- The paper introduces a novel sequence-to-sequence framework to vectorize raster floorplans into labeled polygon sequences.
- An anchor-based autoregressive decoder fuses image features with coordinate embeddings to enhance geometric regression and semantic accuracy.
- Extensive evaluations demonstrate state-of-the-art F1 scores, robust cross-dataset generalization, and effective support for downstream 3D scene generation.
Sequence-to-Sequence Polygon Generation for Floorplan Reconstruction: Raster2Seq
Problem Definition and Motivation
Rasterized floorplan images are ubiquitous in architectural design, yet their lack of structural and semantic detail limits their suitability for downstream computational tasks including CAD, automated editing, semantic understanding, and 3D reconstruction. Existing conversion techniques—ranging from heuristic-based methods to transformer-centric deep architectures—have demonstrated substantial progress on regular layouts, but typically fail to generalize to complex geometries with dense, irregular, multi-room arrangements. The paper "Raster2Seq: Polygon Sequence Generation for Floorplan Reconstruction" (2602.09016) introduces a sequence-to-sequence approach for robust floorplan vectorization, directly targeting the challenges of variable-length entities, semantic integration, and generalization capacity.
Labeled Polygon Sequence Representation
The core contribution is the modeling of a floorplan as a sequence of labeled polygons, where each polygon is represented as a series of corner tokens (ci=(xi,yi,pi)), with pi encoding semantic class probabilities for each corner. This approach captures both geometric and semantic attributes at token-level granularity, allowing windows and doors to be encoded as additional semantic classes in the same sequence. Polygons are separated by special tokens (<SEP>, <BOS>, <EOS>), naturally supporting variable-length and complex layouts without information loss or post-processing. Token-level semantic classification is integrated directly via cross-entropy supervision, avoiding dilution effects observed in prior methods.
Autoregressive Anchor-Based Decoder Architecture
A technical highlight is the anchor-based autoregressive decoder that fuses image features, quantized coordinate embeddings, and learnable anchors to sequentially generate corner tokens. The decoder is composed of masked attention (with a causal mask for left-to-right bias), deformable attention (to attend to local spatial regions guided by anchor points), and feed-forward layers. Anchors serve as geometric reference points, with the decoder predicting residuals relative to these anchors, significantly improving regression accuracy for complex geometric layouts.
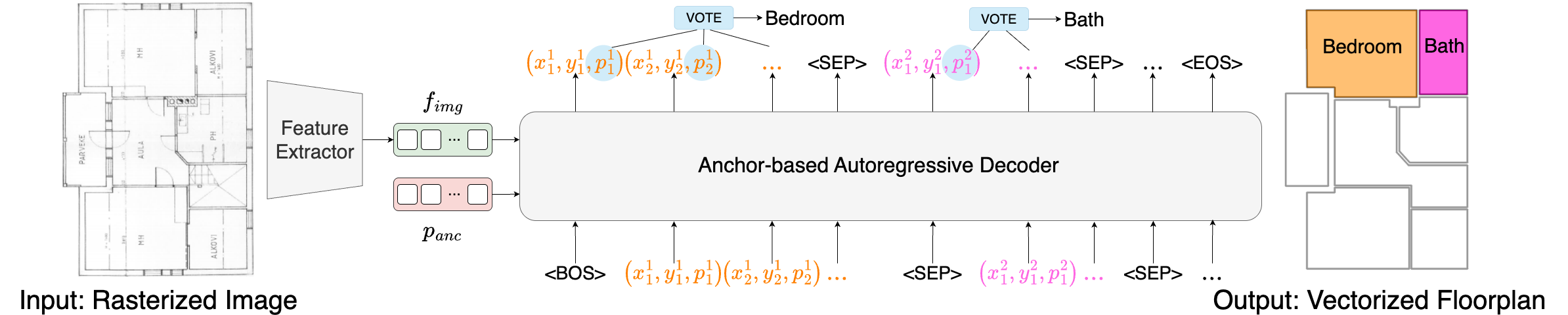
Figure 1: The method overview shows the raster-to-vector pipeline, labeled polygon sequence with <SEP> tokens, and the integration of image features, anchors, and previously generated tokens in the autoregressive decoder.
