharmacies, labs
- Tools/products/workflows: CAP-based drawer/cabinet handling, supply restocking, sample routing in non-sterile zones; audited task logs from verifier-guided completion
- Assumptions/dependencies: Infection control; HIPAA/PHI constraints (for perception); high-reliability verifiers; rigorous fail-safes and overrides
- Disaster response and field robotics
- Sectors: Public safety, defense, emergency services
- Tools/products/workflows: Opening obstructed doors, extracting items, operating ad-hoc latches/cabinets in unknown environments; contact prompting under degraded sensing
- Assumptions/dependencies: Depth and pose tracking under smoke/dust/low-light; robust hardware; teleop fallback; safety under uncertainty
- Standards and APIs for “contact-anchored” intent
- Sectors: Robotics standards bodies, ecosystem vendors
- Tools/products/workflows: Cross-vendor API for contact anchors; common UX semantics (tap-to-contact, VLM-anchor exchange); test suites and conformance
- Assumptions/dependencies: Industry coordination; IP-neutral interfaces; test artifacts spanning common object categories
- Safety certification frameworks for modular utility models
- Sectors: Regulators, certification labs, insurers
- Tools/products/workflows: Certification tracks for Pick/Open/Close skills with EgoGym-like standardized generalization tests, verifier-integrated retry protocols, hazard analyses
- Assumptions/dependencies: Evidence of sim–real correlation beyond CAP-Pick; standardized reporting; shared datasets and scenes
- Verifier-integrated learning (RL with automated reattempts)
- Sectors: Research, applied ML for robotics
- Tools/products/workflows: Training loops that use verifier signals and retries to improve reliability; reward shaping via EgoGym dense signals; curriculum learning
- Assumptions/dependencies: Stable and low-noise verifiers; safe exploration; scalable MLOps for continuous improvement
- Utility-model marketplace and orchestration layers
- Sectors: Robotics software platforms, integrators
- Tools/products/workflows: Reusable CAP skills as plug-ins (Pick/Open/Close variants) orchestrated by planners; telemetry and A/B testing in sim before rollouts
- Assumptions/dependencies: Licensing and IP frameworks; standardized evaluation and metadata; secure distribution
- Multimodal contact sensing (vision + tactile/force)
- Sectors: Robotics hardware, sensor vendors
- Tools/products/workflows: Contact anchors enriched by tactile arrays, GelSight-like sensors, force-torque feedback; improved contact detection and anchor propagation
- Assumptions/dependencies: Cost and durability of sensors; calibration stability; scalable data collection
- Agriculture and outdoor manipulation
- Sectors: AgTech
- Tools/products/workflows: Gate/door operation, selective picking, bin handling using contact anchors under variable lighting/weather
- Assumptions/dependencies: Outdoor-grade depth/pose; crop/contact variability; end-effectors suited for plants and produce
Key cross-cutting assumptions/dependencies for feasibility:
- Sensor reliability: accurate depth at the intended contact pixel; stable eye-in-hand calibration; robustness to occlusions, specular/transparent surfaces, and lighting variation.
- Hardware suitability: compliant and back-drivable grippers; sufficient DOF and reach; safe contact forces; mobile base when needed.
- Software stack: robust IK; consistent kinematic tracking for anchor propagation; stable on-device inference; CI pipelines with sim-in-the-loop (EgoGym).
- VLMs and verification: high-quality contact proposals; low false-positive verifiers or conservative retry budgets; guardrails for safety-critical tasks.
- Data coverage: demonstrations that span target geometries and environments; efficient labeling (SAM2) and filtering (e.g., static-frame pruning); quick site adaptation procedures.
- Governance and safety: human-in-the-loop controls, emergency stops, rate limits; adherence to sector-specific compliance (e.g., healthcare, industrial); standardized evaluation protocols.
Glossary
- 6-DoF: A six–degrees-of-freedom pose describing 3D position and 3D orientation of a camera or end-effector. "The app records synchronized RGB-D streams and 6-DoF camera poses via ARKit visual-inertial odometry at 30Hz."
- Autoregressive transformer: A sequence model that predicts the next token conditioned on previously observed tokens. "Then, second stage trains an autoregressive transformer to predict the tokenized actions given the observation sequence."