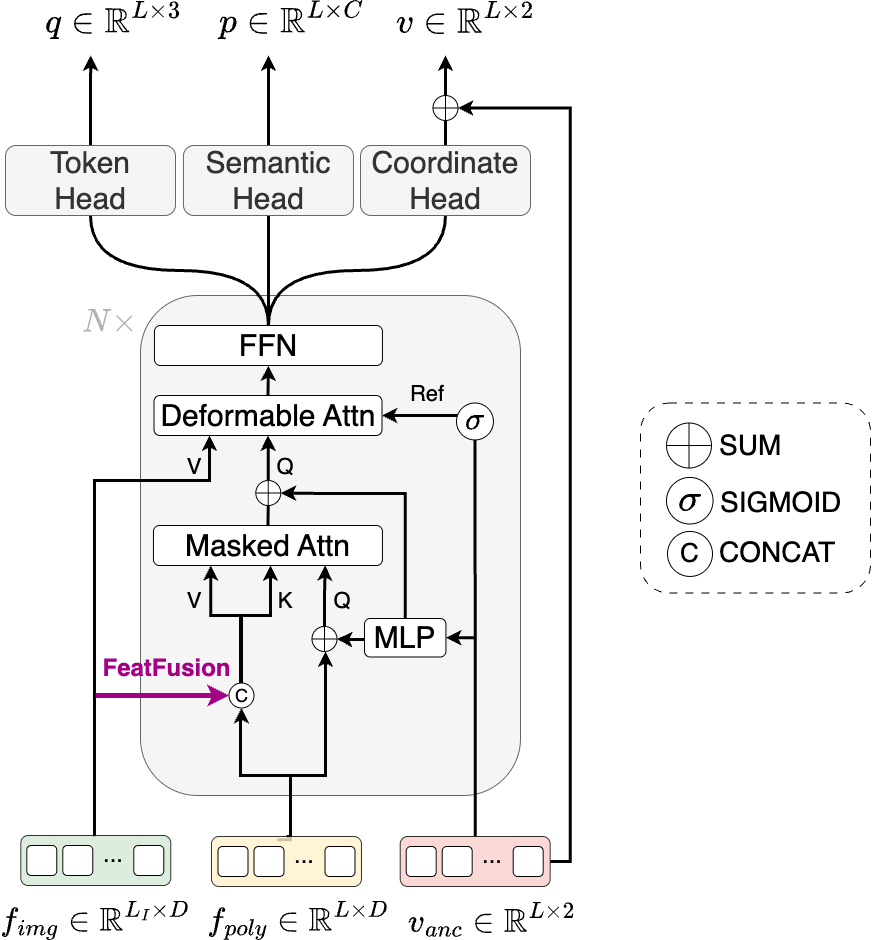
Figure 2: The anchor-based autoregressive decoder architecture illustrating input fusion and causal sequence modeling.
The FeatFusion operation concatenates image features and coordinate embeddings, enabling enriched context during token prediction. The decoder maintains three output heads: (i) token-type head, (ii) semantic head, and (iii) coordinate head (predicting residuals to anchors).
Training and Sequence Order
The loss consists of coordinate regression (L1), token-type classification (cross-entropy), and semantic classification (cross-entropy), applied only to non-padded tokens. Room sequences are ordered left-to-right (top-to-bottom, left-to-right priority), which establishes a geometric inductive bias and improves autoregressive learning.
On Structured3D-B, CubiCasa5K, and Raster2Graph datasets, Raster2Seq achieves state-of-the-art F1 scores for room, corner, angle, and semantic metrics. Notably, performance gaps increase with floorplan complexity (polygon or corner count), and the method demonstrates stable robustness where baselines (e.g., RoomFormer, FRI-Net, PolyRoom) suffer capacity degradation or memory constraints for large-scale layouts.
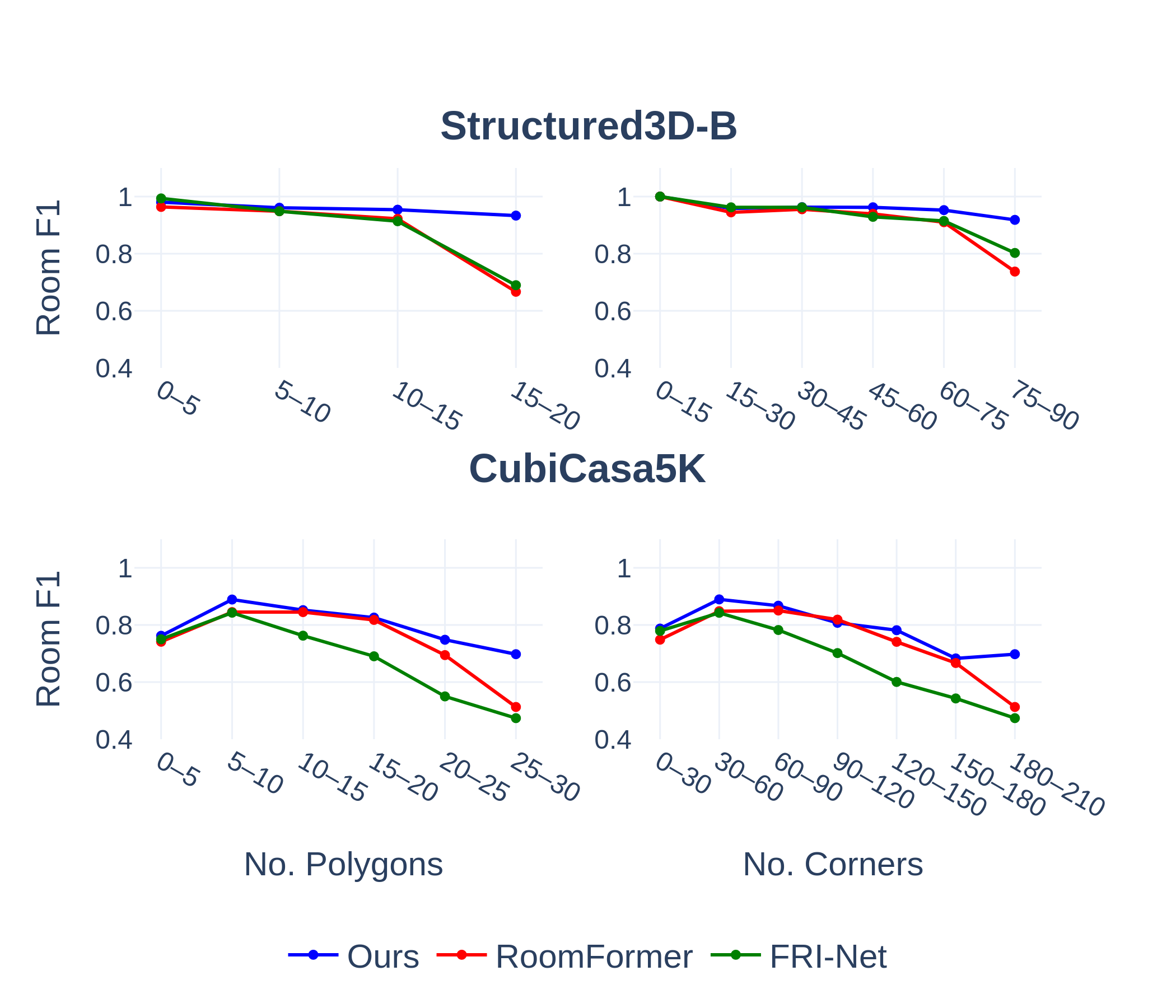
Figure 3: Room F1 scores vs. number of polygons and corners demonstrate superior robustness of Raster2Seq on increasingly complex floorplans.