- Back-projection: Computing a 3D point in a different camera frame by transforming it using recorded poses or odometry. "we generate contact anchors with hindsight relabeling by back-projecting using the recorded camera odometry."
- Behavior Cloning (BC): A supervised learning approach that learns a policy from demonstration data by mapping observations to actions. "Behavior cloning (BC) is one of the primary ways of teaching robots intelligent behavior from humans."
- Camera intrinsics: The internal calibration parameters of a camera (e.g., focal lengths, principal point) used to map between pixels and rays. "Then, we deproject the 2D pixel using the depth map value and camera intrinsics to obtain the initial contact anchor in the camera frame"
- Contact anchor: A 3D point specifying where the robot is intended to make physical contact with the object. "We define the Contact Anchor as a 3D coordinate where the policy is expected to interact with the object."
- Contact-Anchored Policies (CAP): Policies conditioned on explicit physical contact points rather than language to guide manipulation. "We call such policies Contact-Anchored Policies~(CAP)."
- Deprojection: Recovering a 3D point in camera coordinates from a 2D pixel and its depth using camera intrinsics. "Then, we deproject the 2D pixel using the depth map value and camera intrinsics to obtain the initial contact anchor in the camera frame"
- Delta end-effector pose: The incremental change in the gripper’s 3D pose (translation and rotation) between timesteps. "the action space consists of the delta end-effector (EE) pose and the gripper aperture."
- Dense reward signal: A reward function that provides feedback at many timesteps, not only upon completion. "Each environment provides a simple dense reward signal."
- Distribution shift: A change in data distribution between training and evaluation scenarios that can degrade performance. "success in these simulation environments under distribution shift is a great metric for capturing the emergence of general behavior."
- Distractor objects: Irrelevant objects placed in a scene to test robustness against confusion or misidentification. "Across all three tasks, additional diversity is introduced by randomizing surface textures and adding distractor objects."
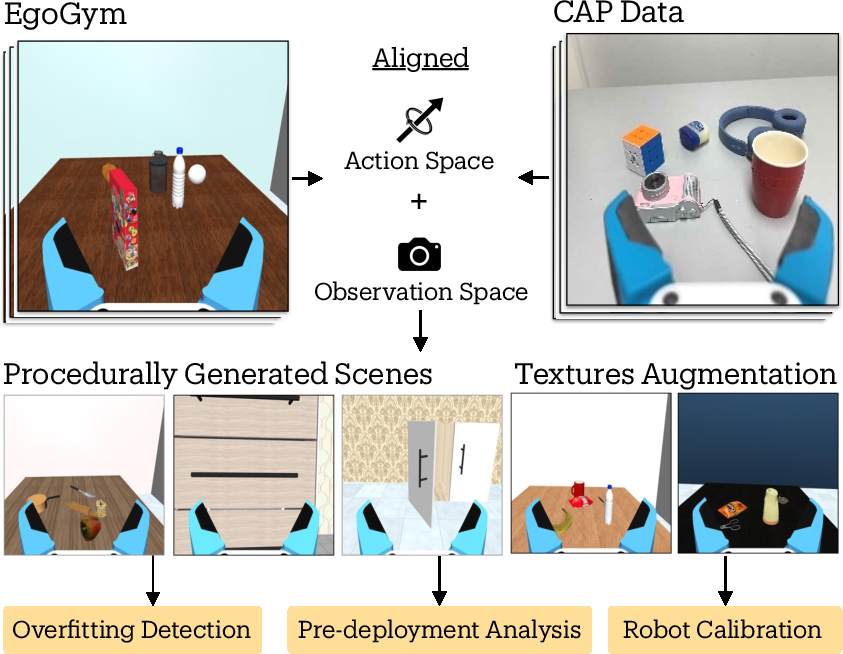
- EgoGym: A lightweight, fast simulation suite focused on scene diversity for iterative development and evaluation. "we develop EgoGym, a lightweight simulation suite used during policy training and development."
- Forward kinematics: Computing the pose of a robot link or end-effector from joint angles. "We track the anchor in the camera frame using the robot's forward kinematics, which provides higher accuracy than visual-inertial odometry."