Cross-dataset generalization experiments further emphasize the model's capacity to learn transferable representations, outperforming counterparts on zero-shot evaluation over real-world Internet data (WAFFLE).
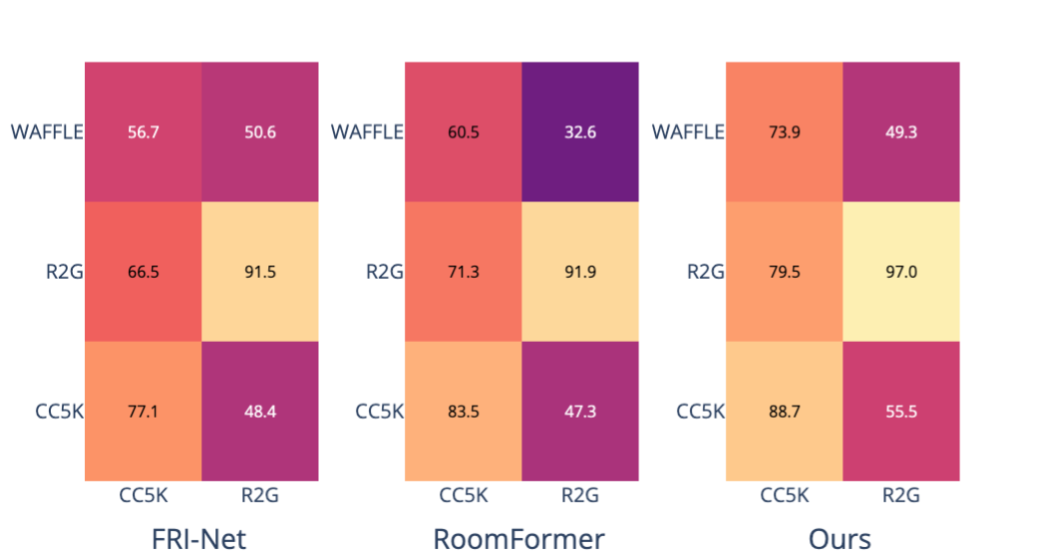
Figure 4: Cross-evaluation heatmaps visualize superior generalization ability across train-test splits, validating robustness beyond the training distribution.
Qualitative and Downstream Applications
Visual reconstructions illustrate geometric fidelity, semantic accuracy, and completeness. The model avoids artifacts such as "short-cut" polygons seen in non-autoregressive baselines. On CubiCasa5K and WAFFLE, Raster2Seq produces more consistent layouts and semantic segmentation.
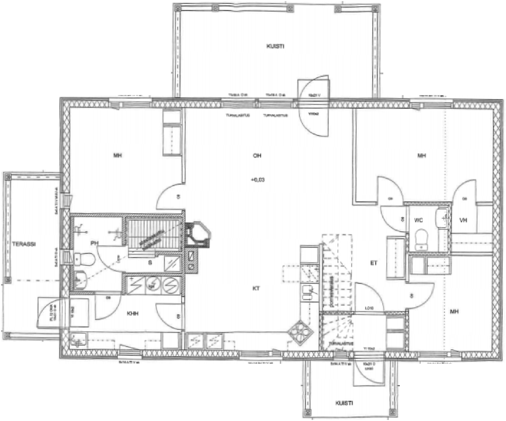
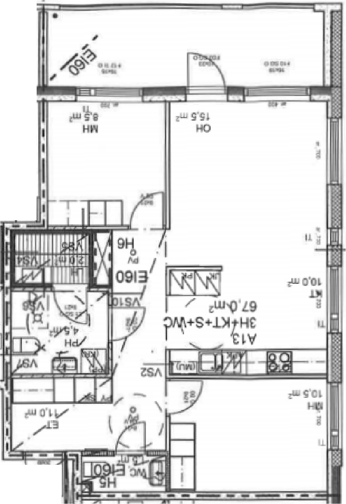
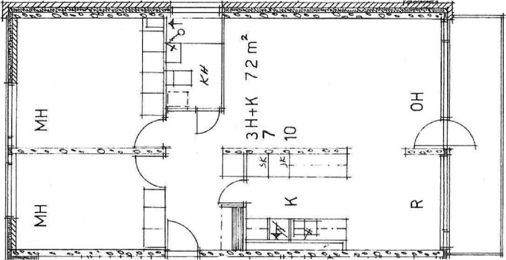
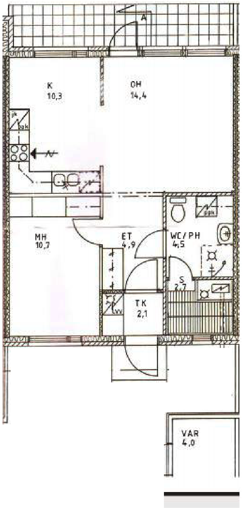
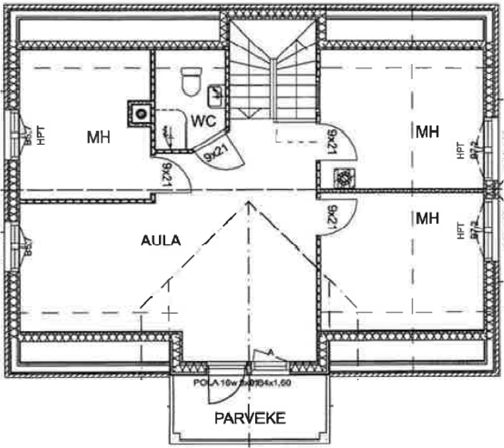
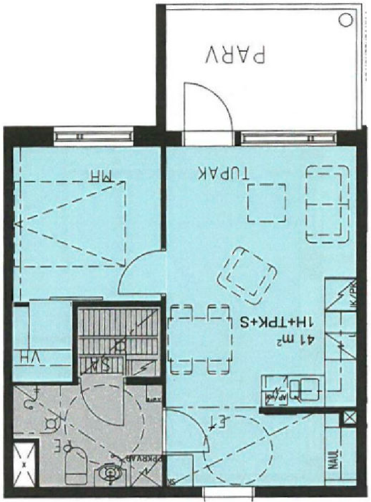
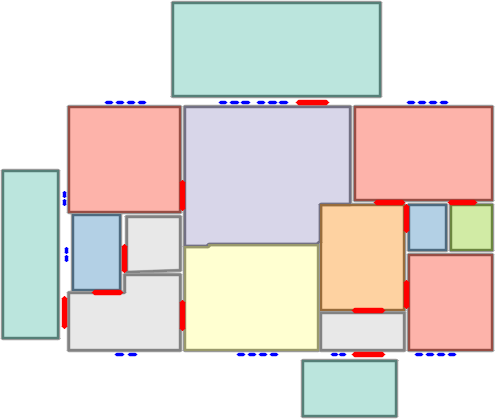
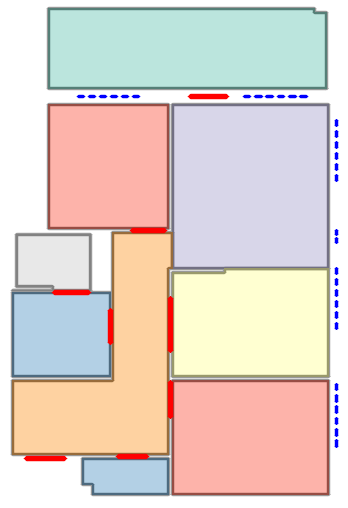
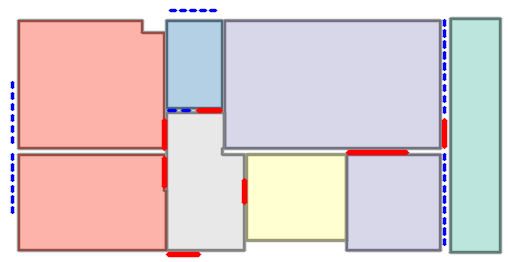
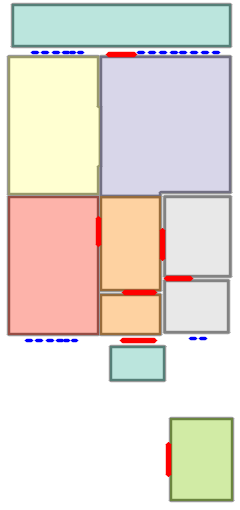