- Gripper aperture: The opening width of the gripper fingers, often used as a continuous control variable. "For Pick and Open tasks, this is naturally defined as the frame where the gripper aperture ceases to decrease"
- Hindsight relabeling: Post-hoc relabeling of earlier timesteps with target information determined at a later time (e.g., contact point). "we generate contact anchors with hindsight relabeling by back-projecting using the recorded camera odometry."
- Inverse kinematics: Computing joint configurations that achieve a desired end-effector pose or motion. "we only adapt our robot gripper mount and the inverse kinematic controller to the specific embodiments."
- Kinematic chain: The linked structure of joints and links whose transformations determine poses along the robot. "derived from the robot's kinematic chain; the anchor is simply updated via "
- MoCo: Momentum Contrast, a self-supervised method to learn visual representations via contrastive learning. "we pretrain a ResNet-50 backbone with MoCo~\citep{chen2021mocov3} on our dataset."
- MuJoCo: A physics engine for model-based simulation of articulated structures and contacts. "EgoGym is implemented in MuJoCo \citep{todorov2012mujoco} and trades off visual realism in favor of scene diversity and execution speed."
- Objaverse: A large-scale dataset of 3D assets for training and evaluating perception and manipulation. "For our pick task, objects are sampled from a pool of 915 Objaverse~\citep{deitke2023objaverse} assets"
- Procedural scene generation: Algorithmically creating varied environments or objects by sampling randomized parameters. "We induce diversity through task-specific procedural scene generation."
- Real-to-sim iteration cycle: An iterative development loop that uses real data to inform and refine models in simulation before redeployment. "This factorization allows us to implement a real-to-sim iteration cycle"
- Residual Vector Quantized Variational Autoencoder (VQ-VAE): A discrete latent-variable autoencoder that learns codebook-based representations, often stacked residually. "by training a Residual Vector Quantized Variational Autoencoder (VQ-VAE)."
- SE(3): The Lie group of 3D rigid-body transformations combining rotations and translations. "Let denote the camera pose in the world frame at timestep ."
- Simulation-in-the-loop: Integrating simulation directly into the training or evaluation loop to guide rapid model iteration. "EgoGym: a lightweight simulation-in-the-loop environment used for quick development and evaluation of Contact-Anchored Policies (CAPs)."
- Tokenized actions: Discrete action representations obtained by quantizing continuous actions into tokens for sequence modeling. "to predict the tokenized actions given the observation sequence."
- Tool calling: Orchestrating specialized sub-policies or skills as callable “tools” under a higher-level controller. "Contact-Anchored Policies controlled by a high-level VLM controller via tool-calling."
- Vector-Quantized Behavior Transformer (VQ-BeT): A two-stage BC method that learns discrete action tokens via VQ-VAE and models sequences with a transformer. "Vector Quantized Behavior Transformer (VQ-BeT) is a behavior cloning algorithm designed to learn robotic behaviors from large, multi-modal behavior datasets."
- Verifier-guided retrying: A loop where an external verifier assesses success and triggers retries until completion or failure. "This work also introduces verifier-guided retrying for robotics, where with guidance from an automated verified, a robot gets to retry a task until it is stuck or successful."
- Vision-LLM (VLM): A model that processes both visual inputs and natural language to output predictions or instructions. "This selection can be performed manually, or by querying an off-the-shelf VLM (e.g. Gemini Robotics-ER 1.5~\citep{team2025gemini}) with a text prompt"
- Vision-Language-Action (VLA): Models that map vision and language inputs directly to action outputs for robotic control. "outperforms large, state-of-the-art VLAs in zero-shot evaluations by 56\%."
- Visual-inertial odometry: Estimating motion by fusing visual data with inertial measurements (e.g., IMU). "The app records synchronized RGB-D streams and 6-DoF camera poses via ARKit visual-inertial odometry at 30Hz."
- Zero-shot generalization: Performing well on novel tasks, objects, or environments without any additional fine-tuning. "generalize zero-shot to novel objects and scenes with orders of magnitude less data"
Collections
Sign up for free to add this paper to one or more collections.