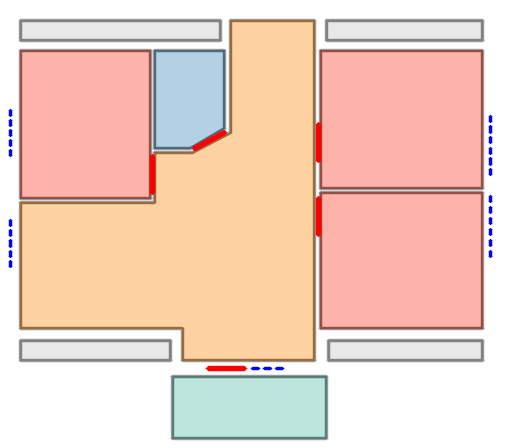
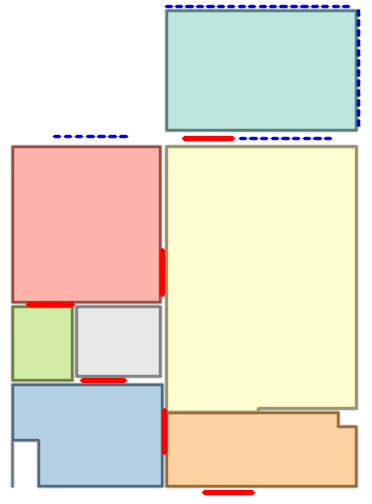
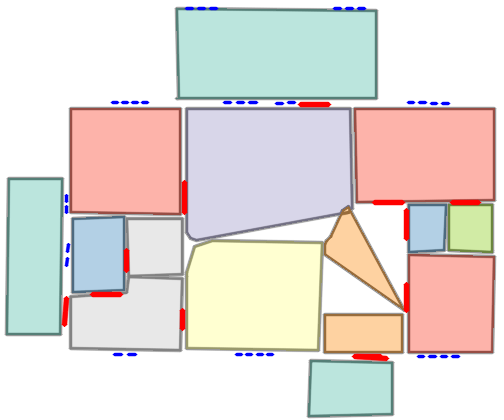
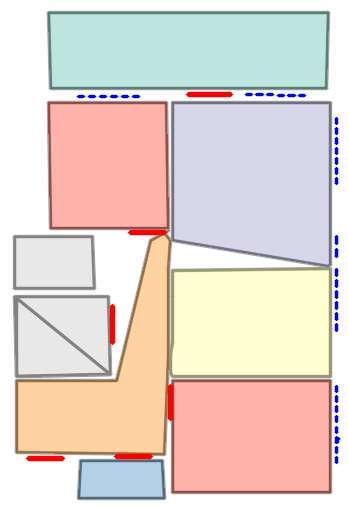
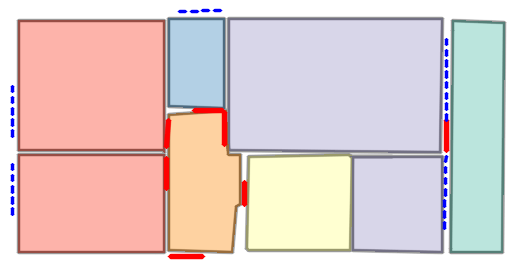
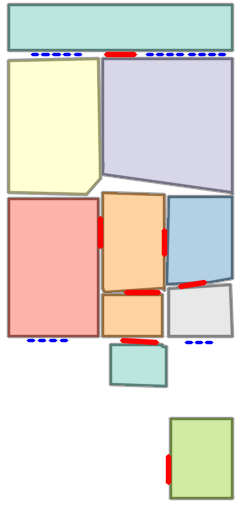
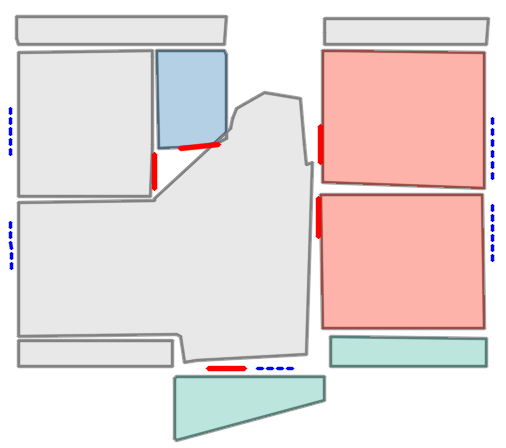
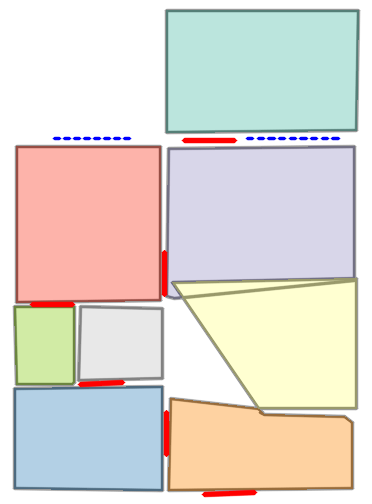
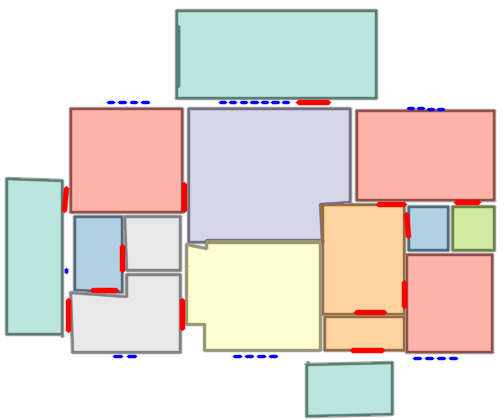
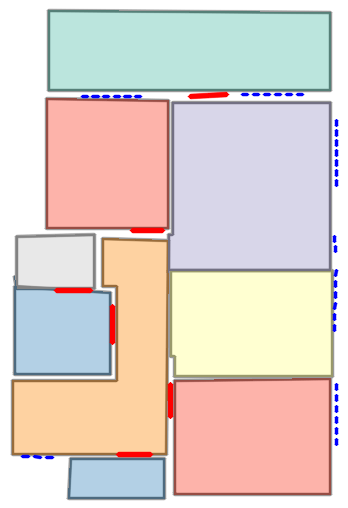
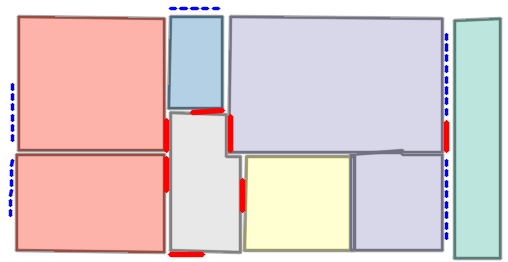
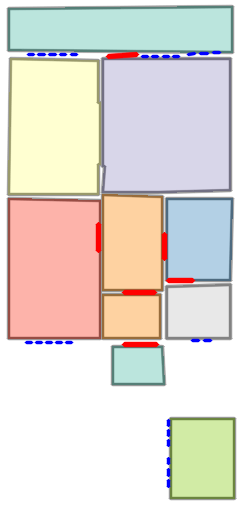
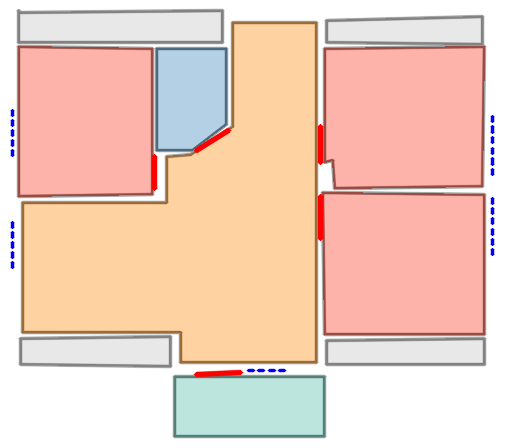
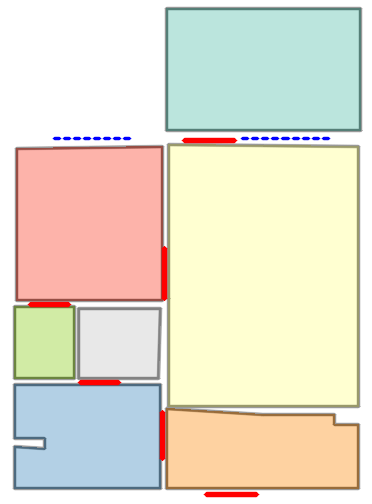
Figure 5: Qualitative comparison with RoomFormer on CubiCasa5K demonstrates improved room boundary adherence and semantic accuracy.
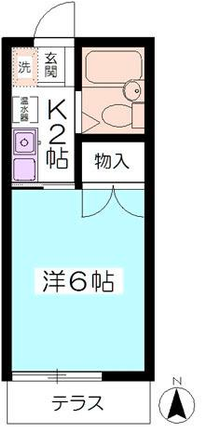
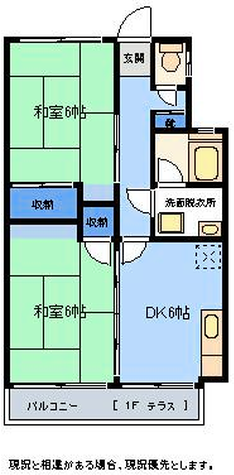
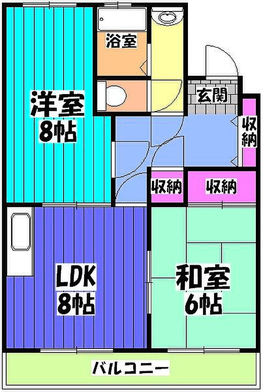
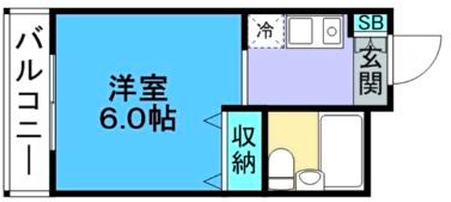
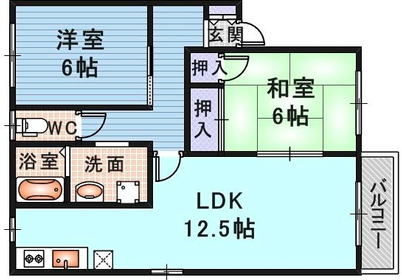
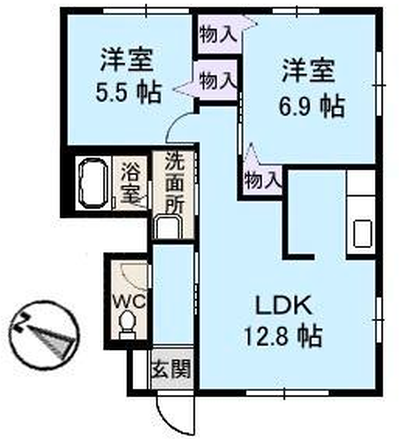
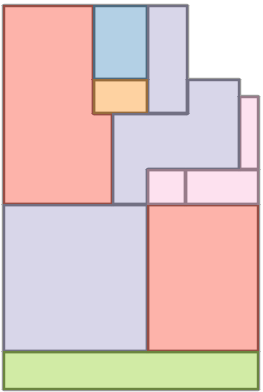
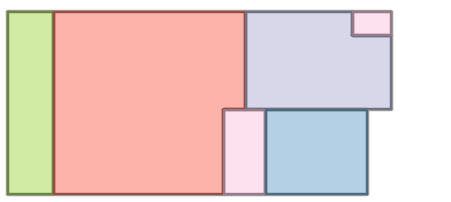
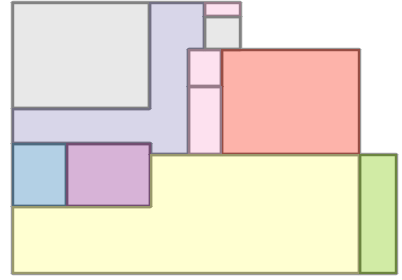
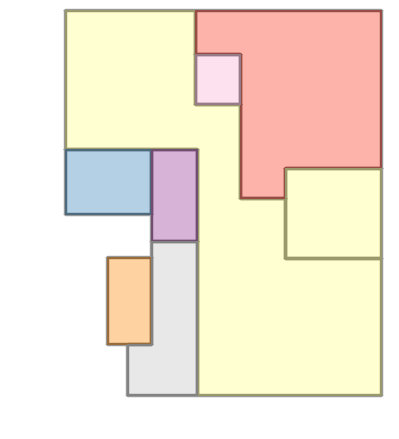
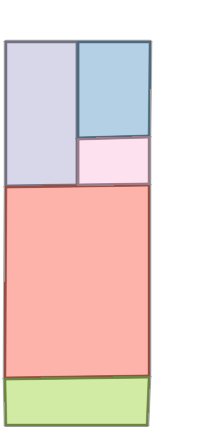
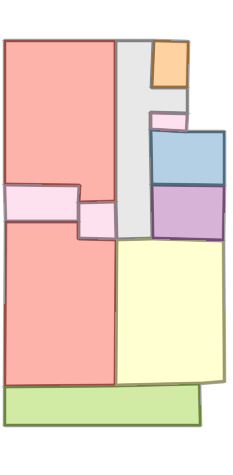
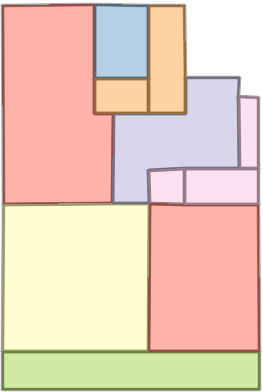
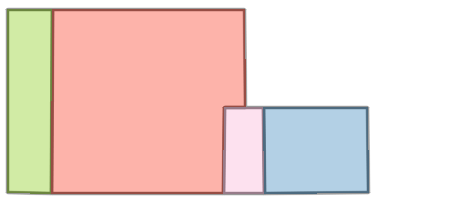
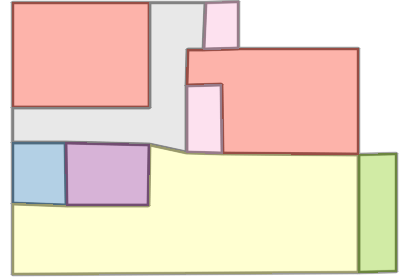
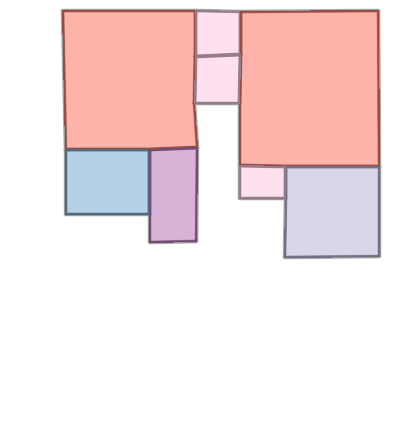
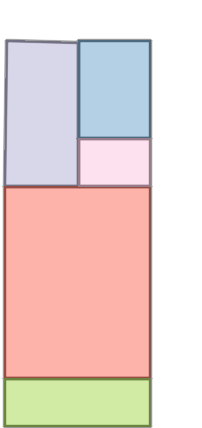
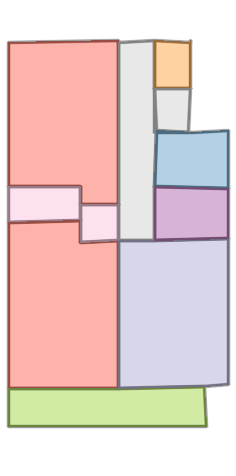
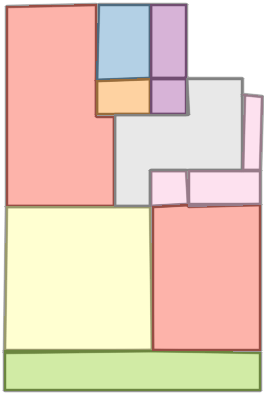
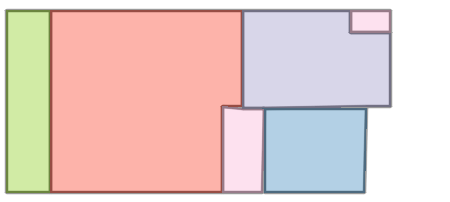
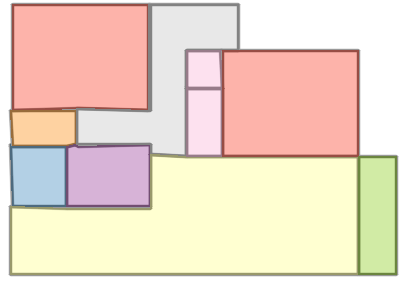
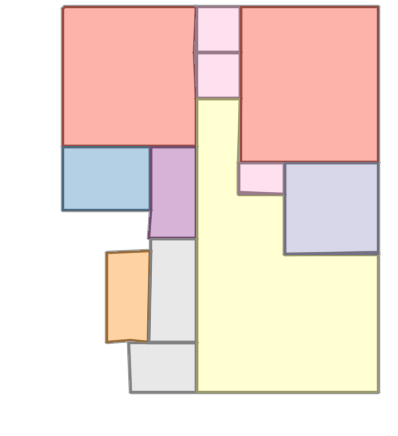
Figure 6: Comparison with Raster2Graph on their dataset shows that the autoregressive approach preserves completeness and avoids incomplete reconstructions.
Vectorized floorplans support downstream geometry-guided 3D generation, providing spatial priors for volumetric scene synthesis.

Figure 7: Controllable 3D scene generation from vectorized floorplans showcases the utility for spatial guidance in architectural modeling.
Ablation Studies
Ablations confirm the contribution of FeatFusion, learnable anchors, and sequence ordering. Integration of these architectural elements yields gains in all geometric metrics. Quantization resolution, sequence length, and coordinate loss coefficient were tuned for optimal trade-off; learnable anchors outperform random initialization.
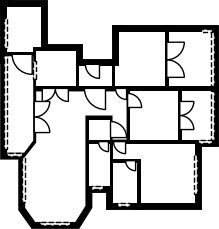
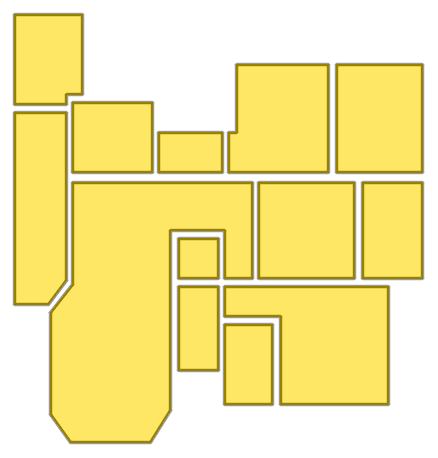
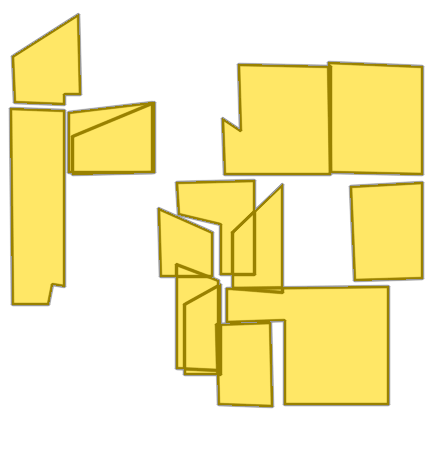
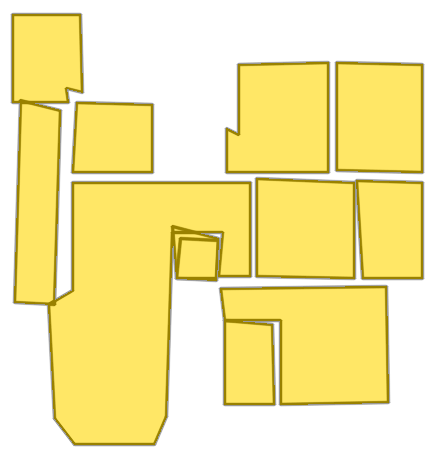
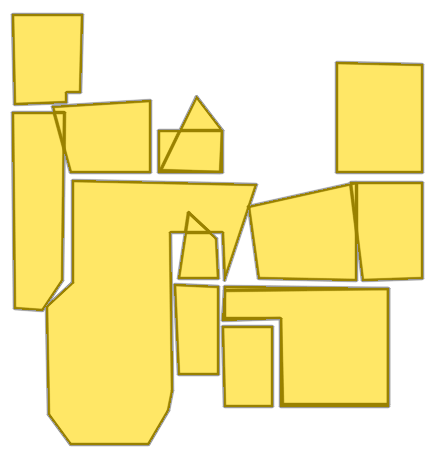
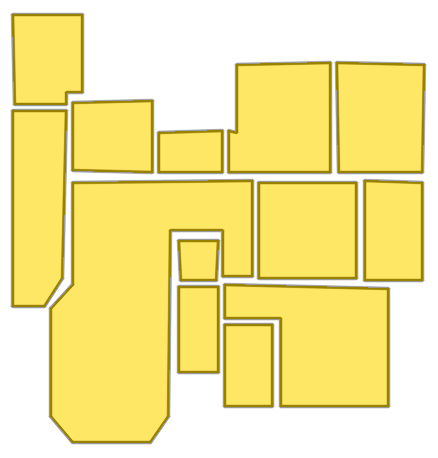
Figure 8: Sequential ablation on Structure3D-B evidences incremental improvement with each component, achieving near-perfect alignment.
Limitations and Future Directions
The model occasionally mislocalizes windows and doors, especially in rare configurations, suggesting a need for dedicated modeling or post-hoc refinement for less prevalent semantic classes. Open-vocabulary prediction and further augmentation could enhance adaptation to diverse, historical, and hand-drawn samples.
Conclusion
Raster2Seq reframes raster-to-vector floorplan conversion as a sequence generation problem, leveraging autoregressive modeling with token-level semantic supervision. It delivers state-of-the-art performance for complex, variable-length, and semantically rich layouts, with demonstrated generalization and utility in downstream 3D scene generation. The architectural innovations—particularly anchor-based attention and fusion mechanisms—represent a robust framework for scalable structured image-to-geometry conversion. Theoretical implications include the expansion of sequence modeling protocols to visual-structural domains and practical impact on CAD, scene synthesis, and interactive editing. Future research may involve adaptation to less prevalent semantic elements and broader semantic granularity for historical and cross-cultural floorplan datasets.
References
For further details and numerical results, refer to "Raster2Seq: Polygon Sequence Generation for Floorplan Reconstruction" (2602.09016).